简介: 从C++11开始,标准引入了一个新概念“属性(attribute)”,本文将简单介绍一下目前在C++标准中已经添加的各个属性以及常用属性的具体应用。

作者 | 寒冬
来源 | 阿里技术公众号
从C++11开始,标准引入了一个新概念“属性(attribute)”,本文将简单介绍一下目前在C++标准中已经添加的各个属性以及常用属性的具体应用。
一 属性(Attribute)的前世今生
其实C++早在[pre03]甚至更早的时候就已经有了属性的需求。彼时,当程序员需要和编译器沟通,为某些实体添加一些额外的信息的时候,为了避免“发明”一个新的关键词乃至于引起一些语法更改的麻烦,同时又必须让这些扩展内容不至于“污染”标准的命名空间,所以标准保留了一个特殊的用户命名空间——“双下划线关键词”,以方便各大编译器厂商能够根据需要添加相应的语言扩展。根据这个标准,各大编译器厂商都做出了自己的扩展实现,目前在业界广泛使用的属性空间有GNU和IBM的 __attribute__(()),微软的 __declspec(),甚至C#还引入了独特的单括号系统(single bracket system)来完成相应的工作。
随着编译器和语言标准的发展,尤其是C++多年来也开始逐渐借鉴其他语言中的独特扩展,属性相关的扩展也越来越庞大。但是Attribute的语法强烈依赖于各大编译器的具体实现,彼此之间并不兼容,甚至部分关键属性导致了语言的分裂,最终都会让使用者的无所适从。所以在C++11标准中,特意提出了C++语言内置的属性概念。提案大约是在2007年前后形成,2008年9月15日的提案版本n2761被正式接纳为C++11标准中的Attribute扩展部分(此处历史略悠久,很可能有不准确的部分,欢迎各位指正)。
二 属性的语法定义
正如我们在上一节讨论的,属性的关键要求就是避免对标准用户命名空间的污染,同时对于未来可能引入的更多属性,我们需要有一个方式可以避免新加的“属性关键字”破坏当前已有的C++语法。所以新标准采用了“双方括号”的语法方式引入了属性说明,比如[[noreturn]]就是一个标准的C++属性定义。而未来新属性的添加都被控制在双方括号范围之内,不会进入标准的命名空间。
按照C++语言标准,下列语言实体可以被属性所定义/并从中获益:
- 函数
- 变量
- 函数或者变量的名称
- 类型
- 程序块
- Translation Unit (这个不知道用中文咋说)
- 程序控制声明
根据C++的标准提案,属性可以出现在程序中的几乎所有的位置。当然属性出现的位置和其修饰的对象是有一定关联的,属性仅在合适的位置才能产生效果。比如[[noreturn]必须出现在函数定义的位置才会产生效果,如果出现在某个变量的声明处则无效。根据C++17的标准,未实现的或者无效的属性均应该被编译器忽略且不产生任何错误报告(在C++17标准之前的编译器则参考编译器的具体实现会有不同的行为)。
由于属性可以出现在几乎所有的位置,那么它是如何关联到具体的作用对象呢?下面我引用了语言标准提案中的一个例子帮助大家理解属性是如何作用于语言的各个部分。
[[attr1]] class C [[ attr2 ]] { } [[ attr3 ]] c [[ attr4 ]], d [[ attr5 ]];
- attr1 作用于class C的实体定义c和d
- attr2 作用于class C的定义
- attr3 作用于类型C
- attr4 作用于实体c
- attr5 作用于实体d
以上只是一个基本的例子,具体到实际的编程中,还有有太多的可能,如有具体情况可以参考C++语言标准或者编译器的相关文档。
三 主流C++编译器对于属性的支持情况
目前的主流编译器对于C++11的支持已经相对很完善了,所以对于属性的基本语法,大部分的编译器都已经能够接纳。不过对于在不同标准中引入的各个具体属性支持则参差不齐,对于相关属性能否发挥应有的作用更需要具体问题具体分析。当然,在标准中(C++17)也明确了,对于不支持或者错误设定的属性,编译器也能够忽略不会报错。
下图是目前主流编译器对于n2761属性提案的支持情况:
