
导读:作为凤睛早期的接入方、后期的核心成员,笔者经历了整个项目前后四年的变迁,看过项目的艰难开端、中期的默默积累以及后期的蓬勃发展。每一次架构的变迁都带着技术浪潮的烙印,也看到项目成员利用有限资源来解决实际问题而持续不断的创新。
凤睛是百度商业业务系统的性能监控系统(APM),它侧重于对Java应用的监控,基本接入了百度绝大部分Java应用(覆盖数千个业务应用,数万个容器)。它能够对主流中间件框架( Spring Web、RPC、数据库、缓存等)进行自动埋点,实现全栈式性能监控和全链路追踪诊断,为百度各业务线提供微服务系统性能指标、业务黄金指标、健康状况、监控告警等。

△凤睛产品流程图
-
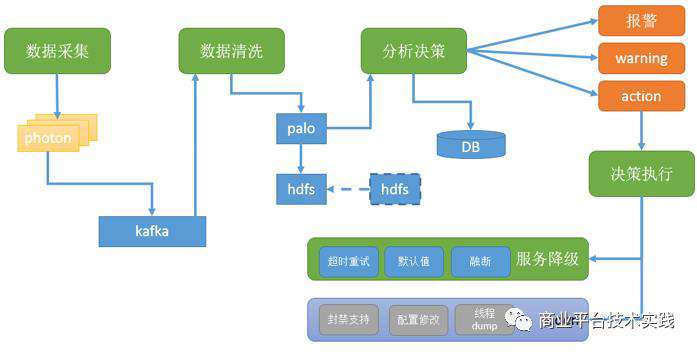
数据采集:凤睛探针技术能够自动植入到业务进程中去,采集相关性能信息,业务进程完全无感知。
-
数据计算和分析:按照类型,时序数据存储在百度SIA智能监控平台的时序数据库 TSDB,用来生成可视化报表和异常报警。调用链数据会被存入Palo( 开源名为Doris) 大数据仓库,用来拓扑分析和调用链检索。
-
应用场景:如上所述,凤睛提供稳定性报表、异常报警、错误堆栈分析、服务耗时分析、调用拓扑分析、业务日志关联分析等。
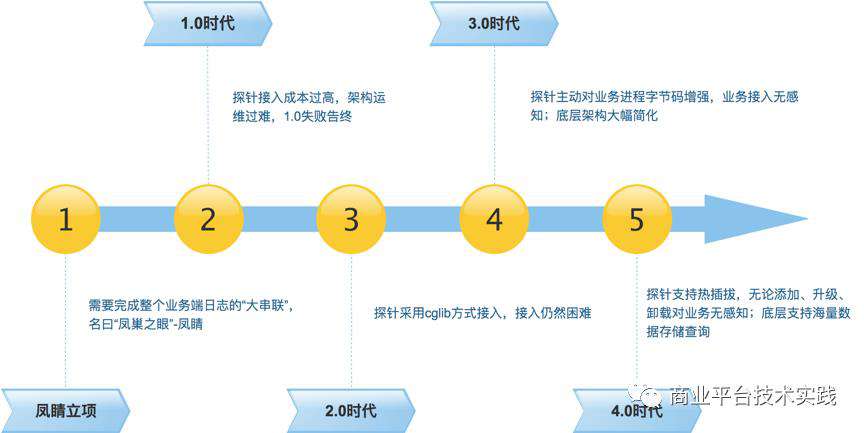
△凤睛的架构变迁时间线
01 凤睛立项
项目发起在2016年,百度凤巢广告业务系统中间件 (分布式RPC框架 Stargate等、配置中心、数据库中间件等)已经完善。随着单体服务拆分的深入,整体Java在线上部署规模逐渐变多,同时,暴露的问题也越来越多。
典型的问题有:
-
核心服务问题定位周期长。多个模块大量报错后,花费了很长时间才定位问题。
-
集群日志获取代价非常高,缺乏日志调用链关系等原因导致定位代价很高,甚至有些问题无法定位。
-
异常日志需要登录具体的线上实例查看。而线上部署实例数目多,排错时间长。
凤巢业务端急需一个分布式追踪系统来完成整个业务端日志的“大串联”。所以百度商业平台基础架构组发起了凤睛的项目,名曰“凤巢之眼”。



