一、nodejs 之 timer 模块
timer模块开放了一个全局的API(不需要调用require),用于安排函数在未来某个时间点被调用。nodejs中的定时器函数实现了与web浏览器提供的定时器API类似的API,但是基于nodejs事件循环使用了不同的内部实现。timer模块主要有四个相关方法:
- setTimeout(callback[, delay[, ...args]])
- setInterval(callback[, delay[, ...args]])
- setImmediate(callback[, ...args])
- process.nextTick(callback[, ...args])
参数具体用法可到nodejs官网查看,这里不展开,process.nextTick实际属于process模块,为了比较才放在一起。
1、nodejs的event loop
现在来看一下以下几个方法的执行先后,这对后面的解析会有一个更加直观的了解:
Promise.resolve().then(() => console.log("promise1 resolved"));
Promise.resolve().then(() => console.log("promise2 resolved"));
Promise.resolve().then(() => {
console.log("promise3 resolved");
process.nextTick(() =>
console.log("next tick inside promise resolve handler")
);
});
Promise.resolve().then(() => console.log("promise4 resolved"));
Promise.resolve().then(() => console.log("promise5 resolved"));
setImmediate(() => console.log("set immediate1"));
setImmediate(() => console.log("set immediate2"));
process.nextTick(() => console.log("next tick1"));
process.nextTick(() => console.log("next tick2"));
process.nextTick(() => console.log("next tick3"));
setTimeout(() => console.log("set timeout"), 0);
setImmediate(() => console.log("set immediate3"));
setImmediate(() => console.log("set immediate4"));
执行结果为:
next tick1
next tick2
next tick3
promise1 resolved
promise2 resolved
promise3 resolved
promise4 resolved
promise5 resolved
next tick inside promise resolve handler
set timeout
set immediate1
set immediate2
set immediate3
set immediate4
或者
next tick1
next tick2
next tick3
promise1 resolved
promise2 resolved
promise3 resolved
promise4 resolved
promise5 resolved
next tick inside promise resolve handler
set immediate1
set immediate2
set immediate3
set immediate4
set timeout
下面让我们一步步揭开它神秘的面纱:
当 nodejs 启动后,它会初始化事件循环,处理已提供的输入脚本(或丢入 REPL,本文不涉及到),它可能会调用一些异步的 API、调度定时器,或者调用 process.nextTick(),然后开始处理事件循环。如图所示:
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
(1)阶段概述
- timer(定时器):本阶段执行已经被 setTimeout() 和 setInterval() 的调度回调函数;
- pending callbacks(待定回调):执行延迟到下一个循环迭代的 I/O 回调;
- idle,prepare:仅系统内部使用;
- poll(轮询):获取新的 I/O 事件,执行相关回调,在适当条件下把阻塞 node;
- check(检查):setImmediate 回调在此阶段执行;
- close callbacks(关闭的回调函数):一些关闭的回调函数,如:socket.on('close', ...);
日常开发中绝大部分异步任务都是在 timers、poll、check 阶段处理的,下面主要介绍这三部分的内容:
(2)阶段的详细描述
a、timer(定时器)
