目前用过的数据结构
- 数组
- 数组可以分为队列、栈等
- 哈希表
- 用来存储 key - value 对
队列 Queue
题目
- 请实现一个「餐厅叫号」网页
- 点击「取号」按钮,生成一个号码
- 点击「叫号」按钮,显示「请 X 号就餐]
分析
-
首先,应该选择「队列 queue」作为数据结构
- 因为「叫号」遵循的应该是「先到先得」的原则,这点与「队列」的「先进先出」是一致的
-
队列的两个重要的 API :入队、出队
- 在 JS 中,「入队」相当于 queue.push (在叫号数组的最后,添加一个人)
- 在 JS 中,「出队」相当于 queue.shift (把叫号数组中第一个人踢走,结束排队、可以去吃饭了)
-
记得练习一下 call 的用法
-
其他的事情就顺其自然了,见完整代码
- 本地编译器中,可安装 parcel(
yarn global add parcel),运行parcel +(文件路径,如 src/index.html )来开启本地服务,实时监听
- 本地编译器中,可安装 parcel(
代码
<body>
<div id="screen"></div>
<div class="actions">
<button class="createNumber">取号</button>
<button class="callNumber">叫号</button>
</div>
<div>
当前号码: <span id="newNumber"></span>
</div>
<div>
当前队列: <span id="queue"></span>
</div>
<script src="./main.js"></script>
</body>
// 获取到所有页面元素
const divScreen = document.querySelector("#screen")
const btnCreateNumber = document.querySelector(".createNumber")
const btnCallNumber = document.querySelector(".callNumber")
const spanNewNumber = document.querySelector("#newNumber")
const spanQueue = document.querySelector("#queue")
// 取号
// 取号号码n默认从0开始,每次点击后自增1
// 需要把所有取过的号都记下来,才能实现叫号
let n = 0
let queue = []
btnCreateNumber.onclick = () => {
n += 1
queue.push(n) // 入队
spanNewNumber.innerText = n
spanQueue.innerText = JSON.stringify(queue)
/* innerText 只能显示字符串,
* 可以用 queue.toString() 显示效果:1,2,3,4
* 用 JSON.stringify(..) 会把JS对象转换成外观完全一样的字符串, [1,2,3,4]
* */
}
// 叫号
btnCallNumber.onclick = () => {
if (queue.length === 0) { // 当队列为空,就不再执行叫号操作
return spanQueue.innerText = `无需排队`
}
const m = queue.shift() // 出队
divScreen.innerText = `请 ${m} 号就餐`
spanQueue.innerText = JSON.stringify(queue)
}

问
-
懂得「队列」,看到这种实现逻辑(先到先得),能立马知道这符合「队列:入队/出队」(先进先出) 科班生只需要了解:「入队、出队」在 JS 中对应的 API 形式即可
-
没有「数据结构」相关知识的辅助,只能一步一步推导这种逻辑的实现方法(相对薄弱)
- 所以「数据结构」很重要
栈 Stack
举例
-
JS 函数的调用栈 call stack 就是一个栈
-
假设 f1 调用了 f2,f2 有调用了 f3
-
那么 f3 结束后应该回到 f2,f2 结束后应该回到 f1
代码
function f1(){ let a = 1; returb a+f2() }
function f2(){ let b = 2; return b+f3() }
function f3(){ let c = 3; return c }
f1()
// 问:上述代码是 如何压栈和弹栈的 ?
