引言
Node 中采用了 CommonJs 规范,通过 module.exports 和 require 来导出导入模块。在模块加载机制中,Node 采用延迟加载的策略,只有到使用到时,才会去加载,加载之后会被存入 cache 中。
面试中关于模块机制的常见问题
- require 的加载机制?
- 假设有 a.js、b.js 两个模块相互引用,会有什么问题?是否为陷入死循环?
- a 模块中的 undeclaredVariable 变量在 b.js 中是否会被打印?
- module.exports 与 exports 的区别
- import 和 require 的区别
- 模块在 require 的过程中是同步还是异步?
Node 模块分类
1. 核心模块
在 Node 中有一些用二进制发布的模块,称之为核心模块。核心模块只能通过模块名来引用,而不能通过文件路径来引用,即使已经存在一个与其同名的第三方模块,也会优先加载核心模块。
2. 文件模块
可以通过绝对路径从文件系统中加载非核心模块。
const module = require('../my_module/module');
通过路径加载模块时可以省略.js后缀,如果没有找到这个文件,Node 会在文件名后面加上.js再次查找路径。
3. 文件夹模块
const module = require('../my_module');
Node 会在指定的文件夹中查找模块。Node 会假设当前文件夹是一个包含了 package.json 的包定义。
- 如果 package.json 存在就会解析文件,查找 main 属性,并将 main 属性作为入口点。
- 如果 package.json 不存在,就会将包入口点假设为 index.js
4. 加载 node_modules 模块
如果在核心模块和文件模块都没有找到模块,Node 就会尝试在当前目录下的 node_modules 文件夹中查找该模块。
const myModule = require('myModule.js');
- 尝试找到文件 './node_modules/myModules.js'
- 如果没有找到,就会查找上一级目录 '../node_modules/myModules.js'
- 如果还是没有找到,就在往上一级目录,直到找到根目录或者找到为止
5. 缓存模块
模块在首次加载时,会被缓存起来,意味着如果模块名能解析为相同的文件名,那么在此调用时,都会返回同一模块。
// myModules.js
