nodejs内存监控2-prometheus+grafana监控实现
前言
本文是基于k8s为前提,所以这边会声明一些你提前需要做得或者有的环境:
- 一套k8s集群
- 已经提前部署了
ingress - 已经提前安装了
helm
使用helm安装kube-prometheus-stack
prometheus是非常流行的监控服务,但是对于k8s的监控需要做很多接口,这导致了prometheus监控K8s比较复杂,官方就出了kube-prometheus这么一个项目,是Prometheus Operator的定制版,如果我们想获取完整的k8s服务监控指标,推荐采用kube-prometheus的方式。
其中kube-prometheus-stack集成了prometheus + grafana + alertmanage等等一些必要的服务同时内部内置了一些常用的k8s dashboard监控指标,我们直接使用helm部署即可。具体部署方式不再赘述,社区已经有非常多的部署文章。具体的部署可以参考接下来的这篇文章,讲的十分详细:
HELM部署Prometheus operator监控k8s
部署成功之后,根据账号密码进入grafana,我们可以看到了一些kube-stack-prometheus已经默认设置好的dashboard:
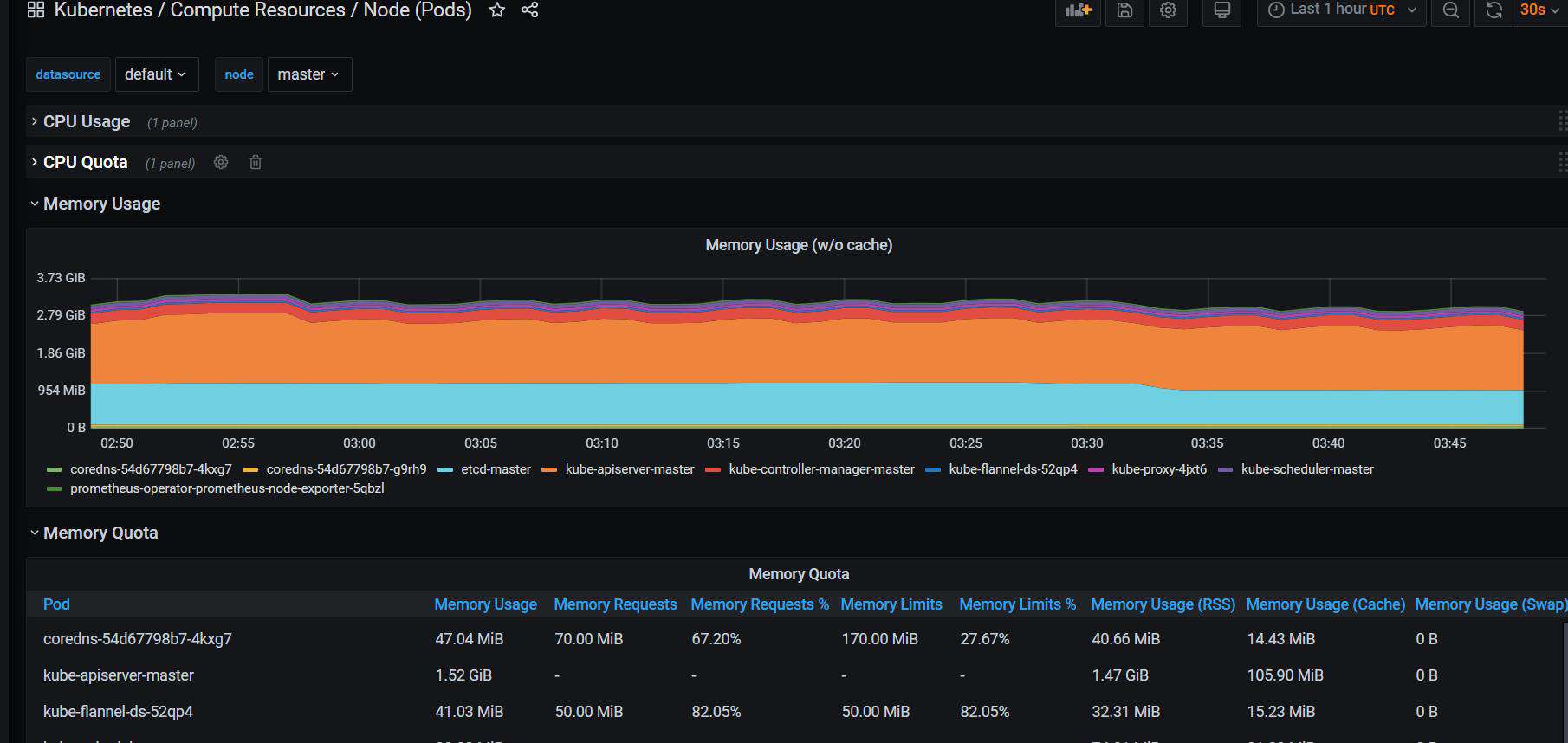
点进去能看到相关的nodes, pods, k8s服务等等的许多指标信息:
node项目集成prom-client收集指标
项目集成prom-client
搭好了监控平台还不够,我们还需要提供数据源才行,社区已经提供了非常棒的开源库prom-clinet。
因为我的博客项目是基于nest.js搭建的,所以为了方便我这边直接使用了express-prom-bundle,这个包也是基于prom-clinet额外收集了http方面的指标数据。具体使用方法可以参考文档,接下来给出我博客后端的示例用法:
import { NestFactory } from '@nestjs/core';
