- 冒泡排序
冒泡排序思想:每次比较相邻两个元素,m,n 其中m < n 当arr[n]< arr[m] 则交换两个元素位置,没执行一次完成的冒泡循环,就会将这次循环中的最大值防止数组末尾
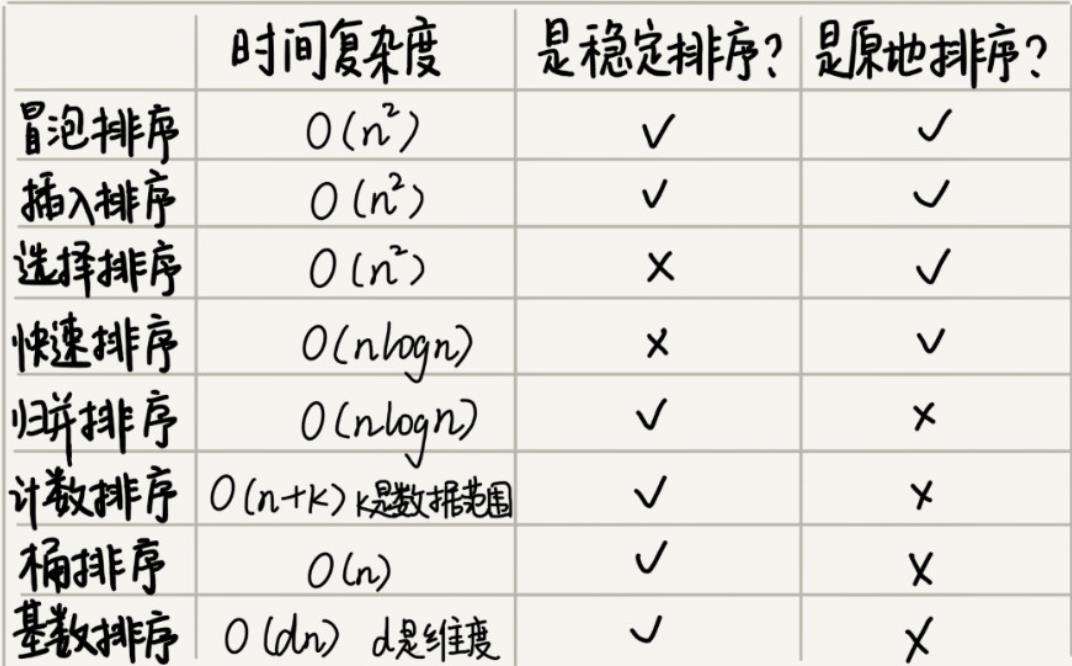
时间复杂度: 最好情况:O(n);最坏情况 O(n^2)
function bubbleSort(array){
if(array.length <=1) return array;
const len = array.length;
for(let i=0;i<len;i++){
let flag = false; // 当一轮循环下来,flag仍然为false,说明数组已经排序完毕了
for(let j = 0;j<n-i-1;++j){ // j<n-i-1 减去i原因为,每一次执行冒泡排序,都会将一个最大值移动到数组末尾,不需要对这部分进行排序
if (array[j] > array[j+1]) { // 交换
const tmp = array[j];
array[j] = array[j+1];
array[j+1] = tmp;
flag = true; // 表示有数据交换
}
}
if(!flag) break;
}
return array;
}
- 插入排序
插入排序思想:
将数组分为两个区间:已排序区间、未排序区间,将未排序区间的第一个元素插入到已排序区间的正确位置
时间复杂度: 最好情况:O(n);最坏情况 O(n^2) 平均 O(n^2)
function insertionSort(array) {
if (n <= 1) return;
const n = array.length;
// i为未排序部分起点 起始为1位置元素
for (let i = 1; i < n; ++i) {
const value = array[i];// 先存储这个元素 -- 未排序初始元素
// 查找插入的位置
let j = i-1; // 已排序末尾元素
for(; j >= 0; --j) { // 从已排序部分末尾往前遍历
if (array[j] > value) {
array[j+1] = array[j]; // 数据移动 相当于把需要移动的元素整体后移一位
} else {
break;
}
}
array[j+1] = value; // 插入数据
}
return array
}
3.选择排序
选择排序思想: 选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
时间复杂度: 最好情况:O(n);最坏情况 O(n^2) 平均 O(n^2)
function bubbleSort(array){
if(array.length <=1) return array;
for(let i=0;i<array.length;i++){
let flag = false;
for(let j = 0;j<array.length-i-1;++j){
if (array[j] > array[j+1]) { // 交换
const tmp = array[j];
array[j] = array[j+1];
array[j+1] = tmp;
flag = true; // 表示有数据交换
}
}
if(!flag) break;
}
return array;
}
4.归并排序
分治思想:如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
时间复杂度:最好情况、最坏情况,平均情况,时间复杂度都是 O(nlogn)。
function merge(array,p,q,r){
let i=p;
let j = q+1;
let k = 0;
let temp = new Array(r-p+1);// 申请与array p --- r 一样长度的数组
while(i<=q && j<=r){
if(array[i]<=array[j]){
temp[k++] = array[i++];
} else {
temp[k++] = array[j++];
}
}
// 判断哪个子数组中有剩余的数据 先假设左边有剩余
let start = i,end = q;
if(j<=r){
start = j;
end = r;
};
while (start <= end){
temp[k++] = array[start++];
