组件化给前端带来前所未有的流畅体验,我们可以使用这些组件拼装我们的完整的 UI 界面。开发提速的同时也提高了可维护性。但是随着业务功能复杂度的提高,越来越多的重复逻辑代码出现,我们不得不复制粘贴、不得不维护多处代码。为了解决这个问题,React 团队不断探究逻辑复用方案:从 Mixin 到 高阶组件 到 Render Props 到现在的 Hook。
React Hooks 是React 16.7.0-alpha 版本推出的新特性,本文将会简单对比一下 Class 语法和 Hook 语法,着重介绍 Hook 的使用以及本人的一些探索,针对 Hook 的优缺点进行表述,不涉及 Hook 教学部分,没有使用过的小可爱欢迎先移步Hooks总览,拥抱函数式 。
类组件现状
类组件(Class 语法)目前是最广泛的 React 写法,整体写法而言没有什么大问题。常见的问题有
- 继承 pure 组件导致渲染失效,常见于同一对象保持相同引用导致。
- Class 的 this 、super 语法不是很友好,同时 babel 最终编译产物还是函数。同样 Class 仅仅作为语法糖,给 React 内部优化也带来了一些困难。
- 事件 this 指向问题, React 合成事件的机制 + 严格模式 直接执行函数导致,需要通过bind 或者箭头函数解决
- 生命周期冗余 ,部分情况下会有 componentDidMount 和 componentDidUpdate 执行相似代码片段,生命周期较多,16又推出新的生命周期,学习成本较大。同时学习新的生命周期需要理解 React 内部的设计哲学,明白 reconciliation、commit 阶段的拆分以及带来的意义。
- 高阶组件能力孱弱,本质上是为了增强组件功能同时实现逻辑复用。大部分的情况下都是用来控制子组件的 props,对于子组件生命周期的劫持、重写或者 super.render() 几乎没有需求。同时因为高阶组件必须使用组件嵌套的方式导致会多若干层 DOM 结构容易变成套娃结构。
- 组件复用困局,这点个人感觉是最大的问题,早期使用 CreateClass + Mixins ,在使用 Class 语法取代 CreateClass 之后又设计了 Render Props 和 HOC,直到再后来的 Function Component + Hooks 设计,React 团队对于组件复用的探索一直没有停止,Hooks也不会是终点。
同样我们越来越偏向于基于视图编写我们的组件。组件慢慢按照视图中部分划分(当然这没有任何问题),通过 props 或者 redux 作为连接。当不同组件具有相似的逻辑的时候,要么通过高阶组件实现,要么通过函数实现。因为函数(不使用 hook)不具备 setState 的能力(当然你传入一个 forceUpdate 函数不算),虽然无状态组件具有较高的性能但是能力不够所以一直只能做简单的展示组件用。
所以为了优雅地复用逻辑和更加简化的 API 以及 React 内部更好的性能优化控制,Hook 出现。
简单介绍 Hook
API 比较简单:
- useState 控制状态;
- useEffect 控制生命周期;
- useCallback 做函数缓存;
- useMemo 做数据结构缓存以避免子组件的 pure 失效;
- useRef 维护数据。
以上几个 API 基本可以满足需求,当然你可以选择 redux 作为中心化状态管理或者使用 useContext + useReducer。
另外一个你可能有用的是使用 useImperativeHandle + forwardRef 方便父组件直接获取使用子组件里面的值、函数,因为函数组件不存在实例。
优点
Hooks 现在极被推崇,的确相比较于类组件优点很明显。
- 生命周期简化,一个 useEffect + 依赖数组走天下。生命周期的概念弱化。这样的好处不仅仅是上手难度降低,同时也让代码编写方式产生了质变。由副作用明显的类模式开发转变到基于纯声明式的函数开发。
- 更加偏向函数式编程,抹杀 Class 的一些副作用(对于 fiber 结构内部调度有优化)。和上一条类似的影响。
- Hooks 提供的 API 更加方便构造合适你的 redux 应用。
- 相较于 HOC 和 props 模式,更加优雅的逻辑复用。类组件的情况下 render 函数必须返回 jsx 结构或者 null,这对于逻辑抽象明显是不友好的。
