一、内存管理
1.内存为什么需要管理:
function fn () {
arrList = [];
arrList[100000] = 'lg is a coder';
}
fn();

上面的代码运行, 就会造成如图所示的内存泄漏;
2.内存管理介绍:
-
内存: 由可读写的单元组成, 表示一片可操作空间;
-
管理: 由人主动去操作一片空间的申请、使用和释放;
-
内存管理: 开发者主动申请空间、使用空间、释放空间;
-
管理流程:申请 -> 使用 -> 释放;
JavaScript中的内存管理: 由于JavaScript中没有提供相对应的内存操作API, 所以 JavaScript不能像C或者C++那样, 由开发者主动调用API, 去管理内存;
//申请空间
//JS执行引擎遇到变量定义语句的时候自动分配空间;
let obj = {};
//使用空间
obj.name = 'lc';
//释放空间
obj = null;
二、垃圾回收与常见的GC算法
1.垃圾回收:
-
JavaScript 中的垃圾:
- JavaScript 中的内存管理是自动的: JavaScript 执行引擎遇到变量定义语句的时候自动分配空间;
- 代码中国的对象不再被引用时是垃圾;
- 代码中的对象不能从根上访问到时是垃圾;
-
JavaScript 中的可达对象:
- 可以访问到的对象就是可达对象(引用、作用域链);
- 可达的标准就是从根出发时否能够找到;
- JavaScript 中的根可以理解为全局变量对象;
//引用
let obj = { name: 'xm' };//小明的对象空间被 obj 引用了
let ali = obj; //小明的对象空间被 ali 引用了;
obj = null; //小明的对象空间 obj 的引用被释放了, 但是 ali 的引用还在, 所以小明的对象空间依然是可达的;
console.log(ali); //{ name: 'xm' }
- JavaScript 的垃圾回收: JavaScript 引擎找到垃圾, 对垃圾进行回收和释放;
function objGroup (obj1, obj2) {
obj1.next = obj2;
obj2.prev = obj1;
return {
o1: obj1,
o2: obj2
}
}
let newObj = objGroup({ name: 'obj1' }, { name: 'obj2' });
console.log(newObj);
- 在代码中会存在一些对象引用的关系, 我们从根开始查找, 按照一些链条, 终究会找到某些对象; 如果找到某些对象的路径(链条)被破坏掉了(上诉代码中如果删除 newObj 的 o1 属性、删除 newObj 中 o2 的 prev 属性), 我们是没有办法找到对象的(obj1), 这个对象就会被 JavaScript 引擎当做垃圾, 被 JavaScript 引擎回收;
上诉这段话可以用如下图来表示:
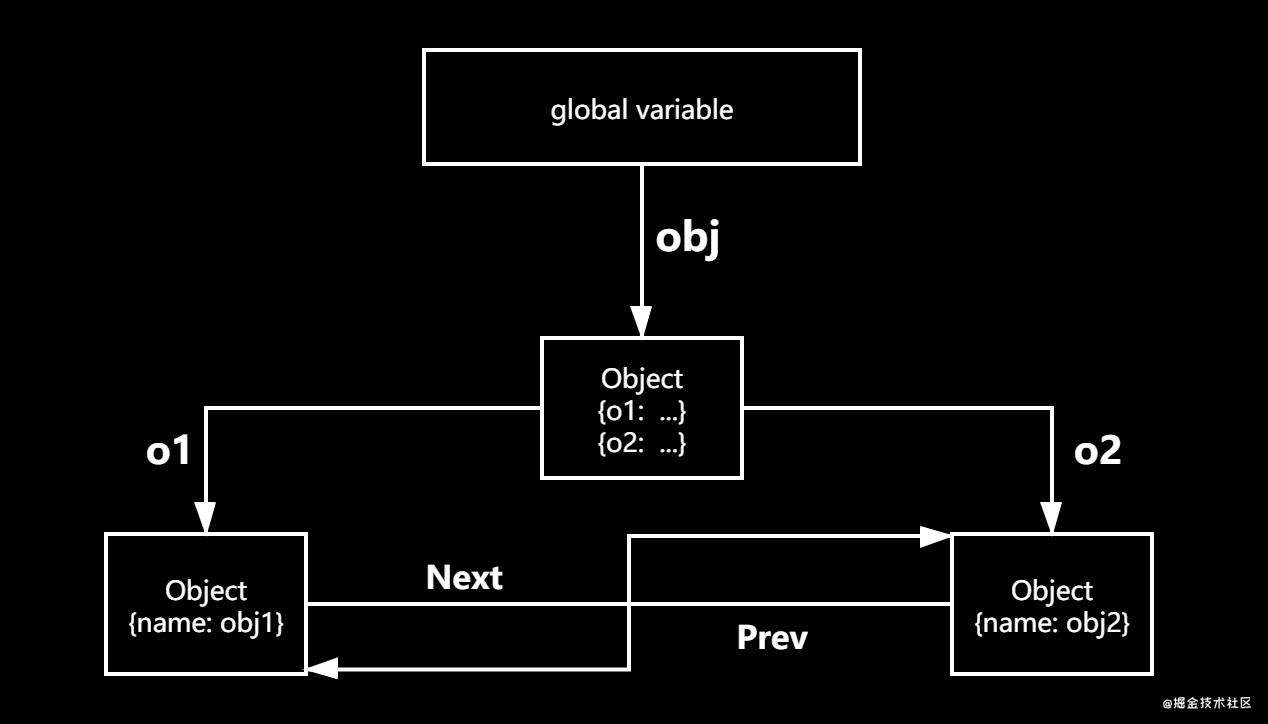
我们从根出发开始查找, 通过某些链条找到某些对象;
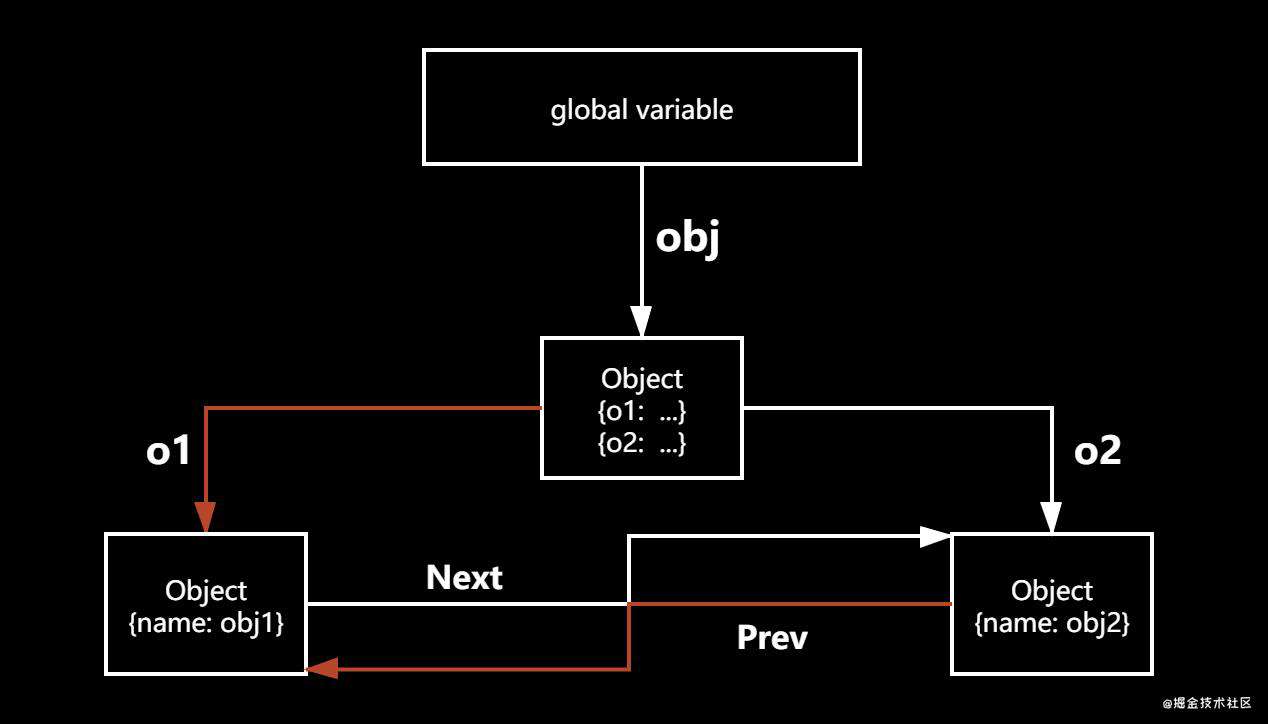
当找到某些对象的路劲(链条)被破坏掉, 比如 删除 newObj 的 o1 属性、删除 newObj 中 o2 的 prev 属性, 我们就没有办法找到该对象, 上图当中的 obj1;
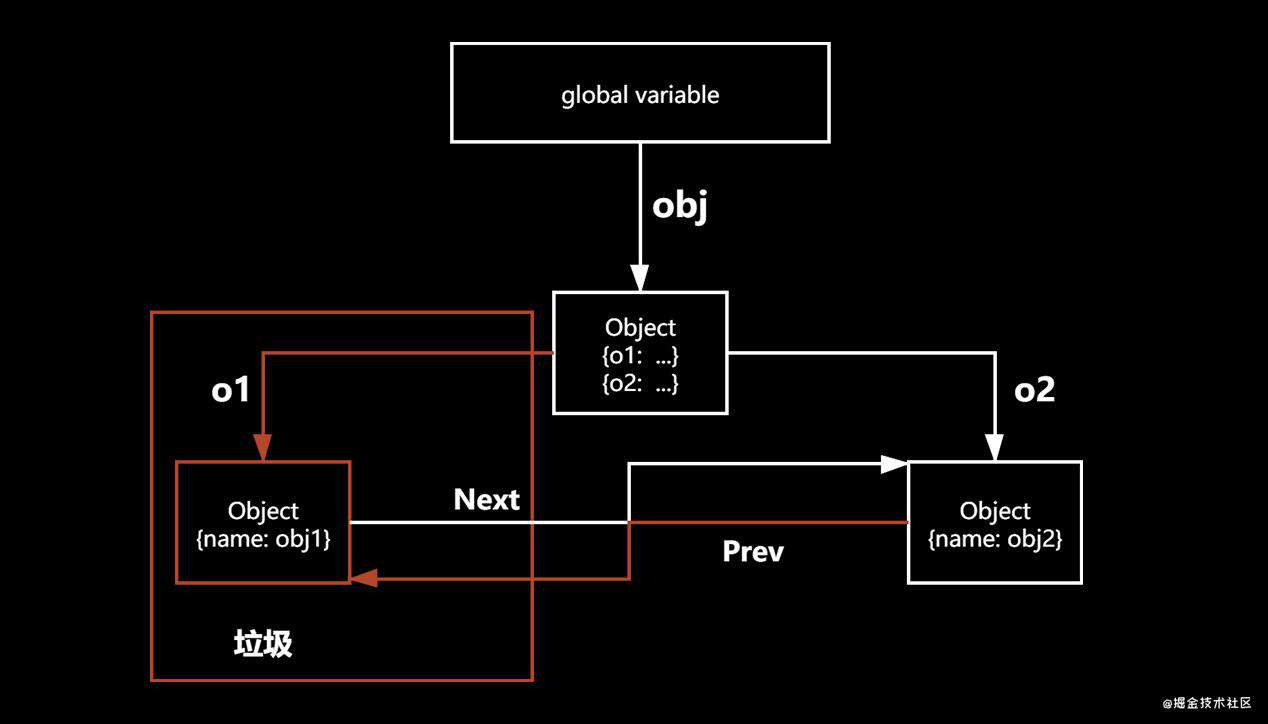
此时 obj 就不是可达的, 就会被当做垃圾, 被回收;
2.GC算法
-
GC定义预作用:
- GC 就是垃圾回收机制的简写;
- GC 可以找到内存中的垃圾、并释放和回收空间;
-
GC 里的垃圾是什么:
- 程序中不在需要使用的对象
function func () { name = 'lg'; return `${name} is a coder`; } func(); 上诉代码当程序调用完成后, 从我们的需求考虑, name 是被当做垃圾回收的;
- 程序中不能在访问到的对象
function func () { const name = 'lg'; return `${name} is a coder`; } func(); 上诉代码中, 从程序运行角度上去考虑, func 中定义的 name不能被访问到, 会被当做垃圾回收的;
-
GC 算法是什么
-
GC 是一种机制, 垃圾回收器完成具体的工作
-
工作的内容就是查找垃圾、释放空间、回收空间
-
算法就是工作是查找和回收以及释放所遵循的规则,好比:一些数学的计算方式;
-
常见的GC算法名称
-
引用计数: 通过一个数字来判断当前对象是不是一个垃圾
- 核心思想: 设置引用数, 判断对象引用数是否为0, 当对象的引用数为0时, GC 就开始工作, 将其所在的对象空间进行回收和释放再使用;
-
引用计数器: 因为有引用计数器的存在, 导致引用计数算法在执行效率上和其他 GC 算法有所差别;
- 规则: 当一个对象它的引用关系发生改变时, 引用计数器就回去修改当前对象的引用数字;