}
// 将 tmp 中的数组拷贝回 A[p...r]
for(let m= 0;m<temp.length;m++){
array[p+m] = temp[m];
}
};
function mergeSort_c(array,p,r){
if(p>=r) return;
let q = Math.floor((p+r)/2);
mergeSort_c(array,p,q);
mergeSort_c(array,q+1,r);
merge(array,p,q,r);
}
function mergeSort(array){
let len = array.length
return mergeSort_c(array,0,len - 1)
}
5.快速排序 快速排序思想:快排的思想是这样的:如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。
/*
* 普通的交换,将a[i]和a[j]的数值交换;
*/
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
function partition(arr, left, right) {
/*
* 这部分是具体实现排序的部分;
* 将right值赋值给pivot,作为参照物,因为right在最右边边,只需要从左到右比较一遍即可判断整个数组;
* i索引是arr中待交换位置;
*/
var pivot = arr[right];
var i = left;
for (let j = left; j < right; j++) {
// 循环中如果有任何小于参照物的,就将他交换到i的位置,然后i向右移动到下一个位置;
if (arr[j] < pivot) {
swap(arr, i, j);
i++;
}
}
swap(arr, i, right );
// 返回index作为拆分子数组的分界线;
return i
}
function quickSort_c(arr, left, right) {
/*
* len为数组的长度;
* left为需要数组中参与排序的起始点;right为数组中参与排序的终止点;
* left如果有传数字那么就为left,没有传参则为0;
* right如果有传参那么就为right,没有传参则为len-1;
* 有传参可能会部分排序可能不会排序,没传参默认排序整个数组;
* divideIndex为分组界限;
*/
var len = arr.length,
divideIndex,
left = typeof left !== 'number' ? 0 : left,
right = typeof right !== 'number' ? len - 1 : right;
// 如果需要排序的起始索引小于终止索引则执行排序;
// 递归的终止条件;
if (left < right) {
// partition的返回值作为divideIndex来分隔数组;
// 索引divideIndex左边的元素均小于arr[divideIndex];
// 索引右边的元素均大于arr[divideIndex];
divideIndex = partition(arr, left, right);
// 数组中小于arr[divideIndex]的部分(索引left到divideIndex-1)再次使用quickSort排序;
quickSort(arr, left, divideIndex - 1);
// 数组中大于arr[divideIndex]的部分(索引divideIndex+1到right)再次使用quickSort排序;
quickSort(arr, divideIndex + 1, right);
}
// 递归执行直到不满足left<right;返回本身;
return ;
}
function quickSort(arr){
return quickSort_c(arr,0,arr.length-1)
}
6.桶排序(Bucket sort)
排序思想:核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。
桶排序对要排序数据的要求是非常苛刻的。
-
首先,要排序的数据需要很容易就能划分成 m 个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。
-
