一、写在前面
相信各位小伙伴在实际做业务的时候都遇到过「大文件上传」的场景。在这种场景下,我们不能直接将大文件直接丢给服务器进行处理,这会对服务器的性能产生巨大的影响,并且上传速度也过于缓慢。因此我们会采用「大文件分片上传」的技术方案,尽可能快地上传文件,并对服务器的性能产生尽可能小的影响。
刚好最近趁着业余时间,详细了解了下「大文件分片上传」的技术细节,发现已有的一些分片上传库的使用体验都不太好,因此在这里从零开始手写一个大文件分片上传库,一是加深理解,二是方便大家后续直接使用。
二、大文件分片上传技术方案
一般来说大文件分片上传主要有以下几个步骤:
1、前端计算文件md5。计算文件的md5是为了检查上传到服务器的文件是否与用户所传的文件一致,同时也可以根据md5进行「秒传」等操作。
2、前端发送初始化请求,后端初始化上传。当计算好文件的md5后,就可以进入初始化上传的步骤,在这一步骤中,前端会发起初始化请求,包含这个文件计算的md5、文件名等信息,而后端则会根据md5初始化接收分片文件的目录。
3、前端进行文件分片,并将分片传输给后端。这个步骤自不必多说,前端会将文件分成多个小块,并按照一定的策略进行上传,如果遇到上传失败的分片,需要重新上传。
4、前端发送结束上传请求,后端合并分片。当发送成功所有的文件分片后,前端会发起结束上传请求,后端收到请求后,会将已有的文件分片合并,生成文件,并确认生成的文件的md5是否与初始化传入的md5一致。
值得注意的是,当文件比较大时,直接根据文件「计算md5」、「进行文件分片」、「合并文件」都是十分消耗内存的(甚至可能直接把内存吃满),因此在这三个步骤,需要使用管道来减小内存上的消耗。
三、easy-file-uploader
先贴一下我用Typescript写的「开箱即用的大文件分片上传库」的地址吧:easy-file-uploader
具体使用方式可以直接点击上述地址,查看README.md。
那么话不多说,让我们来看看这个库我具体是怎么实现的。
四、easy-file-uploader-server实现过程
从刚才「大文件分片上传技术方案」中,我们可以明确后端首先要提供以下几个最基础的能力:
1、初始化文件上传 2、接收文件分片 3、合并文件分片
其次,为了使用体验,我们还需要提供如下附加能力:
4、获取已上传的分片信息 5、清理分片存储目录(用于取消上传)
因此,我们首先要写一个FileUploaderServer类,提供上述这些能力。这样,当开发者在使用easy-file-uploader-server的时候,只需要实例化FileUploaderServer类,并在接口中使用这个类提供的方法即可。
这样做是为了提供了更好的可拓展性——毕竟,开发者可能用express/koa/原生nodejs等框架实现接口,如果我们挨个实现一遍。。。太不利于维护了。
那么我们能很快地写出来这个类的大框架,它大概长这样:
interface IFileUploaderOptions {
tempFileLocation: string; // 分片存储路径
mergedFileLocation: string; // 合并后的文件路径
}
class FileUploaderServer {
private fileUploaderOptions: IFileUploaderOptions;
/**
* 初始化文件分片上传,实际上就是根据fileName和时间计算一个md5,并新建一个文件夹
* @param fileName 文件名
* @returns 上传Id
*/
public async initFilePartUpload(fileName: string): Promise<string> {}
/**
* 上传分片,实际上是将partFile写入uploadId对应的文件夹中,写入的文件命名格式为`partIndex|md5`
* @param uploadId 上传Id
* @param partIndex 分片序号
* @param partFile 分片内容
* @returns 分片md5
*/
public async uploadPartFile(
uploadId: string,
partIndex: number,
partFile: Buffer,
): Promise<string> {}
/**
* 获取已上传的分片信息,实际上就是读取这个文件夹下面的内容
* @param uploadId 上传Id
* @returns 已上传的分片信息
*/
public async listUploadedPartFile(
uploadId: string,
): Promise<IUploadPartInfo[]> {}
/**
* 取消文件上传,硬删除会直接删除文件夹,软删除会给文件夹改个名字
* @param uploadId 上传Id
* @param deleteFolder 是否直接删除文件夹
*/
async cancelFilePartUpload(
uploadId: string,
deleteFolder: boolean = false,
): Promise<void> {}
/**
* 完成分片上传,实际上就是将所有分片都读到一起,然后进行md5检查,最后存到一个新的路径下。
* @param uploadId 上传Id
* @param fileName 文件名
* @param md5 文件md5
* @returns 文件存储路径
*/
async finishFilePartUpload(
uploadId: string,
fileName: string,
md5: string,
): Promise<IMergedFileInfo> {}
}
4-1、初始化文件上传
在初始化上传的时候,我们要在tempFileLocation目录(也就是分片存储目录)下根据md5新建一个目录,用于保存上传的分片。这个目录名就是uploadId,是根据${fileName}-${Date.now()}计算的md5值。
/**
* 初始化文件分片上传,实际上就是根据fileName和时间计算一个md5,并新建一个文件夹
* @param fileName 文件名
* @returns 上传Id
*/
public async initFilePartUpload(fileName: string): Promise<string> {
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadId = calculateMd5(`${fileName}-${Date.now()}`);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (uploadFolderExist) {
throw new FolderExistException(
'found same upload folder, maybe you meet hash collision',
);
}
await fse.mkdir(uploadFolderPath);
return uploadId;
}
4-2、接收文件分片
在接收文件分片的时候,我们首先会获取分片存储位置,然后计算分片的md5,然后将分片命名为${partIndex}|${partFileMd5}.part,存储到对应路径下。
/**
* 上传分片,实际上是将partFile写入uploadId对应的文件夹中,写入的文件命名格式为`partIndex|md5`
* @param uploadId 上传Id
* @param partIndex 分片序号
* @param partFile 分片内容
* @returns 分片md5
*/
public async uploadPartFile(
uploadId: string,
partIndex: number,
partFile: Buffer,
