如果你需要处理复杂的字符串相关的功能,可以考虑使用正则表达式。
正则有两种作用,一种是查找字符,另外一种是替换字符
在学习正式的概念之前,我们通过一系列的案例来快速了解正则,然后再深入讲解一些正则的概念。
这里推荐正则练习网站:regexr.com/
通过这个网站可以跟着下面的案例快速学习正则的基础知识点。
浅出案例
正则的写法:
let reg=/.../
...就是你想匹配的内容,比如我希望在一连串的英文中匹配我的名字:qiuyanxi,怎么办呢?
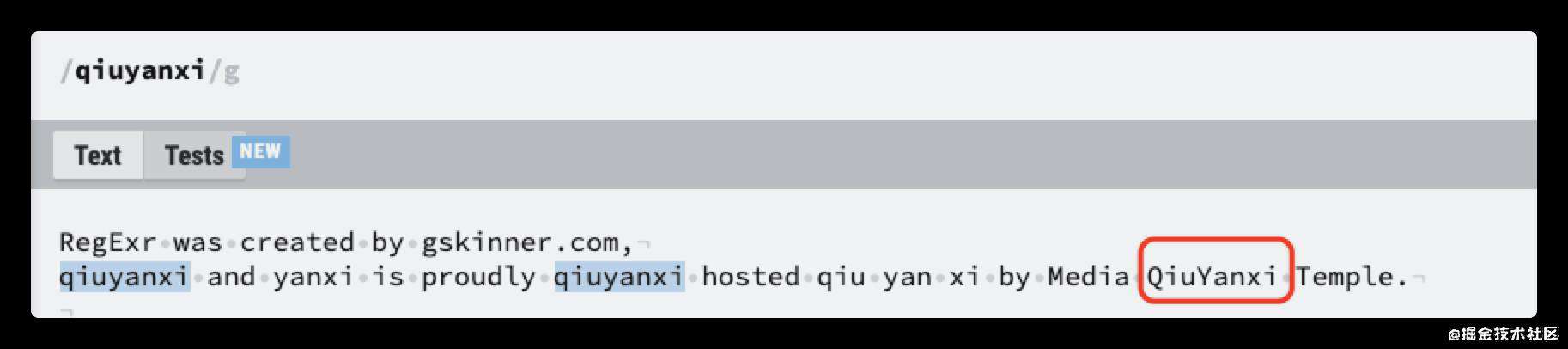
RegExr was created by gskinner.com,
qiuyanxi and yanxi is proudly qiuyanxi hosted qiu yan xi by Media QiuYanxi Temple.
我就直接写/qiuyanxi/就可以正确匹配到。
g修饰符-全局
这样只能访问到第一个,如果我希望访问到所有,也就是全局文字里的 qiuyanxi,这种匹配方式,我们称之为横向匹配模式,需要用到一个修饰符 g,表示全局匹配。它是这样写的/qiuyanxi/g
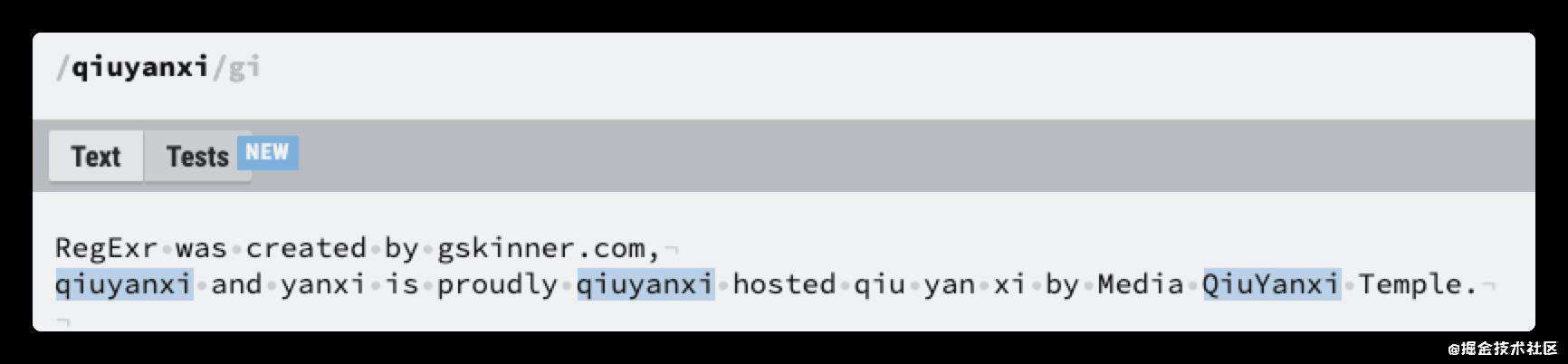
i 修饰符-大小写
可以看到,上面的模式都是精准匹配字符,哪怕大写字母也是不行的,但是我还是希望能匹配到大写字符,则可以使用 i 修饰符,它是这样写的qiuyanxi/gi
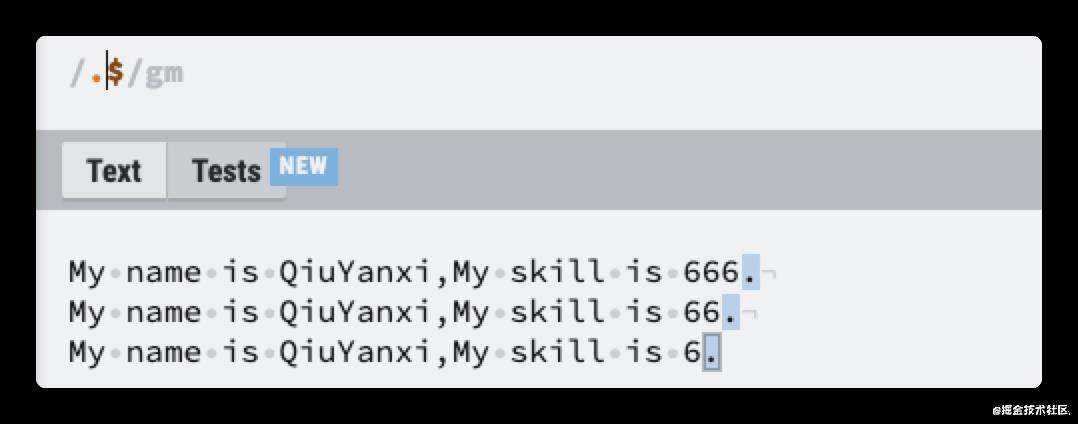
\d 和[0-9]
现在我们转换一下文字
My name is QiuYanxi,my skill is 666.
