大家好,我是微微笑的蜗牛,?。
这篇文章主要讲述 html 的解析过程,实现一个小小的 html 解析器。
html 规则
html 中包含一系列的标签,有单个的,也有嵌套的。同时标签中还可携带属性数据。
比如:
<html>
<body>
<h1>Title</h1>
<div id="main" class="test">
<p>Hello <em>world</em>!</p>
</div>
</body>
</html>
<h1>是单个标签,<div>中带有子标签<p>。id="main",是<div>标签中的属性。h1标签内的"Title"属于文本。
如果要完全实现 html 解析的功能,那将会考虑到很多种场景。为了简单起见,这里我们只实现如下基础功能:
- 完整配对标签的解析,比如
<div></div>,但<div/>这种不支持。 - 标签内属性的解析。
- 文本节点的解析。
其他的,比如注释、字符编码、doctype 声明等等,统统不支持。
而 html 本质上就是一些文本,我们的目的就是从这些文本中解析出标签和属性,以结构化的数据输出。
数据结构
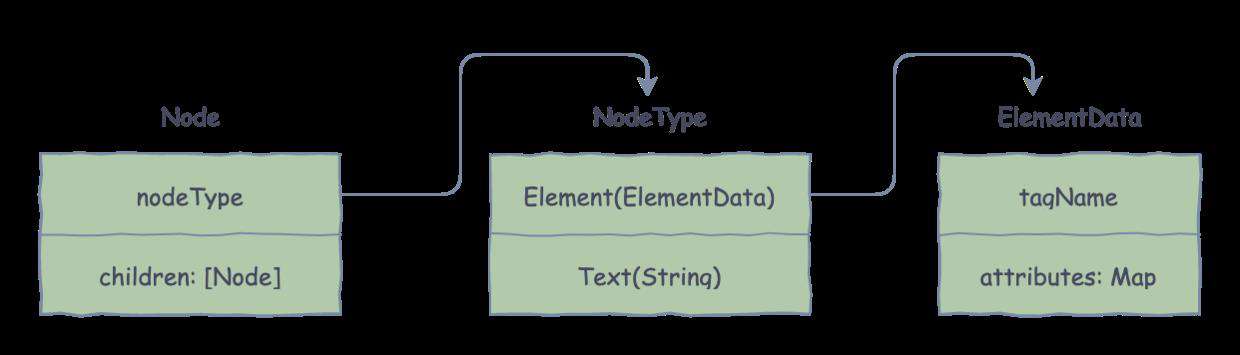
首先,需要定义一套合适的数据结构,来清晰的描述输出结果。
根据上面的最小功能描述,我们只需完成标签、属性、文本的解析。注意标签可以嵌套,并且只有标签才会存在属性。
这里,我们将标签/文本抽象为节点,节点可包含一系列的数据,比如子节点、类型。
于是,可定义出节点的数据结构:
// 节点
public struct Node {
// 子节点
public let children: [Node]
// 节点类型
public let nodeType: NodeType
}
节点类型,分为元素节点和文本节点,采用枚举类型并关联数据,定义如下:
// 节点类型
public enum NodeType {
case Element(ElementData)
case Text(String)
}
ElementData 为元素类型关联的数据,包括标签名和属性,定义如下:
public typealias AttrMap = [String:String]
// 标签元素结构
public struct ElementData {
// 标签名
public let tagName: String
// 属性
public let attributes: AttrMap
}
若觉得看代码麻烦,也可看下图中的数据结构定义。
主体数据结构定义完毕,下面开始进行标签的解析。
但,别急。在解析之前,首先得做一些准备工作,实现一个文本扫描的工具类,因为 css 解析中也会用到同样的扫描代码。
文本扫描工具类
这个工具类 SourceHelper 比较简单,主要是为了辅助处理文本扫描,包括如下功能:
- 读取下一个字符
- 是否以 xx 开头
- 是否到字符串末尾
- 消费单个字符
- 循环消费字符,如果字符满足指定条件
- 跳过空白字符
其结构定义如下,包括游标和源字符串两个字段。
public struct SourceHelper {
// 位置游标
var pos: String.Index
// 源字符串
var input: String
}
下面,我们简单过一下函数实现。
- 读取下一个字符
仅读取,但游标不移动。
// 返回下一个字符,游标不动
func nextCharacter() -> Character {
return input[pos]
}
- 判断是否以 xx 字符串开头
// 是否以 s 开头
func startsWith(s: String) -> Bool {
return input[pos...].starts(with: s)
}
- 游标是否移动到了末尾