console.log('modules start initializing...');
modules.exports = function() {
console.log(1);
}
console.log('modules end initializing...');
// 一次加载
var myModules = require('./myModules.js');
// 输出
// modules start initializing...
// modules end initializing...
// 两次加载
var myModules = require('./myModules.js');
var myModules = require('./myModules.js');
// 还是输出
// modules start initializing...
// modules end initializing...
// 意味着模块的初始化只会被初始化一次
require 模块加载机制
Node 的模块加载机制,分为三个步骤:路径解析、文件定位、编译执行
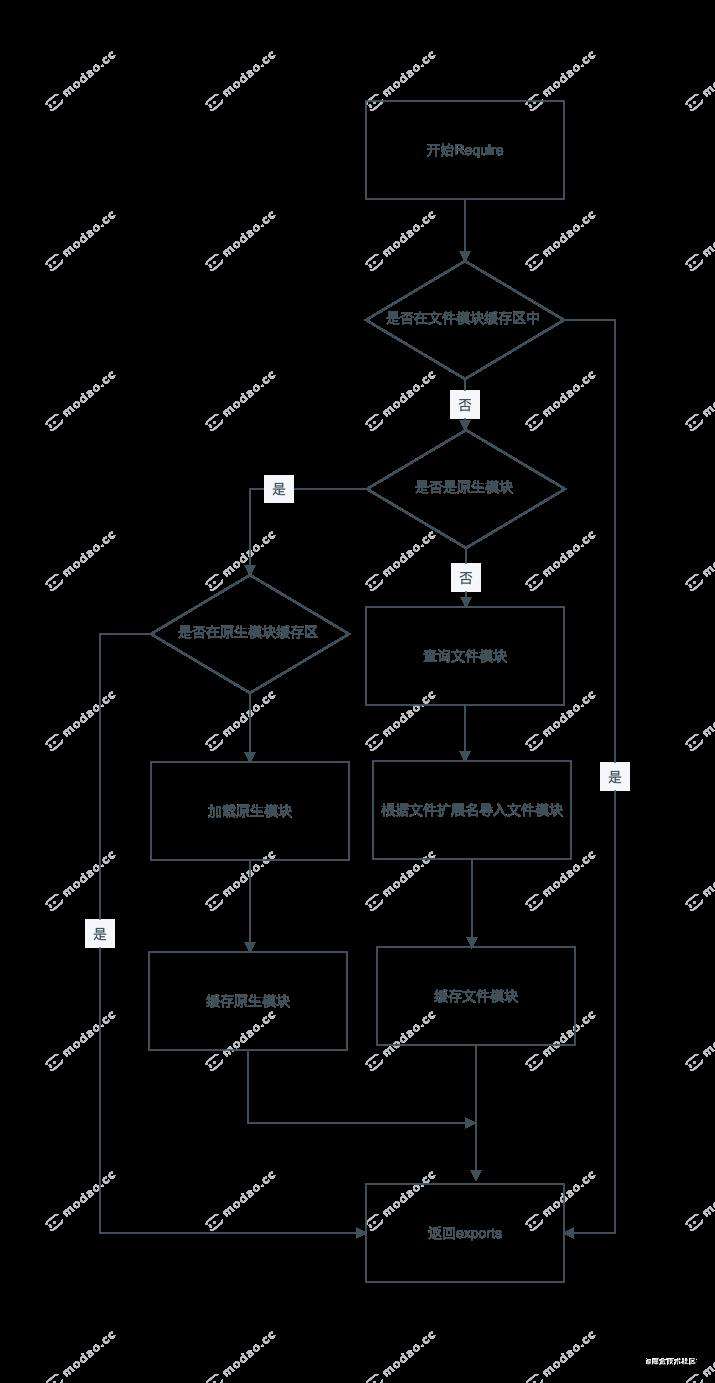
- 缓存模块:模块被加载之后会放入到缓存区,模块执行首先是先进行缓存加载,判断缓存中是否有值。
- 原生模块:仅次于缓存模块,原生模块被编译成二进制,省略了文件定位、编译执行,直接加载到了内存中。
- 文件模块:优先加载 .、..、/ 开头的,如果文件没有加上扩展名,会依次按照 .js、.json、.node 进行扩展名补足尝试,那么在尝试的过程中也是以同步阻塞模式来判断文件是否存在,从性能优化的角度来看待,.json、.node最好还是加上文件的扩展名。
- 文件夹模块:这种情况发生在文件模块查询的过程中,发现没有找到文件模块,但是路径是一个文件夹时,这时候会将目录作为一个包处理。先在包的根目录查找 package.json 文件夹,如果没有就会找index.js,如果有就会解析文件,找 main 属性描述的文件进行加载,如果加载文件没有加载到就会报错。
- node_modules模块:当上诉模块都没有找到的时候就会在当前目录的父目录的 node_modules 中查找如果没有找到就在在往上次目录中查找,直到找到或者找到根目录结束。
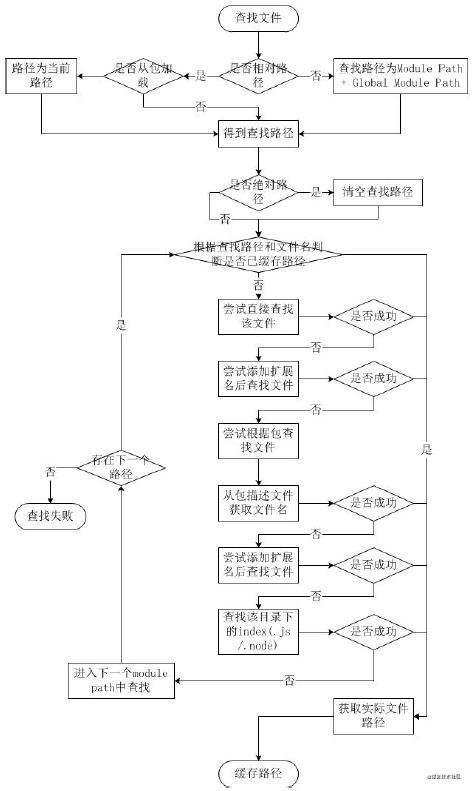
require 文件加载机制
关于文件模块的加载,大家可以直接看这张图,我就不多讲了,很清晰。
require 加载模块的时候是同步还是异步?