首先,栈就是数组
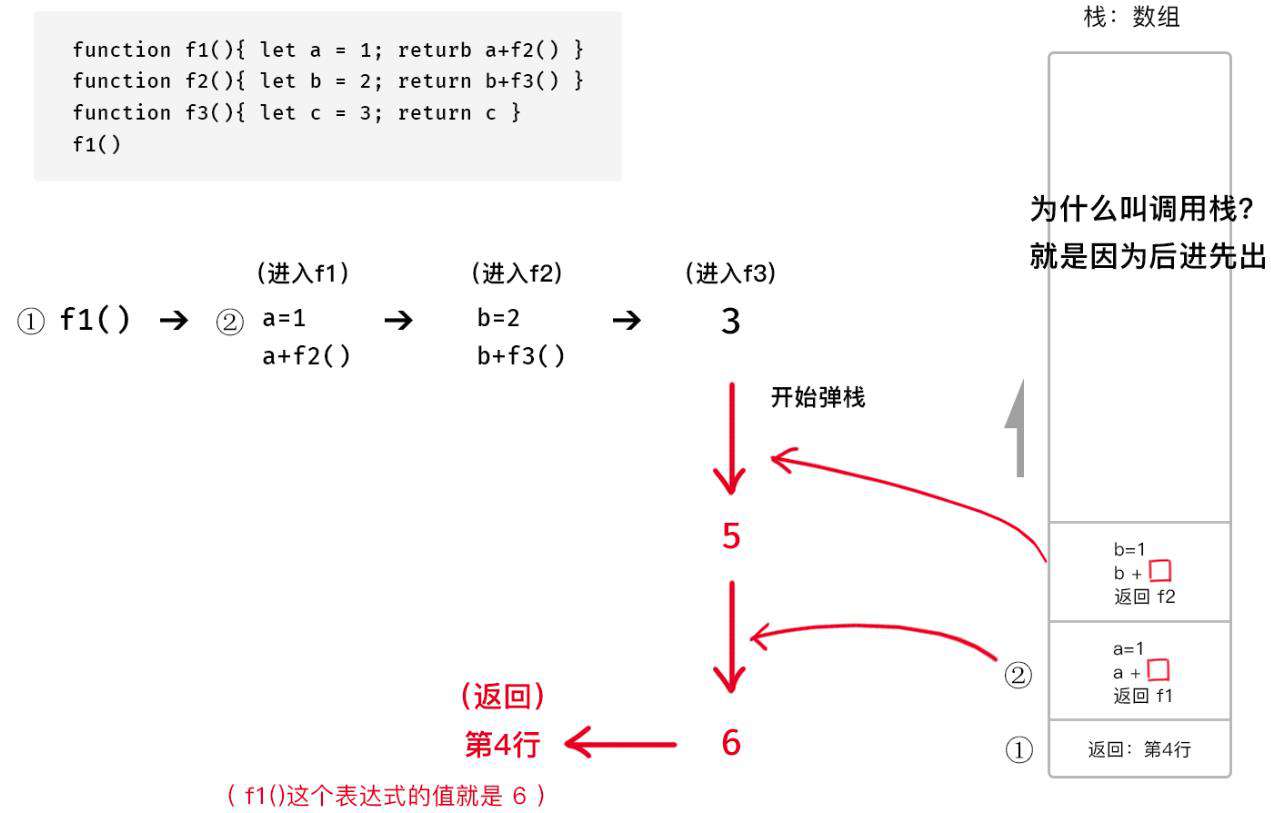
- 压栈就是 push(添加到最后)
- 弹栈就是 pop(把最前面先弹出来)
留一个悬念
内存图里的栈内存和这个调用栈
- 它们是什么关系?—— 关系很大
- 是同一块内存吗?—— (可以说是同一块内存,因为)有很大的地方是重叠的
链表 Linked List

实际使用
let array = [1,2,3]
array.__proto__ === Array.prototype
Array.prototype.__proto__ === Object.prototype
从这个角度看,JS 中任何一个普通对象,都是一个链表(因为有原型的概念)
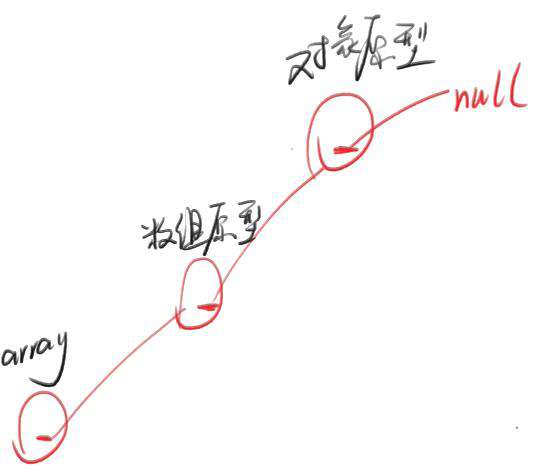
let array = [1,2,3]
array.push // array本身没有push,就去数组原型上找
array.hasOwnProperty // array本身没有,数组原型上没有,只能从对象原型上找到
这是非常简洁的、实现继承的一种机制
链表的好处
例
-
任意一个数组 array,要去掉链条中的数组原型
-
实现方式:让 array 的 _proto_ 直接指向对象原型(那么这个 array 就不再具备 push 这些方法了)
let array = [1,2,3] array.__proto__ // 得到数组原型 array.__proto__.__proto__ // 得到对象原型 array.__proto__.__proto__.__proto__ // null // 让 array 的 __proto__ 直接指向对象原型 array.__proto__ = Object.prototype array.push // undefined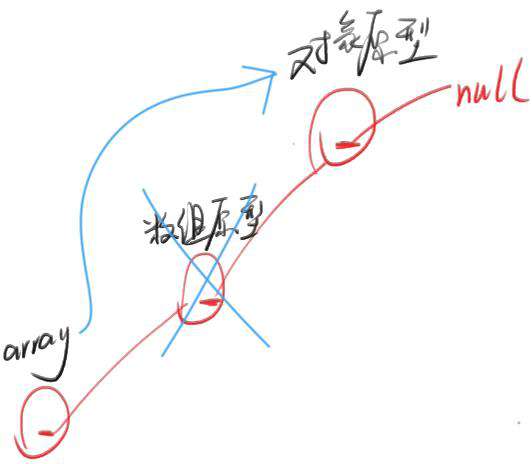
链表的简单操作 ✅
添加节点
第一次尝试:失败 ❌
BUG分析
- 运行下面代码的【appendList 方法】只能实现一种情况:就是在第1个节点后面,添加第2个节点。
- 当你想添加多个节点,多次运行【appendList 方法】会发现链表中始终只有两个节点
- 多次运行的结果,就是第二个节点在不断的被替换,而不会将每次运行时用户写的节点添加到已有节点的后面
/*
* 如何创建一个链表 ↓
* 最简单的链表,就是只有一个节点的链表
* 一个节点,用对象表示。需要包含两个属性:数据、下一个节点(默认是空)
* */
const createList = (value) => {
return {
data: value,
next: null // 默认下一个节点是空
}
}
/* 添加其他节点 */
const appendList = (list, value) => {
const node = {
data: value,
next: null
}
list.next = node
return node // 往list上添加node节点,并把这个node节点作为函数返回值
}
const list = createList(10) // 创建list链条(只有一个节点)