): Promise<string> {
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (!uploadFolderExist) {
throw new NotFoundException('not found upload folder');
}
const partFileMd5 = calculateMd5(partFile);
const partFileLocation = path.join(
uploadFolderPath,
`${partIndex}|${partFileMd5}.part`,
);
await fse.writeFile(partFileLocation, partFile);
return partFileMd5;
}
4-3、合并文件分片
在合并文件分片时,最重要的就是下面这个mergePartFile方法,这个方法会使用readStream和writeStream来读取/写入文件分片,这样做的好处是能尽可能地减少内存占用。同时,使用MultiStream提供的pipe方法,来保证stream的顺序。
export async function mergePartFile(
files: IFileInfo[],
mergedFilePath: string,
): Promise<void> {
const fileList = files.map((item) => {
const [index] = item.name.replace(/\.part$/, '').split('|');
return {
index: parseInt(index),
path: item.path,
};
});
const sortedFileList = fileList.sort((a, b) => {
return a.index - b.index;
});
const sortedFilePathList = sortedFileList.map((item) => item.path);
merge(sortedFilePathList, mergedFilePath);
}
function merge(inputPathList: string[], outputPath: string) {
const fd = fse.openSync(outputPath, 'w+');
const writeStream = fse.createWriteStream(outputPath);
const readStreamList = inputPathList.map((path) => {
return fse.createReadStream(path);
});
return new Promise((resolve, reject) => {
const multiStream = new MultiStream(readStreamList);
multiStream.pipe(writeStream);
multiStream.on('end', () => {
fse.closeSync(fd);
resolve(true);
});
multiStream.on('error', () => {
fse.closeSync(fd);
reject(false);
});
});
}
那么有了mergePartFile方法后,合并文件分片的finishFilePartUpload方法也就呼之欲出了,在mergePartFile的基础上,增加文件保存路径的获取以及md5的校验即可。
/**
* 完成分片上传,实际上就是将所有分片都读到一起,然后进行md5检查,最后存到一个新的路径下。
* @param uploadId 上传Id
* @param fileName 文件名
* @param md5 文件md5
* @returns 文件存储路径
*/
async finishFilePartUpload(
uploadId: string,
fileName: string,
md5: string,
): Promise<IMergedFileInfo> {
const { mergedFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(mergedFileLocation);
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (!uploadFolderExist) {
throw new NotFoundException('not found upload folder');
}
const dirList = await listDir(uploadFolderPath);
const files = dirList.filter((item) => item.path.endsWith('.part'));
const mergedFileDirLocation = path.join(mergedFileLocation, md5);
await fse.ensureDir(mergedFileDirLocation);
const mergedFilePath = path.join(mergedFileDirLocation, fileName);
await mergePartFile(files, mergedFilePath);
await wait(1000); // 要等待一段时间,否则在计算md5时会读取到空文件
const mergedFileMd5 = await calculateFileMd5(mergedFilePath);
if (mergedFileMd5 !== md5) {
throw new Md5Exception('md5 checked failed');
}
return {
path: mergedFilePath,
md5,
};
}
4-4、获取已上传的分片信息
获取已上传的分片信息实际上就是读取uploadId目录下所有后缀为part的分片文件,逻辑很简单,看代码就行。
/**
* 获取已上传的分片信息,实际上就是读取这个文件夹下面的内容
* @param uploadId 上传Id
* @returns 已上传的分片信息
*/
public async listUploadedPartFile(
uploadId: string,
): Promise<IUploadPartInfo[]> {
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (!uploadFolderExist) {
throw new NotFoundException('not found upload folder');
}
const dirList = await listDir(uploadFolderPath);
const uploadPartInfo = dirList.map((item: IFileInfo) => {
const [index, md5] = item.name.replace(/\.part$/, '').split('|');
return {
path: item.path,
index: parseInt(index),
md5,
};
});
return uploadPartInfo;
}
function listDir(path: string): Promise<IFileInfo[]> {
const items = await fse.readdir(path);
return Promise.all(
items
.filter((item: string) => !item.startsWith('.'))
