前言
在使用 Koa 框架搭建网站时,一般返回 index.html 当做入口文件,这需要设置特定的 response header.
由于 Koa 自身极简的设计思想,我相信没看过源码的同学,第一时间会写出如下代码:
const Koa = require("koa");
const fs = require("fs");
const app = new Koa();
app
.use(ctx => {
ctx.set("Content-Type", "text/html");
ctx.body = fs.readFileSync("index.html");
})
.listen(3000);
这当然可行,还能加强你对 HTTP Headers 的理解,但真正熟悉 Koa 的人,不屑于用如此原始的方法。
别看 Koa 的源码短小精悍,它依旧为开发者提供了诸多便捷的功能,例如此文着重介绍的 ctx.type.
带你认识 ctx.type
先上代码,只需将上下文(ctx)的 type 设置为 "html" 即可:
app
.use(ctx => {
ctx.type = "html";
ctx.body = fs.readFileSync("index.html");
})
.listen(3000);
用 http(没有安装这个命令的小伙伴,访问这个网址:httpie.io/ )在终端进行测试:
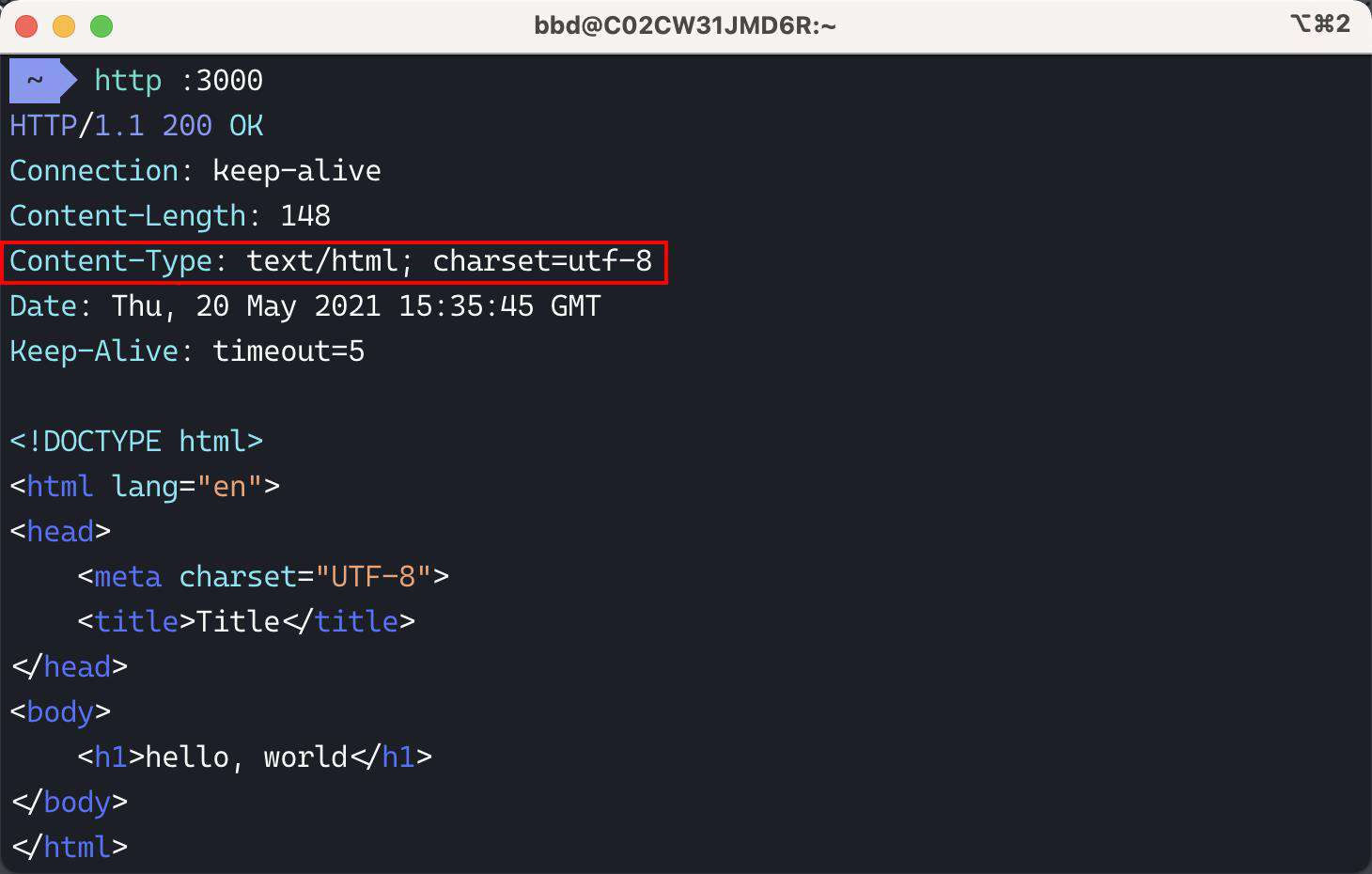
其实它的实现非常简单,通过传入不同的 type,自动设置对应的 Content-Type response header.
