前言
app流量识别是无数计算机学生的毕设,虽然是一个有些陈词滥调的题目,但是这个毕设还是治好了我的人工智能ptsd。很早就知道淘宝工坊的Yorkie大佬安利的pipcook/boa,可以让js调用python的库,于是俺搞了个appscanjs。
使用方式
安装
npm install appscanjs
./node_modules/.bin/bip install dpkt ipaddress scikit-learn
例子
const Appscan = require('appscanjs');
const appscan = new Appscan();
const data = appscan.processor(pcapfilePath, timeThreshold, dataScale, appTimeLog);
appscan.fit(data.xTrain, data.yTrain);
const result = appscan.predict(data.xTest);
const ret = appscan.report(data.yTest, result);
console.log(ret);
文档
new Appscan(classificationType)
classificationType有三个值,'RandomForestClassifier','RidgeClassifier','KNeighborsClassifier',分别代表随机森林算法、岭回归分类算法、k邻近分类算法。其中随机森林的分类效果最好,也是默认使用的算法。
processor(pcapFliePath, timeThreshold, dataScale, appTimeLog)
对数据进行处理
-
pcapFliePath: string pcap文件的路径
-
timeThreshold: number 突发化的阈值时间(默认为1s,一个阈值时间内的数据包称为一个突发,所以这个值越小最后得到的数据越多)
-
dataScale: float 训练集的占比,值为0到1,默认为0.7。
-
appTimeLog: object 用来对pcap文件产生的数据进行标记,毕竟训练的时候要知道每个数据包是哪个app产生的。类型为
[{label: string or number,closeTime: float}]label:app的标签,closeTime: app在pcap文件中关闭的时间。
return: {xTrain:[][],xTest:[][],yTrain:[],yTest:[]}
如果不传入appTimeLog,那么函数会返回提取完特征值的数组,可以直接放进分类器中分类。
predict(xTest, threshold)
对数据进行分类
- threshold:我使用了predict_proba产生每个预测的概率,如果这个概率低于threshold,那么会被舍弃,直接置为-1
会返回预测结果数组
fit(xTrain,yTrain)
和sklearn中的fit一样,训练分类器
report(yTest, yPred)
和sklearn中的classification_report()一样,对结果进行评估
流量分析的原理
流量获取
- 通过简单的爬虫,获取到酷安web端app的下载链接,并下载apk安装到测试手机。
- 测试手机连接电脑热点,wireshark针对虚拟网卡进行抓包
- 通过python脚本控制monkey对手机app进行模糊测试,并且在模糊测试结束后关闭app时记录时间戳,以便后续对流量进行标记的工作;并开启下一个app进行测试。
这是我比较推荐的一种获取流量的方式,还有一类方法是不连续测试app。这样能更方便的对app流量进行标记,因为每一个app对应一个pcap文件,一个pcap文件对应一个label即可;但是这样获取流量无疑也增加很多人工成本。
我们简单抓取40个app的流量-称为flow40和3个app的流量-称为flow3。
数据预处理
- pcap文件解析,这里我用的python dpkt库,从物理层层层解析到运输层,过滤掉载荷为空的数据包,同时获取数据包的源ip、目的ip、长度、时间戳。
- 流量突发化与flow化
这里有两个概念:
-
突发化:将流量按照一个阈值时间进行分割,比如1s,那么1s内的流量就称为一个突发。这个步骤的目的是将流量离散化,并且阈值时间越小代表数据的粒度越小,数据越多,理论上说会越准确,但是粒度太小也会导致训练过拟合。现在一个请求的响应时间大多低于1s,所以appscanjs中时间阈值的默认值为1,当然也可以手动传入。
-
flow化:按照流量的远端ip把同一个突发内的流量集合到同一个数组中,这里我们使用python的ipadress库判断源ip是否是本地ip(即类似192.168.xxx.xxx的ip), 这个方向是每一个数据包都具有的,我们把方向也连同数据包集合进数组中,后面有地方会用到。有意思的是flow化看似简单,但实际上只有少数方法能比较好的解决,比如使用字典,远端ip作为字典的key完成。(多刷刷leetcode还是有用的....)
