前言
在「端智能」概念愈发火热的今天,前端同学是否能在其中找到自己的位置,这是我们应该关注的。放眼今天前端承担的责任早已超过最初业界赋予前端的定义,就是因为有那么一群人在不断探索,不断扩展自己的领域边界。最近看到这篇较早之前的文章,比较感兴趣,顺手把文章也翻译并混合了一些自己的文字,代码也拿过来跑了一下,就当是春节娱乐活动吧。
机器学习通常会被认为其属于数据科学领域,这里是 Python 开发者们的天下。然而在过去的许多年里,众多开源框架的诞生使得不少语言也都具备了这样的能力,其中就包含 JavaScript。本文将用几个小例子带领大家使用 TensorFlow.js 去探索一些在浏览器端应用的可能性。
什么是机器学习 ?
在开始 coding 之前,让我们先简单谈一谈机器学习是什么以及其中的一些概念和术语吧。
定义
通俗的定义是指计算机无需专门编程而是从数据中进行学习的能力。
如果我们对比传统编程来看,上面那句话的意思就是说我们让计算机在没有人工干预的情况下去识别数据中的模式并生成预测结果。
以诈骗侦查为例,实际上并没有严格标准来判定一次交易是否为诈骗。诈骗行为可以发生在任何城市、银行账户、消费者和任何时间等等条件。想要去人工追踪这些信息实在是不可能完成的任务。
然而,利用之前收集的大量诈骗数据,我们可以训练一个机器学习的算法来理解这些数据中的模式,根据任意一次交易数据生成一个模型来预测该次交易是否存在诈骗行为的概率,省去了告诉计算机该怎么做,做什么的问题。
核心概念
为了便于理解后面的代码示例,我们先来认识几个常见的术语。
Model(模型)
当你在用数据集训练一个算法时,model 就是一次训练过程的输出结果,它的作用有点儿像是一个函数:接收数据作为输入,产生预测结果作为输出。
Labels(标注) 和 Features(特征)
label 表示如何将你的数据集中的条目进行分类并进行标记。比如说我们有这么一个数据集描述了不同的动物,我们的labels可能就是「猫」、「狗」、「蛇」等等。
features 则是描述你数据集中每一条目的特征属性,还是上面的例子,对应的特征属性可能就是「有胡须、喵」、「爱闹、汪」、「爬行动物、凶猛」等。
有了这些东西,一个机器学习算法就能找出特征之间的一些联系,label则会被用于未来的预测结果。
Neural Networks(神经网络)
Neural Networks 就是一连串的机器学习算法利用人工神经网络层模拟人类大脑的工作方式,在本文不再深入讲解。
现在我们已经知道了一些常用术语,下面就来看看使用 JavaScript 和 TensorFlow.js 能做些什么吧。
三种主流使用方式
- 使用预训练模型
- 迁移学习
- 使用你自己的模型
1. 使用预训练模型
取决于你想解决的问题,市面上也许已经存在一个使用指定数据集训练好的模型来解决某种问题,你可以稍加改造应用到自己的代码中。
举个栗子,我们要做一个图片识别的功能,就可以使用一个广为人知的图片分类模型 —— MobileNet 进行开发。该模型可以在 TensorFlow.js 的官网上找到。
使用预训练模型极其简单,可以直接引用CDN,也可作为npm modules进行安装到本地(此种方法会让训练过程快一点儿)。下面是简单的 API 调用过程:
const predictImage = async () => {
const img = document.getElementById('image');
console.log("模型加载中...");
const model = await mobilenet.load();
console.log("模型加载完毕!")
