相信很多开发者都了解 Redis,至少听说过它。
Redis 是为集群应用提供分布式缓存机制而闻名。然而,这只是它其中的一个亮点。
Redis 是一个功能强大、通用的内存数据库。强大是因为它非常快;通用是因为它可以处理缓存、类似数据库的特性、会话管理、实时分析、事件流等...
但是,当使用 Redis 作为常规数据库时,必须注意内存中的部分。
在本文中,我们将探索 Redis 缓存模式的一些最有趣的细微差别,使用 Node.js 作为环境来运行一些基准测试。让我们开始吧!
缓存的类型
你可能听说过。随着建立在关系数据库之上的系统快速增长,为了获得更好的性能,通常需要在查询方面减少一些压力。
缓存,作为一种物理实现,在系统应用中随处可见:从数据库层本身到应用服务层,甚至作为远程分布式独立服务(就像 Redis )。
在继续探索之前,我们先来看下这些类型。
Type 1:数据库的集成式缓存
根据你所遵循的系统设计,数据库集成可以帮助你的系统提高一些处理性能。
例如,如果你在读取数据时使用 CQRS 将负载驱动到 NoSQL 数据库,而在写入数据时将负载驱动到关系数据库,那么这可能是一种类似数据库的集成形式,以实现缓存。
然而,这是容易出错的,并且需要大量的人力来运行它,更不用说维护它了。
其他的数据库,如 Aurora 提供了在数据库级别启用缓存的内置机制。换句话说,应用层和客户端不需要知道缓存的存在,因为数据库体系结构本身负责所有事情:通过内部复制逻辑到达时进行更新。
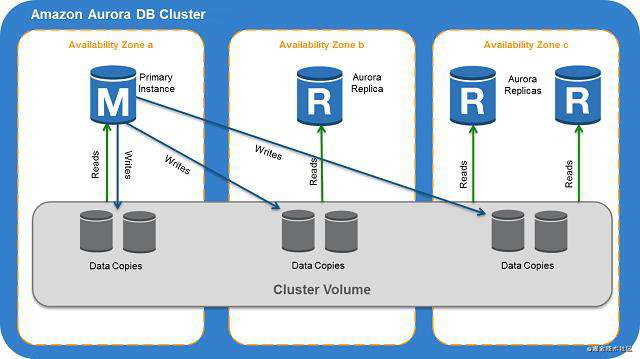
显然,在内存和跨集群实例的数据同步方面存在一些限制。但是,给定正确的用例场景,这将是一个可以考虑使用的强大集成。
Type 2:本地应用缓存
编程式缓存是最常用的类型之一,因为它们只是存储数据的内存结构。
每一种编程语言都有其内置的或社区驱动的库,可以很快轻松地提供本地缓存。
它的特点就是超级快。数据在内存中,因此你可以快速地访问到数据,比通过像是 TCP 请求来获取数据快得多。
另外,如果你工作在一个分布式微服务的环境世界中,那么集群中的每个节点都拥有自己的版本化数据集,这些数据不会在其他节点之间共享,更不可能在某个节点突然关闭时丢失的所有数据了。
Type 3:远程缓存(Redis)
通常,这种类型的缓存也称为端缓存,这意味着它作为服务存在于其他地方,而不是你的应用或数据库。
因为它们是远程工作的,所以它们必须在极端环境下表现良好。这就是为什么它们通常可以在几毫秒内处理大量数据加载的原因。
选择这种类型的缓存是需要讨论和考虑的。例如,你有关于你的(或你的提供商的)网络延迟的详细信息吗?你能水平扩展你的 Redis 集群吗?