-
流量标记
这时候我们传入的appTimeLog就有用啦,里面的closeTime与每一个流的最大时间戳进行对比,从而产生每一个流的标签。当然如果我们不传入appTimeLog就跳过标记环节
- 计算特征值
还记得我们对每个数据包提取的载荷长度吗,并且在flow化时也是集合的长度。实际上我们计算特征值也是对一个流内的一系列载荷长度进行的操作。
在参考文献中,作者使用了18个特征值分别是:最小值,最大值,平均值,中位数,标准偏差,方差,偏斜,峰度,百分位数(从10%到90%)以及数组的长度。但是在我的测试中发现:峰度、中位数、标准差、平均数这四个值对预测的准确度有逆贡献,去掉这四个特征值后准确率和机器学习速度都有提升。故appscanjs中只计算了其中的另外14个特征值。
这里我们就用到之前说的方向啦。同一个流内的数据,我们通过其方向(发出或者接收)再进行一次分类。所以我们的一个流就分出了3类,分别是:发出的数据包,接受的数据包,发出+接受的数据包。分别处理后,得到的特征值数量是3*14=42个,即一个流产生了42个特征值。
之前的flow40和flow3处理完后就成为了data40和data3进入我们的机器学习环节。
机器学习
appscanjs提供了三种分类算法性能差不太多,分别是:随机森林算法、k邻近算法和岭回归算法,为什么没有超级经典的svm呢?svm适合one vs all的问题,但我们的流量识别实际上是多标签问题,使用svm不但训练时间很长,而且准确率也低。
性能测试
这里我们使用data3进行nodejs机器学习和python机器学习进行一个对比
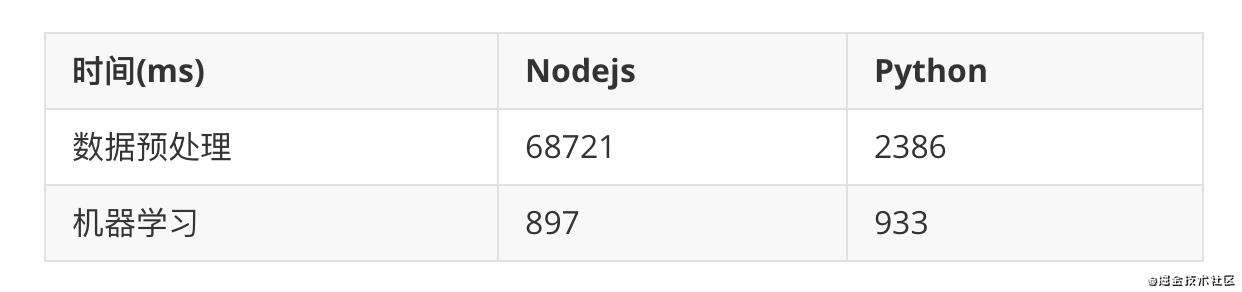
nodejs机器学习的速度和直接用python相比除去误差,起码也能打平手。但是在预处理中时间却长了很多,其实我们稍微一猜也能知道这是python和nodejs中大量的io开销导致的,因为appscanjs使用了dpkt这个python库来处理pcap文件,而pcap文件动辄1g的大小,很难不导致预处理的时间延长。