My name is QiuYanxi,my skill is 66.
My name is QiuYanxi,my skill is 6.
我希望能够匹配里面的数字,数字一般是0-9,如果你写成10-100,正则并不能帮你找10-100的数字,因为正则是挨个字符匹配的,它不认识数字大小。所以要记得正则里面的数字都是用0-9表示的。
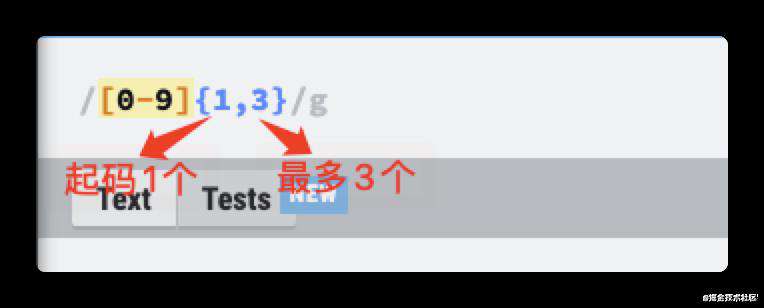
也就是说我希望能够匹配到0-9其中的一个,这种匹配模式,我们称之为纵向匹配,可以用字符组[]进行匹配。它是这样写的
/[0-9]/g
 注意看图中的红框,它的意思是匹配到了6个字符,也就是说,上面这种写法虽然可以匹配到数字,但是每个数字都拆开来匹配了。
注意看图中的红框,它的意思是匹配到了6个字符,也就是说,上面这种写法虽然可以匹配到数字,但是每个数字都拆开来匹配了。
我们并不想这样实现,所以我希望告诉正则,我想要匹配到的数量,那么就需要用到量词
量词使用{}表示,它是这样用的
这样我们就可以完整匹配到6,66,666三个数字了。
如果不想匹配到这三个数字呢,也是可以做到的,可以使用[^...]
在中括号中 ^ 可以表示为非的意思。
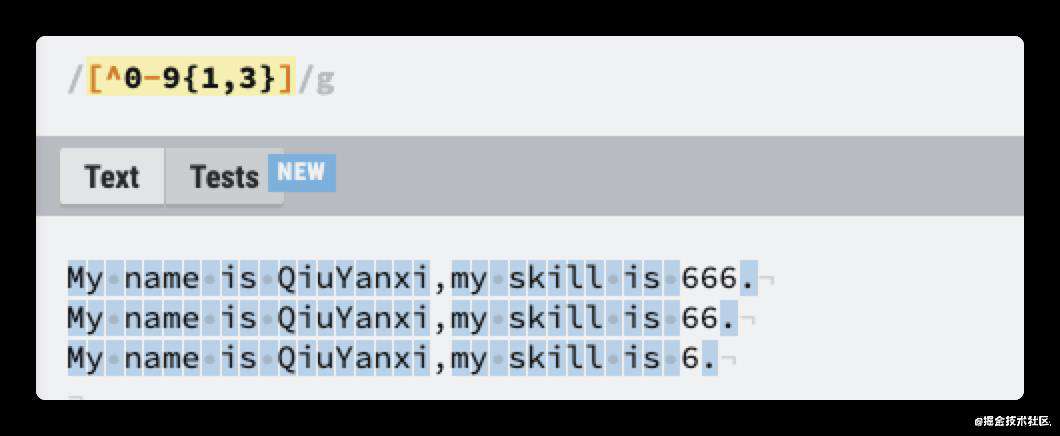
简写字符
在使用字符组时,我们可以用[0-9A-Za-z]表示所有数字+大小写字母的任一字符,这里有简写形式
以下为常用字符集
| 简写 | 描述 | . | 除换行符外的所有字符 | \w | 匹配所有字母数字,等同于 [a-zA-Z0-9_] | \W | 匹配所有非字母数字,即符号,等同于: [^\w] | \d | 匹配数字: [0-9] | \D | 匹配非数字: [^\d] | \s | 匹配所有空格字符,等同于: [\t\n\f\r\p{Z}] | \S | 匹配所有非空格字符: [^\s] | \f | 匹配一个换页符 | \n | 匹配一个换行符 | \r | 匹配一个回车符 | \t | 匹配一个制表符 | \v | 匹配一个垂直制表符 | \p | 匹配 CR/LF(等同于 \r\n),用来匹配 DOS 行终止符 |
|---|
这里以.为例,我可以匹配除换行符外的所有字符。
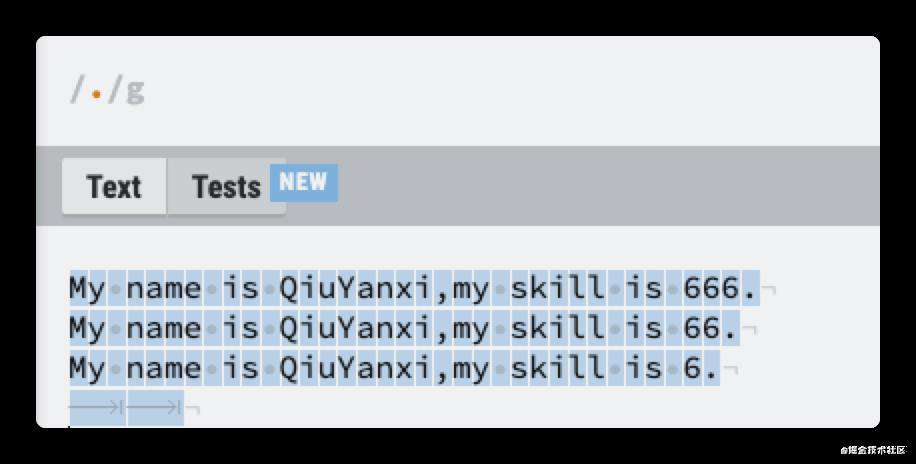
那要是想要匹配点怎么办?这就跟 JS 一样,用到转义符了,正则的转义符是\
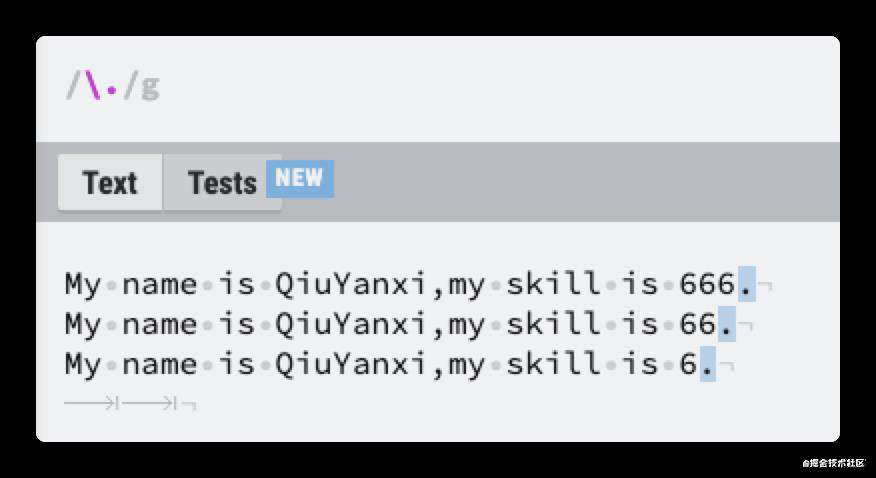 上面就是只匹配点符号。
上面就是只匹配点符号。
开头位置和结尾位置
下面字符中我希望能匹配到 My,应该如何做呢?
My name is QiuYanxi,My skill is 666.