由于应用程序与外部之间存在通信,所以当处理数据失败或变得太慢时,必须有一个计划。开发人员通常通过混合使用本地和远程缓存策略来解决这个问题,这将为他们在边缘情况下提供第二个保护屏障。
缓存的模式
同样,根据你的系统需求,实现缓存的方式可以根据实际情况而变化。
让我们花点时间来分析一下最常见的缓存模式。
Cache-aside 模式
这是最常用的缓存模式。顾名思义,它存在于的系统体系中的不同地方(应用程序除外)。
应用程序负责 缓存 和 数据库 之间的编排,这样会是最好的。请看下图:
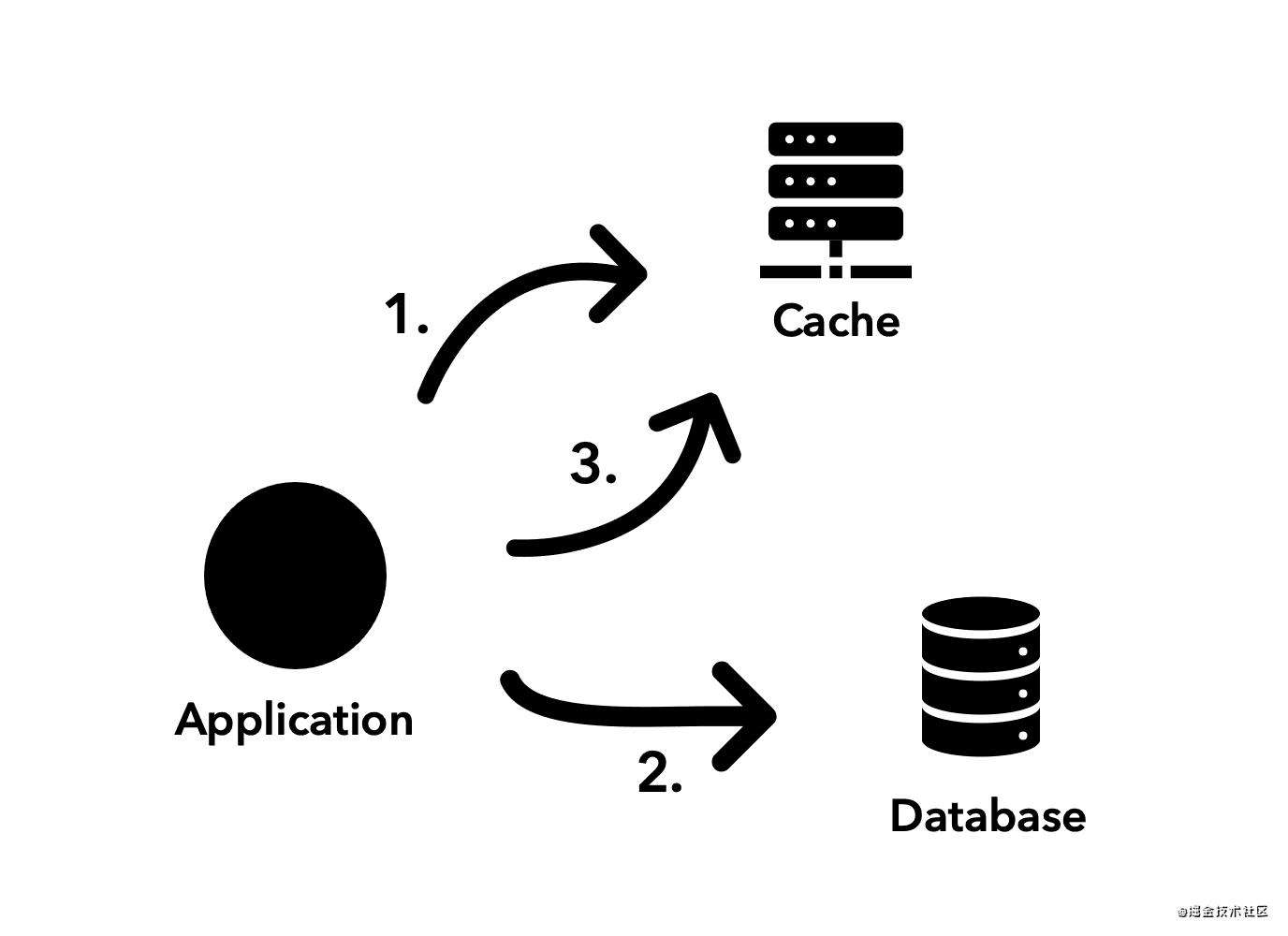
Cache-aside 执行流:
- 第一步是检查缓存,看看是否有所需的数据。如果成功,应用程序将信息返回给客户端,而不调用数据库。
- 如果没有,应用程序将转到数据库获取最新的信息。
- 最后,一旦有了最新版本的数据,应用程序就决定对缓存进行写入,使其也能感知。
这种策略有很多好处,比如可以灵活地处理缓存和数据库中完全不同的数据类型。需要对数据库进行仔细的考虑设计,因为对数据库的更改可能会变得非常痛苦。然而,缓存给了你更多的自由来使用更灵活的数据结构。
请注意,在向数据库写入数据和缓存更新失败的情况下,上面图像中演示的策略可能会带来麻烦。对于这种情况,有备选方案很重要,比如 TTL(生存时间)设置,开发者为使缓存中的特定数据失效建立一个超时。这样,当缓存数据更新失败时,应用程序不会太长时间处理超时的数据。
Write-Through 模式
此模式采用与 Cache-saside 模式相反的方法。在这里,当检测到任何更改时,应用程序首先写入缓存,然后再转到数据库。
这就是它的名字的来源,因为在进行最终的数据库写入之前,它都要经过缓存层。
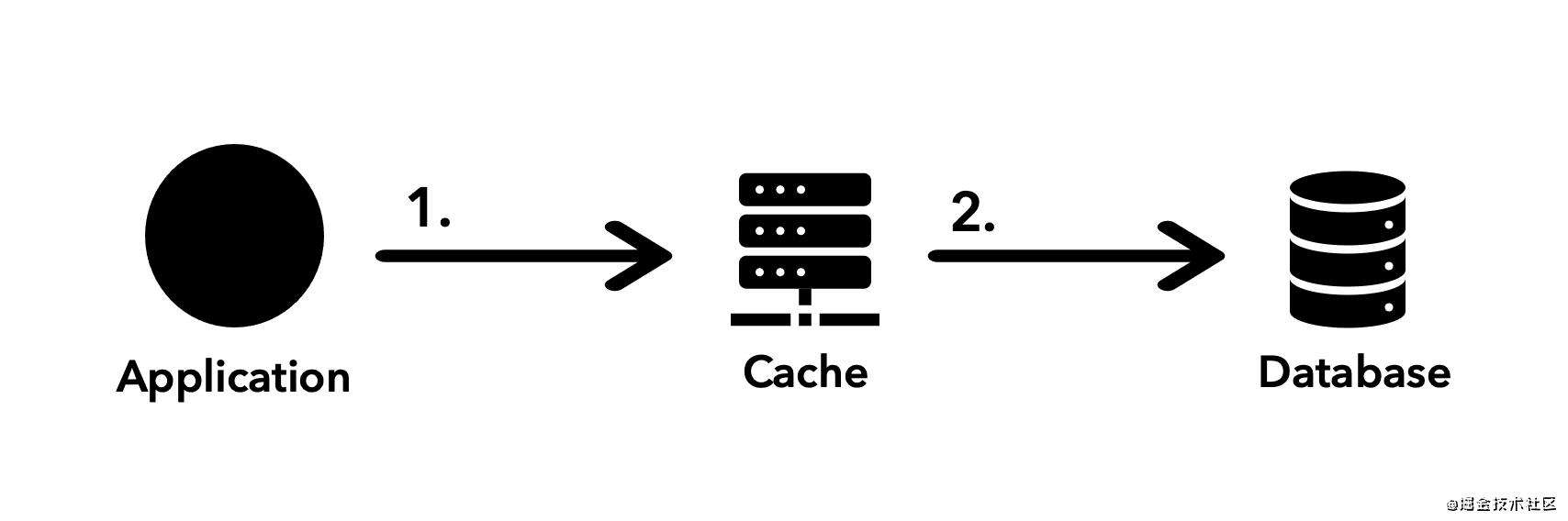
Write-Through 执行流:
在对这种策略建模时,必须非常小心,特别是在数据库写入失败的情况下。
对于这种情况,你可以建立一个重试策略来尝试不惜一切代价将数据保存到数据库,或者抛出一个事务错误,回滚之前的缓存写入。
这里,只需注意每个流的总体处理时间的相应增加。
Redis For Node.js
