每次看到项目中出现的正则表达式,就感觉像看天书一样,好像对正则产生了恐惧心理。这次下定决心一定要弄懂正则,花了大量精力学习,终于可以大声地说我会正则了。本文的目的是让大家能读懂正则表达式,并且用手写正则解决项目中的一些问题。
正则中的符号
在大家的印象中,正则就是一串符号组成的,这些特殊的符号都有特殊的含义,它们是:
^ $ . * + ? = ! < : | \ / ( ) [ ] { }
本小节就从这些符号入手,快速带大家熟悉正则表达式。某些符号只有在正则表达式某些上下文中才具有特殊含义,其他时候则被当成普通字符处理。
反斜杠符号
| 字符 | 含义 | \ | 在非特殊字符前面加\表示下一个字符是特殊字符。比如/d/是匹配小写字母“d”,但是/\d/匹配的是数字0-9。在特殊字符前面加 \表示下一个字符不是特殊字符,而是字符本身,也就是所谓的字符转义。例如,想要匹配字符串中的小数点,必须加\:/\./,因为.是特殊字符,/./代表的是匹配所有字符。 |
|---|
例子1:匹配字符中的小数点,因为小数点.是特殊字符所以需要转义
// 不转义,.代表的是任意字符(后面会讲到)
const regExp = /./;
regExp.test('20'); // true
regExp.test('20.1'); // true
// 转义,\.代表的是小数点本身
const regExp1 = /\./;
regExp1.test('20'); // false
regExp1.test('20.1'); // true
字符组
| 字符 | 含义 | [...] | 包含方括号内的任意一个字符 比如 [123]表示匹配数字123中任意一个数字同时还可以表示一个范围, [a-z]表示匹配字符a到z之间任意一个字符 | [^...] | 反选,排除方括号内字符的任意一个字符 比如 [^123]表示匹配排除数字123的任意一个字符[^a-z]表示匹配排除字符a到z之间所有字符的一个其他字符 | \d | 表示[0-9],任意数字 | \D | 表示[^0-9],除了数字之外的其他任意字符 | \w | 表示[0-9a-zA-Z_] | \W | 表示[^0-9a-zA-Z_] | \s | 表示 [ \t\v\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符。 | \S | 表示 [^ \t\v\n\r\f]。 非空白符。 | . | 表示 [^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外。 |
|---|
例子1:/[abc]/匹配的是字符串是否包含abc中任意一个字符
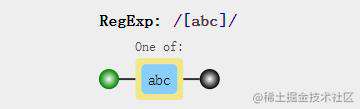
我们可以用RegExp对象上的test方法去验证:
const regExp = /[abc]/;
regExp.test('1a'); // true
regExp.test('bc'); // true
regExp.test('1'); // false
例子2:/a[^bc]d/匹配的是字符串是否有含有子串axd,其中x不能是字符b和c
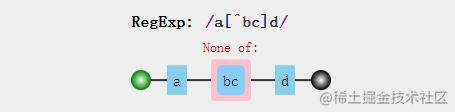
const regExp = /a[^bc]d/;
regExp.test('caed'); // true
regExp.test('abd'); // false
regExp.test('abcd'); // false
量词
| 字符 | 含义 | x{m,n} | x出现的次数为m-n次 | x{m,} | x至少出现m次 | x{m} | x出现m次,相当于{m,m} | x? | x出现0或1次,相当于{0,1} | x+ | x出现1或多次,相当于{1,} | x* | x出现0或多次,相当于{0,} |
|---|
例子1:/a{2,4}bc/中a{2,4}指的是字符串中a出现的次数是2-4次
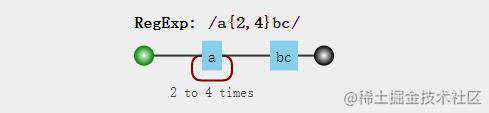
const regExp = /a{2,4}bc/;
regExp.test('aaabc'); // true
regExp.test('aabc'); // true
regExp.test('abc'); // false
例子2:/a{2,}b{3}c?d+e*/

const regExp = /a{2,}b{3}c?d+e*/;
regExp.test('aaabbbcdee'); // true
regExp.test('aabbbdd'); // true
