学习和梳理 G2 的源码,了解怎么开发和使用一个可视化图表库。
G
先感受一下 G 的 API:
G 核心的逻辑就是:
- 通过 Group、Shape 来组织整个选人的树形数据结构
- 通过 addShape 的 API 来填充这个数据结构
- 最后使用递归,去转换为 canvas ctx API
G2
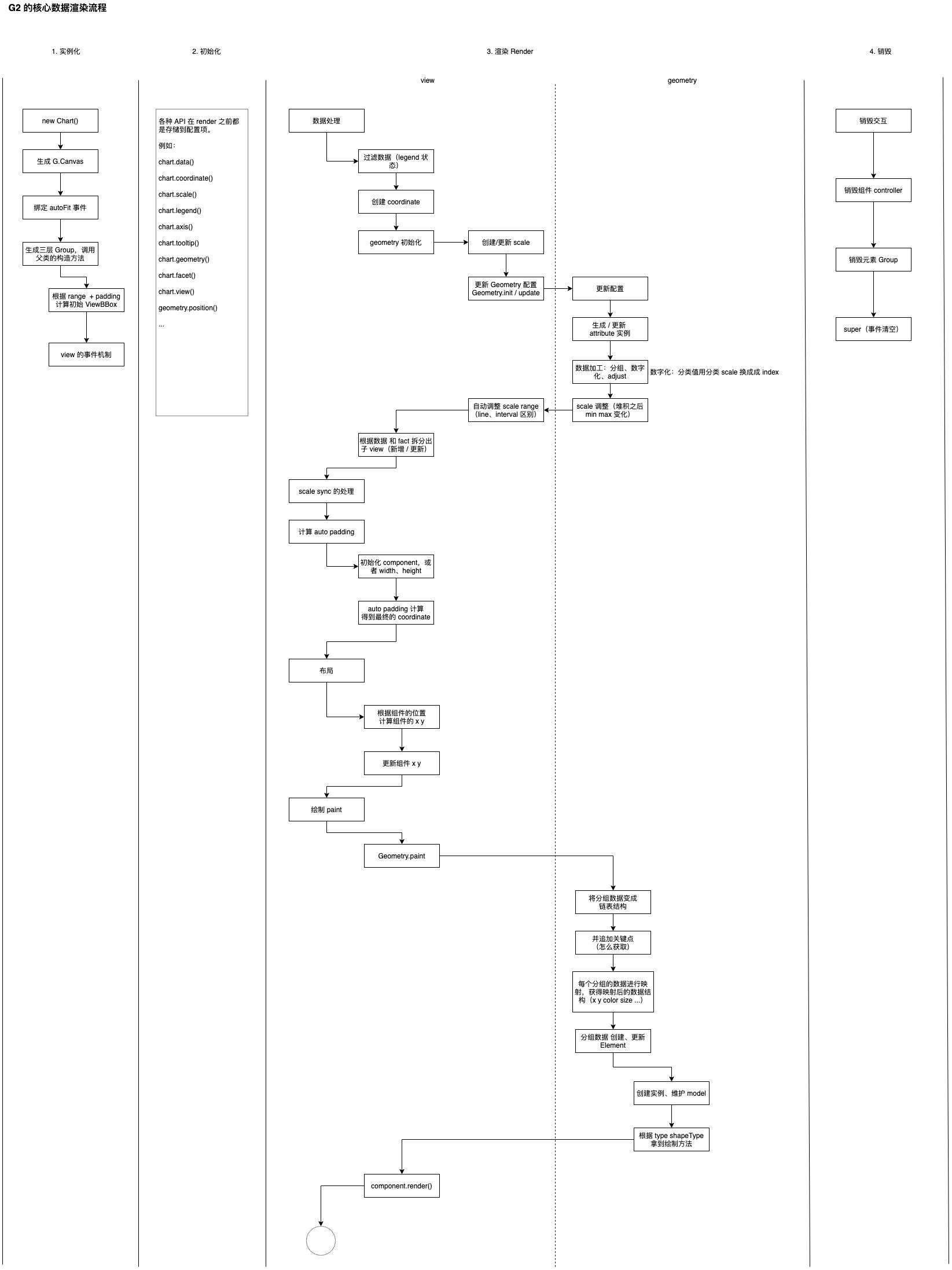 费了我半天时间整理的流程图
费了我半天时间整理的流程图
上图的渲染流程,其实是指他的核心类 View(视图)的数据处理、映射、渲染的流程。
G2 整体是使用 view 去组织渲染结构的,最终暴露的 Chart 类继承自 View,view 可以包含有几个子信息:
- 包含的子 view
- 包含的图形 geometry(折、柱、点等等)
- 包含的组件 component(图例、坐标轴、缩略轴等)
所以不难得知,本质是使用 view 作为容器组织的树形结构,其渲染也是直接是一个大的递归逻辑。分成几个阶段:
- 实例化
- 初始化
- 渲染
- 销毁
分别介绍。每一项都可以参照上面的图形一起看。
实例化
Chart 是 G2 暴露的最重要的入口 API,用来创建一个图表实例。他继承自 View 容器,所以他特有的逻辑就很简单了:
- 创建 G.Canvas 画布
- 绑定事件,处理 autoFit 参数(图表自动适配 DOM 容器的大小)
- 生成三层 G.Group 然后走 View 的构造函数逻辑
初始化
上述 G2 的这类 API 的功能都是类似的:设置配置项并存储起来。这些配置项包含:
- 数据
- 坐标系
- scale 数据列定义
- 组件配置
- 图形配置
- 图形映射配置
- 分面
- ...
