前言
在日常的工作中,由于业务或者工作安排的需要,有时候需要我们参与到一些曾经没有接触过却 历史悠久 的项目当中,如果这个项目创建初期,创建者有很好的 前瞻性,并且严格遵循 code preview 等项目开发工作流,那代码看上去就会像是同一个人写出来一样,十分规范;否则,将会逐渐沦为一个 茅坑代码集合。
接下来我想分享一下近期对公司的一个小程序项目做的一些优化工作,会分别从以下几个方面进行阐述:
- 项目现状
- 项目拆解
- 搭建工具平台
- 项目地址
项目现状
1. 子模块分包不完全,存在子包内文件相互引用的情况
2. 个别没有用到的图片等静态资源文件没有及时删除,导致包体积过大,无法生成预览码
3. 测试同学反馈小程序测试流程过于繁琐,复杂,加大测试工作量和小程序的出错率
项目拆解
因此,需要针对以上提到的三个问题对这个项目进行初步的基于项目目录结构层面上的优化(不涉及到项目里面的业务代码,组件等冗余代码的优化)
其实也很容易理解,当你刚接手一个项目的时候,想必是先对这个项目的目录结构有一个总体初步的认识。
一、 “子模块分包不完全,存在子包内文件相互引用的情况”
1. 分析
如果是微信小程序项目,我们可以通过以下两种方法去快速了解一个项目的模块分包情况:
- 打开根目录下的
app.json文件,找到subPackages字段,这就是当前项目的所有子模块数组集合;(缺点:人工肉眼查找,不智能)
// app.json
{
"pages": [],
"subPackages": [
{
"root": "A",
"pages": [
"pages/A-a",
"pages/A-b",
....
]
},
{
"root": "B",
"pages": [
"pages/B-a",
"pages/B-b",
....
]
}
]
}
- 通过微信提供的 cli 命令行工具,查看当前的分包情况;(优点:不仅智能,还能查看每个子模块压缩后的包大小)
cli preview --project f://workspace/rainbow-mp/xinyu
效果如下:
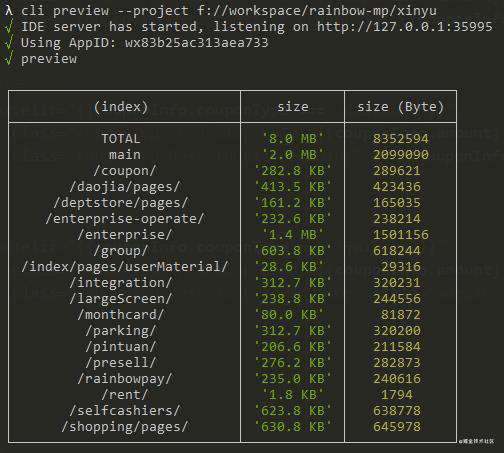
通过cli工具分析出来的结果,我们可以很明显看出当前项目总共分了哪几个子模块,以及这些子模块经过微信压缩工具(实则微信开发者工具编译)之后的大小,由此得出的当前项目存在的问题有如下几点:
-
主包(
main)体积已经超过了微信规定的2MB最大值,无法生成预览码用于移动端测试(问题很严重); -
子包分包不合理,将子包的子目录作为分包的入口(如:
/daojia/pages,/deptstore/pages,/index/pages/userMaterial,/shopping/pages),而不是将子包根目录本身作为拆包的入口,导致其余目录下的文件统一打包到了主包中,造成主包体积变大;
2. 细分拆包
换句话说,如果我们把子包的分包不合理的问题给解决了,主包(main)的体积过大的问题自然而然也就解决了。
定位到问题就相当于解决了一半。
接下来就是想办法把子包根目录更改为模块打包的入口,这时候有人会说了,把 app.json文件下的subPackages模块数组字段的每个模块的root的值都改成子模块的根目录不就完事了吗?