// 是否到了末尾
func eof() -> Bool {
return pos >= input.endIndex
}
- 读取单个字符,移动游标
// 消费字符,游标+1
mutating func consumeCharacter() -> Character {
let result = input[pos]
pos = input.index(after: pos)
return result
}
- 当字符满足指定条件时,循环消费字符
// 如果满足 test 条件,则循环消费字符,返回满足条件的字符串
mutating func consumeWhile(test: (Character) -> Bool) -> String {
var result = ""
while !self.eof() && test(nextCharacter()) {
result.append(consumeCharacter())
}
return result
}
- 跳过空白字符
// 跳过空白字符
mutating func consumeWhitespace() {
_ = consumeWhile { (char) -> Bool in
return char.isWhitespace
}
}
节点解析
节点分为标签节点和文本节点。标签节点的特征很明显,以 < 开头。
因此,我们可将其作为一个标识。当扫描文本时,遇到 <,则可认为是解析标签;其余的,则看做是解析文本。
那么,也就能构建出大致的解析方式:
// 解析节点
mutating func parseNode() -> Node {
switch sourceHelper.nextCharacter() {
// 解析标签
case "<":
return parseElement()
default:
// 默认解析文本
return parseText()
}
}
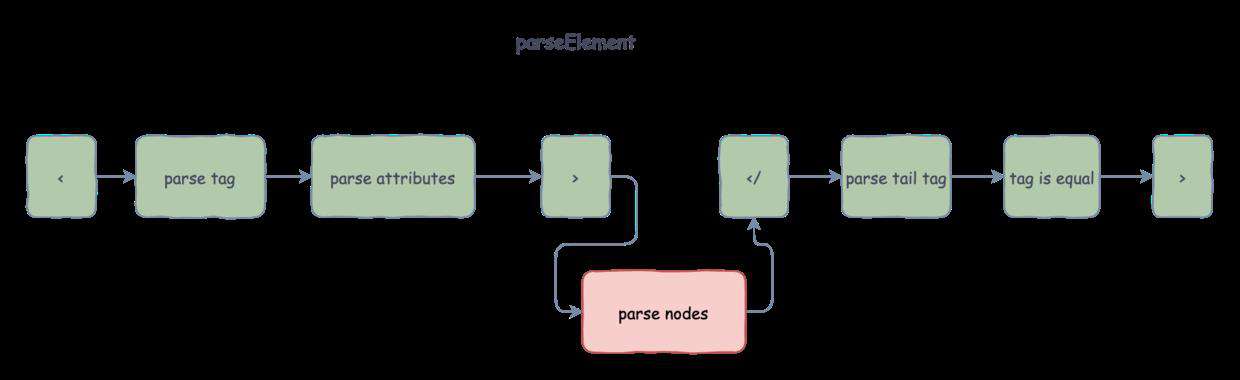
标签解析
首先,考虑最简单的情况,单个标签的解析,比如<div></div>。
标签信息包括标签名和属性,这里属性解析暂且放一放,只提取标签名。
标签名的提取,只需将 <> 之间的字符串提取出来。但是,要注意标签闭合配对情况。
其解析过程分为如下几步:
- 确保标签以
<开始。 - 提取标签名,直至遇到
>结束。 - 保证标签以
</闭合。 - 提取末尾标签名,确保与前面的标签匹配。
<div></p>,这种就不是有效标签,因为p和div不匹配。 - 最后,确保末尾字符以
>结束。
// 解析标签
// <div></div>
mutating func parseElement() -> Node {
// 确保以 < 开头
assert(self.sourceHelper.consumeCharacter() == "<")
// 解析标签,tagName = div
let tagName = parseTagName()
// 确保标签结束是 >
assert(self.sourceHelper.consumeCharacter() == ">")
// 确保标签闭合 </
assert(self.sourceHelper.consumeCharacter() == "<")
assert(self.sourceHelper.consumeCharacter() == "/")
// 确保闭合标签名与前面标签一致
let tailTagName = parseTagName()
assert(tagName.elementsEqual(tailTagName))
// 确保以 > 结束
assert(self.sourceHelper.consumeCharacter() == ">")
...