我们将在 Node.js 应用程序上运行一个基准测试,该应用程序将公开两个 API 端点:一个处理缓存的数据,另一个没有缓存。
我们的目标是演示如何快速配置你的项目来使用 cache-aside 模式,同时对这两个 API 端点进行基准测试,看看 Redis 能为 REST API 的性能提升有多大。
环境准备
你可以按照官方的快速入门配置 redis 环境:
wget http://download.redis.io/redis-stable.tar.gz
tar xvzf redis-stable.tar.gz
cd redis-stable
make
make install
然后,执行 redis-server 命令启动 redis 服务:
接下来,我们创建一个项目文件夹,cd 进入到它。
初始化并安装依赖:
npm init
npm install express redis axios
最后,根目录创建 index.js 文件,添加如下代码:
const axios = require("axios");
const express = require("express");
const redis = require("redis");
const app = express();
const redisClient = redis.createClient(6379); // Redis server started at port 6379
const MOCK_API = "https://jsonplaceholder.typicode.com/users/";
app.get("/users", (req, res) => {
const email = req.query.email;
try {
axios.get(`${MOCK_API}?email=${email}`).then(function (response) {
const users = response.data;
console.log("User successfully retrieved from the API");
res.status(200).send(users);
});
} catch (err) {
res.status(500).send({ error: err.message });
}
});
app.get("/cached-users", (req, res) => {
const email = req.query.email;
try {
redisClient.get(email, (err, data) => {
if (err) {
console.error(err);
throw err;
}
if (data) {
console.log("User successfully retrieved from Redis");
res.status(200).send(JSON.parse(data));
} else {
axios.get(`${MOCK_API}?email=${email}`).then(function (response) {
const users = response.data;
redisClient.setex(email, 600, JSON.stringify(users));
console.log("User successfully retrieved from the API");
res.status(200).send(users);
});
}
});
} catch (err) {
res.status(500).send({ error: err.message });
}
});
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server started at port: ${PORT}`);
});
该代码使用了一个外部 mock API JSONPlaceholder,这对于 API fake 非常有用。在本例中,我们将搜索一些虚拟用户数据。
注意,端口 6379 是 Redis 的默认值,你可以在上图 redis 服务启动日志中可以看到。
有两个 API。第一种基本上从用户的 API 中获取数据,中间没有缓存。通过这种方式,你可以看到后续的 HTTP 调用会给应用程序的总体性能增加多少重载。