没毛病,做法就是这样
但是,在修改之前得保证拆出来子包根目录下的其余子目录下的文件并没有被别的模块引用,否则就会出现文件引用错误的bug。
因此,大致有以下两种做法可以参考一下,我采用的是第一种:
-
对当前拆解子包外的其余模块(包括主包
main) 进行全文件扫描,通过正则的方式过滤出require引用到的文件路径,进而分析是否有子包下的文件被别的模块引用; -
复写
require方法(因为我们项目中文件引入的方式是require方式);
这里简单说明一下我不采用第二种方法的原因:
-
require方法没有挂载在global全局下(因为接下来我需要写脚本在node环境下运行),因此需要重写一个如myRequire的自定义函数,然后挂载到global对象下,接着全局匹配所有文件的require字符替换为myRequire; -
require是动态引入,也就是说,可以在js文件的任意处进行引入,写在了小程序的业务代码中,因为接下来的脚本文件是运行在微信开发者工具以外的环境,缺失了微信小程序需要的模块包,会导致编写的脚本分析文件报错;
3. 编写脚本
接下来就正式步入编码阶段了,其实思路比较简单,我大致从以下几点进行这次脚本文件的编写:
1. 获取当前项目的所有一级目录:除去当前需要拆解的子包以外的所有一级目录都需要进行全局文件扫描
* 获取当前路径下的第一层目录
* @param {*} path 项目路径
* @param {*} targetDir 子包的目录名
*/
const getOwnDirectorys = async(path, targetDir) => {
const dir = await fs.promises.opendir(path)
const result = []
for await (const dirent of dir) {
const isDir = await isDirectory(`${path}/${dirent.name}`)
// 也就是说,除去子包以外的目录都需要进行全局文件扫描
if (isDir && dirent.name !== targetDir) {
result.push(`${path}/${dirent.name}`)
}
}
return result
}
2.过滤出每个一级目录下所有js和json文件
读取到目录了,那接下来自然就是遍历这些一级目录,然后获取到这些目录下的所有资源文件,那为什么只是过滤其中的js和json文件出来呢?
经过一段时间的接触之后,我发现:
-
子包的组件存在被别的模块包引用的情况,而小程序的组件引入主要是通过
json文件的usingComponents字段; -
子包的
js文件也存在被别的模块包引用的情况,多数发生在一些工具函数,接口调用文件上;
因此,为了减少扫描文件的数量和提高效率,先针对项目中每个模块的js和json文件进行扫描匹配。
const filterJsAndJsonFiles = async (dirItem, filterDirs) => {
const subDir = await fs.promises.opendir(dirItem)
const jsFiles = []
const jsonFiles = []
for await (const dirent of subDir) {
// 不需要分析的目录直接跳过
if (!filterDirs.includes(dirent.name)) continue
const currentFiles = getAllFiles(`${PROJECT_NAME}${dirItem}/${dirent.name}`)
// 过滤若干不同类型的文件数组
currentFiles.forEach(fileItem => {
const extname = path.extname(fileItem)
if (extname === '.json') {
jsonFiles.push(fileItem)
}
if (extname === '.js') {
jsFiles.push(fileItem)
}
})
}
return {
jsFiles,
jsonFiles,
}
}
3. 文件查找 & 匹配
到这里,我们已经拿到了每个模块对应下的所有js,json文件,接下来就需要针对这些文件进行分析了,大致思路分为以下两点:
json文件分析:读取文件内容,将json字符串转为json对象格式,过滤出usingComponents字段,查找匹配出拆解子包的组件;
{
"usingComponents": {
"a": "./A/a",
"b": "../B/b",
"c": "../C/c"
}
}
js文件分析:读取文件内容,通过正则表达式过滤出require引入的文件字符数组,从中查找匹配出拆解子包内的文件引用;
const a = require('../../a.js')
const b = require('./b.js')
....