const node = appendList(list, 20) // 往list链条上,添加node节点。
console.log(`node`, node)
console.log(`list`, list)
代码简化
{
data: value, // 形参value
next: null // 默认是单节点链表,下一个节点为空
}
// 提取公共部分,独立成一个函数 createNode
const createNode = (value) => {
return {
data: value,
next: null
}
}
--------------------------------------------------------------------------
const createList = (value) => {
return createNode(value) // <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 多次调用
}
const appendList = (list, value) => {
const node = createNode(value) // <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 多次调用
list.next = node
return node
}
第二次尝试:成功 ✔️
const appendList = (list, value) => {
const node = createNode(value) // 先生成我们要新添加的节点的内容
// 添加节点:我们需要在当前链条的最后一个节点的后面,添加新的节点。
// 所以必须找到 list 的最后一个节点
let x = list
// 重新赋值给变量x,更保险。直接用list原值,可能会导致问题
// 开局假设:链表只有一个节点,声明变量 x,作为链表的这一个节点(也是最后一个节点)
// 循环遍历
// 如果 x 后面还有节点存在,说明 x 不是最后一个节点,需要给 x 重新赋值为下一个节点
while (x.next) {
x = x.next
}
// x.next === null
// 遍历结束,x.next如果是null了,说明 x 是最后一个节点
// 此时只需要,把需要添加的节点,赋值给 x.next 即可
x.next = node
return node // 把需要添加的节点 node 作为函数返回值
}
删除节点
示例分析
-
这个实现的思路和前面的例子类似。
「从链条中删除 20 节点」,实际上就是让 10 节点的 next 不再指向 20,而是直接指向 30
-
删掉 10 和 20 之间的联系后,10 和 20 的 next 仍然分别指向 30。 但是并没有任何对象指向 20 ,20 就相当于没人用的内存垃圾,浏览器会自动把它回收掉
-
所以最终 10 - 20 - 30,就变成了 10 - 30
(图解 ↘)
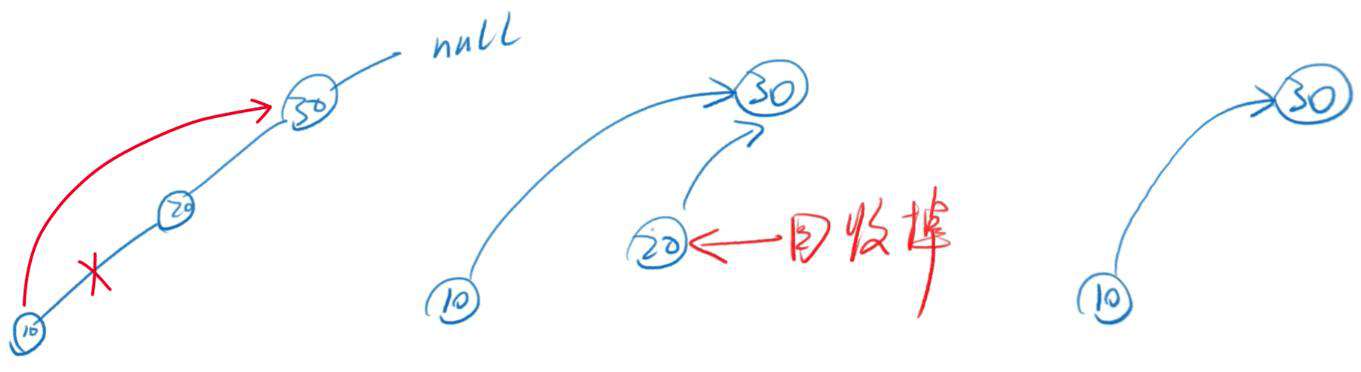
问题:怎么找到 20 节点的上一个节点(我们只能通过 next 找到当前节点的下一个节点,并没有属性保存当前节点的上一个节点??)