const user1 = {age: 11}; const user2 = {age: 22}; const user3 = {age: 33}; const nameList = [user1.age, user2.age, user3.age]; //代码运行完成后, user1, user2, user3 还在被nameList 引用, 所以引用数字不为 0; function fn () { const num1 = 1; const name2 = 2; } fn();//当 fn 调用完成后, fn 中的 num1、num2的引用数字为0, 会被当做垃圾回收;-
引用计数算法的优点:
- 发现垃圾是立即回收: 因为他可以通过引用数字书否为0, 来判断是否为垃圾;
- 可以更大限度减少程序暂停(卡顿): 程序在运行过程中, 必然会对内存有所消耗, 而执行平台的内存肯定是有上限的, 所以内存肯定有占满的时候, 这样就会引起程序暂停; 由于引用计数算法是时刻监控着对象的引用数字的, 当对象的引用数字为0是, 引用计数算法就会回收该对象释放空间, 所以最大程度上减少程序的暂停;
-
引用计数算法的缺点:
- 无法回收循环引用的对象:
function fn () { const obj1 = {}; const obj2 = {}; obj1.name = obj2; obj2.name = obj1; return 'lg is a coder'; } fn();//当函数调用完后, 在全局是找不到 obj1 和 obj2 的, 应该被回收; 但运用引用计数算法, obj1 和 obj2 的引用数字不为0, 所以引用计算算法不认为是垃圾, 不能被回收, 就会造成内存的浪费;- 时间开销大: 因为当前的引用计数器需要去维护一个数字的变化, 在这种情况下, 他要时刻的监控对象引用数字的是否需要修改; 对象的变化需要时间, 对象的引用数字修改也需要时间;
-
标记清除: 在GC 工作的时候, 给活动对象添加标记, 以此来判断该对象是否是垃圾;
- 核心思想: 分标记和清除两个阶段完成;
- 标记阶段: 遍历所有对象找到可达对象, 对可达对象进行标记;
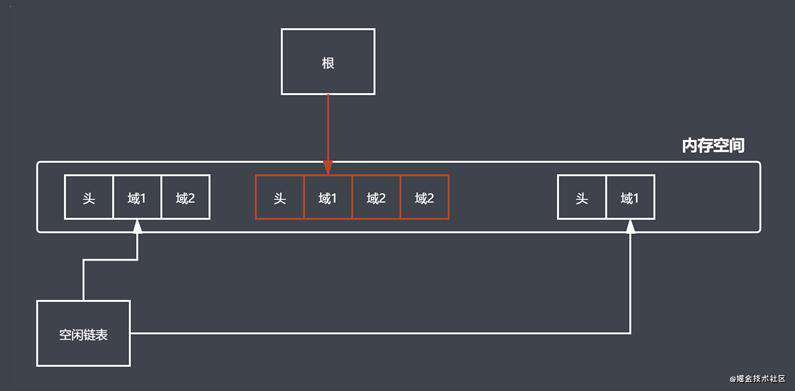
- 清除阶段: 遍历所有对象, 找到没有标记的对象, 进行清除操作; 在这个阶段中也会把标记阶段所做的标记清除, 保证 GC 下一次能正常的工作;
- 清除操作后就回收相应的空间, 将回收的空间放到空闲列表上面, 方便后续的程序可以在空闲列表申请空间使用;
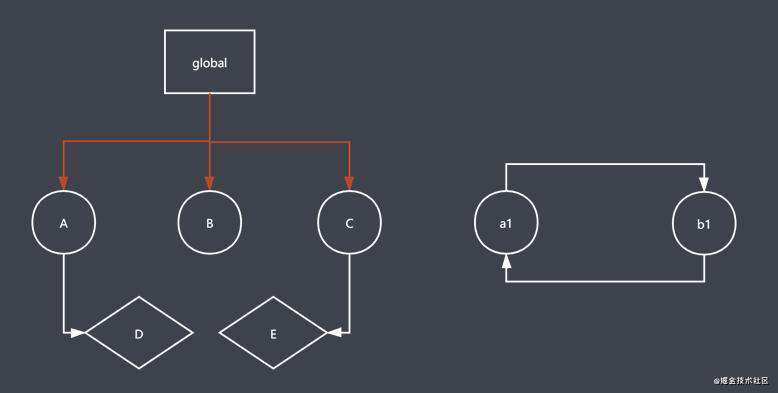
在全局可以找到 A、B、C 三个可达对象,标记清除算法就会给A, B, C 做标记
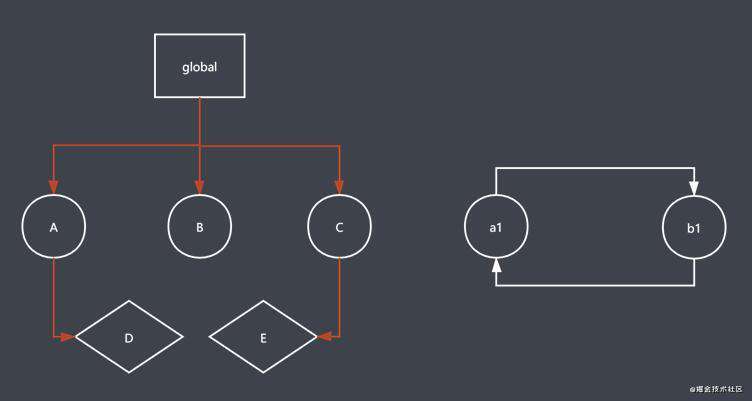
发现 A、B、C 下面还有子对象, 通过递归的方式继续往下找, 可以找到 D、E两个可达对象;标记清除算法就会给 D, E 做标记;
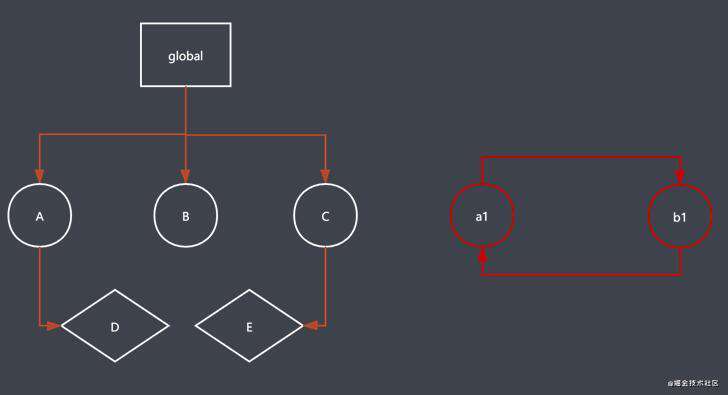
a1 和 b1 可能是在局部作用域中, 当前局部作用域执行完成后, 空间就被回收了, a1 和 b1 就不是可达的, 标记清除算法就不会给 a1 和 b1 做标注, 当GC 运行到清除阶段时, 就会把 a1 和 b1 当垃圾回收;
最终 标记清除算法 会把 回收的空间 直接放在空闲列表上面, 方便后面的程序直接在这里申请空间使用;
-
标记清除算法的优点:
可以去解决对象循环引用的回收操作, 如上图所示, a1 和 b1 循环调用, 当a1 和 b1 的作用域中的程序执行完成后, a1 和 b1 就是不可达对象, 标记清除算法就会把 a1 和 b1 回收了; 这就解决了引用计数算法不能回收循环引用对象的缺点;
-
标记清除算法的缺点:
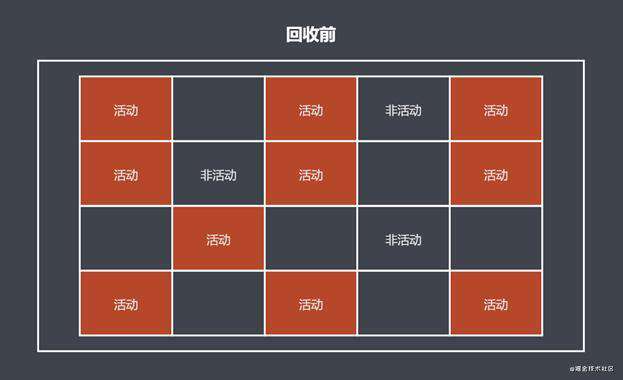
标记清除算法标记阶段: 会去对中间的可达对象空间进行标记, 左右两边的不可达对象是不进行标记的; 标记清除算法清除阶段: 会去对左右两边的不可达对象空间进行空间回收, 放到空闲列表上;
- 上图所示: 回收的空间的地址是不连续的; 由于不连续, 所以回收的空间分散在各个角落, 新申请空间如果和所有的回收空间大小都不匹配, 这样就可能造成空间的浪费; 这就叫: 空间碎片化;
- 不会立即回收垃圾对象;
-
标记整理: 与标记清除很类似, 在后续回收的过程中会做出与标记清除不一样的事情;
-
实现原理:
- 标记整理算法可以看做是标记清除算法的增强算法;
- 标记整理算法的标记阶段和标记清除算法一致;
- 标记整理算法的清除阶段会先执行整理, 移动对象位置, 让回收空间的地址连续;
在标记阶段: 去对可达对象进行标记;
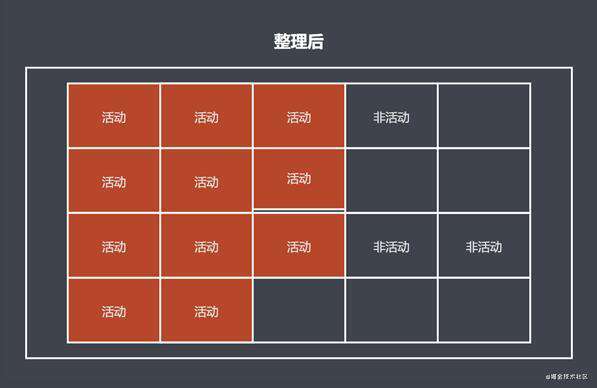
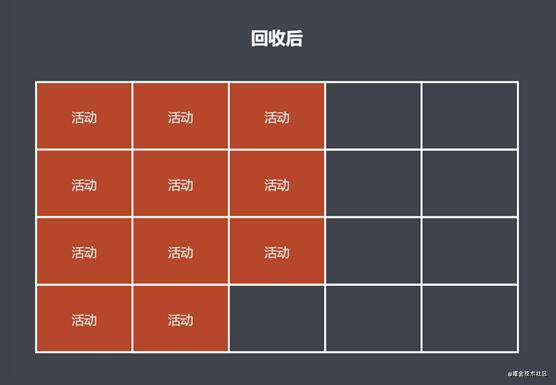
在清除阶段: 先对回收空间进行整理, 然后再去进行对回收空间进行空间回收释放, 放到空闲列表上;
- 标记整理的优点: 减少碎片化空间;
- 标记整理的缺点: 不会立即回收垃圾对象;
-
-
分代回收:
-
三、V8 的垃圾回收机制
1. 认识V8
- V8 是一款主流的 JavaScript 执行 引擎;
- V8 采用即时编译: 可以将源码翻译成环境可以直接执行的机器码;