regExp.test('aaabc'); // false
非贪婪的匹配
| 字符 | 含义 | x{m,n}? | x出现的次数m-n次 | x{m,}? | x至少出现m次 | x?? | x出现0或1次,相当于{0,1} | x+? | x出现1或多次,相当于{1,} | x*? | x出现0或多次,相当于{0,} |
|---|
上面我们讲的重复字符都是尽可能多地匹配,这种我们称为贪婪的匹配,同时我们还有非贪婪的匹配(也可以叫惰性匹配),它是尽可能少的匹配。
语法:在表示量词后跟随一个“?”。
例子1:使用"aaa"作为匹配字符串,用正则表达式/a+/去匹配,匹配的结果是"aaa",用/a+?/匹配的结果是"a"。
'aaa'.match(/a+/)
// ["aaa", index: 0, input: "aaa", groups: undefined]
'aaa'.match(/a+?/)
// ["a", index: 0, input: "aaa", groups: undefined]
多选分支
| 字符 | 含义 | | | 多选分支符。例如,/x|y/匹配的字符x或者y |
|---|
语法:p1|p2|p3,表示p1,p2,p3有一个满足即可。匹配的尝试顺序是从左至右的,如果左边的选择项匹配就会忽略后面的匹配项。
例子1:/scss|sass/,表示匹配scss或者sass都可以
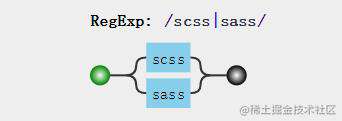
位置
有些正则表达式的元素匹配的是字符之间的位置,而不是实际字符,这在我们向字符串中插入字符的时候很常用。 正则表达式中的位置有以下几种:
| 字符 | 含义 | ^ | 字符串开头,多行检索中匹配的是行开头 比如 /^A/匹配以A开头的字符串,匹配不了 "an A"中的“A”,但能匹配 "An A"中的第一个“A” | $ | 字符串结尾,多行检索中匹配的是行结尾 比如 /t$/匹配以t结尾的字符串, 不能匹配 "eater" 中的 "t",但是可以匹配 "eat" 中的"t"。 | \b | 单词边界的位置 | \B | 非单词边界的位置 | x(?=p) | x后面的字符与p匹配时匹配x,即匹配p前面的位置 比如对于/ Jack(?=Sprat)/,“Jack”在跟有“Sprat”的情况下才会得到匹配. | x(?!p) | x后面的字符不与p匹配时匹配x,即匹配非p前面的位置 | (?<=p)x | x前面的字符与p匹配时匹配x,即匹配p后面的位置例如,对于 /(?<=Jack)Sprat/,“Sprat”紧随“Jack”时才会得到匹配。 | (?<!p)x | x前面的字符不与p匹配时匹配x,即匹配非p后面的位置 |
|---|
例子1:我们通过简单的例子来理解这些位置。
// 在字符串首尾(即^和$)处插入“#”
'javascript css html'.replace(/^|$/g,'#'); // "#javascript css html#"
// 在单词边界(即\b)处插入“#”
'javascript css html'.replace(/\b/g,'#'); // "#javascript# #css# #html#"
// 非单词边界(即\B)处插入“#”
'javascript css html'.replace(/\B/g,'#'); // "j#a#v#a#s#c#r#i#p#t c#s#s h#t#m#l"
// 在空格前的位置插入“#”
'javascript css html'.replace(/(?=\s)/g,'#'); // "javascript# css# html"
// 在非空格前的位置插入“#”
'javascript css html'.replace(/(?!\s)/g,'#'); // "#j#a#v#a#s#c#r#i#p#t #c#s#s #h#t#m#l#"
// 在空格后的位置插入“#”
'javascript css html'.replace(/(?<=\s)/g,'#'); // "javascript #css #html"
// 在非空格后的位置插入“#”
'javascript css html'.replace(/(?<!\s)/g,'#'); // "#j#a#v#a#s#c#r#i#p#t# c#s#s# h#t#m#l#"
例子2:/Jack(?=Sprat\|Frost)/ “Jack”后跟有“Sprat”或“Frost”的情况下才会得到匹配,匹配结果不包括“Sprat”或“Frost”。