思路
- 通过上图可知,**「删除 X 节点」**可以转嫁成另一个需求 ?
- **「让 X 的上一个节点的 next,直接指向 X 的下一个节点」 **
- 跳过了 X 节点,相当于从链条中删除了 X 节点(浏览器还会自动回收)
第一次尝试:找规律 ⚠️
/*
* 删除节点
* 参数1:从哪个链条删除
* 参数2:删除哪个节点
* */
const removeFromList_Demo = (list, node) => { // 注意:链条的名称 === 第一个节点的名称
// 如果要删除的(node传入的)是第1个节点(那node.next就表示第2个节点)
if (node === list) {
list = node.next // 就将第1个节点list重新赋值为第2个节点(相当于第1节点就不存在了)
} else {
// 如果要删除的(node传入的)是第2个节点(那node.next就表示第3个节点)
if (node === list.next) {
list.next = node.next // 就将第1个节点的next,直接指向第3个节点(跳过第2节点,相当于删除)
} else {
// 如果要删除的(node传入的)是第3个节点(那node.next就表示第4个节点)
if (node === list.next.next) {
list.next.next = node.next // 就将第2个节点的next,直接指向第四个节点(跳过第3节点,相当于删除)
} else {
// 如果要删除的是第4个节点 => 让第3个节点.next,直点接指向第5个节(跳过4)
if (node === list.next.next.next) {
(list.next.next).next = node.next
} else {
// 找到规律了吗?
// 这是一个循环(递归)呀
}
}
}
}
}
第二次尝试:有 bug ⭕️
- 删除X节点:就是让【 X 的上一个节点】的 next,直接指向【 X 的下一个节点】(X.next)
- 所以**关键在于: X 的上一个节点怎么找到 **
- 要知道 X 的上一个节点,这就与 X 节点联系紧密
/*
* 删除节点
* 参数1:从哪个链条删除
* 参数2:删除哪个节点
* (链条名===第一个节点)
* */
const removeFromList = (list, node) => {
let x = list // x 默认为第一个节点
let p = null // p 始终表示 x 的上一个节点,默认为空
// 传入的 node 表示是要删除的节点。
// 要遍历链条中的每一个节点,用 x 表示当前遍历的节点
// 将 x 与 node 比对,如果当前节点 x 不等于 node 节点,就给 x 重新赋值下一个节点,再次判断是否相等
// 不断循环查找下一个,最终 x 就会找到要删除的那个节点
// 因为【x的上一个节点】是关键,所以循环每轮都要把【当前x的上一个节点】记录下来
while (node !== x) {
p = x // 每轮先用 p 把当前 x 记下来
x = x.next // 然后再把 x 重新赋值为下一个节点
//(此时x成为x的下一个节点,p就成为x的上一个节点)
}
// while 遍历完,得出当前要删除的节点。如果找不到,说明用户传入的 node 不存在 (╯□╰)
// 综上,遍历完后,x 和 p 的取值各有两种情况 ?
