DOM树(dom tree):DOM结构
DOM树描述了标签和标签之间的关系(节点间的关系)
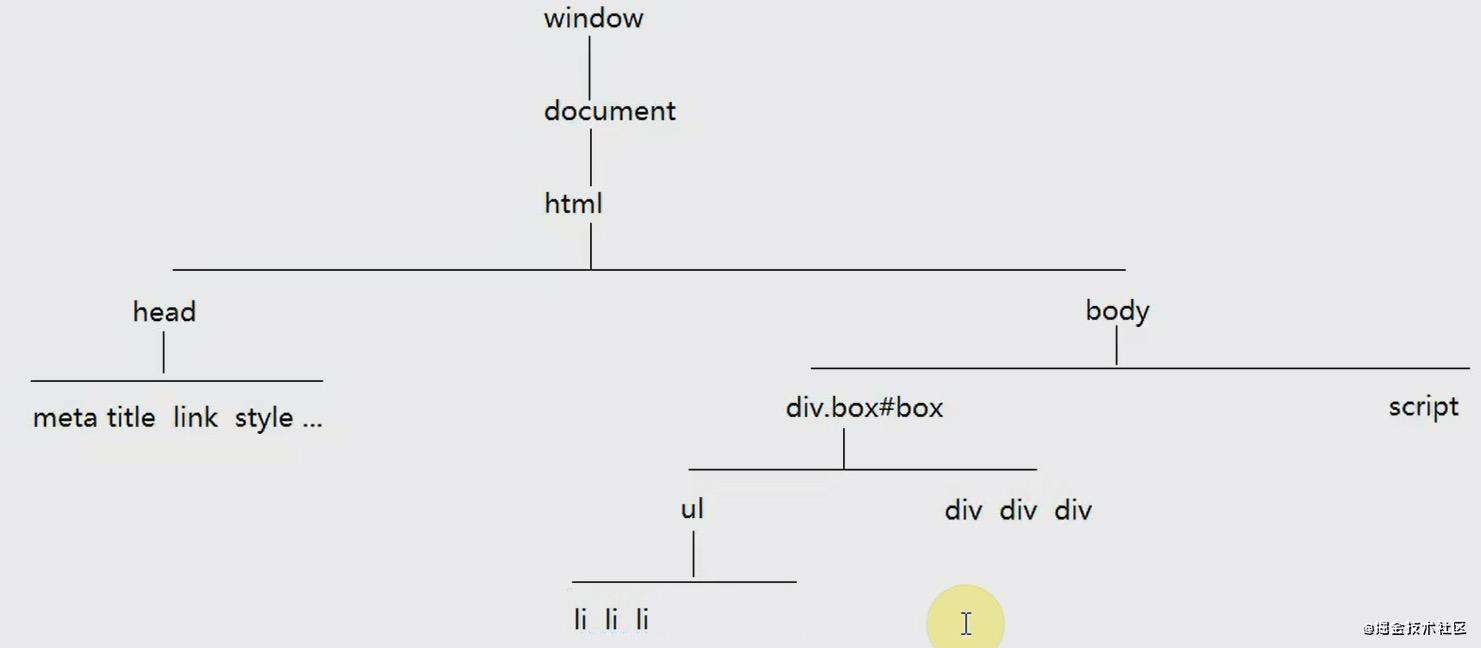
JS中获取DOM元素的方法
document.getElementById('id值')document.documentElement获取html元素对象document.body获取body元素对象document.head获取head元素对象document.getElementsByName('name属性值')[context].getElementsByTagName('标签名')[context].getElementsByClassName('class名')[context].querySelector(css的选择器:'#aaa''.ddd''.ddd div')[context].querySelectorAll(css的选择器:'#aaa''.ddd''.ddd div')
document.getElementById('id值')
document限定了获取元素的范围,我们把这个范围称之为‘上下文【context】’
获取到的是对象数据类型的值
getElementById的上下文只能是document:
如果页面中的ID重复了,我们基于这个方法只能获取到第一个元素,后面相同ID元素无法获取
IE6,7下 会把表单元素的name属性当做ID来使用,所以要注意id和表单元素name属性的重复问题
var oBox=document.getElementById('box')
typeof oBox => "object"
//分析包含的属性
className:存储的是一个字符串,代表当前元素的样式类名
oBox.className='aaa' 会覆盖原有的class
oBox.className +=' aaa' 不会覆盖原有class 新的class前边要有空格
id:存储的是当前元素的id值
innerHTML:存储当前元素中所有的内容(包含HTML标签)
innerText:存储当前元素中所有的文本内容(不包含HTML标签)
style:存储当前元素所有的“行内样式”值(获取和操作的都只能是标签上的行内样式,写在样式表中的样式无法获取到)
兼容处理
在ID重复时获取所有ID为‘aaa’的标签(兼容所有浏览器):获取所有标签,判断id
function queryAllById(id){
var nodeList=document.getElementsByTagName('*');
var arr=[];
for(var i=0;i<nodeList.length;i++){
nodeList[i].id=== id?arr.push(nodeList[i]):null;
}
return arr;
}
queryAllById('aaa')
//直接用 aaa也行
console.log(aaa)
获取元素集合(获取多个元素):
[context].getElementsByTagName('标签名')获取一组元素集合
-
1、获取的结果是一组元素集合(HTMLCollection,
__proto__指向HTMLCollection)(是一个类数组,不能直接使用数组的方法), -
2、集合中的每一个值又是一个
元素对象(对象数据类型,包含很多内置属性,例如:id、className) -
3、它会把当前上下文中,子子孙孙(后代)层级内的该标签都获取到(
并不是只获取到子级) -
4、基于这个方法
获取到的结果永远都是一个集合,不管里边是否有内容,也不管有几项;如果想操作集合中具体的某一项,需要基于索引获取到才可以
var liList=oBox.getElementsByTagName('li');
liList[0] //就是第一个li(通过索引获取具体某一个li)
liList.length //集合中li的数量
[context].getElementsByClassName('class名')获取到一组元素集合
解决兼容问题:
获取所有标签,筛选他们的class
Node.prototype.queryElementsByClassName=function(){
if(arguments.length === 0) return [];
var className=arguments[0];
//Array.prototype.slice.call 类数组转化为数组,要不然nodeList.splice不能用
var nodeList=Array.prototype.slice.call(this.getElementsByTagName('*'));
className=className.replace(/^| +$/g,'').split(/ +/);
for(var i=0;i<className.length;i++){