My name is QiuYanxi,My skill is 66.
My name is QiuYanxi,My skill is 6.
很简单,使用/My/g就可以匹配到,但是我只想匹配到第一个 My,需要怎样做呢?还是使用^这个元字符,它放在中括号里的意思表示非,不放在中括号里则表示开头。
它是这样写的
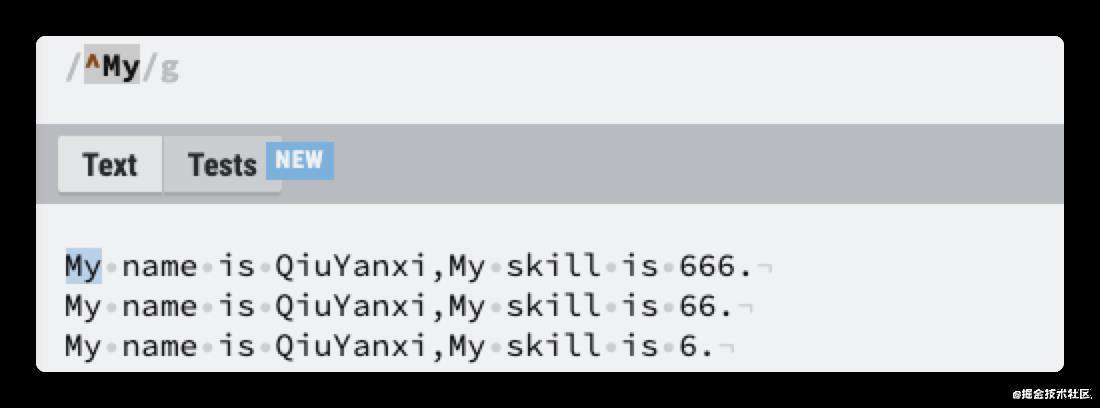
匹配成功了,这里看到另起一行没有匹配到。这是因为对于正则来说,换行符只不过是一个符号而已,我们需要让正则知道,我们希望它能匹配多行。这时候可以使用m 这个修饰符,它跟 g 一样都属于修饰符。
以下例子就是修饰符 m 的使用
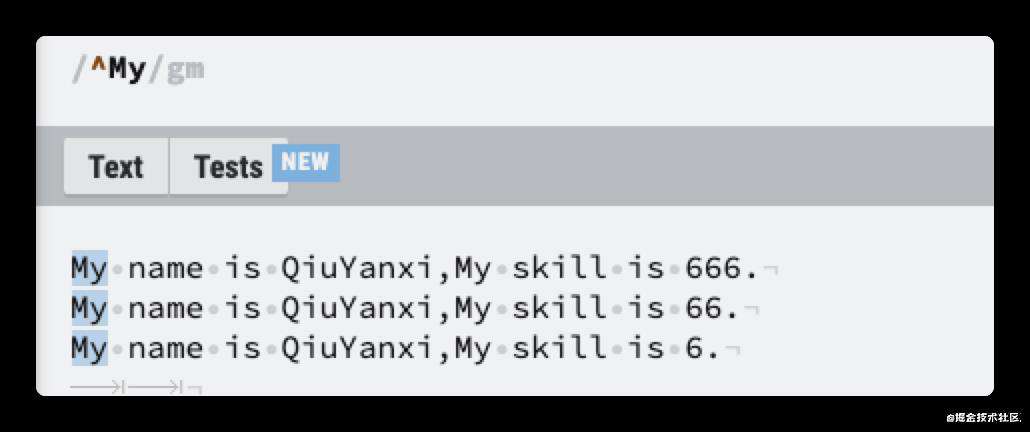
所谓有头必然有尾,结尾则使用$这个元字符。
元字符
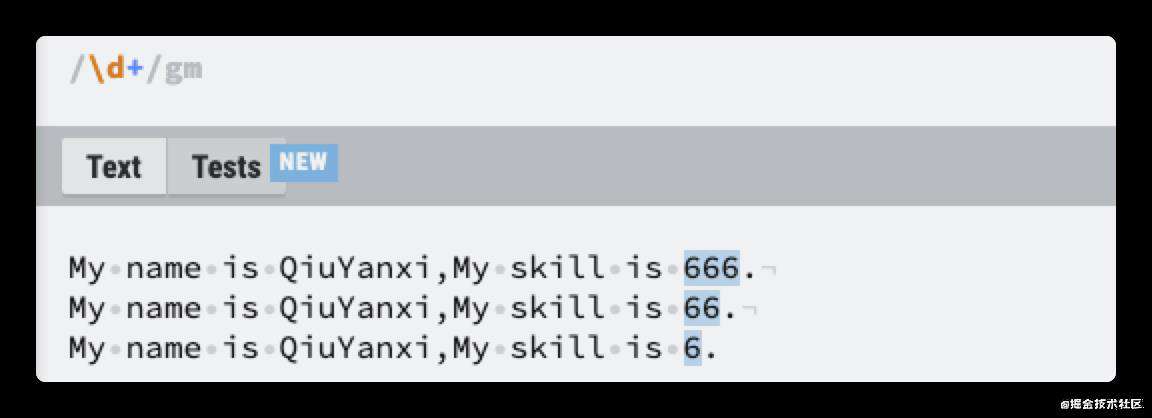
简写字符可以帮助我们将[0-9]用更简单的\d代替,那么量词呢?量词也有一些元字符可以帮助我们简写.
上面已经介绍了量词采用大括号表示,{最少位,最大位},例如
{0,1} 可以没有,最多1
{1,} 最少1,最多不限
{0,} 零个到无限个
使用元字符来替代就是
{0,1} ==> ?
{1,} ==> +
{0,} ==> *
例如,\d{1,}表示1个数字,无上限。可以用\d+表示
另外两个元字符是一样的使用方式。这里附上常用元字符表
| 元字符 | 描述 | . | 句号匹配任意单个字符除了换行符。 | [ ] | 字符种类。匹配方括号内的任意字符。 | [^ ] | 否定的字符种类。匹配除了方括号里的任意字符 | * | 匹配>=0个重复的在*号之前的字符。 | + | 匹配>=1个重复的+号前的字符。 | ? | 标记?之前的字符为可选. | {n,m} | 匹配num个大括号之前的字符或字符集 (n <= num <= m). | (xyz) | 字符集,匹配与 xyz 完全相等的字符串. | | | 或运算符,匹配符号前或后的字符. | \ | 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ | | ^ | 从开始行开始匹配. | $ | 从末端开始匹配. |
|---|
这里面比较重要的是中括号[]字符集、小括号()分组和管道符|。
中括号字符集已经基本了解了,在纵向匹配时使用,匹配其中之一的,比如[tT]就可以匹配 t 或者 T ,在里面没有顺序。
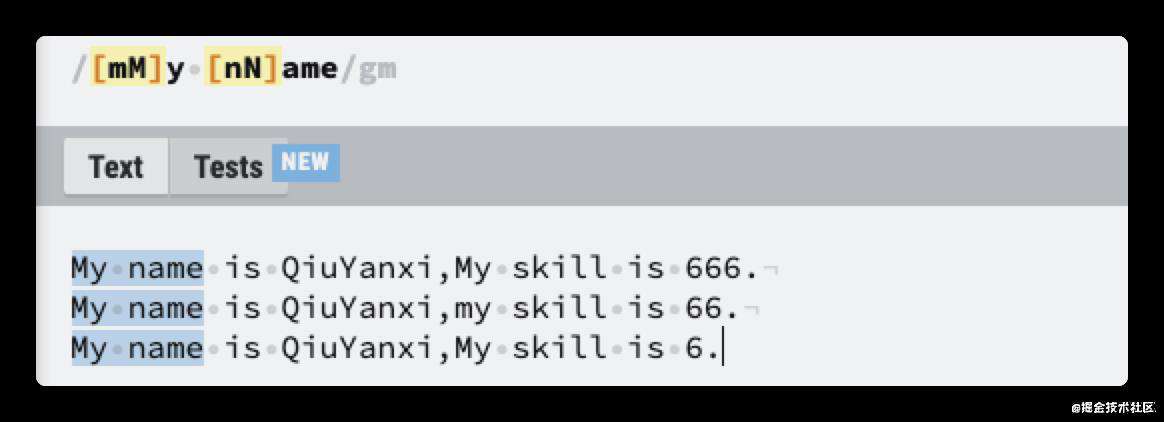
上面的例子还可以使用小括号()和管道符|写。