02 凤睛1.0
在分布式链路追踪领域,探针采集这个环节主要存在侵入式和无侵入式。1.0探针走的侵入方式。业务开发人员首先引入探针相关的依赖 jar 包,通过拦截器自动收集调用关系以及性能数据;然后,添加硬编码补充业务数据。

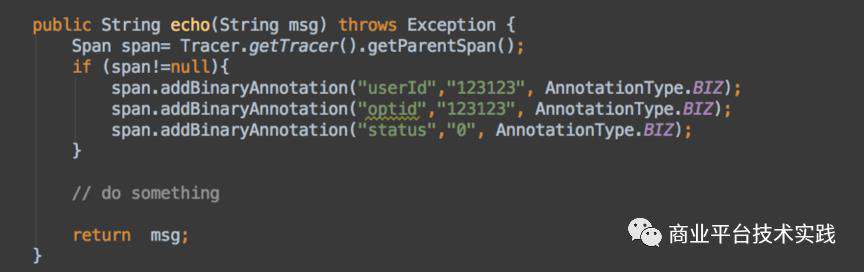
△编码示例
探针采集的数据会被打印到磁盘,通过kafka收集走。底层的数据处理和数据存储采用了Storm、 Hbase等当时流行的数据处理系统。后端架构比较复杂。

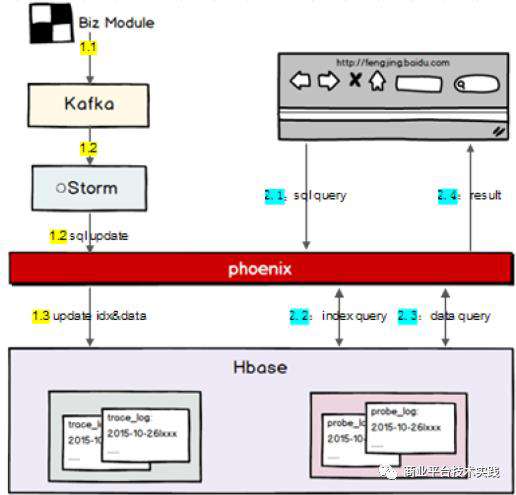
△凤睛1.0架构示意图
03 凤睛2.0
凤睛2.0版本中,首先是降低探针接入成本。2.0版本中,探针改用java agent技术结合cglib 做AOP注解,把依赖引入的jar 包从N个降低到1个。从编写大段的调用链填充代码改为尽量走AOP。探针端传输层采用了更高效的传输协议(protobuffer+gzip), 直接通过 HTTP 协议发送到 kafka,大大了降低磁盘IO开销。

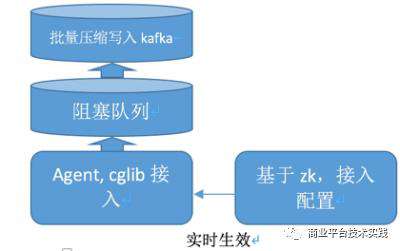
2.0探针较1.0接入方便,传输也更快。但是仍需业务方添加AOP代码。对于业务端数以百计的应用来说,接入仍然是大工程,推广依然困难。
04 凤睛3.0
凤睛3.0架构设计中,项目组成员一直在思考两个问题:
-
如何让业务方快速接入,尽量少改动,甚至“无感知接入”?
-
如何降低架构运维难度,既能处理海量数据,又能低成本运维?
为了解决问题1,探针3.0 决定完全放弃侵入式方式,改为无侵入即字节码增强方式。
对当时几种流行的监控诊断工具进行了调研:


△Newrelic,pinpoint,greys监控探针调研
3.0探针参考了Greys支持运行时增强的特点以及 pinpoint、Newrelic基于插件扩展开发的设计理念。最终效果是探针能够自动对业务进程植入监控代码,监控具体工作交由插件体系完成,完全面向切面监控。