'JackFrost'.match(/Jack(?=Sprat|Frost)/g); // ["Jack"]
例子3:对于/\d+(?!.)/,数字后没有跟随小数点的情况下才会得到匹配,匹配结果是“141”而不是“3”
/\d+(?!.)/.exec(3.141)
// ["141", index: 2, input: "3.141", groups: undefined]
例子4:结合前面所学,我们可以完成数字千分位分隔,比如把123456789变成123,456,789。这个例子稍微有点复杂,我们可以分为3步完成:
- 弄出最后一个逗号:找到倒数第三个数字前面的位置
/(?=(\d{3})$)/g,然后用replace()方法插入逗号
'123456789'.replace(/(?=(\d{3})$)/g,','); // "123456,789"
- 弄出所有逗号:用我们上面学的量词
+
'123456789'.replace(/(?=(\d{3})+$)/g,','); // ",123,456,789"
- 处理特殊情况。从上面可以看到当数字个数刚好是3的倍数的时候,数字开头也会加上逗号,这个时候就要再单独处理这些特殊情况了,我们想要插入逗号的位置不能是开头,马上就想到了
(?!^),所以完整的写法是:
'123456789'.replace(/(?!^)(?=(\d{3})+$)/g,','); // "123,456,789"
圆括号的作用
| 字符 | 含义 | (x) | 捕获组:匹配x并将括号内的正则表达式定义为一个子表达式,供后面反向引用使用或者获取子表达式匹配结果。使用结果元素的索引 ([1], ..., [n]) 或从预定义的 RegExp 对象的属性 ($1, ..., $9)来获取。 捕获组会带来性能损失,如果你不需要存储匹配项或者你的括号只是分组作用,可以选择下面的非捕获组。 | (?:x) | 非捕获组:匹配x并且不定义子表达式,只用括号最原始的功能 | \n | 反向引用:n是一个正整数,引用之前出现的分组,\1表示正则中与第一个左括号相匹配的子表达式 | (?<Name>x) | 具名捕获组:匹配x并将其存储在返回的匹配项的groups属性中 |
|---|
正则表达式中的圆括号有多种作用,下面会详细介绍这些作用。
1.分组
正则中的括号可以将单独的项进行分组,即将括号里的内容当作是一个整体。
例子1:/(ab|cd)+|ef/,把(ab|cd)当做一个整体作用于+,(ab|cd)+的意思是字符串“ab”或者“cd”可以重复出现一次或者多次。
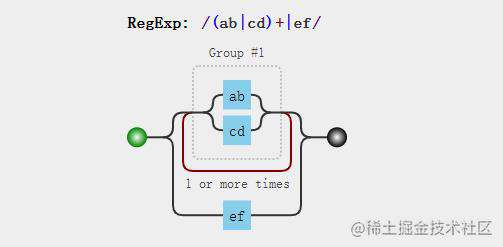
const regExp = /(ab|cd)+|ef/;
regExp.test('abab'); // true
regExp.test('cdef'); // true
regExp.test('acf'); // false
2.定义子表达式
当一个正则表达式和字符串匹配的时候,可以从字符串中抽离出和圆括号的子表达式相匹配的字符串子串。
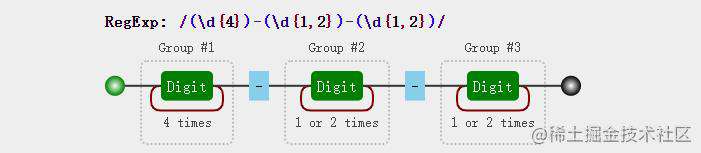
例子1:我们可以抽取日期中的年月日,分别将匹配年月日的子表达式用圆括号包裹起来
const regExp = /(\d{4})-(\d{1,2})-(\d{1,2})/
"2021-1-20".match(regExp);
// ["2021-1-20", "2021", "1", "20", index: 0, input: "2021-1-20", groups: undefined]
例子2:我们也可以通过RegExp的全局属性的$1-$9来获取我们子表达式匹配的结果
const regExp = /(\d{4})-(\d{1,2})-(\d{1,2})/
regExp.test("2021-1-20");
console.log(RegExp.$1); // 2021
console.log(RegExp.$2); // 1
console.log(RegExp.$3); // 20
例子3:结合上面的例子,我们可以使用字符串的replace方法转化日期格式,比如将“2021-1-20”变成“2021/1/20”的形式
const regExp = /(\d{4})-(\d{1,2})-(\d{1,2})/
"2021-1-20".replace(regExp,"$1/$2/$3"); // "2021/1/20"
3.引用
圆括号另一个作用是允许同一个正则表达式的后部引用前面的子表达式。
