查找特定字符,替换特定文本,数据有效性的验证,以及看框架源码等,或多或少都会用到正则表达式。
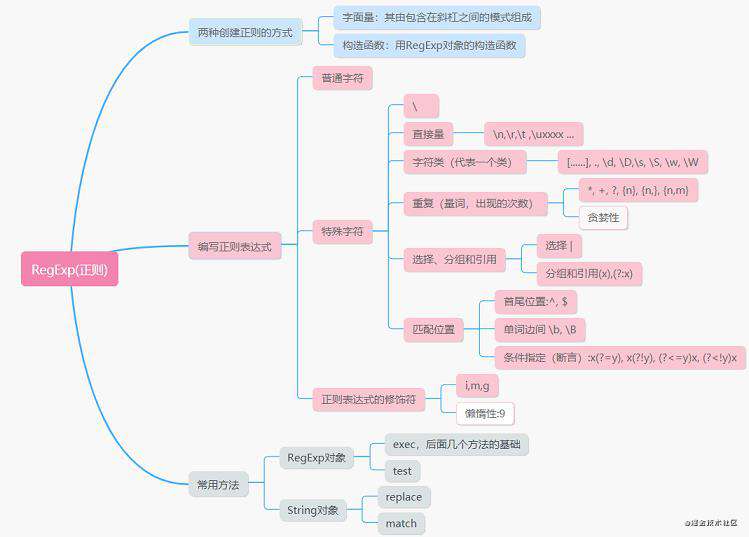
文章能了解:如何创建正则,如何理解编写正则,以及常用方法。看着上面那张图,大概率入个门不会懵。
概要:
- 两种创建正则的方式
- 编写正则表达式规则
- 常用方法
- 总结
1. 两种创建RegExp对象方法
> Regular expressions are patterns used to match character combinations in strings. In JavaScript, regular expressions are also objects.
正则表达式是用于匹配字符串中字符组合的模式。用来处理字符串的规则。
1.1字面量方式
字面量方式,由包含在 斜杠之间 的模式组成:
var re = /abc/;
脚本加载后,正则表达式字面量就会被编译。当正则表达式保持不变时,使用此方法可获得更好的性能。 举个小例子:
//字符串中是否包含123
let str = "123xiaoer";
let reg = /123/;
reg.test(str); //=>true
1.2RegExp对象的构造函数
RegExp对象的构造函数:
var re = new RegExp("abc");
在脚本运行过程中,用构造函数创建的正则表达式会被编译。如果正则表达式将会改变,或者它将会从用户输入等来源中动态地产生,就需要使用构造函数来创建正则表达式。
举个小例子:在Chrome浏览器页面查找功能(ctrl + f)
用户输入 字符串“Regexp”,动态生成一条正则表达式,查找出文中RegExp字符串。
2.编写正则表达式规则
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的规则。规则描述在搜索文本时要匹配的一个或多个字符串。
编写正则表达式需要了解:
- 简单字符(数字,字母,逗号,@符等按照字面含义匹配的符号,非特殊字符)
- 特殊字符(又叫元字符,一些有特殊含义的字符)
- \
- 字符类(代表一个类)
- 重复(量词,出现的次数)
- 选择、分组和引用
- 匹配位置
- 修饰符(i,m,g)
2.1 特殊字符
2.1.1 反斜杠 \
\ :指示 \ 相连接的字符被特殊对待或“转义”。它表现为两种方式之一。