- V8 的内存是设有上限的: 在 64 位的操作系统中不超过 1.5G 的, 在 32 位的操作系统中不超过800M;
- 原因1: V8 本生就是为了浏览器而制造的, 现有的内存大小对于网页来说是足够使用了;
- 原因2: V8 中采用的垃圾回收机制也决定了采用这样的设置是合理的,(官方统计: 垃圾达到了1.5G, 采用增量标记算法进行垃圾回收需要50ms, 不采用增量标记算法进行垃圾回收, 需要1s钟, 从用户体验的角度来说, 1s钟已经算是很长的时间了);
2. V8 垃圾回收策略
- 前置描述: 在程序的使用过程中, 会用到很多的数据, 这些数据我们可以分为原始类型数据和对象类型数据; 对于原始类型数据而言: 都是由程序的语言自身来进行控制的; 所以这里所说的回收, 主要还是指的是当前存活在我们堆区里的对象类型数据; 因此 这个过程我们是离不开内存操作的, 在 V8 中是对内存设置了上限的, 我们很想知道 V8 的垃圾回收策略;
- 采用的是分代回收的思想: 把我们当前的内存空间去按照一定的规则分为两类;
- 内存分为新生代存储区 和 老生带存储区;
- 针对不同的存储区采用不同的高效的GC 算法进行垃圾回收;
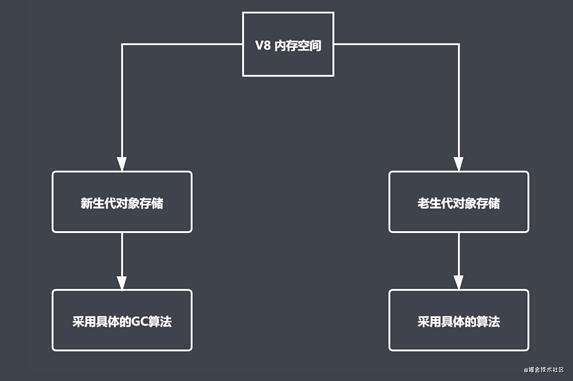
- V8 中常用 GC 算法: 分代回收、空间复制、标记清除、标记整理、标记增量
3. V8 对新生代对象的回收:
-
V8 内存分配

- V8 内存空间一分为二: 左侧是新生代存储区, 右侧为老生代存储区;
- 小空间用于存储新生代对象(64位: 32M/ 32位: 16M )
- 新生代对象指的是存活时间较短的对象:
-
新生代对象回收实现
-
回收过程采用复制算法 + 标记整理算法;
-
首先会将新生代存储区分为两个等大小空间: 如上图所示的 From 和 To
-
使用空间为 From 空间, 空闲空间为 To;
-
活动对象存储于 From 空间: 当 From 空间运用到一定程度的时候, 就会去触发 GC 操作;
-
这个时候采用标记整理的操作, 对 From 空间中的活动对象进行标记, 然后进行整理, 整理完以后会将活动对象拷贝到 To 空间
-
然后 From 空间 和 To 交换空间完成释放;
-
回收细节说明:
- 拷贝过程中可能出现晋升: 如果在拷贝时, 发现某一个变量对象所使用的空间在当前老生代存储区也会出现, 这个时候我们就会触发晋升操作,;
- 晋升就是将新生代存储区的某个对象移动至老生代存储区中进行存储;
- 触发晋升操作的标准1: 一轮 GC 后还存活的新生代存储区的对象需要晋升;
- 触发晋升操作的标准2: 在拷贝的过程中, 发现 To 空间的使用率超过 25%(原因: 将来进行回收操作的时候, 最终 From 空间和 To 空间是要交换的, 就是说以前的 To 空间变成 From 空间, 以前的 From 空间变成 To 空间, 如果 拷贝过程中 To 空间的使用率达到了25%, 后面便成 From 空间后存储空间就不够了);
-
4. V8 对老生代对象的回收:
-
老生代空间和老生代对象说明:
- 老生代对象存在在右侧老生代区域(上图中的右侧部分为老生代存储区);
- 老生代存储区也有内存上限: 64位操作系统 1.4 G, 32位操作系统 700M;
- 老生代对象就是指存活时间较长的对象: 全局作用域下存放的变量、闭包里放置的变量数据等;
-
老生代对象的回收实现:
-
主要采用标记清除、标记整理、增量标记算法;
-
首先使用标记清除完成垃圾空间的回收;
-
采用标记整理进行空间优化: 新生代晋升操作时, 老生代存储区空间不足以存储新生代晋升过来的对象时,;
-
采用增量标记进行效率优化:
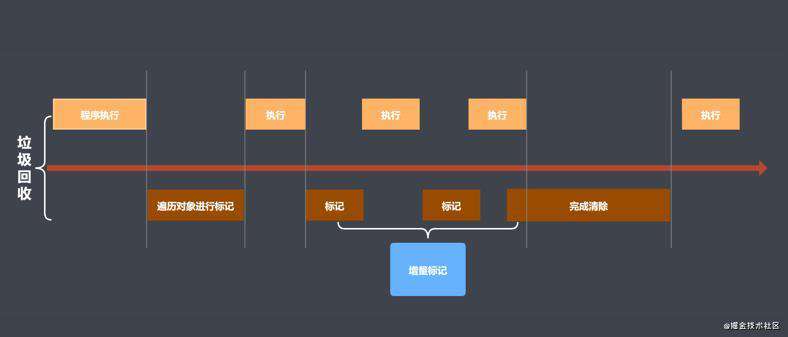
- 当垃圾回收工作的时候, 会去阻塞 JavaScript 程序的执行;
- 标记增量: 将一整段的垃圾回收操作拆分为多个部分组合着去完成当前的回收操作, 从而去替代一整段的垃圾回收操作;
- 标记增量的好处: 让我们可以实现垃圾回收和程序执行去交替执行, 让程序运行的时间消耗更加合理;
- 标记增量的步骤: 先去老生代存储区找直接可达对象, 然后停下来让程序执行, 然后再去找间接可达对象, 然后交替执行;
-
与新生代回收实现的细节对比:
- 新生代存储区垃圾回收使用空间换时间: 因为新生代存储区垃圾回收采用的是复制算法, 每时每刻新生代存储区都会有空闲空间存在;
- 老生代存储区垃圾回收不适合复制算法: 原因: 1.老生代存储区的空间是比较大的, 如果说一分为二, 那么就是有很大的空间被浪费;2.老生代存储区内储存的的对象比较多, 在复制对象的过程中所花费的时间很大;
-
四、Performance 工具
1.为什么使用 Performance
- GC 的目的是为了实现内存空间的良性循环;
- 良性循环的基础是对内存的合理使用;
- 时刻关注才能确定是否合理: 原因 -> ECMAScript 并没有提供操作内存空间的API;\
- Performance 提供多种监控方式
总结: 通过使用Performance, 可以对当前程序的内存进行实时监控, 定位代码块;
2.Performance 使用步骤:
- 打开浏览器输入目标网址;
- 进入开发人员工具面板, 选择性能;
- 开启录制功能, 访问具体界面;
- 执行用户行为, 一段时间后停止录制;
