前言
好的程序员懂得如何从重复的工作中逃脱:
- 操作DOM时,发现了Jquery。
- 操作JS时,发现了lodash。
- 操作事件时,发现了Rx。
Rxjs本身的 概念 并不复杂,简单点说就是对观察者模式的封装,观察者模式在前端领域大行其道,不管是使用框架还是原生JS,你一定都体验过。
在我看来,Rxjs的强大和难点主要体现对其近120个操作符的灵活运用。
可惜官网中对这些操作符的介绍晦涩难懂,这就导致了很多人明明理解Rxjs的概念,却苦于不懂的使用操作符而黯然离场。
本文总结自《深入浅出Rxjs》一书,旨在于用最简洁、通俗易懂的方式来说明Rxjs常用操作符的作用。学习的同时,也可以做为平时快速查阅的索引列表。
阅读提醒
- 流的概念
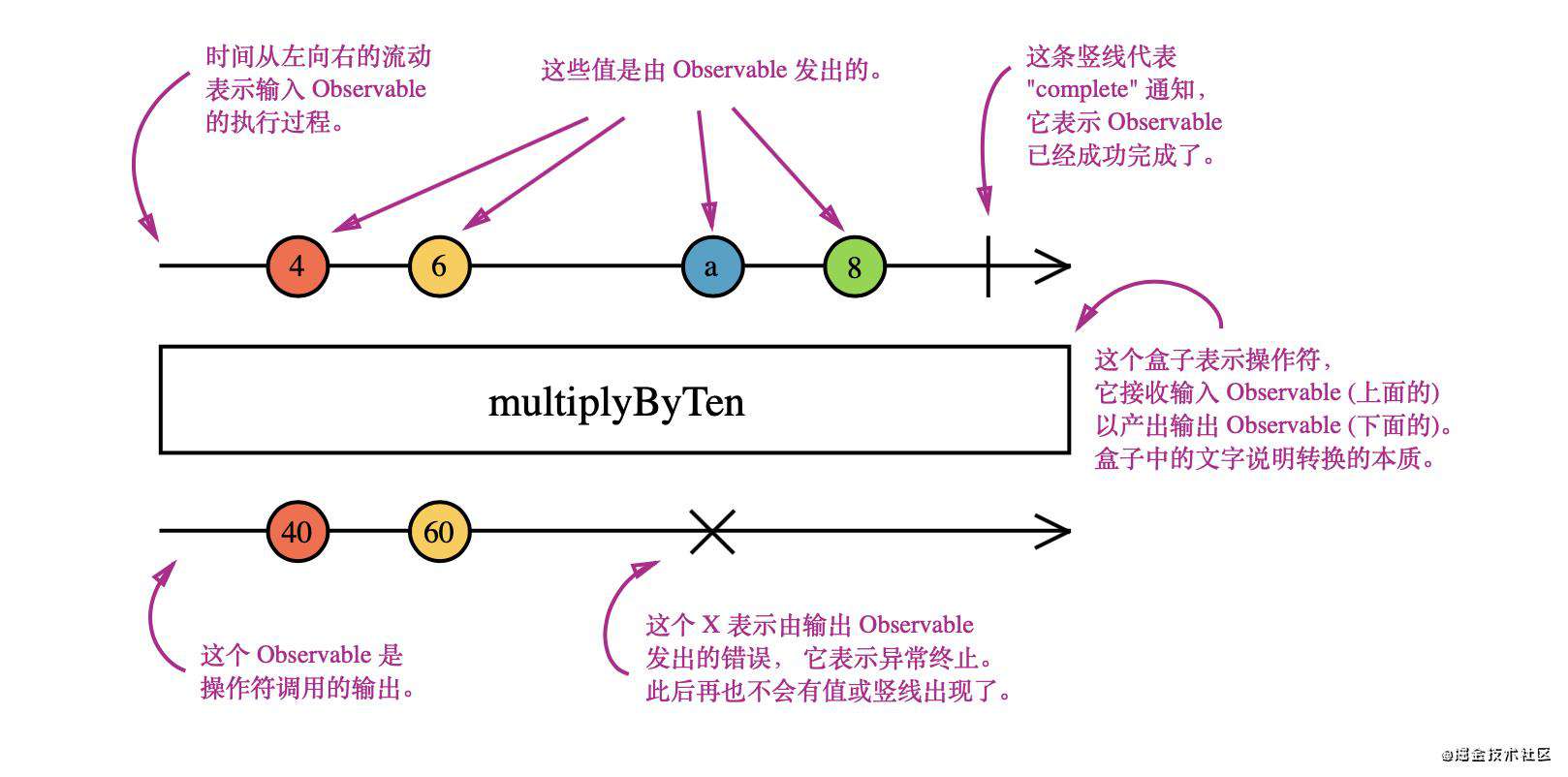
- 订阅:调用
subscribe - 吐出:调用
next - 完成:调用
complete
创建流操作符
创建流操作符最为流的起点,不存在复杂难懂的地方,这里只做简单的归类,具体使用查阅官网即可,不再赘述。
同步流
- create:new Observable
- of
- range
- repeat
- empty
- never
- throw
- generate
异步流
- interval/timer
- form:string/number/数组/类数组/promise/generator
- formPromise
- formEvent
- formEventPattern
- ajax
- repeatWhen
- defer:订阅时再创建
合并类操作符
订阅多条流,将接收到的数据向下吐出。
concat
首尾连接
-
依次订阅:前一个流完成,再订阅之后的流。
-
当流全部完成时concat流结束。
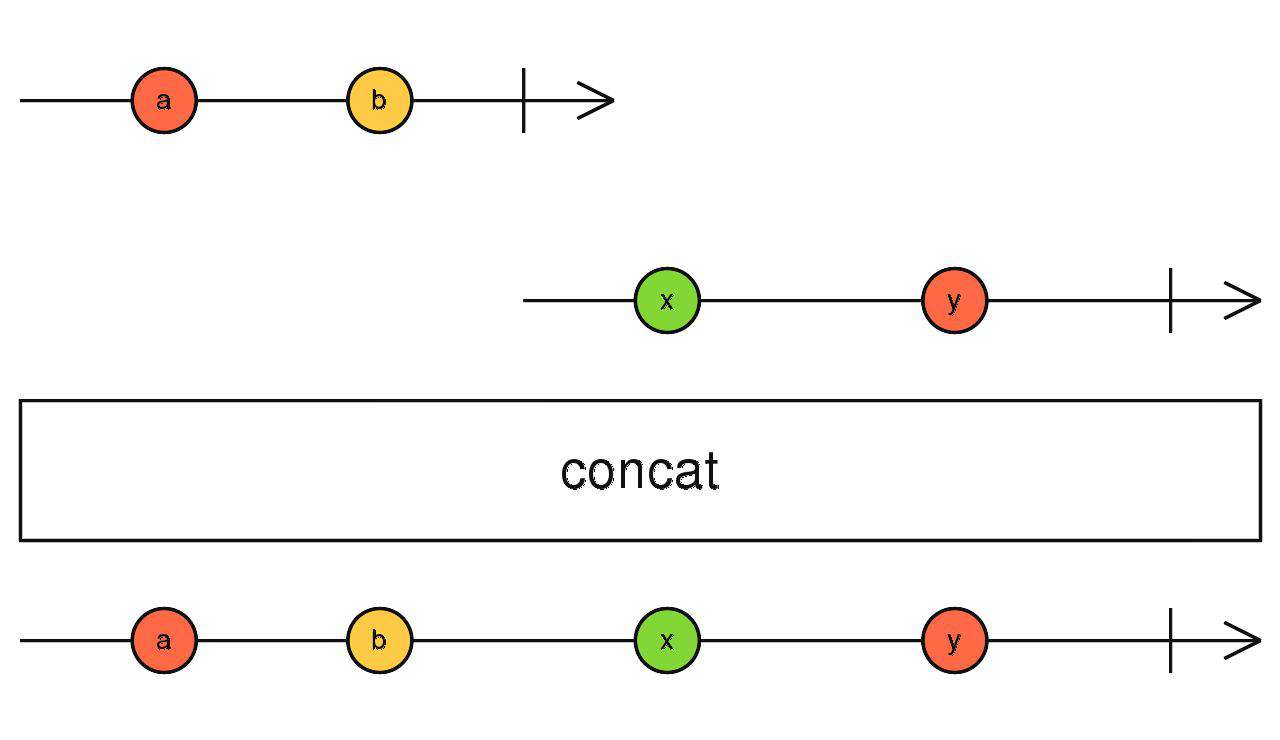
concat(source1$, source2$)
merge
先到先得
-
订阅所有流,任意流吐出数据后,merge流就会吐出数据。
-
对异步数据才有意义。
-
当流全部完成时merge流结束。
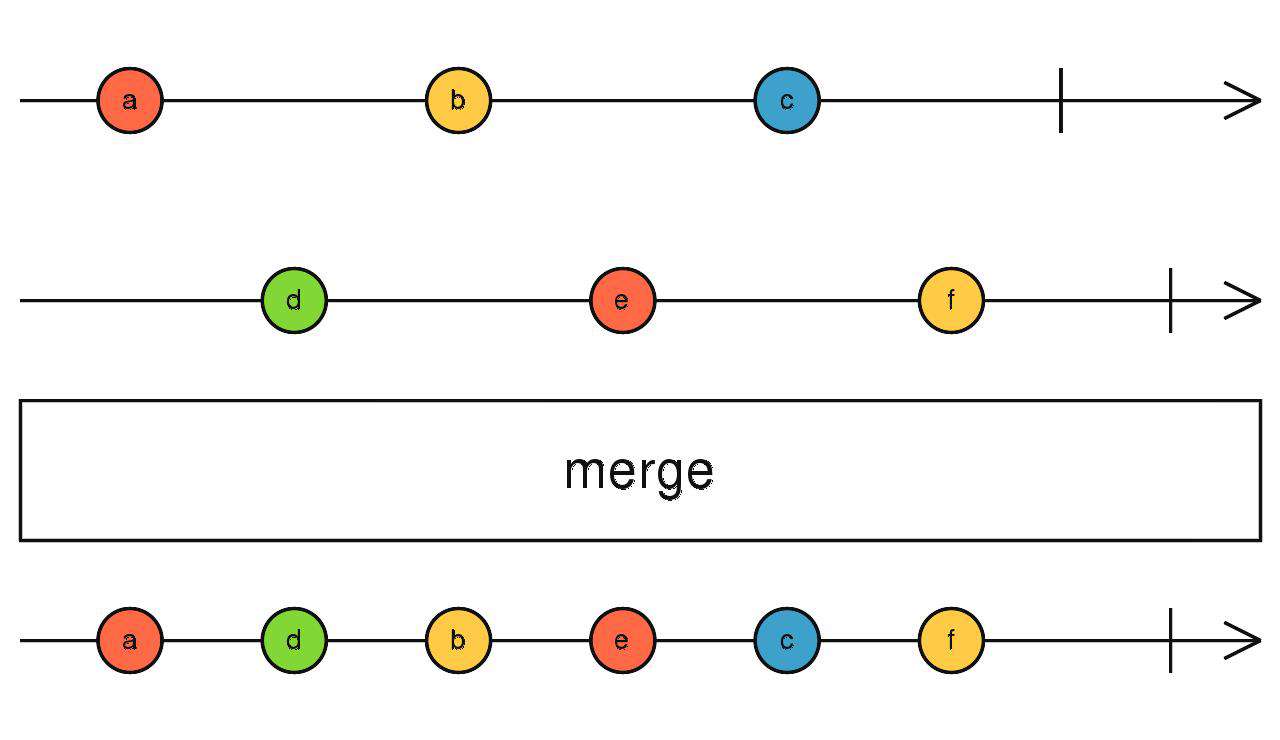
merge(source1$, source2$)
zip
一对一合并(像拉链一样)
-
订阅所有流,等待所有的流都触发了
i次,将第i次的数据合并成数组向下传递。 -
其中一个流完成之后,等待另一个流的同等数量数据到来后完成zip流。
-
当我们使用zip时,期望第一次接受到的数据是所有的流第一次发出的数据,第二次接受的是所有的流第二次发出的数据。
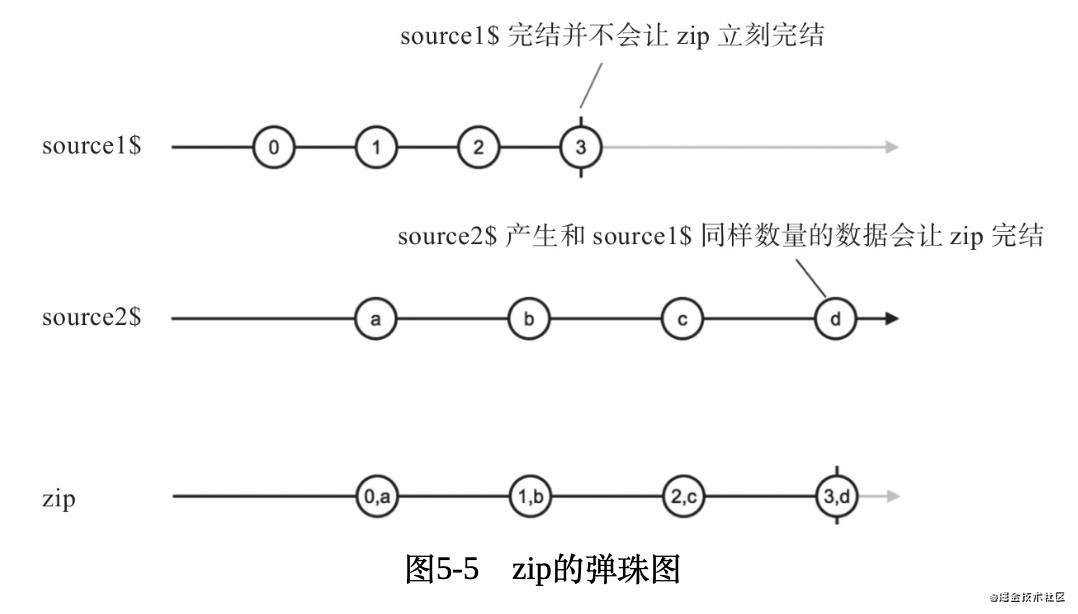
zip(source1$, source2$)
combineLatest
合并所有流的最后一个数据
-
订阅所有流,任意流触发时,获取其他所有流的最后值合并发出。
-
因为要获取其他流的最后值,所以在刚开始时,必须等待所有流都吐出了值才能开始向下传递数据。
-
所有的流都完成后,combineLatest流才会完成。
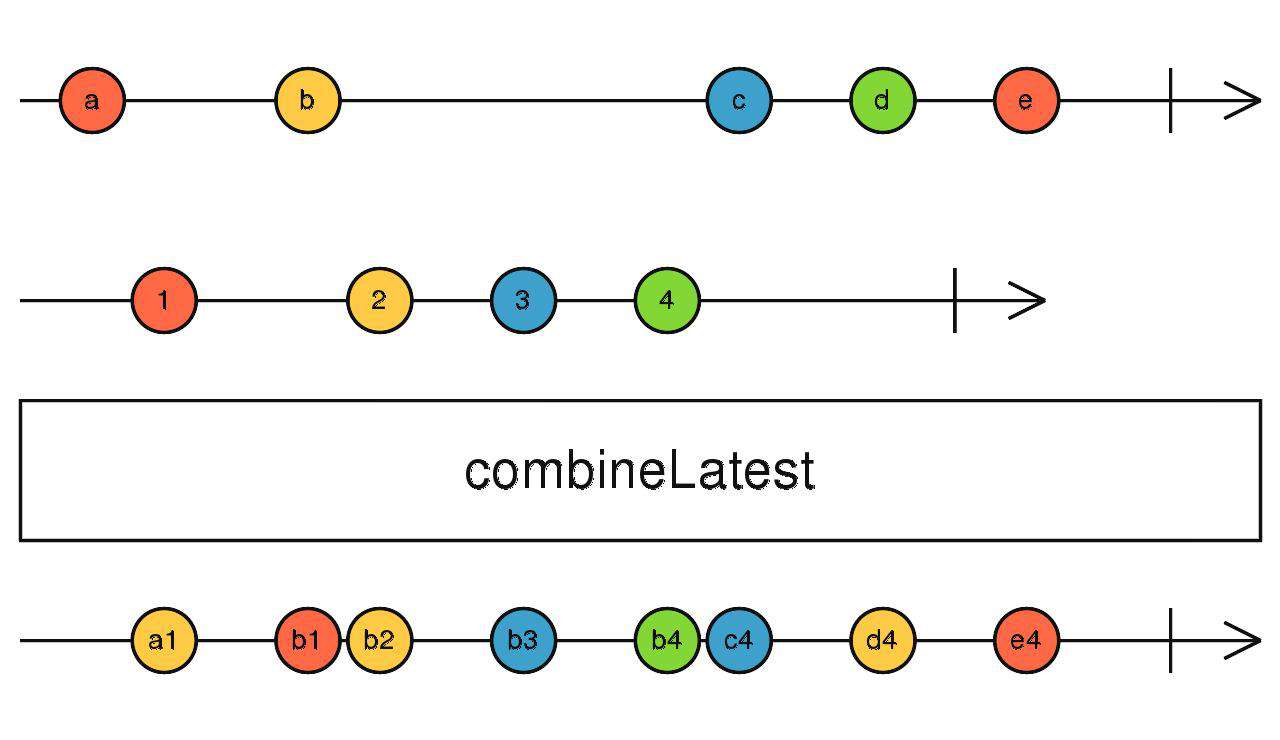
combineLatest(source1$, source2$)
