概述
流(Stream)在NodeJs中是个十分基础的概念,很多基础模块都是基于流实现的,扮演着十分重要的角色。流是一个十分难以理解的概念,同时相关的文档又比较缺少,对于NodeJs初学者来说,理解流往往需要花很多时间理解,才能真正掌握这个概念,所幸的是,对于大部分NodeJs使用者来说,仅仅是用来开发Web应用,对流的不充分认识并不影响使用。但是,理解流能够对NodeJs中的其他模块有更好的理解,同时在某些情况下,使用流来处理数据会有更好的效果。
考虑使用NodeJs处理以下这个场景:
没了解NodeJs的流之前,大家可能都会想到以下方案:
以上方法其实有比较多的问题:
-
效率很低,多了读写本地文件的io;
-
容易造成用内存溢出;
流其实能够很好解决像上述这类型的问题,如果大家能够用流的思维去思考,就能很好地解决这个问题。
什么是流?
流的理解
以下是官方定义: 流(stream)是 Node.js 中处理流式数据的抽象接口 。
官方这个定义其实有点难理解,这里的流其实可以分两个角度理解。
-
对于一般开发者来说,流其实可以认为是一种数据集合,可以认为是跟数组一样,只需要关心获取(消费)以及写入(生产)数据就可以了。
-
对于流开发者来说(使用stream模块创建一个新实例),关注的是如何实现这个抽象接口,通常需要关注两点,资源目标是什么以及如何操作数据。一旦确定资源目标之后,就需要根据流的状态以及资源目标的状态做相应的操作。
流的类型
流的类型有4种:
-
可读流(Readable)
-
可写流(Writable)
-
双工流(Duplex)
-
转换流 (Transform)
其中可读流以及可写流是基础,理解这两个流之后,就比较容易裂解另外两个流了。
可读流
可读流是对提供数据的来源的一种抽象。
可读流的实现
所谓的实现可读流就是实现 _read 方法, _read 方法定义了从哪里用怎样的方式把数据push到缓冲池中,这里要注意的是,push的数据并不是直接给到消费者消费的,而是首先经过一个缓冲池,当缓冲池满了的时候(超出highWaterMark),会产生“背压”,调用push的时候返回false。
class MyReadable extends Readable {
/**
* @param size 指定读取的大小
*/
_read(size?:number) {
const data = getDataFromSomeWhere();
// console.log('source:'+data)
const res= this.push(data || null);
// res will be false if over highWaterMark
// push a null data means finished
}
}
可读流模式
可读流有读取两种模式:流动模式(flowing)或暂停模式(paused)。
暂停模式