var reg = new RegExp('(^| +)'+className[i]+'( +|$)');
for(var j=0;j<nodeList.length;j++){
if(!reg.test(nodeList[j].className)){
nodeList.splice(j,1);
j--;
}
}
}
return nodeList;
}
document.getElementById('J_focus').queryElementsByClassName('slider_item')
document.getElementsByName('name属性值')获取一组节点集合
[context].querySelector(css的选择器:'#aaa''.ddd''.ddd div')获取的是一个元素对象哪怕选择器匹配了多个,也只获取第一个
[context].querySelectorAll(css的选择器:'#aaa''.ddd''.ddd div')获取到选择器匹配到的所有元素,结果是一个节点集合
querySelector、querySelectorAll都不兼容 IE6~8,不考虑兼容的情况下,我们能用别的方法获取尽量不要用这两个,这两个方法消耗性能较大
获取浏览器一屏幕的宽高(兼容所有浏览器)
document.documentElement.clientWidth || document.body.clientWidth;
document.documentElement.clientHeight || document.body.clientHeight;
DOM中的节点(node):元本注档1389
每一种类型的节点都会有一些属性区分自己的特性和特征:
nodeType:节点类型;nodeName:节点名称;nodeValue:节点值;
元素节点 1
nodeType:1;nodeName:大写标签名;nodeValue:null;
oBox.nodeType //1
oBox.nodeName //"DIV"
oBox.nodeValue //null
文本节点 3
nodeType:3;nodeName:'#text';nodeValue:文本内容;- 在标准浏览器中,会把
空格和换行都当做文本节点来处理
注释节点 8
nodeType:8;nodeName:'#common';nodeValue:注释内容;
文档节点 9
nodeType:9;nodeName:'#document';nodeValue:null;
描述节点之间关系的属性
parentNode,获取当前节点唯一的父亲节点
childNodes,获取当前元素的所有子节点
- 1、子节点:只获取到
儿子级别,不能获取到孙子级及以后 - 2、所有:
包含元素节点,文本节点等
children,获取当前元素的所有元素子节点
- 在I
E6~8中会把注释节点也当做元素节点获取到,所以兼容性不好 - 元素节点
previousSibling,获取当前节点的上一个哥哥节点(获取的哥哥可能是元素也可能是文本等)
previousElementSibling:获取上一个哥哥 元素 节点(不兼容IE6~8)
nextSibling,获取当前节点的下一个弟弟节点(紧跟的节点)(获取的弟弟可能是元素也可能是文本等)
nextElementSibling:获取下一个弟弟 元素 节点(不兼容IE6~8)
firstChild,获取当前元素的第一个子节点(可能是元素也可能是文本等)
firstElmentChild:获取第一个 元素 子节点(不兼容IE6~8)
lastChild,获取当前元素的最后一个子节点(可能是元素也可能是文本等)
lastElmentChild:获取最后一个 元素 子节点(不兼容IE6~8)`
兼容处理
获取当前元素的所有元素子节点
function children(curEle){
//1、获取当前元素下的所有子节点
//2、筛选出来所有的元素子节点(nodeType===1)
var nodeList=curEle.children;
var res=[];
for(var i=0;i<nodeList.length;i++){
var item=nodeList[i];
if(item.nodeType === 1){
res.push(item)
}
}
return res;
}
获取当前元素的上一个哥哥元素节点
function prevElement(curEle){
//1、获取上一个哥哥节点
//2、判断上一个各个节点是不是元素节点(nodeType===1)
//不是再往前找
var node=curEle.previousSibling;
//node存在 并且 不是元素节点 才往前找
while(node && node.nodeType !== 1){
node=node.previousSibling;