withLatestFrom
合并所有流的最后一个数据,功能同combineLatest,区别在于:
-
combineLatest:当所有流准备完毕后(都有了最后值),任意流触发数据都会导致向下吐出数据。
-
withLatestFrom:当所有流准备完毕后(都有了最后值),只有调用withLatestFrom的流吐出数据才会向下吐出数据,其他流触发时仅记录最后值。
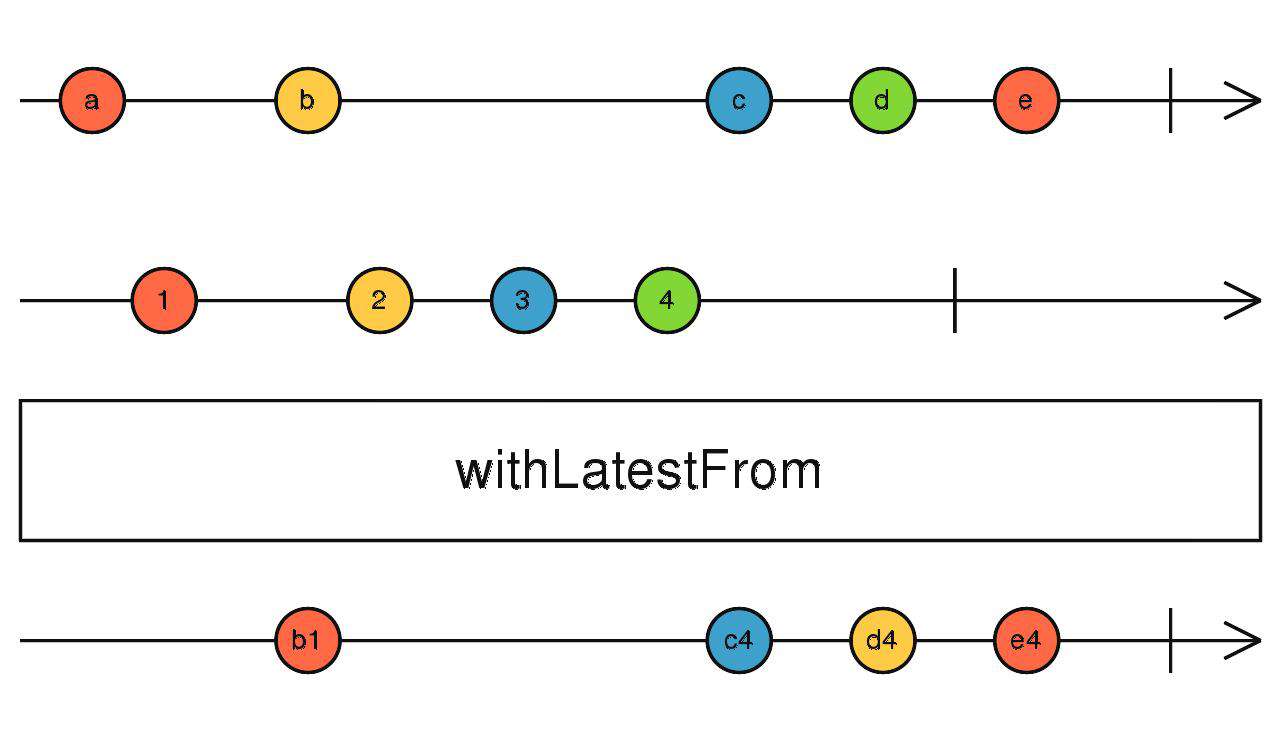
source1$.pipe(withLatesFrom(source2$, source3$))
race
胜者通吃
- 订阅所有的流,当第一个流触发后,退订其他流。
race(source1$, source2$)
startWith
在流的前面填充数据
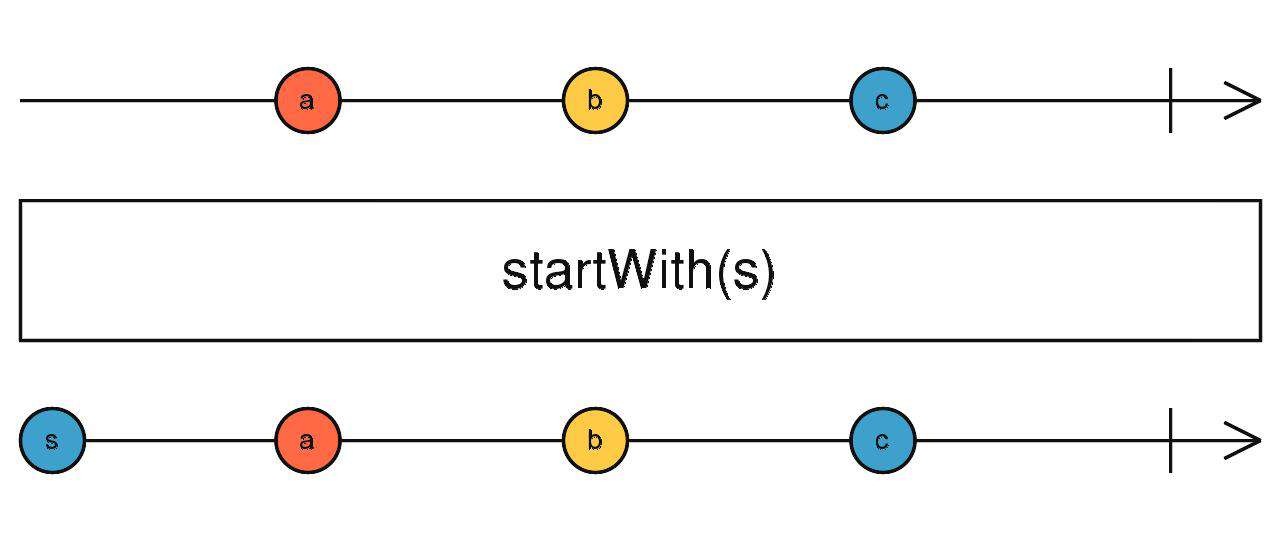
source1$.pipe(startWith(1))
forkJoin
合并所有流的最后一个数据
- 订阅所有流,等待所有流全部完成后,取出所有流的最后值向下发送。
forkJoin(source1$, source2$)
辅助类操作符
count
当前流完成之后,统计流一共发出了多少个数据。
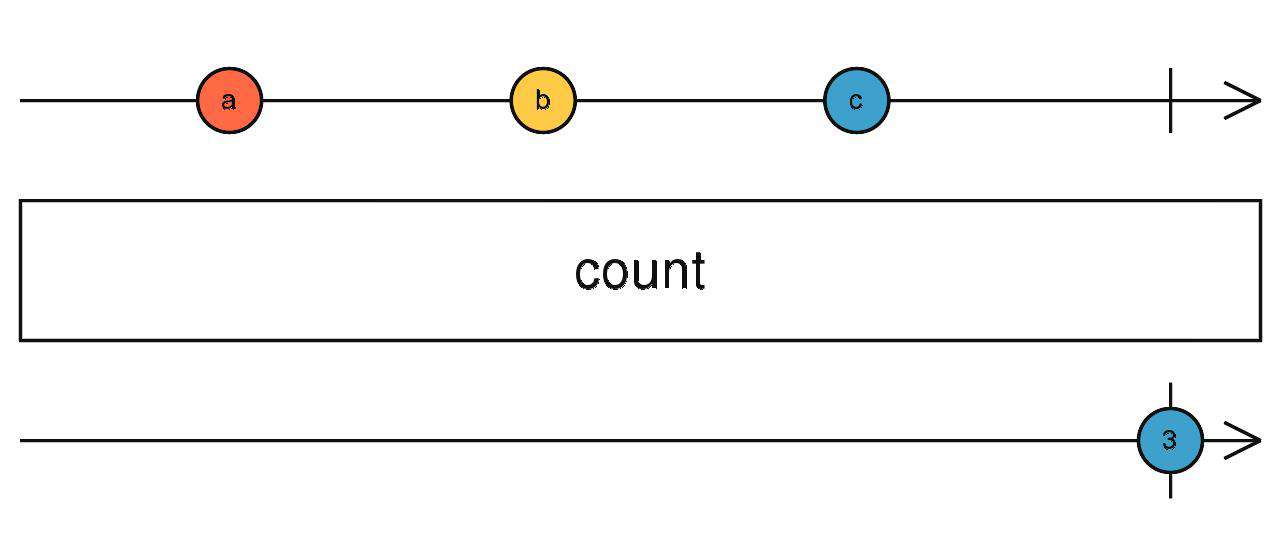
source$.pipe(count())
mix/max
当前流完成之后,计算 最小值/最大值。
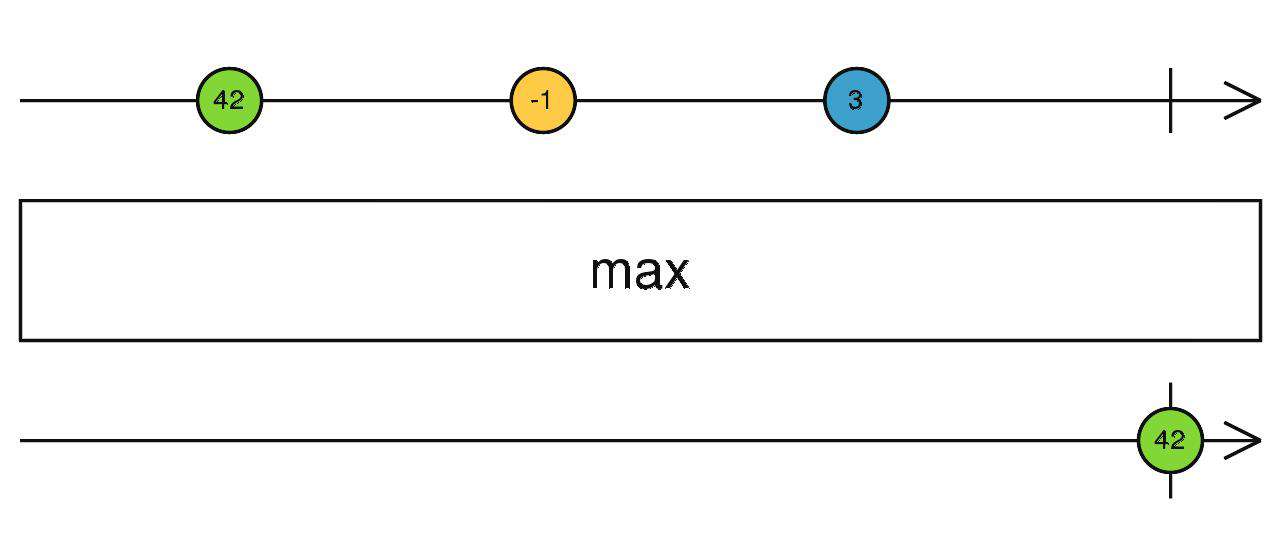
source$.pipe(max())
reduce
同数组用法,当前流完成之后,将接受的所有数据依次传入计算。
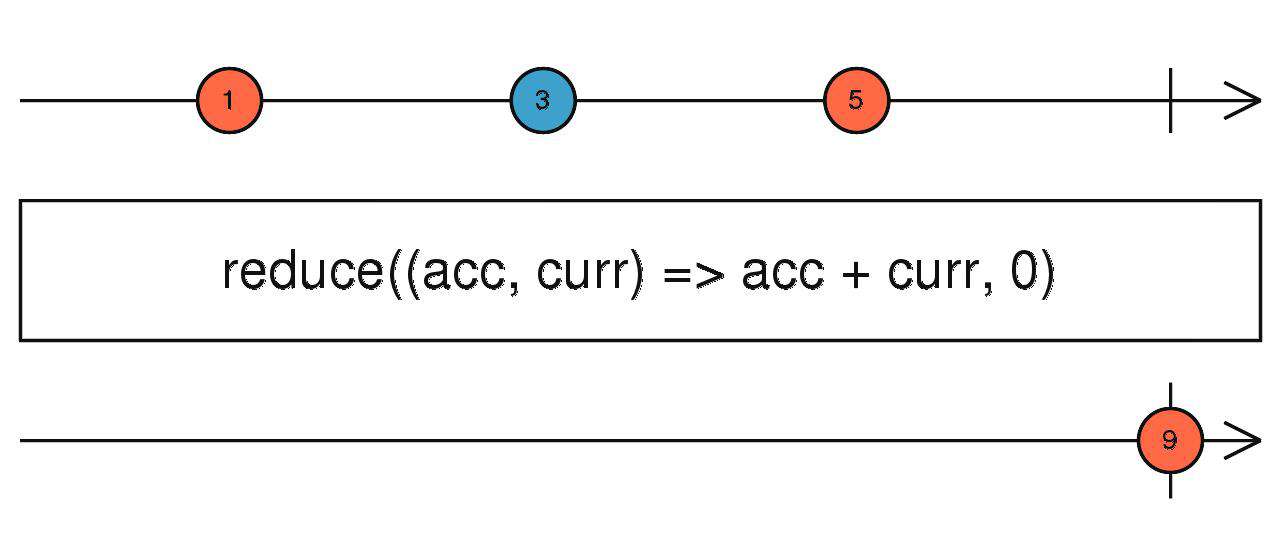
source$.pipe(reduce(() => {}, 0))
布尔类操作符
every
同数组,需要注意的是:如果条件都为true,也要等到流完成才会吐出结果。
原因也很简单,如果流没有完成,那怎么保证后面的数据条件也为true呢。
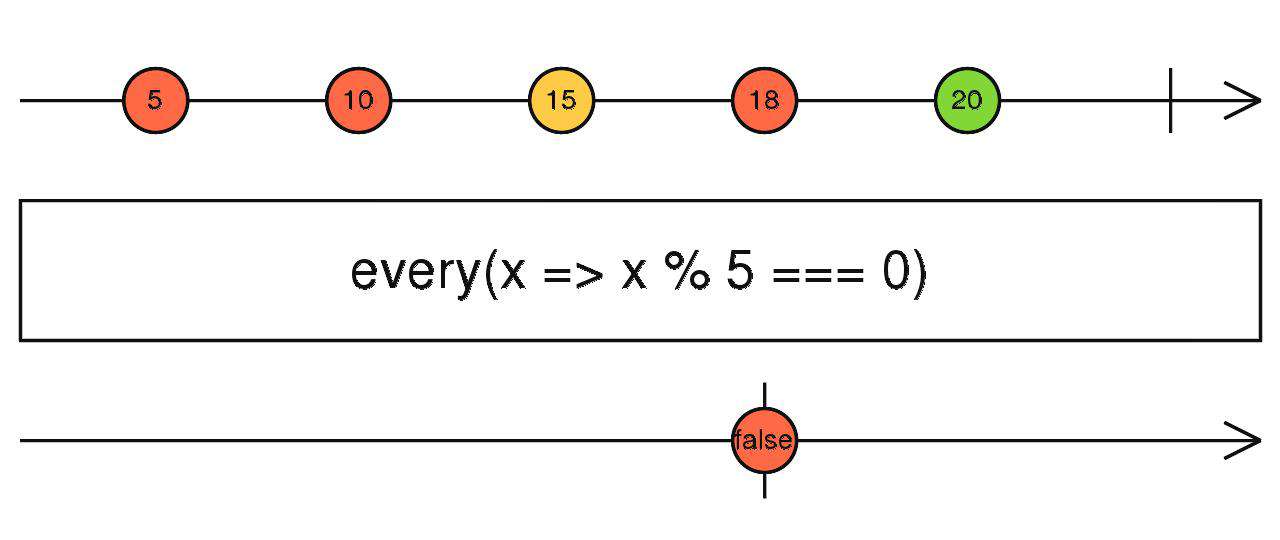
source$.pipe(every(() => true/false))
find、findIndex
同数组,注意点同every
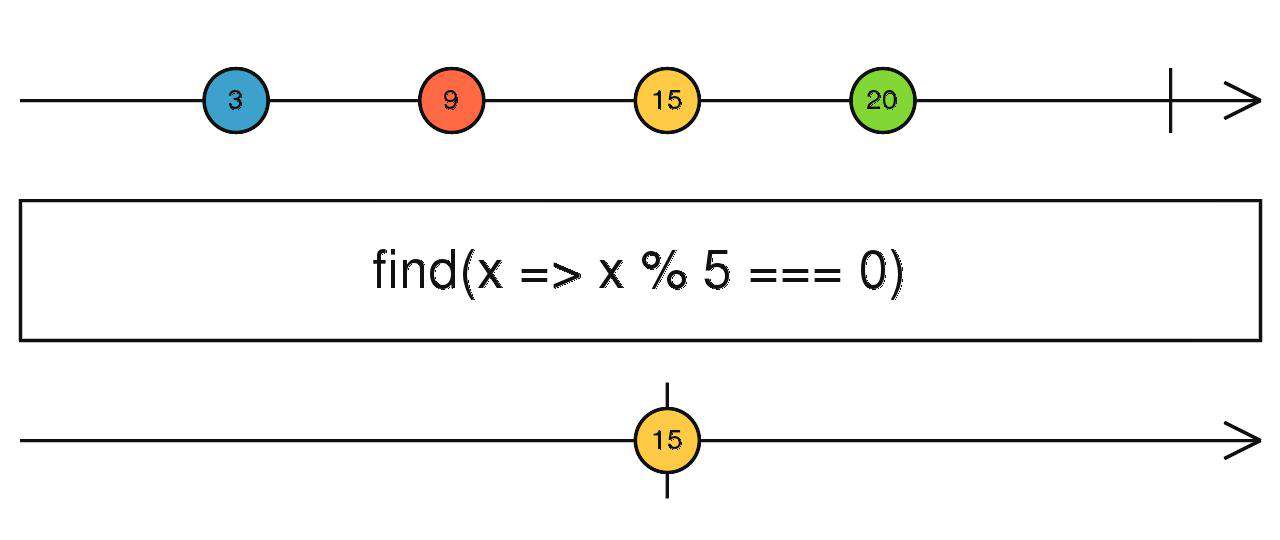
source$.pipe(find(() => true/false))
isEmpty
判断流是不是一个数据都没有吐出就完成了。

source$.pipe(isEmpty())
defaultIfEmpty
如果流满足isEmpty,吐出默认值。

source$.pipe(defaultIfEmpty(1))
过滤类操作符
filter
同数组
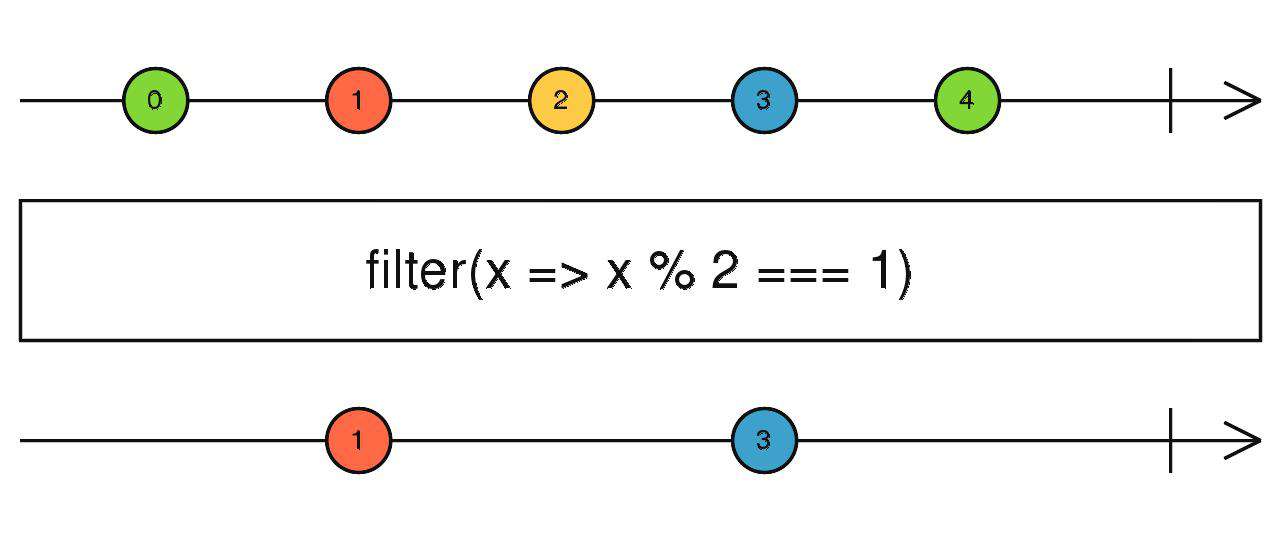
source$.pipe(filter(() => true/false))
first
取第一个满足条件的数据,如果不传入条件,就取第一个
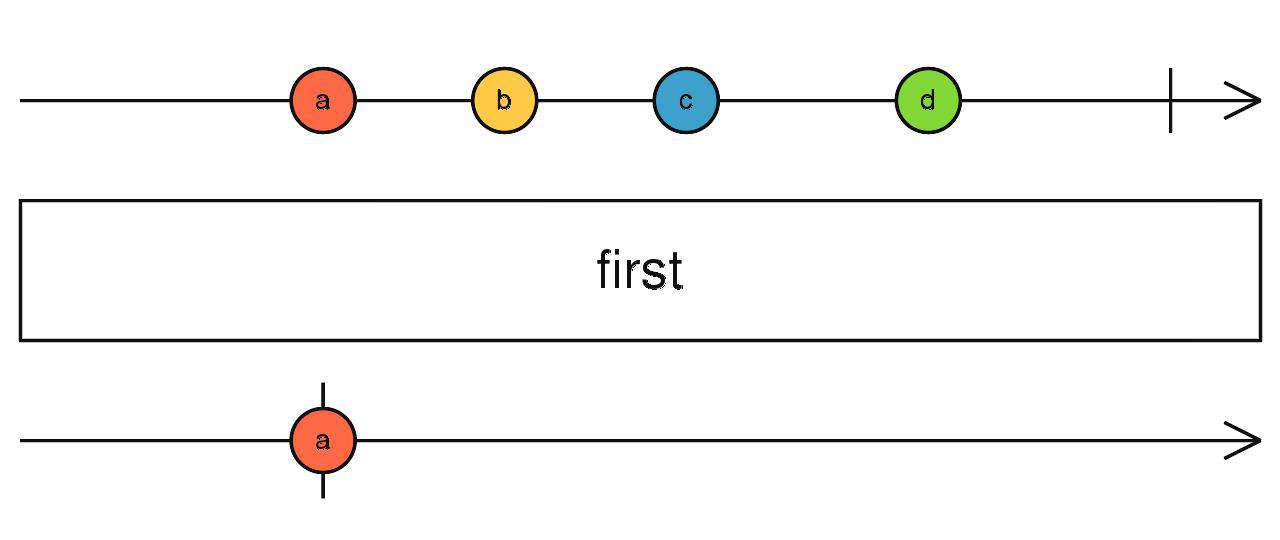
source$.pipe(first(() => true/false))
last