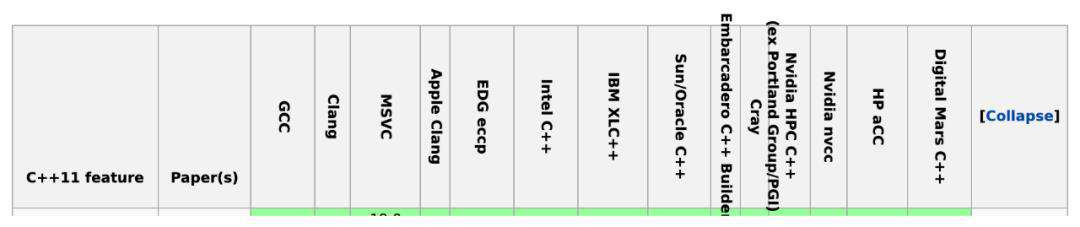

对于未知或不支持的属性忽略报错的主流编译器支持情况:


四 目前C++标准中引入的标准属性
C++11引入标准:
- [[noreturn]]
- [[carries_dependency]]
C++14引入标准:
- [[deprecated]] 和 [[deprecated("reason")]]
C++17引入标准:
- [[fallthrough]]
- [[nodiscard]] 和 [[nodiscard("reason")]] (C++20)
- [[maybe_unused]]
C++20引入标准:
- [[likely]] 和 [[unlikely]]
- [[no_unique_address]]
接下来我将尝试对已经引入标准的属性进行进一步的说明,同时对于已经明确得到编译器支持的属性,我也会尝试用例子进行进一步的探索,希望抛砖引玉能够帮大家更好的使用C++属性这个“新的老朋友”。
1 [[noreturn]]
从字面意义上来看,noreturn是非常容易理解的,这个属性的含义就是标明某个函数一定不会返回。
请看下面的例子程序:
// 正确,函数将永远不会返回。
[[noreturn]] void func1()
{ throw "error"; }
// 错误,如果用false进行调用,函数是会返回的,这时候会导致未定义行为。
[[noreturn]] void func2(bool b)
{ if (b) throw "error"; }
int main()
{
try
{ func1() ; }
catch(char const *e)
{ std::cout << "Got something: " << e << " \n"; }
// 此处编译会有警告信息。
func2(false);
}
这个属性最容易被误解的地方是返回值为void的函数不代表着不会返回,它只是没有返回值而已。所以在例子中的第一个函数func1才是正确的无返回函数的一个例子;而func2在参数值为false的情况下,它还是一个会返回的函数。所以,在编译的时候,编译器会针对func2报告如下错误:
noreturn.cpp: In function 'void func2(bool)':
noreturn.cpp:11:1: warning: 'noreturn' function does return
11 | }
| ^
而实际运行的时候,func2到底会有什么样的表现属于典型的“未定义行为”,程序可能崩溃也可能什么都不发生,所以一定要避免这种情况在我们的代码中出现。(我在gcc11编译器环境下尝试过几次,情况是什么都不发生,但是无法保证这是确定的行为。)
另外,[[noreturn]]只要函数最终没有返回都是可以的,比如用exit()调用直接将程序干掉的程序也是可以被编译器接受的行为(只是暂时没想到为啥要这么干)。
2 [[carries_dependency]]
这个属性的作用是允许我们将dependency跨越函数进行传递,用于避免在弱一致性模型平台上产生不必要的内存栅栏导致代码效率降低。
一般来说,这个属性是搭配 std::memory_order_consume 来使用的,支持这个属性的编译器可以根据属性的指示生成更合适的代码帮助程序在线程之间传递数据。在典型的情况下,如果在 memory_order_consume 的情况下读取一个值,编译器为了保证合适的内存读取顺序,可能需要额外的内存栅栏协调程序行为顺序,但是如果加上了[[carries_dependency]]的属性,则编译器可以保证函数体也被扩展包含了同样的dependency,从而不再需要这个额外的内存栅栏。同样的事情对于函数的返回值也是一致的。
参考如下例子代码:
std::atomic<int *> p;
std::atomic<int *> q;
void func1(int *val)
{ std::cout << *val << std::endl; }
void func2(int * [[carries_dependency]] val)