脚本编写:
json文件组件引入分析:
/**
* 统计json文件引入到的组件数组
* @param {*} jsonFile
*/
const listComponents = (jsonFile) => {
if (!jsonFile) return
const jsonDataStr = fs.readFileSync(jsonFile)
const jsonData = JSON.parse(jsonDataStr)
const componentList = []
if (jsonData) {
const { usingComponents } = jsonData
for (let key in usingComponents) {
componentList.push({
name: key,
path: usingComponents[key],
filePath: jsonFile,
})
}
}
return componentList
}
js文件require引入分析:
const lineReg = /require\s*\([\'\"][\w\W]*[\'\"]\)/g
// 子模块初始化
moduleResultMap[dirKey] = {
componentImport: [],
fileImport: {},
}
jsFiles.forEach(filePath => {
const fileContent = fs.readFileSync(filePath, 'utf8')
// 为了避免无用查找,只针对前30行文本进行内容分析
const lines = fileContent.split(/\r?\n/).splice(0, 30)
// 初始化子包目录文件名
moduleResultMap[dirKey]['fileImport'][filePath] =
lines.reduce((acc, current) => {
const matchArr = current.match(lineReg)
return matchArr && matchArr.length > 0 && matchArr[0].indexOf('/daojia/') > -1 ?
[...acc, matchArr[0]] : acc}
, [])
})
4. 效果展示
最后,我是将分析出来的结果导出到了csv文件中,以便于为我接下来的拆包提供一份相对有保障的可视化的支持:
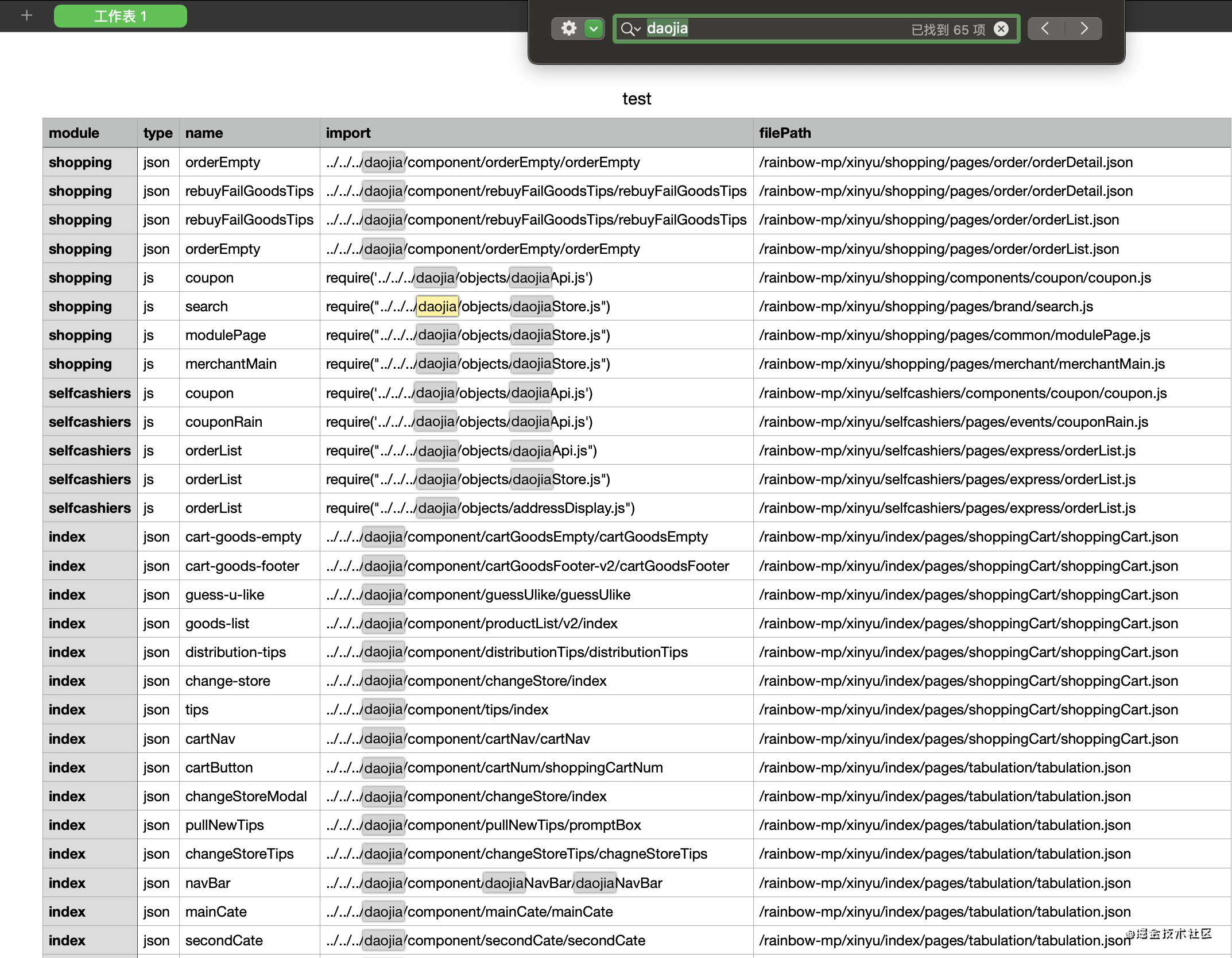
因为我这次主要是针对项目中daojia这个子模块进行一个拆包,因此分析的也是针对项目中其余子模块对该模块文件的一个引用情况做一个分析,表格中的每个字段所代表的意思我也大概说明一下:
interface Table {
module: string //子模块
type: string // 分析的文件类型
name: string // 分析的文件名
import: string // 引用的组件 || 引用的文件
filePath: string // 分析的文件路径
}
5. 终极展示
我们再回过头来看这幅图:
当我们成功地都将以下几个子包根目录从项目中剥离抽身之后,才会真的有底气地说:把app.json文件下的subPackages改下就好了
/daojia/pages -> /daojia
/deptstore/pages -> /deptstore
/index/pages/userMaterial -> /index
/shopping/pages -> /shopping
再来看看现在的模块包分析表:
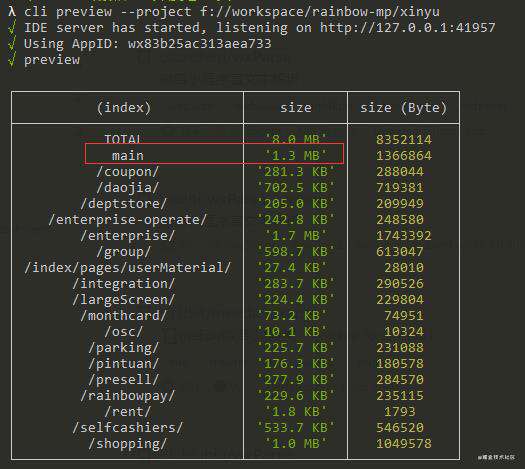
结论:经过合理化的分包之后,优化后的主包体积比优化前整整减少了35%
二、“个别没有用到的图片等静态资源文件没有及时删除,导致包体积过大,无法生成预览码”
1. 分析
在上一节里,我的做法概括起来:拆解子包,合理化模块打包
由于各种原因,一是在当前项目里面存在了过多的活动图片,重复的icon等等,但是当活动下架之后,这些图片并没有得到及时移除;二是组件引用混乱,相同组件的代码会同时出现在各个子模块里面;
这些无疑都是导致 项目体积过大 和造成 项目难以维护 的主要原因;
所以,在这一节里,也可以概括一句话:剔除无用资源,减少项目文件
2. 思路
总体来说,我也是通过写脚本来分析这些资源文件,思路如下:
- 无用图片资源查找
① 根据不同模块配置信息,依次读取当前模块图片目录下的所有图片文件,过滤出图片文件名,存储在一个数组内;
② 然后全扫描这个项目内的所有文件,通过fs模块读取到文件的字符串内容,遍历图片数组,根据字符串匹配indexOf,如果存在,则标记图片的引用路径;文件全扫描之后,如果找不到,则在路径一栏标记为“没有用到”;
③ 又或者匹配到的图片,则从数组内剔除出去,当扫描完所有的文件之后,剩下的就是没有引用到的图片文件了;(以上方法很蠢,但是胜在简单粗暴,希望有更好方法的朋友可以给我留言,不胜感激。)
- 组件引用分析
① 根据不同模块的配置信息,依次读取当前模块内pages和components目录下的json文件(组件引入的入口),实则一个JSON字符串的转成JSON对象;JSON.parse(jsonstring)
{
"usingComponents": {
"a": "./A/a",
"b": "../B/b",
"c": "../C/c"
}
}
② 然后获取其相同文件名的js文件(页面或者组件的主体文件),通过fs模块读取文件内容,注意,这时候是得将这些富文本字符串转为DOM节点树结构对象,然后遍历节点对象,去匹配解析出对应的json组件引入入口文件下的json对象,然后分析出引用到的组件,实际就是节点标签名的匹配过程。
3. 脚本编写
这里就把一些核心代码贴出来就好,大家看看就好,不做过多阐述了
- 无用图片资源查找脚本
// 需要分析的图片目录地址
const imgDirPath = path.resolve(__dirname + '/../..' + imagesEntry);
const imgFiles = getAllFiles(imgDirPath)
if (imgFiles.length === 0) return
// 只保留图片的文件名数组
const allImageFiles = imgFiles.map(imgItem => path.basename(imgItem))
// 查找所有的wxml, js文件
const allWxmlFiles = targetEntrys.reduce((acc, targetEntry) => {
const targetDirPath = path.resolve(__dirname + '/../..' + targetEntry)
const targetAllFiles = getAllFiles(targetDirPath, true)
const allWxmlFiles = targetAllFiles.filter(filePath => {
const extname = path.extname(filePath)
return ['.wxml', '.js'].indexOf(extname) > -1