小括号()是分组,表示为整体。
管道符|表示或
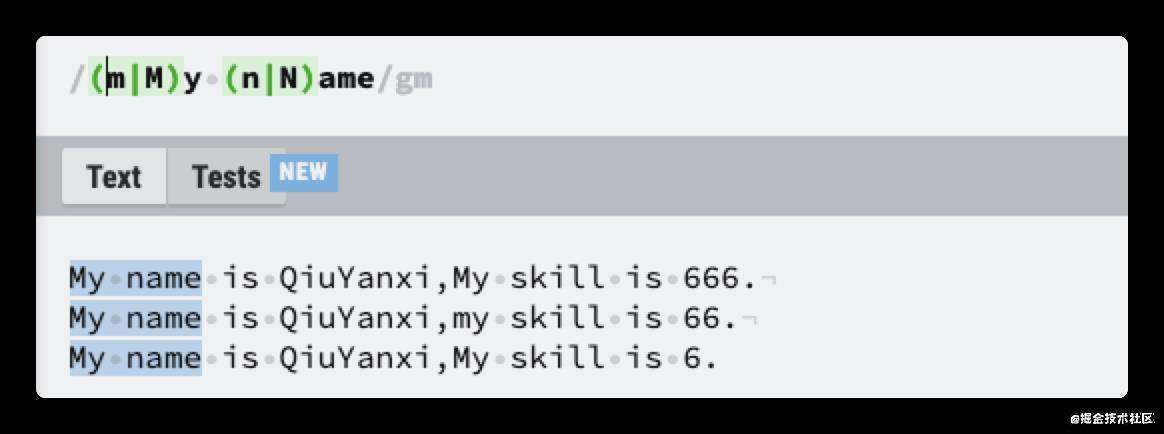
比较难理解的可能是小括号分组(),它是一个分组,表示一个整体,在里面也严格定义顺序。
之所以说难理解是因为它一般需要配合$进行引用替换。
My name is QiuYanxi,QiuYanxi's skill is 666.
如何转化为 QiuYanxi => 666 ?
这里就需要先引用再替换。引用就是用小括号分组对应字符再使用$取得对应引用。就像下图
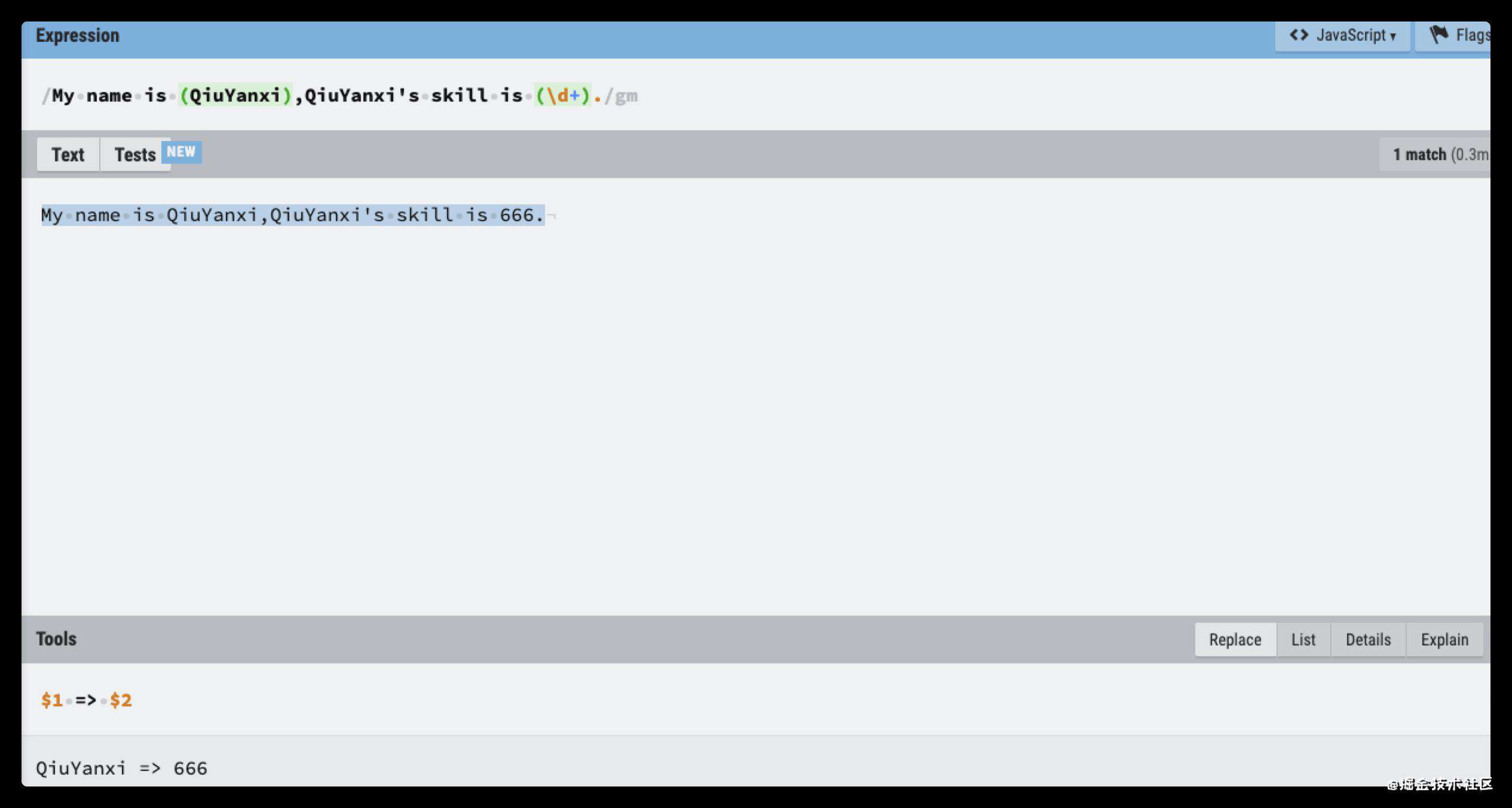
上面的例子先给需要的字符加上括号,然后用$+顺序号来引用。
如(QiuYanXi)被$1引用得到QiuYanXi
(\d+)被$2引用得到666
深入概念
正则表达式是匹配模式,要么匹配字符,要么匹配位置。
字符匹配
1.横向模糊匹配---你要匹配几个
横向模糊匹配的意思就是匹配1个或者多个数量的意思。
主要实现方法是使用量词,比如{m,n},表示 m-n 次
var regex = /ab{2,5}c/g;
var string = "abc abbc abbbc abbbbc abbbbbc abbbbbbc";
console.log( string.match(regex) );
//=> ["abbc", "abbbc", "abbbbc", "abbbbbc"]
案例中的尾数 g是表示全局匹配模式,是一个修饰符。
即在目标字符串中按顺序找到满足匹配模式的所有子串,强调的是“所有”,而不只是“第一个”。g是单词global的首字母。
2.纵向模糊匹配---你要匹配什么
纵向模糊匹配的意思就是匹配的某一个字符可以是多种可能性,不一定非要这个。
实现的方法是使用字符组,譬如[abc],表示该字符是可以字符“a”、“b”、“c”中的任何一个。
var regex = /a[123]b/g;
var string = "a0b a1b a2b a3b a4b";
console.log( string.match(regex) );
上面就是采用字符组,意思是中间的数可以是1或者2或者3。
小结
横向模糊匹配用来匹配数量,纵向模糊匹配用来匹配多种可能性。
横向模糊匹配用量词,纵向模糊匹配用字符组
3.量词---用来表示字符数量
量词用通俗的话来说就是这个字符出现多少次。
简写形式
{m,} 表示至少出现m次。
{m,n} 表示至少出现m次,最多出现n次
{m} 等价于{m,m},表示出现m次。
? 等价于{0,1},表示出现或者不出现。记忆方式:问号的意思表示,有吗?
+ 等价于{1,},表示出现至少一次。记忆方式:加号是追加的意思,得先有一个,然后才考虑追加。