- 模型更加声明式。
- 函数式组件的心智模型。
上面说了这么多套话,实际体验下来,写法才是最大的变化,实现功能的方式相比较于类方式有了很大的改变。生命周期这种副作用集合体被弱化,纯函数式、声明式的写法个人感觉更加回归 JS 语言本身,语言本身的特性可以被挖掘,函数的功能得到了极大拓展。
类组件的写法在发展中已经逐步固化,这是好处,一个页面该怎么写、用不用 redux、哪些重复逻辑可以被 HOC 抽离出来、哪些组件是公用的在了解到页面的视图和功能的时候基本上就可以确认下来。Hooks 并不是,在类组件的基础上,逻辑也可以进行抽离,没有 HOC 的局限,你可以随意抽离,进行自然式或者触发式。
更加简单或者直白的优点是:
- 多个状态不会产生嵌套,写法还是平铺的(解决 HOC 的嵌套问题)
- 允许函数组件使用 state 和部分生命周期(赋予了函数 react 能力)
- 更容易将组件的 UI 与状态分离(最大的优点)
使用探索
Hook 作为 React 框架内提供的一种逻辑复用形式,很多时候开发者更容易流于表面,仅仅体验到函数式编程的愉快但是没有做到逻辑的复用,或者过犹不及,复用过程中缺乏设计感和复用性。
下面的想法仅仅提供一个思路,不代表做法一定是对的,希望大家可以有自己的思考可以一起讨论,发掘 Hook 的更多最佳实践。
颗粒组合
正常开发流程来讲,类组件的 state 中定义状态(部分非状态的数据有时候也会存在 state 中),生命周期中定义请求数据然后更新 state 视图的逻辑,最后在 render 中获取 state 和 this 上面挂载的各种自定义函数应用于 JSX 结构中。
现在切换到 Hook 开发中,你可以按照上面相同的结构开发你的功能,或者想多点。
const ComponentA = props => {
const {
state: {},
data: {},
action: {}
} = useLogic(props);
return <div></div>;
};
上面的结构中,useLogic 封装了该组件的全部能力,同时返回状态、静态数据、操作函数。return 的 JSX 结构中直接使用即可,可以简单得认为 useLogic 是对 ComponentA 的逻辑抽取。当然逻辑抽离应当是合理的,不只是简单把逻辑函数全部放到另外一个文件中,这种做法唯一收益可能只是减少了文件的代码行数。
这种情况下 useLogic 太过于耦合 ComponentA 的功能,不具备通用性,不具备通用性的抽离可能意义稍小。(只是减少了 ComponentA 的代码行数)
const ComponentA = props => {
const {rdData} = useRequest(props)
const {
state: {},
data: {},
action: {}
} = useLogic(rdData);
return <div></div>;
};
现在将 useLogic 中请求部分剥离出来,这部分往往都是极度耦合页面功能的,useRequest 会接收基本参数然后发出请求,同时会在获取到返回值的时候 setState 一下,由此 ComponentA 会重新 render 一次,此时 useLogic 拿到后端数据重新进行逻辑处理。
目前为止,页面可以简单抽离出接口请求部分和针对数据的处理部分。发散一下思维,你可以把你页面的列表数据懒加载、拖拽功能、倒计时、答题逻辑、进度条逻辑封装成一个个独立的 Hook,甚至于是某种通用的功能,比如图表渲染、boss 中通用的表格操作逻辑、分页逻辑。
再回到代码本身,其实有一个问题,state 该保存在哪儿,你可以保存在 ComponentA 中,这样 useLogic 中根据传入的 state 进行一系列操作返回对应的值,需要使用 useCallback、useMemo 进行众多变量的缓存(避免重复 render)。这种情况下 useLogic 不具备 setState 的能力,功能稍弱但是使用很灵活,比较适用于简单交互的功能。
const ComponentA = props => {
const [pageData, setPagedate] = useState({})
const {
state: {},
data: {},
action: {}
} = useLogic(pageData);
const {rdData} = useRequest(props);