})
return [...acc, ...allWxmlFiles]
}, [])
// 遍历图片集数组,查找文件是否有引入
const result = allImageFiles.reduce((acc, imgName) => {
const rowItems = allWxmlFiles.reduce((childAcc, filePath) => {
const fileStr = fs.readFileSync(filePath, 'utf8')
return fileStr.indexOf(imgName) === -1 ? childAcc : [...childAcc, {
image: imgName,
existPath: filePath,
}]
}, [])
// 如果查找完毕数组为空,则说明没有引入到该图片
return rowItems.length === 0 ? [...acc, {
image: imgName,
existPath: '没有用到'
}] : [...acc, ...rowItems]
}, [])
// 导出csv文件
const csv = new ObjectsToCsv(result)
const exportPath = `${__dirname}${'/../..'}${BASE_EXPORT_IMG}/${imageReportFile}`
await csv.toDisk(exportPath)
- 组件引用分析脚本
// 解析入口目录
const entryDir = path.resolve(__dirname + '/../..' + entry)
const allFiles = getAllFiles(entryDir)
if (allFiles.length === 0) return
const filterFiles = getFilterFiles(allFiles, ['wxml', 'json'])
// 组装导出对象数组数据
const pageWithComponents = filterFiles.reduce((acc, { jsonFile }) => {
const current = path.basename(jsonFile, '.json')
const currentDir = path.dirname(jsonFile)
const components = listComponents(jsonFile) || []
if (components.length == 0) {
return [...acc, {
page: current,
directory: currentDir,
}]
} else {
// 输入wxml地址,转化为json标签对象
const fileJsonData = getFileJsonData(currentDir + `/${current}.wxml`)
const childs = components.reduce((childAcc, { name, path: compPath }) => {
let used
if (fileJsonData) {
used = isWxmlImportComponent(fileJsonData, name)
used = used ? 'true' : 'false'
} else {
used = '解析出错'
}
return [...childAcc, {
page: current,
directory: path.resolve(currentDir),