}
元素解析完整流程如下图所示:

标签名解析
有效的标签名,为字母和数字的组合。
这时候,辅助工具中的 consumeWhile 方法就派上用场了。如果字符满足是字母或者数字时,则一直向后遍历字符,直至遇到不满足条件的字符为止。
// 解析标签名
mutating func parseTagName() -> String {
// 标签名字,a-z,A-Z,0-9 的组合
return self.sourceHelper.consumeWhile { (char) -> Bool in
char.isLetter || char.isNumber
}
}
属性解析
标签中还可能存在属性数据,比如 <div id="p1" class="c1"></div>,id、class 就是属性信息。
属性定义也有它的规则:以 = 分隔,左边是属性名,右边是属性值。
从栗子中可以看出,属性的定义,位置在标签名之后。因此,在提取出标签后,便可进行属性的解析,以 map 形式存储。
对于 id="p1" class="c1" 这串文本,我们要将其解析成 {"id": "p1", "class": "c1"} 的形式。
- 首先,来看下单个属性的解析。
- 解析属性名,有效属性名的规则可套用标签名。
- 确保中间是等号。
- 解析属性值,属性值以
""或者''包裹。
// 解析单个属性
mutating func parseAttribute() -> (String, String) {
// 属性名
let name = parseTagName()
// 中间等号
assert(self.sourceHelper.consumeCharacter() == "=")
// 属性值
let value = parseAttrValue()
return (name, value)
}
对于属性值来说,需确保其格式正确以及引号的配对。
- 确保字符以双引号
"或者单引号'开头 - 取出引号之间的字符串,当遇到右引号结束
- 判断引号配对
// 解析属性值,遇到 " 或 ' 结束
mutating func parseAttrValue() -> String {
let openQuote = self.sourceHelper.consumeCharacter()
// 以单引号或双引号开头
assert(openQuote == "\"" || openQuote == "'")
// 取出引号之间的字符
let value = self.sourceHelper.consumeWhile { (char) -> Bool in
char != openQuote
}
// 引号配对
assert(self.sourceHelper.consumeCharacter() == openQuote)
return value
}
- 多个属性的解析,使用循环即可,在遇到
>退出循环。
// 解析属性,返回 map
mutating func parseAttributes() -> AttrMap {
var map = AttrMap()
while true {
self.sourceHelper.consumeWhitespace()
// 如果到 opening tag 的末尾,结束
if self.sourceHelper.nextCharacter() == ">" {
break
}
// 解析属性
let (name, value) = parseAttribute()
map[name] = value
}
return map
}
并列标签解析
当有多个并列标签时,又该如何进行解析呢?