- 分析界面中记录的内存信息;
3.内存问题的体现:
-
内存问题的外在表现:
- 页面出现延迟加载或经常性暂停: 一般认为底层存在频繁的 GC 操作;
- 页面持续性出现糟糕的性能: 一般认为底层存在内存膨胀(当前界面为了去达到最佳的使用速度, 会去申请一定的内存空间, 但是这个空间远远超过了设备所能提供的大小, 就叫内存膨胀);
- 页面的性能随时间延长越来越差: 一般认为底层存在内存泄漏;
-
界定内存问题的标准:
- 内存泄漏: 内存使用持续升高;
- 内存膨胀: 在多数设备上都存在性能问题 -> 在多个设备上去测试这个问题;
- 频繁垃圾回收: 通过内存变化图进行分析;
-
监控内存的几种方式:
-
浏览器任务管理器: 以数值的形式将程序执行过程中内存的变化体现出来;
火狐浏览器: 菜单 -> 更多 -> 任务管理器 或者 地址栏中输入 about:performance;
谷歌浏览器: shift + Esc 或者 菜单 -> 更多工具 -> 任务管理器;
浏览器任务管理器中 内存 和 JavaScript 内存的区别:
- 内存: 表示原生内存, 当前界面里有很多DOM节点, 这个内存就是 DOM节点所占据的内存, 不过这个内存在不断增大, 说明界面中在创建新的DOM节点;
- JavaScript 内存: 表示的是JS堆, 应关注小括号()里面的值, 表示界面中所有可达对象正在使用的内存大小, 如果这个内存一直在增大, 要么是在创建新对象, 要么是现有对象内存在不断的增长;
- 当前操作只能用于判断当前脚本是否存在问题, 不能定位问题;
-
Timeline 时序图记录: 直接将引用程序执行过程中所有内存的走势都以时间点的形式呈现出来;
谷歌浏览器里面的 Performance 使用;
-
堆快照查找分离 DOM: 很有针对性的去查找当前界面中是否存在一些分离的DOM, 分离DOM就是内存上的泄漏;
-
堆快照工作的原理: 找到当前的JS堆, 对Js堆进行照片的留存, 有了照片以后就可以查看里面的所有信息, 这就是我们监控的由来;
-
什么是分离 DOM
- 界面元素存活在 DOM 树上:
- 垃圾对象时的DOM 节点: 如果这个节点从当前DOM树上进行了脱离, 而且在JS代码中也没有引用这个DOM节点, 他就成为了一个垃圾对象时的DOM节点;
- 分离状态的DOM节点: 如果这个节点从当前DOM树上进行了脱离, 在JS代码中还有对这个DOM节点的引用, 他就是分离状态的DOM节点; 分离DOM在界面上时看不见的, 但是在内存中确实占据着空间的, 这种情况下就是内存泄漏;
- 谷歌浏览器开发者工具里面的内存模块 -> 堆快照;
-
-
判断是否存在频繁的垃圾回收;
- 为什么要确定频繁垃圾回收
- GC 工作时应用程序是停止的
- 频繁且过长的 GC 会导致应用假死
- 用户使用中感知应用卡顿
- 确定频繁的垃圾回收
- Timeline 中频繁的上升下降
- 任务管理器中数据频繁的增加减少
- 为什么要确定频繁垃圾回收
-
五、代码优化
1、代码优化介绍
-
如何精准测试 JavaScript 性能
- 本质上就是采集大量的执行样本进行数学统计和分析, 从而得到比对的结果, 来证明什么样的脚本执行效率最高, 这样对于开发者来说比较的麻烦;
- 使用基于 Benchmark.js 的 jsperf.com 完成
- 使用 jsbench.me 进行性能测试
-
Jsperf 使用流程
-
使用 GitHub 账号登陆
-
填写个人信息 (非必填)
-
填写详细的测试用例信息(title、slug): slug 必须是唯一的, 会生成一个空间, 便于我们去访问;
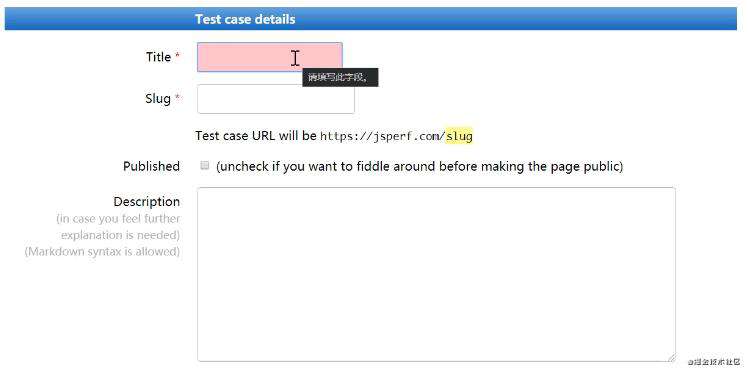
-
填写准备代码(DOM操作时经常使用):
-
填写必要的 setup 与 teardown 代码: setup: 当前要做的前置准备工作, teardowm: 所有代码执行完后要执行的销毁操作;
-
填写测试代码片段
-
2.慎用全局变量
- 解释:在程序执行过程中, 如果某些数据需要存储, 尽可能的将数据放在局部作用域中;
- 为什么要慎用
- 全局变量定义在全局执行上下文, 是所有作用域链的顶端: 如果按照作用域层级网上查找的过程来说, 下边某些局部作用域中没有找到的变量就会去查找到全局执行上下文, 这样的查找时间消耗非常大, 降低了代码的执行效率;
- 全局执行上下文一直存在于上下文执行栈, 直到程序退出: 这对于 GC 工作很不利, GC 发现变量是存活状态, 就不会把它当做垃圾回收, 这样会降低程序运行过程中对内存的使用;
- 如果某个局部作用域出现了同名变量则会遮蔽或污染全局变量;
//代码片段1
var i, str = '';
for (i = 0; i < 1000; i++) {
str += i;
}
//代码片段2
{
let str = '';
for (let i = 0; i < 1000; i++) {
str += i;
}
}
在 jsperf 中 代码片段1 用时明显 长于 代码片段2
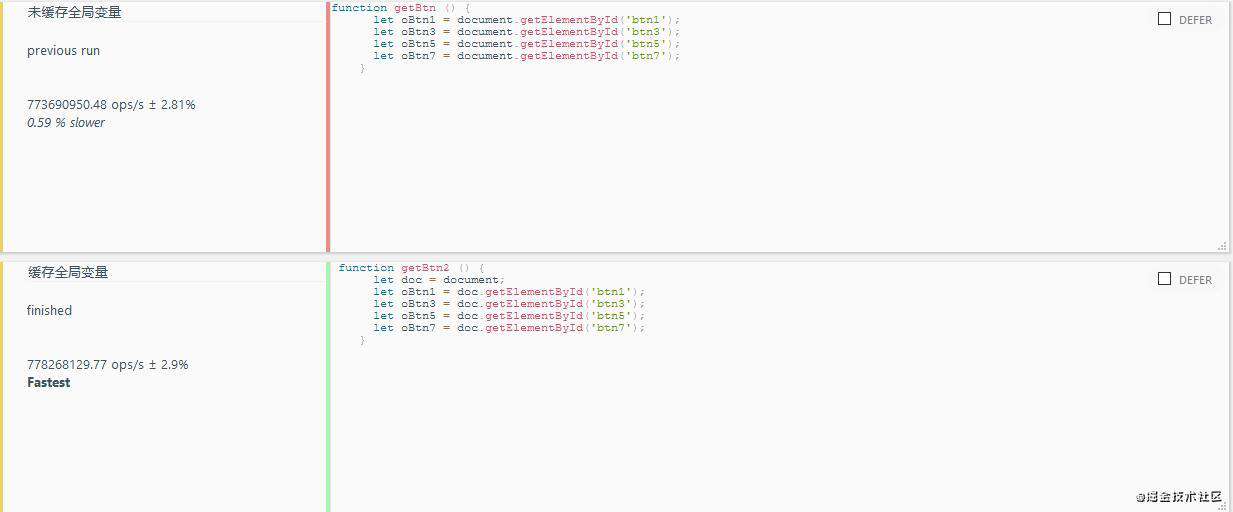
3.缓存全局变量
- 解释: 在某些地方针对于全局变量的使用是无法避免的, 所以要将使用中无法避免的全局变量缓存到局部;
<body>