取第一个满足条件的数据,如果不传入条件,就取最后一个,流完成才会触发。
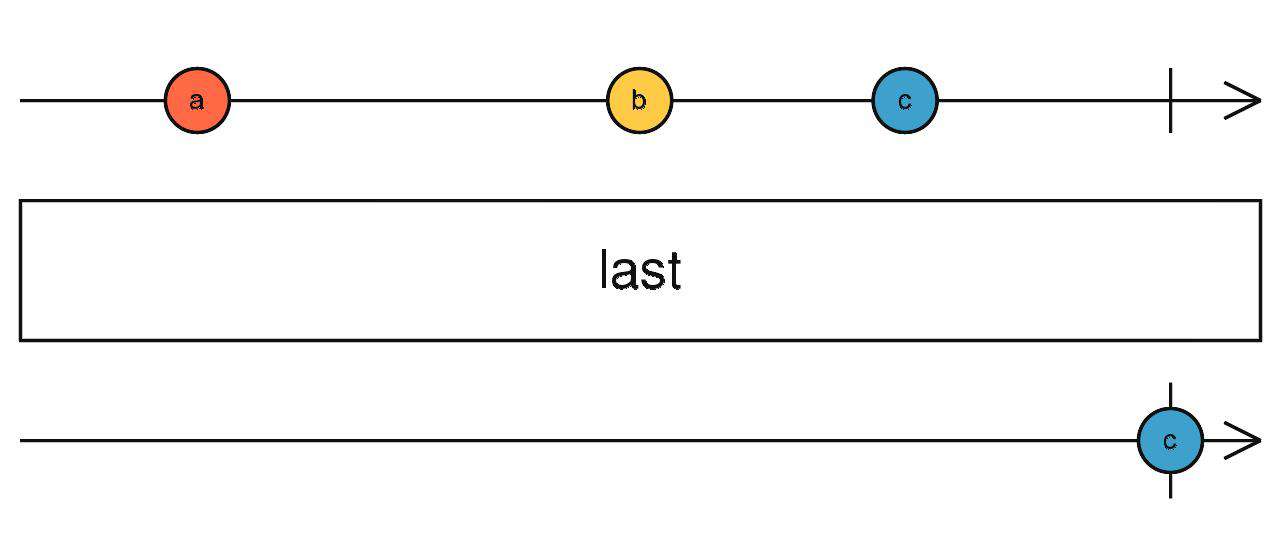
source$.pipe(last(() => true/false))
take
拿够前 N 个就完成
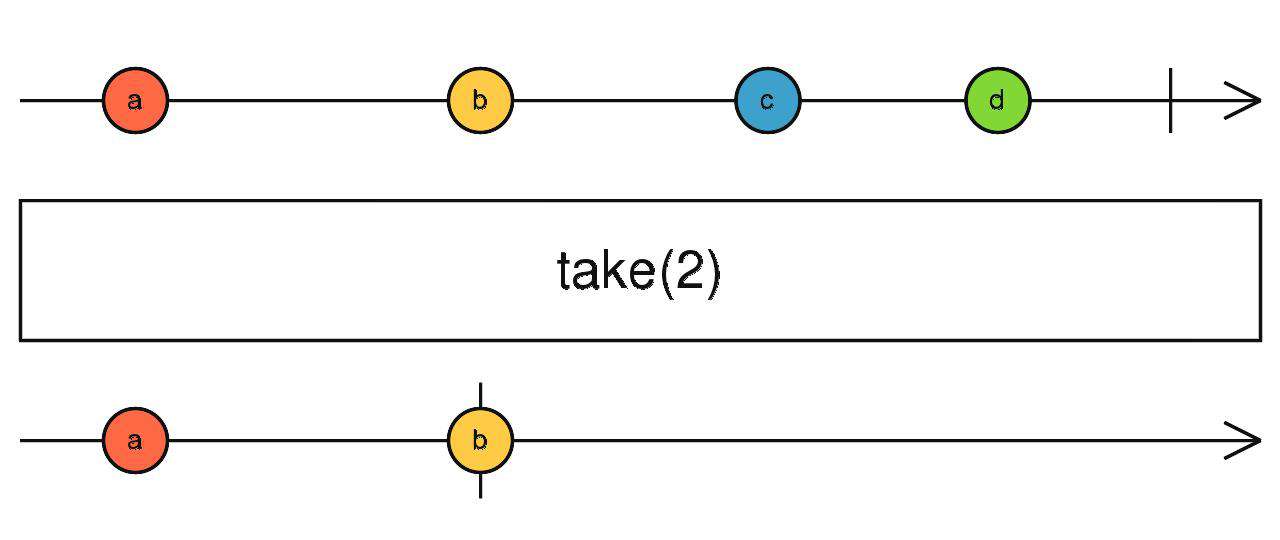
source$.pipe(take(N))
takeLast
拿够后N个就结束,因为是后几个所以只有流完成了才会将数据一次发出。
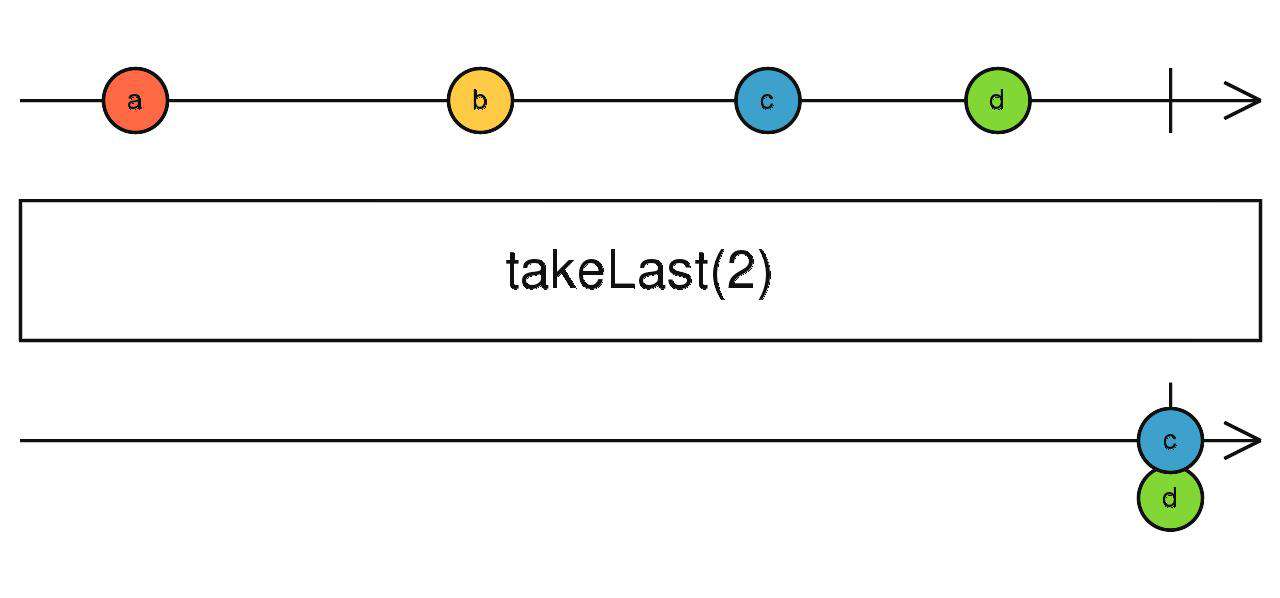
source$.pipe(takeLast(N))
takeWhile
给我传判断函数,什么时候结束你来定
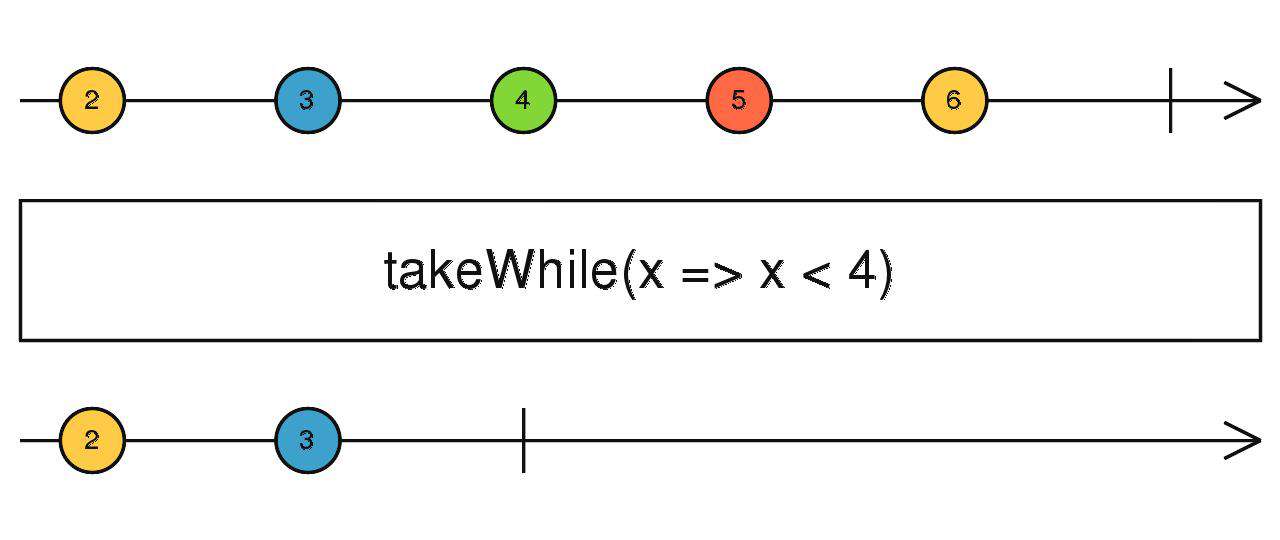
source$.pipe(takeWhile(() => true/false))
takeUntil
给我一个流(A),什么时候这个流(A)吐出数据了,我就完成
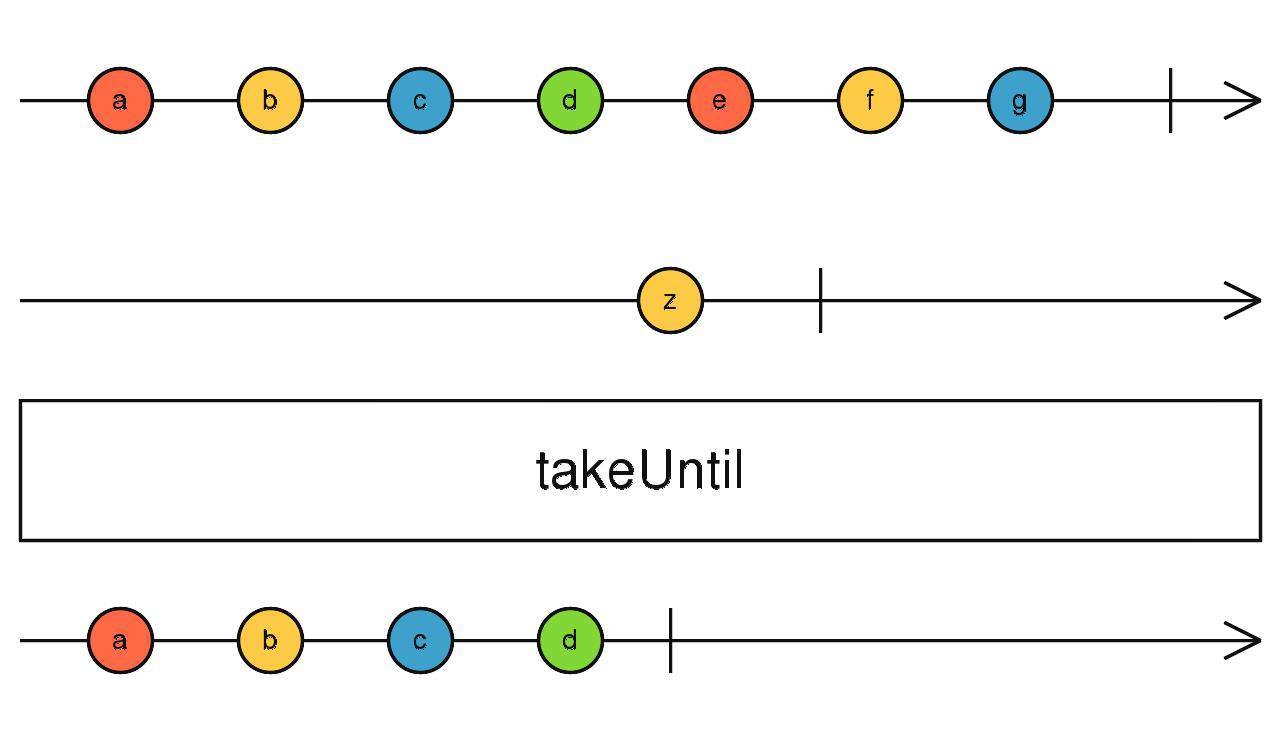
source$.pipe(takeUntil(timer(1000)))
skip
跳过前 N 个数据
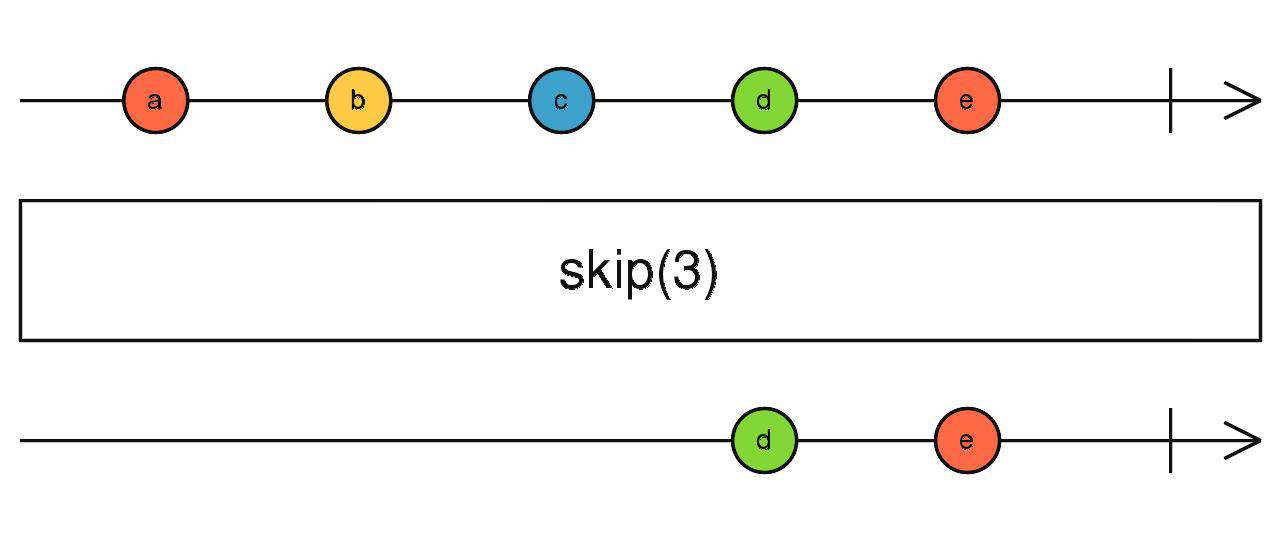
source$.pipe(skip(N))
skipWhile
给我传函数,跳过前几个你来定
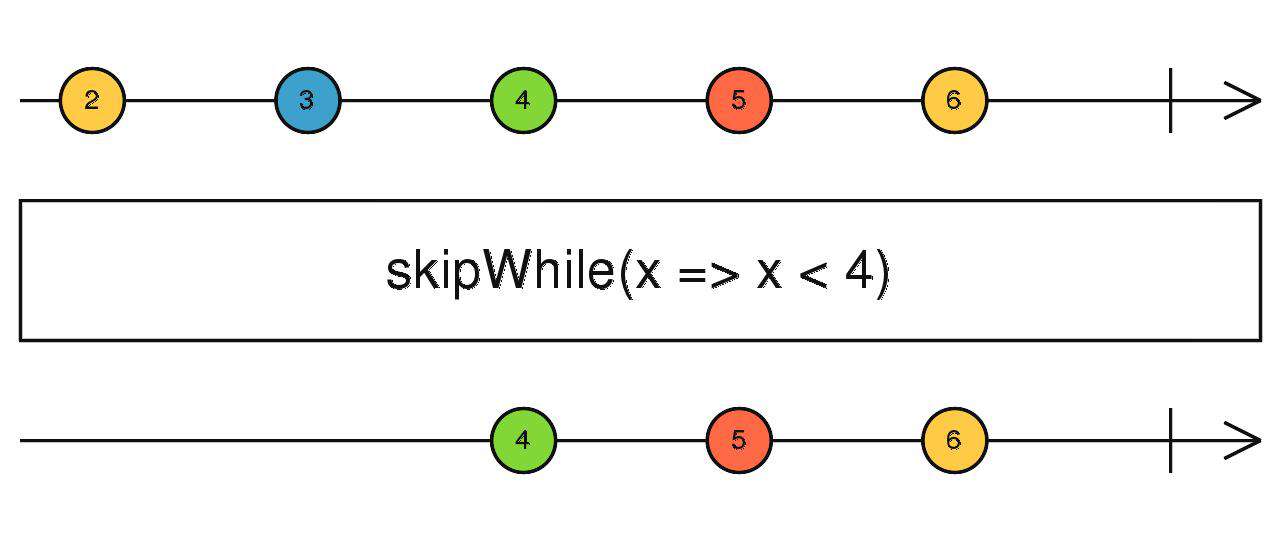
source$.pipe(skipWhile(() => true/false))
skipUntil
给我一个流(A),什么时候这个流(A)吐出数据了,我就不跳了
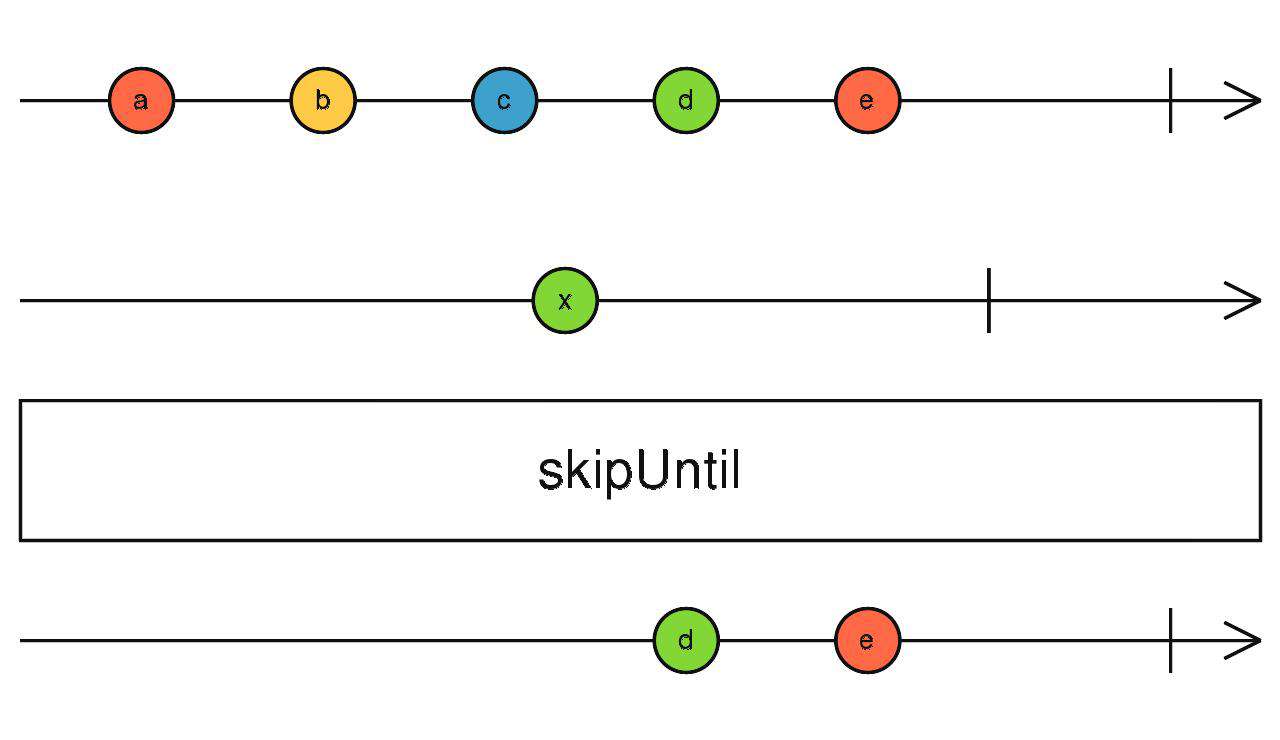
source$.pipe(skipUntil(timer(1000)))
转化类操作符
map
- 接受上游传入的值,返回一个其他的值给下游。(如果你还返回上游的值,那就没有任何意义了)
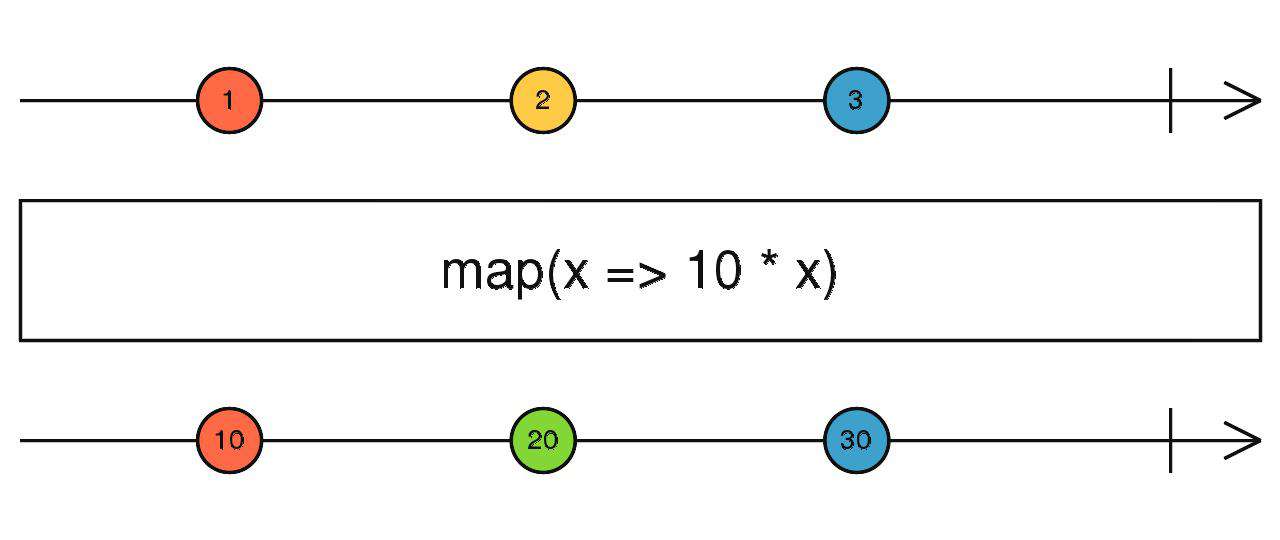
source$.pipe(map(() => {}))
mapTo
- 将传入的值给下游。
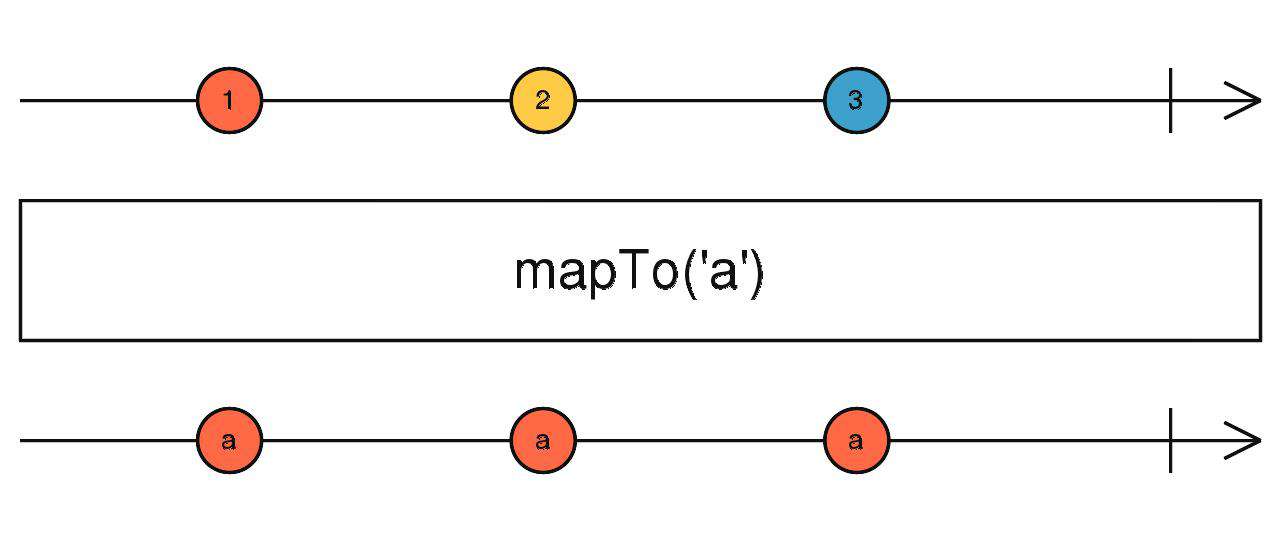
source$.pipe(mapTo('a'))
pluck
- 提取上游吐出对象的某个key,传给下游。
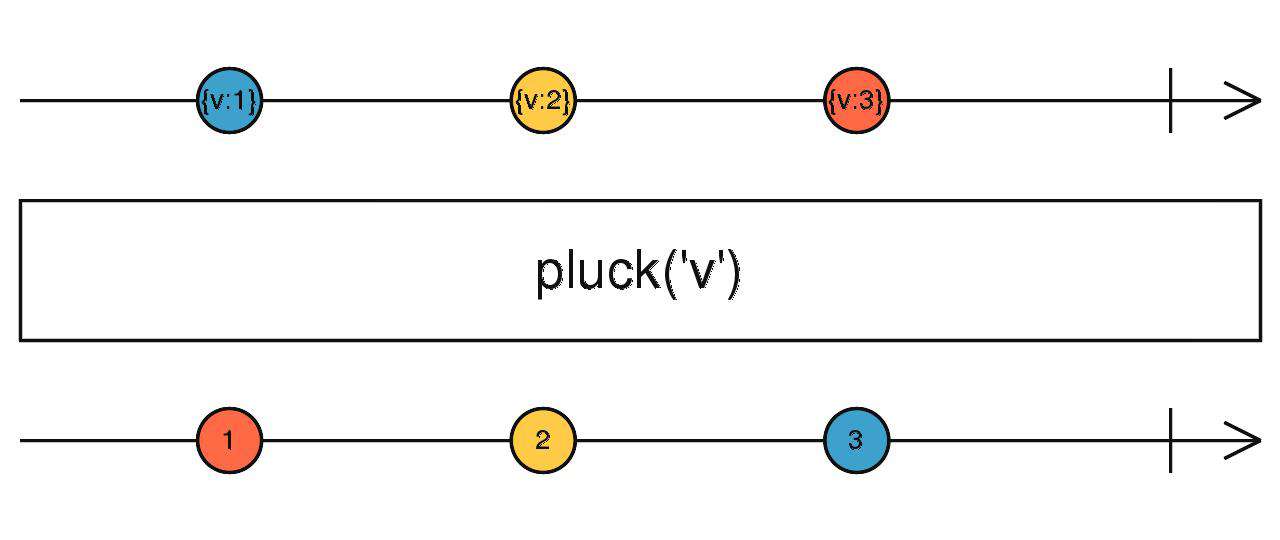
source$.pipe(pluck('v'))
有损回压控制
throttle
传入一个流(A),对上游数据进行节流,直到流(A)吐出数据时结束节流向下传递数据,然后重复此过程
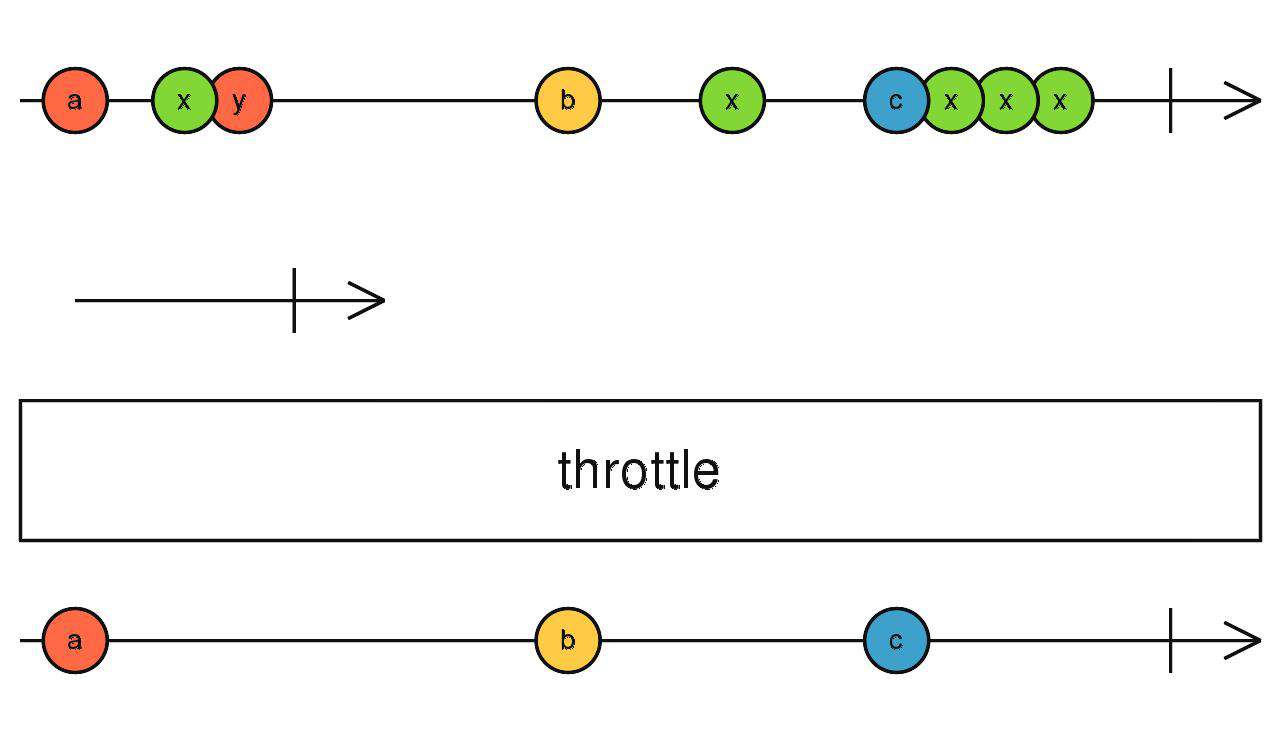
source$.pipe(throttle(interval(1000)))
throttleTime
根据时间(ms)节流
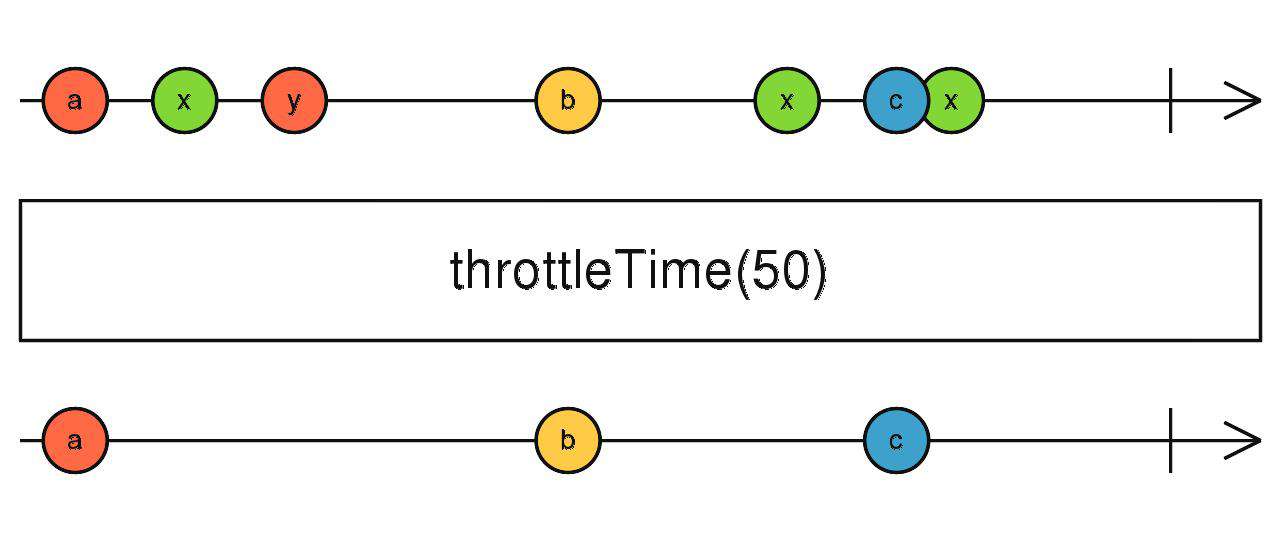
source$.pipe(throttleTime(1000))
debounce
传入一个流(A),对上游数据进行防抖,直到流(A)吐出数据时结束防抖向下传递数据,然后重复此过程