定时器指定的时间为可以执行所提供的回调的阈值,而不是用户希望其执行的确切时间。简单点说,回调会在用户指定时间或者之后执行,这取决于上下文。 举个例子: 现在同时设置文件的读取(fs.readFile,假设文件读取耗时为95ms,读取完毕后执行耗时10ms的任意操作)以及setTimeout(耗时为100ms),获取setTimeout的执行间隔:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
最后输出的结果为:105ms
这背后的执行过程为:当95ms过后,fs.readFile() 完成读取文件,它的那个需要10ms才能完成的回调,将被添加到轮询队列中并执行。当回调完成时,队列中不再有回调,因此事件循环机制将查看最快到达阈值的计时器,然后将回到计时器阶段,以执行定时器的回调,这也是为什么sentTimeout设置的时间为100ms,但实际执行时间为105ms的原因
b、poll(轮询)
轮询阶段主要有两个任务:
- 计算应该阻塞和轮询I/O的时间
- 处理轮询队列里的事件
当event loop进入 poll 阶段且没有被调度的计时器时:
- 如果 poll 队列不是空的 ,event loop 将循环访问回调队列并同步执行,直到队列已用尽或者达到了系统或达到最大回调数
- 如果poll队列是空的:
- 有 setImmediate() 任务,event loop 会在结束 poll 阶段后进入 check 阶段;
- 没有 setImmediate()任务,event loop 阻塞在 poll 阶段等待回调被添加到队列中,然后立即执行
c、check(检查)
此阶段允许人员在轮询阶段完成后立即执行回调。如果轮询阶段变为空闲状态,并且脚本使用 setImmediate() 后被排列在队列中,则事件循环可能继续到检查阶段而不是等待。
(3)setImmediate() 对比 setTimeout()
setImmediate() 和 setTimeout() 很类似,但是基于被调用的时机,他们也有不同表现:
- setImmediate() 设计为一旦在当前 轮询 阶段完成, 就执行脚本
- setTimeout() 在最小阈值(ms 单位)过后运行脚本
如果运行以下不在 I/O 周期(即主模块)内的脚本,则执行两个计时器的顺序是非确定性的,因为它受进程性能的约束:
// timeout_vs_immediate.js
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
$ node timeout_vs_immediate.js
timeout
immediate
$ node timeout_vs_immediate.js
immediate
timeout
但是,如果你把这两个函数放入一个 I/O 循环内调用,setImmediate 总是被优先调用:
// timeout_vs_immediate.js
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
$ node timeout_vs_immediate.js
immediate
timeout
$ node timeout_vs_immediate.js
immediate
timeout
使用 setImmediate() 相对于setTimeout() 的主要优势是,如果setImmediate()是在 I/O 周期内被调度的,那它将会在其中任何的定时器之前执行,跟这里存在多少个定时器无关
(4)promise对比setTimeout
前端的朋友们应该都听过宏任务(macroTask)和微任务(microTask),promise属于微任务,在浏览器环境下微任务会在每个宏任务执行最末端执行。 在 nodejs 环境下 promise 微任务会在 process.nextTick 任务后执行,在宏任务之前执行完毕
(5)setImmediate()对比process.nextTick()
process.nextTick() 从技术上讲不是事件循环的一部分。相反,它都将在当前操作完成后处理 nextTickQueue, 而不管事件循环的当前阶段如何。这里的一个操作被视作为一个从底层 C/C++ 处理器开始过渡,并且处理需要执行的 JavaScript 代码。 回顾 event loop 的阶段,任何时候再给定的阶段中调用 process.nextTick() ,所有传递到 process.nextTick() 的回调将在事件循环继续之前解析,这也是为什么在前面例子中 promise 执行完以后立即执行其中调用的 process.nextTick() 的原因。 这可能会造成一个问题就是,可以通过递归 process.nextTick() 来‘饿死’I/O,阻止事件循环到达轮询阶段,所以需要谨慎使用 process.nextTick() 。
const fs = require('fs');
fs.readFile('a.txt', (err, data) => {
console.log('read file task done!');
});
let i = 0;
function test(){
if(i++ < 999999) {
console.log(`process.nextTick ${i}`);
process.nextTick(test);
}
}
test();
执行程序将返回:
nextTick 1
nextTick 2
...
...
nextTick 999999
read file task done!