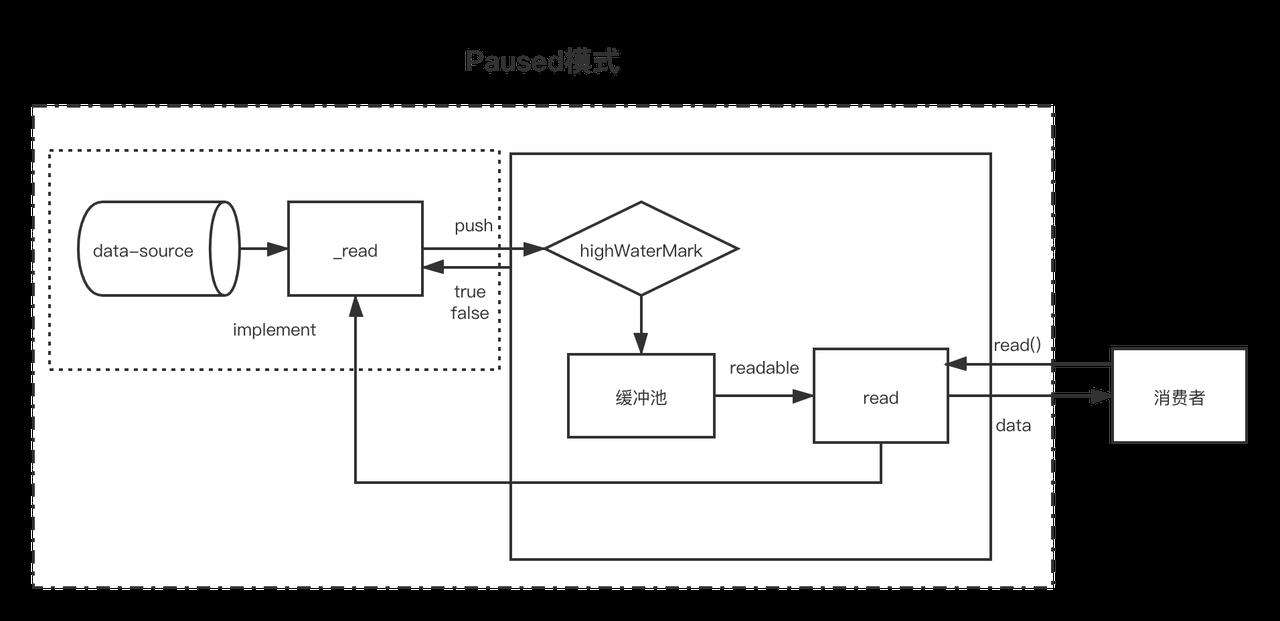
暂停模式下,一个可读流读创建时,模式是暂停模式,创建后会自动调用_read方法,把数据从数据源push到缓冲池中,直到缓冲池中的数据达到了浮标值。每当数据到达浮标值时,可读流会触发一个 " readable " 事件,告诉消费者有数据已经准备好了,可以继续消费。
一般来说, 'readable' 事件表明流有新的动态:要么有新的数据,要么到达流的尽头。所以,数据源的数据被读完前,也会触发一次'readable'事件;
消费者 " readable " 事件的句柄中,通过 stream.read(size) 主动获取获取缓冲池中的数据。
demo:
import { Readable } from 'stream';
class Source {
private data :string[] =Array(10).fill('byte');
public getData() {
return this.data.pop()
}
}
class MyReadable extends Readable {
source=new Source()
_read() {
const data=this.source.getData()
// console.log('source:'+data)
this.push(data||null);
}
}
const myReadable = new MyReadable();
myReadable.setEncoding('utf-8')
myReadable.on('readable',()=>{
console.log('readable')
let data=''
while(data=myReadable.read()){
console.log(data)
}
})
myReadable.on('end',()=>{
console.log('end')
})
流动模式

所有可读流开始的时候都是暂停模式,可以通过以下方法可以切换至流动模式:
-
添加 "
data" 事件句柄; -
调用 “
resume”方法; -
使用 "
pipe" 方法把数据发送到可写流
流动模式下,缓冲池里面的数据会自动输出到消费端进行消费,同时,每次输出数据后,会自动回调_read方法,把数据源的数据放到缓冲池中;直到流动模式切换至其他暂停模式,或者数据源的数据被读取完了( push(null) );
可读流可以通过以下方式切换回暂停模式:
-
如果没有管道目标,则调用
stream.pause()。 -
如果有管道目标,则移除所有管道目标。调用
stream.unpipe()可以移除多个管道目标。
demo:
import { Readable } from 'stream';
class Source {
private data: string[] = Array(10).fill('byte');