例子1:我们知道日期有多种格式,可能是“2021-1-20”,也可能是“2021/1/20”或者“2021.1.20”,现在我们要实现一个正则表达式能匹配这三种形式的日期,可以发现年月日的分隔符要一致,我们实现的正则表达式不应该匹配“2021-1/20”这种形式
const regExp = /\d{4}(-|\/|\.)\d{1,2}\1\d{1,2}/
regExp.test("2021-1-20"); // true
regExp.test("2021/1/20"); // true
regExp.test("2021.1.20"); // true
regExp.test("2021-1/20"); // false
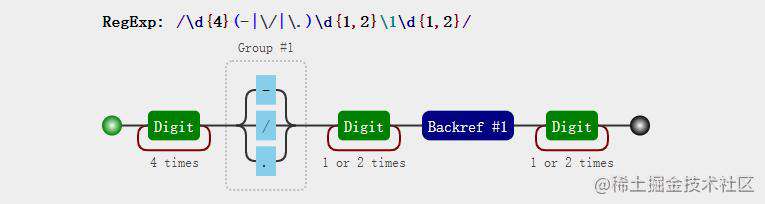
上面的正则表达式中\1指代的其实就是-|\/|\.,所以上面的正则表达式也等价于/\d{4}(-|\/|\.)\d{1,2}(-|\/|\.)\d{1,2}/。
\1指的是第一个括号的位置,第二个括号包裹的内容可以用\2代替,以此类推。如果出现括号嵌套也是如此,只是第一个括号的位置指的是左括号的位置。
例子2:为了更好的理解圆括号的作用,我们再举个圆括号嵌套的例子
const regExp = /^(((\d)\d)(\d))(\d)\1\2\3\4\5$/;
regExp.test('123412312134'); // true
console.log( RegExp.$1 ); // 123
console.log( RegExp.$2 ); // 12
console.log( RegExp.$3 ); // 1
console.log( RegExp.$4 ); // 3
console.log( RegExp.$5 ); // 4

修饰符
正则表达式有六个可选参数 (flags) 允许全局和不分大小写搜索等。这些参数既可以单独使用也能以任意顺序一起使用, 并且被包含在正则表达式实例中。
| 字符 | 含义 | i | 不区分大小写 | g | 全局匹配,查找所有的匹配项,没有g修饰符的话匹配到第一个就停止了 | m | 多行匹配模式,^/$匹配一行或者字符串的开头/结尾 | s | 允许 . 匹配换行符 | u | 使用unicode码的模式进行匹配。 | y | 执行“粘性(sticky)”搜索,匹配从目标字符串的当前位置开始。 |
|---|
例子1:匹配字符串不区分大小写
const regExp = /html/i;
regExp.test("html"); // true
regExp.test("HTML"); // true
regExp.test("Html"); // true
例子2:把字符串匹配的文本换成'text'
// 无g修饰符
const regExp = /html|css/;
"javascript html css".replace(regExp,'text'); // "javascript text css"
// 有g修饰符
const regExp = /html|css/g;
"javascript html css".replace(regExp,'text'); // "javascript text text"
例子3:在多行模式下,每行的开头结尾处插入字符'#'(字符串中的\n是换行符)
// 无m修饰符
const regExp = /^|$/g;
"javascript\nhtml\ncss".replace(regExp,'#'); // "#javascript\nhtml\ncss#"
// 有m修饰符
const regExp = /^|$/mg;
"javascript\nhtml\ncss".replace(regExp,'#'); // "#javascript#\n#html#\n#css#"
处理正则的String方法
正则表达式是强大、便捷、高效的文本处理工具,使用正则,你可以对文本进行修改、删除等等操作,但这常常要借助js中的一些方法来实现,下面我们把经常用来处理正则的几个方法详细介绍一下。
字符串上有4个常用的方法,它们的名字分别是search、replace、match和split,通常正则表达式是作为参数传递进去。
1. search()
执行正则表达式和String对象之间的一个搜索匹配。
语法:str.search(regexp)
参数:regexp是一个正则表达式对象;如果传入一个非正则表达式对象,则会使用new RegExp(regexp)隐式地将其转换为正则表达式对象
返回值:匹配成功则返回匹配结果在字符串中的索引;否则返回-1
例子1:
const regExp = /script/i;
"JavaScript".search(regExp); // 4