.map(async (item: string) => {
return {
name: item,
path: `${path}/${item}`,
};
}),
);
}
4-5、清理分片存储目录
清理分片存储目录实际上也很简单,如果是软删除,则直接为目录改个名字即可。如果是硬删除,那么就删掉这个目录。
/**
* 取消文件上传,硬删除会直接删除文件夹,软删除会给文件夹改个名字
* @param uploadId 上传Id
* @param deleteFolder 是否直接删除文件夹
*/
async cancelFilePartUpload(
uploadId: string,
deleteFolder: boolean = false,
): Promise<void> {
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (!uploadFolderExist) {
throw new NotFoundException('not found upload folder');
}
if (deleteFolder) {
await fse.remove(uploadFolderPath);
} else {
await fse.rename(uploadFolderPath, `${uploadFolderPath}[removed]`);
}
}
4-6、详细代码
那么把上述代码整合到一起,FileUploaderServer类就完成了。更详细的代码可通过上面的github地址去查看:点击这里
import * as path from 'path';
import * as fse from 'fs-extra';
import {
calculateFileMd5,
calculateMd5,
IFileInfo,
listDir,
mergePartFile,
wait,
} from './util';
import {
FolderExistException,
Md5Exception,
NotFoundException,
} from './exception';
const DEAFULT_TEMP_FILE_LOCATION = path.join(__dirname, './upload_file');
const DEAFULT_MERGED_FILE_LOCATION = path.join(__dirname, './merged_file');
const DEFAULT_OPTIONS = {
tempFileLocation: DEAFULT_TEMP_FILE_LOCATION,
mergedFileLocation: DEAFULT_MERGED_FILE_LOCATION,
};
export interface IFileUploaderOptions {
tempFileLocation: string;
mergedFileLocation: string;
}
export interface IUploadPartInfo {
path: string;
index: number;
md5: string;
}
export interface IMergedFileInfo {
path: string;
md5: string;
}
export class FileUploaderServer {
private fileUploaderOptions: IFileUploaderOptions;
constructor(options: IFileUploaderOptions) {
this.fileUploaderOptions = Object.assign(DEFAULT_OPTIONS, options);
}
public getOptions() {
return this.fileUploaderOptions;
}
/**
* 初始化文件分片上传,实际上就是根据fileName和时间计算一个md5,并新建一个文件夹
* @param fileName 文件名
* @returns 上传Id
*/
public async initFilePartUpload(fileName: string): Promise<string> {
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadId = calculateMd5(`${fileName}-${Date.now()}`);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (uploadFolderExist) {
throw new FolderExistException(
'found same upload folder, maybe you meet hash collision',
);
}
await fse.mkdir(uploadFolderPath);
return uploadId;
}
/**
* 上传分片,实际上是将partFile写入uploadId对应的文件夹中,写入的文件命名格式为`partIndex|md5`
* @param uploadId 上传Id
* @param partIndex 分片序号
* @param partFile 分片内容
* @returns 分片md5
*/
public async uploadPartFile(
uploadId: string,
partIndex: number,
partFile: Buffer,
): Promise<string> {
const uploadFolderPath = await this.getUploadFolder(uploadId);
const partFileMd5 = calculateMd5(partFile);
const partFileLocation = path.join(
uploadFolderPath,
`${partIndex}|${partFileMd5}.part`,
);
await fse.writeFile(partFileLocation, partFile);
return partFileMd5;
}
/**