第二个 API 总是在 Redis 中检查给定的数据。如果数据的 key 是存在的,我们跳过 mock API 调用,直接从缓存中获取数据,否则,我们会继续获取信息并将结果存储到 Redis 中。
很简单,对吧?让我们继续看看基准测试代码。首先,让我们添加一个 Node 库来帮助我们解决这个问题。我们将使用 api-benchmark 工具,因为它功能强大,能够为基准生成可视化报告。
执行以下代码,安装 api-benchmark:
npm install api-benchmark
然后,在根目录创建另一个文件 benchmark.js , 并添加如下代码:
var apiBenchmark = require("api-benchmark");
const fs = require("fs");
var services = {
server1: "http://localhost:3000/",
};
var options = {
minSamples: 100,
};
var routeWithoutCache = { route1: "users?email=Nathan@yesenia.net" };
var routeWithCache = { route1: "cached-users?email=Nathan@yesenia.net" };
apiBenchmark.measure(
services,
routeWithoutCache,
options,
function (err, results) {
apiBenchmark.getHtml(results, function (error, html) {
fs.writeFile("no-cache-results.html", html, function (err) {
if (err) return console.log(err);
});
});
}
);
apiBenchmark.measure(
services,
routeWithCache,
options,
function (err, results) {
apiBenchmark.getHtml(results, function (error, html) {
fs.writeFile("cache-results.html", html, function (err) {
if (err) return console.log(err);
});
});
}
);
我们将分别执行两个命令:一个没有缓存;另一个使用 redis 缓存。
这里对每个 API 服务进行 100 个请求的负载,这对于为生产准备的压测不是理想的,但已经足够证明 Redis 的能力了。稍后你可以使用更多请求重新运行测试,以查看差距是如何增大的。
执行 node index.js 命令,接着另起终端,执行 node benchmark.js。
如果一切顺利,你可能会在项目的根目录下看到两个新的 HTML 文件。在 web 浏览器中打开它们,可能会显示类似如下所示的结果:
- Redis 缓存 API 的基准测试结果:
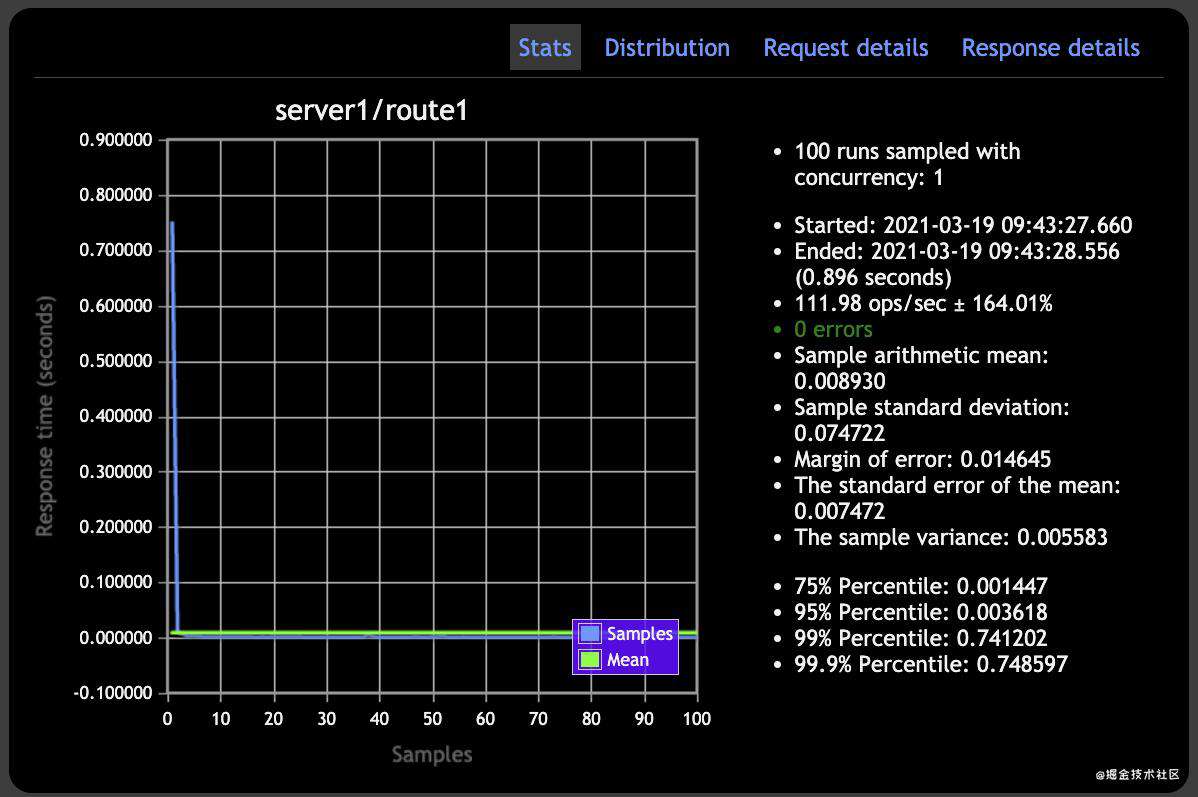
- 无缓存的 API 基准此时结果:
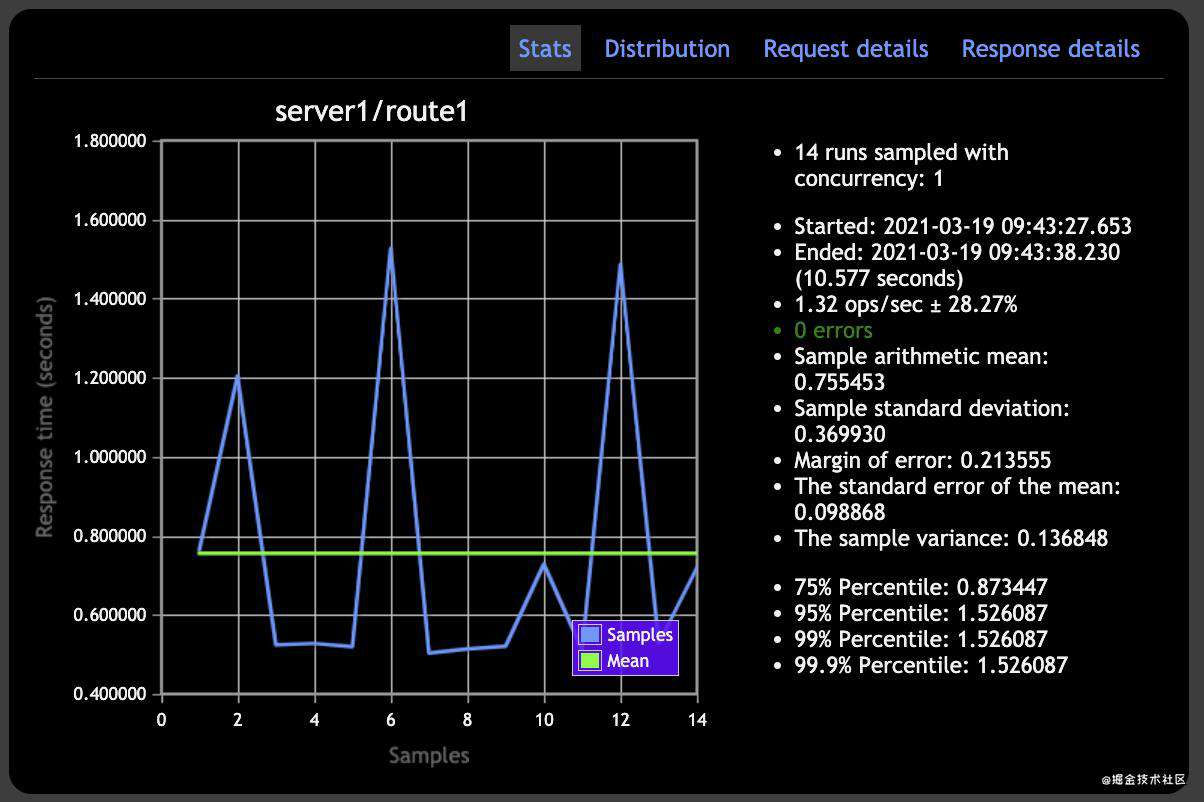
看下右侧面板中生成的统计数据。非缓存 API 在大约 11 秒内结束了测试,而redis 缓存 API 在大约 0.9 秒内就结束了测试。
如果你在开发每秒接收大量请求的应用程序,那么这是一个非常不错的选择?。
总结
现实中还会有其他的缓存模式,但是,为了简单起见,我们只关注最流行和最强大的缓存模式。
现代应用注重考虑性能。随着时间的推移,这个要求变得越来越严格,因为对应用程序请求的复杂性和数量呈指数级增长。
Redis 只是众多缓存选项中的一个。事实上,它强大、灵活,深受许多公司和技术社区的喜爱。
我建议你实现一下第二个缓存模式,即 write-through,对比与 cache-aside 在性能方面的区别。
你可以在 GitHub 上看到本文中的示例代码。
参考
- Powerful Caching with Redis for Node.js Applications
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!