"I Love Java".search(regExp); // -1
2. replace()
替换字符串中的文本。
语法:str.replace(regexp|substr, newSubStr|function)
参数:
regexp是一个正则表达式对象或者其字面量,其匹配的字符串会被第二个参数的返回值替换;substr是字符串,直接搜索该字符串,第一个匹配项会被替换;newSubStr用于替换匹配文本的字符串,如果该字符串出现了下面这些特殊字符,有特殊的含义:
| 字符 | 含义 | $$ | 插入一个 "$" | $& | 插入匹配的子串 | $` | 插入当前匹配的子串左边的内容 | $' | 插入当前匹配的子串右边的内容 | $n | 假如第一个参数是 RegExp对象,并且 n 是个小于100的非负整数,那么插入第 n 个子表达式匹配的字符串。如果不存在第 n个分组,那么将会把匹配到到内容替换为字面量。比如不存在第3个分组,就会用“$3”替换匹配到的内容。 |
|---|
function是函数,这个函数将在每个匹配结果上调用,他返回的字符串则将作为替换文本;该函数的第一个参数是匹配该模式的字符串,接下来的参数是子表达式匹配的字符串,可能有0个或多个,后面的参数index是匹配的位置,input是字符串本身。
返回值:一个部分或全部匹配由替代模式所取代的新的字符串
例子1:把文本中的所有javascript(不区分大小写)换成JavaScript
const text = "I love javascript, and I am learning javaScript.";
const regExp = /javascript/ig;
text.replace(regExp, "JavaScript");
// I love JavaScript, and I am learning JavaScript.
例子2:现在我们再来看前面日期那个例子就更容易理解了,用replace方法转化日期格式,比如将“2021-1-20”变成“2021/1/20”的形式
const regExp = /(\d{4})-(\d{1,2})-(\d{1,2})/
"2021-1-20".replace(regExp,"$1/$2/$3"); // "2021/1/20"
例子3:我们经常会遇到驼峰转“-”写法,比如把字符串“helloWorld”转换成“hello-world”,可以用下面的这种方法实现
function formatStr(str) {
return str.replace(/[A-Z]/g, (match)=>{
return '-' + match.toLowerCase();
});
}
formatStr("helloWorld"); // "hello-world"
3. match()
字符串匹配,返回匹配结果。
语法:str.match(regexp)
参数:regexp是一个正则表达式对象;如果传入一个非正则表达式对象,则会使用new RegExp(regexp)隐式地将其转换为正则表达式对象;如果没有传参数,则返回[""]
返回值:
- 如果使用
g修饰符,则将返回与完整正则表达式匹配的所有结果的一个数组。 - 如果未使用
g修饰符,则数组第一个元素是匹配的字符串,余下的元素是圆括号括起来的子表达式,此外还有三个属性:index属性指明了匹配文本在string中的开始位置,input则是对该string本身的引用,groups:一个捕获组数组或者 undefined(如果没有定义命名捕获组)
例子1:从字符串中提取时间
const regExp = /(\d{4})-(\d{1,2})-(\d{1,2})/
"date:2021-1-20".match(regExp);
// ["2021-1-20", "2021", "1", "20", index: 5, input: "date:2021-1-20", groups: undefined]
例子2:有g修饰符,返回所有的匹配结果
const regExp = /\d{1,4}/g
"date:2021-1-20".match(regExp); // ["2021", "1", "20"]
4. split()
将字符串分割为数组。普通的用法在这里就不介绍了,只介绍下参数为正则的用法。
语法:str.split(separator,limit)
参数:
separator:指定表示每个拆分应发生的点的字符串。limit:一个整数,限定返回的分割片段数量。
返回值:返回源字符串以分隔符出现位置分隔而成的一个新数组。
