前言
当我在测试SparkStreaming的状态操作mapWithState算子时,当我们设置timeout(3s)的时候,3s过后数据还是不会过期,不对此key进行操作,等到30s左右才会清除过期的数据。
百度了很久,关于timeout的资料很少,更没有解决这个问题的文章,所以说,百度也不是万能的,有时候还是需要靠自己。

所以我就在周末研究了一下,然后将结果整理了出来,希望能帮助大家更全面的理解Spark状态计算。
mapWithState
按理说Spark Streaming实时处理,数据就像流水,每个批次之间的数据都是独立的,处理完就处理完了,不留下任何状态。但是免不了一些有状态的操作,例如统计从流启动到现在,某个单词出现了多少次,所以状态操作就出现了。
状态操作分为updateStateByKey和mapWithState,两者有着很大的区别。简单的来说,前者每次输出的都是全量状态,后者输出的是增量状态。
过期原理
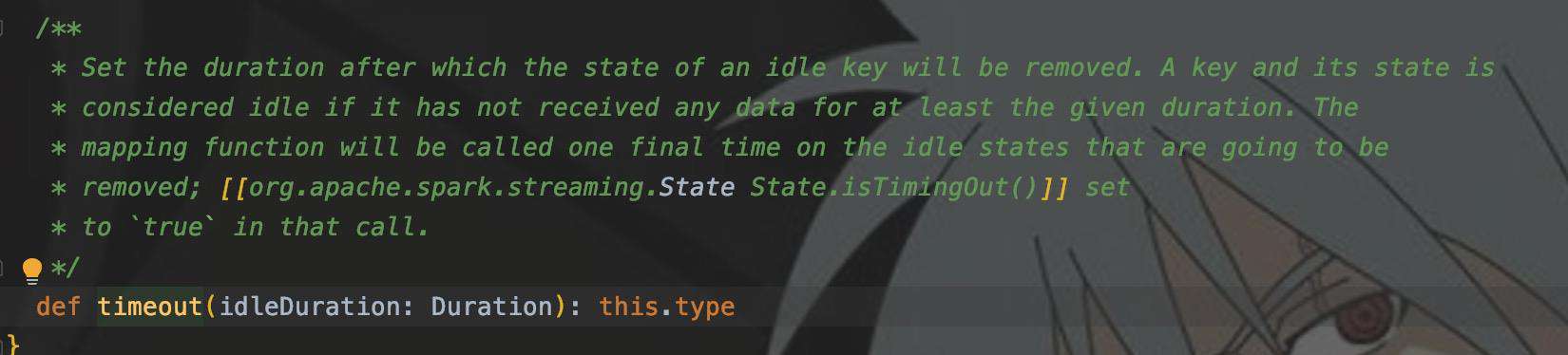
过期这一块估计很多人开始都理解错了,我刚开始理解就是数据从出现,经过多少秒之后就会过期。其实不是,这里的过期指的是空闲时间。