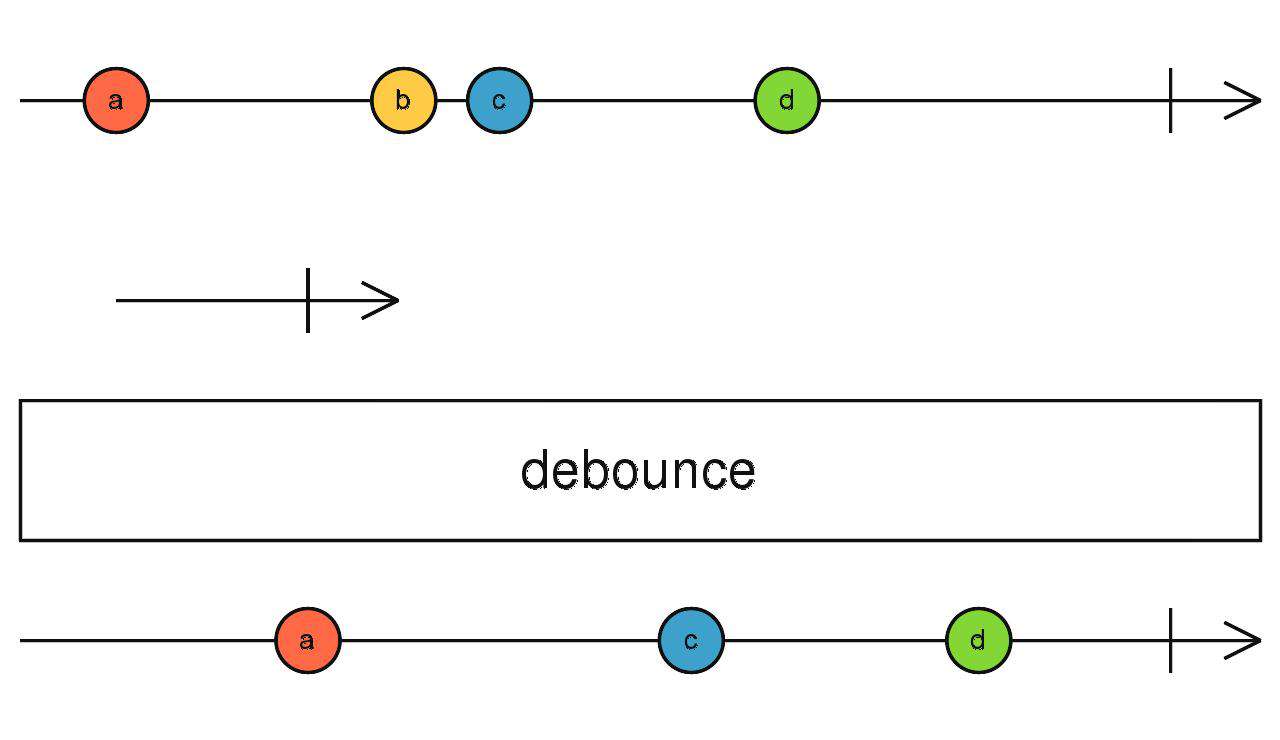
source$.pipe(debounce(interval(1000)))
debounceTime
根据时间(ms)防抖
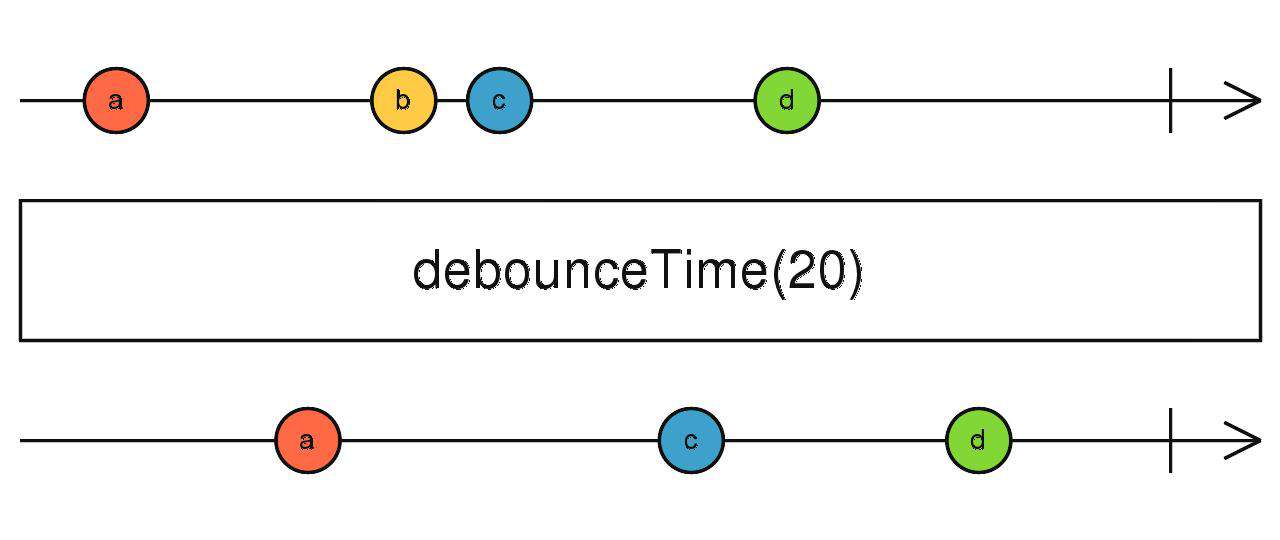
source$.pipe(debounceTime(1000))
audit
audit 同 throttle,区别在于:
- throttle:将节流期间接受的第一个数据发出
- audit:将节流期间接受的最后一个数据发出
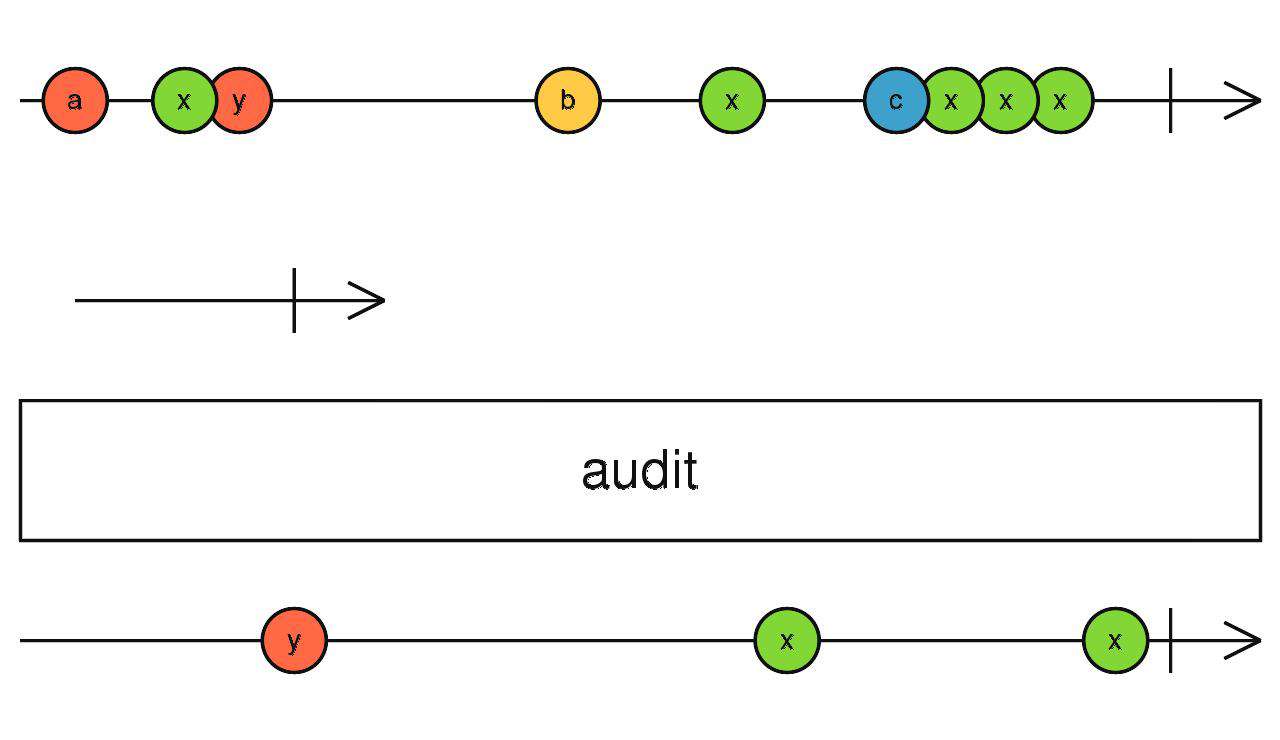
source$.pipe(audit(interval(1000)))
auditTime
同上,不再赘述
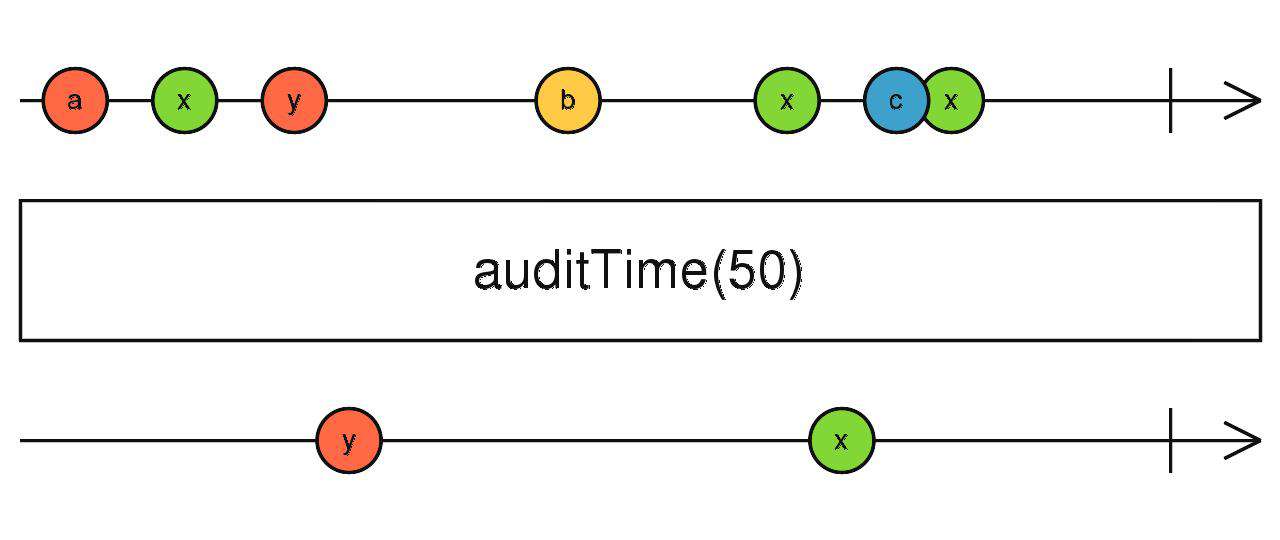
source$.pipe(auditTime(1000))
sample
-
正常的流,上游触发,下游就会收到数据。
-
使用了sample之后的流,会将上游发出的最新一个数据缓存,然后按照自己的节奏从缓存中取。
-
换句话说,不管上游发出数据的速度是快是慢。sample都不管,他就按照自己的节奏从缓存中取数,如果缓存中有就向下游吐出。如果没有就不做动作。
传入一个流(A),对上游数据吐出的最新数据进行缓存,直到流(A)吐出数据时从缓存中取出数据向下传递,然后重复此过程
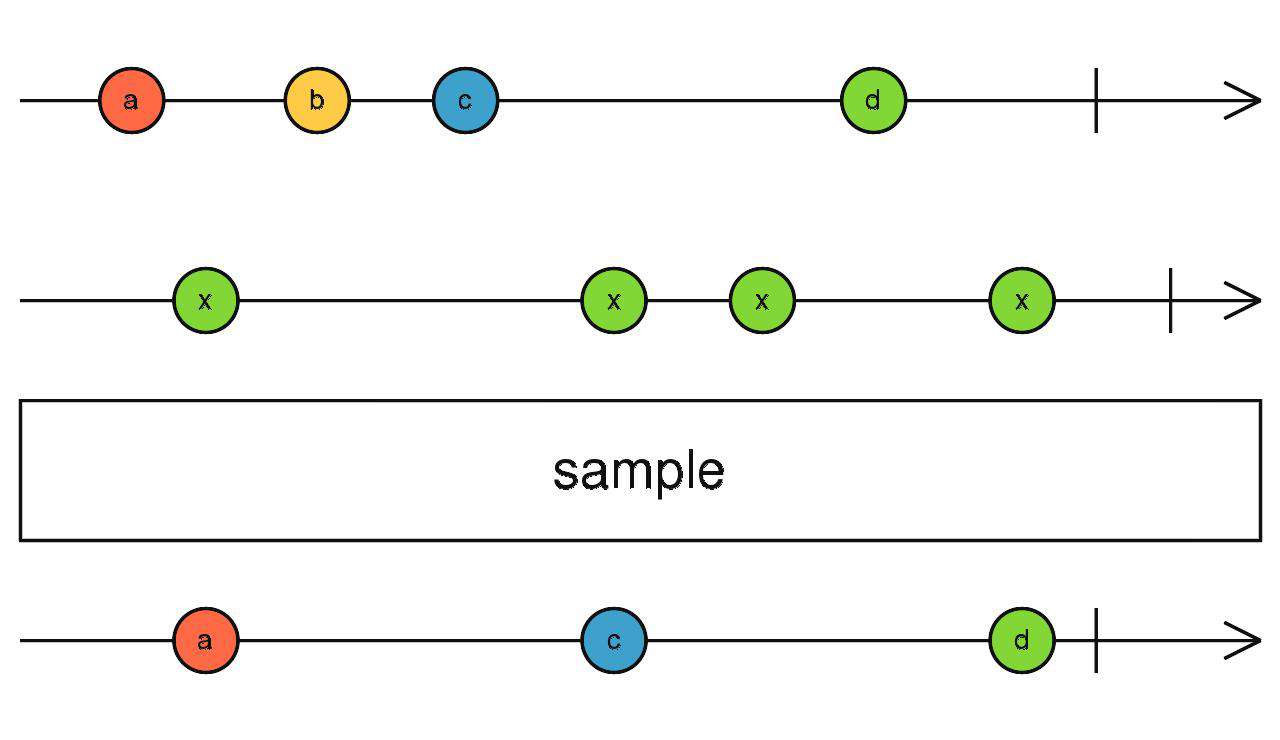
source$.pipe(sample(interval(1000)))
sampleTime
根据时间(ms)取数
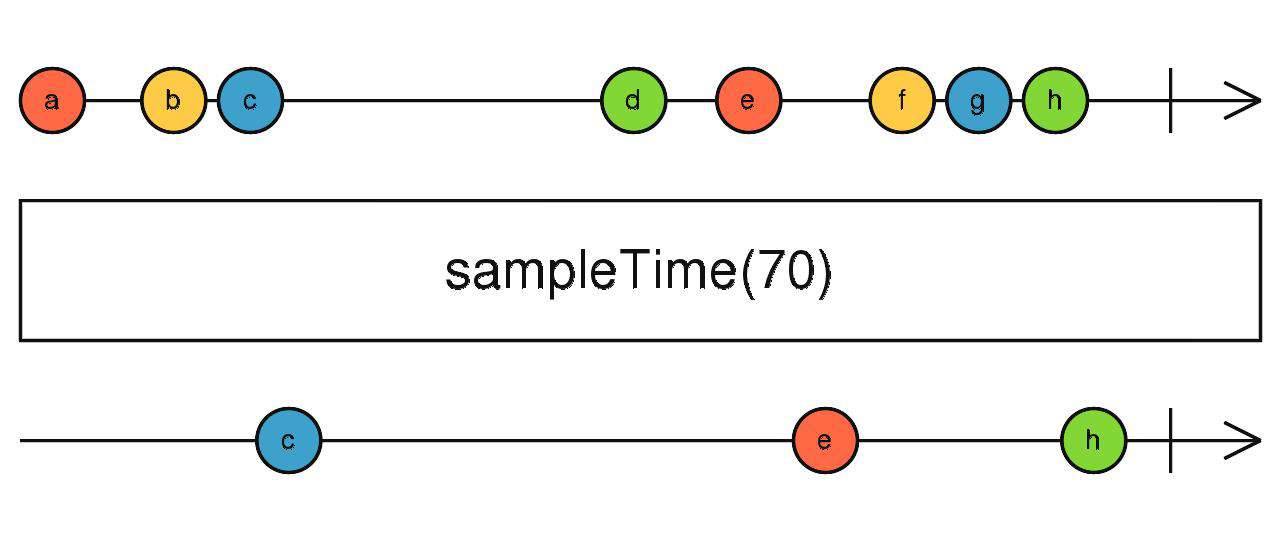
source$.pipe(sampleTime(1000))
distinct
- distinct前缀表示去重操作
所有元素去重,返回当前流中从来没有出现过的数据。
传入函数时,根据函数的返回值分配唯一key。
source$.pipe(distinct())
Observable.of({ age: 4, name: 'Foo'}).pipe(distinct((p) => p.name))
distinctUntilChanged
相邻元素去重,只返回与上一个数据不同的数据。
传入函数时,根据函数的返回值分配唯一key。
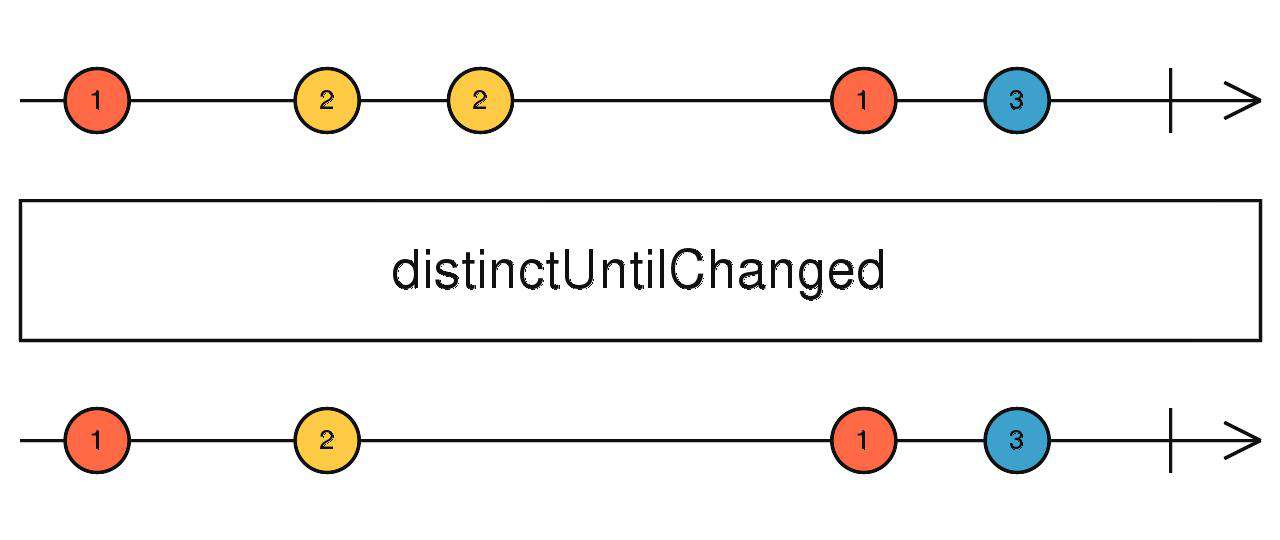
source$.pipe(distinctUntilChanged())
distinctUntilKeyChanged
- distinctUntilChanged的简化版,帮你实现了取对象key的逻辑。
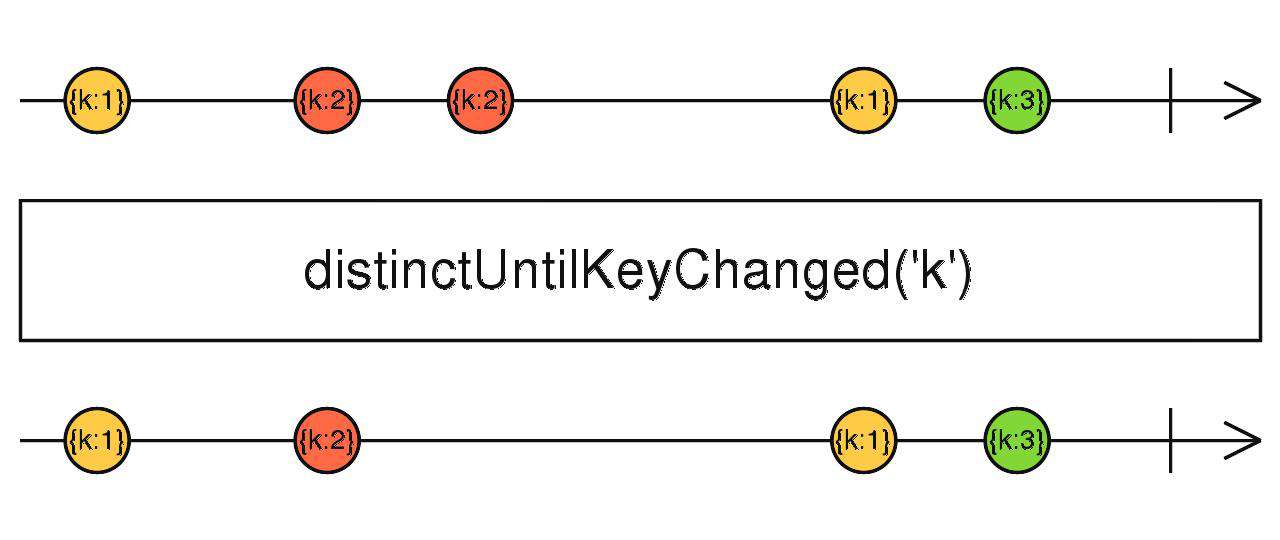
source$.pipe(distinctUntilKeyChanged('id'))
ignoreElements
忽略上游的所有数据,当上游完成时,ignoreElements也会完成。(我不关心你做了什么,只要告诉我完没完成就行)
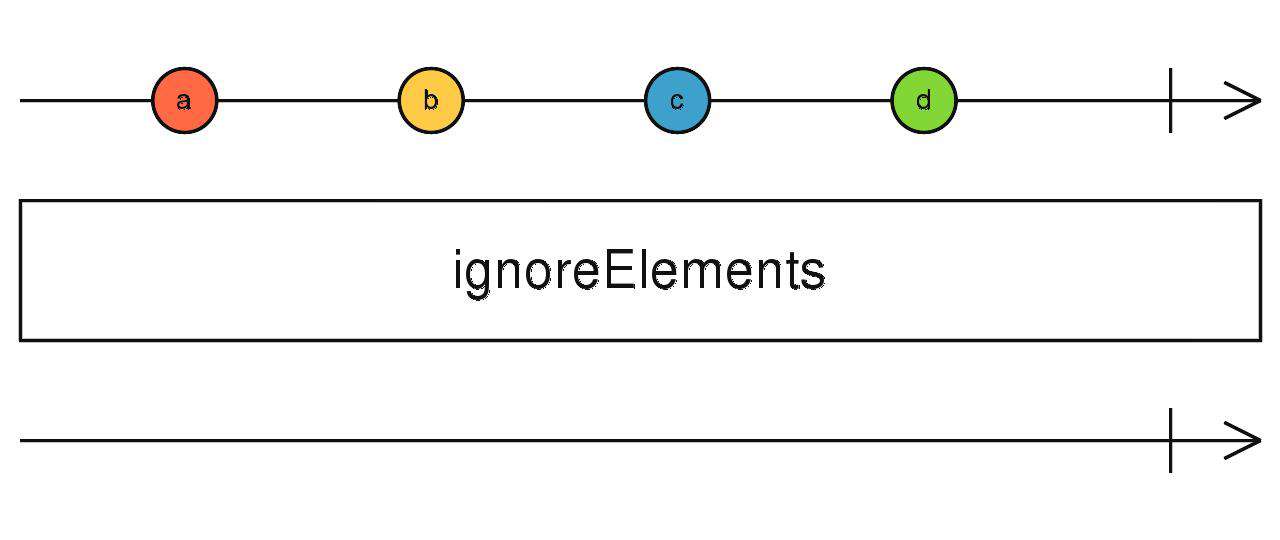