具体源码戳着 lib/response.js.
module.exports = {
// ...
set type(type) {
type = getType(type);
if (type) {
this.set("Content-Type", type);
} else {
this.remove("Content-Type");
}
},
};
那么 getType 函数是个啥?原来借助了第三方包的“神秘力量”。
const getType = require("cache-content-type");
出现了关键词 "cache",作为一名专业的前端工程师(切图仔),察觉到这里一定做了某些优化。
为了验证我的猜测,我查看了此文件在 GitHub 上的历史提交记录。
果不其然,在 18 年的 7 月,一个有关性能优化的 PR 被合入 master.

来看看具体改动了哪些内容:

破案了!最先使用的是 mime-types 库。
这个库实现同样很简单,大致就是从一个 JSON 文件(mime-db/db.json)匹配文件后缀名,返回 Content-Type,如 html -> text/html 的映射关系,库还会根据情况来为你加上 charset=utf-8.
// db.json
{
"text/html": {
"source": "iana",
"compressible": true,
"extensions": ["html", "htm", "shtml"]
}
}
这里推荐一个非常 nice 的在线运行 Node.js package 的网站:npm.runkit.com/mime-types.
你可以在浏览器上在线体验这些库、还包括查看源码,README.md 等功能。
Koa 的优化之路:LRU
让我们把视角转向现在,Koa 中 mime-types 库已被无情抛弃,取而代之的是 cache-content-type 库.
它的源码更简单,总共就 15 行:
"use strict";
const mimeTypes = require("mime-types");
const LRU = require("ylru");
const typeLRUCache = new LRU(100);
module.exports = type => {
let mimeType = typeLRUCache.get(type);
if (!mimeType) {
mimeType = mimeTypes.contentType(type);
typeLRUCache.set(type, mimeType);
}
return mimeType;
};
核心思路是维护一个 Cache:
- 当 Cache 中没有该 type 对应的 mimeType 时,会去进行一次查找并将结果 mimeType 存储在 Cache 中
- 当第二次查找 type,发现 Cache 中已存在,就直接返回对应的 mimeType,不再进行查找
因为存储 MIME 信息的 JSON 文件非常大,每次查找都非常耗时,所以尽可能减少查找次数。
细心的小伙伴发现了,这个 typeLRUCache 为什么还要设置最大容量为 100 个?难道存储超过 100 个 type 后,之后查找 type 的结果就不能被缓存了吗?
No,因为代码中 typeLRUCache 跟我说的 Cache 不是同一个东西。
我说的 Cache 是一种单纯以空间换时间的方法,但也不能无脑去拓宽空间,假设容量为 1000000 或 1e10 个,这会急剧增加程序的运行内存,引起电脑卡顿、死机。
归功于 ylru 这个库,我们有一种折中的方案。
因为它实现了 Least recently used (LRU) 算法,这个算法做了什么呢?我举个栗子,便于大家理解。
一个小区里只有两个停车位 P1 和 P2,但有四个车主分别为 A、B、C、D.
-
第一天特斯拉车主 A 使用了 P1
-
第二天宝马车主 B 使用了 P2
-
第三天保时捷车主 C 来停车,发现没有停车位了,咋办呢?
- 小区物业出于人性化考虑,宝马车主 B 一天前刚用的 P2,而特斯拉车主 A 是两天前用的 P1,估计特斯拉车主 A 已经去世了,于是强制让 A 移出了停车位
- 保时捷车主 C 顺利将车停入 P1
-
第四天上午,宝马车主 B 离开了停车位
-
第四天下午,宝马车主 B 进入了停车位
-
第五天奔驰车主 D 来停车,发现停车位已满,咋办呢?
- 小区物业出于人性化考虑,宝马车主 B 一天前刚频繁使用过 P2,而保时捷车主 C 已经一天没动静了,就算你是豪华车也没用,强制让保时捷车主 C 移出了停车位
- 奔驰车主 D 顺利将车停入 P1
总结:停车位总量不变,但至少能让最近经常使用停车位车主的权益得到保障,停车位始终有你一份,而不是看先来后到,也不是看谁的车贵。
类比到 typeLRUCache 上,只能存储 100 个缓存结果,防止容量无限增大,但能保证最近被频繁查找 type 的结果始终被缓存,提示后续查找效率。
我在这写了一个简易版 LRU 的 demo:
class LRUCache {
constructor(capacity) {
this.cache = new Map();
this.capacity = capacity;
}
get(key) {
if (this.cache.has(key)) {
const temp = this.cache.get(key);
this.cache.delete(key);
this.cache.set(key, temp);
return temp;
}
return -1;
}
put(key, value) {
if (this.cache.has(key)) {
this.cache.delete(key);
} else if (this.cache.size >= this.capacity) {
this.cache.delete(this.cache.keys().next().value);
}
this.cache.set(key, value);
}
}
const cache = new LRUCache(2);
cache.put("A", 1);
cache.put("B", 2);
cache.get("A"); // 返回 1
cache.put("C", 3); // 该操作会使得 'B' 作废
cache.get("B"); // 返回 -1 (未找到)
cache.put("D", 4); // 该操作会使得 'A' 作废
cache.get("A"); // 返回 -1 (未找到)
cache.get("C"); // 返回 3
结尾
这篇文章到这就 happy ending 了,从设置 Content-Type 出发,我们一连看了 4 个库的源码,这波血赚不亏。
如果对 Koa 源码感兴趣的同学,请猛击 Koa 源码剖析 & 实现,教你手写一个 “复刻版” Koa.
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!