现代前端构建在 AST 之上,无论是 ESlint、Babel、Webpack,还是 css 处理器、代码压缩,都是站立在 AST 的肩膀上。在深入学习 Babel 之前,先了解一些关于 AST 的知识。
上周我还发了一篇 # 学习写一个简单的babel插件,这两篇文章一起看,效果会更好哟。
AST 是什么?
如果看完定义如果还是一脸懵逼,那么就上一个简单的 ? ,看看把一个简单函数转成 AST 后的样子。示例中的 AST 可以通过网站 astexplorer在线生成。
可以看到 AST 每一层都拥有相似的结构:
这样的每一层结构也被叫做 节点(Node)。 一个 AST 可以由单一的节点或是成百上千个节点构成。 它们组合在一起可以描述用于静态分析的程序语法。
每一个节点都有如下所示的接口:
type 字段表示节点的类型(如:FunctionDeclaration、Identifier、BinaryExpression)。每一种类型的节点还定义了一些附加属性来进一步描述该节点。
还有一些属性用来描述该节点在原始代码中的位置。
生成 AST 的步骤
生成 AST 分为两个阶段,分别是词法分析(Lexical Analysis)和语法分析(Syntactic Analysis)。
词法分析/扫描(Scanning)
词法分析阶段从左向右逐行扫描源程序的字符,识别出各个单词,确定单词的类型,将识别出的单词转换成统一的词法单元(token)形式。
token <种别码,属性值>
| 单词类型 | 种别 | 种别码 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 关键字 | if、else、then、... | 一词一码 | 标识符 | 变量名、方法名、... | 多词一码 | 常量 | 数字、字符串、布尔值 | 一型一码 | 运算法 | 算术(+ - * / ++ --) 关系(> < == != >= <=) 逻辑(& | ~) | 一词一码 或 一型一码 | 界限符 | ; () = {} | 一词一码 |
举个例子: a + b,这段程序通常会被分解成为下面这些词法单元: a、+、b,空格是否被当成此法单元,取决于空格在这门语言中的意义。
下面的代码就是利用词法分析网站解析 a + b 后得到的词法单元序列(toekns)。
对于词法分析感兴趣的同学可以阅读 @babel/parser 中的词法分析方法 Tokenizer。
语法分析(Parsing)
语法分析器从词法分析器输出的 token 序列中识别出各类短语,并转换成 AST 的形式。
Babel 工作流程
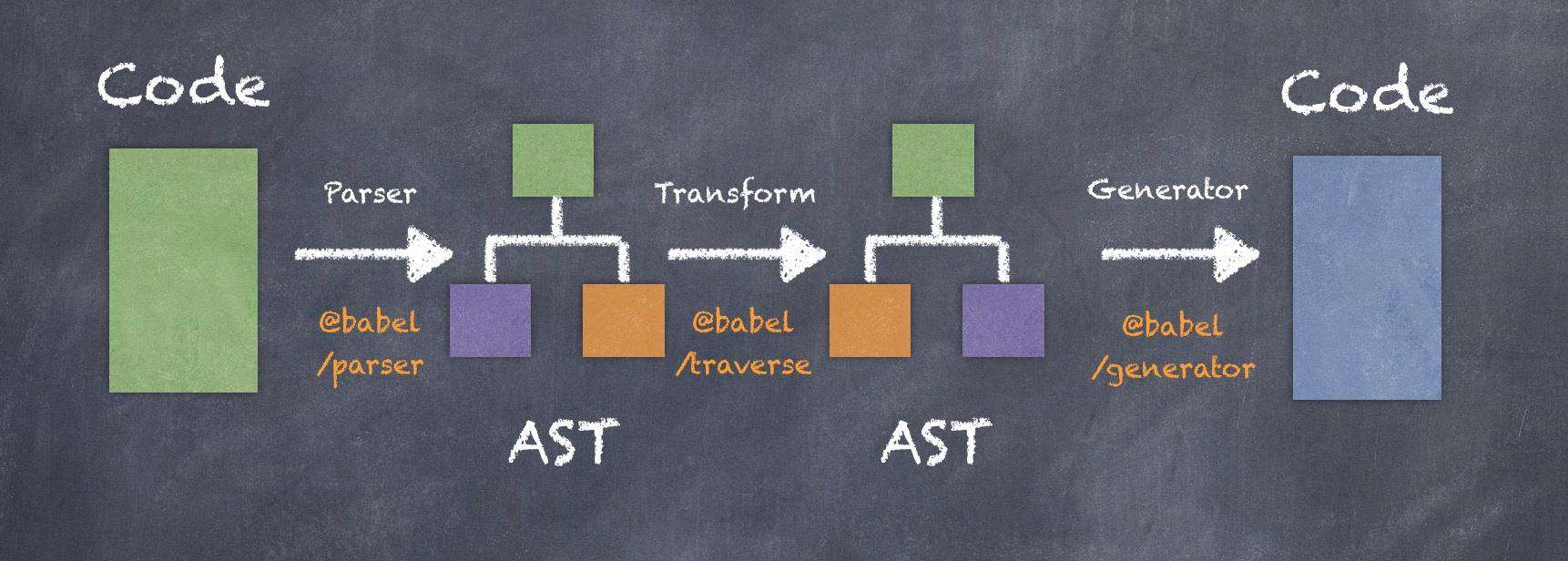
Babel 工作流程分为三步:Parse、Transform、Generator。
Parse 解析
第一步,Babel 会利用 @babel/parse 包提供的方法,经过 词法分析 和 语法分析 两个步骤,将源代码解析为抽象语法树(AST)的形式。