实质上,这两个名称应该交换,因为 process.nextTick() 比 setImmediate() 触发得更快,但这是过去遗留问题,因此不太可能改变。如果贸然进行名称交换,将破坏 npm 上的大部分软件包。
那么是不是编程中应该杜绝使用 process.nextTick 呢?官方推荐大部分时候应该使用 setImmediate,同时对 process.nextTick 的最大调用堆栈做了限制,但 process.nextTick 的调用机制确实也能为我们解决一些棘手的问题:
- 允许用户在 even tloop 开始之前 处理异常、执行清理任务
- 允许回调在调用栈 unwind 之后,下次 event loop 开始之前执行
举个例子:一个类继承了 EventEmitter,而且想在实例化的时候触发一个事件:
const EventEmitter = require('events');
const util = require('util');
function MyEmitter() {
EventEmitter.call(this);
this.emit('event');
}
util.inherits(MyEmitter, EventEmitter);
const myEmitter = new MyEmitter();
myEmitter.on('event', () => {
console.log('an event occurred!');
});
在构造函数执行 this.emit('event') 会导致事件触发比事件回调函数绑定早,使用 process.nextTick 可以轻松实现预期效果
const EventEmitter = require('events');
const util = require('util');
function MyEmitter() {
EventEmitter.call(this);
// use nextTick to emit the event once a handler is assigned
process.nextTick(() => {
this.emit('event');
});
}
util.inherits(MyEmitter, EventEmitter);
const myEmitter = new MyEmitter();
myEmitter.on('event', () => {
console.log('an event occurred!');
});
(6)例题解析
在上面的例子里,会发生以下行为:
- 循环将会辨识出在 process.nextTick 队列中有 3 项,Node 将会开始处理 nextTick 队列直到队列为空。
- 然后事件循环将会检查 promises 微队列并且辨识出有 5 项,然后开始处理队列。
- 在 promises 微队列处理过程中,process.nextTick 队列中再次被添加一项。
- promises 微队列被处理完后,事件循环会再次检测到 process.nextTick 队列中有一项(在处理 promises 微队列过程中添加的)。然后 node 将会处理 nextTick 队列中剩余的一项。
- 这时没有需要处理的微任务了。然后事件循环移到第一个阶段,timers 阶段。这时,它会发现在计时器队列中有一个过期的 timer 回调,然后会处理这个回调。
- 现在没有其他定时器回调了,循环将会等待 I/O。因为我们没有任何的即将发生的(pengding) I/O,循环会继续,开始处理 setImmediate 队列。它在 immediate 队列中发现了 4 项,并且处理它们,直到 immediate 队列为空。
- 循环结束(步骤5和步骤6执行顺序不确定,取决于上下文)
二、nodejs之stream模块
nodejs诞生是为了解决 I/O 密集的 Web 性能问题,最常使用的两个模块就是文件系统和网络,而这两个模块都是 stream 的重度用户,stream 是 nodejs 从入门到进阶的必经之路 流(stream)是 nodejs 中处理流式数据的抽象接口,stream 模块用于构建实现了流接口的对象。从术语上讲流是对输入输出设备的抽象,是一组有序的、有起点和终点的字节数据传输手段。
1、为什么使用stream
有个用户 Web 在线看视频的场景,假定我们通过 HTTP 请求返回给用户电影内容,那么代码可能写成这样
const http = require('http');
const fs = require('fs');
http.createServer((req, res) => {
fs.readFile(moviePath, (err, data) => {
res.end(data);
});
}).listen(8080);
这样的代码有两个明显的问题:
- 电影文件需要读完之后才能返回给客户,等待时间超长
- 电影文件需要一次放入内存中,内存吃不消
使用 stream 可以把电影文件一点点的放入内存中,然后一点点的返回给客户(利用了 HTTP 协议的 Transfer-Encoding: chunked 分段传输特性),用户体验得到优化,同时对内存的开销明显下降:
const http = require('http');
const fs = require('fs');
http.createServer((req, res) => {
fs.createReadStream(moviePath).pipe(res);
}).listen(8080);
通过管道我们还可以在某一阶段对数据进行相应的处理,由此可以看出stream使代码优雅了很多,功能逻辑独立,拓展也比较简单,像知名的gulp正是基于stream写出的自动化构建工具
2、stream的分类
nodejs中有四种基本的流类型:
- Writable - 可写入数据的流(例如 fs.createWriteStream()
- Readable - 可读取数据的流(例如 fs.createReadStream())
- Duplex - 可读又可写的流(例如 net.Socket)
- Transform - 在读写过程中可以修改或转换数据的 Duplex 流(例如 zlib.createDeflate())
下面将围绕这四种基本流展开描述。
3、Readable-可读流
可读流的例子包括:
- 客户端的 HTTP 响应
- 服务器的 HTTP 请求
- fs 的读取流
- zlib 流
- crypto 流
- TCP socket
- 子进程 stdout 与 stderr
- process.stdin
(1)可读流模式
可读流可运作于两种模式:流动模式(flowing)和暂停模式(paused)。这些模式与对象模式分开,无论是出于流动模式或暂停模式,可读流都可以出于对象模式。