<input type="button" value='btn' id="btn1" />
<input type="button" value='btn' id="btn2" />
<p>111</p>
<input type="button" value='btn' id="btn3" />
<input type="button" value='btn' id="btn4" />
<p>222</p>
<input type="button" value='btn' id="btn5" />
<input type="button" value='btn' id="btn6" />
<p>333</p>
<input type="button" value='btn' id="btn7" />
<input type="button" value='btn' id="btn8" />
<script>
//不缓存全局变量
function getBtn () {
let oBtn1 = document.getElementById('btn1');
let oBtn3 = document.getElementById('btn3');
let oBtn5 = document.getElementById('btn5');
let oBtn7 = document.getElementById('btn7');
}
//缓存全局变量
function getBtn2 () {
let doc = document;
let oBtn1 = doc.getElementById('btn1');
let oBtn3 = doc.getElementById('btn3');
let oBtn5 = doc.getElementById('btn5');
let oBtn7 = doc.getElementById('btn7');
}
</script>
</body>
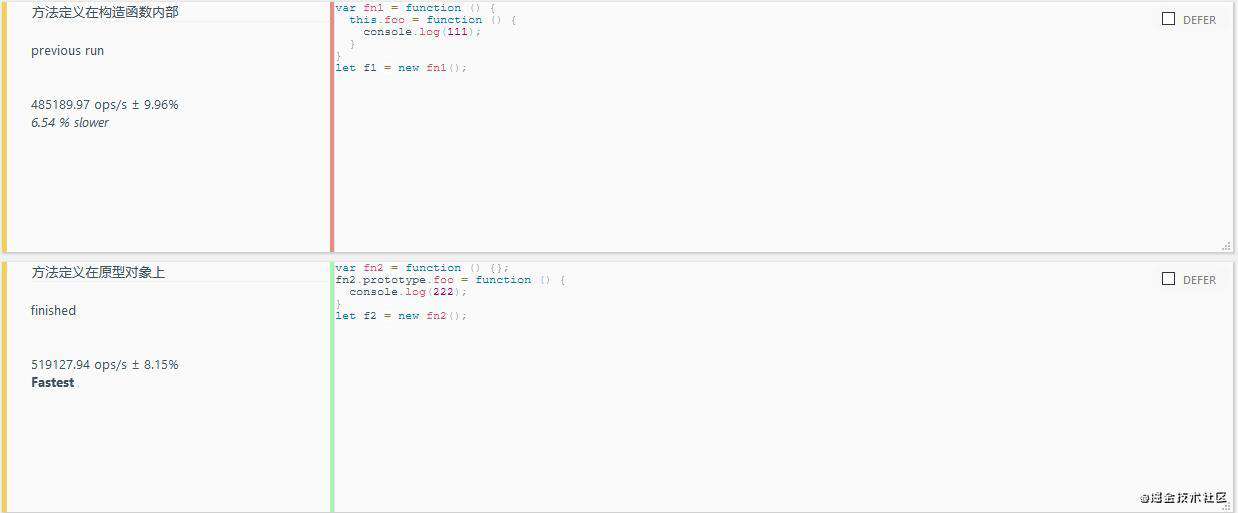
4.通过原型新增方法
在javascript存在着三个概念: 构造函数、原型对象、实例对象;我们的实例对象和构造函数都是可以指向原型对象的; 在代码中, 示例对象需要频繁的调用某个方法, 我们可以直接把这个方法添加到原型对象上, 而不需要把这个方法放在构造函数内部;
//通过构造函数新增方法
var fn1 = function () {
this.foo = function () {
console.log(111);
}
}
let f1 = new fn1();
//通过原型新增方法
var fn2 = function () {};
fn2.prototype.foo = function () {
console.log(222);
}
let f2 = new fn2();
5.避开闭包陷阱
-
闭包的特点
- 外部具有指向内部的引用
- 在“外”部作用域中访问“内”部作用域的数据
function foo () { var testName = 'lg'; function fn () { console.log(testName); } return fn; } var a = foo(); a();//在这里可以调用foo 函数的变量 testName -
关于闭包
- 闭包是一种强大的语法
- 闭包使用不当很容易出现内存泄漏
- 在以后的编码过程中不要为了闭包而闭包;
<body> <button id="btn">add</button> <script> function foo () { var el = document.getElementById('btn'); el.onclick = function () { console.log(el.id); } el = null; } foo();//在代码的执行过程中, 就产生了闭包现象: 当button 去点击的时候, 会调用foo 函数里面的变量el, 形成闭包; //这里的存在内存泄漏, 当button 去点击多次的时候, el 始终得不到释放, 就会造成内存泄漏; //解决这里的内存泄漏, 在添加点击事件后 置空el;这里还可以解决 如果 DOM 上的button 节点被删除后, el 继续被引用的问题; </script> </body>
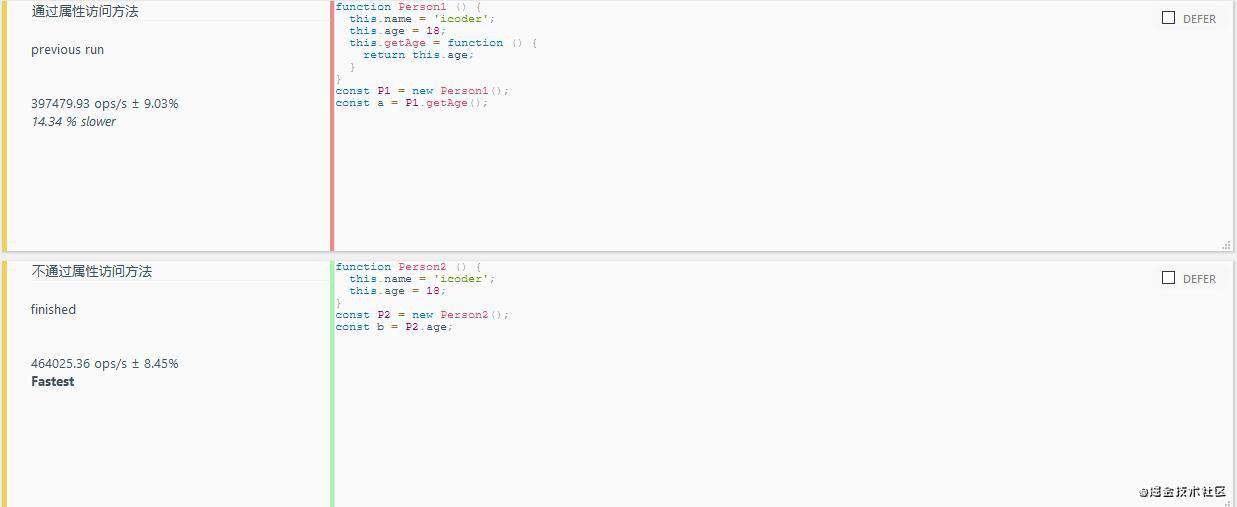
6.避免属性访问方法使用
- 解释:属性访问方法,跟面向对象相关的; 为了实现更好的封装性, 可能会将一些对象的资源属性和方法放在一个函数的内部, 然后向外面暴露一个方法, 去对对象内的属性进行增删改查操作; 这个操作在 JavaScript面向对象中, 不是特别的适用
- JavaScript 中的面向对象
- Js 中不需要属性的访问方法, 因为所有属性都是外部可见的;
- 使用属性访问方法只会增加一层重定义, 没有访问的控制力;
//通过属性访问方法
function Person1 () {
this.name = 'icoder';
this.age = 18;
this.getAge = function () {
return this.age;
}
}
const P1 = new Person1();