public getData() {
return this.data.pop();
}
}
class MyReadable extends Readable {
source = new Source();
/**
*
* @param size 指定读取的大小
*/
_read(size?:number) {
const data = this.source.getData();
// console.log('source:'+data)
this.push(data || null);
}
}
const myReadable = new MyReadable();
myReadable.setEncoding('utf-8');
myReadable
.on('data', chunk => {
console.log(chunk);
})
.on('end', () => {
console.log('end');
});
两种模式的区别
这里的模式其实对消费者来说的,采用哪一种模式消费从流种读取的数据。两者的区别是:
-
在流动模式中,数据自动从底层系统读取,并通过 EventEmitter 接口的事件尽可能快地被提供给应用程序。
-
在暂停模式中,必须显式调用 stream.read() 读取数据块。
pipe
可读流对象有个 pipe 方法,pipe方法中接受一个可写流为参数,返回的也是这个目标可写流。使用流pipe方法,可读流会自动切换至流动模式。
可写流
可写流是对数据要被写入的目的地的一种抽象。 所谓实现可写流,就是实现可写流的_write方法,就是当生产者把数据输入时,怎么把这些数据写到目的地中。
import {Writable} from 'stream'
class MyWritable extends Writable{
/**
* @param str 每次写入的数据
* @param encoding 编码
* @param cb 回调,每次写入数据成功需要回调这个参数,如果不回调,不会自动清空缓冲队列。
*/
_write(str:string,encoding:string,cb:(err?:any)=>void){
console.log(str)
console.log(encoding)
cb()
}
}
相对可读流来说,可写流要简单一些。
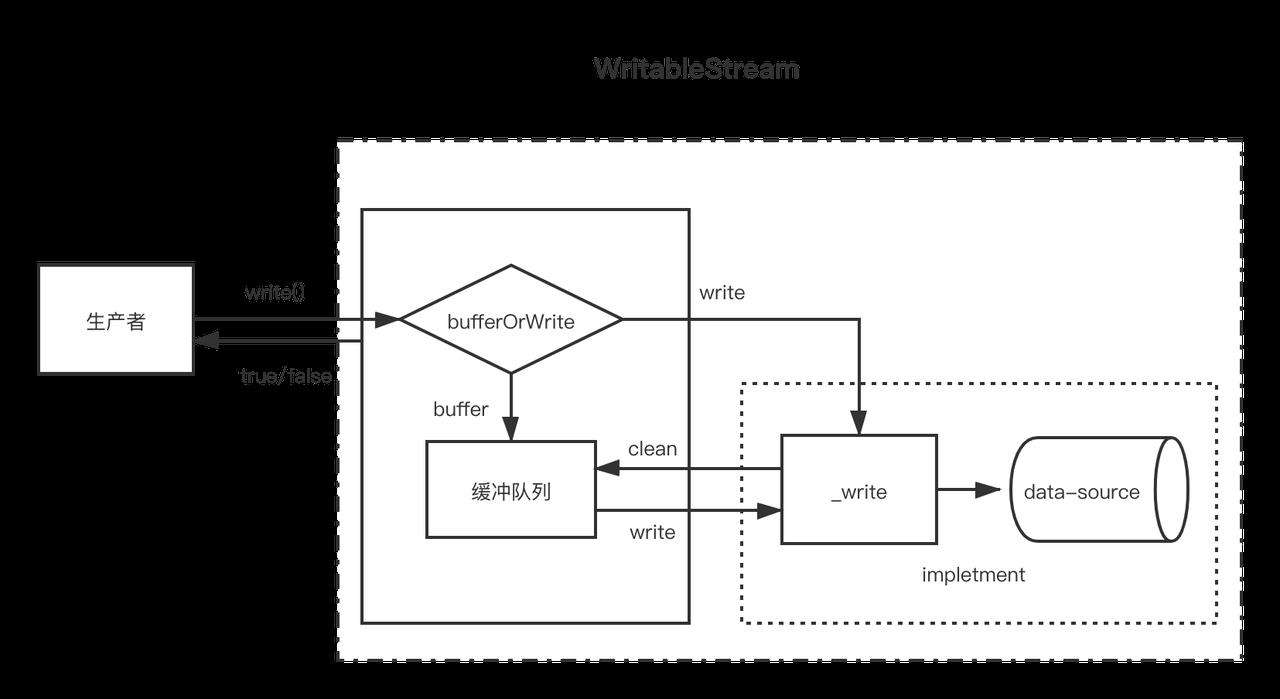 当生产者调用write(chunk)时,内部会根据一些状态(corked,writing等)选择是否缓存到缓冲队列中或者调用_write,每次写完数据后,会尝试清空缓存队列中的数据。如果缓冲队列中的数据大小超出了浮标值(highWaterMark),消费者调用write(chunk)后会返回false,这时候生产者应该停止继续写入。