对于通常按字面意义处理的字符,表示下一个字符是特殊字符,不应按字面意义进行解释。普通字符变特殊-> 如 \d
对于通常被特殊对待的字符,指示下一个字符不是特殊字符,应按字面意义进行解释。特殊字符变普通-> 如 \\d
2.1.2 直接量
常用的:
| 字符 | 含义 | \n | 换行符 | \r | 回车符 | \uxxxx | 匹配查找xxxx(四个十六进制数字)规定的Unicode字符。 |
|---|
2.1.3 字符类
特殊说明:
| 字符 | 含义 | [......] | 1.字符集。 匹配任何一个包含在方括号中的字符。[^.....]以^开头,匹配任何一个没有包含在方括号[.....]中的字符 2.此处需要注意连字符 -。可以使用连字符来指定字符范围[1-5],但如果连字符显示为方括号中的第一个或最后一个字符,则被视为作为普通字符-。 3.在方括号中出现\ 时需注意不一定是字符本意[\d] 相当于[0-9] 而不是 "\" 或 d。 | . | 1.匹配除行终止符之外的任何单个字符 2.在字符集内(方括号中),点失去了它的特殊意义,并与文字点匹配。 |
|---|
举个小例子:正则表达式/[xiaobu123]/ ( 使用的工具Regexper),展示如图
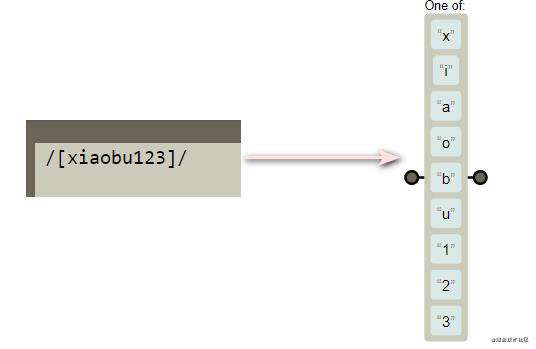
只要字符串从左到右匹配出现[xiaobu123]括号中的任意一个字母或数字,就满足此正则表达式规则/[xiaobu123]/
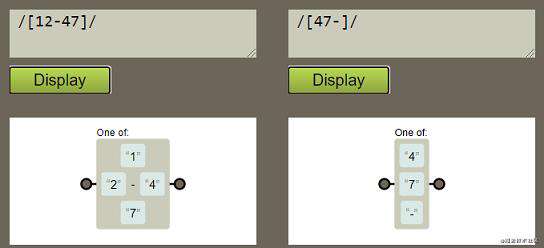
连字符 -出现在方括号中,可能是起连字符作用比如[12-47](匹配1,2,3,4,7这几个数字),也可能是匹配字符本身比如[-47]
常用的字符类:
| 常用匹配字符 | 含义 | \d | 匹配任何数字(阿拉伯数字), 相当于 [0-9] | \D | 匹配任何非数字(阿拉伯数字)的字符。相当于[^0-9] | \w | 匹配英文字母数字,下划线。相当于 [A-Za-z0-9_] | \W | 匹配任何不是英文字母数字,[^A-Za-z0-9_] | \s | 匹配任何 Unicode空白符的字符,空格,制表符,换页符等 | \S | 匹配任何非 Unicode空白符的字符。 |
|---|
2.1.4 重复(量词,出现的次数)
指定字符重复的标记:
| 语法 | 含义 | {n,m} | 匹配前一项至少n次,但不超过m次 | {n,} | 匹配前一项至少n次,或更多次 | {n} | 匹配前一项n次 | ? | 匹配前一项0次或1次,等价于 {0,1} | + | 匹配前一项至少1次或多次,等价于{1,} | * | 匹配前一项0次或多次,等价于 {0,} |
|---|
补充一个记忆点: ?+*(问就加一颗星~)
举个小例子:正则表达式/ab{3}/ ( 使用的工具Regexper),展示如图,看图方便理解
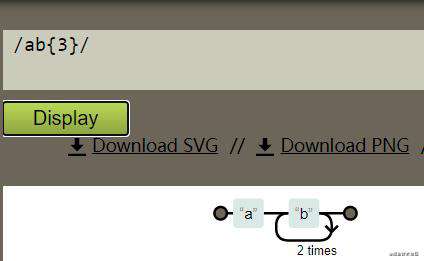
即字符串从左到右包含abbb串就符合此正则表达式规则
?+ * 结合图理解:
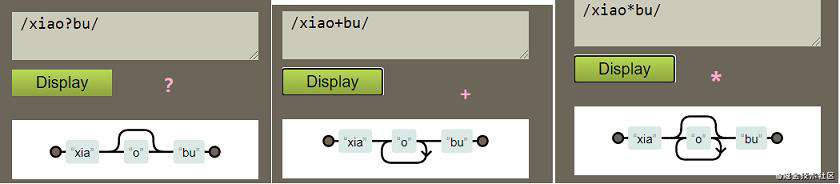
正则的一大特性贪婪性: 试图匹配尽可能多的字符串
| 符号 | 量词 | x*? x+? x?? x{n}? x{n,}? x{n,m}? | 默认情况下,像 * 和 + 等这样的量词是“贪婪的”,这意味着它们试图匹配尽可能多的字符串。在这些量词后面加 ?,这些量词就变成非贪婪的了,意味着一旦找到匹配项,就停止。 |
|---|
如图/\d+/和/\d+?/对同一字符串的匹配:
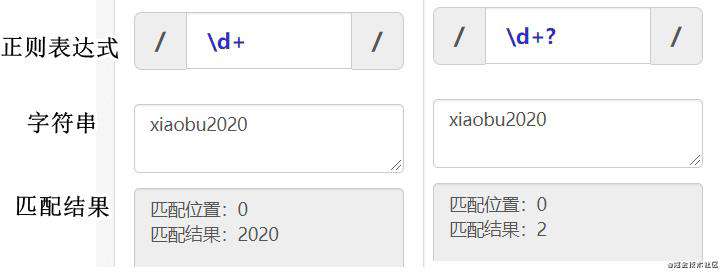 左图由于贪婪性,匹配尽可能多的字符串结果为2020,右图非贪婪匹配到数字2就停止匹配了。
左图由于贪婪性,匹配尽可能多的字符串结果为2020,右图非贪婪匹配到数字2就停止匹配了。
2.1.5 选择、分组和引用
选择:
| 语法 | 含义 | | | 或,匹配竖线左边或右边,比如/ab|bc/ 即字符串中有ab 或bc 即可 |
|---|
举个小例子:正则表达式/12|28/ ( 使用的工具Regexper),展示如图
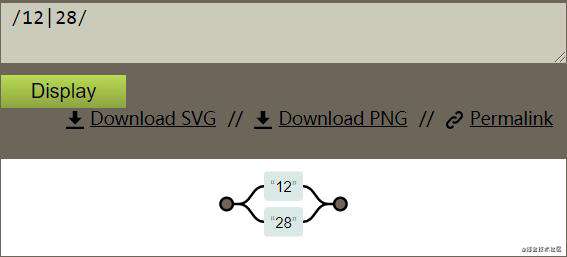
只要字符串从左到右匹配出现12或者28,就满足此正则表达式规则/12|28/
分组和引用:
| 语法 | 含义 | (xyz) | 1.分组: 将xyz的项分成一个组,以便整体匹配比如 /(abc){2}/ ,abc这一组字符串连续出现两次才能匹配 2.捕获:匹配括号的里面的项并记住匹配项。例如,/(foo)/匹配并记住“foo bar”中的“foo” 3.引用:正则表达式可能具有多个捕获组。捕获组中左括号的顺序数字为x,\x 则为第x个组捕获的字符的引用。 | (?:xyz) | 1.只将xyz的项分成一个组,但不捕获记忆。(只分组,不捕获) 2.捕获组会产生性能损失。 如果不需要调出匹配的子字符串,请使用非捕获括号 |
