诞生原由
在了解 HTTP/2 之前,我们先了解一下它为什么会被实现出来?
在之前的 HTTP 1.1 中,我们发起一个请求的过程如下所示:浏览器请求 URL -> 域名解析 -> 建立 TCP 连接 -> 服务器处理接收文件 -> 返回数据文件 -> 浏览器接收数据文件并且解析渲染。
这一套执行流程最大的问题就是,每一个请求,都将创建一个 TCP 连接,这个代价对于性能来说无疑是昂贵的。
我们可以先来看一张网图来快速了解一下:
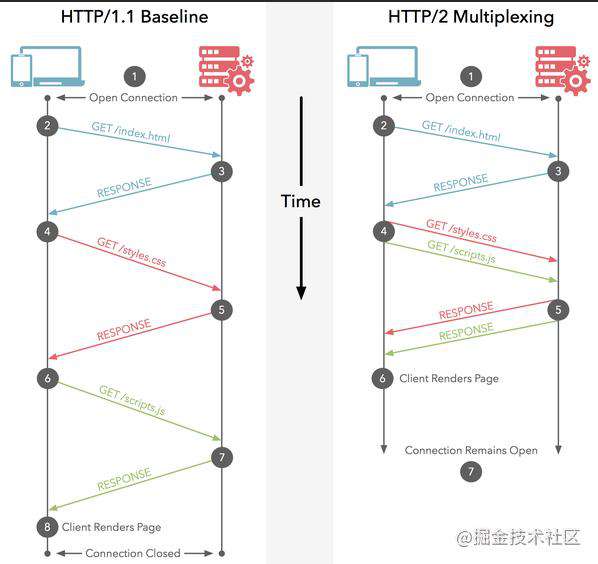
HTTP 1.1 - Keep-Alive
我们期待着第一次建立请求通道后,在一定的时间范围内不要关闭,那么我们后续的请求会继续走这个通道,完成请求响应,这无疑减少了重新建立 TCP 连接的时间,从而提升性能。
所以,HTTP 1.1 提供了 Keep-Alive 属性,来满足我们这个期望。
而这个时间范围,其实服务端或者代理中间件都是可以配置的。
那么这个属性是否完美解决了流程上的问题呢?
答案是否定的!
因为 HTTP 1.1 中,就算使用了 Keep-Alive 属性,那么也会引发两个问题:
- HTTP 1.1 数据传输形式是串行的文本形式,所以文件内容必须按顺序来传输,不能并行传输,否则服务端无法还原内容顺序,从而发生数据错误。
- 当多用户请求的总数达到了服务端的并发限制,后面用户的请求就会被挂起等待。
基于以上两点,其实 Keep-Alive 还是不够用,并且浏览器为了控制资源,一般最多允许单个域名同时存在 6-8 个 TCP 的连接通道,所以此刻就轮到 HTTP/2 闪亮登场了。
HTTP/2 - 多路复用
基于 HTTP 1.1 所暴露出的问题,HTTP/2 实现了多路复用,以此来替代 HTTP 1.1 中的阻塞机制。
多路复用,其实就是引入了二进制分帧和流这两个概念。
请求或响应,其实都可以看做是一个消息,而一个消息可能由一个或多个帧组成,帧负责对数据内容进行标号,传输到服务端后,再根据标号来对数据内容进行整合,因为可以乱序传输,所以我们就可以来并发传输数据内容,所以我们用到了流。
实现同一个域名下的所有请求,都可以走一个 TCP 通道,无论有多少双向的数据流通过都可以承载。
注意事项
由于我们使用了 HTTP/2 ,所以之前有的资源优化就可以省略了,否则就是适得其反,例如以下两点:
- 多文件合并,减少资源请求数量
虽然我们减少了资源请求的数量,但是我们资源文件变大了,客户端缓存资源文件后,当某个板块修改了一句代码,那么客户端不得不将整个资源文件重新下载缓存,但是我们其他板块的代码未发生变化,这种做法现在看来其实是不合理的。
- 多域名资源
当客户端需要请求很多资源时,为了避开浏览器同域名同时只能建立 6-8 个 TCP 连接的限制,我们会将资源文件放在不同的域名上,以此来让浏览器同时下载资源。但是这样做,会增加服务器的压力,并且解析 DNS 的时间也会累加,反而性能变得低下。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!