{ q.store(val, std::memory_order_release);
std::cout << *q << std::endl; }
void thread_job()
{
int *ptr1 = (int *)p.load(std::memory_order_consume); // 1
std::cout << *ptr1 << std::endl; // 2
func1(ptr1); // 3
func2(ptr1); // 4
}
- 程序在1的位置因为ptr1明确的使用了memory_order_consume的内存策略,所以对于ptr1的访问一定会被编译器排到这一行之后。
- 因为1的原因,所以这一行在编译的时候势必会排列在1后面。
- func1并没有带任何属性,而他访问了ptr1,那么编译器为了保证内存访问策略被尊重所以必须在func1调用之间构建一个内存栅栏。如果这个线程被大量的调用,这个额外的内存栅栏将导致性能损失。
- 在func2中,我们使用了[[carries_dependency]]属性,那么同样的访问ptr1,编译器就知道程序已经处理好了相关的内存访问限制。这个也正如我们再func2中对val访问所做的限制是一样的。那么在func2之前,编译器就无需再插入额外的内存栅栏,提高了效率。
3 [[deprecated]] 和 [[deprecated("reason")]]
这个属性是在C++14的标准中被引入的。被这个属性加持的名称或者实体在编译期间会输出对应的警告,告诉使用者该名称或者实体将在未来被抛弃。如果指定了具体的"reason",则这个具体的原因也会被包含在警告信息中。
参考如下例子程序:
[[deprecated]]
void old_hello() {}
[[deprecated("Use new_greeting() instead. ")]]
void old_greeting() {}
int main()
{
old_hello();
old_greeting();
return 0;
}
在支持对应属性的编译器上,这个例子程序是可以通过编译并正确运行的,但是编译的过程中,编译器会对属性标志的函数进行追踪,并且打印出相应的信息(如果定义了的话)。在我的环境中,编译程序给出了我如下的提示信息:
deprecated.cpp: In function 'int main()':
deprecated.cpp:9:14: warning: 'void old_hello()' is deprecated [-Wdeprecated-declarations]
9 | old_hello();
| ~~~~~~~~~^~
deprecated.cpp:2:6: note: declared here
2 | void old_hello() {}
| ^~~~~~~~~
deprecated.cpp:10:17: warning: 'void old_greeting()' is deprecated:
Use new_greeting() instead. [-Wdeprecated-declarations]
10 | old_greeting();
| ~~~~~~~~~~~~^~
deprecated.cpp:5:6: note: declared here
5 | void old_greeting() {}
| ^~~~~~~~~~~~
[[deprecated]]属性支持广泛的名字和实体,除了函数,它还可以修饰:
- 类,结构体
- 静态数据成员,非静态数据成员
- 联合体,枚举,枚举项
- 变量,别名,命名空间
- 模板特化
4 [[fallthrough]]
这个属性只可以用于switch语句中,通常在case处理完毕之后需要按照程序设定的逻辑退出switch块,通常是添加break语句;或者在某些时候,程序又需要直接进入下一个case的判断中。而现代编译器通常会检测程序逻辑,在前一个case处理完毕不添加break的情况下发出一个警告信息,让作者确定是否是他的真实意图。但是,在case处理部分添加了[[fallthrough]]属性之后,编译器就知道这是程序逻辑有意为之,而不再给出提示信息。