|---|
补充:如果只分组,不捕获引用,就使用(?:xyz)
举几个小例子:正则表达式/xiaobu(123|456)ha\1/ ( 使用的工具Regexper),展示如图:
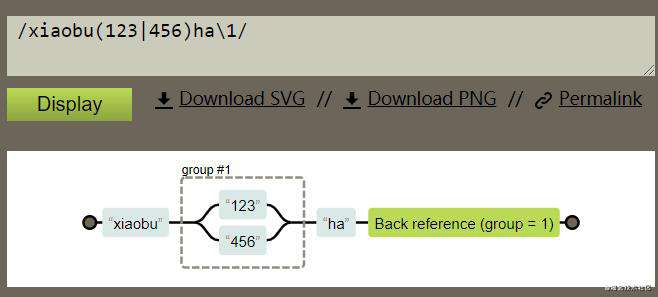
group1 捕获的是123,后面的\1 引用的就是123,group1 捕获的是456,后面的\1 引用的就是456。
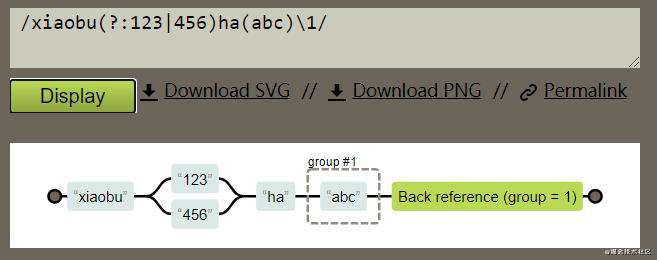
正则表达式/xiaobu(?:123|456)ha(abc)\1/ ( 使用的工具Regexper),展示如图: 可以和上图做比较(?:123|456) 并没有被捕获记忆。
2.1.6 匹配的位置
符号指定字符串匹配的“合法”位置:指定位置不是实际的字符
- 首尾位置
- 单词边间
- 条件指定(断言)
首尾位置指定符号
| 语法 | 含义 | ^ | 1.匹配输入字符串的开始位置 2.注意与在方括号[]表达式中使用区分,方括号[]表达式中使用表示不接受该方括号表达式中的字符集合[^......] | $ | 匹配输入字符串的结尾位置 |
|---|
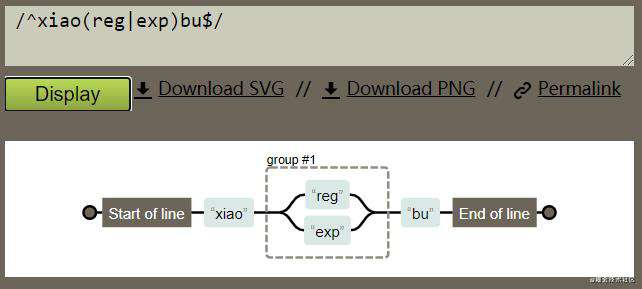
以/^xiao(reg|exp)bu$/ 为例 ( 使用的工具Regexper),展示如图:
单词边间:
| 语法 | 含义 | \b | 匹配一个单词的边界 | \B | 匹配非单词边界的位置 |
|---|
\b 匹配一个单词的边界:指定\w和\W 之间的位置、字符\w和字符串开头之间位置、字符\w和字符串结尾之间位置。用法:
- /\b表达式/ 匹配符串中单词以表达式开头部分(单词起始位置)
- /表达式\b/ 匹配字符串中单词以表达式结尾部分(单词结束位置)
- /\b表达式\b/ 匹配字符串中存在表达式的单词
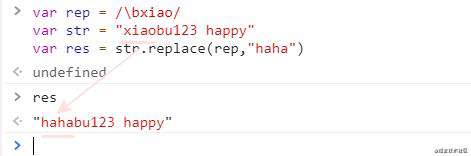
举个例子:
var rep = /\bxiao/
var str = "xiaobu123 happy"
var res = str.replace(rep,"haha")
结果
var rep = /\Bis/
var str = "This is a test"
正则会匹配单词This 中的is

条件指定: ?=、?<=、?!、?<!