const predictions = await model.classify(img);
console.log('预测结果: ', predictions);
}
这个模型做了一件事,就是识别我们上传的图片并进行预测这张图片的内容,返回带有三个结果的数组,按概率大小依次排序,下面是我跑了两次得出的结果:
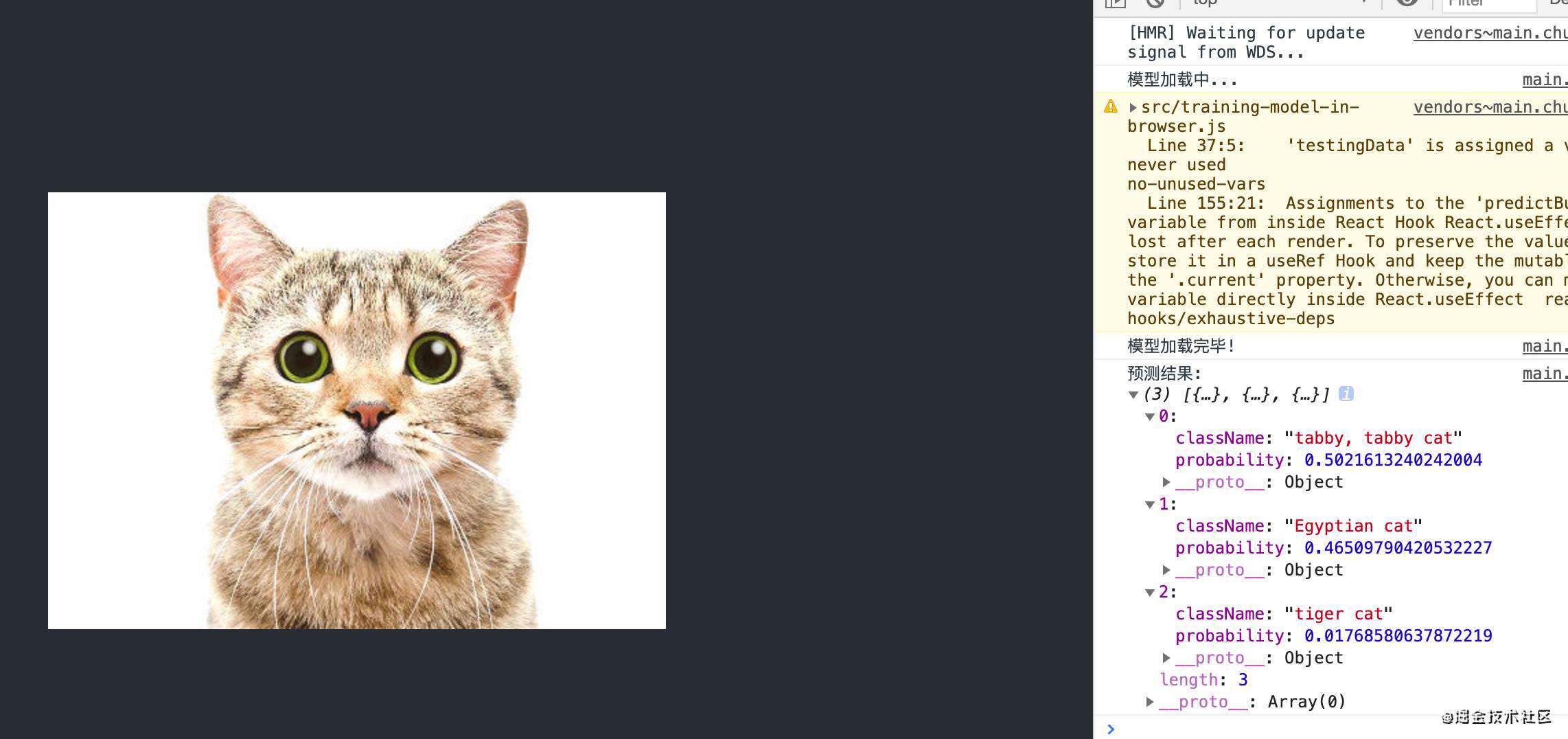
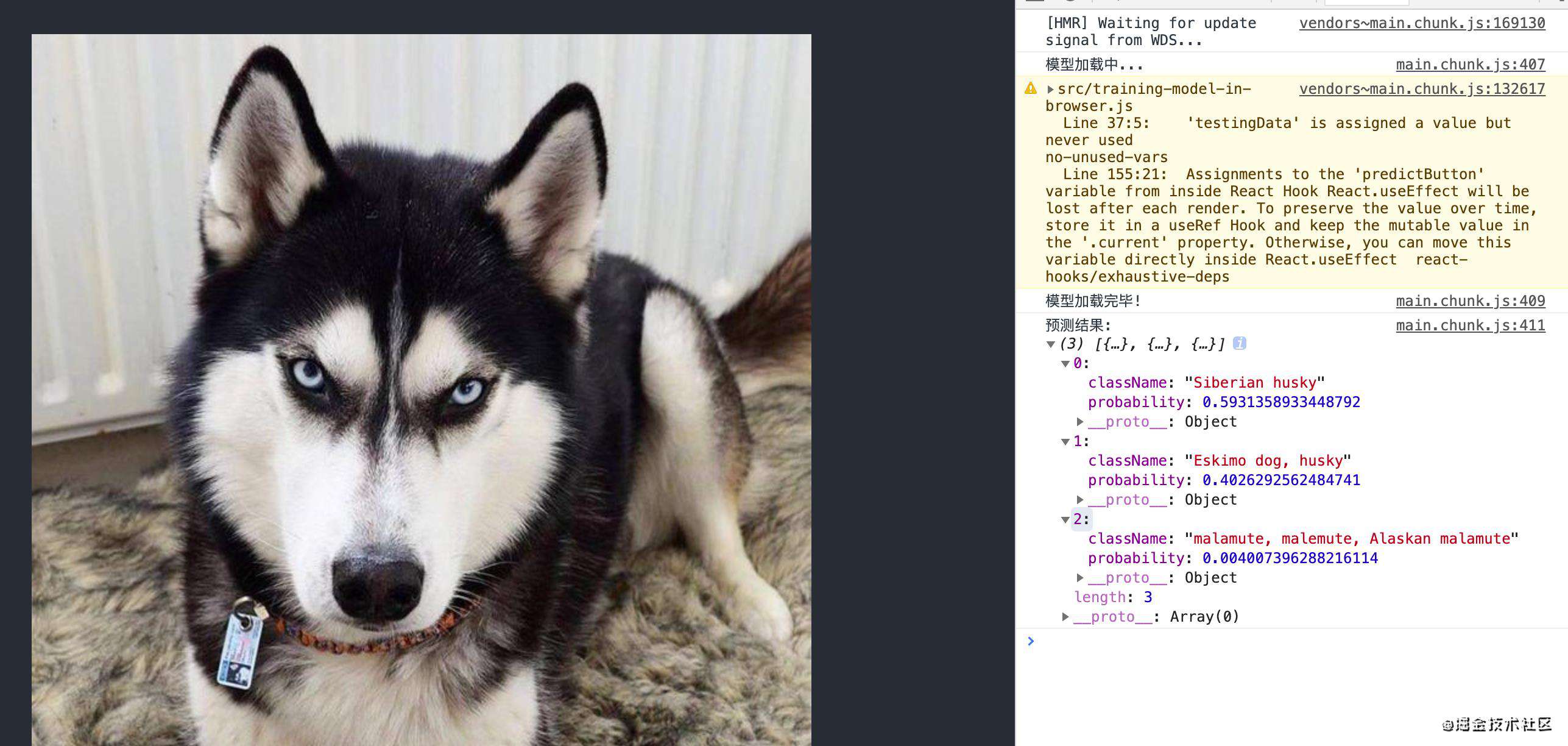
完整代码在这里可以看到。这就是 TensorFlow.js 的预训练模型在浏览器中的使用。
2. 迁移学习
迁移学习结合了预训练模型加定制化数据集的能力,也就是你可以使用一个现存模型功能的同时又能添加自己的样本数据进去,而不用从零开始创建一个模型。这一特性使得我们可以快速又简便的拥有一个可定制化的分类器。
迁移学习的应用示例,该功能是为了实现即时采集人物歪头方向样本并作出预测判断后续动作。模型分别从左右方向各采集一定数量的样本进行学习,最后点击test prediction后,可以自动判断出我们的歪头方向(这个功能有没有很眼熟)。