component: name,
componentPath: compPath,
used,
}]
}, [])
return [...acc, ...childs]
}
}, [])
// 导出csv文件
const csv = new ObjectsToCsv(pageWithComponents)
const exportPath = `${__dirname}/../..${BASE_EXPORT_COMPONENT}/${exportFileName}`
await csv.toDisk(exportPath)
结论:剔除没有引入的图片资源,减少项目体积;分析页面的组件引入,为项目的组件库的搭建提供数据支持。
三、“测试同学反馈小程序测试流程过于繁琐,复杂,加大测试工作量和小程序的出错率”
1. 分析
小程序测试步骤如下:
- 开发同学在功能提测阶段,需提供功能分支名给到测试同学,比如说:
feature/monthcard - 测试同学需要切换功能分支,并且拉取最新代码,执行
git checkout feature/montcardgit pull origin feature/monthcard
- 打开
小程序开发者工具,更改配置文件环境参数,如:config.js,比如说修改成env = test/dev/pre/pro等等,切换到对应的接口环境进行测试 - 如只需要本地测试,直接在工具上面测试即可,如需要移动端测试,则需要点击
编译执行生成小程序预览码,手机扫码测试 - 后期开发同学推了代码,需要同步测试同学定期去更新代码,执行:
git pull origin 分支名
上面就是我司的关于小程序提测时的做法,相信这也是一部分公司的关于小程序的测试流程,又或者一部分公司的做法如下:
-
开发同学在本地生成测试预览码,然后将预览码截图发给测试同学进行测试(测试预览码有时效限制,需要开发每隔一段时间去重新生成一个新的预览码);
-
开发同学编写工具,将整个小程序代码包压缩放在内网的一个网页下,每次由测试下载到本地,解压,然后用开发者工具打开测试(一定程度自动化了测试流程和简化了测试同学的流程,但是依然很麻烦);
结论:总得来说,开发和测试同学都没有成功从上面的开发工作流中解耦出来。
2. 解决方案
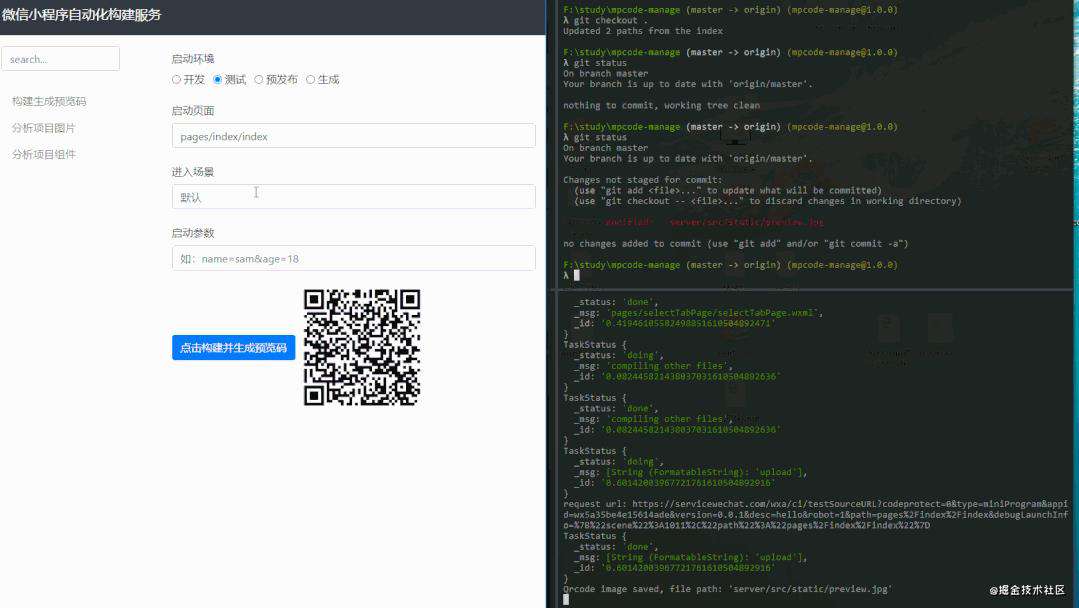
基于上述的一些问题,我发现这一系列的测试步骤可以通过微信官方提供的ci命令行工具,是完全可以抽象出来,做成一个可以简化测试工作流的工具平台,听着是不是很棒?
下面就是我的一些调研发现:
微信ci文档地址
搭建工具平台
- 前端(js)
- React 搭建前端骨架(借用facebook提供
create-react-app脚手架即可) - Bootstrap 作为前端界面布局的ui框架库
- 后端(nodejs)
- 采用
Expressweb应用开发框架搭建即可 - 安装
miniprogram-ci包(构建预览码,提交发版等) - 安装
html2json,objects-to-csv包(用于项目静态资源使用分析等)
ps: 这里就不对里面的技术细节做过多阐述了,具体可以查看文末的项目地址,我已经开源出来了。
效果展示:
项目地址
出于代码保密考虑,开源项目里面分析的小程序源码采用的是自己的一个小程序项目作为分析的基础项目:
- 小程序项目脚本分析项目地址
github.com/csonchen/wx…
- 小程序项目的自动化构建服务平台
github.com/csonchen/mp…
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!