* 获取已上传的分片信息,实际上就是读取这个文件夹下面的内容
* @param uploadId 上传Id
* @returns 已上传的分片信息
*/
public async listUploadedPartFile(
uploadId: string,
): Promise<IUploadPartInfo[]> {
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (!uploadFolderExist) {
throw new NotFoundException('not found upload folder');
}
const dirList = await listDir(uploadFolderPath);
const uploadPartInfo = dirList.map((item: IFileInfo) => {
const [index, md5] = item.name.replace(/\.part$/, '').split('|');
return {
path: item.path,
index: parseInt(index),
md5,
};
});
return uploadPartInfo;
}
/**
* 取消文件上传,硬删除会直接删除文件夹,软删除会给文件夹改个名字
* @param uploadId 上传Id
* @param deleteFolder 是否直接删除文件夹
*/
async cancelFilePartUpload(
uploadId: string,
deleteFolder: boolean = false,
): Promise<void> {
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (!uploadFolderExist) {
throw new NotFoundException('not found upload folder');
}
if (deleteFolder) {
await fse.remove(uploadFolderPath);
} else {
await fse.rename(uploadFolderPath, `${uploadFolderPath}[removed]`);
}
}
/**
* 完成分片上传,实际上就是将所有分片都读到一起,然后进行md5检查,最后存到一个新的路径下。
* @param uploadId 上传Id
* @param fileName 文件名
* @param md5 文件md5
* @returns 文件存储路径
*/
async finishFilePartUpload(
uploadId: string,
fileName: string,
md5: string,
): Promise<IMergedFileInfo> {
const { mergedFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(mergedFileLocation);
const uploadFolderPath = await this.getUploadFolder(uploadId);
const dirList = await listDir(uploadFolderPath);
const files = dirList.filter((item) => item.path.endsWith('.part'));
const mergedFileDirLocation = path.join(mergedFileLocation, md5);
await fse.ensureDir(mergedFileDirLocation);
const mergedFilePath = path.join(mergedFileDirLocation, fileName);
await mergePartFile(files, mergedFilePath);
await wait(1000); // 要等待一段时间,否则在计算md5时会读取到空文件
const mergedFileMd5 = await calculateFileMd5(mergedFilePath);
if (mergedFileMd5 !== md5) {
throw new Md5Exception('md5 checked failed');
}
return {
path: mergedFilePath,
md5,
};
}
/**
* 获取上传文件夹的路径
* @param uploadId 上传Id
* @returns 文件夹路径
*/
private async getUploadFolder(uploadId: string): Promise<string> {
const { tempFileLocation } = this.fileUploaderOptions;
await fse.ensureDir(tempFileLocation);
const uploadFolderPath = path.join(tempFileLocation, uploadId);
const uploadFolderExist = fse.existsSync(uploadFolderPath);
if (!uploadFolderExist) {
throw new NotFoundException('not found upload folder');
}
return uploadFolderPath;
}
}
五、easy-file-uploader-client实现过程
写完了后端逻辑,我们就可以开始写前端逻辑了。
就像上面说的,为了满足开发者对于扩展性的需要,easy-file-uploader-server提供的是「大文件分片上传」的能力,而不是直接提供「大文件分片上传」的接口。这就导致在设计easy-file-uploader-client时,不能直接发起请求。因此,easy-file-uploader-client在设计功能之初,就只预期提供对分片上传流程的把控,而不会对具体上传函数进行实现。
那么按照这个思路,easy-file-uploader-client需要提供如下基础能力:
1、文件md5计算及分片 2、支持用户自定义上传函数,并对这些上传函数的执行流程进行把控。
因此,我们首先要写一个FileUploaderClient类,提供上述这些能力。这样,当开发者在使用easy-file-uploader-client的时候,只需要实例化FileUploaderClient类,并在上传时使用提供的能力即可。当然,如果用户希望自己控制上传函数的执行流程,那么可以只用「文件md5计算及分片」的能力。
5-1、文件md5计算及分片
实现文件计算md5功能这里使用了spark-md5去计算文件的md5值。而分片的话,是使用浏览器自带的FileReader读取文件,然后用浏览器自带的APIblobSlice去进行分片。
这里值得注意的是,因为当文件体积较大时,「直接对整个文件计算md5」以及「直接加载整个文件并进行分片」都是很吃性能的操作,会耗时很久。这种时候我们同样也需要像easy-file-uploader-server一样,通过输入流对文件进行读取。
/**
* 将file对象进行分片,然后根据分片计算md5
* @param file 要上传的文件
* @returns 返回md5和分片列表
*/
public async getChunkListAndFileMd5(
file: File,
): Promise<{ md5: string; chunkList: Blob[] }> {
return new Promise((resolve, reject) => {
let currentChunk = 0;
const chunkSize = this.fileUploaderClientOptions.chunkSize;
const chunks = Math.ceil(file.size / chunkSize);
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
const blobSlice = getBlobSlice();
const chunkList: Blob[] = [];
fileReader.onload = function (e) {
if (e?.target?.result instanceof ArrayBuffer) {
spark.append(e.target.result);
}
currentChunk++;
if (currentChunk < chunks) {
loadNextChunk();
} else {
const computedHash = spark.end();
resolve({ md5: computedHash, chunkList });
}
};
fileReader.onerror = function (e) {
console.warn('read file error', e);
reject(e);
};
function loadNextChunk() {
const start = currentChunk * chunkSize;
const end =
start + chunkSize >= file.size ? file.size : start + chunkSize;
const chunk = blobSlice.call(file, start, end);
chunkList.push(chunk);
fileReader.readAsArrayBuffer(chunk);
}
loadNextChunk();
});
}
5-2、上传流程把控
把控上传流程实际上就比较简单了,首先我们需要开发者自行实现initFilePartUploadFunc、uploadPartFileFunc、finishFilePartUploadFunc三个函数,然后将它们作为配置项传入FileUploaderClient。最后,我们再提供一个uploadFile函数,依次执行配置项中的这三个函数,就能完成大文件分片上传的整个流程了。
整体上传流程其实比较简单:
1、执行getChunkListAndFileMd5,对文件进行分片并计算md5。
2、执行initFilePartUploadFunc,初始化文件上传。
3、对每一个分片都执行一次uploadPartFileFunc,如果失败,则将其加入retryList。
4、对retryList中上传失败的分片进行重试。
5、执行finishFilePartUploadFunc,完成文件上传。
/**
* 上传文件方法,当FileUploaderClient的配置项中传入了requestOptions才能使用
* 会依次执行getChunkListAndFileMd5、配置项中的initFilePartUploadFunc、配置项中的uploadPartFileFunc、配置项中的finishFilePartUploadFunc
* 执行完成后返回上传结果,若有分片上传失败,则会自动重试
* @param file 要上传的文件
* @returns finishFilePartUploadFunc函数Promise resolve的值
*/
public async uploadFile(file: File): Promise<any> {
const requestOptions = this.fileUploaderClientOptions.requestOptions;
const { md5, chunkList } = await this.getChunkListAndFileMd5(file);
const retryList = [];
if (
requestOptions?.retryTimes === undefined ||
!requestOptions?.initFilePartUploadFunc ||
!requestOptions?.uploadPartFileFunc ||
!requestOptions?.finishFilePartUploadFunc
) {
throw Error(
'invalid request options, need retryTimes, initFilePartUploadFunc, uploadPartFileFunc and finishFilePartUploadFunc',
);
}