| 语法表达 | 含义 | x(?=y) | 向前断言: x 被 y 跟随时匹配 x。例如,对于/Jack(?=Sprat)/,“Jack”在跟有“Sprat”的情况下才会得到匹配./Jack(?=Sprat | x(?!y) | 向前否定断言: x 没有被 y 紧随时匹配 x。例如,对于/\d+(?!.)/,数字后没有跟随小数点的情况下才会得到匹配。 | (?<=y)x | 向后断言: x 跟随 y 的情况下匹配 x。例如,对于/(?<=Jack)Sprat/,“Sprat”紧随“Jack”时才会得到匹配。对于/(?<=Jack | (?<!y)x | 向后否定断言: x 不跟随 y 时匹配 x。例如,对于/(?<!-)\d+/,数字不紧随-符号的情况下才会得到匹配。(有旧版浏览器兼容问题) |
|---|
总结,就是x在y前出现匹配,就是x不在y前出现匹配,就是x在y后出现匹配,就是x不在y后出现匹配,
2.2. 修饰符
正则表达式的修饰符,用来修饰规则
常用的有 i,m,g : (记忆点,图片标签img)
| 语法 | 含义 | i | 执行不区分大小写的匹配,搜索时不区分大小写: A 和 a 没有区别。 | m | 多行匹配。(这种修饰符下,边界字符 ^ 和 $ 匹配每一行的开头和结尾,多行,而不是整个字符串的开头和结尾) | g | 全局匹配,查找所有的匹配项而不是第一个就停止。 |
|---|
正则的一个特性懒惰性:查找到一个匹配项就是停止查找,如果要全局查找就需要加上修饰符g
如图/\d+/g和/d+/对同一字符串的匹配:左图是全局匹配,会查找所有匹配项。右图不是全局匹配,查找到第一个满足的项就停止查找了。
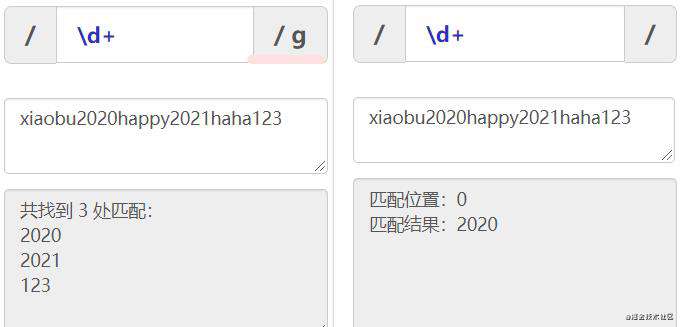
3.常用方法
正则常用的方法:
- RegExp对象
- exec (需要捕获结果时使用)
- test (只是为了判断是否匹配时使用)
- String对象
- match
- replace
3.1 RegExp对象
RegExp实例的属性 lastIndex:表示从哪里开始下一个匹配。默认值为 0。(还有其它属性本文查看文档)
如果正则表达式设置了全局标志g,lastIndex才会在每次匹配中变化
3.1.1 exec()
RegExp实例的属性 lastIndex:表示从哪里开始下一个匹配。默认值为 0。
exec() 方法在一个指定字符串中执行一个搜索匹配。返回一个结果数组或 null。
返回一个数组时的结构:包括第一个完整匹配的字符串和相关的捕获组,index,input 属性。
| 对象 | 索引/属性 | 表达的意思 | 数组 | 0 | 数组第0位为,第一个匹配的字符串 | [1]~[n] | 数组第n位:表示正则表达式捕获组中左括号的顺序数字为n,第n个组捕获的字符 | index | 匹配到的字符位于原始字符串的基于0的索引值 | input | 原始字符串 |
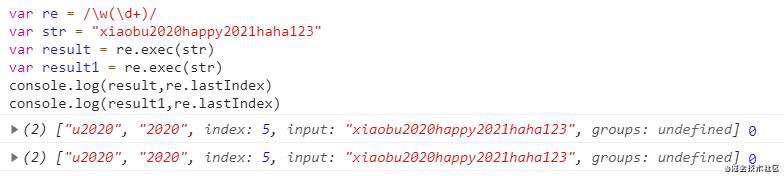
var re = /\w(\d+)/
var str = "xiaobu2020happy2021haha123"
var result = re.exec(str)
console.log(result)
console.log(re.lastIndex)
// 输出
// [
// 'u2020', 匹配的全部字符串,数组第0位
// '2020', 括号中的分组捕获,数组第1位