注释大概是这个意思:timeout()传入一个时间间隔参数,如果一个key在大于此间隔没有此key的数据流入,则被认为是空闲的,就会单独调用一次mapWithState中的func来清除这些空闲数据状态。
先写结论
使用了timeout()之后,需要使用以下代码来在间隔内清除失效key。
stream.checkpoint(Seconds(6))
checkpoint的时候,会开启全面扫描,才会对state中的失效key进行清理。
测试
val conf = new SparkConf().setMaster("local[2]").setAppName("state")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("./tmp")
val streams: DStream[(String, Int)] = ssc.socketTextStream("localhost", 9999)
.map(x => (x, 1))
val result = streams.mapWithState(StateSpec.function((k: String, v: Option[Int], state: State[Int]) => {
val count = state.getOption().getOrElse(0)
println(k)
println(v)
var sum = 0
if (!state.isTimingOut()) {
sum = count + v.get
state.update(sum)
} else {
println("timeout")
}
Option(sum)
})
.timeout(Seconds(3))
)
// 这行代码是触发清除机制的关键
// result.checkpoint(Seconds(6))
result.print()
ssc.start()
ssc.awaitTermination()
使用上面的代码进行测试,设置过期时间为3s。但是3s过后发现key并没有过期,也不会被清除,大概30S之后被清除。
在9999端口输入一个tom后,不再进行任何操作。测试结果如下:
tom
Some(1)
-------------------------------------------