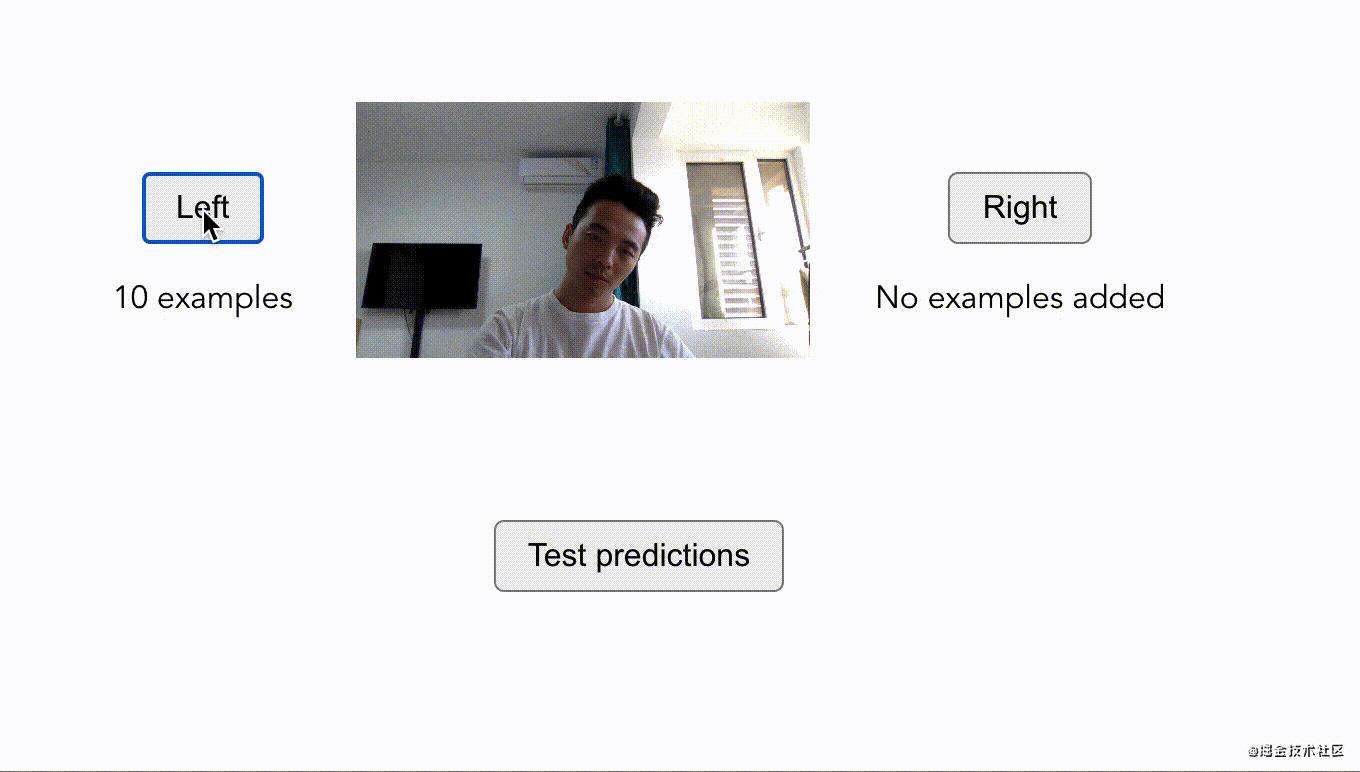
这里用到了一个KNN分类器,结合了MobileNet 模型进行功能的定制化。完整代码可以看这里。细节不再一一讲解,可参考原文。
3. 使用你自己的模型
最后一种方式是完全在浏览器中进行定义、训练和运行一个模型。为了阐述这个例子,我们来创建一个识别鸢尾花的经典例子。
构建一个神经网络来分类识别鸢尾花的3个品类,分别是 Setosa, Virginica, 和 Versicolor(数据集里是这样分的),基于一个开源数据集。
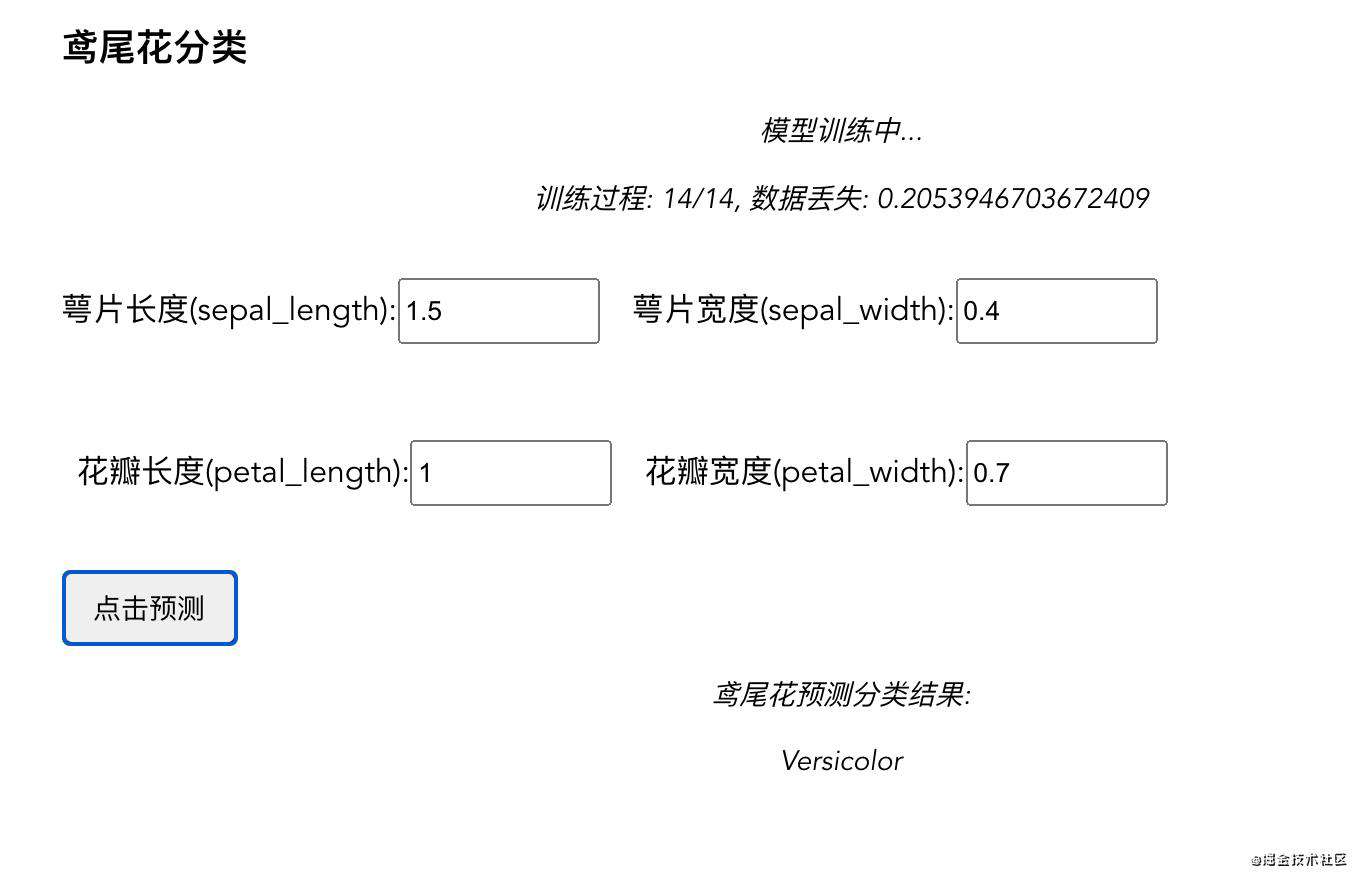
每一个机器学习项目的核心都是数据集。训练模型的第一步就是要将数据集分为训练集和测试集。原因是我们要用训练集去训练我们的算法,测试集用来测试我们算法预测的准确度,从而验证我们模型的可用性或者是否需要改进。例子中的数据集和代码可以在这里找到,里面包含的130+条数据。
数据长这个样子:
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2,
"species": "setosa"
}
如图所示,你可以看到这里面的参数、数据集等等都是我们自己可控的,可定制程度较高。看到了吧,这其实就是一个TensorFlow.js实现的简单的神经网络!
如果你想保存这个模型用于预测其他数据,执行下面的操作即可:
await model.save('file:///path/to/my-model'); // in Node.js
局限性
说完了TensorFlow.js目前主流的三种模型训练方式,下面也要说一说在前端应用机器学习的局限性了。
1. 性能
使用预训练模型时,外部资源会严重影响我们的应用。比如一些物体检测模型的大小会超过10MB,这会使得我们网站的性能显著降低。确保综合考虑用户体验并优化资源加载速度来提升性能。
2. 数据的质量
如果你想从零构建一个自己的模型,那就需要自行收集数据或使用开源数据集。在进行数据处理之前务必要确保数据的质量。比如你想做一个情绪识别模型,一定要确保你所使用的数据集的准确性和多样性。如果从数据上就不够准确,那输出结果大概率也是不可用的。
3. 可信度
使用开源的预训练模型是十分快速又省力的选择。但也意味着你并不清楚它是如何被训练出来的,数据集是否全面,算法是哪一个,这类黑盒模型也增加了预测结果的不确定性。
总结
总而言之,使用 JavaScript 和 TensorFlow.js 这样的框架依然是入门机器学习的一种较好途径。即使相关项目大概率都是使用Python等语言实现的,JavaScript 依然是开发者学习相关知识的一个优秀语言。
在本教程中,我们仅提到了使用 TensorFlow.js 的几点可能性。相关工具库的数量正如雨后春笋般增长,更多特定的机器学习框架也被开发出来,允许你在不同的领域探索。比如音乐领域的magenta.js,预测用户网站行为导航的guess.js。
随着工具变得越来越高效可靠,使用 JavaScript 构建基于机器学习的应用指日可待,扩展边界的机会就是现在,加油吧少年们。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!