Transform 转换
第二步,在得到源代码的 AST 后,Babel 会使用 @babel/traverse 遍历整个 AST,并在此过程中根据需求修改 AST。
Visitors(访问者)
Transform 阶段,Babel 会维护一个 visitor 对象,这里对象里定义了用于在 AST 中获取具体节点的方法。下面请看一个例子:
上面的 visitor 对象中定义了 2 个方法,分别是 Identifier 和 FunctionDeclaration。Identifier 方法在遍历到 type: Identifier 的节点时会执行,而 FunctionDeclaration 方法会在节点的 type 为 FunctionDeclaration 时执行。
所以在下面的代码中 Identifier() 会被调用四次。
这些调用都发生在进入节点时,不过我们也可以在退出时调用访问者方法。将访问者方法修改一下:
Paths(路径)
访问者方法接收一个 path 对象参数,这个对象代表当前节点的路径。可以通过 path 访问当前节点、当前节点的父节点、还有其他 Babel 添加到该路径上的一些元数据。
State(状态)
修改 AST 时还要考虑代码的状态。比如有以下的例子,我们要将 square 方法中的标识符 n 修改为 x,这时候不能直接使用 Identifier 访问者方法,否则会将方法外的其他同名的标识符一起修改掉。
对于这种情况,可以使用 FunctionDeclaration 访问者方法,通过这个方法找到 square ,然后再深入递归查找递归查找。
Scopes(作用域)
JavaScript 支持词法作用域,在嵌套的代码块中可以创建出新的作用域。内部作用域可以访问外层作用域的变量、函数、类等,可以统一称这些为引用,而且内部作用域还可以创建和外层作用域同名的引用。因此,在修改 AST 时,必须注意引用的作用域。
幸运的是,Babel 替我们维护了引用和作用域之间的关系,这种关系称之为:绑定(binding)。可以通过 path.scope.bindings 获取当前路径所属作用域内的所有引用的绑定关系。单个绑定看起来就像这样:
有了这些信息你就可以查找一个绑定的所有引用,并且知道这是什么类型的绑定(参数,定义等等),查找它所属的作用域,或者拷贝它的标识符。 你甚至可以知道它是不是常量,如果不是,那么是哪个路径修改了它。
Generator 生成
经过上一步的 AST 修改后,需要将其再转换为代码,这时候就会用到 @babel/generator。
参考资料
- AST 详解与运用:zhuanlan.zhihu.com/p/266697614
- ESTree AST 规范:github.com/estree/estr…
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!