无头浏览器是什么
无头(headless)浏览器是一种没有图形界面的web浏览器。
无头浏览器对于测试web页面特别有用,因为它们能够以与浏览器相同的方式展示和解析HTML,包括页面布局、颜色、字体选择以及JavaScript和Ajax的执行等样式元素,而这些元素在使用其他测试方法时通常不可用。[1]
无头浏览器能做什么
无头浏览器可以用来做很多事情,包括但不限于:
- web页面测试
- web页面截图
- 将web页面生成pdf文件
- 测试javascript库
- 自动提交表单
- 爬虫
如何使用无头浏览器
生成pdf文件
使用无头浏览器其实很简单,只要安装了node,其实不需要安装任何库也可以使用。
以chrome为例,chrome提供了许多命令行指令,其中包括使用无头的形式 --headless,chrome的所有启动参数
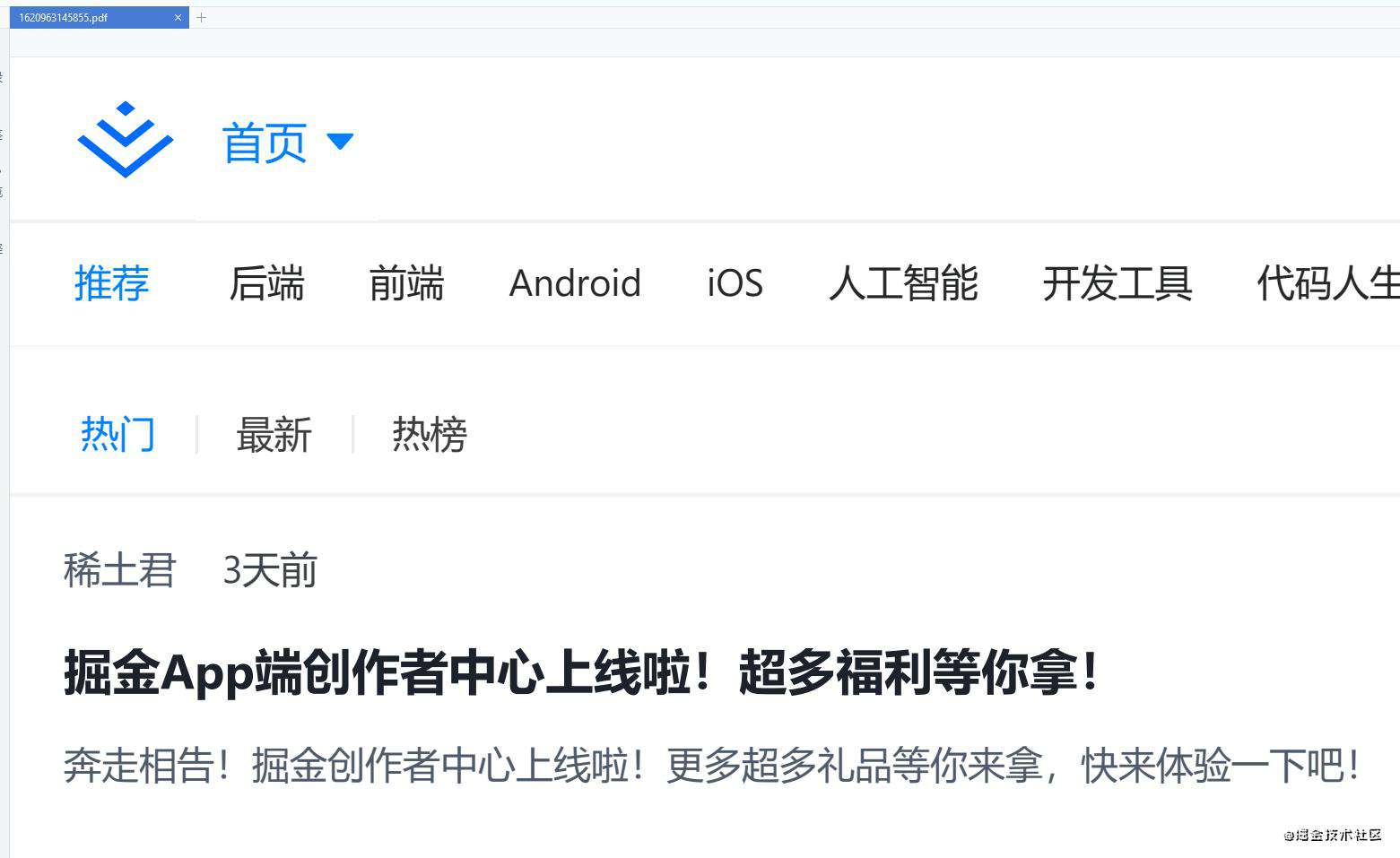
如果我们需要将网页展示的内容生成为pdf,则需要用到--print-to-pdf参数,代码如下:
执行后会将网页生成pdf文件保存到指定目录
生成网页图片
同理如果我们需要生成网页快照,只需将上面代码--print-to-pdf改为--screenshot
抓取网页信息
无头浏览器库 puppeteer
从上面的例子可以看到,其实我们不需要任何插件仅仅需要node和浏览器,就可以调用无头浏览器。但是可以看出来,多且繁杂的启动参数命令使得原生无头浏览器难以使用。因此我们可以使用一些无头浏览器的库简化操作。
puppeteer 是 Chrome 开发团队在 2017 年发布的一个 Node.js 包,用来模拟 Chrome 浏览器的运行。puppeteer 是用js封装操控浏览器的功能。使我们更容易地调用浏览器的功能。
如:获取网页截图
将网页转为pdf
执行脚本
自动表单提交
更多的功能点击这里
总结
- 无头(headless)浏览器是一种没有图形界面的web浏览器。
- 无头浏览器可以用来进行web页面测试,网页截图,将网页生成pdf,测试javscript库,自动提交表单,爬虫等功能
参考文章
- Headless browser, wiki
- 无头浏览器 Puppeteer 初探
- chrome启动参数大全
文中如有错误,欢迎在评论区指正
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!