5 [[nodiscard]] 和 [[nodiscard("reason")]]
这两个属性和前面的[[deprecated]]类似,但是他们是在不同的C++标准中被引入的,[[nodiscard]]是在C++17标准中引入,而[[nodiscard("reason")]]是在C++20标准中引入。
这个属性的含义是明确的告诉编译器,用此属性修饰的函数,其返回值(必须是按值返回)不应该被丢弃,如果在实际调用中舍弃了返回变量,则编译器会发出警示信息。如果此属性修饰的是枚举或者类,则在对应函数返回该类型的时候也不应该丢弃结果。
参考下面的例子程序:
struct [[nodiscard("IMPORTANT THING")]] important {};
important i = important();
important get_important() { return i; }
important& get_important_ref() { return i; }
important* get_important_ptr() { return &i; }
int a = 42;
int* [[nodiscard]] func() { return &a; }
int main()
{
get_important(); // 此处编译器会给出警告。
get_important_ref(); // 此处因为不是按值返回nodiscard类型,不会有警告。
get_important_ptr(); // 同上原因,不会有警告。
func(); // 此处会有警告,虽然func不按值返回,但是属性修饰的是函数。
return 0;
}
在对上述例子进行编译的时候,我们可以看到如下的警告信息:
nodiscard.cpp:8:25: warning: 'nodiscard' attribute can only be applied to functions or to class or enumeration types [-Wattributes]
8 | int* [[nodiscard]] func() { return &a; }
| ^
nodiscard.cpp: In function 'int main()':
nodiscard.cpp:12:18: warning: ignoring returned value of type 'important',
declared with attribute 'nodiscard': 'IMPORTANT THING' [-Wunused-result]
12 | get_important();
| ~~~~~~~~~~~~~^~
nodiscard.cpp:3:11: note: in call to 'important get_important()', declared here
3 | important get_important() { return i; }
| ^~~~~~~~~~~~~
nodiscard.cpp:1:41: note: 'important' declared here
1 | struct [[nodiscard("IMPORTANT THING")]] important {};
| ^~~~~~~~~
可以看到,编译器对于按值返回带属性的类型被丢弃发出了警告,但是对于非按值返回的调用没有警告。不过如果属性直接修饰的是函数体,那么则不受此限制。
在新的C++标准中,除了添加了[[nodiscard]]属性对应的处理逻辑,同时对于标准库中的不应该丢弃返回值的操作也添加相应的属性修饰,包含内存分配函数,容器空判断函数,异步运行函数等。请参考下面的例子:
#include <vector>
std::vector<int> vect;
int main()
{ vect.empty(); }