例子1:分割字符串获取名字数组
const names = "Harry Trump ;Fred Barney; Helen Rigby ; Bill Abel ;Chris Hand ";
const regExp = /\s*(?:;|$)\s*/;
const nameList = names.split(regExp);
console.log(nameList);
// ["Harry Trump", "Fred Barney", "Helen Rigby", "Bill Abel", "Chris Hand", ""]
const nameList2 = names.split(regExp, 4);
console.log(nameList2);
// ["Harry Trump", "Fred Barney", "Helen Rigby", "Bill Abel"]
处理正则的RegExp方法
在介绍RegExp方法之前,先介绍下RegExp对象下面这些属性:
source:正则表达式的文本global:只读的布尔值,是否有修饰符gignoreCase:只读的布尔值,是否有修饰符imultiline:只读的布尔值,是否有修饰符msticky:只读的布尔值,是否有修饰符yunicode:只读的布尔值,是否有修饰符ulastIndex:可读可写的整数,如果匹配模式带有g修饰符,这个属性存储匹配成功的位置,也是下一次检索的开始位置,这个属性会被exec()和test()方法用到
前六个属性用法都比较简单,这里我们要特别注意的是lastIndex属性。正则表达式的lastIndex属性值只作为exec和test方法的起始搜索位置,并且仅当正则表达式带有g修饰符的时候。
1. exec()
与上面介绍的String方法match()相似,只不过参数变成了字符串,无论正则表达式有没有g修饰符函数返回值都是一样的。
语法:regexObj.exec(str)
参数:str要匹配的字符串
返回值:如果匹配成功,exec() 方法返回一个数组(包含属性 index 和 input ),并更新正则表达式对象的 lastIndex 属性。完全匹配成功的文本将作为返回数组的第一项,从第二项起,后续每项都对应正则表达式内和子表达式匹配成功的文本。
例子1:
const regExp = /(\d{4})-(\d{1,2})-(\d{1,2})/
regExp.exec("2021-1-20")
// ["2021-1-20", "2021", "1", "20", index: 0, input: "2021-1-20", groups: undefined]
例子2:当正则表达式使用 "g" 标志时,可以多次执行 exec 方法来查找同一个字符串中的成功匹配。当你这样做时,查找将从正则表达式的 lastIndex属性指定的位置开始。
const myRe = /ab*/g;
const str = 'abbcdefabh';
let myArray = myRe.exec(str);
while (myArray !== null) {
console.log(myArray, myRe.lastIndex);
myArray = myRe.exec(str);
}
// ["abb", index: 0, input: "abbcdefabh", groups: undefined] 3
// ["ab", index: 7, input: "abbcdefabh", groups: undefined] 9
2. test()
test方法的用法就简单多了,用来查看正则表达式与字符串是否匹配。
语法:regexObj.test(str)
参数:str用来与正则表达式匹配的字符串
返回值:如果正则表达式与指定的字符串匹配 ,返回true;否则false。
例子1:
var regex = /foo/g;
// regex.lastIndex为 0
regex.test('foo'); // true
// 执行完上一句,regex.lastIndex现在变成了 3,所以下面的匹配结果是false
regex.test('foo'); // false
更多关于RegExp对象的内容,可以查阅RegExp(正则表达式)
参考
- JS正则表达式完整教程(略长):老姚总结的这篇通俗易懂,举的例子也恰到好处
- JavaScript权威指南(第6版)(中文版):第10章是讲正则的,可谓是“浓缩的精华”
- 正则表达式:MDN上的正则,具有权威性
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!