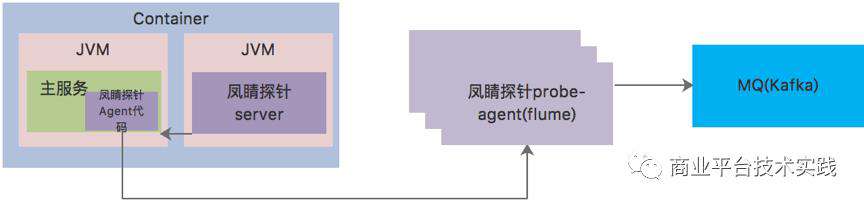
△探针主动加载示意图
后端存储系统转而依托Doris。Doris是百度自研的基于 MPP 的交互式 SQL 数据仓库,兼容mysql协议,学习成本低。既可以做存储又可以做分析计算,初期避免引入spark,storm等技术,降低系统复杂度。

△架构设计如图所示
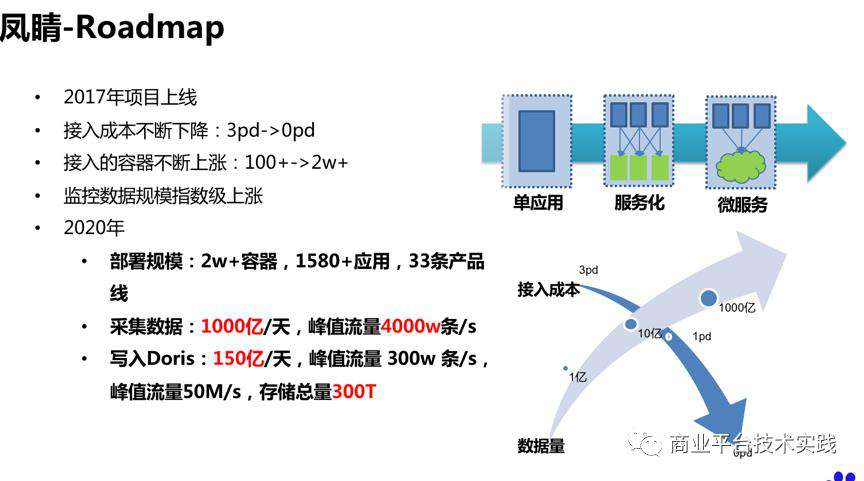
架构升级后,作为小团队,也能快速批量部署探针,计算存储能力也能满足需求。截止2017年,凤睛3.0上线了100多个应用,跑在1000多个容器上面。
05 凤睛4.0
2018年,微服务和虚拟化浪潮席卷而来。随着部署平台的不断升级和 springboot体系的成熟完善,单体能够被快速拆分成了数目众多的微服务,依托平台进行高效的运维部署。凤睛作为基础组件被微服务托管平台集成,并得到公司级的推广应用,整体部署应用规模从百级别激增到了千级别,部署容器从千级别变成了万级别。
这个阶段爆发了很多问题,技术核心问题主要有两点:
-
探针升级需要重启业务应用生效,而线上应用重启流量有损。导致难以频繁升级探针版本,快速引入新功能。
-
每天实时写入150亿条,峰值流量 300w 条/s。数据导入容易丢失;检索单条调用链性能查,大概需要100多秒。
2019年,凤睛进行了进一步的改造升级,针对1、2两个问题,进行了技术攻坚。
探针层面研究如何支持热插拔,也就是探针在业务进程运行的情况下自动完成升级。起初为了保证业务类对探针插件类的可见性,探针类统一放到了 System Classloader里。但是System Classloader 作为系统默认的,不支持卸载。反之,如果把探针类全部放到自定义类加载器中。探针类则对业务类完全不可见,也就无法完成字节码增强。