source$.pipe(ignoreElements())
elementAt
只获取上游数据发出的第N个数据。
第二个参数相当于默认值:当上游没发出第N个数据就结束时,发出这个参数给下游。
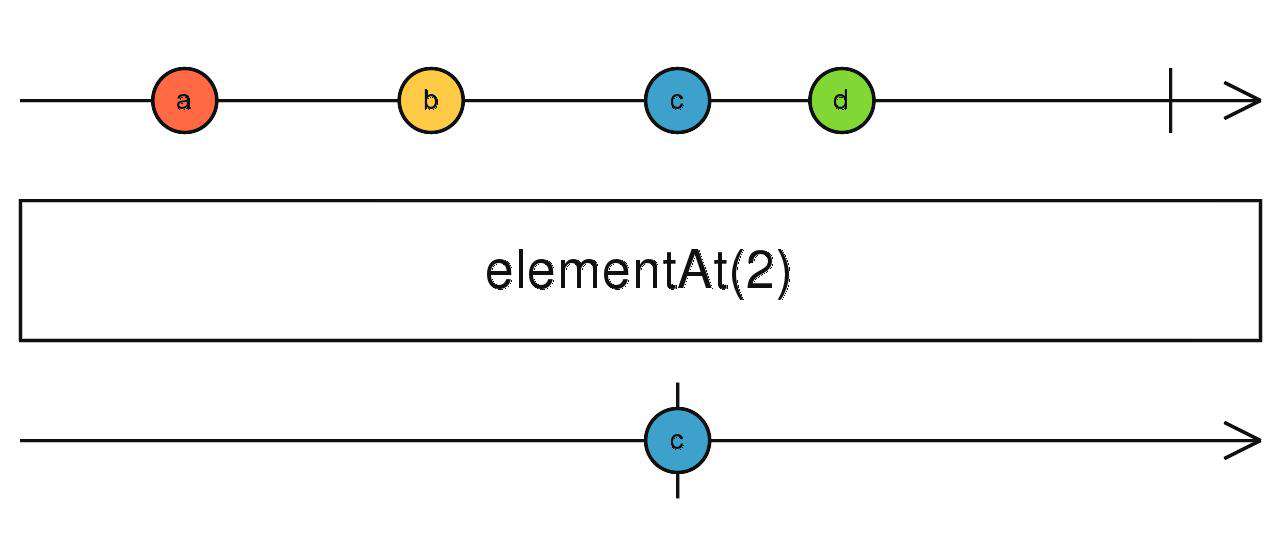
source$.pipe(elementAt(4, null))
single
- 检查上游的所有数据,如果满足条件的数据只有一个,就向下发送这个数据。否则向下传递异常。
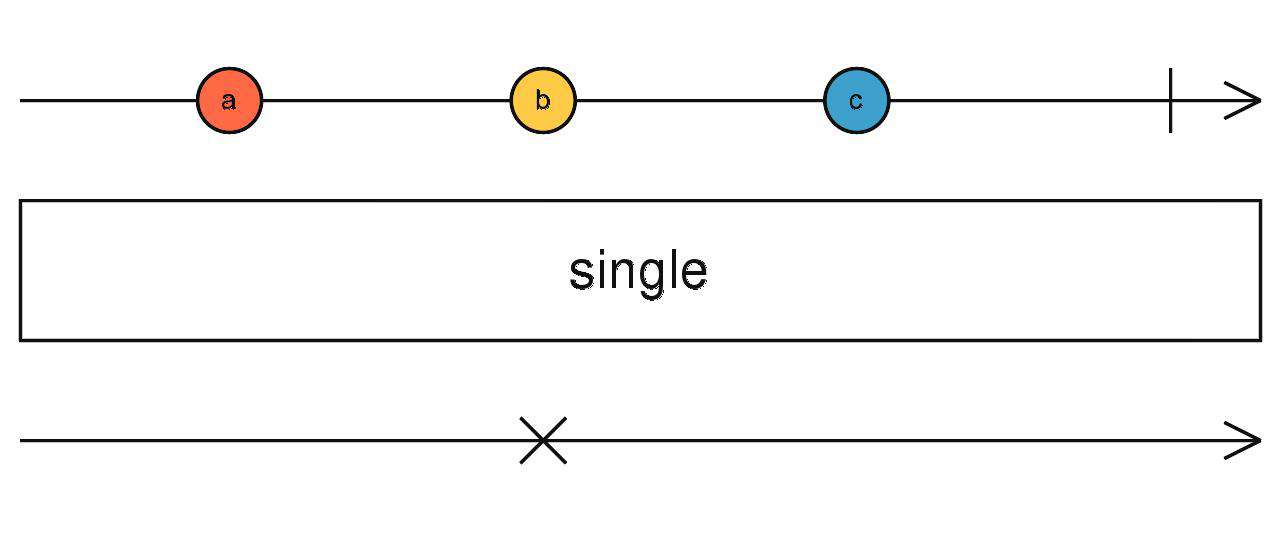
source$.pipe(single(() => true/false))
无损回压控制
- buffer前缀:将值缓存到数组中,吐出给下游。
- window前缀:将值缓存到一个流中,吐出给下游。
bufferTime、windowTime
缓存上游吐出的数据,到指定时间后吐出,然后重复。
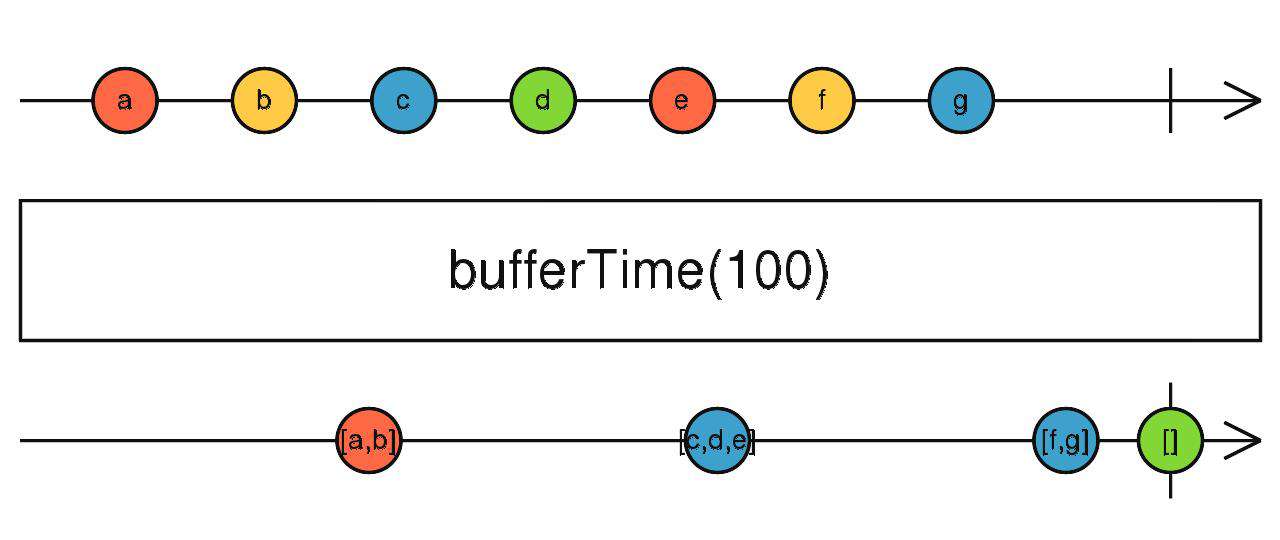
source$.pipe(bufferTime(1000))
bufferCount、windowCount
缓存上游吐出的数据,到指定个数后吐出,然后重复。
第二个参数用来控制每隔几个数据开启一次缓存区,不传时可能更符合我们的认知。
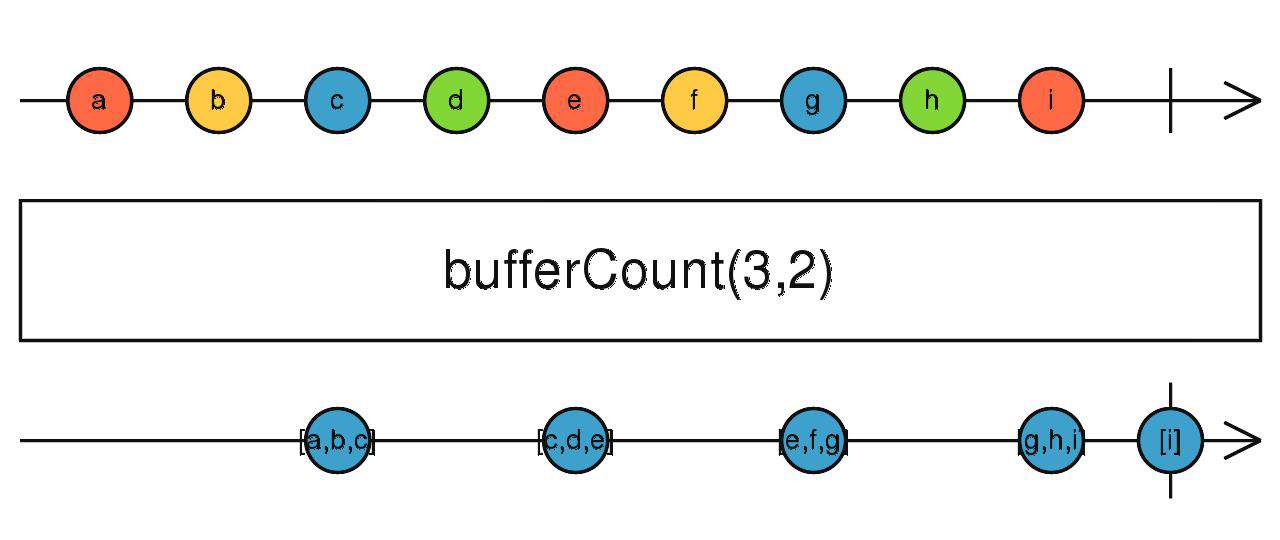
source$.pipe(bufferCount(10))
bufferWhen、windowWhen
传入一个返回流(A)的工厂函数
流程如下:
- 触发订阅时,调用工厂函数拿到流(A),开始缓存
- 等待流(A)发出数据时,将缓存的值向下吐出
- 重新调用工厂函数,拿到一个新的流(A),开启缓存,循环往复。
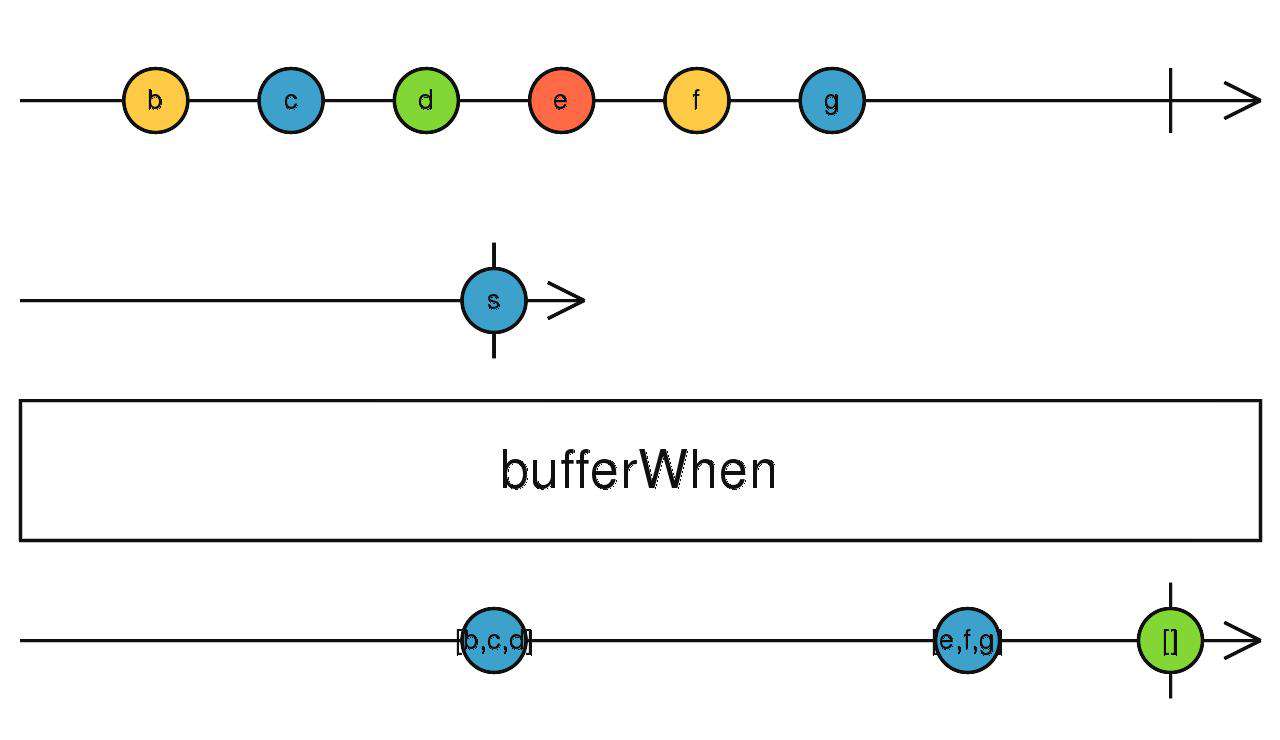
randomSeconds = () => timer(Math.random() * 10000 | 0)
source$.pipe(bufferWhen(randomSeconds))
bufferToggle、windowToggle
第一个参数为开启缓存流(O),第二个参数为返回关闭缓存流(C)的工厂函数
流程如下:
- 当开启流(O)吐出数据时,调用工厂函数获取关闭流(C),开始缓存
- 等待关闭流(C)吐出数据后,将缓存的值向下吐出
- 等待开启流(O)吐出数据,然后重复步骤1
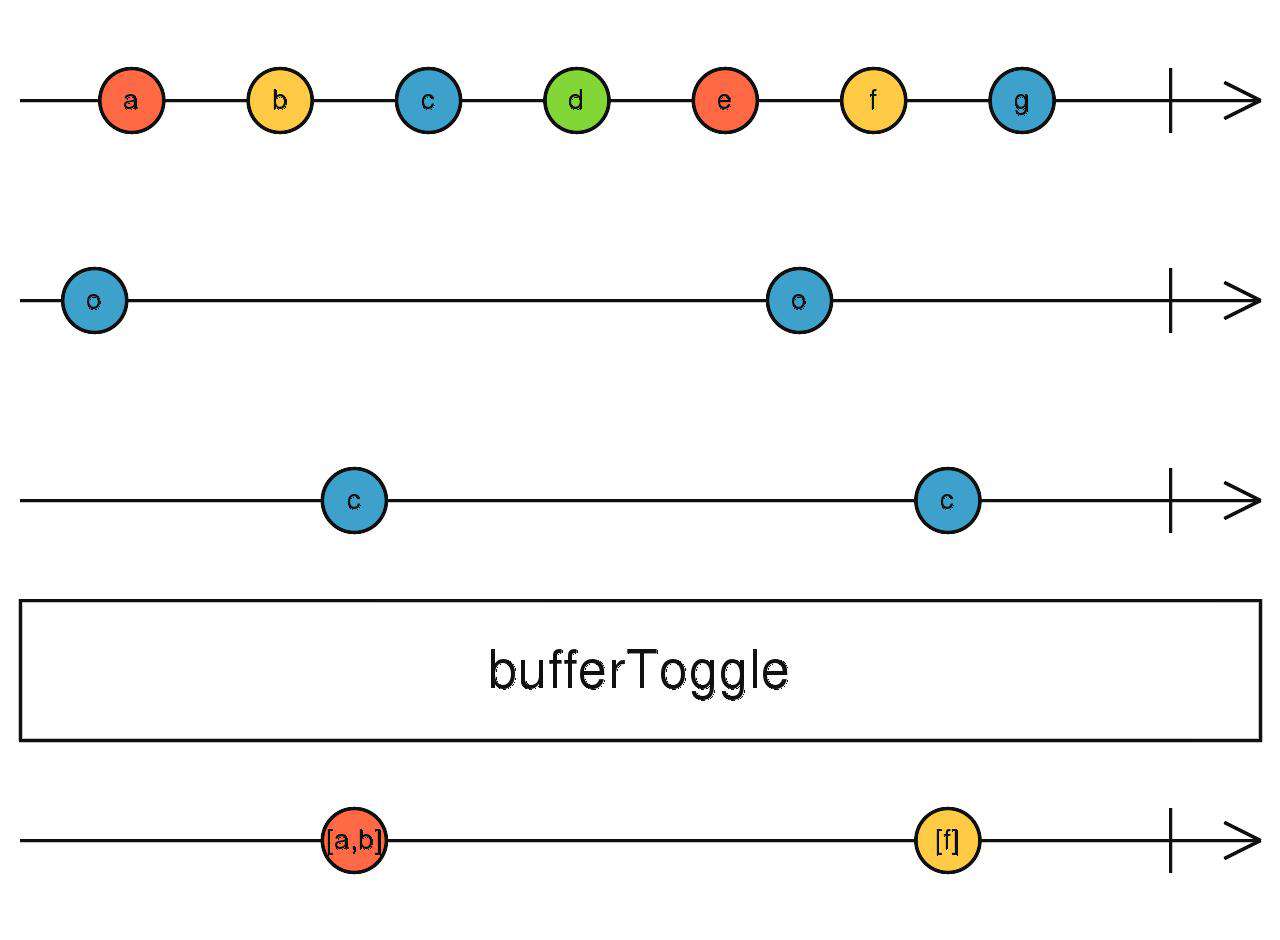
source$.pipe(bufferToggle(interval(1000), () => randomSeconds))
buffer、window
传入一个关闭流(C),区别与bufferWhen:传入的是流,而不是返回流的工厂函数。
触发订阅时,开始缓存,当关闭流(C)吐出数据时,将缓存的值向下传递并重新开始缓存。
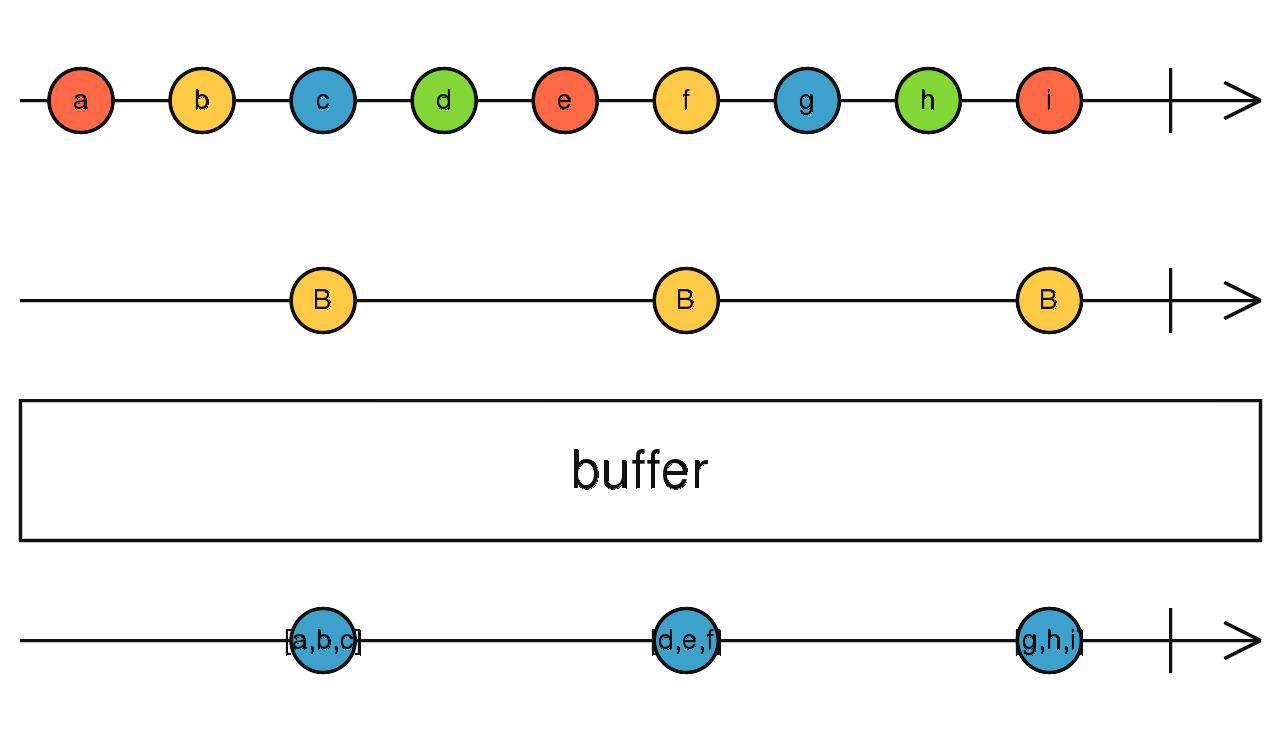
source$.pipe(buffer(interval(1000)))
累计数据
scan
scan和reduce的区别在于:
- reduce:只有当流完成后才会触发
- scan:每一次流接受到数据后都会触发
区别于其他流,scan拥有了保存、记忆状态的能力。
