
Google的新框架 Lit ,有 Google 加持的框架引起了我的兴趣,就去简单的了解了一下,简单的给大家分享一下学习成果。由于Lit框架还在快递迭代中,文中讲到的一些代码实现很可能已经重构,感兴趣的同学,可以去翻一下Lit源码。
什么是 Lit
Lit 是一个基于 Web-Component 构建的前端框架,前身基本可以理解为即 Polymer , Lit 提供了如下具有竞争力的特性
-
基于
Web-Component的更高层封装,提供了现代前端开发习惯的响应式数据,声明式的模版,减少了web component的一部分样板代码. -
小。运行时仅有5K
-
性能强悍。规避了
VDOM的一些弊端,更新时仅处理 UI 中的异步部分(可以理解成仅处理响应式的部分) -
兼容性较好。因为
web-component是 HTML 的原生能力,也就代表着web-component可以在任何使用 HTML 的地方使用,框架无关。
小和框架无关是促使我关注这个框架的一个重点(svelte也是,有时间再说,学不动了),因为对于一些通用业务代码来说, 运行时尽可能的小 和 框架无关 是最核心的两个技术选型指标。
什么是 Web-Component

我个人认为,组件化是现在前端快速发展和规模壮大的一个比较重要的原因,想想写 JQ 的年代,HTML 代码基本都长这个样子
哪怕后面出现了模版语法,状况也没有变得更好(与服务端协作共用模版 -> JSP or 要在JS中封装方法,通过模版语法注入 -> handlebars),单纯的loop循环渲染可能能方便的解决DOM复用的问题,但是跨层级的组件复用仍然是一个问题。
因此任何一个想要进一步发展的前端框架技术,组件化是必不可少的一步。 Web-Component 就是这样一个浏览器原生支持的创建可重用元素(自定义组件)的能力,而 Lit 则是基于 Web-Component 构建的。
那我们需要先了解下 Web-Component
Web-Component 的简单开发流
我们先了解 Web-Component 的两个核心点,了解了这两个属性就可以构建你自己的组件了
Custom Element 自定义元素
首先,我们需要通过浏览器提供的 **CustomElementRegistry** ****接口实例注册自定义元素,实例被挂载在 window.customElements 上
CustomElementRegistry的 define 方法可以用来注册一个自定义的元素,有两种类型可选
-
自定义元素 :独立元素,行为完全由开发者定义。
-
自定义内置元素 :这些元素继承并扩展内置HTML元素
API如下

name 就是你自定义的元素名称(符合 DOMString 标准,必须带短横线),以上述为例,可以通过 <my-component></my-component> 的形式使用
constructor 就是我们定义的组件
options 声明了我们定义的是哪种类型的自定义元素,目前只有一个extends可用,指定继承于什么元素。
当定义了继承什么元素之后,使用方式就与自定义元素不太一致了,需要用到 is 属性假设你定义了一个名为my-paragraph的继承自p标签的自定义内置元素,那么使用时,需要 <p is="my-paragraph"></p> 这样写
这么看来, Web-Component 的逻辑核心就在constructor上了,我们如何定义一个自己的 component 呢?
不同于 React 和 Vue,可以在 render 方法中书写 JSX 或者模版语法来创建一颗 VDOM 树来定义组件结构。 Web-Component 并没有提供可以用来书写模版的方式(但这也代表着他可以使用任何模版语法)。通常是使用常规的 DOM 操作来在 constructor 中创建你的组件结构。举个栗子:
上面这段代码创建了一个根据双层span嵌套的文本节点
当然,单纯的创建UI没有什么意思,我们来思考下,现代框架还提供了什么能力?
响应式!事件绑定!lifecycle!