- 在流动模式中,数据自动从底层系统读取,并通过 EventEmitter 接口的事件尽可能快地被提供给应用程序
- 在暂停模式中,必须显式调用 stream.read() 读取数据块
所有可读流开始都处于暂停模式,可以通过下列方式切换到流动模式:
- 添加 'data' 事件句柄
- 调用 stream.resume() 方法
- 调用 stream.pipe() 方法将数据发送到可写流
可读流可以通过以下方式切换回暂停模式:
- 如果没有管道目标,则调用 stream.pause()
- 如果有管道目标,则移除所有管道目标。调用 stream.unpipe() 可以移除多个管道目标
(2)可读流状态
在任意时刻,可读流会处于以下三种状态之一:
- readable.readableFlowing === null
- readable.readableFlowing === false
- readable.readableFlowing === true
当 readable.readableFlowing 为 null 时,没有提供消费流数据的机制,所以流不会产生数据。 在这个状态下,监听 'data' 事件、调用 readable.pipe()、或调用 readable.resume() 都会使 readable.readableFlowing 切换到 true,可读流开始主动地产生数据并触发事件; 调用 readable.pause()、 readable.unpipe()、或接收到背压(back-pressure),则 readable.readableFlowing 会被设为 false,暂时停止事件流动但不会停止数据的生成。 在这个状态下,为 'data' 事件绑定监听器不会使 readable.readableFlowing 切换到 true;
(3)可读流事件
可读流可以监听的事件包括:
- on(event: "close", listener: () => void): this
当流或其底层资源(比如文件描述符)被关闭时触发 'close' 事件。 该事件表明不会再触发其他事件,也不会再发生操作
- on(event: "data", listener: (chunk: any) => void): this;
对于非对象模式的流, chunk 可以是字符串或 Buffer。 对于对象模式的流, chunk 可以是任何 JavaScript 值,除了 null
- on(event: "end", listener: () => void): this;
'end' 事件只有在数据被完全消费掉后才会触发。 要想触发该事件,可以将流转换到流动模式,或反复调用 stream.read() 直到数据被消费完
- on(event: "error", listener: (err: Error) => void): this;
'error' 事件可能随时由 Readable 实现触发。 通常,如果底层的流由于底层内部的故障而无法生成数据,或者流的实现尝试推送无效的数据块,则可能会发生这种情况
- on(event: "pause", listener: () => void): this;
当调用 stream.pause() 且 readsFlowing 不为 false 时,就会触发 'pause' 事件
- on(event: "readable", listener: () => void): this;
当有数据可从流中读取时,就会触发 'readable' 事件;当到达流数据的尽头时, 'readable' 事件也会触发,但是在 'end' 事件之前触发 如果同时使用 'readable' 事件和 'data' 事件,则 'readable' 事件会优先控制流,也就是说,当调用 stream.read() 时才会触发 'data' 事件, readableFlowing 属性会变成 false。 当移除 'readable' 事件时,如果存在 'data' 事件监听器,则流会开始流动,也就是说,无需调用 .resume() 也会触发 'data' 事件
- on(event: "resume", listener: () => void): this;
当调用 stream.resume() 且 readsFlowing 不为 true 时,将会触发 'resume' 事件
(4)自定义可读流
如果你想以某种特定的方式生产数据,交给程序消费,那可以这么做:
- 继承 sream 模块的 Readable 类
- 重写 _read 方法,调用 this.push 将生产的数据放入待读取队列
举一个例子:实现一个每100ms生产一个随机数的流,最大数量为5:
const Readable = require('stream').Readable;
class RandomNumberStream extends Readable {
constructor(max, options) {
super(options || null);
this.max = max;
}
_read() {
setTimeout(() => {
if (this.max) {
const randomNumber = parseInt(Math.random() * 10000);
// 只能 push 字符串或 Buffer,为了方便显示打一个回车
this.push(`${randomNumber}\n`);
this.max -= 1;
} else {
this.push(null);
}
}, 100);
}
}
module.exports = RandomNumberStream;
执行看一下效果:
const RandomNumberStream = require('./RandomNumberStream');
const rns = new RandomNumberStream(5);
rns.pipe(process.stdout);
// node index.js
6334
6632
3232
3941
300
每隔100ms向缓冲区推送一个数字,那么就像读取一个本地文件总有读完的时候,如何停下来呢?向缓冲区push一个null就可以了
为什么是setTimeout而不是setInterval? 流在默认状态下是处于暂停模式的,也就是需要程序显式的调用 read() 方法,可上面例子中并没有调用就可以得到数据,因为流通过 pipe() 方法切换成了流动模式,这样 _read() 方法会自动被反复调用,直到数据读取完毕,所以每次 _read() 方法里面只需要读取一次数据即可
(5)如何读取可读流数据
结合上面的事件在不同模式下如何读取可读流的数据呢?