setPagedate(rdData)
return <div></div>;
};
此时的 useLogic 便是一个简单的运行时数据 + 操作的工厂,但是当 state 复杂、运行时数据繁多的时候,这种方式起不到足够的逻辑分离功能。
此时你可以选择将 state 保存在 useLogic 中,这样的 useLogic 似乎才更像一个自定义 hook。 useLogic 管理自己的 state,对外暴露数据层 + 操作。
const useLogic = data => {
const [state, setState] = useState({});
useEffect(() => {
if (data) {
setState();
}
}, [data]);
return {
state: {state},
data: {},
action: {setState}
};
};
此时的 useLogic 是和 ComponentA 的功能强耦合的,任何新增功能基本上都是在 useLogic 中修改,因此为了具备普适性(如果你不想这个 useLogic 别的地方也可以复用的话就不用处理), useLogic 的功能维度必须够小,逻辑抽离的细度必须足够(也不能太小)。
const ComponentA = props => {
const [pageData, setPagedate] = useState({})
const {
state: {},
data: {},
action: {}
} = useLogic1(pageData);
const {
state: {},
data: {},
action: {}
} = useLogic2(pageData);
const {
state: {},
data: {},
action: {}
} = useLogic3(pageData);
const {rdData} = useRequest(props);
setPagedate(rdData)
return <div></div>;
};
此时另外一个问题出现,功能的关联性。useLogic1 需要联动触发 useLogic2 的一个功能或者获取数据,这种情况下,大部分依靠 ComponentA 做粘合剂的功能,对独立功能的耦合模块做整合。
上面说到的页面组件设计颗粒是基于业务层面,采用合适的抽离 + 组合,可以使得我们的页面代码风格更加简洁、逻辑抽象更加优雅。可能唯一的问题就是合适的点在哪儿了。
分层
下面看一下整体架构设计里面的分层,在React Hooks的体系设计之一 - 分层这篇文章中提到一个颇有争议的观点:
架构层面的分层设计是无关于 Hook 的,这是原本就应该存在,只不过因为 Hook 锦上添花。页面的基本通用能力原本就应该在底层提供,通过路由或者其他工具提供给每一个消费者。Hook 本身仅仅提供最基本的使用功能,在这之上完全可以实现一层我们自己的业务使用,譬如下面会提到的 useRefState。我们可以借助例如 VCA 中部分理念模拟出我们想要的方式(例如为了学好 React Hooks, 我抄了 Vue Composition API),比如借助代理实现响应式、通过 generator 实现 Hook 同步化执行(很难搞)。
总的来说,自定义 Hook 的封装应当是基于功能维度,将页面的独立功能摘出来,比如倒计时功能、报名逻辑,在页面中做逻辑组合,对,这可能又是你写 Hook 的一个理由,因为组合优于继承。自定义 Hook 的封装不应该是盲目的,而是需要充分考虑到功能的解耦、需求未来的变动。
但是同时 Hook 存在的问题也是很明显。
缺陷
Hook 很强大,使用起来却也是存在一些不是那么美好的地方,下面就是我自己的吐槽环节。
函数重复执行区域过大,容易造成性能问题。
类组件每次 render 的时候,重复执行的都是部分生命周期和 render 函数,而对于函数组件而言,render 就是一次重新执行。所以你在其中定义的局部变量在和 Hook 本身 API 不挂钩的情况下都是会被重新赋值,你能做的就是提升到全局或者利用例如 useRef 的缓存功能进行一次保存。
重复执行,重复生成新的对象或者函数自然会导致子组件的 pure 优化失效。
例如下面:
let Son = ({data: {aaa}}) => {
console.log('son render');
return ...