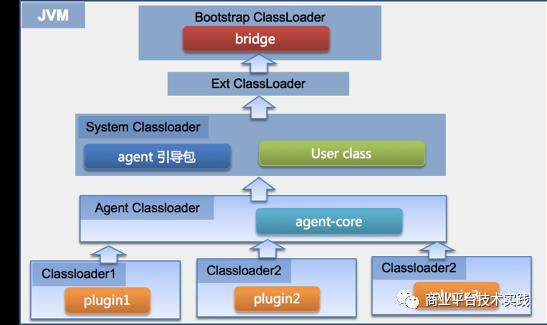
△探针热插拔classloader体系
为了解决可见性问题,探针引入了桥接类,通过桥接类提供的代码桩和插件类库投影,用户类可以访问实际使用的探针类,完成监控改造的目的。对于不同插件,则放在不同的自定义 Classloader 里面。这样来插件之间互不可见。单个插件也可以完成热插拔。具体的设计细节后面会有文章详细解读。
毋庸置疑,凤睛探针是业界唯一能够热插拔的监控探针技术,我们也申请了专利。它的功能正确性和性能是经历过大规模线上流量验证的。
继续推进优化调用链检索的性能。
首先分析下我们的底层存储结构:
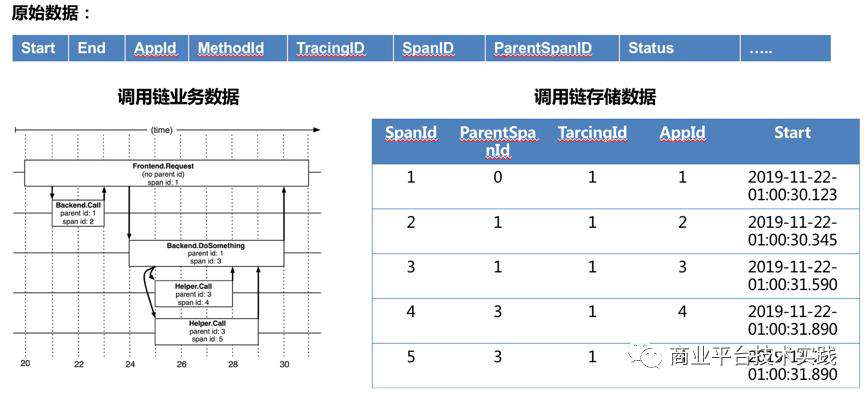
通过对慢查询的分析,发现检索慢主要是两个原因:一是大量查询没有走任何索引,全表扫描海量数据非常慢。二是,导入碎片过多,导致文件Compaction特别慢,典型的LSM-Tree 的读放大。为了解决这些问题,调用链存储层重构表结构,通过大量Rollup配合基本表,优化查询时间。Doris 此时已经具备流式导入的能力,也借机从小批量导入切换到流式导入。