当生产者调用write(chunk)时,内部会根据一些状态(corked,writing等)选择是否缓存到缓冲队列中或者调用_write,每次写完数据后,会尝试清空缓存队列中的数据。如果缓冲队列中的数据大小超出了浮标值(highWaterMark),消费者调用write(chunk)后会返回false,这时候生产者应该停止继续写入。
那么什么时候可以继续写入呢?当缓冲中的数据都被成功_write之后,清空了缓冲队列后会触发 'drain' 事件,这时候生产者可以继续写入数据。
当生产者需要结束写入数据时,需要调用 stream.end 方法通知可写流结束。
demo
import {Writable} from 'stream'
class MyWritable extends Writable{
/**
*
* @param str 每次写入的数据
* @param encoding 编码
* @param cb 回调,每次写入数据成功需要回调这个参数,如果不回调,不会自动清空缓冲队列。
*/
_write(str:Buffer,encoding:string,cb:(err?:any)=>void){
console.log(str.toString('utf8'))
console.log(encoding)
cb()
}
}
const myWritable = new MyWritable();
console.log(myWritable.write('hello world','utf8'))
console.log( myWritable.write('hello world1','utf8'))
双工流
在理解了可读流与可写流后,双工流就好理解了,双工流事实上是同时实现流可写流与可读流。
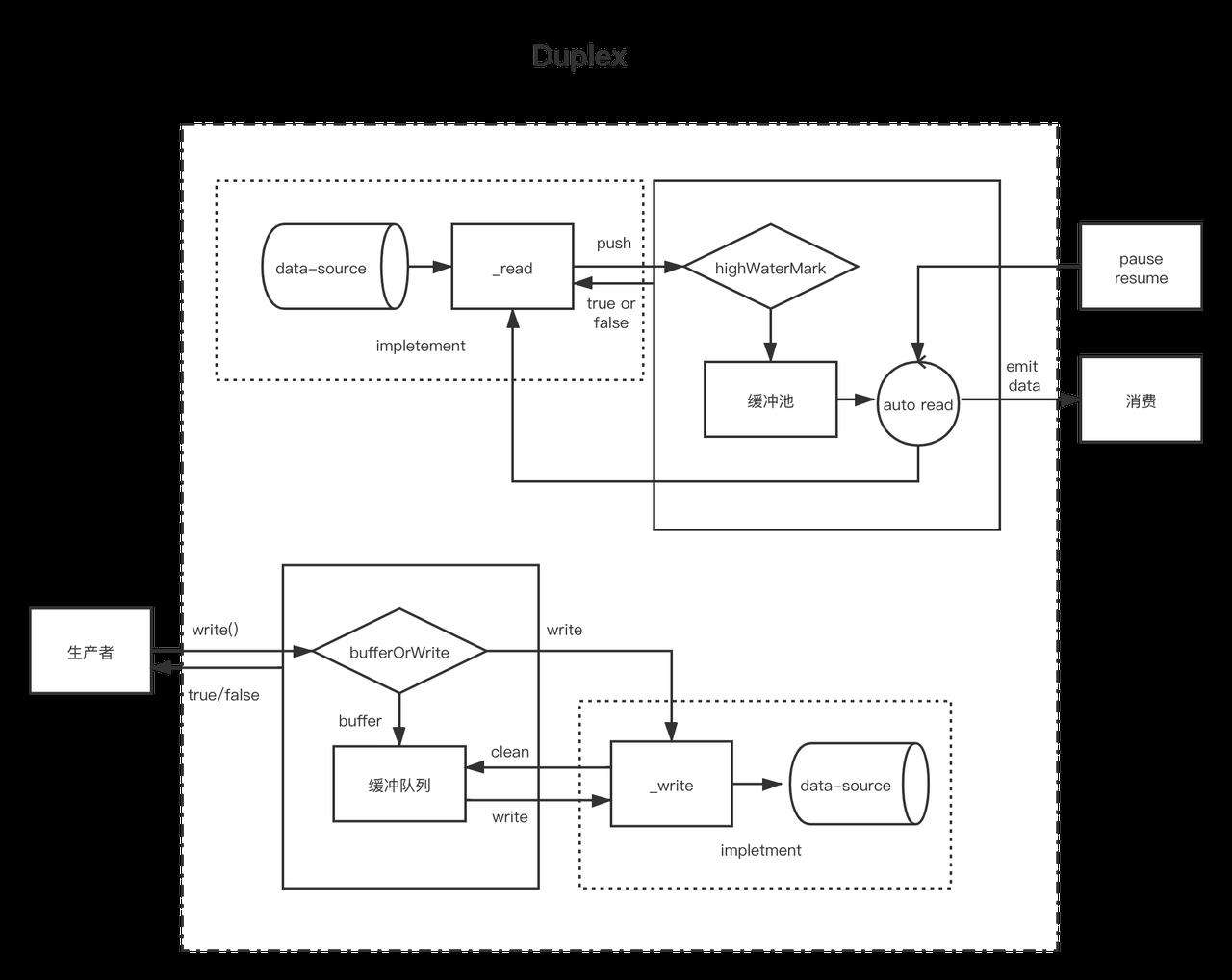 这里需要注意的是,双工流中,独立维护两个缓冲区,同时可读可写流的数据源不一定是同一个目标。
这里需要注意的是,双工流中,独立维护两个缓冲区,同时可读可写流的数据源不一定是同一个目标。
demo
import { Duplex } from 'stream';
class MyDuplex extends Duplex {
readEnd = false;
_read() {
if (!this.readEnd) {
this.push('read');
this.readEnd = true;
}
this.push(null);
}
_write(chunk, encoding, callback) {
console.log(chunk.toString('utf8'));
callback();
}
}
const duplex = new MyDuplex();
duplex
.on('data', chunk => {
console.log(chunk.toString());
})
.on('end', () => {