* 等价于{0,},表示出现任意次,有可能不出现。记忆方式:看看天上的星星,可能一颗没有,可能零散有几颗,可能数也数不过来。
3.1贪婪匹配和惰性匹配
贪婪匹配就是我尽可能多的匹配
惰性匹配就是我尽可能少的匹配
var regex = /\d{2,5}/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["123", "1234", "12345", "12345"]
这是一个贪婪匹配的例子,给我的我全都要。
上面的正则表示\d我需要数字,{2,5}表示我需要2-5个,有5个就要5个。
换成惰性匹配,就是给我2个,我就够了。
惰性匹配是这样写的
var regex = /\d{2,5}?/g;
var string = "123 1234 12345 123456";
console.log( string.match(regex) );
// => ["123", "1234", "12345", "12345"]
通过在量词后面加个问号就能实现惰性匹配,因此所有惰性匹配情形如下:
对惰性匹配的记忆方式是:量词后面加个问号,问一问你知足了吗,你很贪婪吗?
4.字符组---用来表示字符范围
需要强调的是,虽叫字符组(字符类),但只是其中一个字符。例如[abc],表示匹配一个字符,它可以是“a”、“b”、“c”之一。
4.1匹配的字符范围太大怎么办
如果需要匹配的字符范围很多,写不完,可以用范围表示法。这里可以使用连字符-。
比如[123456abcdefGHIJKLM],可以写成[1-6a-fG-M]。
比如26个字母小写,可以写成[a-z]
因为连字符有特殊用途,那么要匹配“a”、“-”、“z”这三者中任意一个字符,该怎么做呢?不能写成[a-z],因为其表示小写字符中的任何一个字符。可以写成如下的方式:[-az]或[az-]或[a\-z]。即要么放在开头,要么放在结尾,要么转义。总之不会让引擎认为是范围表示法就行了。
4.2我不需要某一字符怎么办
比如字符可以是任何东西,但我们不需要“a”、“b”、“c”,就可以使用排除字符^,表示取反。
此时就是排除字符组(反义字符组)的概念。例如[^abc],表示是一个除"a"、"b"、"c"之外的任意一个字符。字符组的第一位放^(脱字符),表示求反的概念。
常见简写形式
如果要匹配任意字符怎么办?可以使用[\d\D]、[\w\W]、[\s\S]和[^]中任何的一个。
5.多选模式
上面介绍的都是基于一个模式下的匹配,但是有时候我们需要多种模式,比如说我又想在 abc 中选一个,又想在 xyz 中选一个,就可以用多选模式,通过管道符|分割
var reg=/[abc]?|[xyz]?/g