// index: 5, 匹配到的字符位于原始字符串的基于0的索引值
// input: 'xiaobu2020happy2021haha123', 原始字符串
// groups: undefined
// ]
// 0
因为正则表达式的懒惰性多次执行re.exec(str)结果也不会改变。
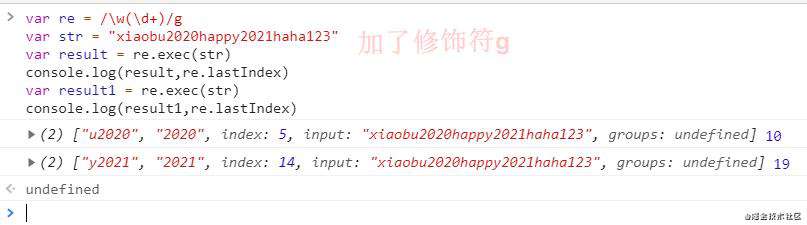
 要想将整个字符串查找匹配就要修改,正则的规则添加修饰符g,多次执行re.exec(str)结果发生了变化,此时lastIndex 也变化了
要想将整个字符串查找匹配就要修改,正则的规则添加修饰符g,多次执行re.exec(str)结果发生了变化,此时lastIndex 也变化了
如果正则表达式设置了全局标志,exec() 的执行会改变正则表达式 lastIndex属性
3.1.2 test()
test() 方法执行一个检索,用来查看正则表达式与指定的字符串是否匹配。返回 true 或 false。
如果正则表达式设置了全局标志,test() 的执行会改变正则表达式lastIndex属性
test()使用同 exec()方法,只是返回结果不同,返回true或false。
3.2 String 对象
3.2.1 match()
match() 方法检索返回一个字符串匹配正则表达式的结果。
- 未使用g标志,返回结果同exec()
- 使用g标志,则将返回与完整正则表达式匹配的所有结果,但不会返回捕获组。
未使用g标志,返回结果同exec():
var re = /\w(\d+)/
var str = "xiaobu2020happy2021haha123"
var result = str.match(str)
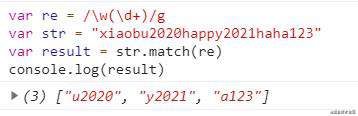
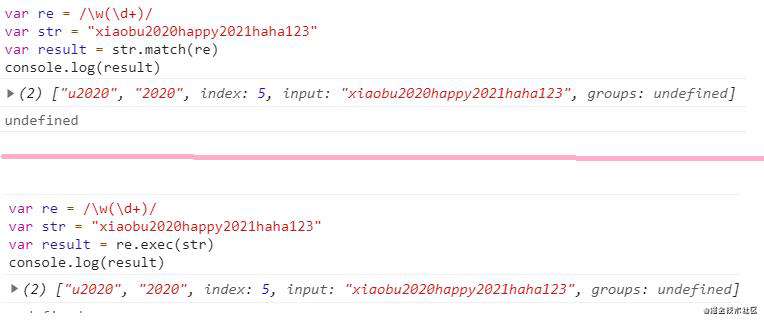 使用g标志,则将返回与完整正则表达式匹配的所有结果,但不会返回捕获组:
使用g标志,则将返回与完整正则表达式匹配的所有结果,但不会返回捕获组:
3.2.2 replace()
文章感兴趣的是 str.replace(regexp,function)这种用法,其它用法参考文档
function 被内部调用时接收的参数,跟exec()执行得到的结果一致,按顺序接收到,匹配的字符串,捕获组展开,index值(匹配到的字符位于原始字符串的基于0的索引值,input被匹配的原字符串。 function return 的值就是用来替换匹配到的字符串的值
举个例子:
var re = /\w(\d+)/
var str = "xiaobu2020happy2021haha123"
var result = str.replace(re, function() {
console.log(arguments)
})

如果使用g标志,正则匹配多少次,就执行多少次function。
4. 总结
文章整理了相关资料,比较基础,没有写到正则的回溯,有兴趣的同学可以深入下去。
文章理解不准确之处,还请斧正。欢迎一起讨论学习。
书籍:《JavaScript权威指南》
工具:Regexper
文章:
developer.mozilla.org/en-US/docs/…
developer.mozilla.org/en-US/docs/…
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!