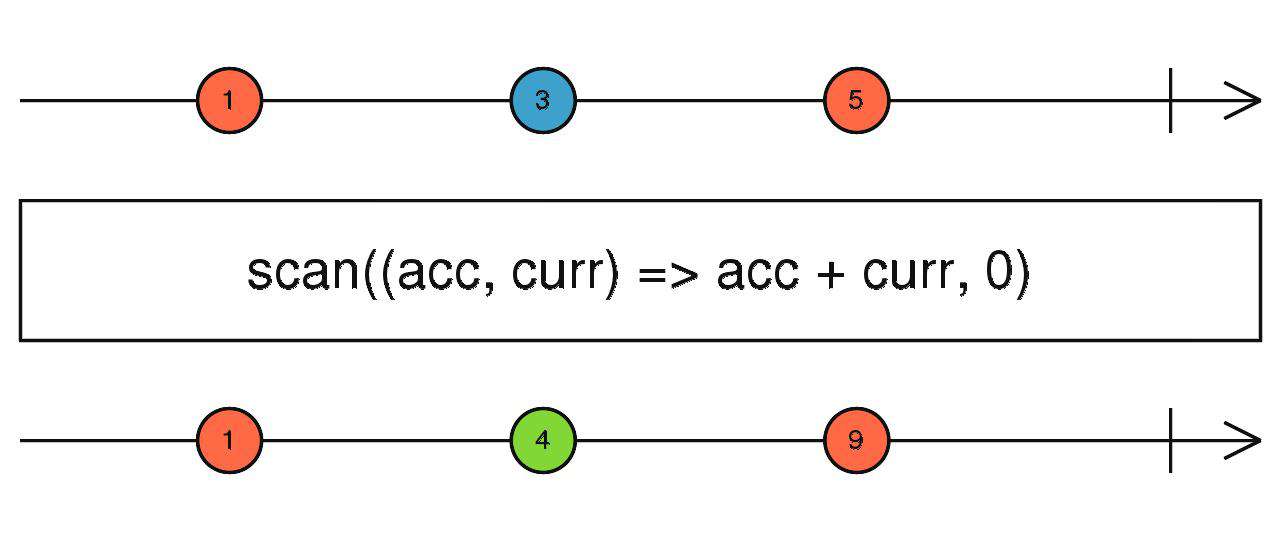
source$.pipe(scan(() => {}, 0))
mergeScan
同scan,但是返回的不是数据而是一个流。
- 当上游吐出数据时,调用规约函数得到并订阅流(A),将流(A)返回的数据向下游传递,并缓存流(A)返回的最后一个数据。当上游再次吐出数据时,将缓存的最后一个数据传给规约函数,循环往复。
source$.pipe(mergeScan(() => interval(1000)))
错误处理
catch
捕获错误
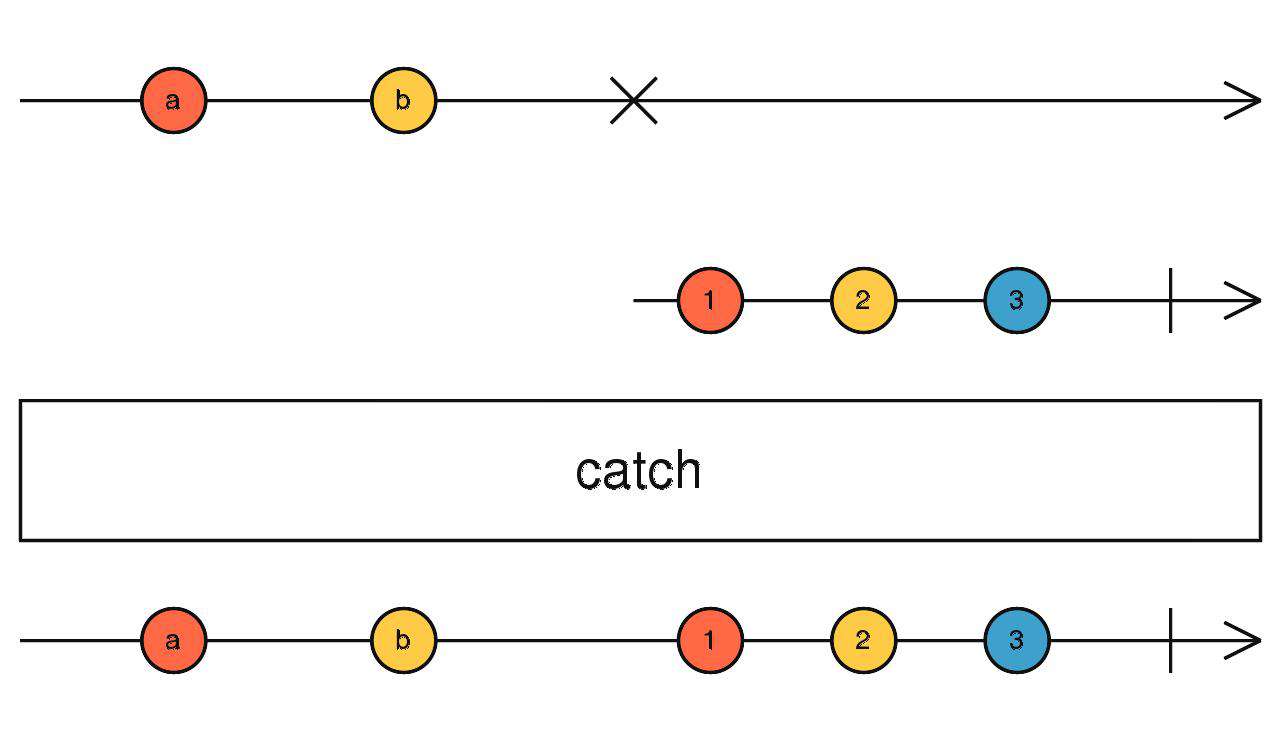
source$.pipe(catch(err => of('I', 'II', 'III', 'IV', 'V')))
retry
传入数字 N,遇到错误时,重新订阅上游,重试 N 次结束。
source$.pipe(retry(3))
retryWhen
传入流(A),遇到错误时,订阅流(A),流(A)每吐出一次数据,就重试一次。流完成,retrywfhen也完成。
source$.pipe(retryWhen((err) => interval(1000)))
finally
source$.pipe(finally())
多播操作符
multicast
接收返回Subject的工厂函数,返回一个hot observable(HO)
当链接开始时,订阅上游获取数据,调用工厂函数拿到Subject,上游吐出的数据通过Subject进行多播。
- 返回的HO拥有
connect、refCount方法。 - 调用
connect才会真正开始订阅顶流并发出数据。 - 调用
refCount则会根据subscribe数量自动进行connect和unsubscribe操作。 - 多播操作符的老大,较为底层的设计,日常使用不多。
- 后面的多播操作符都是基于此操作符实现。
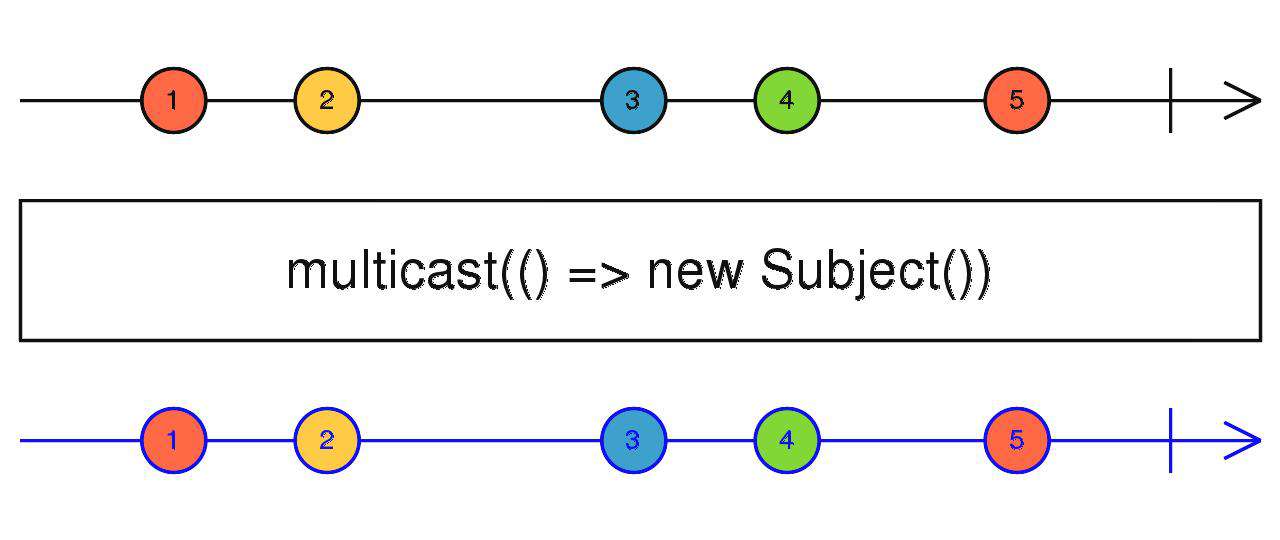
source$.pipe(multicast(() => new Subject()))
publish
- 封装了multicast操作符需要传入Subject工厂函数的操作,其他保持一致。
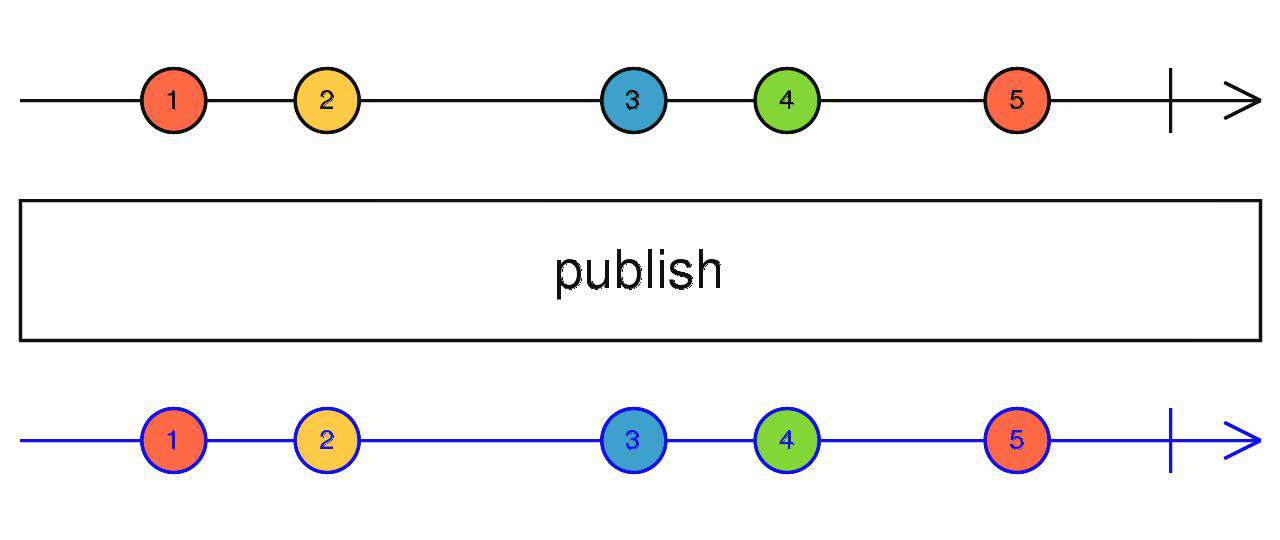
source$.pipe(publish())
share
基于publish的封装,返回调用refCount后的结果(看代码)
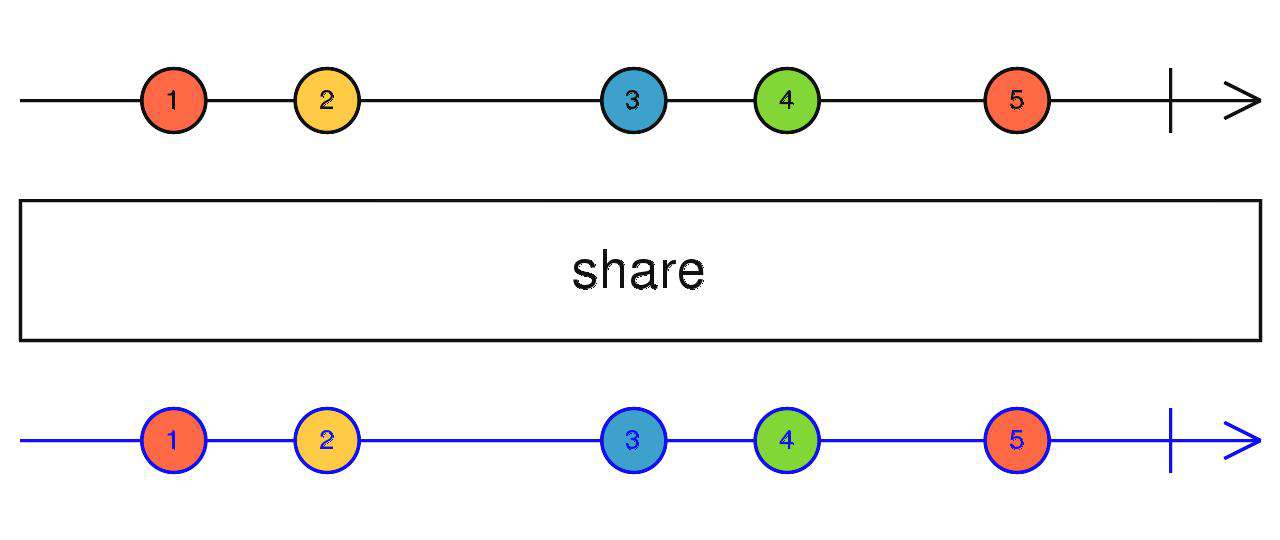
source$.pipe(share())
// 等同于
source$.pipe(publish().refCount())
publishLast
当上游完成后,多播上游的最后一个数据并完成当前流。
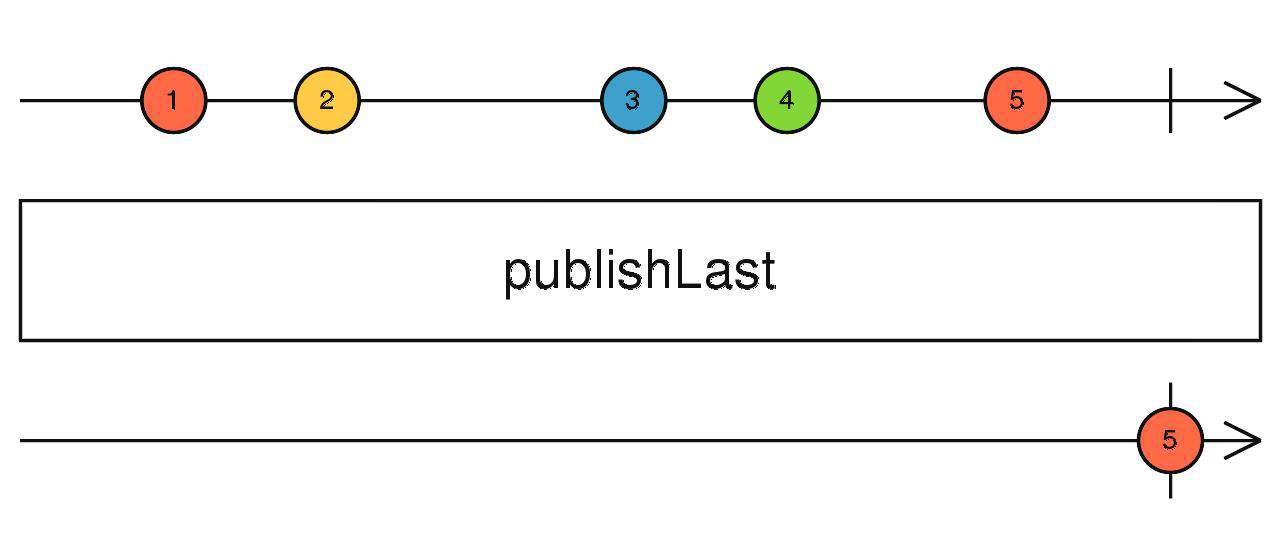
source$.pipe(publishLast())
publishReplay
传入缓存数量 N ,缓存上游最新的 N 个数据,当有新的订阅时,将缓存吐出。
- 上游只会被订阅一次。
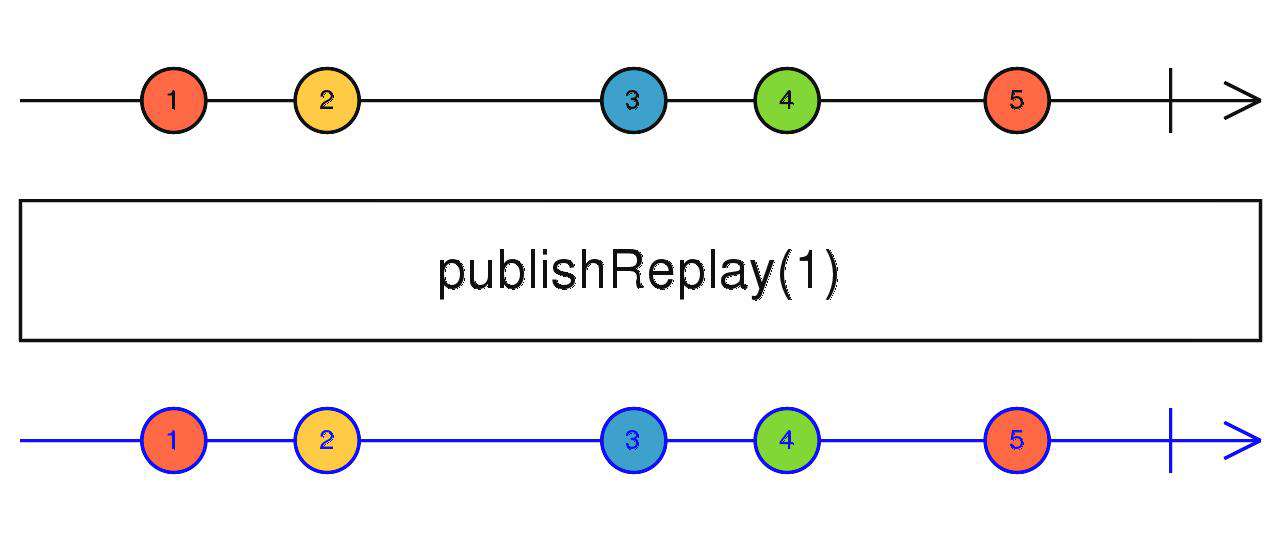