OK,安排。
先说比较简单的事件绑定,既然 DOM 都是内部创建的,那么绑定事件也是轻而易举(注意this指向)
上述代码创建在之前的文本基础上,多了一个按钮,点一下这个按钮就会把整个 custom element 移除掉(当然,这个按钮也可以由组件自己创建)
然后我们再来说 lifecycle ,customeElemnts.define接受的构造函数中,允许开发者定义如下几个生命周期,会在相关的时机被调用
-
connectedCallback:当 custom element 首次被插入文档DOM时,被调用。 -
disconnectedCallback:当 custom element 从文档DOM中删除时,被调用。 -
adoptedCallback:当 custom element 被移动到新的文档时,被调用。 -
attributeChangedCallback:当 custom element 增加、删除、修改自身属性时,被调用
简单来说,就是
-
componentDidMount
-
componentWillUnmount
-
Not exist(这个我还没测试出什么场景会用出现)
-
componentDidUpdate
因为没有 state 这个概念,所有的组件内部属性的变化监听都需要我们手动处理,心智负担可能会略重一些。
当然也可以把他们作为自定义元素的属性,通过 ~~attributeChangedCallback~~ 处理
顺路,有了属性变化的回调响应式也就出来了(当然,只是响应式的基础,属性变化并不会直接作用到内部渲染逻辑上,心智负担 +1 )
如果需要在元素属性变化后,触发回调函数,必须通过定义 observedAttributes() get函数来监听这个属性
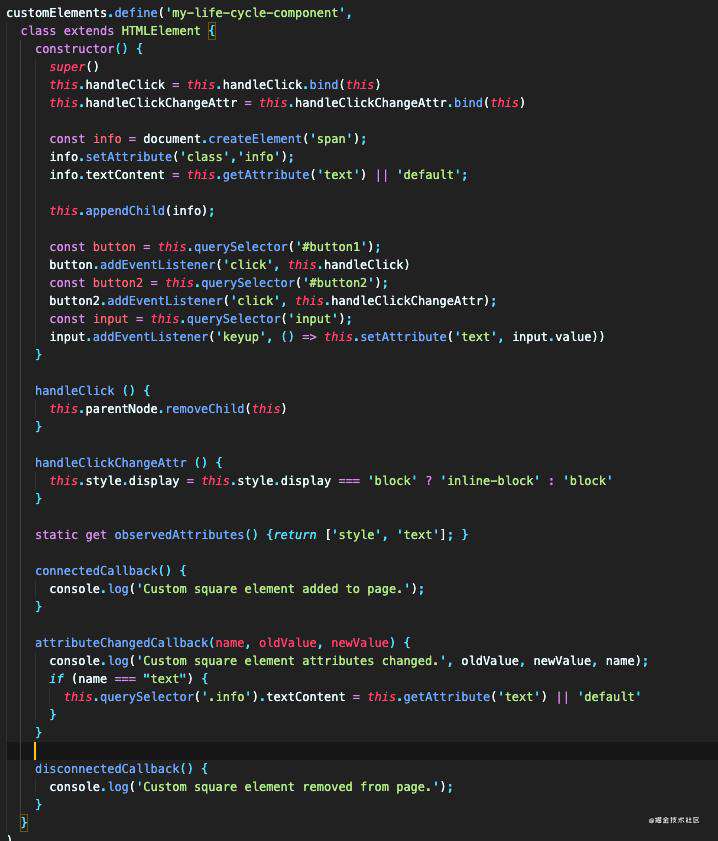
看下代码,这里定义了一个带输入框的组件,输入框输入后,会重新渲染 componnet 内部的文本。同时监听 style 属性,变化后打印出来(无意义的demo +1)
Shadow DOM 影子DOM
Shadow DOM 的好处有很多。
Shadow DOM 主要的作用在于,“他可以将独立的一个DOM(style标签也属于)附加到元素上(这个DOM是隐藏的),且不会影响外层的样式,这给web component带来了十分强大的封装能力,能够完全的将组件的结构,样式和行为动作对外隐藏起来,对外隔离”]
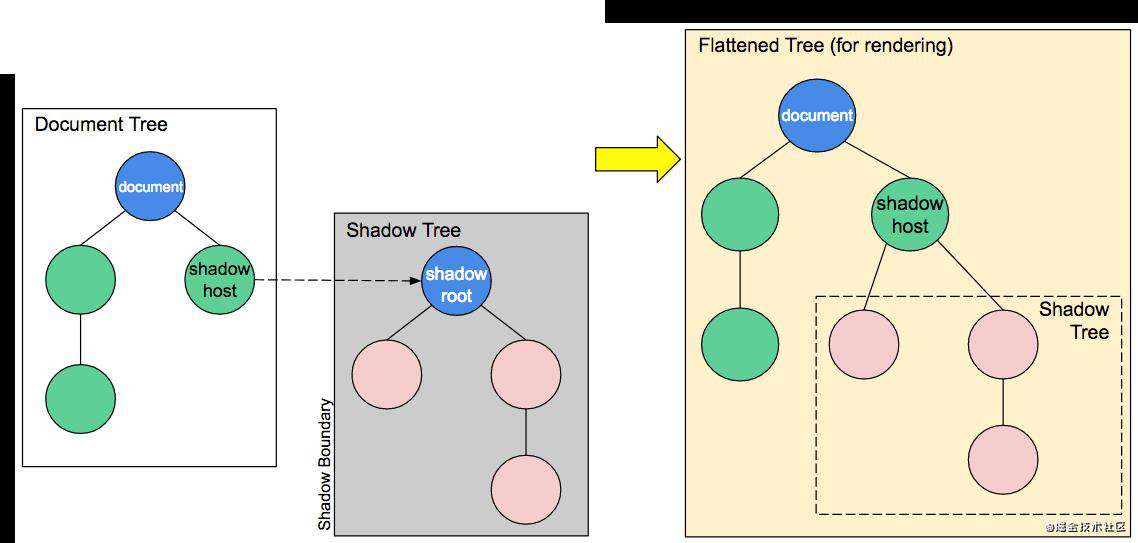
有一个需要关注的概念 - Shadow boundary
Shadow boundary 指的是 Shadow DOM 结束的地方,也是常规 DOM 开始的地方。整个 shadow dom 内的样式、元素都不会对外影响超过 shadow boundary 的范围。
那么,如何使用呢? 有一个核心API, Element.attachShadow({mode: }) ,可以将一个 shadow root 附加到任何一个元素上,mode 的取值有 open 或者 closed。区别在于能否从外部获取到 shadowDOM 的结构。想要更深入的了解 open 和 close 的区别可以参考 blog.revillweb.com/open-vs-clo… 这篇文章,这里就不展开描述了。
那么,拿上边最简单的那个例子做一下改造
这样就创建了一个基于 shadowDOM 的自定义元素了,看起来没什么差别,我们再添加一些自定义的样式试试
可以尝试在页面的其他地方也添加一些span标签,但是你会发现,只有 下面的 span 标签生效了红色的样式。