import { SwaggerModule, DocumentBuilder } from '@nestjs/swagger';
import * as express from 'express';
import { AppModule } from './app.module';
import ErrorFilter from '@utils/errorFilter';
import { logMiddleware, authMiddleware } from './middlewares';
import TransformInterceptor from './interceptor/transform.interceptor';
import * as promBundle from 'express-prom-bundle';
const metricsMiddleware = promBundle({
includeMethod: true,
customLabels: {
app: 'blog-backend',
version: '1.0.0',
},
includePath: true,
promClient: {
collectDefaultMetrics: {},
},
});
async function bootstrap() {
const app = await NestFactory.create(AppModule);
app.use(metricsMiddleware);
// 处理请求数据
app.use(express.json());
// For parsing application/x-www-form-urlencoded
app.use(express.urlencoded({ extended: true }));
app.use(authMiddleware);
app.use(logMiddleware);
app.useGlobalFilters(new ErrorFilter());
app.useGlobalInterceptors(new TransformInterceptor());
// 配置 Swagger
const options = new DocumentBuilder()
.setTitle('xxx')
.setDescription('xxx')
.setVersion('1.0')
.build();
const document = SwaggerModule.createDocument(app, options);
SwaggerModule.setup('xxx', app, document);
await app.listen(xxx);
}
bootstrap();
启动服务后,我们就能通过localhost:端口号/metrics路径获取到对应的指标数据:

prometheus deployment配置收集数据
在上一步中,我们通过prom-clinet获取到了基本的监控数据指标,我们还需要让prometheus对这些数据指标进行收集。在deployment中需要添加相对应的配置:
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: APP_NAME
name: APP_NAME
namespace: NAMESPACE
# service 需要声明添加prometheus监控
annotations:
prometheus.io/scrape: 'true'
# prometheus获取指标协议
prometheus.io/scheme: http
# prometheus获取指标路径
prometheus.io/path: /metrics
prometheus.io/port: "80"
spec:
ports:
- port: 80
targetPort: 4000
name: APP_NAME
selector:
k8s-app: APP_NAME
---
# kube-stack-prometheus需要制定servicemonitor才会自动去获取数据
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: blog-backend