// console.log(x === node || x === null) // x 要么找到传入的要删除的节点;要么就是null
// console.log(p === x的上一个节点 || p === null) // p 要么是 x 的上一个节点;要么就是null(说明要删除的就是第1个节点,所以 p 是 null)
/*
* 最后,删除节点,相当于跳过这个节点。
* x是要删除的节点,那么跳过x这个节点,就应该是x的上一个节点的next ,直接指向 x 的下一个节点 (跳过x)
* x的上一个节点的next ===> p.next
* x的下一个节点 ===> x.next
* */
p.next = x.next // ← ← 综上得出
}
示例如下:
const list = createList(10);
const node = list // node 就是 list 的第一个节点了现在
removeFromList(list, node) // 你会发现 list 没有任何变化
const newList = removeFromList(list, node) // 就算获取返回值也没有用,因为根本就没返回新 list
第三次尝试:成功 ✅
/*
* 删除节点
* 参数1:从哪个链条删除
* 参数2:删除哪个节点
* removeFromList_Demo1: 原始代码,用于发现规律
* removeFromList_Demo2: 最终代码,用于实现规律(循环),未处理边界情况
* removeFromList:非常抽象,且不是最优方案
* 关键思路:就是让【 X 的上一个节点】的 next,直接指向【 X 的下一个节点】,跳过x节点
* */
const removeFromList = (list, node) => {
let x = list
let p = node // p 仍然表示x的上一个节点,Demo2中将 p 初始化为 null,这里改为 node
while (x !== node && x !== null) { // Demo2中忘了对null进行处理,如果node不 list中,x就可能为 null
p = x
x = x.next
//(此时x被重新赋值为【x的下一个节点】,那么p就成为【x的上一个节点】,稍稍有点抽象,注意理解)
}
if (x === null) { // 若 x 为 null,则不需要删除,直接 return, false 表示无法删除不在list里的节点
return false
} else if (x === p) {
// x初值为list,p初值为node。
// 如果node接收传参list,则循环过后x===p,也就是两个参数都是list,说明要删除的节点是第一个节点
p = x.next // p是list,list重新赋值为list.next,那list原值就不存在,相当于删除原本的list第一个节点
return p
// 如果删除的是第一个节点,那么就要把新 list 的头节点 p 返回给外面
// 即 newList = removeFromList(list, list)
} else {
p.next = x.next // 赋值跳过x节点
return list // 如果删除的不是第一个节点,返回原来的 list 即可
}
}
const list = createList(10)
const node = list // node 就是 list 的第一个节点了现在
const newList = removeFromList(list, node) // 必须用 newList 获取返回值才能拿到删除了第一个节点的新 list
遍历节点
/*
* 获取节点
* 参数:要获取第几个节点
* 返回这个节点 node
* 思路:遍历一次记1,遍历两次记2,遍历到第index次把这个节点返回出来
* */
const getNode = (list, index) => {
let x = list
let count = 1
while (x !== null) {
if (count !== index) {
count += 1
x = x.next
} else {
return x
}
}
}
总结
list = create(value) // 创建
node = get(index)
append(node, value) // 添加
remove(node) // 删除
travel(list,fn) // 遍历
链表的变形
双向链表
每个节点有一个 previous ,指向上一个节点
循环链表
最后一个节点的 next ,指向头节点
哈希表 key-value pairs
有人说:哈希表看起来就是 JS 对象的简化版,有什么难点吗?
-
哈希表的难点,不在于「表」这个字
-
难点在于**「哈希」**二字
-
这里有一篇文章(停车场案例),帮助你理解什么是 hash
哈希表
- 就是存 key-value 这种形式的数据
- 并没有限制存储容量的上限。但是存的越多,读取就越难
- 难点就是如何读取hash表更快
哈希表的难点
场景
- 假设哈希表 hashTable 里有10000对 key-value (N=10000)
- 如何使得读取任意一个 hashTable['yyy'] 速度都很快呢 ?
- 可以看一篇文章(与停车场案例,同理)
hashTable = {
aaa: value1
aab: value2
aba: value3
abb: value4
...