上述两个属性可以创建一个不受外部影响,且拥有内部JS运行逻辑、拥有独立CSS的自定义元素(也就是Web Component) 我觉得大家已经开始在吐槽,这种类JQ的写法简直是异类,DOM复杂起来之后就很难整了。那么如何组装更复杂的dom,难道无解了么?不,那么这里需要提到另外一个属性
Template & Slot
template 元素是浏览器一直以来都支持的一个特性,template 中的内容在渲染 HTML 到屏幕上的时候不会显示出来,需要通过 Javascript 获取到模版后才能实例化,并渲染到页面上。
那么,我们可以把 template 作为一个可以储存在文档中的内容片段,然后在组件渲染的时候把 template 填充到 Web-Component 的 shadow dom 里面。还是拿上边的那个例子做修改
这样以来,是不是有点 Vue 那个意思了,但是还缺点什么,my-component 上之前可以读取 text 属性填充到 span.info 里面,现在好像没有这个能力了。
这个时候需要请出我们的 slot 槽来做这件事
Slot 通过 name 属性标示,放置的位置表示他在模版中的位置,当有另外一个元素定义了同名的 slot 属性,那么这个元素就会被替换到模版中。我们修改下上边的那个例子
当然这里只是最为简单的用法,但至此,基本上 Web-Component 你就算入门了。整体写起来难度也不算太高,但还是有不少值得吐槽的地方 (更多关于Web Component) 。那么我们来看看 Lit 做了啥,能不能让 Web-Component 变得更好用些
Lit做了啥
看下我们刚才说到的 Web-Component 里面的几个槽点
-
响应式仅有回调,无法自动映射到UI上
-
没有 state 内部状态,自己维护的状态无法直接监听变化
-
没有模版语法(可以用 slot 和 template)
明确一点,在学习 Lit 的过程中,可以认为没有 state 这个概念(实际上有,理解为私有的 reactive properties),只有名为 reactive properties 的成员属性。可以简单的理解成又是 state,又是 props。
那么现在问题转变成了
-
如何响应reactive properties的变化,并应用到UI上
-
如何解决模版语法
Lit 用了两个个核心库来解决这个问题,分别是 lit-element 和 lit-html
Lit-html
lit-html 是 Lit 的核心逻辑,可以理解为 Literal Html ,他异于JSX创造了另外一种高性能的字符流HTML模版引擎。
Lit选择了直接继承Polymer的LitHTML项目,并将整体框架重命名为 Lit
我们知道 jsx 是需要编译的它的底层最终还是 createElement ....。而 lit-html 就不一样了,它是基于 tagged template 的,使得它不用编译就可以在浏览器上运行,并且和 HTML Template 结合想怎么玩怎么玩,扩展能力更强。下面我们展开来看。
lit-html 提供了两个核心方法 render 和 html
lit-html.html
这个是es6的原生语法 - 带标签的模板字符串 (tagged template),并不是什么magic,html 这个函数会接受到如下的参数
经过 lit-html 的修饰上面这段代码最终会构造一个 Template Result 对象,形如
这里需要注意一下 getHTML 和 getTemplateElement 方法,这两个方法可以将strings转化成为一个 <template> 标记,也就是上面提到的 template