渲染
在设置了各项配置之后,最后在 render 的时候,会消费这些配置,然后去生成衍生数据、数据映射、绘制图形组件、G 渲染。
前面已经提到,View 包含有子 View,然后无限嵌套的树形结构,所以渲染逻辑是一个递归的渲染过程,这其中的逻辑主要分成为几个阶段:
1. 数据处理阶段
数据处理,主要是将初始化过程中的配置项,进行处理,产生一些衍生数据,用于做渲染。主要包含:
- **经过过滤后的数据(**比如 legend 的过滤)
 这里逻辑很简单,就是存储一个内部状态,然后直接数组的 filter 即可,过滤之后的数据才是最终的渲染数据。
这里逻辑很简单,就是存储一个内部状态,然后直接数组的 filter 即可,过滤之后的数据才是最终的渲染数据。
- 创建 coordinate 实例
coordinate 坐标系是一个相对坐标映射到画布绝对坐标的函数。
不同的坐标系会将一个相对坐标映射到不同的像素点上,从而实现图形的变化。比如主题和饼图其实就是一个图形经过坐标系变化而来的。
| Rect | Polar |
|---|---|
 |  |
当然,坐标系还能做一些变化能力,比如 translate,rotate,scale 等我们 CSS 中常见的 transform。
- Geometry 的初始化
Geometry 是 G2 很重要的代码,承载技术所有的数据处理过程,将图形语法的理论写到其中。而在这个阶段,主要做的事情是初始化。初始化主要包含:
-
根据字段配置,生成 scale 信息
-
数据加工
- 分组:根据分组字段(color、shape、size)将数据分组,每个分组的数据组成一簇。
- 数字化:使用 scale 将数据数字化,好处在于便于后续经过 coordinate,然后获取数据的实际画布坐标。数字化逻辑很简单,就是对于分类的信息使用其 index 作为数据。
- 调整:主要是对于堆积图,需要调整数据。
- scale 调整:对于堆积图,调整 scale 的 min max;对于线图、柱图修改 range 范围。
-
fact 分面处理
这是高级功能,逻辑也不难。根据 fact 配置 + 数据,生成子 view,以及他们的位置。
2. 计算 auto padding
padding 可能是 G2 特有的一个概念了,他的含义是:图形区域上右下左的间距,这个间距是保留给图形组件使用的。
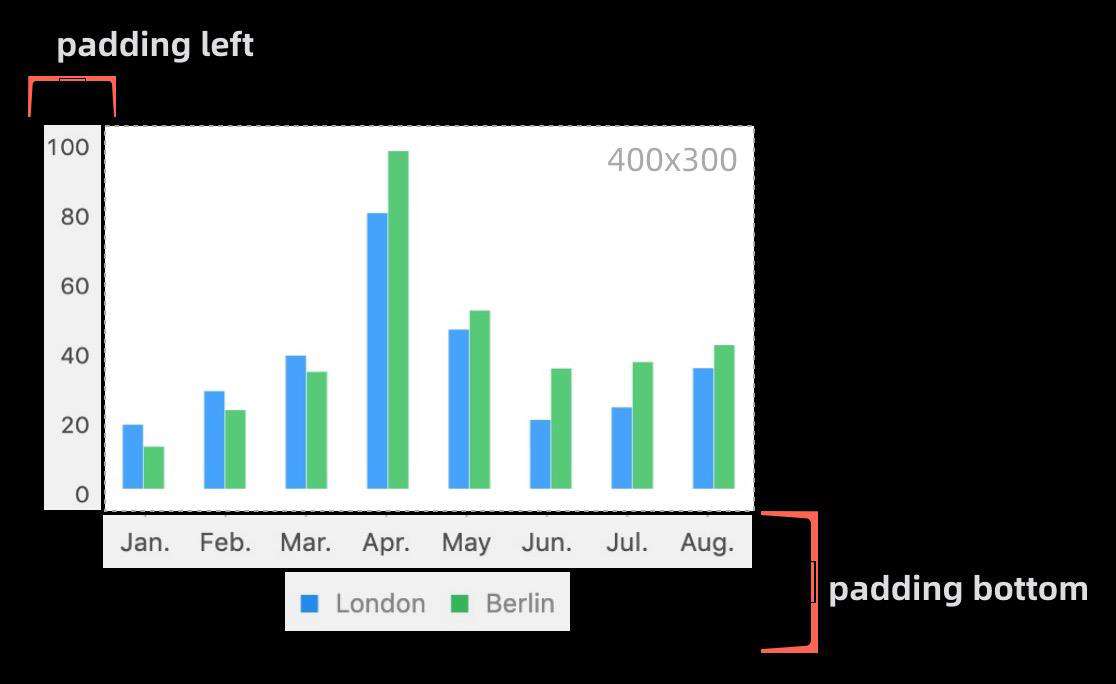 在 G2 中,padding 是可以设置一个固定值,或者 auto 的,而对于 auto,就存在一个过程需要计算这个 padding 具体值。所以 auto padding 的逻辑就是将 auto 转换成 类似 css 的 padding 确定的数据。