namespace: monitoring
# kube-stack-prometheus会自动获取含有 app: kube-prometheus-stack 的servicemonitor
labels:
release: kube-prometheus-stack
app: kube-prometheus-stack
release: prometheus
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 5s
port: blog-backend
jobLabel: k8s-app
namespaceSelector:
matchNames:
- blog-project
selector:
matchLabels:
k8s-app: blog-backend
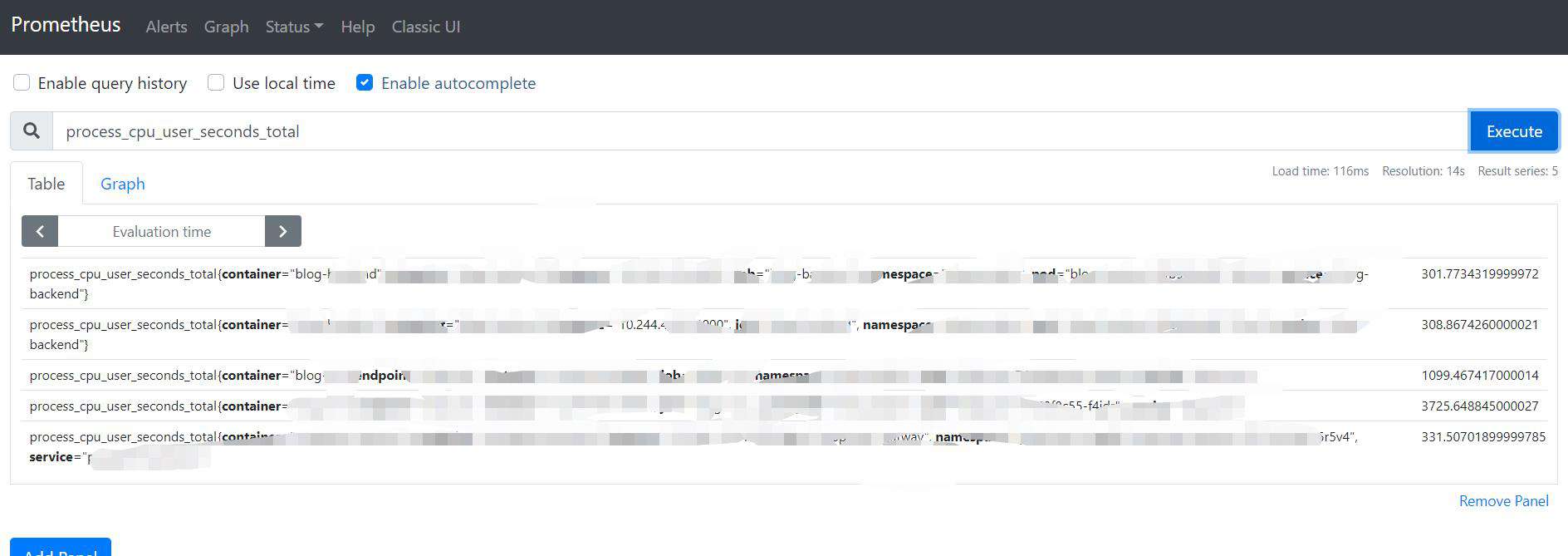
启动pod服务之后,我们可以进入prometheus控制台,输入其中metrics路径中的随便一个指标process_cpu_user_seconds_total。如果有相对应的数据出现,证明prometheus已经能够成功的收集node项目的指标数据。
grafana可视化数据
当然获取了数据还不行,我们还需要把数据反映称图表信息用于查看,这时候就需要granafa了,在部署kube-stack-prometheus的时候其实grafana也自动进行了部署。
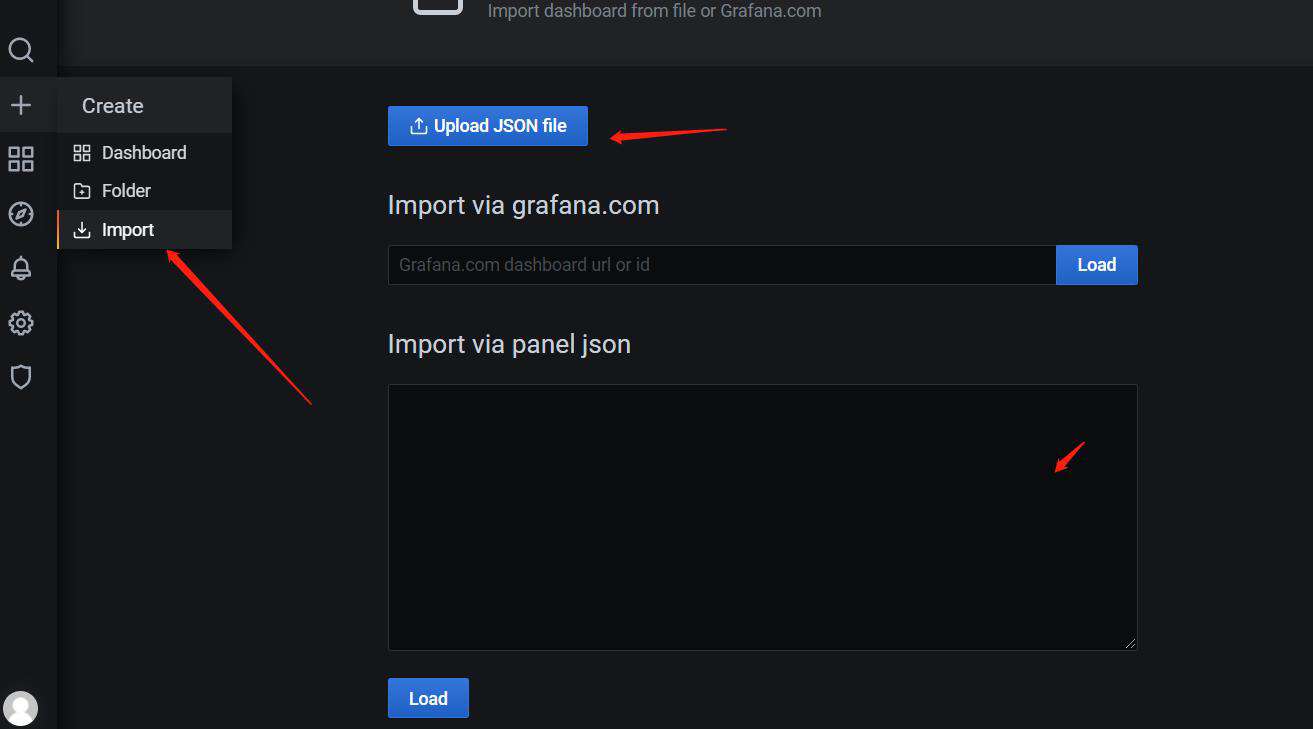
我们只需要手动添加dashboard,然后把dashboard的json数据复制进去即可,我配置的json数据文件可在此处下载导入即可:
导入完成之后,选择对应的pod就可以看到当前监控的node项目性能指标啦:
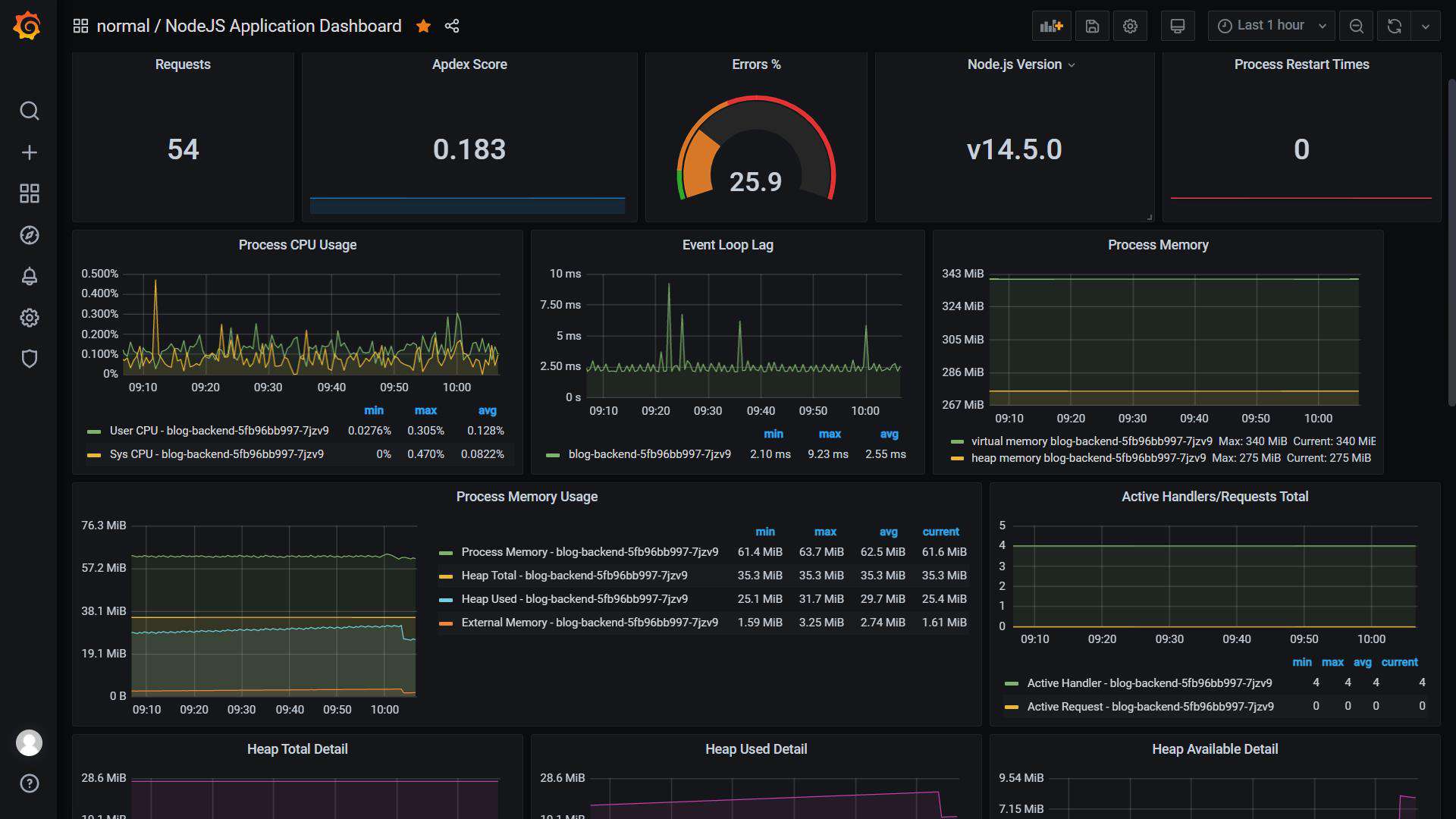
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!