Time: 1618228587000 ms
-------------------------------------------
Some(1)
tom
None
timeout
-------------------------------------------
Time: 1618228614000 ms
-------------------------------------------
Some(0)
从测试结果可以看出,从输入到清除大概是27s。
我们现在将注释的代码放开,每6s进行checkpoint一次,输入tom:
tom
Some(1)
-------------------------------------------
Time: 1618228497000 ms
-------------------------------------------
Some(1)
tom
None
timeout
-------------------------------------------
Time: 1618228506000 ms
-------------------------------------------
Some(0)
从生成到清除用了9秒,正好是过期时间 + 下一个窗口时间,触发了checkpoint。
猜想
第一次学状态操作的时候,就考虑如何去掉一些过期的key,通过timeout()的方法没有完成自己想法,从网上也没有找到解决方案,所以就暂且搁置在一边了。后来又回过头来考虑这个问题,然后根据自己的想法去猜想、去验证。
1. 我先看的是mapWithState()的返回值
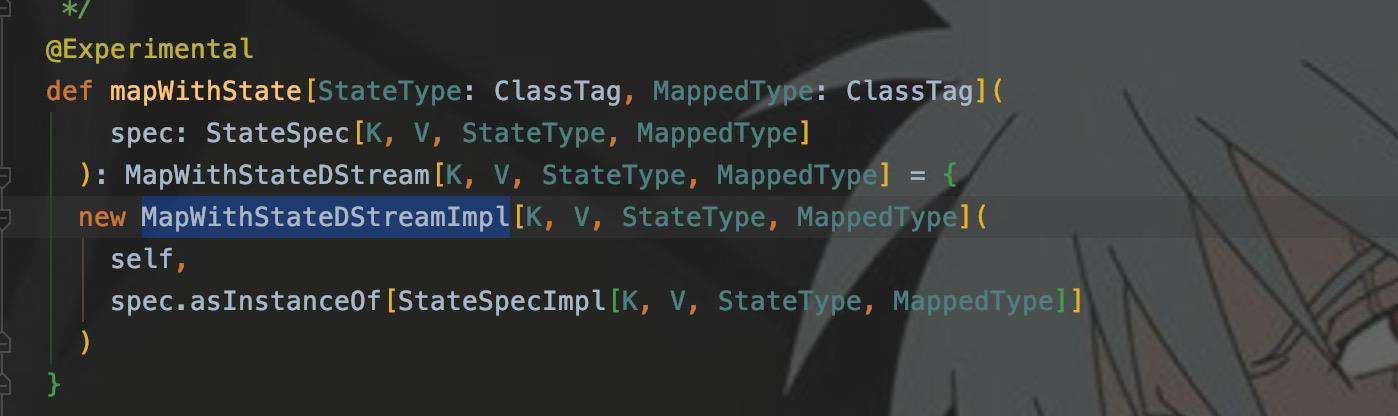
2. MapWithStateDStreamImpl
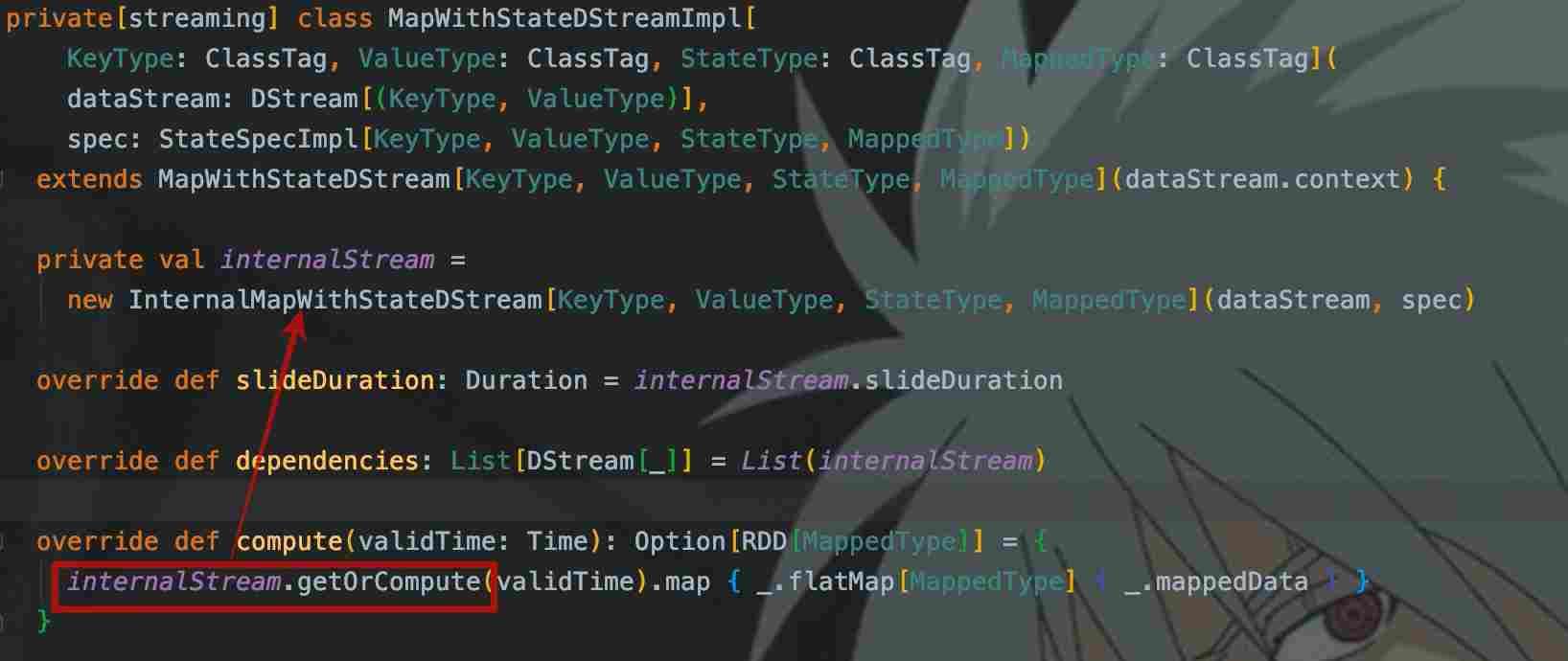
每个Dstream的计算逻辑都在compute()中,这里是调用了internalStream的getOrCompute(),根据继承关系,调用的是父类Dstream的此方法:
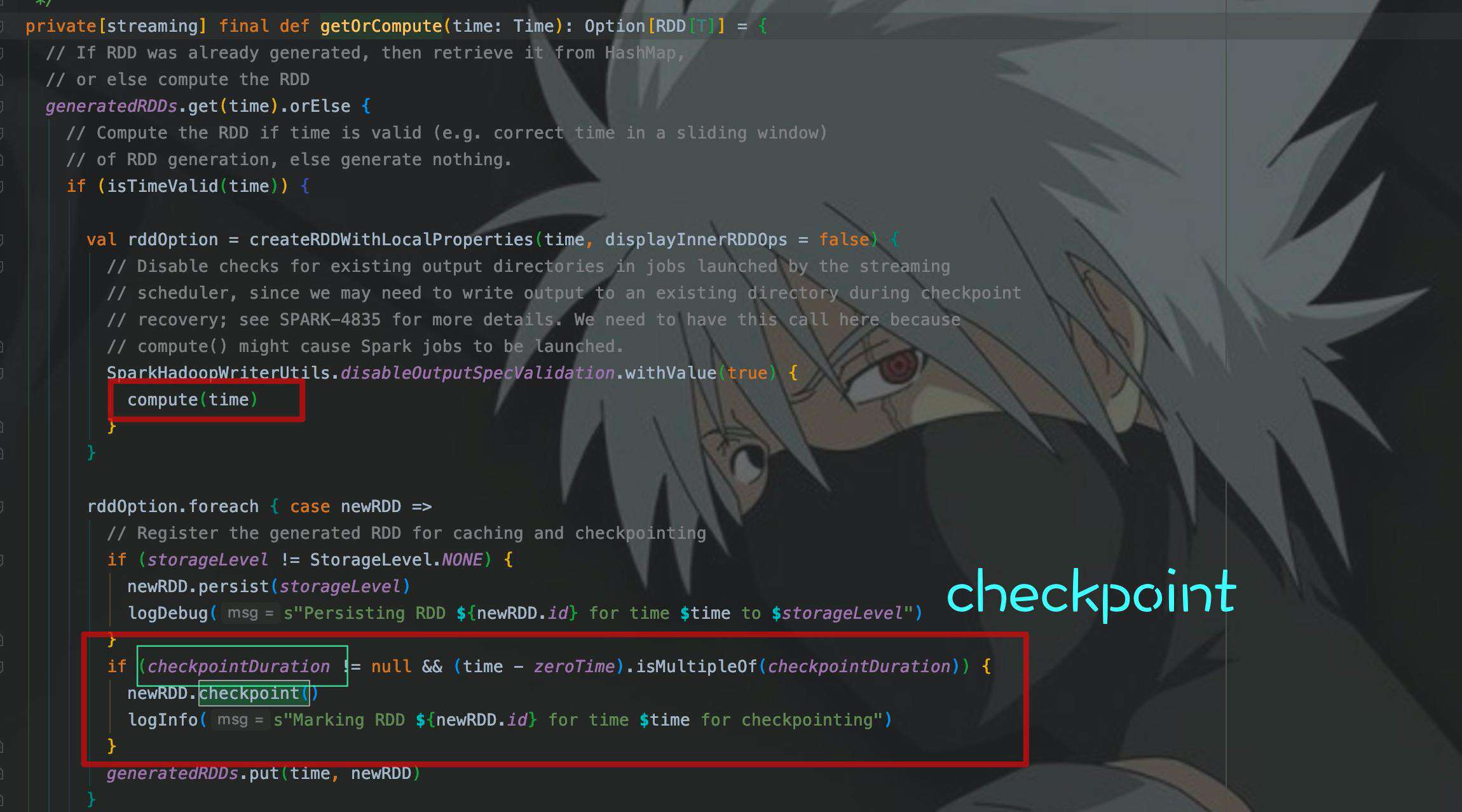
getOrCompute()主要功能为:计算、缓存、checkpoint。这里只需要记住几个地方:checkpointDuration,即checkpoint间隔,和调用了checkpoint()。其实真正的计算还是调用了compute(),接着去看compute()