其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为 O(nlogn) 的排序算法了
7.计数排序 排序思想:计数排序其实是桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。(利用另外一个数组来计数的)
- step1:找到最大值,分成max个桶
- step2:将每个数字的出现频次放到对应
- step3:从左往右,对频次进行累加,(相当于数组C[i]存储的数据意义为,小于i的个数有多少个)
- step4:申请一个长度等于原始数组的新数组temp,对原始数据进行从尾到头进行遍历,假如该元素为a则 根据C数据得知,小于a的元素有C[a]个,那么这个元素a放到temp[C[a]处,同事因为已经放入了一个元素,我们将C[a]减去1
- step5:将temp元素copy给原始数组
// 计数排序,array 是数组,n 是数组大小。假设数组中存储的都是非负整数。
function countingSort(array) {
let n = array.length;
if (n <= 1) return;
// 查找数组中数据的范围
int max = array[0];
for (let i = 1; i < n; ++i) {
if (max < array[i]) {
max = array[i];
}
}
const c = new Array(max+1); // 申请一个计数数组 c,下标大小 [0,max]
for (let i = 0; i <= max; ++i) {
c[i] = 0;
}
// 计算每个元素的个数,放入 c 中
for (let i = 0; i < n; ++i) {
c[array[i]]++;
}
// 依次累加
for (let i = 1; i <= max; ++i) {
c[i] = c[i-1] + c[i];
}
// 临时数组 temp,存储排序之后的结果
const temp = new Array(n);
// 计算排序的关键步骤,有点难理解
for (int i = n - 1; i >= 0; --i) {
let index = c[array[i]]-1;
temp[index] = array[i];
temp[array[i]]--;
}
// 将结果拷贝给 a 数组
for (int i = 0; i < n; ++i) {
array[i] = temp[i];
}
}
8.基数排序 场景:假设我们有 10 万个手机号码,希望将这 10 万个手机号码从小到大排序,你有什么比较快速的排序方法呢?
假设要比较两个手机号码 a,b 的大小,如果在前面几位中,a 手机号码已经比 b 手机号码大了,那后面的几位就不用看了。
借助稳定排序算法,这里有一个巧妙的实现思路。先按照最后一位来排序手机号码,然后,再按照倒数第二位重新排序,以此类推,最后按照第一位重新排序。经过 11 次排序之后,手机号码就都有序了。
可以理解为:11位数手机,我们理解为11个条件的排序,只要进行稳定排序,就不会破坏原始的排列顺序。
这里先理解一个例子: 我们现在要给电商交易系统中的“订单”排序。订单有两个属性,一个是下单时间,另一个是订单金额。如果我们现在有 10 万条订单数据,我们希望按照金额从小到大对订单数据排序。对于金额相同的订单,我们希望按照下单时间从早到晚有序。对于这样一个排序需求,我们怎么来做呢?
最先想到的方法是:我们先按照金额对订单数据进行排序,然后,再遍历排序之后的订单数据,对于每个金额相同的小区间再按照下单时间排序。这种排序思路理解起来不难,但是实现起来会很复杂。
借助稳定排序算法,这个问题可以非常简洁地解决。解决思路是这样的:我们先按照下单时间给订单排序,注意是按照下单时间,不是金额。排序完成之后,我们用稳定排序算法,按照订单金额重新排序。两遍排序之后,我们得到的订单数据就是按照金额从小到大排序,金额相同的订单按照下单时间从早到晚排序的。为什么呢?
稳定排序算法可以保持金额相同的两个对象,在排序之后的前后顺序不变。第一次排序之后,所有的订单按照下单时间从早到晚有序了。在第二次排序中,我们用的是稳定的排序算法,所以经过第二次排序之后,相同金额的订单仍然保持下单时间从早到晚有序。
so:对于手机号排序,从尾到头,没个位次数字进行稳定排序
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!