const a = P1.getAge();
//不通过属性访问方法
function Person2 () {
this.name = 'icoder';
this.age = 18;
}
const P2 = new Person2();
const b = P2.age;
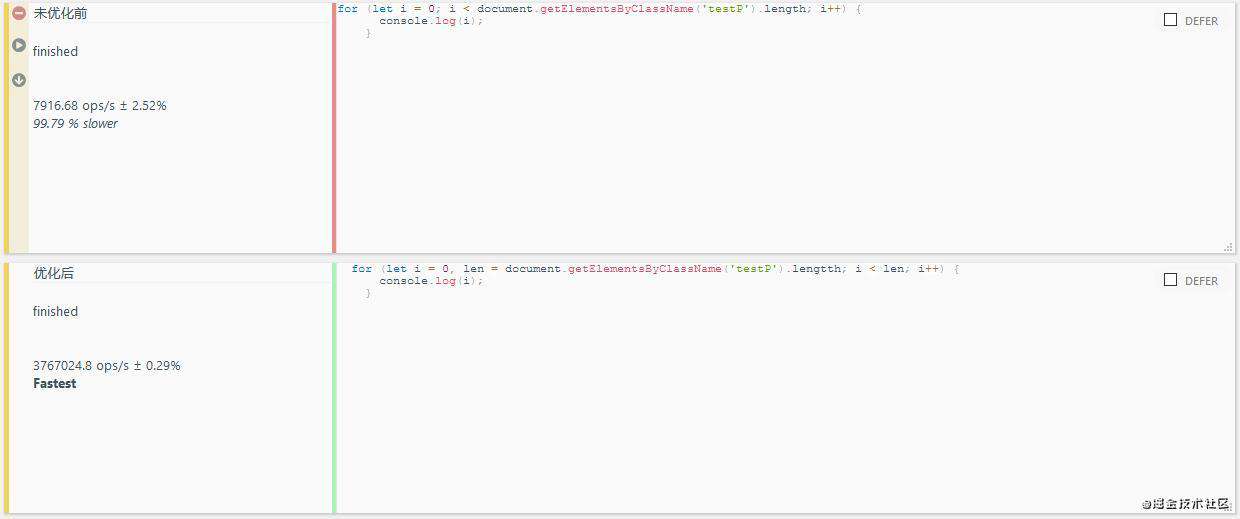
7.For 循环优化
<body>
<p class="testP">add</p>
<p class="testP">add</p>
<p class="testP">add</p>
<p class="testP">add</p>
<p class="testP">add</p>
<p class="testP">add</p>
<p class="testP">add</p>
<p class="testP">add</p>
<p class="testP">add</p>
<script>
//未优化前
for (let i = 0; i < document.getElementsByClassName('testP').length; i++) {
console.log(i);
}
//优化后
for (let i = 0, len = document.getElementsByClassName('testP').lengtth; i < len; i++) {
console.log(i);
}
</script>
</body>
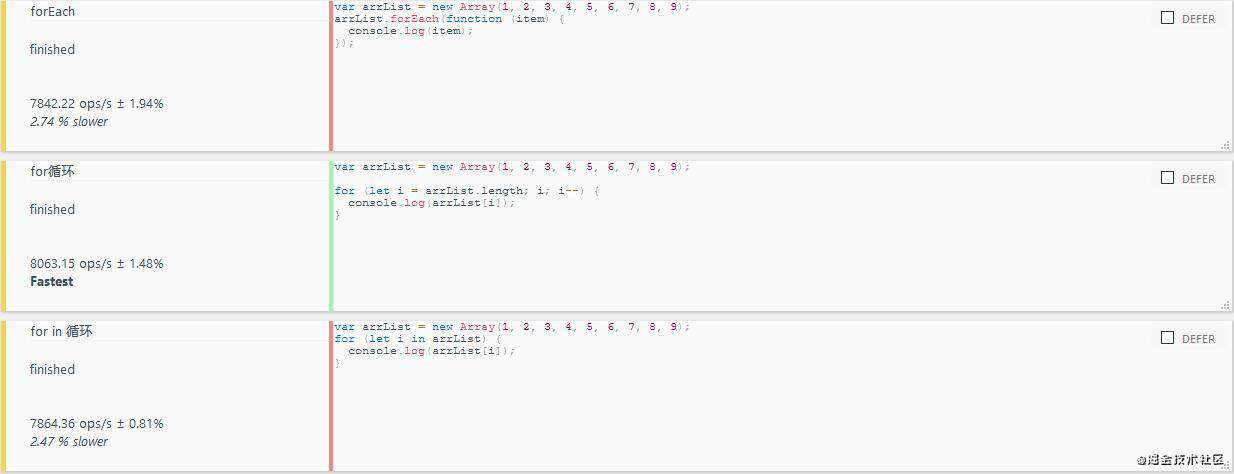
8.选择最优的循环方式
var arrList = new Array(1, 2, 3, 4, 5, 6, 7, 8, 9);
//forEach
arrList.forEach(function (item) {
console.log(item);
});
//for循环
for (let i = arrList.length; i; i--) {
console.log(arrList[i]);
}
//for in 循环
for (let i in arrList) {
console.log(arrList[i]);
}
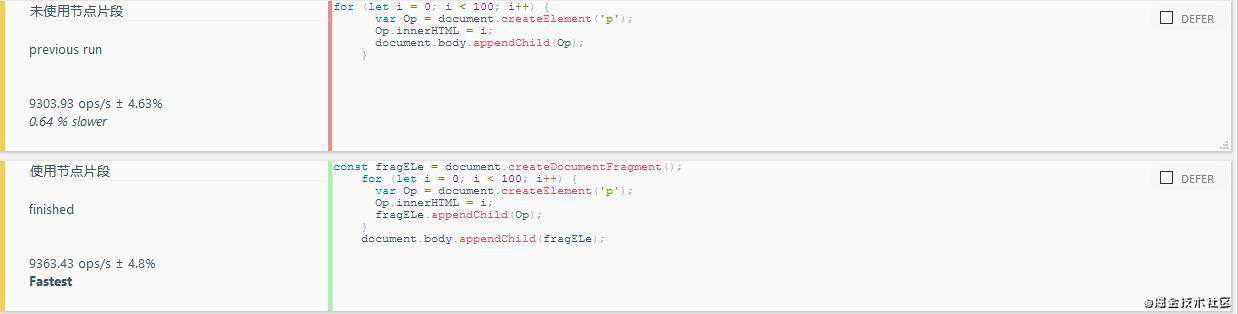
9.节点添加优化
- 解释: 针对以Web 引用开发来说, DOM的操作时很频繁的, 而针对于DOM的交互操作又很耗费性能, 特别是创建一个新的节点, 添加到页面中时;
- 节点的添加操作必然会有回流和重绘: 回流和重绘消耗性能是很大的;
<body>
<script>
//未使用节点片段
for (let i = 0; i < 100; i++) {
var Op = document.createElement('p');
Op.innerHTML = i;
document.body.appendChild(Op);
}
//使用节点片段
const fragELe = document.createDocumentFragment();
for (let i = 0; i < 100; i++) {
var Op = document.createElement('p');
Op.innerHTML = i;
fragELe.appendChild(Op);
}
document.body.appendChild(fragELe);
</script>
</body>
10.克隆优化节点操作
<body>
<p id="testP">oldP</p>
<script>
//不使用克隆
for (let i = 0; i < 10; i++) {
var Op = document.createElement('p');
Op.innerHTML = i;
document.body.appendChild(Op);
}
//使用克隆
let oldP = document.getElementById('testP');
for (let i = 0; i < 10; i++) {
var newP = oldP.cloneNode(false);
newP.innerHTML = i;
document.body.appendChild(newP);
}
</script>
</body>

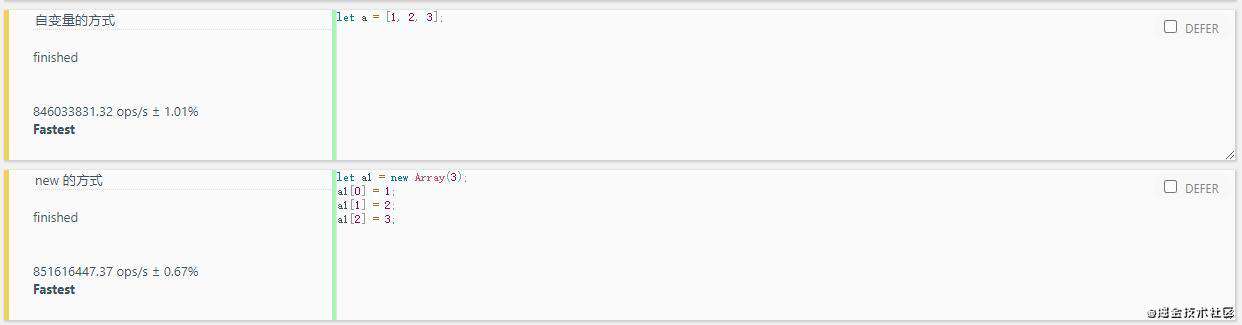
11.直接量替换 Object 操作
- 说明: 当我们去定义一些对象或者数组时, 有两种形式:
- 通过 new 的方式
- 通过自变量的方式
let a = [1, 2, 3];
let a1 = new Array(3);
a1[0] = 1;
a1[1] = 2;
a1[2] = 3;
六、JavaScript 性能的其他优化
1.减少判断层级对代码性能的影响
- 说明: 在我们编写代码的过程中, 可能出现判断条件嵌套的场景, 当出现多层 if else 嵌套时, 我们都可以通过提前return 去掉一些无效的条件, 来达到判断层级的优化;
//减少判断层级优化
//需求: 一个网站中有很多模块, 每个模块下, 一个列表中, 前5章是免费的, 后面的是收费的
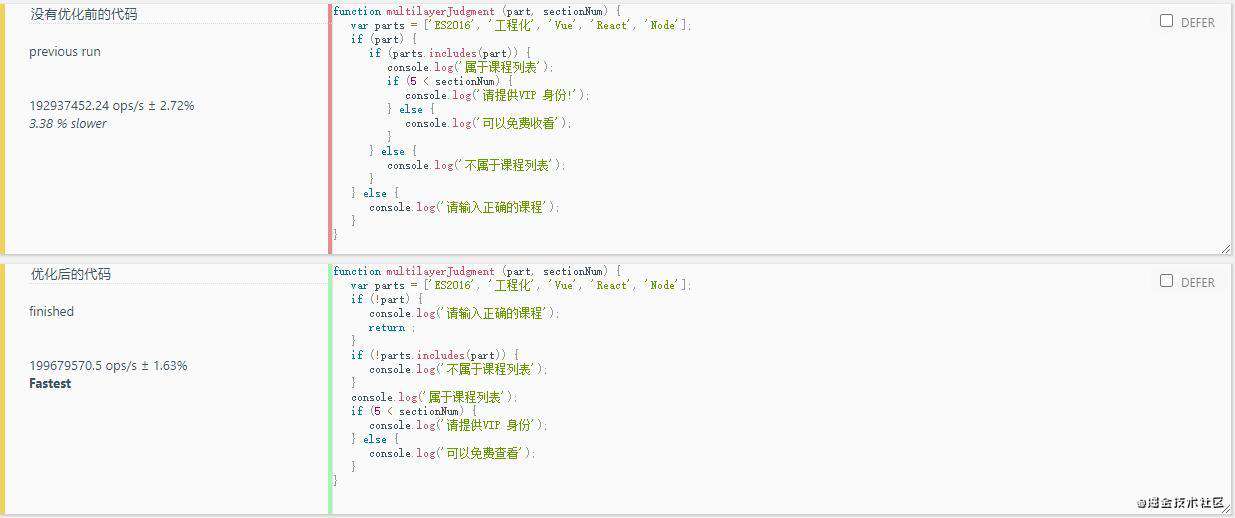