var string='xyz abc '
var string2='abc xyz'
console.log(string.match(reg))
console.log(string2.match(reg))
// => ["x"]
// => ["a"]
例如要匹配"good"和"nice"可以使用/good|nice/。测试如下:
var regex = /good|nice/g;
var string = "good idea, nice try.";
console.log( string.match(regex) );
// => ["good", "nice"]
案例分析
正则表达式最重要的是分析过程,其次是书写,比如要匹配以下字符
var string = "#ffbbad #Fc01DF #FFF #ffE abc";
需要匹配出16进制字符。
分析:
1.16进制字符范围在1-9,a-z,A—Z之间
2.前面有个#号
3.3-6位
范围就是第一个条件,使用字符组
数量就是第三个条件,使用量词
var reg=/#[0-9a-fA-F]{3,6}/g
var string = "#ffbbad #Fc01DF #FFF #ffE abc";
console.log(string.match(reg))
// => ["#ffbbad", "#Fc01DF", "#FFF", "#ffE"]
匹配时间
23:59
12:59
24:00
分析:
1.第一位数字在0-2之间
2.第二位数字在0-9之间
3.第三位数字在0-5之间
4.第四位数字在0-9之间
5.如果第一位数字是2,那第二位数字在0-4之间
6.如果第一、二位数字是24,那么第三、四位只能是00
var reg=/(([0-1][0-9]|[2][0-3]):[0-5][0-9])|24:00/
console.log( reg.test("01:09") ); // true
console.log(reg.test("24:01")); // false
console.log(reg.test("00:60")); // false
如果想忽略前面的0,可以这样写
var reg=/((^(0?[0-9]|1[0-9])|[2][0-3]):(0?|[0-5])[0-9])|24:00/
console.log(reg.test("21:19") ); // true
console.log(reg.test("24:01")); // false
console.log(reg.test("23:9")); // true
匹配日期
比如yyyy-mm-dd格式为例。
要求匹配2017-06-10
分析:
需要匹配什么范围?