在编译这个例子的时候,我们收到了编译器的如下警告,可见,新版本的标准库也已经对[[nodiscard]]属性提供了支持(不过这个具体要看编译器和对应库版本,需要参考编译器和标准的提供方)。
nodiscard2.cpp: In function 'int main()':
attibute/nodiscard2.cpp:5:13: warning:
ignoring return value of 'bool std::vector<_Tp, _Alloc>::empty() const [with _Tp = int; _Alloc = std::allocator<int>]',
declared with attribute 'nodiscard' [-Wunused-result]
5 | { vect.empty(); }
| ~~~~~~~~~~^~
In file included from /usr/local/include/c++/11.1.0/vector:67,
from attibute/nodiscard2.cpp:1:
/usr/local/include/c++/11.1.0/bits/stl_vector.h:1007:7: note: declared here
1007 | empty() const _GLIBCXX_NOEXCEPT
| ^~~~~
6 [[maybe_unused]]
通常情况下,对于声明了但是从未使用过的变量会给出警告信息。但是在声明的时候添加了这个属性,则编译器确认是程序故意为之的逻辑,则不再发出警告。需要注意的是,这个声明不会影响编译器的优化逻辑,在编译优化阶段,无用的变量该干掉还是会被干掉的。
7 [[likely]] 和 [[unlikely]]
这一对属性是在C++20的时候引入标准的,这两个语句只允许用来修饰标号或者语句(非声明语句),目的是告诉编译器,在通常情况下,哪一个分支的执行路径可能性最大,显然,他俩也是不能同时修饰同一条语句。
截止我撰写本文的今天,已经有不少编译器对于这个属性提供了支持,包括GCC9,Clang12,MSVC19.26等等。但是结合现代编译器各种登峰造极的优化行为,我们在使用这个属性的时候也需要有一个合理的期望,不能指望他发挥点石成金的效果。当然,这并不代表我不鼓励你使用它们,明确的让编译器知道你的意图总归是一件好事情。
同样的,我们先来看第一个例子:
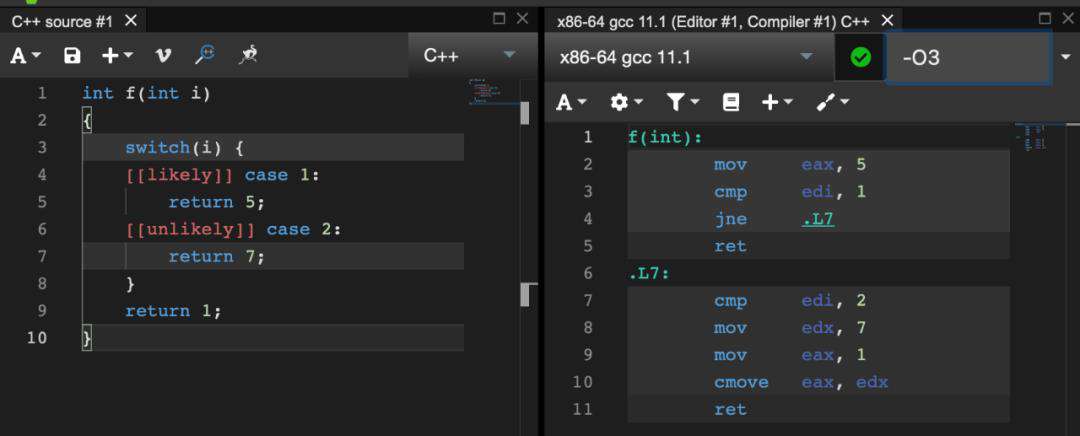
我们看到case 1是我们明确用属性标明的运行时更有可能走到的分支,那么我们可以看到对应生成的汇编代码中,case 1的流程是:首先给eax寄存器赋值5,然后比对输入值1,如果输入值为1,则直接返回,eax寄存器包含返回值。但如果这时候输入值不为1,则需要一次跳转到.L7去进行下面的逻辑。显然,在case1的情况下,代码是不需要任何跳转,直接运行的。
我们再看第二个例子:
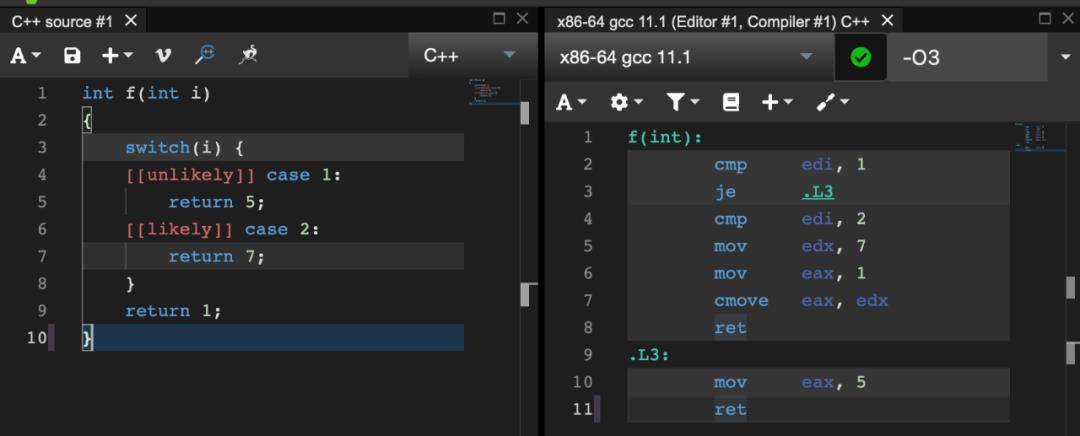
这次我们将优先级顺序调转,用属性标明case 2的是运行时更有可能走到的分支,那么对应的汇编代码中,我们看看case 1的逻辑:首先进来就和1比对,如果相等,跳转到.L3执行返回5的操作;如果不相等,那么直接和2比对,同时edx和eax寄存器分别赋值7和1,根据比对的结果确定是否将edx的值赋值到eax(cmove语句),然后返回。似乎上来还是优先比对了1的情况,但是仔细研究我们就会发现,在case 2的逻辑通路上是不存在跳转指令的,意味着case 2的流程也是需要跳转可以直接运行下去的,没有跳转处理器也就不需要清空流水线(此处简化理论,不涉及到处理器内部分支预测逻辑),case 2相对于case 1还是更加快速的流程,[[likely]]属性发挥了它应有的作用。
当然,程序的优化涉及到的领域实在太多了,在真实的场景中,[[likely]]和[[unlikely]]属性能否如我们所愿发挥作用是需要具体问题具体分析的。不过正确的使用属性即便没有正向收益,也不会有负收益,并且我相信在大部分的场景下这是有好处的,并且在未来编译器更加优化之后,明确意图的代码总是能得到更多优化。