await requestOptions.initFilePartUploadFunc();
for (let index = 0; index < chunkList.length; index++) {
try {
await requestOptions.uploadPartFileFunc(chunkList[index], index);
} catch (e) {
console.warn(`${index} part upload failed`);
retryList.push(index);
}
}
for (let retry = 0; retry < requestOptions.retryTimes; retry++) {
if (retryList.length > 0) {
console.log(`retry start, times: ${retry}`);
for (let a = 0; a < retryList.length; a++) {
const blobIndex = retryList[a];
try {
await requestOptions.uploadPartFileFunc(
chunkList[blobIndex],
blobIndex,
);
retryList.splice(a, 1);
} catch (e) {
console.warn(
`${blobIndex} part retry upload failed, times: ${retry}`,
);
}
}
}
}
if (retryList.length === 0) {
return await requestOptions.finishFilePartUploadFunc(md5);
} else {
throw Error(
`upload failed, some chunks upload failed: ${JSON.stringify(
retryList,
)}`,
);
}
}
5-3、总体代码
把上述代码整合到一起,FileUploaderClient类就完成了。更详细的代码可通过上面的github地址去查看:点击这里
import SparkMD5 from 'spark-md5';
import { getBlobSlice } from './util';
const DEFAULT_CHUNK_SIZE = 5 * 1024 * 1024;
const DEFAULT_OPTIONS = {
chunkSize: DEFAULT_CHUNK_SIZE,
};
export interface IFileUploaderClientOptions {
chunkSize: number;
requestOptions?: {
retryTimes: number;
initFilePartUploadFunc: () => Promise<any>;
uploadPartFileFunc: (chunk: Blob, index: number) => Promise<any>;
finishFilePartUploadFunc: (md5: string) => Promise<any>;
};
}
export class FileUploaderClient {
fileUploaderClientOptions: IFileUploaderClientOptions;
constructor(options: IFileUploaderClientOptions) {
this.fileUploaderClientOptions = Object.assign(DEFAULT_OPTIONS, options);
}
/**
* 将file对象进行分片,然后根据分片计算md5
* @param file 要上传的文件
* @returns 返回md5和分片列表
*/
public async getChunkListAndFileMd5(
file: File,
): Promise<{ md5: string; chunkList: Blob[] }> {
return new Promise((resolve, reject) => {
let currentChunk = 0;
const chunkSize = this.fileUploaderClientOptions.chunkSize;
const chunks = Math.ceil(file.size / chunkSize);
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
const blobSlice = getBlobSlice();
const chunkList: Blob[] = [];
fileReader.onload = function (e) {
if (e?.target?.result instanceof ArrayBuffer) {
spark.append(e.target.result);
}
currentChunk++;
if (currentChunk < chunks) {
loadNextChunk();
} else {
const computedHash = spark.end();
resolve({ md5: computedHash, chunkList });
}
};
fileReader.onerror = function (e) {
console.warn('read file error', e);
reject(e);
};
function loadNextChunk() {
const start = currentChunk * chunkSize;
const end =
start + chunkSize >= file.size ? file.size : start + chunkSize;
const chunk = blobSlice.call(file, start, end);
chunkList.push(chunk);
fileReader.readAsArrayBuffer(chunk);
}
loadNextChunk();
});
}
/**
* 上传文件方法,当FileUploaderClient的配置项中传入了requestOptions才能使用