};
// memo 优化失效
Son = memo(Son);
const father = () => {
// 每次 father 渲染都会生成一个新的 data 对象
const data = {aaa: 111};
return (
<div >
<Son data={data} />
</div>
);
};
虽然 son 是被 memo 包裹进行了一次 shallow 比较同时传递过去的 data 中的 aaa 每次都不变,但是只要 father 中重新 render 了,子组件还是会必然重新 render,这就是因为每次 data 都是一个新生成的对象,同时不管是 pure 还是 memo 都只是进行了 shallowEqual 的比较,不同的引用对象导致直接返回了 false,子组件重新渲染。虽然一次不必要的 render 不一定会造成很大的问题但是代码层面尽可能的优化是每一个 coder 应该具备的素养。
正确的做法自然是使用上面提及的 useMemo 和 useCallback。记住搭配 memo 使用效果更佳,当然,不需要使用这个优化的时候就不必用,毕竟依赖数组里面的几次比较和闭包问题比定义一个内联函数的成本大得多。
另外值得注意的一点是 Hook 内部使用 Object.is 来比较新/旧 state 是否相等。
本身不存在合适的全局变量
类似上面提到的问题,因为每次 render 执行面积是整个函数,所以你在函数内部不使用 Hook API 的情况下是不具备一个全局变量的。当然你可以定义在函数外围解决这个问题,或者可以基于 useRef 功能造出一个类似于类组件中 this 的全局变量,它能够将内部函数中会用到的参数进行传递,类似于类组件中你挂载在 this 上不作为 state 使用的变量。
无处不在的闭包
简单说,看下图
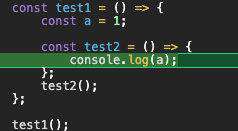
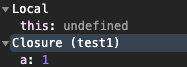
函数中定义的函数执行的时候内部访问到外部的变量都会基于闭包存储。如上的 test2 执行的时候访问到的 a 就是闭包中的值。
所以你在 Hook 中写的每个内联函数内部访问到的外部变量都会是以闭包模式获取到的值。这本身不存在任何问题,但是一旦你的函数是被缓存过的或者是只绑定过一次的事件,那么你访问到的必然是被预解析器复制到堆中的值,也就是旧值。
这个在定时器、useCallback、只绑定一次的事件中必现,解决办法可以通过添加依赖数组,但是增加依赖的做法毕竟不治本,同时也会干扰语义,在依赖过多的时候也会丑陋。在部分场景下你是可以通过 useState 的函数语法或者使用 useReducer 规避这些问题,目前看,最普适的还是通过 useRef 保存,useRef 会构造一个hook 渲染周期外的全局对象,你可以通过 useRef 保存某一个值(大部分场景下一个就够了),或者构造一个全局大对象,手动保存一下所有的 state 引用。
我目前的做法是基于原生的 setState 构造一层新的 API:
/**
* useRefState 引用state的最新值
* @param {any} initialState
*
* Demo:
* const [count, setCount, countRef] = useRefState(0)
* countRef.current 获取最新值
*/
export const useRefState = initialState => {
const ins = useRef();
const [state, setState] = useState(() => {
// 初始化
const value = isFunction(initialState) ? initialState() : initialState;
ins.current = value;
return value;
});
const setValue = useCallback(value => {
if (isFunction(value)) {
setState(prevState => {
const finalValue = value(prevState);
ins.current = finalValue;
return finalValue;
});
}
else {
ins.current = value;
setState(value);