在 G2 中,padding 是可以设置一个固定值,或者 auto 的,而对于 auto,就存在一个过程需要计算这个 padding 具体值。所以 auto padding 的逻辑就是将 auto 转换成 类似 css 的 padding 确定的数据。
而这个逻辑也不难,就是根据 axis、legend、slider 等组件的方位,以及他们的 width height,最终计算出实际的 padding 值。
这个 padding 有了之后,就可以更新坐标系的宽高了,这很重要。(也就是画布的宽高 - padding)
3. 布局
布局是在有了 padding 值,有了 coordinate 的具体宽高之后,然后根据组件(axis、legend、slider)的 position(上右下左),来计算组件具体的 x y。
这么一来,组件的 x y width height 都确定了,然后绘制就没有什么问题了。
4. 渲染绘制
布局完成之后,最后的一步就是渲染了。主要分成为图形的渲染、组件的渲染。
- Geometry 渲染
** 前面初始化过程中,做了一部分的数据处理,将数据进行分组、数字化。那么到了渲染这一步的时候,主要的逻辑就是 shapeFactory 的逻辑了。
不同的图形有不同的 shapeFactory,每个 shapeFactory 都有自己的渲染方法(转化成 G 的 shape)。主要分成为几步:
- 分组数据变成单向链表,这样数据之间就能互相索引了
- 计算关键点,这个是有 shapeFactory 的 getPoints 决定的。比如柱形图的关键点就是:
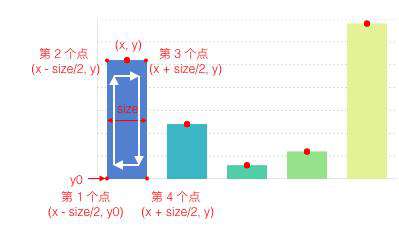
- 将图形属性配置映射后的数据,比如 x y 就映射陈 0 ~ 1 的位置,color 就映射出具体的颜色。等等
- 每个分组数据,创建一个 Element 实例,这个实例会管理自己的数据 model,然后会根据 shape 获取对应的 shapeFactory 去绘制。
** 在这个流程中,我们暴露了 registerShape API 来做图形的自定义。** **
- Component 渲染
组件的渲染就很简单了。
- axis 根据字段对应 scale + 设置的 axisCfg,去生成 G 的结构即可
- legend 根据 legendCfg 去绘制 marker + text
- tooltip 使用 html 绘制
- ...
销毁
不多说了,见最上面的流程图。
最后
一天扫描代码下来,变成一个流程图和文字版本。 内容其实还是挺多的,还是需要对照流程图 + 代码逻辑过一过,才能好好消化。
G2 本身对于自定义能力还是做了不少的,理解这个之后,对我们使用 G2 做业务定制需要还是有很大帮助的。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!