* 会依次执行getChunkListAndFileMd5、配置项中的initFilePartUploadFunc、配置项中的uploadPartFileFunc、配置项中的finishFilePartUploadFunc
* 执行完成后返回上传结果,若有分片上传失败,则会自动重试
* @param file 要上传的文件
* @returns finishFilePartUploadFunc函数Promise resolve的值
*/
public async uploadFile(file: File): Promise<any> {
const requestOptions = this.fileUploaderClientOptions.requestOptions;
const { md5, chunkList } = await this.getChunkListAndFileMd5(file);
const retryList = [];
if (
requestOptions?.retryTimes === undefined ||
!requestOptions?.initFilePartUploadFunc ||
!requestOptions?.uploadPartFileFunc ||
!requestOptions?.finishFilePartUploadFunc
) {
throw Error(
'invalid request options, need retryTimes, initFilePartUploadFunc, uploadPartFileFunc and finishFilePartUploadFunc',
);
}
await requestOptions.initFilePartUploadFunc();
for (let index = 0; index < chunkList.length; index++) {
try {
await requestOptions.uploadPartFileFunc(chunkList[index], index);
} catch (e) {
console.warn(`${index} part upload failed`);
retryList.push(index);
}
}
for (let retry = 0; retry < requestOptions.retryTimes; retry++) {
if (retryList.length > 0) {
console.log(`retry start, times: ${retry}`);
for (let a = 0; a < retryList.length; a++) {
const blobIndex = retryList[a];
try {
await requestOptions.uploadPartFileFunc(
chunkList[blobIndex],
blobIndex,
);
retryList.splice(a, 1);
} catch (e) {
console.warn(
`${blobIndex} part retry upload failed, times: ${retry}`,
);
}
}
}
}
if (retryList.length === 0) {
return await requestOptions.finishFilePartUploadFunc(md5);
} else {
throw Error(
`upload failed, some chunks upload failed: ${JSON.stringify(
retryList,
)}`,
);
}
}
}
六、试用一下!
6-1、server端
先用koa写一个server吧,easy-file-uploader-server的使用方式可以重点可以看下router配置
const Koa = require('koa')
const bodyParser = require('koa-bodyparser')
const router = require('./router')
const cors = require('@koa/cors')
const staticResource = require('koa-static')
const path = require('path')
const KoaRouter = require('koa-router')
const multer = require('@koa/multer')
const path = require('path')
const { FileUploaderServer } = require('easy-file-uploader-server')
const PORT = 10001
const app = new Koa()
const upload = multer()
const router = KoaRouter()
const fileUploader = new FileUploaderServer({
tempFileLocation: path.join(__dirname, './public/tempUploadFile'),
mergedFileLocation: path.join(__dirname, './public/mergedUploadFile'),
})
router.post('/api/initUpload', async (ctx, next) => {
const { name } = ctx.request.body
const uploadId = await fileUploader.initFilePartUpload(name)
ctx.body = { uploadId }
await next()
})
router.post('/api/uploadPart', upload.single('partFile'), async (ctx, next) => {
const { buffer } = ctx.file
const { uploadId, partIndex } = ctx.request.body