console.log('read end');
});
duplex.write('write');
转换流
与双工流一样,转换流(Transform)同时实现可写流(_write)与可读流(_read),只不过,这里的数据流输入与输出有关联的。
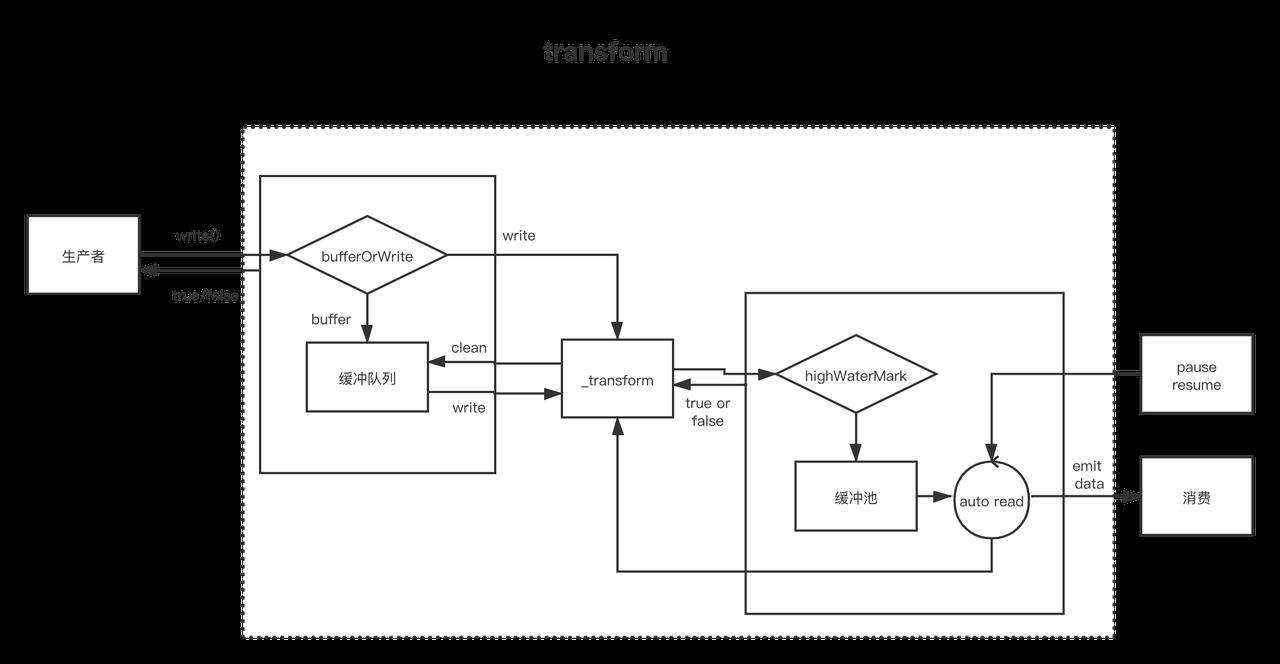 这里要注意的是,这里的输入输出虽然是有关联,但是并不一定是一一对应关系,或者不一定是同步的。
比如,在压缩的时候,有可能对多个写入压缩成一个chunk,这时候指提供一个压缩后的chunk给消费者消费。
另外,也有可能是一次写入会被输出多个chunk,比如转换的时候,把输入的1kb数据,放大至1M多次push到缓冲中,如果缓冲池超出了浮标值,就会造成“背压”。
这里要注意的是,这里的输入输出虽然是有关联,但是并不一定是一一对应关系,或者不一定是同步的。
比如,在压缩的时候,有可能对多个写入压缩成一个chunk,这时候指提供一个压缩后的chunk给消费者消费。
另外,也有可能是一次写入会被输出多个chunk,比如转换的时候,把输入的1kb数据,放大至1M多次push到缓冲中,如果缓冲池超出了浮标值,就会造成“背压”。
有机智的同学可能会发现,这个转换流既是可写流同时又是可读流,是不是可以结合上面提到的可读流的pipe方法,是不是可以进行无限的管道接驳? 确实是这样的,转换流以及双工流都可以进行管道的接驳。
readabl
.pipe(tranform1)
.pipe(tranform2)
.pipe(tranformN)
一些常用事件与方法
流内部维护了一些列状态,不同的流在不同的阶段会发生状态改变, 由于流都是继承于 EventEmiter,当状态发生改变时,会触发相关的事件。
| 可读流 | 可写流 | 事件 | - data | - drain | 实例方法 | - read() | - write() | 需要实现的方法 | _read | _write |
|---|
NodeJs内置流
NodeJs中很多,模块是都是使用流实现的。
| readable | writable | duplex | transform | - Http client response | - Http client request | Tcp socket | crypto |
|---|
有哪些应用?
- 流式渲染chunk传输
demo
import { createServer } from 'http';
import { Readable } from "stream";
const source=[
`
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Test</title>
<script src="https://unpkg.com/react-dom@16.13.1/umd/react-dom.production.min.js"></script>