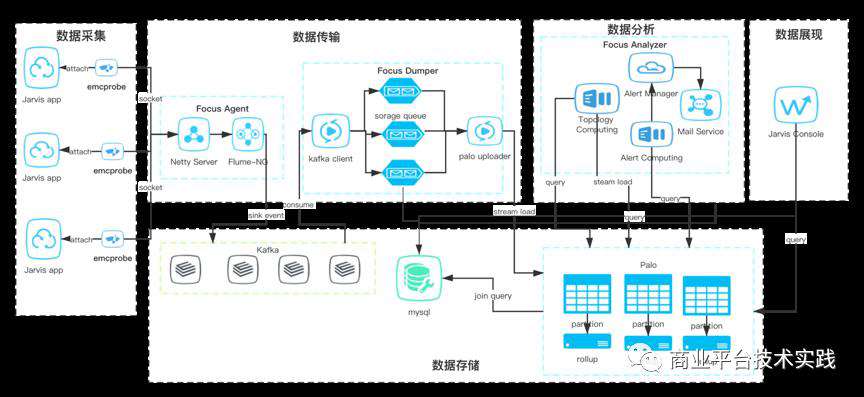
△调用链处理架构
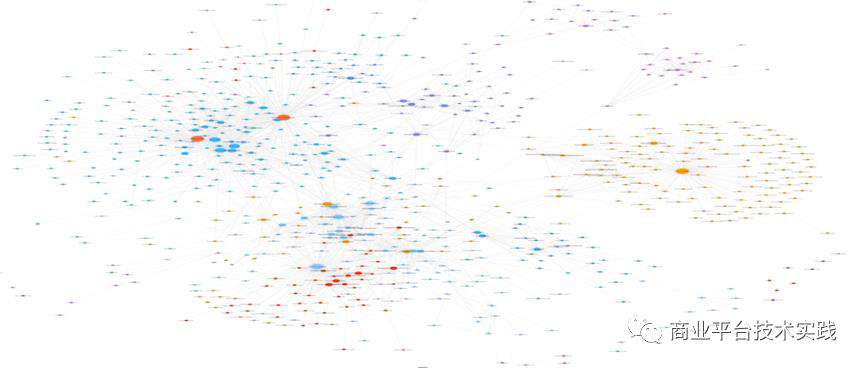
△上图是凤睛实时构建的微服务全景拓扑图。截止2020年1月,大概涵盖了数十条产品线的线上流量拓扑,最细粒度的节点为接口,即 Java 应用中的函数。从图中可以分析出,托管全平台非孤岛接口节点大概有50w+,接口节点连线200w+ 条。
06 数据处理架构分离
架构继续演进,凤睛采集的数据量越来越多,业务方需求也越来越多。
主要面临两个问题:
-
数据可视化能力依赖于前端开发,大量多维可视化分析需求难以满足。
-
调用链做了采样,导致统计数据不准确,无法满足统计报表的需求。
这两个问题归根结底是时序数据如何存储和展现。这涉及到分布式追踪领域两个很基础的概念,时序时间和调用链数据。所谓的时序数据是基于时间的一系列的数据,用于查看一些指标数据和指标趋势。调用链数据是指记录一个请求的全部流程,用于查看请求在哪个环节出了故障,系统的瓶颈在哪儿。
时序数据不需要保存细节,只存时间、维度和指标的数据点, 可以存储在专门的时间序列数据库(Time Series Database)。实际场景中,凤睛没有专门去维护一个时序数据库。而是对接百度SIA智能监控平台的分布式时序数据库TSDB。同时,利用百度SIA平台提供丰富的多维可视化分析报表,用以解决用户各种可视化多维度数据分析的需求。

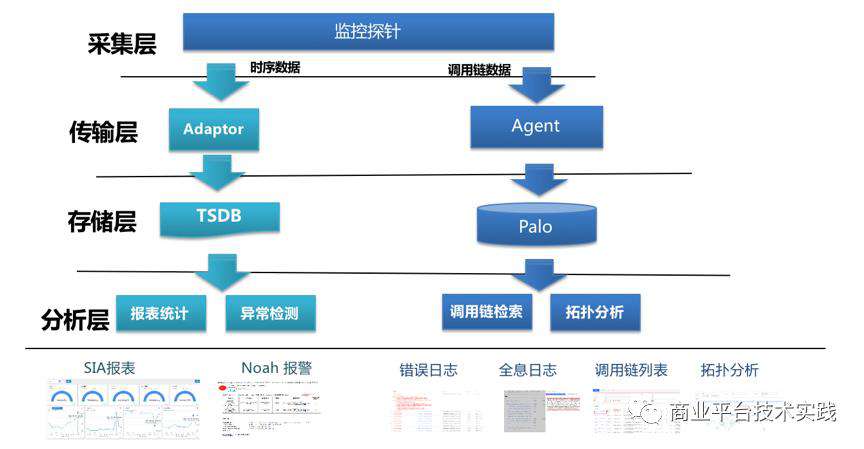
△当前整体的架构
07 结语
凤睛整个项目前后持续了4年,中间经历过无数的困难和坎坷,通过积累了项目成员们持续的付出,最终取得里程碑式的成果。本文简要介绍了凤睛产品的业务背景、技术架构和产品形态,后续会继续发文介绍技术相关的实现细节,欢迎持续关注。
阅读原文
百度商业大规模微服务分布式监控系统——凤睛
推荐阅读
|百度搜索与推荐引擎的云原生改造
最后欢迎各位关注我们的同名公众号「百度Geek说」~
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!