3. InternalMapWithStateDStream
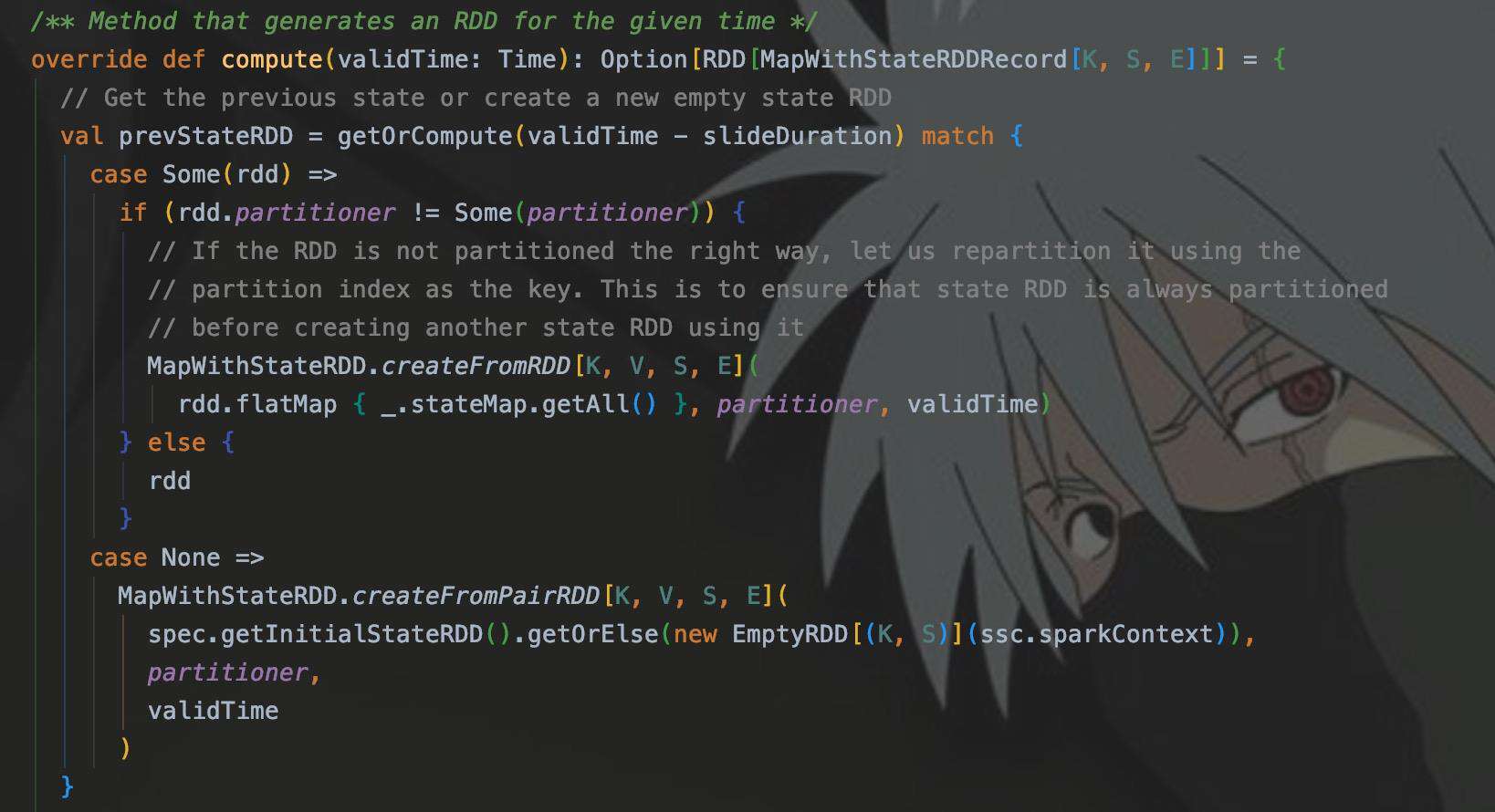
compute()里面也调用了getOrCompute()方法,其实和上面调用的一样,都是Dstream的,这里主要看的是使用createFromRDD()生成的StateRDD。
4. MapWithStateRDD
这个StateRDD就是参与状态计算的数据集合,首先看它是如何生成的:
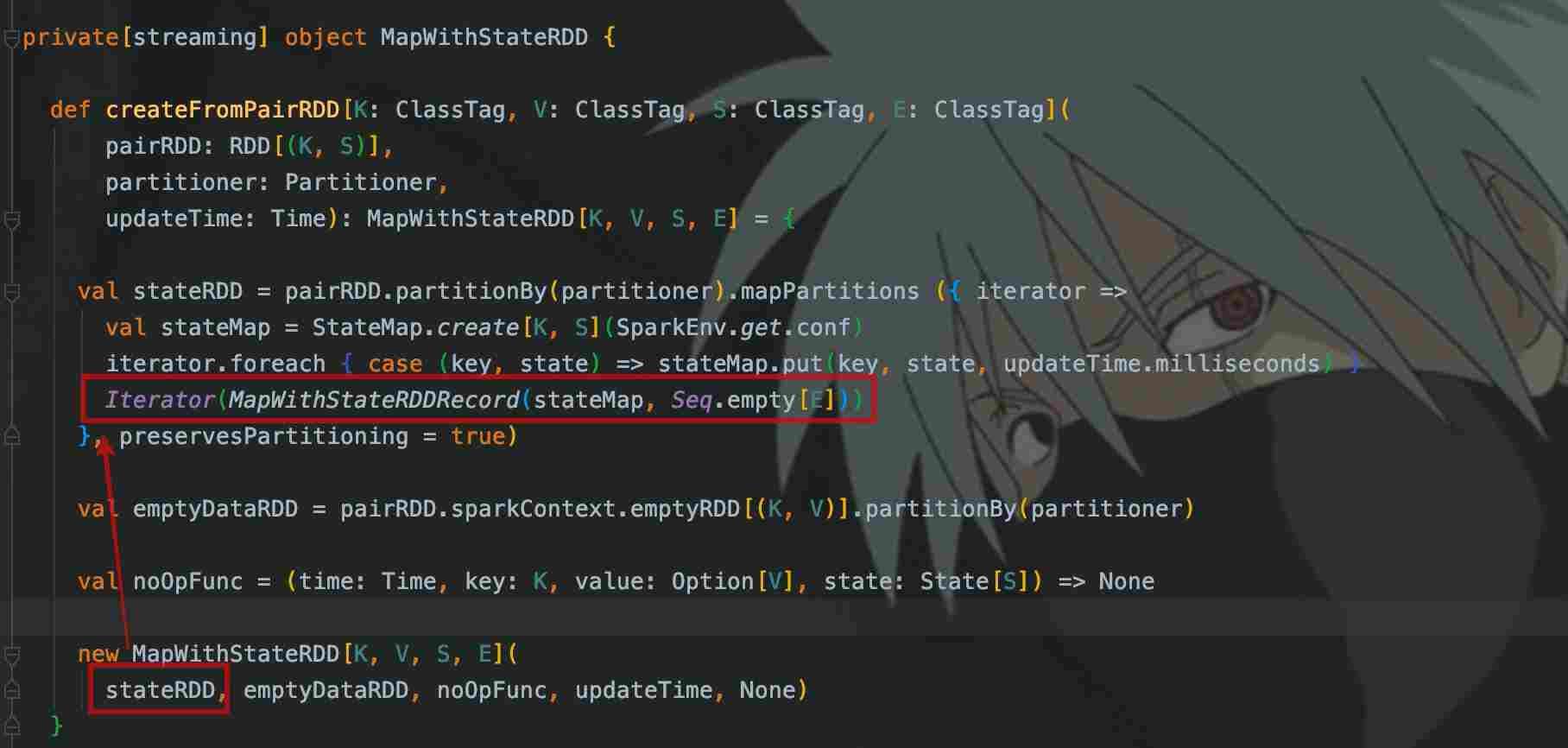
再看看StateRDD的compute()是如何计算的:
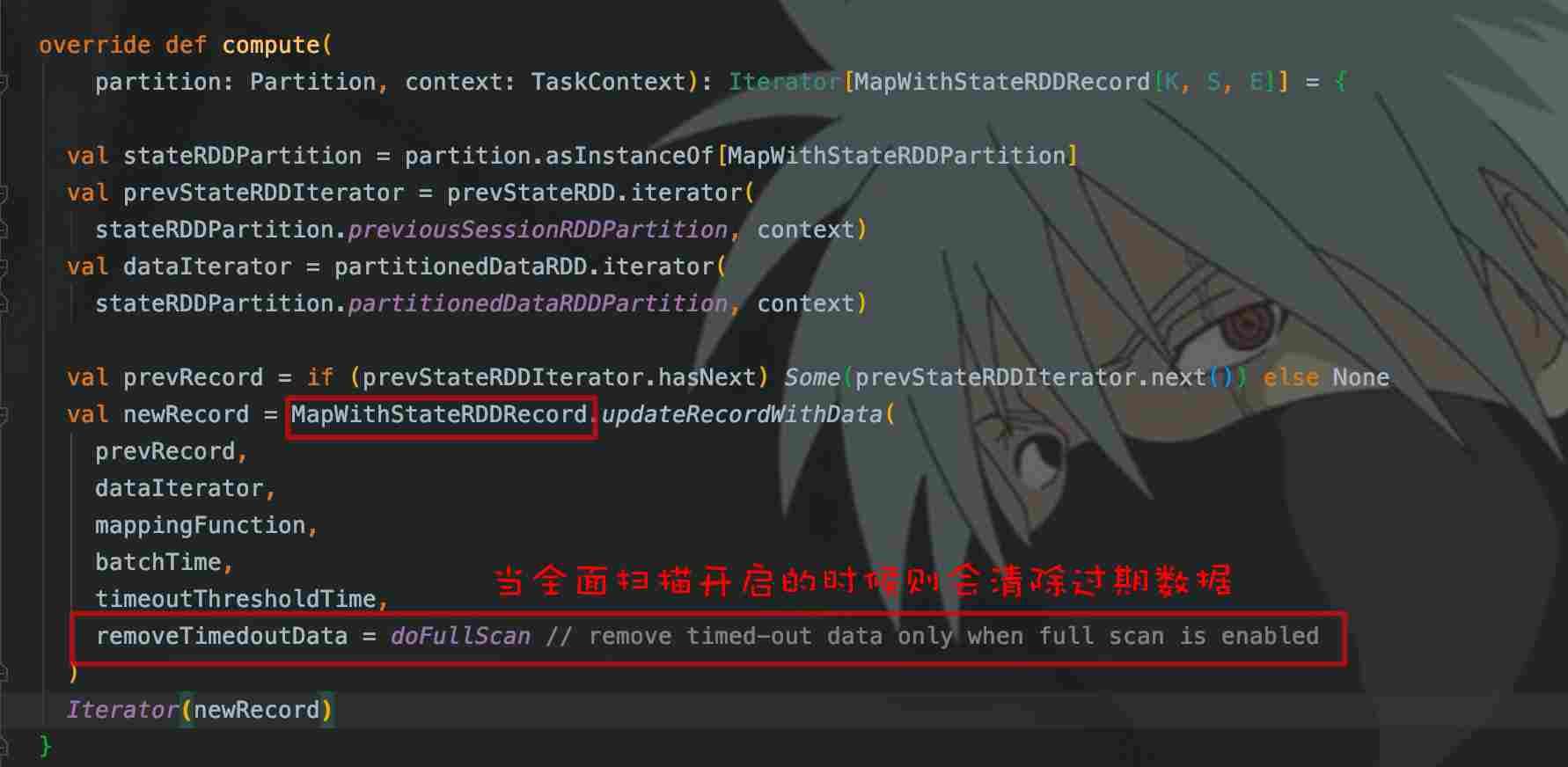
从compute()看出,当doFullScan为true的时候,才会触发过期key的清除,updateRecordWithData()负责全面扫描清除过期key。
这不,思路就来了,我们只要找到开启FullScan的方法,不就可以自行触发清除机制了吗!