const partFileMd5 = await fileUploader.uploadPartFile(uploadId, partIndex, buffer)
ctx.body = { partFileMd5 }
await next()
})
router.post('/api/finishUpload', async (ctx, next) => {
const { uploadId, name, md5 } = ctx.request.body
const { path: filePathOnServer } = await fileUploader.finishFilePartUpload(uploadId, name, md5)
const suffix = filePathOnServer.split('/public/')[1]
ctx.body = { path: suffix }
await next()
})
app.use(cors())
app.use(bodyParser())
app.use(staticResource(path.join(__dirname, 'public')))
app.use(router.routes())
app.use(router.allowedMethods())
app.listen(PORT)
console.log(`app run in port: ${PORT}`)
console.log(`visit http://localhost:${PORT}/index.html to start demo`)
6-2、client端
再用react写一个client吧,重点可以看下APP组件中的逻辑。
import { useRef, useState } from 'react'
import './App.css'
import axios from 'axios'
import { FileUploaderClient } from 'easy-file-uploader-client'
const HOST = 'http://localhost:10001/'
function App() {
const fileInput = useRef(null)
const [url, setUrl] = useState<string>('')
let uploadId = ''
const fileUploaderClient = new FileUploaderClient({
chunkSize: 2 * 1024 * 1024, // 2MB
requestOptions: {
retryTimes: 2,
initFilePartUploadFunc: async () => {
const fileName = (fileInput.current as any).files[0].name
const { data } = await axios.post(`${HOST}api/initUpload`, {
name: fileName,
})
uploadId = data.uploadId
console.log('初始化上传完成')
setUrl('')
},
uploadPartFileFunc: async (chunk: Blob, index: number) => {
const formData = new FormData()
formData.append('uploadId', uploadId)
formData.append('partIndex', index.toString())
formData.append('partFile', chunk)
await axios.post(`${HOST}api/uploadPart`, formData, {
headers: { 'Content-Type': 'multipart/form-data' },
})
console.log(`上传分片${index}完成`)
},
finishFilePartUploadFunc: async (md5: string) => {
const fileName = (fileInput.current as any).files[0].name
const { data } = await axios.post(`${HOST}api/finishUpload`, {
name: fileName,
uploadId,
md5,
})
console.log(`上传完成,存储地址为:${HOST}${data.path}`)
setUrl(`${HOST}${data.path}`)
},
},
})
const upload = () => {
if (fileInput.current) {
fileUploaderClient.uploadFile((fileInput.current as any).files[0])
}
}
return (
<div className="App">
<h1>easy-file-uploader-demo</h1>
<h3>选择文件后点击“上传文件”按钮即可</h3>
<div className="App">
<input type="file" name="file" ref={fileInput} />
<input type="button" value="上传文件" onClick={upload} />
</div>
{url && <h3>{`文件地址:${url}`}</h3>}
</div>
)
}
export default App
6-3、使用效果
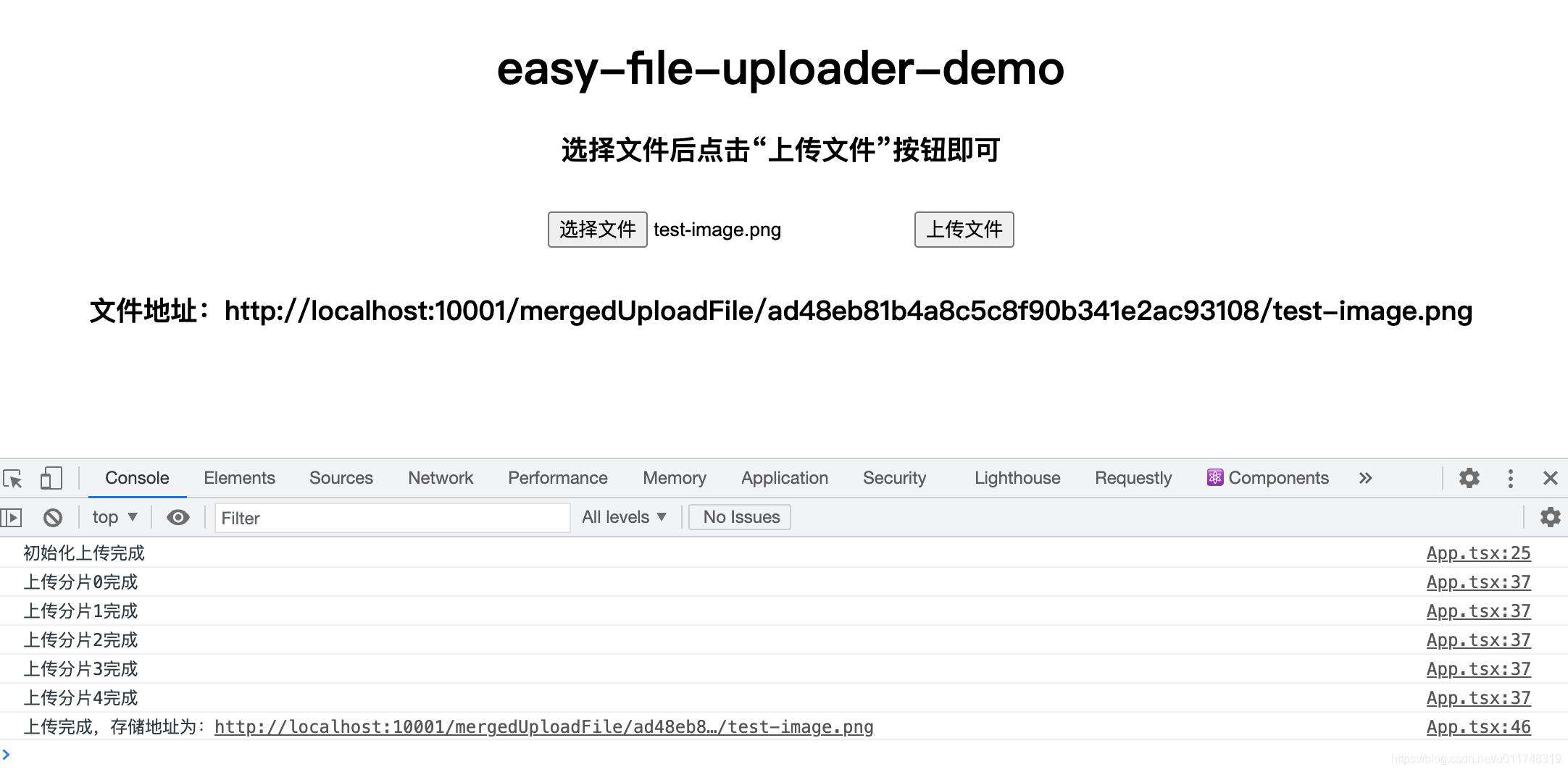
首先选择大文件,然后点击上传,上传完毕后显示了文件地址。
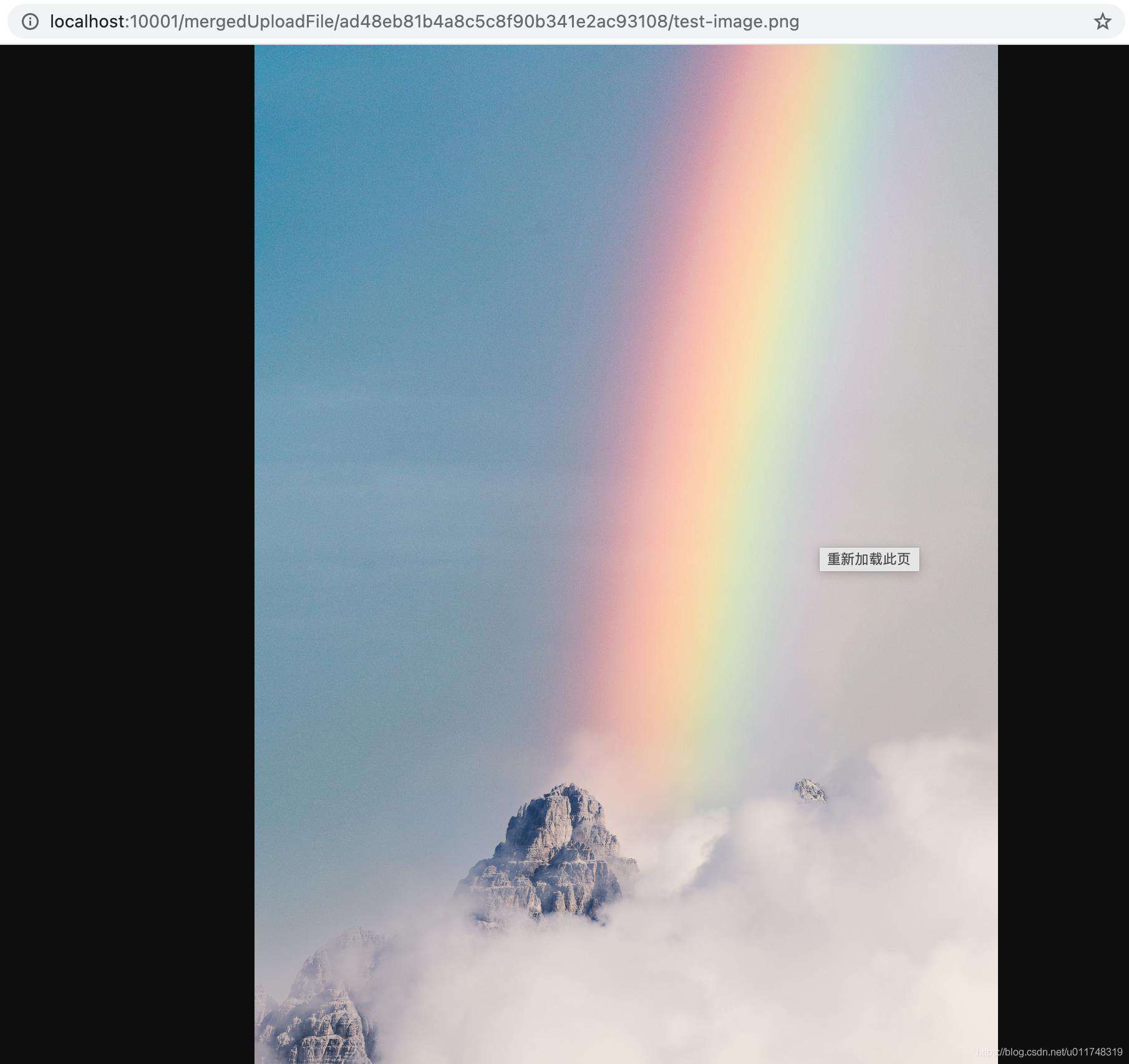
 访问一下文件,看起来文件已经成功上传到服务器了,完美!
访问一下文件,看起来文件已经成功上传到服务器了,完美!
更详细的使用样例可以到github中查看:easy-file-uploader使用样例
作者:shadowings-zy
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!