简单的解释一下,这个过程就是逐个处理strings中的数据,根据不同的情况
-
Attribute
-
Node
-
Comment
拼接成一个完整的字符串,然后innerHTML插入到创建好的template标记中。 Q:如何区分代码中真正的comment?
lit-html.render
现在我们有了通过标签模版得到的 TemplateResult (一个纯值对象),接下来需要调用 render 方法去渲染模版到页面上,先看API
render(templateResult, container, options?)
render 接收一个 templateResult实例 和 container 渲染容器来完成一次渲染,这里分为首次渲染和更新渲染。
首次渲染
先创建一个 NodePart 对象(继承自Part,可以理解为节点的构造器controller,这个是核心实现,暂时不展开,后面来看),然后调用 NodePart 实例的 appendInto 方法,在渲染容器中加入两个 comment ,同时记录了两个 comment 的引用。后续 NodePart 会把 DOM 渲染到这两个 comment 中间
然后会调用 part.commit 方法,将内容渲染到容器中
commit分为了几种情况
-
directive
-
primitive(原始类型)
-
templateResult
-
node
-
Iterable
-
清空
根据前面的逻辑,第一次一定会直接走进 templateResult 的分支,这里的逻辑可以简单这么描述,
通过 Factory ,使用 TemplateResult 中的模版部分 strings 创建一个 Template 对象(中间产物), Factory 这里做了一层缓存,如果使用 TemplateResult 的模版(strings)有现成的模版的话,直接使用现成的模版,如果没有,则重新创建。
在后续调用 render方法时,相同的模版(strings 值与第一次调用时是完全一致)是重用第一次的Template的,可以理解为编译时期就确定的一个常量值,而变化的只有 value 数组
-
先用TemplateResult的模版(string)找有没有现成的模版,如果有,直接复用
-
如果没有,则检查keyString的模版中有没有 模版.join markerKey的引用(markKey means lit-7227407027270176)
-
如果还是没有,则创建一个Template实例,并且将Template 使用模版 和 keyString缓存起来
缓存流程不展开讲解,如果有兴趣自己看一下
Template 对象中分为 parts 和 element,element就是TemplateResult转化出来的 <template> ,parts部分,是在遍历<template>(dom walker)的时候生成的。处理流程简化理解
-
如果是Node节点
- 判断是否有attribute,且属性名有特殊标记,有的话,移除template上的属性,并往part push一个
{type: 'attribute', index, name, strings: statics}的结构,index是当前的walker下标,name是属性名,strings是这个属性的插值前后字符
- 判断是否有attribute,且属性名有特殊标记,有的话,移除template上的属性,并往part push一个
-
如果是Comment节点
-
如果comment的内容等同于marker -(这里可以和真正的comment区分开),然后往part中推入一个node节点