//没有优化前的代码
function multilayerJudgment (part, sectionNum) {
var parts = ['ES2016', '工程化', 'Vue', 'React', 'Node'];
if (part) {
if (parts.includes(part)) {
console.log('属于课程列表');
if (5 < sectionNum) {
console.log('请提供VIP 身份!');
} else {
console.log('可以免费收看');
}
} else {
console.log('不属于课程列表');
}
} else {
console.log('请输入正确的课程');
}
}
multilayerJudgment('ES2016', 6);
//优化后的代码
function optimizeMultilayerJudgement (part, sectionNum) {
var parts = ['ES2016', '工程化', 'Vue', 'React', 'Node'];
if (!part) {
console.log('请输入正确的课程');
return ;
}
if (!parts.includes(part)) {
console.log('不属于课程列表');
}
console.log('属于课程列表');
if (5 < sectionNum) {
console.log('请提供VIP 身份');
} else {
console.log('可以免费查看');
}
}
optimizeMultilayerJudgement('ES2016', 6);
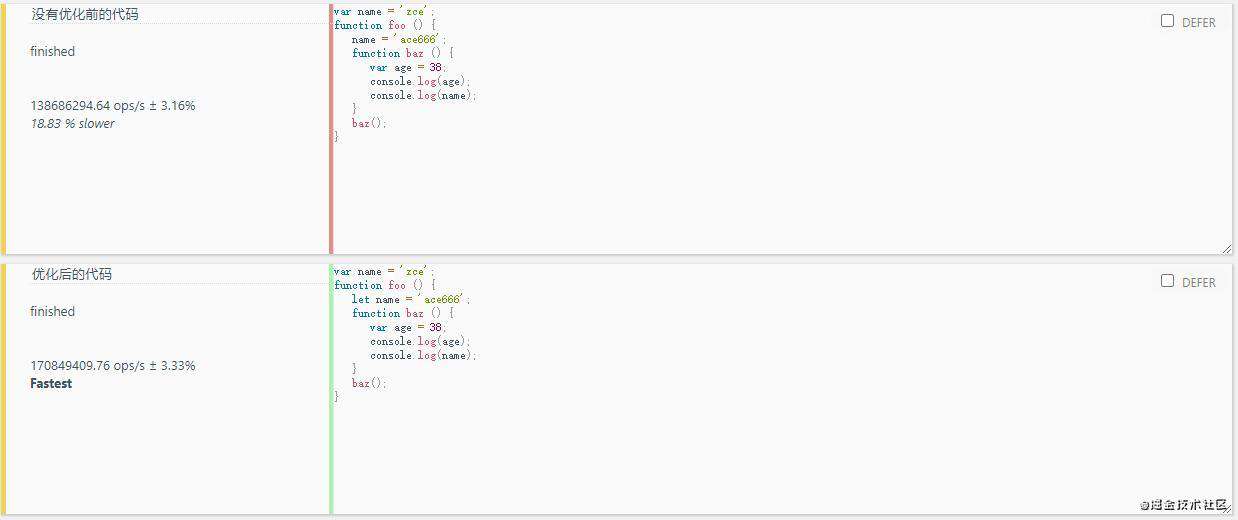
2.减少作用域链查找层级
//优化前代码
var name = 'zce';
function foo () {
name = 'ace666';
function baz () {
var age = 38;
console.log(age);
console.log(name);
}
baz();
}
foo();
//优化后的代码
var name = 'zce';
function foo () {
let name = 'ace666';
function baz () {
var age = 38;
console.log(age);
console.log(name);
}
baz();
}
foo();
3.减少数据读取次数
-
说明: 在js中, 主要使用的最常见的数据表现形式: 自面量(常量)、局部变量、数组元素、对象成员;访问自变量和局部变量速度是最快的(原因: 他们都可以直接存放于栈区中), 访问数组元素和对象成员就会相对较慢些(原因: 按照引用的关系, 先要找到在堆内存中的位置), 例如对象成员的访问, 在操作的时候, 往往还要去考虑到原型链上的内容查找; 因此如果我们减少查找的时间消耗, 就应该尽可能的去减少对象成员的查找次数和属性的嵌套层级(嵌套深度);
-
最常见的做法: 提前缓存对象的数据;
<body> <!-- 需求: 在使用某产品的时候, 有广告的入口页(欢迎页), 上面一般会提供跳过按钮, 我们需要判断上面是否有这个按钮, 如果存在就触发后续的操作, 如果不存在, 我们需要走其他的逻辑 --> <div id="skip" class="skip moreClassName"></div> <script type="text/javascript"> let oBox = document.getElementById('skip'); //优化前的代码 function eleHasClass (ele, cls) { if (ele.className.includes(cls)) return true; else return false; } eleHasClass(oBox, 'skip'); /*为什么要优化: 上面函数中传减去的ele 是一个对象, 他的身上会有很多的属性, 每次使用ele.className 的时候都要去查询一下, 如果className 的层级较深, 所消耗的时间会很长; */ //优化后的算法 function hasEleClass (ele, cls) { var eleClassName = ele.className; if (eleClassName.includes(cls)) return true; else return false; } hasEleClass(oBox, 'skip'); </script> </body>
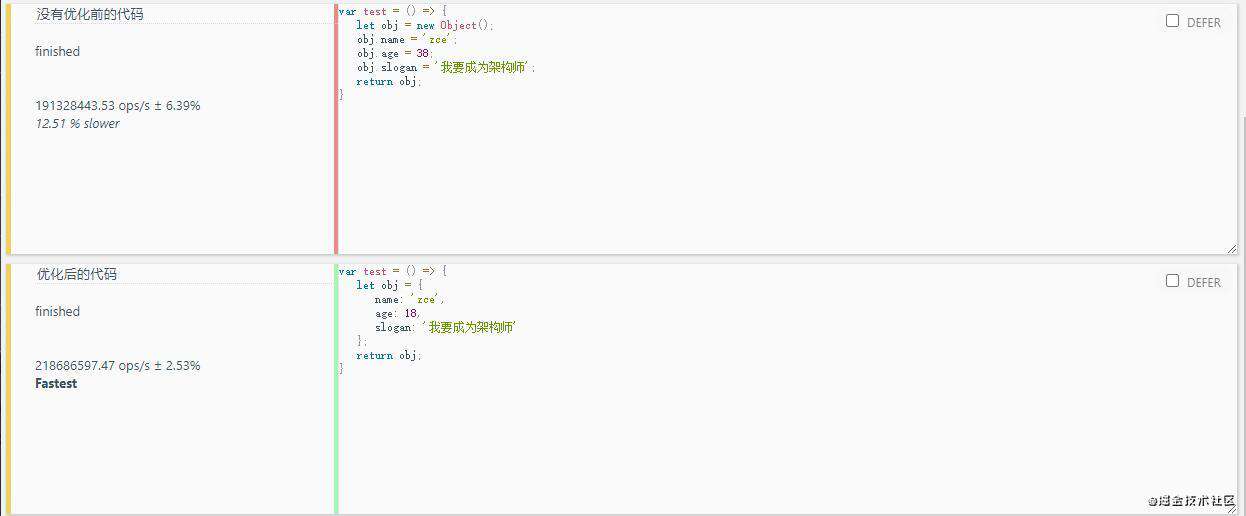
4.字面量与构造函数
//优化前代码
/* var test = () => {
let obj = new Object();
obj.name = 'zce';
obj.age = 38;
obj.slogan = '我要成为架构师';
return obj;
} */
//console.log(test());
//优化后代码
var test = () => {
let obj = {
name: 'zce',
age: 18,