source$.pipe(publishReplay(1))
publishBehavior
缓存上游吐出的最新数据,当有新的订阅时,将最新值吐出。如果被订阅时上游从未吐出过数据,就吐出传入的默认值。
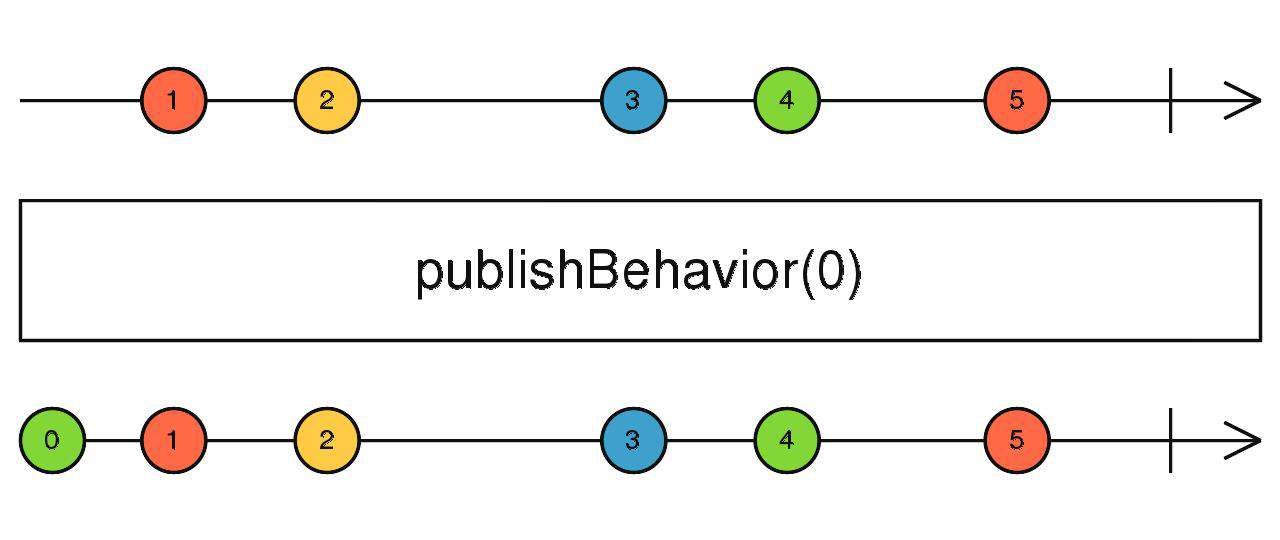
source$.pipe(publishBehavior(0))
高阶合并类操作符
- 高阶操作符不是高级操作符
- 当一个流吐出的不是数据,而是一个流时,这就是一个高阶流,就像如果一个函数的返回值还是一个函数的话,我们就称之为高阶函数
- 高阶操作符就是操作高阶流的操作符
如下代码示例,顶层的流吐出的并不是普通的数据,而是两个会产生数据的流,那么此时下游在接受时,就需要对上游吐出的流进行订阅获取数据,如下:
of(of(1, 2, 3), of(4, 5, 6))
.subscribe(
ob => ob.subscribe((num) => {
console.log(num)
})
)
上面的代码只是简单的将数据从流中取出,如果我想对吐出的流运用前面讲的操作符应该怎么办?
cache = []
of(of(1, 2, 3), of(4, 5, 6))
.subscribe({
next: ob => cache.push(ob),
complete: {
concat(...cache).subscribe(console.log)
zip(...cache).subscribe(console.log)
}
})
先不管上述实现是否合理,我们已经可以对上游吐出的流运用操作符了,但是这样实现未免也太过麻烦,所以Rxjs为我们封装了相关的操作符来帮我们实现上述的功能。
总结一下:高阶操作符操作的是流,普通操作符操作的是数据。
concatAll
对应concat,缓存高阶流吐出的每一个流,依次订阅,当所有流全部完成,concatAll随之完成。
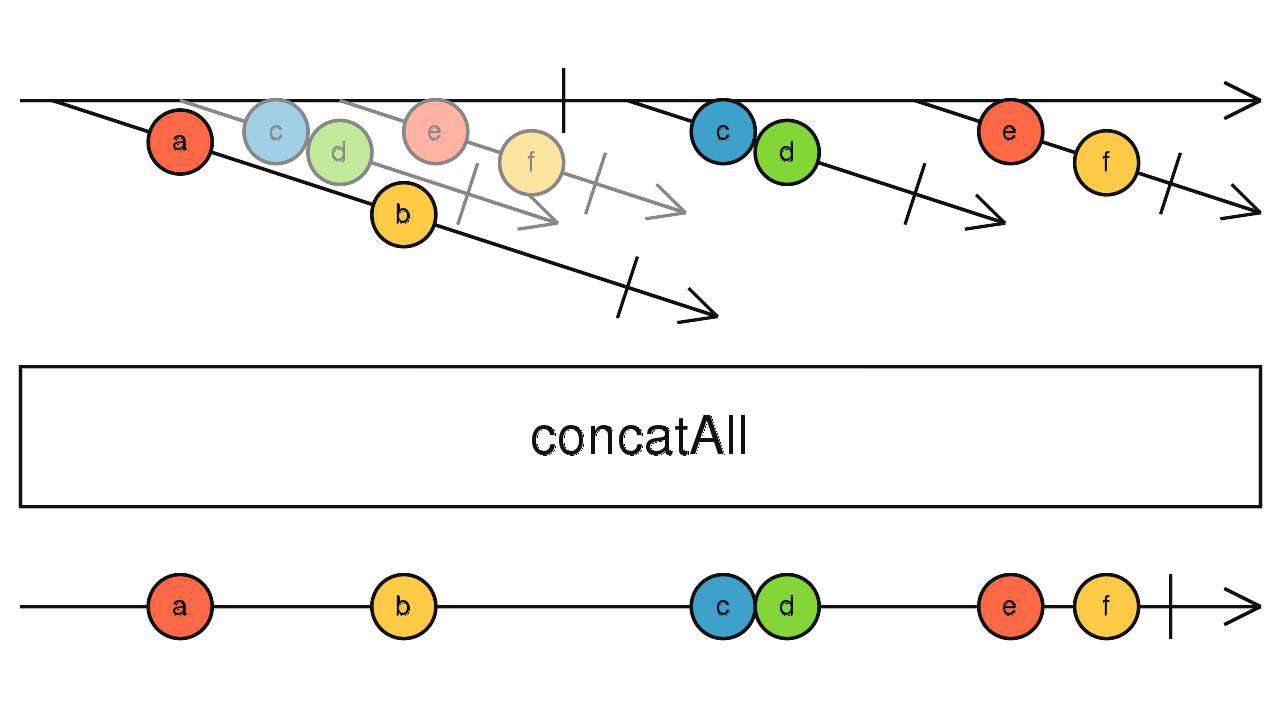
source$.pipe(concatAll())
mergeAll
对应merge,订阅高阶流吐出的每一个流,任意流吐出数据,mergeAll随之吐出数据。
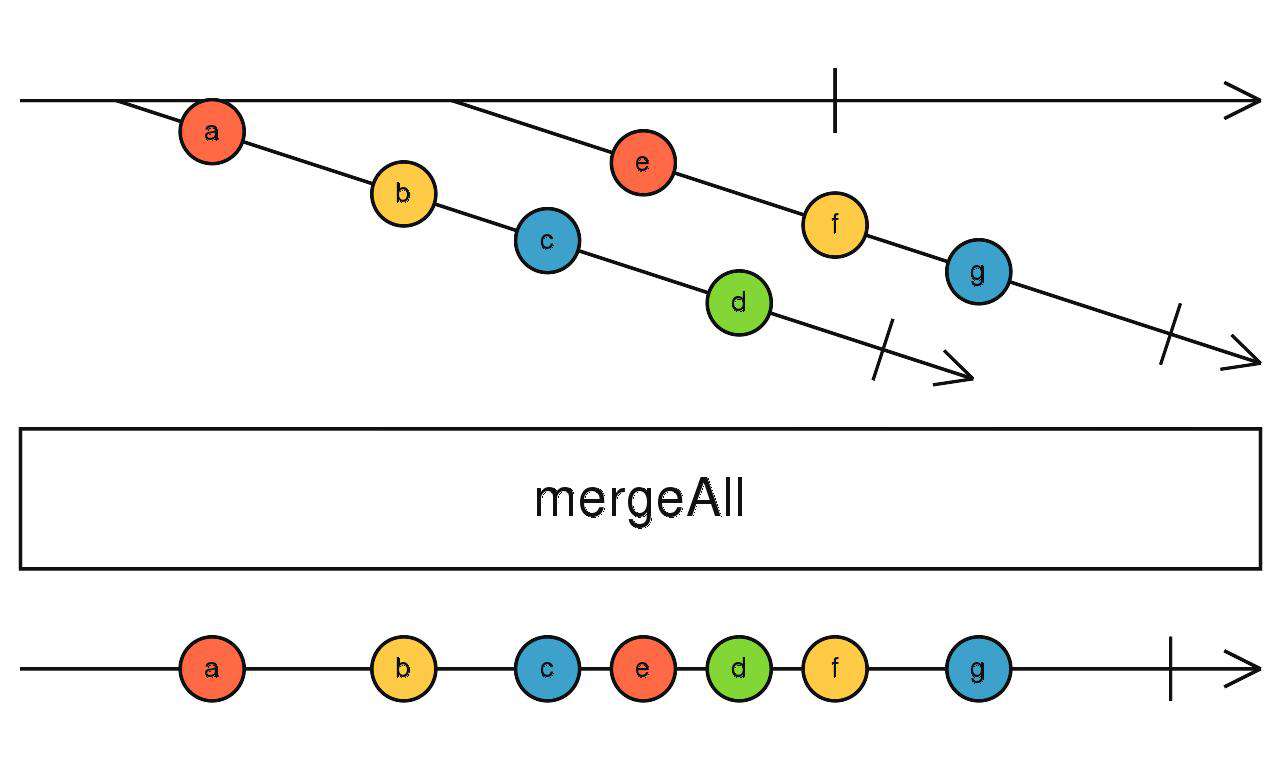
source$.pipe(mergeAll())
zipAll
对应zip,订阅高阶流吐出的每一个流,合并这些流吐出的相同索引的数据向下传递。
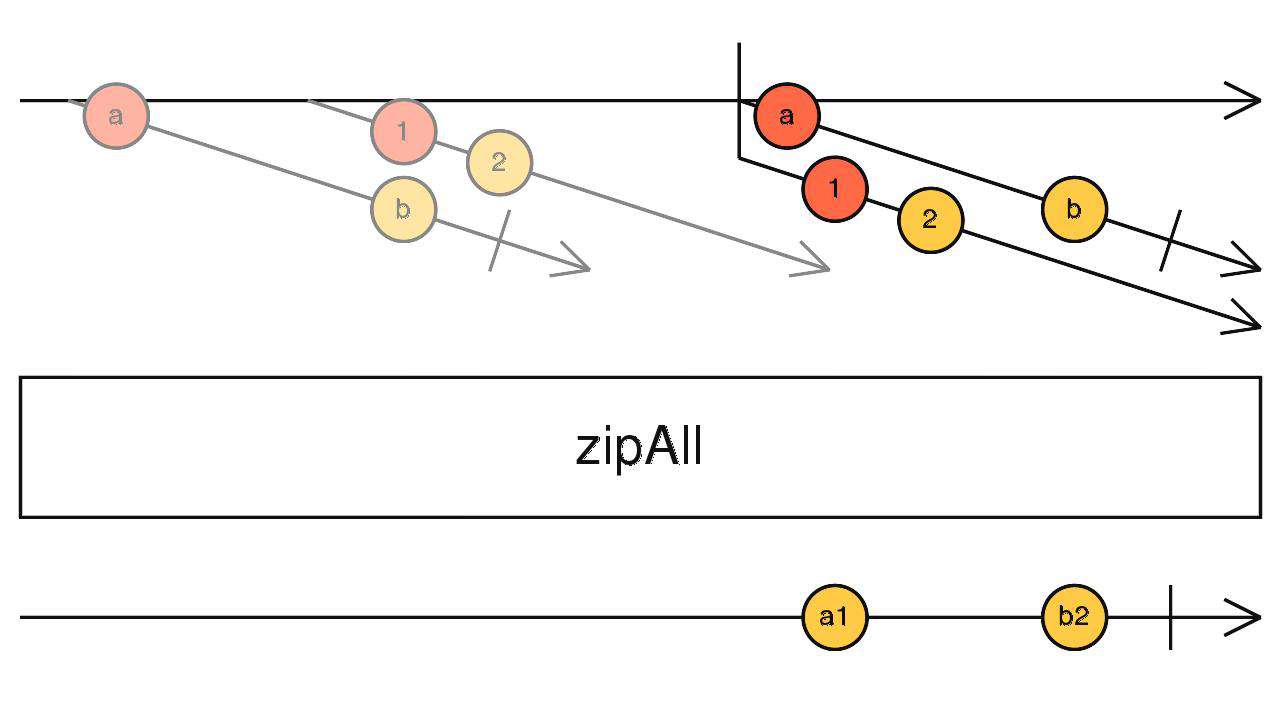
source$.pipe(zipAll())
combineAll
对应combineLatest,订阅高阶流吐出的每一个流,合并所有流的最后值向下传递。
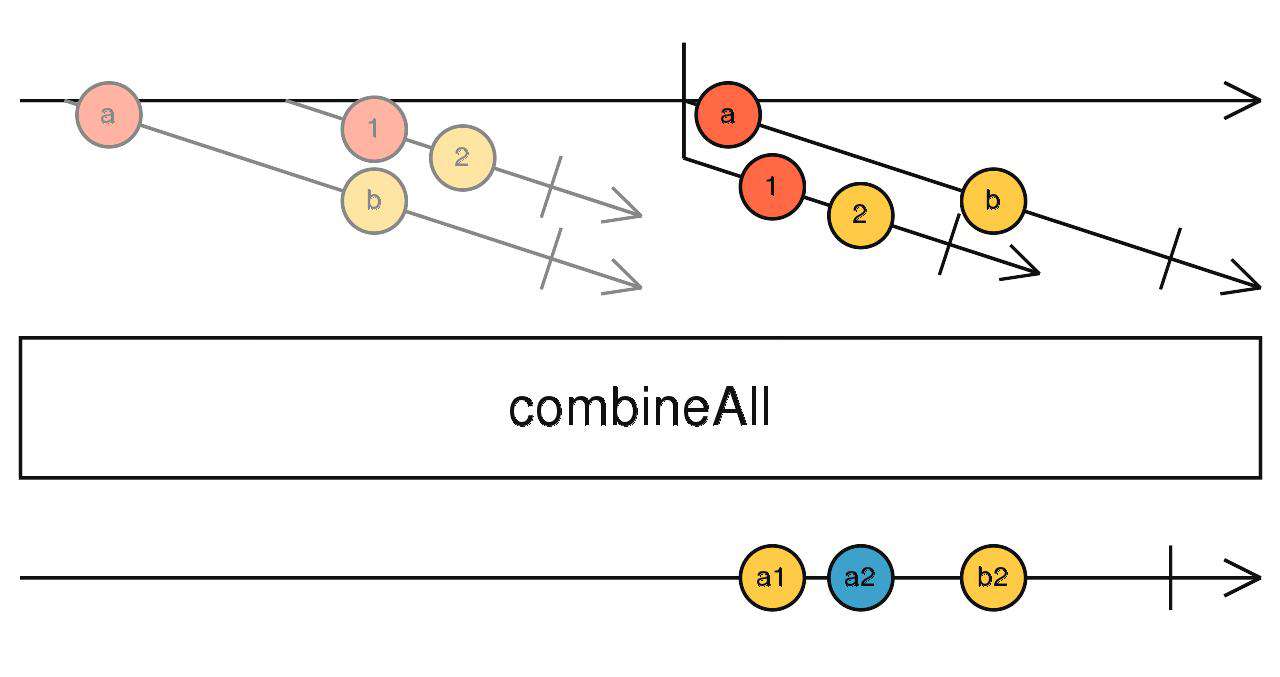
source$.pipe(combineAll())
高阶切换类操作符
switch
切换流 - 喜新厌旧
高阶流每吐出一个流时,就会退订上一个吐出的流,订阅最新吐出的流。
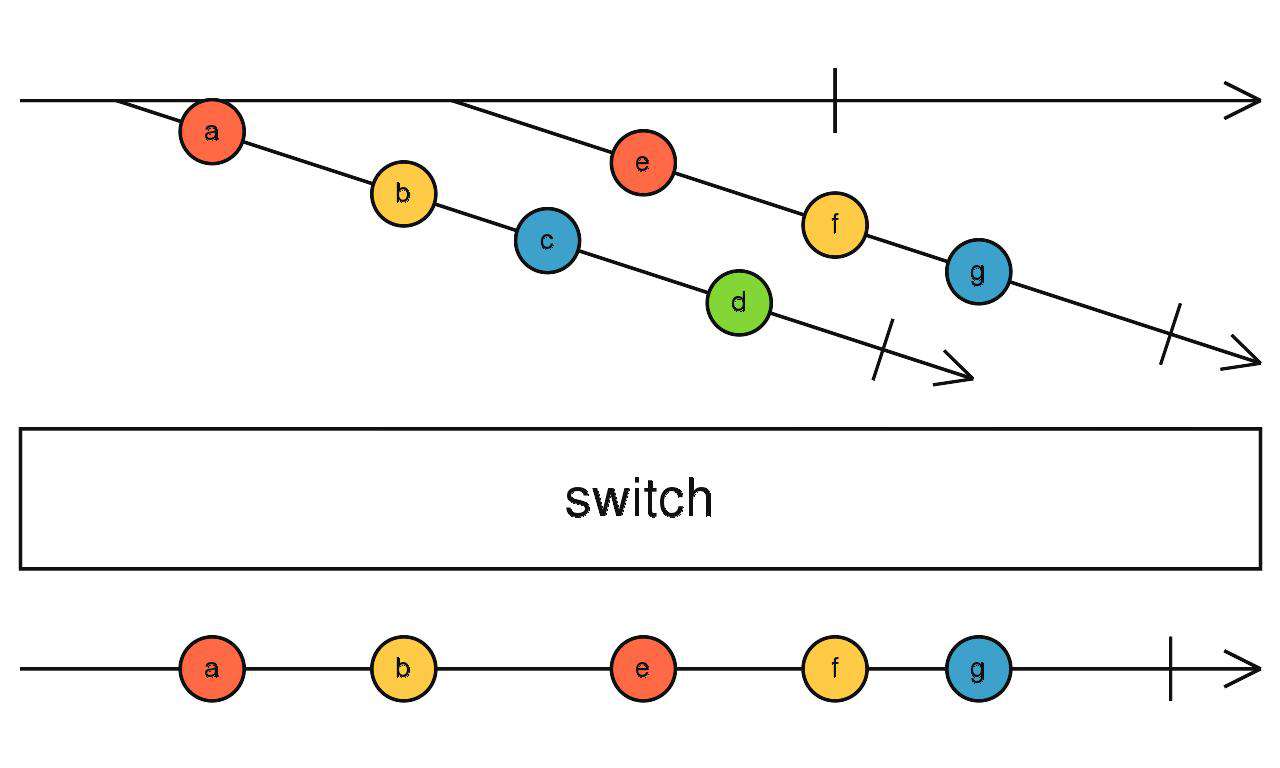
source$.pipe(switch())
exhaust
切换流 - 长相厮守
当高阶流吐出一个流时,订阅它。在这个流没有完成之前,忽略这期间高阶流吐出的所有的流。当这个流完成之后,等待订阅高阶流吐出的下一个流订阅,重复。