{type: 'node', index}- 如果是第一个节点或者前面一个节点已经是一个part的标记了,会先在当前节点前添加一个空的comment节点,
-
处理完成后
可以理解 Template 是一个已经成型的 DOM 模版,他拥有完整的 DOM 和需要插值的位置定位,但他还没渲染到 DOM 上
接下来检查当前的 Template 是否已经创建了 TemplateInstance 实例,如果没有,实例化一个 TemplateInstance
TemplateInstance 会通过<template>创建 fragment ; 然后遍历 parts ,根据 TemplatePart 字面量的类型,分别创建 NodePart 和 AttributePart 实例。
最终调用 TemplateInstance 实例的 update 方法,这个方法会逐个调用 Part 实例的 setValue (真实的值)和 commit (渲染方法)方法,至此,循环回了render的最开始的方法调用,剩下的就是递归调用,直到找到原始的值类型的那一层,渲染到Fragment上。
-
__commitText:直接修改文本节点的文本 -
__commitNode:清空父亲节点中的startNode到endNode(最开始提到的那两个comment占位),然后把node添加进去。
当递归回到最顶层后, commitNode 拿到的就是完整的 fragment ,塞到容器中就可以了。
核心流程
至此,第一次的渲染完成,大致流程如下
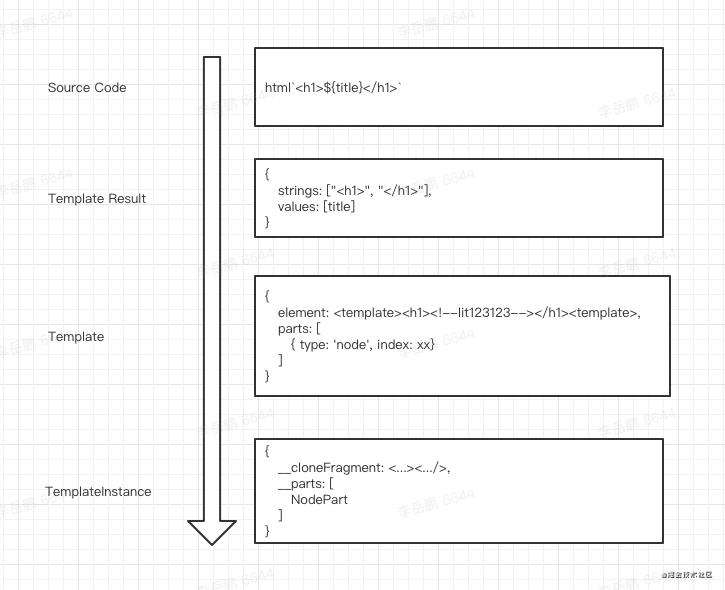
可能听起来有些绕,我们可以暂时忽略 Template ,它是一个中间状态
TemplateResult 是类似 JSX 的一种更轻量的对于模版的字面量描述,是一个模型
TemplateInstance 可以理解成一个小的 MVC 框架的嵌套
-
DOM(fragment) 是应用的外层框架,是不变的 View 部分
-
TemplateResult中的成员value是 Model -
Controller(Part)中连接了 View 和 Model。提供了更新数据的方法(setValue)和渲染到视图的方法(Commit)
更新渲染
可以类比SQL执行过程中的库缓存,如果SQL结构一致就复用已有的模型 逐层比较检查所有的缓存是否命中(对比类型 和 模版 - strings结构)
-
如果命中的话就使用已有模版,找到
TemplateInstance的Part,把templateResult的value更新给Part -
如果没有命中的话,就走第一次渲染的流程
效率
-
带标签的模版字符串执行相比JSX会更加高效。JSX的每次 render 都需要完整的构造一个虚拟DOM,而lit-html,则只是重新构建一个十分轻量的 TemplateResult 对象,变化的只有 value 集合。 -
从 TemplateResult 到 < template> 的过程,是直接从 TemplateResult 构造 html ,然后使用 template.innerHTML 完成解析的。这个过程完全使用浏览器自己的语法解析器来完成的。由于使用了 template 技术,这个DOM是一个Fragement,并不是真实DOM的一部分,内存占用小
-
实际渲染的DOM生成,是从 template.importNode 来完成DOM的复制。而不是像React一样逐个Dom节点的创建。对于较大的DOM,效率十分可观
-
在增量更新的过程中,Lit 和 React 相类似,都是按照相同层次的节点重用的方式,React通过