那么,我们先看看doFullScan的默认值:

默认是没开启的,接着通过快捷键看看哪些地方使用了doFullScan:

从图中看出,有两处代码修改了doFullScan,我们找到这两处代码:


第一个基本上排除,那么就剩下第二个:checkpoint(),我们要知道的是,状态操作必须要checkpoint。
还记得在2中的getOrCompute()吗,当checkpointDuration不为null的时候,调用checkpoint()。
我们来看3中InternalMapWithStateDStream是如何定义这个duration的:
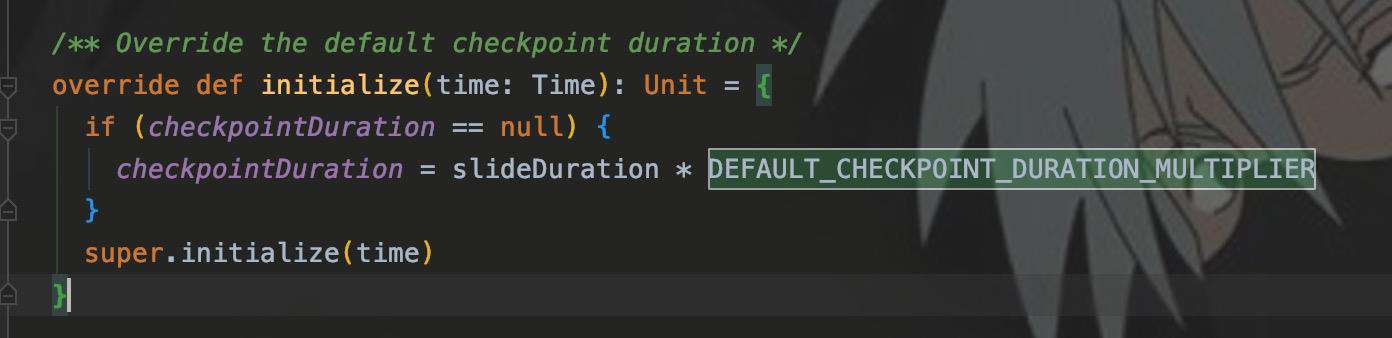

如图,sideDuration是窗口时间,乘以系数10就是默认的checkpoint时长,所以当我设置窗口为3s时,checkpoint周期就是30s,30s才会清理一次过期key。
而通过checkpoint(interval)可以设置checkpoint的间隔,所以覆盖了上面程序中默认的30s。
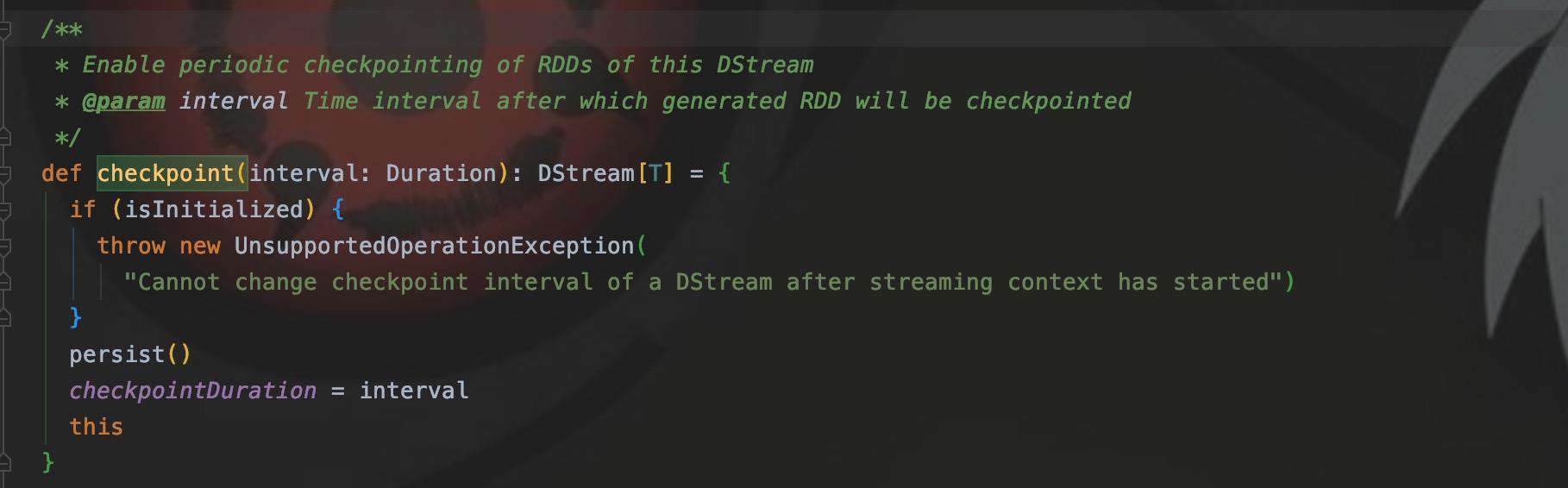
5.MapWithStateRDDRecord