zzz: value10000 // 假设共有 10000 对 key-value
}
// 找到 hashTable[`yyy`] 的最快方式
解决办法
-
不作任何优化,hash['xxx'] 需要遍历所有 key,复杂度为 O(N) (N表示key的总个数10000)【速度慢】
- 一万个需要1秒,十万个10秒 …
-
对 key 排序,使用二分法查找,复杂度就是 O(log(2)N) => 可简写成(ln N)【速度较快】
-
用字符串对应的 ASCII 数字做索引,复杂度 O(1) 【速度最快,占空间巨大】
aaa => 979797 (a: 97) yyy => 121121121 (y: 121) // 虽然一次就可以直接找到 yyy, 但是就像停车场的案例,这样导致占用的空间太大了(每一个指都对应一个空间) -
对索引做除法,取余数,O(1) 【速度最快,节省大部分空间】
假设要获取的key的ASCII为 979797,准备一个长度为 1000 的容器 那就用 979797 / 1000 余数肯定在 0~999 之间 这个数组只需要 0~999 项 { 0:aaa,aab,aba,abb,... 1: bbb,bba,bab,baa,... 2: ccc,... ... 998: yyy,... 999: zzz,... }(同一个号码有两个)冲突了怎么办,冲突了就顺延
- 998 满了就存 999,999 满了就存到 0,0 满了就存到 1 …
- 反正只有 1000 个位置
树 Tree
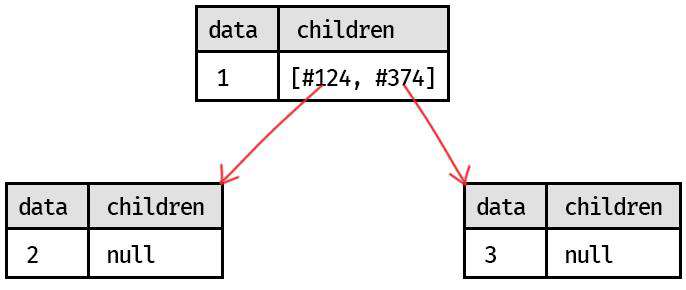
- children 是个数组
- data1 节点有两个子节点(数组元素) data2 / data3 ,共同组成一个「树」结构(可以有无限长)
- 两个子节点 data2 / data3 可以再向下链接其他的子节点 data4 / 5 / 6 … ,也可不再有其他子节点
- 如果子节点不再(分枝杈)有 children,就称这个子节点为「叶子」
- 链到头了,最后一个节点
- 所以 data1 有两个叶子
实际使用
- 中国的省市区,可以看成一棵树
- 公司的层级结构,可以看成一棵树
- 网页中的节点,可以看成一棵树 html > head、body,body > div、span、a、p …,head > link、title、meta
对「树」进行增删改查
let tree = createTree(value) // 创建树
let node = createNode(value) // 创建节点
addChild(tree,node) // 添加节点
removeChild(node1,node2) // 删除节点
travel(tree) // 遍历树
创建树(根节点)
const createTree = (value) => {
return {
data: value,
children: null, // 子节点
parent: null // 父节点
}
}
添加子节点
/*
* 添加子节点
* 参数1:往哪个节点下添加子节点
* 参数2:要添加的子节点数据是什么
* */
const addChild = (node, value) => {
const newNode = {
data: value,
children: null,
parent: node
}
node.children = node.children || [] // 必须保证node.children是数组,才能用push方法
node.children.push(newNode)
return newNode
}
遍历节点
/*
* 遍历节点
* 先fn操作根节点,然后遍历根节点上的所有子节点,分别用fn操作子节点(不断循环)
* 这种先打印根节点,后处理子节点的遍历方法,称为「先根遍历」法,是比较简单的遍历方法
* 当然还有其他遍历方法
* */
const travel = (tree, fn) => {
fn(tree)
if (tree.children) {
for (let i = 0; i < tree.children.length; i++) {
travel(tree.children[i], fn)
}
}
}
删除节点
/*
* 删除节点
* 数组只能通过下标删除元素(splice)
* 所以必须先找到node的兄弟姐妹,遍历兄弟姐妹,看node排行第几(获取下标)
* */
const removeNode = (tree, node/*要删除的节点*/) => {
const siblings = node.parent.children
let index = 0
for (let i = 0; i < siblings.length; i++) {
if (siblings[i] === node) {
index = i
}
}
siblings.splice(index, 1)
}
查找节点
/*
* 查找节点
* */
const findNode = (tree, node) => {
if (tree === node) { // 要查找的就是根节点
return tree
} else if (tree !== node && tree.children) { // 非根节点、且存在子节点的情况
for (let i = 0; i < tree.children.length; i++) { // 遍历所有子节点,找到目标node
const result = findNode(tree.children[i], node) // 递归
if (result) {
return result
}
}
return undefined
}
return undefined
}
数据结构就这么简单 ?
- 程序员崇尚简洁优雅
- 如果你觉得某个编程概念真的很难
- 那么请相信一定是你哪里理解错了
- 请试着重新理解一下
- 把细节自己动手敲一敲,才找到错误点。
- 这个过程中可能会突然意识到「噢!!原来是这样,我之前大脑想的是错的」
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!