</head>
`,
`
<body>
<div>chunk1</div>
`,
` <div>chunk2</div>
</body>`,
`</html>`
]
function getRS(){
let hasRead=false;
const dataSource=[...source]
return new Readable({
read(){
if(hasRead){
return
}
hasRead=true
dataSource.forEach((d,index)=>{
setTimeout(() => {
if(index===dataSource.length-1){
this.push(null)
}else{
this.push(d)
}
}, index*1000);
})
}
})
}
const server = createServer((req, res) => {
let reqData;
const readable= getRS();
req.on('data', chunk => {
reqData += chunk;
});
req.on('end', () => {
console.log('req end')
res.statusCode=200
readable.pipe(res);
readable.on('end',()=>{
console.log('end')
})
});
});
server.listen(3000);
-
大文件读取
-
大文件上传下载
-
数据的加解密
-
数据压解
流有哪些不足?
- 文档不够友好
由于Stream模块比较难理解,很多程度上是因为NodeJs这块不够友好,官网上仅仅是Api文档,重要知识点 比较零碎,不成系统,对于一些细节的实现,往往需要看源码才能弄清楚,这个对新手来说不太友好。
- 对流的组合不够强大
目前可读流只有pipe方法,不够强大,某些场景下需要手动做比较多的额外工作,比如,想要从两个流中消费到以一个地方。熟悉RX的同学可能知道,Observable对象之间的关系可能有很多种,Rx有相关的方法去组合不同的Observable,目前社区上也有相关的 工具 ,可以把Stream转为Rx对象,方法处理数据。
- 使用不当可能存在性能问题
由于流内部会维护一个缓存区,虽然缓冲区默认大小为16Kb,但是某些情况下会自动扩容,如果流没有及时消费或者没有被终止,会有OOM的风险。 另外,流的读写数据是分多次的,如果往数据源中读写是有额外开销的话,这部分开销会随着读写次数的线性增加。
总结
本文尝试从宏观一点介绍NodeJs中的流,让大家对流有个系统点的认识,还有很多细节没有讲解,有兴趣的话,建议可以看看NodeJs中关于流的源码。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!