准确率测试
这里使用data40来测试。在appscanjs的文档中有一个datascala的参数,这个参数用于分割数据集为训练集和测试集。故名思义,训练集用来训练分类器,测试集用来测试准确率。
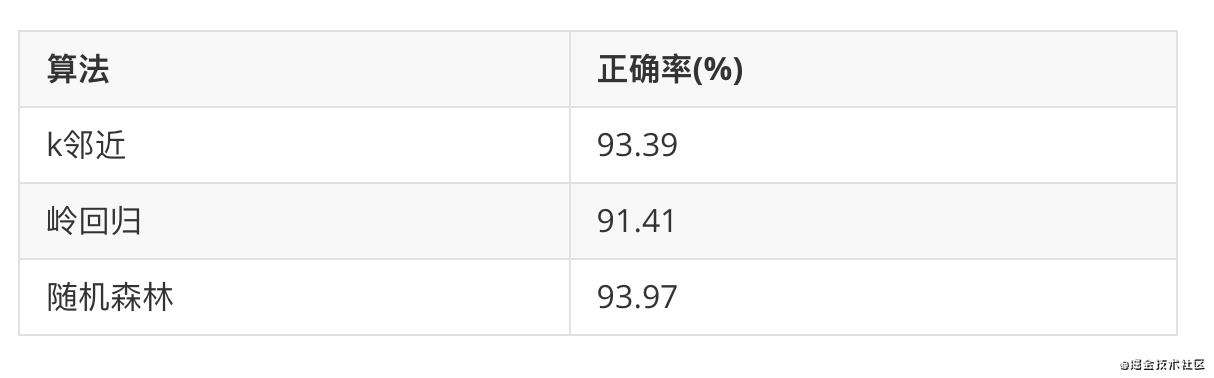
三个算法的准确率都很高,差不太多。故而具体的选择需要实际情况了。
开放世界测试
开放世界测试故名思义,是模拟现实生活中的情况,即有一些流量不在训练集中。这里我的测试方案为使用data40,但是把训练集中的后20个app数据删除,而测试集中依旧保留后20个app的数据。
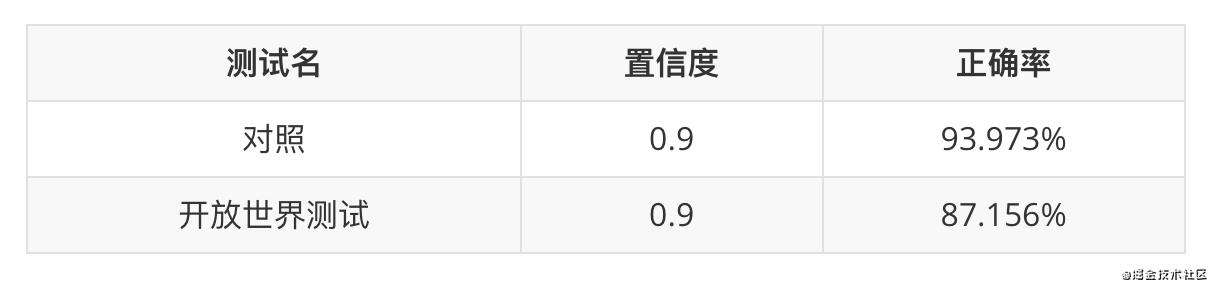
在开放世界测试中,正确率有所下降,但是也没有到不可用的程度,所以大可以放心使用。
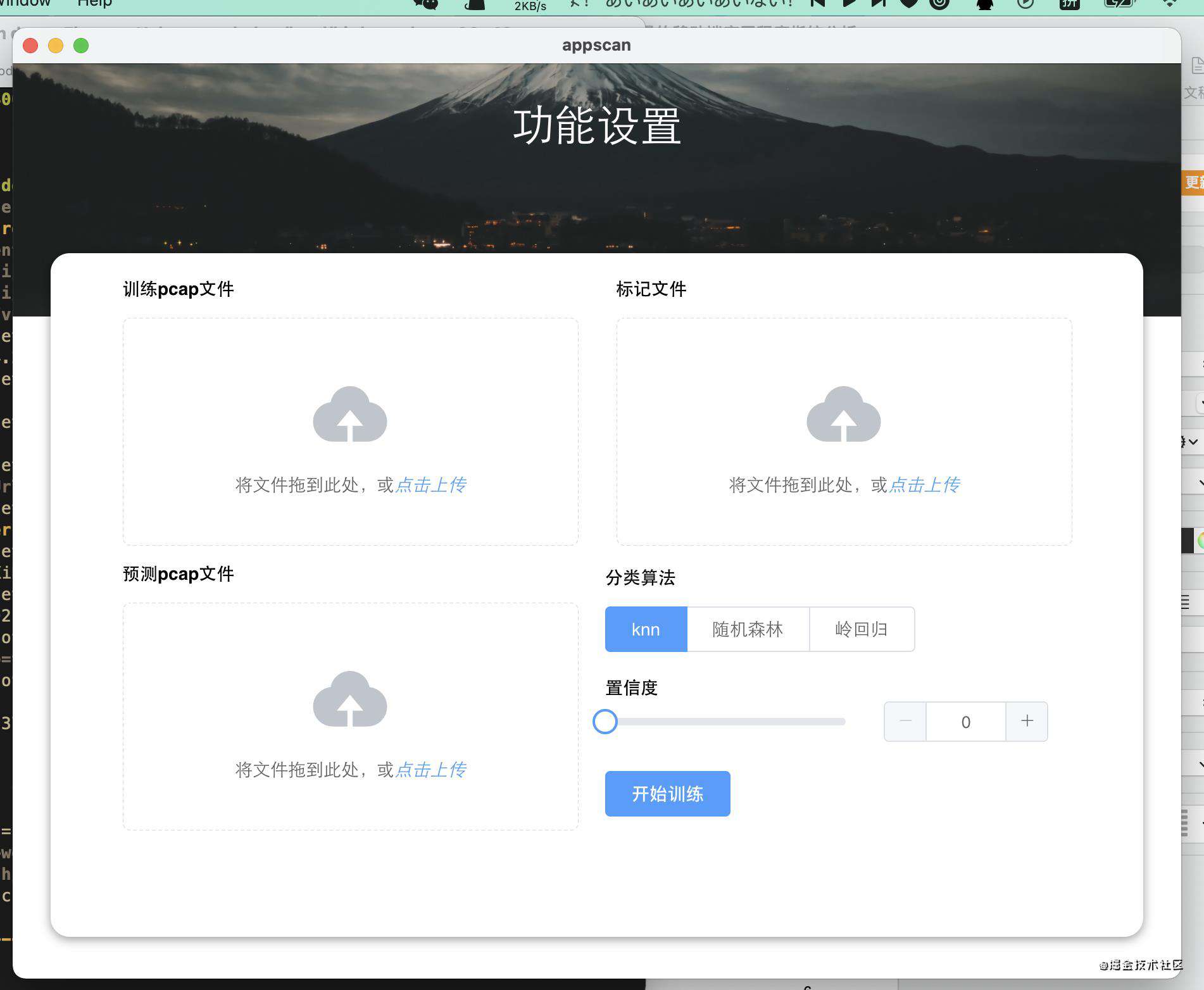
一个简单electron应用