年:数字,在0-9之间[0-9]
月:数字,可能是在01-09,以及在10-12之间,可以用(0[1-9]|1[0-2])
日:数字,可能是01-09,以及10-29,最大31,可以用0[1-9]|[12][0-9]|3[0-1]
需要匹配几位?
年匹配4位,月匹配两位,日匹配两位
const reg=/[0-9]{4}-(0[1-9]|1[0-2])-0[1-9]|[12][0-9]|3[0-1]/
console.log(reg.test("2017-06-10") ); //true
位置匹配
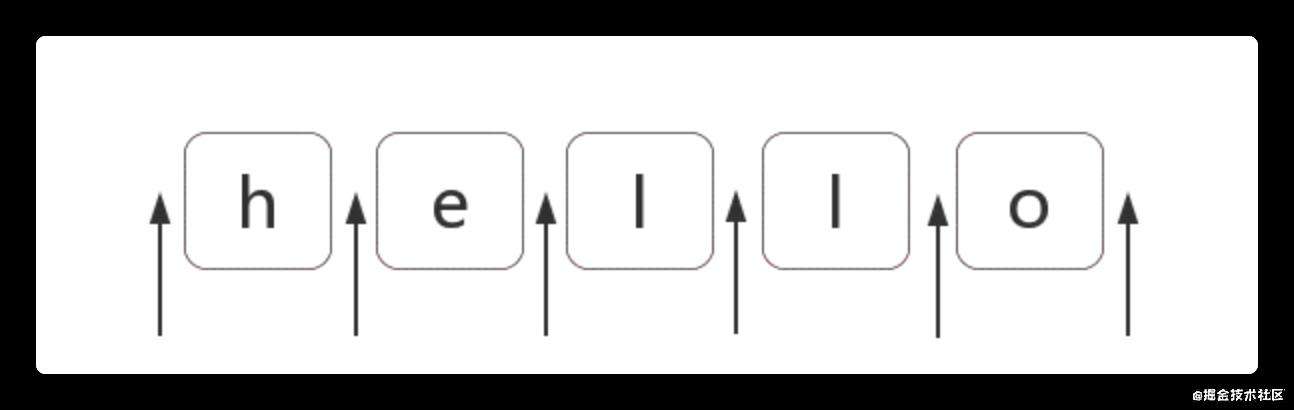
什么是位置
位置是相邻字符之间的位置。比如,下图中箭头所指的地方:
如何匹配位置
在正则中,一共有6个锚字符
匹配开头和结尾
匹配开头和结尾用^和$
^(脱字符)匹配开头,在多行匹配中匹配行开头。
$(美元符号)匹配结尾,在多行匹配中匹配行结尾。
比如我们把字符串的开头和结尾用"#"替换(位置可以替换成字符的!):
var result = "hello".replace(/^|$/g, '#');
console.log(result);
// => "#hello#"
多行匹配模式时,二者是行的概念,这个需要我们的注意:
var result = "I\nlove\njavascript".replace(/^|$/gm, '#');
console.log(result);
/*
#I#
#love#
#javascript#
*/
匹配单词边界和非单词边界
\b是单词边界
\B是非单词边界
\b是单词边界,具体就是\w和\W之间的位置,也包括\w和^之间的位置,也包括\w和$之间的位置。
\w是[0-9a-zA-Z_]表示字母、数字、大写字母和下划线。
\W是除了字母、数字、大写字母和下划线,表示取反。
比如一个文件名是"[JS] Lesson_01.mp4"中的\b,如下:
var result = "[JS] Lesson_01.mp4".replace(/\b/g, '#');
console.log(result);
// => "[#JS#] #Lesson_01#.#mp4#"
上面的正则要在单词边界上加入#。
什么是单词边界呢?首先JS就是跟\w 有关的单词,其次 Lesson_01和 mp4都属于\w。
那么\W是什么呢?就是[]、空格和.