<div></div>
<div></div>
同样的套路,循环解析即可,返回节点数组。
// 循环解析节点
mutating func parseNodes() -> [Node] {
var nodes: [Node] = []
while true {
self.sourceHelper.consumeWhitespace()
// "</" 的判断,目的是:当无嵌套标签时,能跳出循环。比如,<html></html>,在解析完<html>后,会重新调用 parseNodes 解析子标签
// 这时字符串是 </html>。
if self.sourceHelper.eof() || self.sourceHelper.startsWith(s: "</") {
break
}
// 解析单个节点
let node = self.parseNode()
nodes.append(node)
}
return nodes
}
子标签解析
对于标签嵌套的情况,如下所示:
<div><p></p></div>
那么如何解析出子标签 <p></p> 呢?
先观察下 <p> 标签的位置,位于 <div> 之后。确切的说,在 > 之后。因此,我们可以在这个时机进行子标签的解析。
子标签 <p></p>,它跟普通标签的解析毫无差别。只是在解析出标签后,需要添加到父标签的 children 中,所以会采用递归的方式。
这样一来,我们便可在 > 的判断之后,添加新一轮节点解析代码:
// 确保标签结束是 >
assert(self.sourceHelper.consumeCharacter() == ">")
// 解析嵌套子节点
let children = parseNodes()
流程如下图所示:
最后,综合前面所得到的标签名、属性、子节点列表,生成父节点:
// 生成元素节点
let node = Node(tagName: tagName, attributes: attributes, children: children)
return node
而子标签中又可包含子标签,解析会不会出现问题?
答案是不会。
因为每次解析标签时,都会进行子标签的解析,而子标签解析是递归调用的标签解析过程。无论嵌套多少层,都会解析出来。
文本解析
文本解析较为简单,只需将标签中间的字符提取出来即可。比如,<p>hello</p>,提取出 hello。
上面我们提到,在 > 的判断之后,会开始新一轮子节点的解析。
拿 <p>hello</p> 来说,也就是会从字符 h 开始扫描。最后,会调用到单个节点解析的方法。
mutating func parseNode() -> Node {
switch sourceHelper.nextCharacter() {
// 解析标签
case "<":
return parseElement()
default:
// 默认解析文本
return parseText()
}
}
毫无疑问,最终会进入到解析文本方法中。
那么,对于 hello</p> 来说,就只需从字符 h 开始,一直向后遍历字符,直到遇到闭合标签 < 结束。这样就提取出了 hello。
// 解析文本
mutating func parseText() -> Node {
// 获取文本内容,文本在标签中间,<p>hhh</p>
let text = self.sourceHelper.consumeWhile(test: { (char) -> Bool in
char != "<"
})
return Node(data: text)
}
因为从 h 开始,是新一轮节点解析。所以,文本节点 hello 是作为 p 标签的子节点存在的。
输出 dom
在完成节点解析后,返回数据是个数组,但我们只需要根节点就好。
如果只有一个元素,那么直接返回它;如果有多个元素,则用 html 包裹一层,再返回,这里做了一些兼容处理。
mutating public func parse(input: String) -> Node {
// 设置输入源
sourceHelper.updateInput(input: input)
// 解析节点
let nodes = self.parseNodes()
// 如果只有一个元素,则直接返回
if nodes.count == 1 {
return nodes[0]
}
// 用 html 标签包裹一层,再返回
return Node(tagName: "html", attributes: [:], children: nodes)
}
完整代码可点击 github 链接查看。
测试输出
let input = """
<html>
<body>
<h1>Title</h1>
<div id="main" class="test">
<p>Hello <em>world</em>!</p>
</div>
</body>
</html>
"""
var htmlParser = HTMLParser()
let dom = htmlParser.parse(input: input)
print(dom)
现在,我们就可以用这个 html 解析器来测试下,看看输出结果。
总结
这篇文章完成了一个极简功能的 html 解析器,主要讲述了 html 中标签、子标签、属性、文本节点的解析,并输出 dom 结构。
下一篇文章,将讲解 css 的解析,敬请期待~
参考资料
- limpet.net/mbrubeck/20…
- www.screaming.org/blog/2014/0…
- github.com/silan-liu/t…
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!