diff(VDOM, DOM)来实现增量更新,而LitHtml并没有使用diff算法,而是基于相同模板的渲染,只需要对动态部分进行更新即可。没有diff算法会更加的轻
Lit-element
OK,模版语法有了,剩下的就是如何把状态变化响应式的应用到模版里了。
如何使用
这部分实际上不复杂,有过Vue开发经历的同学一定都清楚Vue是如何将数据和视图绑定起来。 Lit-element 也是如此
在Lit中,你需要这样声明一个组件
customElement 实际上是 customElement.defined 的语法糖,而 LitElement 是 Lit 提供的一个基类,其中就处理了数据的响应式处理(实际上 LitElement 还继承了 UpdateElement ,由 UpdateElement 做响应式的处理)。
Reactivity Property
我们先看看,Lit的文档中要求怎么定义 reactivity property
我们会会发现,如果需要响应式属性的话,需要使用 property 这个装饰器来装饰属性,property 这个装饰器的逻辑为,调用所在类的静态方法 createProperty 往类的静态成员 _classProperties 中注册这个属性,同时,给这个属性添加 getter 和 setter,到这里,类准备工作就做好了。
-
getter:直接取
-
setter:更新后触发更新
每次在组件内部修改 reactive property 的时候,属性更新完成后会重新调用 lit-html 的 render 方法渲染到UI上。
这个和 state 的概念十分的相似,那么 lit-element 又是如何处理外部传输属性(props)的变化呢?
这里我们需要应用到前面提到的 Web-Component 的生命周期get observedAttributes 和 attributeChangedCallback 。每次当传递给 component 的属性发生变化的时候,这两个周期就会触发,只需要查询是否在 _classProperties 中,并主动更新 reactive property 即可。
除此之外,property 装饰器还可以接受一个 options 配置一些属性来进行适配
-
attribute - 定义这个成员变量是否和元素属性绑定
-
converter - 定义转化逻辑,从元素属性(都是string)到真实属性
-
hasChanged - 判断属性是否发生变化
-
type - 在没有定义converter时使用,转化元素类型
-
state - 如果定义了state的话,象征这个成员变量是一个内部状态,是私有的,新版的
Lit提供了一个单独的装饰器@state 来替代这个属性
Lit 剩下的诸如装饰器,事件绑定之类的就不再展开细说了,有兴趣的同学可以去阅读下源码,整体上比 React 易读性高的多(Doge)。至此,一个完整的可用的面向未来的前端框架就完成了。
小结
Lit 因为兼容性问题现在还不能应用到实际的业务场景中,但是确实是一个值得关注和学习的框架。其中的一些设计思想和理念,跳出了 React 限制的框架,给出了前端框架的另一种可能的解决方案。在框架领域上一家独大不是什么好事,有更多的奇思妙想和拥抱未来才能让前端的发展更加广阔。
还有个不能实际场景应用的问题,Lit 还在快速的迭代中,每次都是很大的 Breaking changes。比如刚才提到的UpdateElement又被拆成单独的包了。。。。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!