先回答问题,同步的! 但是面试官要是问你为什么是同步还是异步的呢? 其实这个答案并不是固定的,但是小伙伴们可以通过这几方面给面试官解释。
- 一个作为公共依赖的模块,当然想一次加载出来,同步更好
- 模块的个数往往是有限的,而且 Node.js 在 require 的时候会自动缓存已经加载的模块,再加上访问的都是本地文件,产生的IO开销几乎可以忽略。所以不需要异步,同步就好。
require加载模块会先运行目标文件
当在文件中 require 某个模块时,会从头开始先运行目标文件。
列子1
// a.js
let a = 1;
a = a + 1;
module.exports = a;
a = a + 1;
// main.js
const a = require('./a');
console.log(a); // 2
a.js导出了一个基础数据类型a,module.exports ,这时 a = 2,后面的 a 再次加一,并不会影响前面a的结果。
例子2
// b.js
let b = {
x: 1,
y: 2,
};
b.x = 3;
module.exports = b;
b.x = 4;
// main.js
const b = require('./b');
console.log(a.x); // 4
当a不是基础的数据类型,而是一个引用类型时,module.exports 后面的赋值 a.x = 4 生效。并且你可以在外部改变这个值。
// main.js
const b = require('./b');
console.log(b.x); // 4
b.x= 5;
console.log(b.x); // 5
当基础数据类型和引用数据类型出现不一致的结果
reqire时会从头到尾先运行目标文件,当 a 是基本数据类型时,运行到 module.exports 时将当前 a 的值赋值给 module.exports ,也就相当于在内存中创建了一个变量然后给它赋值为2,它的值就不会改变了,后面对 a 的修改并不会对它有影响。
当为引用数据类型时,赋值给 module.exports 是一个内存地址指向对象,后续对对象的修改也会反应到 module.exports 中。
模块被加载之后会被缓存起来
运行上面的列1、列2,在 main.js 中输出 rquire.cache 。
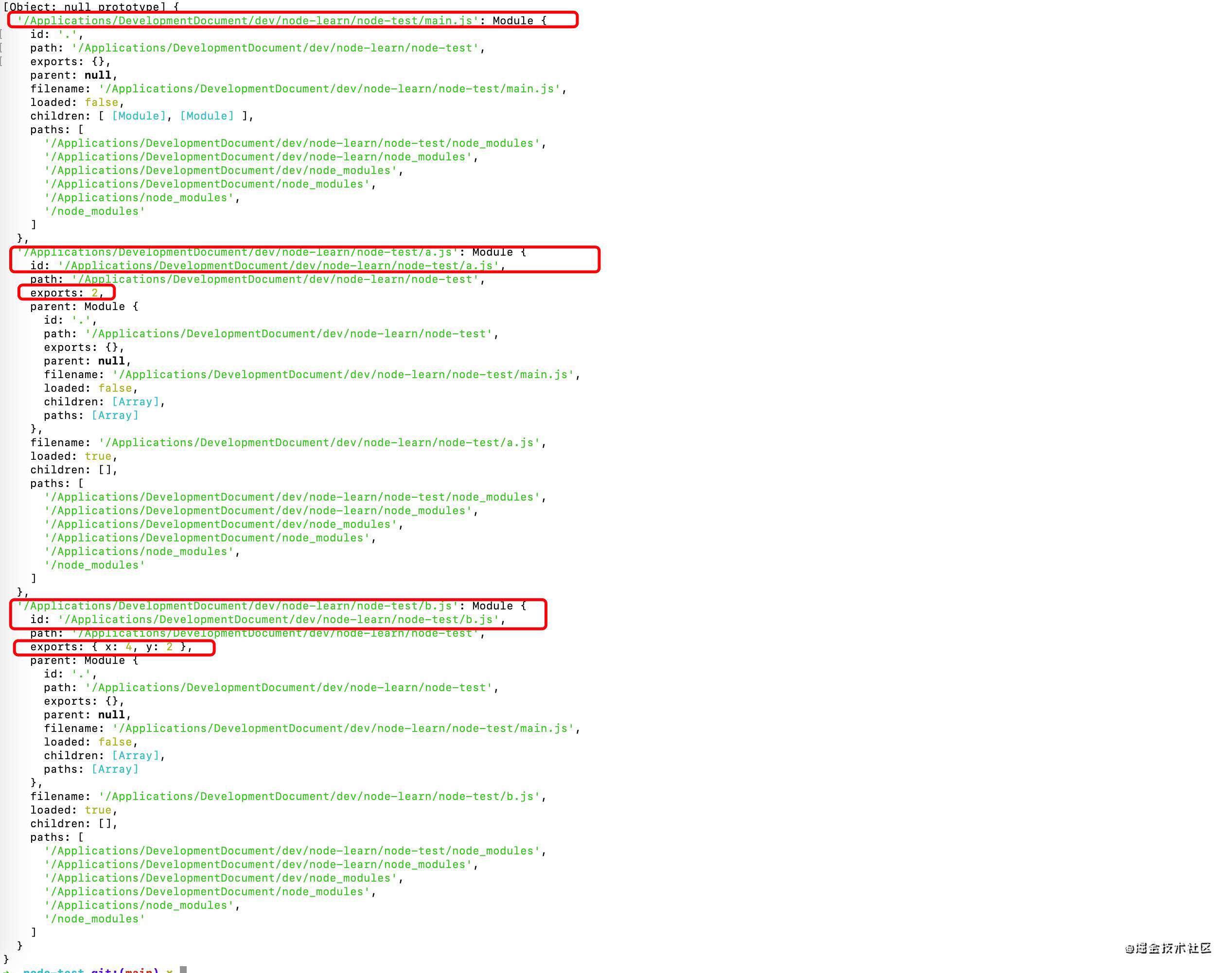
模块基于其文件名进行缓存(绝对路径),由于调用模块的位置的不同,模块可能被解析成不同的文件名(比如从 node_modules 目录加载),这样就不能保证 require('xx') 总能返回完全相同的对象。
此外,在不区分大小写的文件系统或操作系统中,被解析成不同的文件名可以指向同一文件,但缓存仍然会将它们视为不同的模块,并多次重新加载。 例如, require('./a') 和 require('./A') 返回两个不同的对象,而不会管 ./a 和 ./A 是否是相同的文件。
模块的循环引用
// a.js
console.log('a starting');
exports.done = false;
const b = require('./b.js');
console.log('in a, b.done = %j', b.done);
exports.done = true;
console.log('a done');
// b.js
console.log('b starting');
exports.done = false;
const a = require('./a.js');
console.log('in b, a.done = %j', a.done);
exports.done = true;
console.log('b done');
// main.js
console.log('main starting');
const a = require('./a.js');
const b = require('./b.js');
console.log('in main, a.done = %j, b.done = %j', a.done, b.done);
// 运行结果
$ node main.js
main starting
a starting
b starting
in b, a.done = false
b done
in a, b.done = true
a done
in main, a.done = true, b.done = true
- node main.js
- require a.js,load a.js,输出“a starting“
