学习材料为 这个
1. 怎么写
js 中的正则表达式包括在两个 / 之间,注意是注释的那个 /。不用(也不能)加引号等修饰。第二个/后面可以接修饰符,不属于表达式。
const reg = /hi/;
const reg = /hi/i; // 后面的 i 是修饰符,表示前面的正则表达式不区分大小写
2. 常用的
2.1 . 和 * 的用法
const reg = /hi.*/;
*不能单独使用,表示的是任意数量的*前面的字符,在该实例中为.,而.匹配的是一个非换行字符。那么.*就是任意个非换行的字符了。
那么以上语法表示的就是,从 hi 开始,直到这一行的结束。
2.1.1 + 的用法
+ 和 * 一样,但是+匹配至少 1 个字符,而*可以匹配 0 个字符。
2.1.2 ? 的用法
? 表示匹配 0 个或者 1 个。
2.2 换行符
就是 \n
2.3 \d 的用法
匹配的是一个数字
2.4 - 的用法
看起来好像是个特殊字符,但其实不是,就是单纯匹配 - 这个字符。
2.5 \s 的用法
\s匹配任意空白字符。
2.6 \w 的用法
\w匹配任意字母或数字或下划线或汉字。
2.7 \b 的用法
\b 非常特殊,它不匹配一个字符,而是匹配一个位置,这个位置为单词的开始或者结束。假设我们有一个字符串 "hi, i'm chi\n"。
const reg = /\bhi\b/; // 匹配开头的 hi(注意不是hi,)
const reg2 = /hi\b/; // 匹配开头的 hi,和 chi 中的 hi(注意不是hi\n)
// 注意\b 匹配的不是标点符号换行等字符,而是一个位置,介乎于单词和标点符号之间。
单词的开始或者结束,不是真正意味上的英文单词,而是当该位置前后字符都不全是 \w 的时候。
2.8 {} 的用法
2.8.1 {a} 精确个数
表示匹配前一个字符的连续 a 个。
比如 const reg = /\d{5}/,意思是匹配连续的 5 个数字。
2.8.1 {a, b} 范围个数
表示匹配前一个字符的连续 a 次到 b 次之间。
const reg = /\d{5,12}/ 表示最少匹配 5 个数字,最多匹配 12 个数字。
2.8.2 {a,} 最少 a 个
和上面的一样,只是没有最大上限。
2.9 ^ 和 $ 的用法
^ 和 $ 表示 字符串 的开头和结尾。也就是说整个输入的开头和结尾。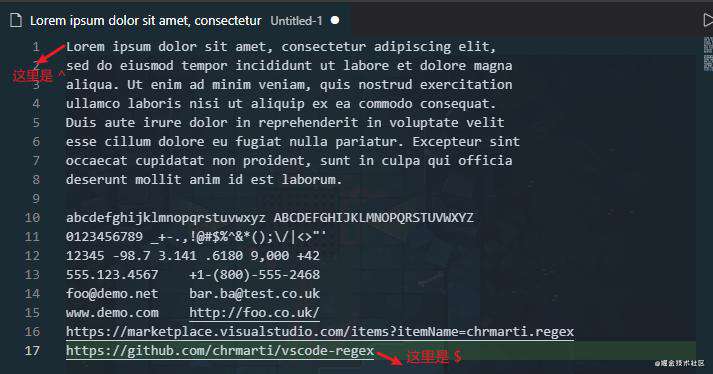 不过如果使用修饰符
不过如果使用修饰符 m 处理多行,^ 和 $ 则可以表示每一行的开头和结束。(为什么用可以,因为字符串的开头和结尾同时也是第一行的开始和最后一行的结尾)
3. 自定义的
如果想选择几个字符其中一个,比如o,y,i,s,h 这几个字符之一怎么办,正则里没有专门匹配这些的表达式。
可以用 [] 来选择,如 [oyish],会选取其中任意一个字符。
也可以使用 - 表示范围,如 [0-9a-zA-Z] 表示数字或者小写字母或大写字母。
[] 里的字符无需转义,可以直接用。不过如果是使用 [0-9]这种范围写法的时候,其实是想匹配 0 或 - 或 9,那么此时需要对 - 进行转义。
时刻记住 [] 只匹配其中的一个字符。
4. 条件
| 表示多种可能的条件。
条件的顺序很重要,满足了前面的条件,就不会去测试后面的条件。
正则表达式表示不了很多东西(如数学意义的大小比较),因此有时候需要很多个 | 来表示各种情况。
5. 分组
可以将一串表达式用 () 括起来,然后接 {} 表示重复这个表达式多次,这样就可以选择重复的多个字符。([]{} 只能选取重复的一个字符)
6. 反义
以上的各种表达式,变成大写就是反义。如 \D 表示非数字。\B 表示非单词开始或者结束的位置。
在 [] 里则用 ^ 表示反义。如 [^0-9a-zA-Z] 表示非数字或字母。
7. 后向引用
当用 () 表示一个分组后,这个表达式匹配的结果可以通过 \1 简单的提取出来,有多个括号是,从前往后依次是 \1,\2。。。以此类推。如:
([0-9]),\1,\1表示用逗号分隔的三个重复数字。
8. 零宽断言
零宽,意思是匹配的是位置而不是字符。
8.1 (?=exp) 语法
如 (?=ing) 匹配的是 ing 前面的位置(不包括 ing)。
使用 \b\w+(?=ing\b) ,则"I'm singing a song" 匹配出的是 "sing"(不是 "singing")
8.2 (?>exp) 语法
如 (?<=un) 匹配的是 un 后面的位置(不包括 un)。
使用 (?<=\bun)\w+\b,则 "This is an unordered set" 匹配出的是 "ordered" (不是 "unordered")
9. 负向零宽断言
零宽断言的反义。分别为(?!exp)和(?!<!exp)。
如 (?!ing) 表示该位置后面不能是 ing。
(?<!un) 表示该位置前面不能是 un。
10. 贪婪与懒惰
正则表达式是默认贪婪匹配,也就是当匹配重复字符的时候。是按照尽量多匹配的原则的。比如 {5,12} ,能匹配 12 个重复字符(串)就不会匹配 11 个重复字符,能匹配 11 个就不会匹配 10 个,以此类推。
以及 * 和 +,即无上限的贪婪匹配,匹配的越长越好。
10.1 懒惰
懒惰顾名思义是贪婪的反义词,也就是匹配的越少越好。
语法就是在各种表示匹配重复的语法(*,+,{})后面加上 ?。
如:
const reg = /[0-9]{2,5}?/; // 匹配 2 个数字
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!