- 在流动模式下,监听data事件进行读取
- 在暂停模式下,使用read()方法读取
a、流动模式-data事件
所有可读流开始都处于暂停模式,通过监听data事件,流就进入了流动模式,仍然是上面的例子:
const RandomNumberStream = require('./RandomNumberStream');
const rns = new RandomNumberStream(5);
rns.on('data', chunk => {
console.log(chunk);
});
这样可以看到控制台打印出类似下面的buffer结果:
<Buffer 39 35 37 0a>
<Buffer 31 30 35 37 0a>
<Buffer 38 35 31 30 0a>
<Buffer 33 30 35 35 0a>
<Buffer 34 36 34 32 0a>
如果想显示数字,可以调用buffer的toString()方法
b、暂停模式-read()方法
流在暂停模式下需要程序显式调用 read() 方法才能得到数据,read() 方法会从内部缓冲区中拉取并返回若干数据,当没有更多可用数据时,会返回null。 使用 read() 方法读取数据时,如果传入了 size 参数,那么它会返回指定字节的数据;当指定的size字节不可用时,则返回null。如果没有指定size参数,那么会返回内部缓冲区中的所有数据
const RandomNumberStream = require('./RandomNumberStream');
const rns = new RandomNumberStream(5);
const chunk = rns.read();
console.log(chunk);
但是控制台打印的结果却是null,这是因为读取的数据还没准备好,如果使用轮询的方式去查询未免效率低下,这个时候我们可以使用可读流的readable事件,正如前面介绍的,当有数据可从流中读取时,就会触发 'readable' 事件,所以代码为:
const RandomNumberStream = require('./RandomNumberStream');
const rns = new RandomNumberStream(5);
rns.on('readable', () => {
let chunk;
if((chunk=rns.read()) !== null) {
console.log(chunk);
}
})
执行结果与data事件的执行结果相同
<Buffer 36 36 37 35 0a>
<Buffer 33 32 37 39 0a>
<Buffer 31 35 35 35 0a>
<Buffer 31 34 39 36 0a>
<Buffer 32 35 39 36 0a>
4、Writable-可写流
可写流的例子包括:
- 客户端的 HTTP 请求
- 服务器的 HTTP 响应
- fs 的写入流
- zlib 流
- crypto 流
- TCP socket
- 子进程 stdin
- process.stdout、process.stderr
不同于可读流,可写流没有模式分类,自然也没有状态之分,下面直接介绍可写流相关的事件
(1)可写流事件
可写流可以监听的事件包括:
- on(event: "close", listener: () => void): this;
当流或其底层资源(比如文件描述符)被关闭时触发。 表明不会再触发其他事件,也不会再发生操作
- on(event: "drain", listener: () => void): this;
如果调用 stream.write(chunk) 返回 false,则当可以继续写入数据到流时会触发 'drain' 事件
- on(event: "error", listener: (err: Error) => void): this;
如果在写入或管道数据时发生错误,则会触发 'error' 事件。 当调用时,监听器回调会传入一个 Error 参数
- on(event: "finish", listener: () => void): this;
调用 stream.end() 且缓冲数据都已传给底层系统之后触发
- on(event: "pipe", listener: (src: Readable) => void): this;
当在可读流上调用 stream.pipe() 方法时会发出 'pipe' 事件,并将此可写流添加到其目标集
- on(event: "unpipe", listener: (src: Readable) => void): this;
在可读流上调用 stream.unpipe() 方法时会发出 'unpipe'事件,从其目标集中移除此可写流;当可读流通过管道流向可写流发生错误时,也会触发此事件
(2)自定义可写流
调用可写流实例的 write() 方法就可以把数据写入可写流,write()方法有三个参数:
- chunk: | | | 要写入的数据
对于非对象模式的流, chunk 必须是字符串、 Buffer 或 Uint8Array。 对于对象模式的流, chunk 可以是任何 JavaScript 值,除了 null
- encoding: 如果chunk是字符串,则指定字符编码,默认值为'utf8'
- callback:当数据块被输出到目标后的回调函数
const fs = require('fs');
const rs = fs.createReadStream('./w.js');
const ws = fs.createWriteStream('./copy.js');
rs.setEncoding('utf-8');
rs.on('data', chunk => {
ws.write(chunk);
});
可自定义可读流类似,简单的自定义可写流只需要两部:
- 继承stream模块的Writable类
- 实现_write()方法
下面是一个简单的例子:
const Writable = require("stream").Writable;
class OutputStream extends Writable {
constructor(options) {
super(options || null);
}
_write(chunk, enc, done) {
process.stdout.write(`${chunk.toString()}`);
setTimeout(done, 1000);
}
}
module.exports = OutputStream;
值的注意的是,在官网的介绍中有这么一段描述:
当流还未被排空时,调用 write() 会缓冲 chunk,并返回 false。 一旦所有当前缓冲的数据块都被排空了(被操作系统接收并传输),则触发 'drain' 事件。 建议一旦 write() 返回 false,则不再写入任何数据块,直到 'drain' 事件被触发。 当流还未被排空时,也是可以调用 write(),Node.js 会缓冲所有被写入的数据块,直到达到最大内存占用,这时它会无条件中止。 甚至在它中止之前, 高内存占用将会导致垃圾回收器的性能变差和 RSS 变高(即使内存不再需要,通常也不会被释放回系统)。 如果远程的另一端没有读取数据,TCP 的 socket 可能永远也不会排空,所以写入到一个不会排空的 socket 可能会导致远程可利用的漏洞 这也跟后面介绍的背压(back-pressure)有关
5、背压(back-pressure)
在数据处理过程中会出现一个叫做背压的常见问题,它描述了数据传输过程中缓冲区后面数据的累积,当传输的接收端具有复杂的操作时,或者由于某种原因速度较慢时,来自传入源的数据就有累积的趋势,就像阻塞一样。 举个例子:现在想把某个文件下载下来并进行压缩,那么在该过程可能发生以下情况,下载速度为3Mb/s,当压缩速度为1Mb/s,这样的话,很快缓冲队列就会形成堆积,这会造成
- 明显使其它进程处理变慢
- 太多繁重的垃圾回收
- 内存好近
在nodejs中为解决这个问题,提供了pipe()或者pipeline()方法,它主要依靠几个方面来建立背压机制:
- 将数据按照chunk进行划分,写入
- 当chunk过大,或者队列忙碌时,暂停读取
- 当队列为空时,继续读取数据
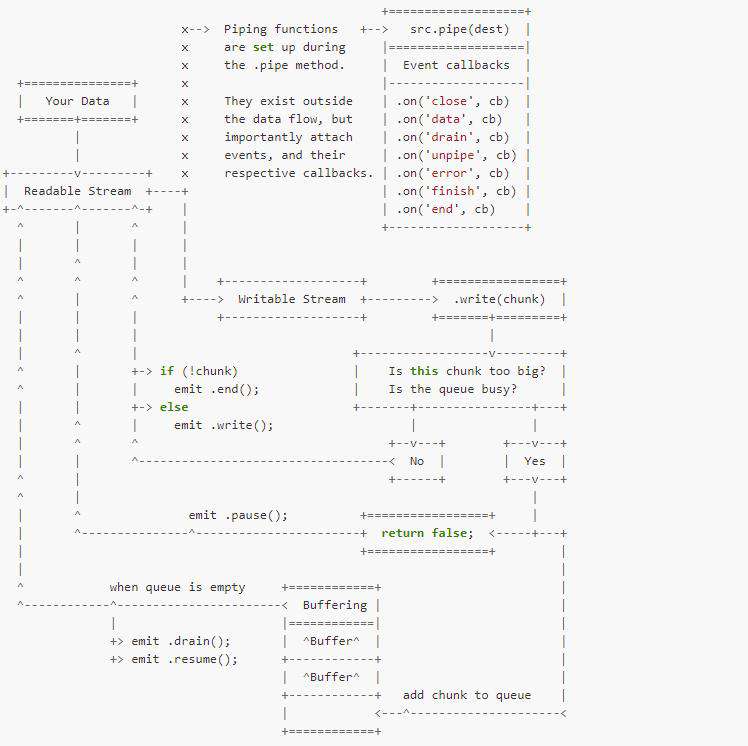 根据上面的原理,结合之前可读流和可写流的举例代码,实现一个简单的背压机制:
根据上面的原理,结合之前可读流和可写流的举例代码,实现一个简单的背压机制:
// random-number-stream.js
const Readable = require("stream").Readable;
class RandomNumberStream extends Readable {
constructor(max, options) {
super(options || null);
this.max = max;
}
_read() {
setTimeout(() => {
if (this.max) {
const randomNumber = parseInt(Math.random() * 10000);
// 只能 push 字符串或 Buffer,为了方便显示打一个回车
this.push(`${randomNumber}\n`);
this.max -= 1;
} else {
this.push(null);
}
}, 100);
}
}
module.exports = RandomNumberStream;
//output-stream.js
const Writable = require("stream").Writable;
class OutputStream extends Writable {
constructor(options) {