- a: exports.done = false,require b.js,load b.js
- 输出”b starting“,b: exports.done = false
- require a.js, 由于a.js没有执行完,将未完成的副本导出,所以 a = {done: false}
- 输出in b, a.done = false
- b: exports.done = true,输出b done,b.js执行完毕,返回a.js继续执行
- b = { done: true },输出in a, b.done = true,输出a done
- a.js 执行完毕,a = { done: true } ,返回 main.js 继续执行,require b.js
- 由于 b.js 已经被执行完毕,缓存中拿值,现在 a = { done: true }, b = { done: true }
- 输出in main, a.done = true, b.done = true
循环依赖的时候为什么不会无限循环引用
源码解析:有兴趣的同学可以看看这里
不会循环引用的大体思路是:
- require('./a.js');此时会调用 self.require(), 然后会走到module._load,在_load中会判断./a.js是否被load过,当然运行到这里,./a.js还没被 load 过,所以会走完整个load流程,直到_compile。
- 运行./a.js,运行到 exports.done = false 的时候,给 esports 增加了一个属性。此时的 exports={done: false}。
- 运行require('./b.js'),同 第 1 步。
- 运行./b.js,到require('./a.js')。此时走到_load函数的时候发现./a.js已经被load过了,所以会直接从_cache中返回。所以此时./a.js还没有运行完,exports = {done.false},那么返回的结果就是 in b, a.done = false;
- ./b.js全部运行完毕,回到./a.js中,继续向下运行,此时的./b.js的 exports={done:true}, 结果自然是in main, a.done=true, b.done=true
未定义变量引用问题
// a.js
let a = 1;
a = a + 1;
x = 10;
module.exports = a;
// b.js
let b = {
x: 1,
y: 2,
};
b.x = 3;
console.log(x); // 10
module.exports = b;
// main.js
const a = require('./a');
console.log(a); // 2
const b = require('./b');
console.log(b.x); // 4
发现在 b.js 总可以访问到 a.js 未定义的变量 x。还可以正常获取到值。原因很简单,因为 x 是一个未声明的变量,也就是一个挂在全局的变量,那么在其他地方当然是可以拿到的。
exports和module.exports的区别
在 node 的 js 模块里可以直接调用 exports 和 module 两个“全局”变量,但是 exports 是 module.exports 的一个引用。在 node 编译的过程中,会把js模块编译成如下形式:
// require 是对 Node.js 实现查找模块的 Module._load 实例的引用
// __finename 和 __dirname 是 Node.js 在查找该模块后找到的模块名称和模块绝对路径
(function(exports, require, module, __filename, __dirname){
// ....
})
- exports 是 module.exports 的一个引用
- module.exports 初始化是一个{},exports 也只想这个{}
- require 引用返回的是 module.exports,而不是 exports
- exports.xxx = xxxx 相当于在导出对象上直接添加属性或者修改属性值,在调用模块直接可见
- exports = xxx 为 exports 重新分配内存,将脱离 module.exports ,两者无关联。调用模块将不能访问。
参考
- cnodejs.org/topic/56710…
- www.bookstack.cn/read/Nodejs…
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!