最后提一提,FullScan是在这个类中开启的,所以先看看这个Record的注释介绍:

意思就是负责存储StateRDD的状态KV,updateRecordWithData()负责清除过期的Record,我们来看看这个方法的实现:
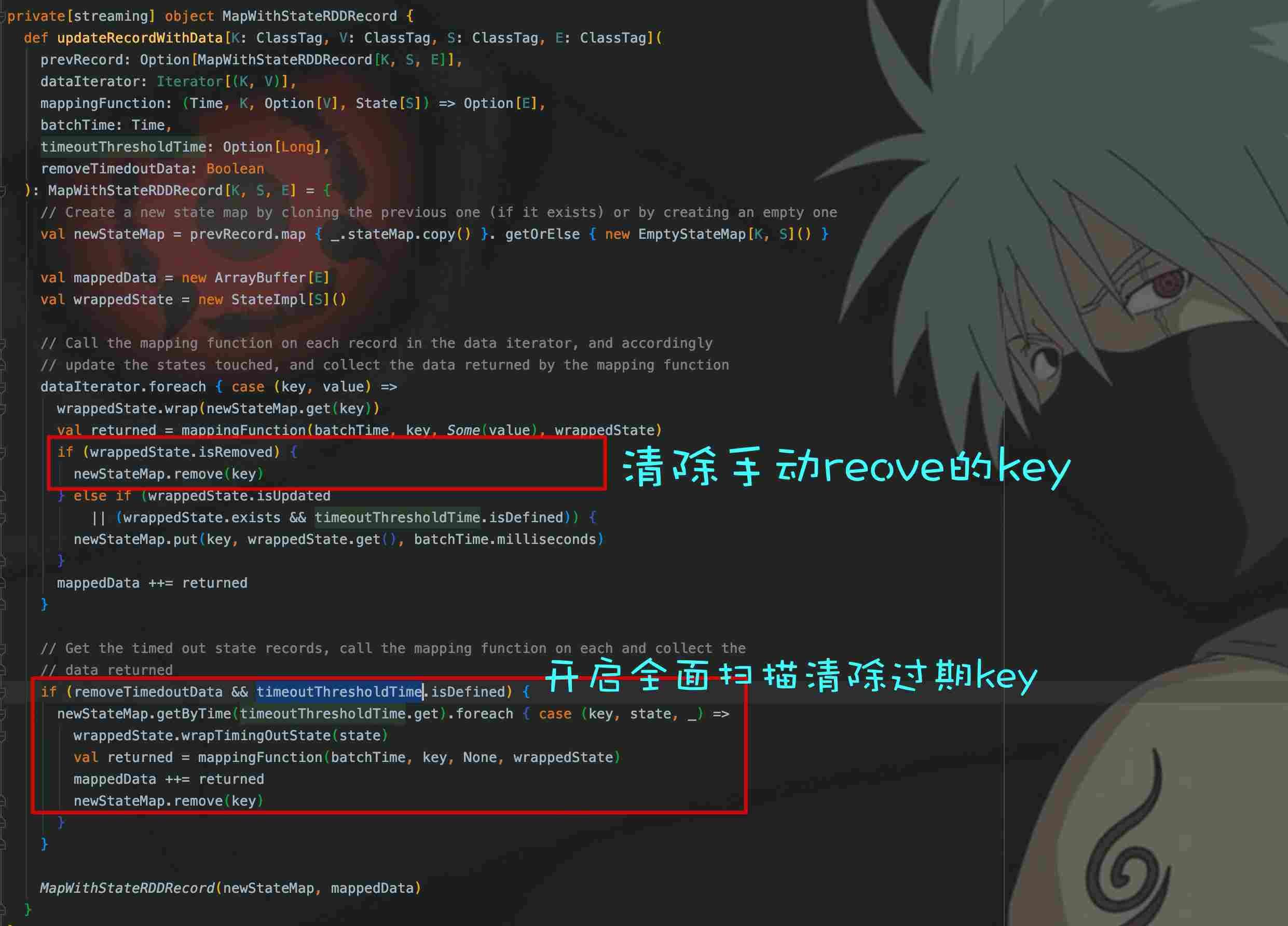
removeTimedoutData就是是否开启全面扫描,即doFullScan的值。
结语
写完看起来感觉真的是简简单单,逻辑看起来也比较清晰,但是自己去解决这个问题的时候也是花了一下午时间,过期key的清除与checkpoint有关也是我凭空弄猜想,然后分析了两次,某一瞬间才找到他们之间的关系。所以说,猜想和运气还是很重要的。
当然,找不到关于这块的文章和资料可能是因为这个知识点太小了。所以这次过后,要开始系统阅读Spark源码了,也希望在某一天能结合着自己的理解,写一下Spark的文章。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。
文章会在公众号 [入门到放弃之路] 首发,期待你的关注。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?


发表评论
还没有评论,快来抢沙发吧!