super(options || null);
}
_write(chunk, enc, done) {
process.stdout.write(`${chunk.toString()}`);
setTimeout(done, 1000);
}
}
module.exports = OutputStream;
// index.js
const RandomNumberStream = require('./random-number-stream');
const OutputStream =require('./output-stream');
const rns = new RandomNumberStream(5);
const os = new OutputStream({
highWaterMark: 8,
})
rns.on('data', chunk => {
if(os.write(chunk) === false) {
console.log('pause');
rns.pause();
}
})
os.on('drain', () => {
console.log('drain');
rns.resume();
})
根据前面的介绍,当流还未被排空时,调用 write() 会缓冲 chunk,并返回 false,这个时候就证明读取的数据多于写入的数据,这个时候就可以暂停读取
又如果调用 stream.write(chunk) 返回 false,则当可以继续写入数据到流时会触发 'drain' 事件,这个时候证明了缓冲的chunk已经全部写入目标,可以继续读取新的数据进行写入,循环往复,直到数据全部读取完成并写入
6、Duplex-双工流
双工流(Duplex)是同时实现了 Readable 和 Writable 接口的流 Duplex 流的例子包括:
- TCP socket
- zlib 流
- crypto 流
(1)Duplex实例化
使用new stream.Duplex(options)即可进行实例化,下面介绍一下options的相关参数:
- allowHalfOpen : 如果设为 false,则当可读端结束时,可写端也会自动结束。 默认为 true
- readable :设置双工流是否可读,默认值为:true
- writable :设置双工流是否可写,默认值为:true
- readableObjectMode 设置流的可读端为 objectMode。 如果 objectMode 为 true,则不起作用。 默认为 false
- writableObjectMode 设置流的可写端为 objectMode。 如果 objectMode 为 true,则不起作用。 默认为 false
- readableHighWaterMark 设置流的可读端的 highWaterMark。 如果已经设置了 highWaterMark,则不起作用
- writableHighWaterMark 设置流的可写端的 highWaterMark。 如果已经设置了 highWaterMark,则不起作用
(2)自定义双工流
和 Readable、Writable 实现方法类似,实现 Duplex 流非常简单,但 Duplex 同时实现了 Readable 和 Writable, NodeJS 不支持多继承,所以我们需要继承 Duplex 类:
- 继承Duplex类
- 实现_read()方法
- 实现_write()方法
这里我们直接使用官网的例子:
const Duplex = require('stream').Duplex;
const kSource = Symbol('source');
class MyDuplex extends Duplex {
constructor(source, options) {
super(options);
this[kSource] = source;
}
_write(chunk, encoding, callback) {
// The underlying source only deals with strings
if (Buffer.isBuffer(chunk))
chunk = chunk.toString();
this[kSource].writeSomeData(chunk);
callback();
}
_read(size) {
this[kSource].fetchSomeData(size, (data, encoding) => {
this.push(Buffer.from(data, encoding));
});
}
}
双工流最重要的方面是,可读端和可写端相互独立于彼此地共存同一个对象实例中
7、Transform-转换流
转换流(Transform)也是一种 Duplex 流,但它的输出与输入是相关联的。 与 Duplex 流一样, Transform 流也同时实现了 Readable 和 Writable 接口 Duplex 流的例子包括:
- zlib 流
- crypto 流
虽然会从可读流进入可写流,但并不意味这两者的数据量相同,上面说的一定的处理逻辑会决定如果 tranform 可读流,然后放入可写流,transform 原义即为转变,很贴切的描述了 Transform 流作用 最常见的压缩、解压缩用的 zlib 即为 Transform 流,压缩、解压前后的数据量明显不同,而流的作用就是输入一个 zip 包,输出一个解压文件或反过来。我们平时用的大部分双工流都是 Transform。
(1)转换流事件
转换流可以监听的事件包括:
- 'end'事件
'end' 事件来自 stream.Readable 类。 当调用了 transform._flush() 中的回调函数并且所有数据已经输出之后,触发 'end' 事件。 如果出现错误,则不应触发 'end'
- 'finish'事件
'finish' 事件来自 stream.Writable 类。 当调用了 stream.end() 并且 stream._transform() 处理完全部数据块之后,触发 'finish' 事件。 如果出现错误,则不应触发 'finish'
(2)自定义转换流
Tranform 类内部继承了 Duplex 并实现了 writable.write() 和 readable._read() 方法,自定义一个 Transform 流,只需要三个步骤 1、继承 Transform 类 2、实现 _transform() 方法 3、实现 _flush() 方法(可以不实现)
_transform(chunk, encoding, callback) 方法用来接收数据,并产生输出,参数我们已经很熟悉了,和 Writable 一样, chunk 默认是 Buffer,除非 decodeStrings 被设置为 false 在 _transform() 方法内部可以调用 this.push(data) 生产数据,交给可写流,也可以不调用,意味着输入不会产生输出 当数据处理完了必须调用 callback(err, data) ,第一个参数用于传递错误信息,第二个参数可以省略,如果被传入了,效果和 this.push(data) 一样
transform.prototype._transform = function (data, encoding, callback) {
this.push(data);
callback();
};
transform.prototype._transform = function (data, encoding, callback) {
callback(null, data);
};
8、Duplex 对比 Transform
了解了 Readable 和 Writable 之后,理解双工流十分自然,但两者的区别会让一些初学者困惑,简单的区分:Duplex 的可读流和可写流之间并没有直接关系,Transform 中可读流的数据会经过处理后自动放入可写流中。 看两个简单的例子就能直观了解到 Duplex 和 Transform 的区别
(1)TCP socket
net 模块可以用来创建 socket,socket 在 NodeJS 中是一个典型的 Duplex,看一个 TCP 客户端的例子
var net = require('net');
//创建客户端
var client = net.connect({port: 1234}, function() {
console.log('已连接到服务器');
client.write('Hi!');
});
//data事件监听。收到数据后,断开连接
client.on('data', function(data) {
console.log(data.toString());
client.end();
});
//end事件监听,断开连接时会被触发
client.on('end', function() {
con
可以看到 client 就是一个 Duplex,可写流用于向服务器发送消息,可读流用于接受服务器消息,两个流内的数据并没有直接的关系。
(2)gulp
gulp 非常擅长处理代码本地构建流程,看一段官网的示例代码:
function css() {
return src('client/templates/*.less')
.pipe(less())
.pipe(minifyCSS())
.pipe(dest('build/css'))
}
可以看出来,less() 和 minify() 都是对输入数据做了些特殊处理,然后交给了输出数据。这样简单的对比就能看出 Duplex 和 Transform 的区别,在平时使用的时候,当一个流同时面向生产者和消费者服务的时候会选择 Duplex,当只是对数据读取后需要对之做一些转换工作的时候就会选择使用 Tranform
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!