slogan: '我要成为架构师'
};
return obj;
}
console.log(test());
//优化前的代码
/* var testStr = new String('我要成为高级架构师'); */
//优化后的代码
var testStr = '我要成为高级架构师';
console.log(testStr);

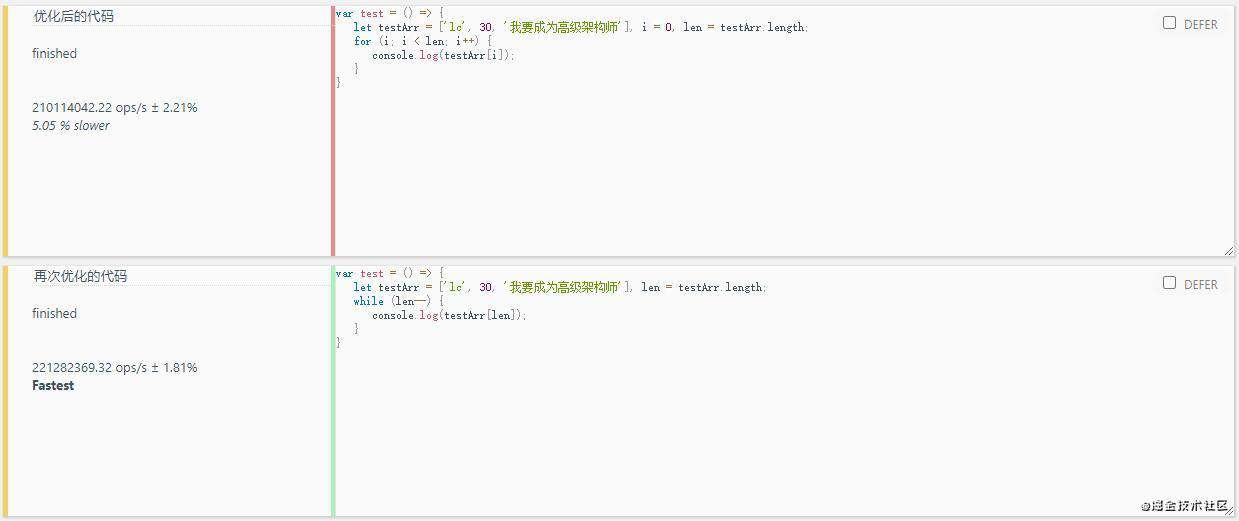
5.较少循环体中活动
//优化前的代码
/* var test = () => {
let testArr = ['lc', 30, '我要成为高级架构师'];
for (var i = 0; i < testArr.length; i++) {
console.log(testArr[i]);
}
}
test(); */
//优化后的代码
var test = () => {
let testArr = ['lc', 30, '我要成为高级架构师'], i = 0, len = testArr.length;
for (i; i < len; i++) {
console.log(testArr[i]);
}
}
test();

//优化后的代码
/* var test = () => {
let testArr = ['lc', 30, '我要成为高级架构师'], i = 0, len = testArr.length;
for (i; i < len; i++) {
console.log(testArr[i]);
}
}
test(); */
//再次优化后的代码
var test = () => {
let testArr = ['lc', 30, '我要成为高级架构师'], len = testArr.length;
while (len--) {
console.log(testArr[len]);
}
}
test();
6.减少声明及语句数
- 介绍声明
<body>
<div id="testDiv" style="width: 100px; height: 200px;"></div>
<script type="text/javascript">
var oBox = document.getElementById('testDiv');
/* //优化前的代码
var test = ele => {
let w = ele.offsetWidth, h = ele.offsetHeight;
return w * h;
} */
//优化后的代码
var test = ele => {
return ele.offsetWidth * ele.offsetHeight;
}
console.log(test(oBox));
</script>
</body>
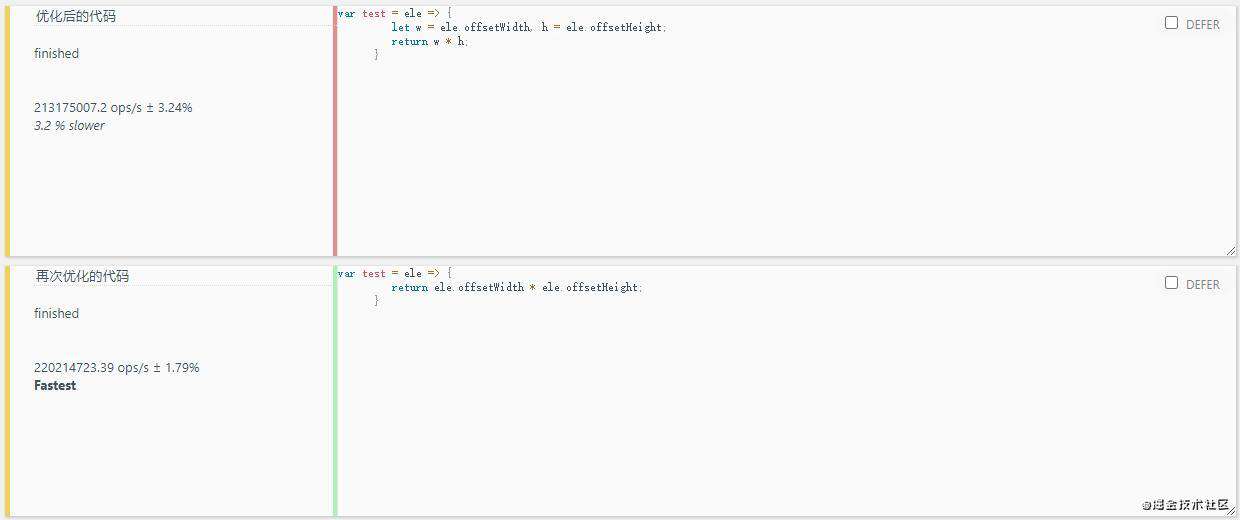
原因: 1、优化前的代码的量是多的; 2、js编译器, 在做词法分析的时候, 需要按照一定的规则进行拆分成词法单元, 词法单元有了以后它要去做语法分析, 最终展成我们的语法树, 有了语法树以后, 在转化为代码, 然后再执行; 优化前的解析时间过长;
-
较少语句数
//优化前代码 var test = () => { var name = 'lc'; var age = 29; var solgan = '我要成为高级架构师'; return name + age + solgan; } console.log(test()); //优化后代码 var test = () => { var name = 'lc', age = 29, solgan = '我要成为高级架构师'; return name + age + solgan; } console.log(test());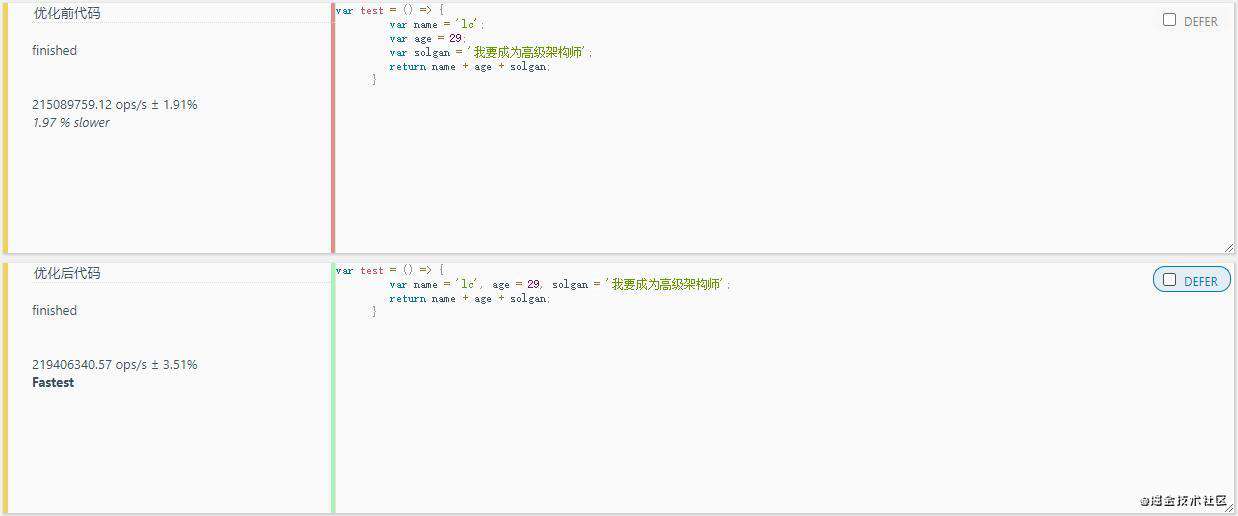
7.采用事件委托
<body>
<ul id="testUl">
<li>lc</li>
<li>29</li>
<li>我要成为高级架构师</li>
</ul>
<script type="text/javascript">
//优化前代码
var testList = document.querySelectorAll('li');
for (let item of testList) {
item.onclick = showLiText;
}
function showLiText (ev) {
console.log(ev.target.innerHTML);
}
//优化后代码: 利用事件委托
var thisUl = document.getElementById('testUl');
thisUl.addEventListener('click', showText, true);
function showText (ev) {
var obj = ev.target;
if ('li' === obj.nodeName.toLowerCase()) {
console.log(obj.innerHTML);
}
}
</script>
</body>
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!