}
}, []);
return [state, setValue, ins];
};
API 使用条件严格
最重要的一条规则是只能在函数的最外层调用 Hook。不要在循环、条件判断或者子函数中调用,这个是因为 Hook 的实现原理导致的。这个条件会使得你的自定义 Hook 必须直接写在组件最外面,不能有任何逻辑判断。这个要求对于新手的难度稍大,同时也会造成一些不便。
一个基于后端数据产生新数据的自定义 Hook,不管有没有获取到后端数据,都得直接写在组件最外层,所有的判断都得在自定义 Hook 的内部,
const ComponentA = props => {
const {rdData} = useRequest(props);
const {
state: {},
data: {},
action: {}
} = useLogic(rdData);
return <div></div>;
};
useLogic 内部判断 rdData 有没有获取到,如果是一个通用功能的话,这个 rdData 有没有值可能会稍稍麻烦,无法依据某一个字段判断。
报错不友好
如果你违背了上面说到的规则,你可能收获:
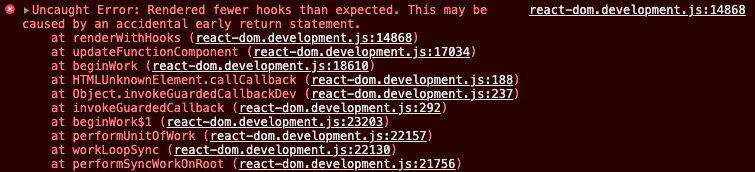

同样的问题造成的报错可能还会不同,这对于问题的排查可以说是灾难级别。这时候给安装合适的代码检测插件就显得极其重要,比如使用 eslint 并且开启相关的规则。
不适宜重页面
结合上面各种原因,其实一个重页面的主页面,实际上并不适合用 Hook 编写,当然拆分出来的小组件怎么写都可以。主页如果拆分合理 + 使用合适的状态管理工具的不会存在什么问题,但是如果页面的主要逻辑都在主页面,主页面承担了状态创建、修改 + 修改状态函数分发 + 子组件数据传递,难免会出现使用大量 useMemo、useCallback 的情况,以及埋在地下的闭包地雷。
数据源太多,无法保证一个运行时数据在后续迭代中拿取到正确的值,也许你没问题,但是下一个接手的人呢,修改依赖数据还是将值通过全局变量引用起来呢。偶尔使用起来还没什么问题,但多了起来难免有些饮鸩止渴的感觉。
理解困难
这点本人目前还没有发觉,但是网上很多人吐槽逻辑封装后阅读变得难以理解。这点应该和逻辑封装的合理性有关,还是上面说到了,封装应当是独立功能维度,不宜颗粒过粗也不以宜太细,
作弊器 useRef
这点我不知道算不算缺陷,但是通过 useRef 达到作弊效果个人认为是 track 的方式(但是真香)。期望这个问题在未来能够被 React 团队解决,比如推出一个新的 API 之类。使用全函数式编程,在复杂场景下稍显羸弱(也可能就是本人太菜),数据传递 + 闭包问题会让参数变得极为复杂,这个时候 Ref 作为作弊器全局变量让一切问题迎刃而解。其实 useRef 产生的值可以简单理解成函数外的一个全局变量,由 React 提供,可以保证渲染周期内不会改变。
未来
不必纠结于 OOP 还是 FP,JS 本身的特性,对于完整实现 OOP 本身就不容易,函数在 JS 中强大的灵活性,作为一等公民的现状也让使用函数式变得推崇。但是在 Hook 中你照样可以使用 OOP 的一些思维方式来开发,总之实现功能的方式或技巧是你自己决定的,对症下药,千万不要忽视使用场景而过度偏向。
按照 React 第一网红 Dan 的说法,Hook 会是 React 未来。同时 Hook 存在的一些问题也是不容忽视的,可以点击React Hooks的丑陋一面简单一看。写 Hook 并不难,困难之处在于写好。
在未来,Hook 的公共类库必然会出现类似 antd 一样的级别,但是分层和颗粒组合的最佳实践依旧算是一个探索的方向,但是毫无疑问的一点是,这必然会迸发出无限的创造力。
最后本文并没有涉及 Hook 另外一个很重要的功能:useReducer、useContext 相关功能。如果有机会下次介绍包括但不限于基于 Hook API 实现 redux 管理工具、逻辑组件 connect 的问题。
欢迎评论区一起讨论。
扩展阅读
- 命令式编程(Imperative) vs声明式编程( Declarative)
- 烤透 React Hook
参考
- 为什么 React 现在要推行函数式组件,用 class 不好吗?
- React 官网
- 以类hooks编程践行代数效应
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!