8 [[no_unique_address]]
这个属性也是在C++20中引入的,旨在和编译器沟通非位域非静态数据成员不需要具有不同于其相同类型其他非静态成员不同的地址。带来的效果就是,如果该成员拥有空类型,则编译器可以将它优化为不占用空间的部分。
下面也还是用一个例子来演示一下这个属性吧:
#include <iostream>
struct Empty {}; // 空类型
struct X { int i; };
struct Y1 { int i; Empty e; };
struct Y2 { int i; [[no_unique_address]] Empty e; };
struct Z1 { char c; Empty e1, e2; };
struct Z2 { char c; [[no_unique_address]] Empty e1, e2; };
int main()
{
std::cout << "空类大小:" << sizeof(Empty) << std::endl;
std::cout << "只有一个int类大小:" << sizeof(X1) << std::endl;
std::cout << "一个int和一个空类大小:" << sizeof(Y1) << std::endl;
std::cout << "一个int和一个[[no_unique_address]]空类大小:" << sizeof(Y2) << std::endl;
std::cout << "一个char和两个空类大小:" << sizeof(Z1) << std::endl;
std::cout << "一个char和两个[[no_unique_address]]空类大小:" << sizeof(Z2) << std::endl;
}
编译之后,我们运行程序可以得到如下结果(这个例子是在Linux x64 gcc11.1下的结果,不同的操作系统和编译器可能结果不同):
- 空类大小:1
- 只有一个int类大小:4
- 一个int和一个空类大小:8
- 一个int和一个[[no_unique_address]]空类大小:4
- 一个char和两个空类大小:3
- 一个char和两个[[no_unique_address]]空类大小:2
说明:
- 对于空类型,在C++中也会至少分配一个地址,所以空类型的尺寸大于等于1。
- 如果类型中有一个非空类型,那么这个类的尺寸等于这个非空类型的大小。
- 如果类型中有一个非空类型和一个空类型,那么尺寸一定大于非空类型尺寸,编译器还需要分配额外的地址给非空类型。具体会需要分配多少大小取决于编译器的具体实现。本例子中用的是gcc11,我们看到为了对齐,这个类型的尺寸为8,也就是说,空类型分配了一个和int对齐的4的尺寸。
- 如果空类型用[[no_unique_address]]属性修饰,那么这个空类型就可以和其他非同类型的非空类型共享空间,可以看到,这里编译器优化之后,空类型和int共享了同一块内存空间,整个类型的尺寸就是4。
- 如果类型中有一个char类型和两个空类型,那么编译器对于两个空类型都分配了和非空类型char同样大小的尺寸,整个类型占用内存为3。
- 同样的,如果两个空类型都用[[no_unique_address]]进行修饰的话,我们发现,其中一个空类型可以和char共享空间,但是另外一个空类型无法再次共享同一个地址,又不能和同样类型的空类型共享,所以整个结构的尺寸为2。
五 总结
以上本文介绍了属性作为一个新的“旧概念”是如何引入到C++标准的和属性的基本概念,同时还介绍了已经作为标准引入C++语言特性的部分属性,包含C++11,14,17和20的部分内容。希望能够抛砖引玉,和大家更好地理解C++的新功能并让它落地并服务于我们的产品和项目,初次撰文,如果有错漏缺失,还请各位读者斧正。
原文链接
本文为阿里云原创内容,未经允许不得转载。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?


发表评论
还没有评论,快来抢沙发吧!