}
return node;
}
DOM的增删改
document.createElement('标签名')
createTextNode,创建一个文本节点
[container].appendChild(创建的元素对象或已有的元素对象),把一个元素对象插入到指定容器【末尾】
[container].insertBefore(创建的元素对象,要插入其前面的元素)
- 1、把一个元素对象插入到
指定容器中某一个元素标签之前 - 2、如果
未规定要插入其前面的元素,则 insertBefore 方法会在结尾插入 newnode - 3、如果给定的子节点是对文档中现有节点的引用,insertBefore() 会将其从当前位置移动到新位置(在将节点附加到其他节点之前,不需要从其父节点删除该节点)
[curEle要克隆的元素].cloneNode(),把一个节点进行克隆
- 1、[curEle要克隆的元素].cloneNode():浅克隆(只克隆当前的标签,标签的样式也有,只是没有innerHTML)
- 2、[curEle要克隆的元素].cloneNode(true):深克隆,当前标签及里面的内容都一起克隆了
[container].removeChild(要删除的元素),在指定容器当中删除某一个元素
[curEle要操作的元素].set/get/removeAttribute(属性名,属性值)
var oBox=document.getElementById('box');
//=>1、把当前元素作为一个对象,在对象对应的堆内存中新增一个自定义的属性
oBox.myIndex=10; //设置
console.log(oBox.myIndex) //获取
delete oBox.myIndex; //删除
//2、基于Attribute等dom方法完成自定义属性的设置
oBox.setAttribute('myHahaha','123456') //设置
oBox.getAttribute('myHahaha') //获取
oBox.removeAttribute('myHahaha') //删除
-
第一种是
基于对象键值对操作方式,修改当前元素对象的堆内存空间来完成(不存在时获取到的是undefined) -
第二种是
直接修改页面中HTML标签的结构来完成的,此种办法设置的自定义属性可以在结构上呈现出来(不存在时获取到的是null) -
第一种方法设置的属性在elements控制台是
看不到的,第二种设置的能看到(myIndex看不到,myHahaha看得到) -
基于setAttribute设置的自定义属性值
都是字符串 -
能用第一种不要用第二种,第二种结构上可见易被攻击,而且第二种操作的是dom耗费性能
var oBox=document.getElementById('box');
//=>1、把当前元素作为一个对象,在对象对应的堆内存中新增一个自定义的属性
oBox.myIndex=10; //设置
console.log(oBox.getAttribute('myIndex')) //null
oBox.setAttribute('m','123456') //设置
console.log(oBox.m) //undefined
node.attributes,获取指定节点的属性集合
解析一个URL字符串问号传参和HASH值部分:a元素对象的hash/search两个属性分别存储了哈希值和参数值
var str="http://www.baidu.com/stu?lx=1&name=AA&age=20#haha";
function queryURLParametr(str){
//1、创建一个A标签,把需要解析的地址当做a标签的href赋值
var newA=document.createElement('a');
newA.href=str;
//页面不需要展示newA,我们只是利用他的属性而已,所以不需要添加到页面中
//2、a元素对象的hash/search两个属性分别存储了哈希值和参数值
var search=newA.search.substr(1);
var hash=newA.hash.substr(1);
//3、分别解析出hash和参数即可
var obj={};
hash?obj.HASH=hash:null;
if(search){
var search=search.split('&'); //["lx=1","name=AA","age=20"]
for(var i=0;i<search.length;i++){
var itemArr=search[i].split('='); //["lx","1"]
obj[itemArr[0]]=itemArr[1]
}
}
return obj;
}
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!