那么我们来分析一下:
[跟J之间有一个单词边界S跟]之间有一个单词边界- 空格跟
L之间有一个单词边界 - 1跟
.之间有一个单词边界 .跟m之间有一个单词边界- 最后一个
#是因为4属于\w,跟$结尾之间有一个单词边界
知道了\b的概念后,那么\B也就相对好理解了。
\B就是\b的反面的意思,非单词边界。例如在字符串中所有位置中,扣掉\b,剩下的都是\B的。
var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#');
console.log(result);
// => "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"
前面的位置和非前面的位置
(?=p)和(?!p)分别代表p模式前面的位置和非前面的位置。比如
var result = "hello".replace(/(?=l)/g, '#');
console.log(result);
// => "he#l#lo"
上面的代码表示插入l 前面位置的字符为#
而(?!p)就是(?=p)的反面意思,比如:
var result = "hello".replace(/(?!l)/g, '#');
console.log(result);
// => "#h#ell#o#"
位置的特性
可以把位置的特性理解为空字符。
比如"hello"字符串等价于如下的形式:
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "o" + "";
也就是说字符之间的位置,可以写成多个。
把位置理解空字符,是对位置非常有效的理解方式。
相关案例
数字的千位分隔符表示法
比如把"12345678",变成"12,345,678"。
需要在三位数字前面加上逗号,所以就变成了
const reg=/(?=(\d{3})+$)/g
console.log('12345678'.replace(reg,','))
// "12,345,678"
不过上面的字符如果换成123456789就会变成",123,456,789"
所以我们需要排除第一个位置,首位可以用^表示。
非首位可以用位置中的?!p模式,于是就变成了
const reg=/(?!^)(?=(\d{3})+$)/g
console.log('123456789'.replace(reg,','))
//"123,456,789"
正则表达式括号的作用
括号的作用,其实三言两语就能说明白,括号提供了分组,便于我们引用它。
引用某个分组,会有两种情形:在JavaScript里引用它,在正则表达式里引用它。
分组和分支结构
我们知道/a+/匹配连续出现的“a”,而要匹配连续出现的“ab”时,需要使用/(ab)+/。
其中括号是提供分组功能,使量词+作用于“ab”这个整体,测试如下:
var regex = /(ab)+/g;
var string = "ababa abbb ababab";
console.log( string.match(regex) );
// => ["abab", "ab", "ababab"]
而在多选分支结构(p1|p2)中,此处括号的作用也是不言而喻的,提供了子表达式的所有可能。
比如,要匹配如下的字符串:
var regex = /^I love (JavaScript|Regular Expression)$/;
console.log( regex.test("I love JavaScript") );
console.log( regex.test("I love Regular Expression") );
// => true
// => true
引用分组
这是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作。
而要使用它带来的好处,必须配合使用实现环境的API。
以日期为例。假设格式是yyyy-mm-dd的,我们可以先写一个简单的正则:
var regex = /\d{4}-\d{2}-\d{2}/;
然后再修改成括号版的:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
为什么要使用这个正则呢?
提取数据
比如提取出年、月、日,可以这么做:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log( string.match(regex) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
match返回的一个数组,第一个元素是整体匹配结果,然后是各个分组(括号里)匹配的内容,然后是匹配下标,最后是输入的文本。(注意:如果正则是否有修饰符g,match返回的数组格式是不一样的)。
另外也可以使用正则对象的exec方法:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log( regex.exec(string) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
同时,也可以使用构造函数的全局属性1至9来获取:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
regex.test(string); // 正则操作即可,例如
//regex.exec(string);
//string.match(regex);
console.log(RegExp.$1); // "2017"
console.log(RegExp.$2); // "06"
console.log(RegExp.$3); // "12"
替换
比如,想把yyyy-mm-dd格式,替换成mm/dd/yyyy怎么做?
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1");
console.log(result);
// => "06/12/2017"
相当于
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function(){
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1;
});
console.log(result);
// => "06/12/2017"
反向引用
除了使用相应API来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。
还是以日期为例。
比如要写一个正则支持匹配如下三种格式:
最先可能想到的正则是:
var regex = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // true
其中/和.需要转义。虽然匹配了要求的情况,但也匹配"2016-06/12"这样的数据。
假设我们想要求分割符前后一致怎么办?此时需要使用反向引用:
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/;
var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true
console.log( regex.test(string2) ); // true
console.log( regex.test(string3) ); // true
console.log( regex.test(string4) ); // false
正则表达式的四种操作
查
var regex = /\d/;
var string = "abc123";
console.log( regex.test(string) );
// => true
切
匹配上了,我们就可以进行一些操作,比如切分。
所谓“切分”,就是把目标字符串,切成一段一段的。在JS中使用的是split。
比如,目标字符串是"html,css,javascript",按逗号来切分:
var regex = /,/;
var string = "html,css,javascript";
console.log( string.split(regex) );
// => ["html", "css", "javascript"]
可以使用split“切出”年月日:
var regex = /\D/;
console.log( "2017/06/26".split(regex) );
console.log( "2017.06.26".split(regex) );
console.log( "2017-06-26".split(regex) );
// => ["2017", "06", "26"]
// => ["2017", "06", "26"]
// => ["2017", "06", "26"]
取
虽然整体匹配上了,但有时需要提取部分匹配的数据。
此时正则通常要使用分组引用(分组捕获)功能,还需要配合使用相关API。
这里,还是以日期为例,提取出年月日。注意下面正则中的括号:
var regex = /^(\d{4})\D(\d{2})\D(\d{2})$/;
var string = "2017-06-26";
console.log( string.match(regex) );
// =>["2017-06-26", "2017", "06", "26", index: 0, input: "2017-06-26"]
换
找,往往不是目的,通常下一步是为了替换。在JS中,使用replace进行替换。
比如把日期格式,从yyyy-mm-dd替换成yyyy/mm/dd:
var string = "2017-06-26";
var today = new Date( string.replace(/-/g, "/") );
console.log( today );
// => Mon Jun 26 2017 00:00:00 GMT+0800 (中国标准时间)
参考资料
JS正则表达式完整教程(略长)
learn-regex
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!