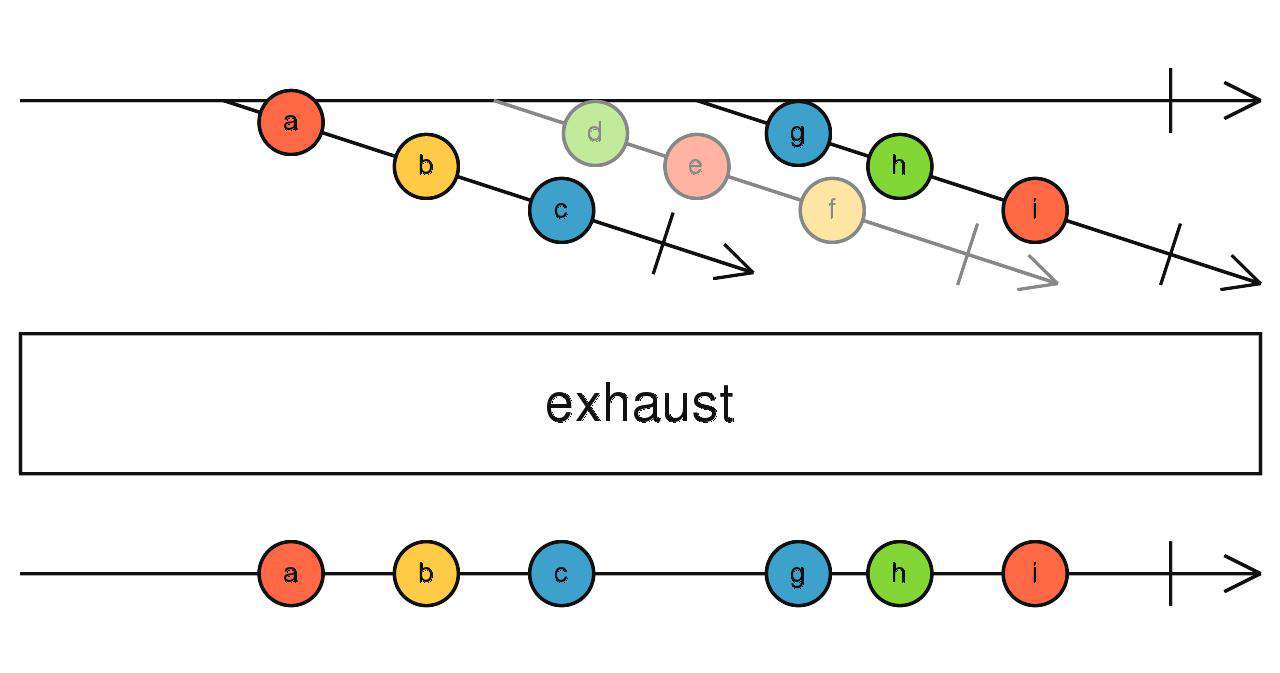
source$.pipe(exhaust())
高阶Map操作符
看完例子,即知定义。
例子
实现如下功能:
mousedown事件触发后,监听mousemove事件
普通实现
mousedown$ = formEvent(document, 'mousedown')
mousemove$ = formEvent(document, 'mousemove')
mousedown$.pipe(
map(() => mousemove$),
mergeAll()
)
- 当
mousedown事件触发后,使用map操作符,将向下吐出的数据转换成mousemove事件流。 - 由于返回的是流而非数据,所以需要使用
mergeAll操作符帮我们将流中的数据展开。 - 这样我们最终接受到的就是
mousemove的event事件对象了。
注:由于只有一个事件流,所以使用上面介绍的任意高阶合并操作符都是一样的效果。
高阶Map实现
mousedown$.pipe(
mergeMap(() => mousemove$)
)
不难看出,所谓高阶map,就是
concatMap = map + concatAll
mergeMap = map + mergeAll
switchMap = map + switch
exhaustMap = map + exhaust
concatMapTo = mapTo + concatAll
mergeMapTo = mapTo + mergeAll
switchMapTo = mapTo + switch
expand
类似于mergeMap,但是,所有传递给下游的数据,同时也会传递给自己,所以expand是一个递归操作符。
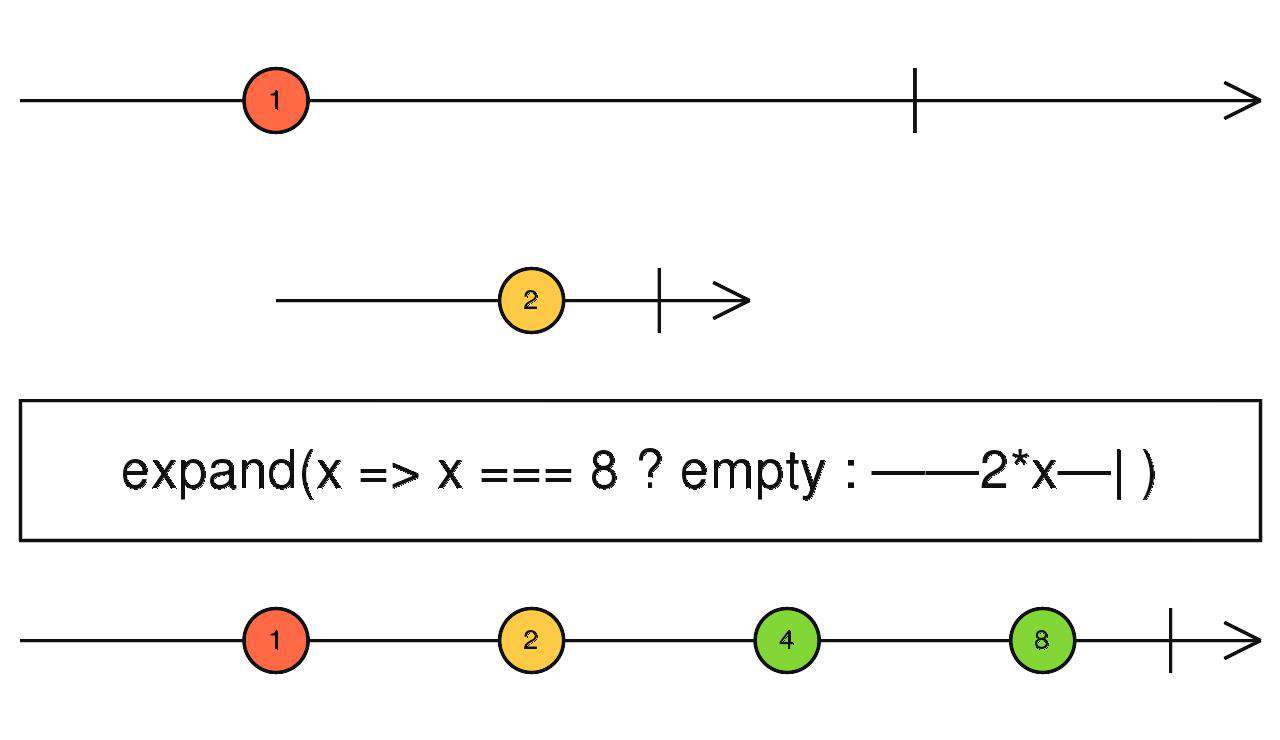
source$.pipe(expand(x => x === 8 ? EMPTY : x * 2))
数据分组
groupBy
输出流,将上游传递进来的数据,根据key值分类,为每一个分类创建一个流传递给下游。
key值由第一个函数参数来控制。
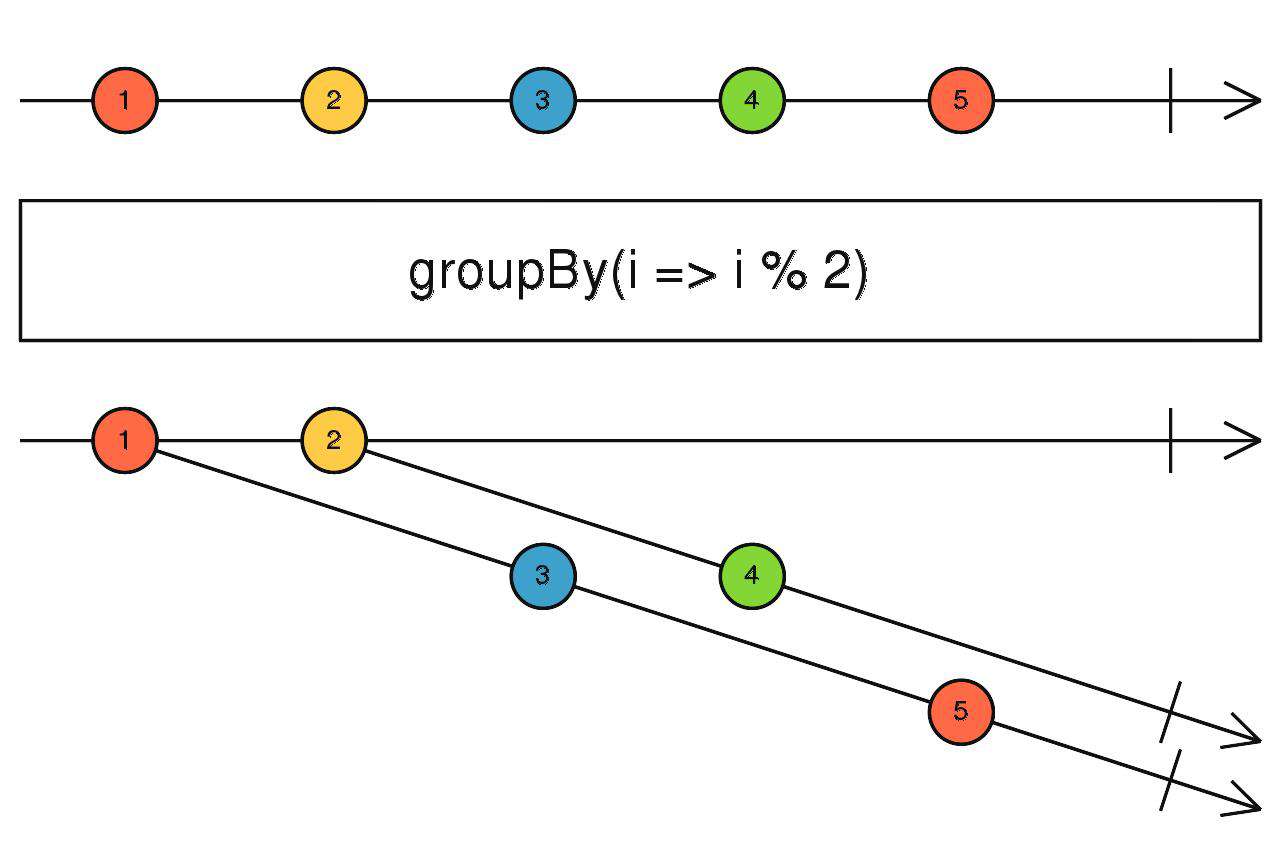
source$.pipe(groupBy(i => i % 2))
partition
groupBy的简化版,传入判断条件,满足条件的放入第一个流中,不满足的放入第二个流中。
简单说:
- groupBy根据key的分类,可能会向下传递N条流。
- partition只会向下传递两条流:满足条件的和不满足条件的。
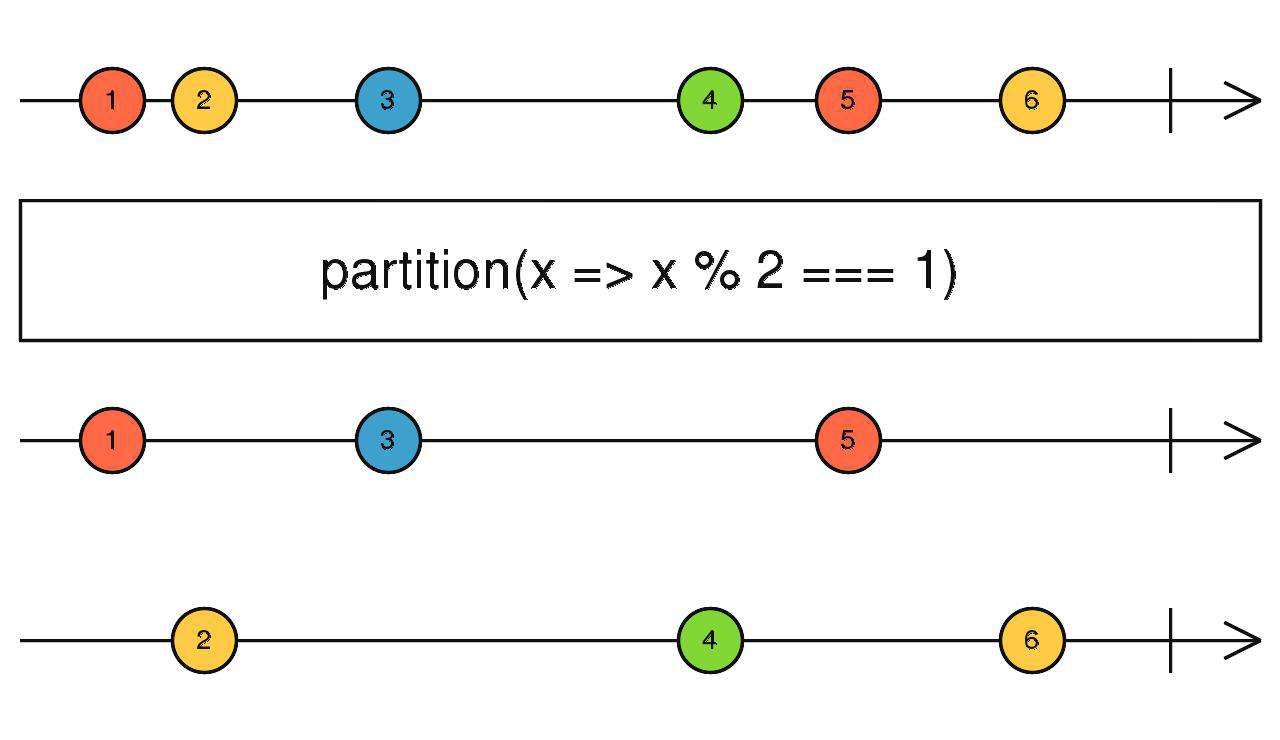
source$.pipe(partition())
结语
以上就是本文的全部内容了,希望你看了会有收获。
如果有不理解的部分,可以在评论区提出,大家一起成长进步。
祝大家早日拿下Rxjs这块难啃的骨头。
参考资料
- 官方文档
- 《深入浅出Rxjs》
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?




发表评论
还没有评论,快来抢沙发吧!