只要有js环境,appscanjs可以运用到很多地方,完全可以花几个小时切一个electron应用出来。
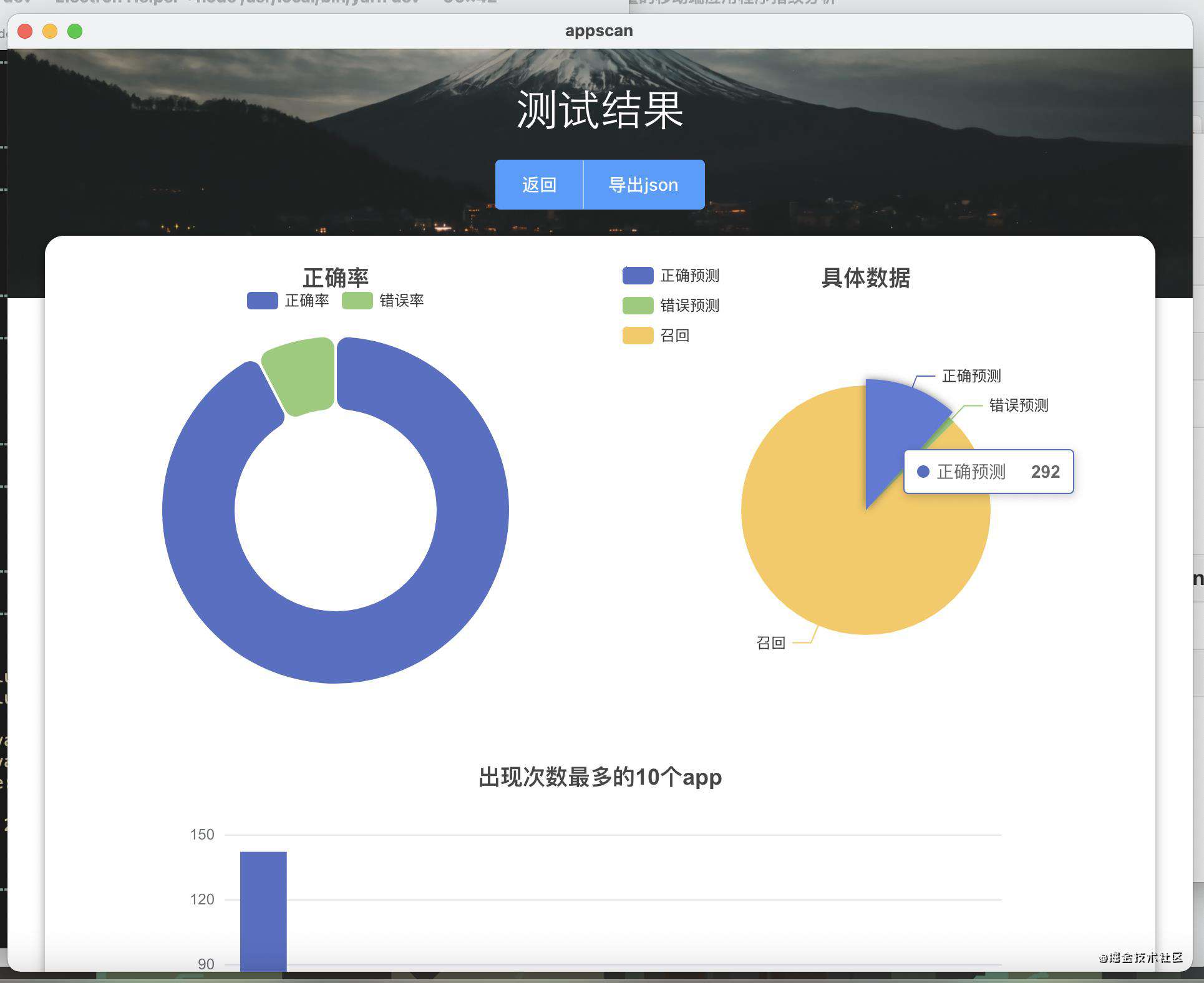
总结
其实nodejs和python混写挺刺激的,比如js的Object.keys()可以获取到python数据结构的key,用for in遍历python的list时会把list的__hash__等属性给遍历出来;要获取数组长度必须用专门导入的len()来,而不能用传统js在原型链上的length属性。作为一个js程序员写python是一件非常轻松的事,需要机器学习的时候直接写python就完事了,混写刺激是刺激但是心理压力也挺大的...但至少boa是另一种选择,想必也没有人不会对为什么js能够获取到python数据结构的属性感到好奇吧。如果这篇文章能超过一个赞,我就去用贫瘠的知识认真看看boa是怎么做到js能调用python的。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!