对于“为什么要进行依赖预构建?"这个问题vite文档已经解释的很清楚了,那么预构建大概的流程是什么样的呢?
启动预构建
从文档中我们知道在服务启动前会进行预构建,对应源码位置在src/node/server/index.ts,预构建的函数名是optimizeDeps
开始预构建
函数optimizeDeps定义在src/node/optimizer/index.ts,其主要流程可分为以下几步:
- 判断是否需要预构建,如果之前预构建的内容还可以用,那么直接
return,反之继续往下执行。需要说明的是判断预构建的内容是否可用的依据是package.lock.json和部分vite配置的内容,具体实现在getDepHash函数中。
- 使用esbuild解析整个项目,获取本次需要进行预构建的依赖和解析出问题的依赖,分别赋值给
deps和missing,其主要执行过程在函数scanImports中(这部分的代码实现过程梳理放在本部分最后)。
- 正式预构建前的一系列的处理
- 如果
missing有值,则报错,就是我们在控制台看到的The following dependencies are imported but could not be resolved.... Are they installed - 把配置项
config.optimizeDeps?.include里的依赖加入到deps中,如果处理失败的话也会在控制台报错 - 如果
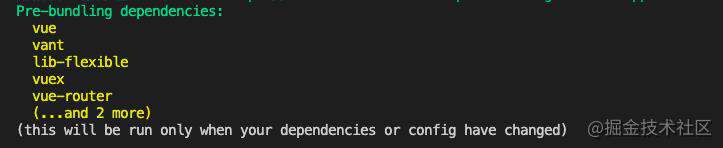
deps为空的话,说明不需要预构建,更新预构建内容的hash值后直接return - 执行到这说明本次需要进行预构建,在控制台提示本次预构建的依赖,如下图所示
- 如果
 4. 进一步处理
4. 进一步处理deps得到flatIdDeps,主要是因为默认esbuild打包的话对于依赖的分析、映射的处理可能比较麻烦,这里主要做了两方面的工作
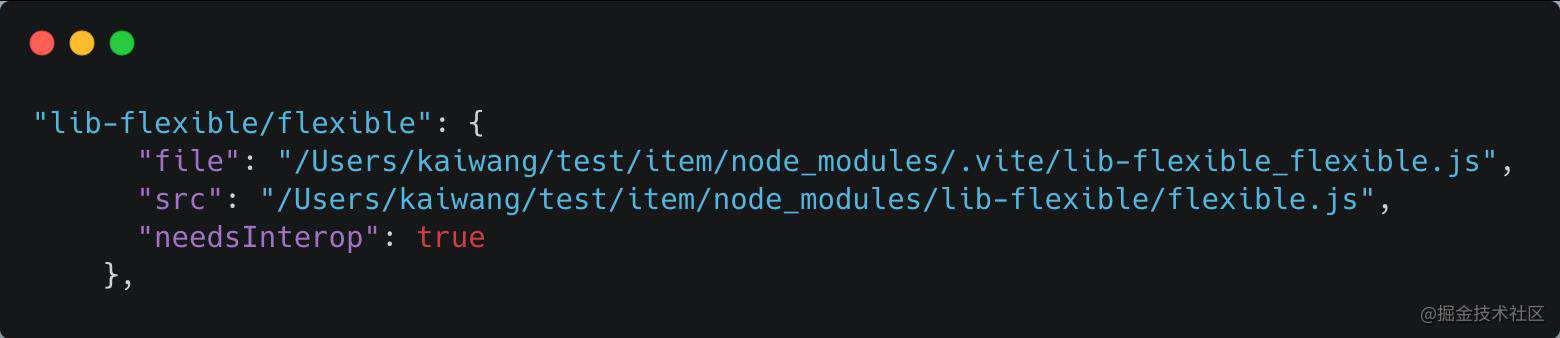
- 使用esbuild对
deps每个依赖进行构建并默认输出到node_modules/.vite中
- 把此次预构建的信息更新并写入文件
node_modules/.vite/_metadata.json,完成预构建!
scanImports
”具体哪些依赖是需要预构建的?“是函数scanImports处理的,在src/node/optimizer/scan.ts中,其过程比较简单,大概分为两步:
由上可以看出,deps和missing是在esbuild插件esbuildScanPlugin中得到的,那么这个插件是怎么做的呢?
esbuildScanPlugin
还是在src/node/optimizer/scan.ts中,该插件主要做了以下两件事:
- 处理导入模块(依赖),在
build.onResolve中,具体:
由上可知模块(依赖)是否放在deps、missing里、放的话放在哪一个都是由函数resolve决定的,从代码中可以看到resolve的执行逻辑如下:
由于我对于这一段的处理逻辑不是很清楚,这里只能简单的理解为:
这里就把预构建需要的deps和missing收集到了。
- 处理文件内容,在
build.onLoad中,具体:
预构建的结果
预构建的结果都放在了node_modules/.vite/中,一般如下图所示,包括两方面的信息:
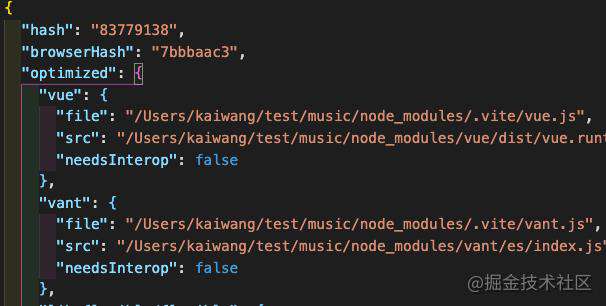
_metadata.json,是本次预构建产生的一些“版本”和依赖包的信息,如下图所示:
xx.js, xxx.js.map各个依赖包的打包结果
END
预构建部分的代码实现大概就是这样,文章同步放在了vite源码阅读中,关于vite源码相关的学习都会记录在这里,欢迎大家讨论交流,感谢各位?
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?




发表评论
还没有评论,快来抢沙发吧!