译者:is_january
原文链接
随着最近添加了 SharedArrayBuffer,高并发正在寻找其在 Javascript 语言中的呈现方式,这项额外特性允许 Javascript 程序能够对 SharedArrayBuffer 对象执行高并发访问。WebKit 正在支持 SharedArrayBuffer,而且在我们编译器的 pipeline 里面 它已经有了完整的优化支持。但不幸的一点是,Javascript 并不允许除 SharedArrayBuffer 以外的对象被共享。
本文考虑了一种天马行空式的实验:它会采用什么来对整个 Javascript 堆(heap) 扩展并发性?在这个世界里,任何对象都能被其他线程共享,这不会是一个小小的改动。目前 Javascript 虚拟机(VM) 的优化利用了只有一个执行线程的基本事实,因此高并发肯定会带来一些性能问题。本文考虑的问题是这是否在技术上是可行的,如果可行,那代价会是什么?
我们提供了一个基础的 strawman API 来阐述我们所指的高并发的意义,本文的大部分内容会关注 WebKit 的 Javascript VM (叫做 JavascriptCore 或者简称 JSC) 是如何实现 strawman 的。实现这样一个 strawman 会花很多功夫,我们认为我们期望的实现方式应该能满足以下目标:
-
对于不使用高并发的代码不产生性能退化
-
当程序在并行运行,而且不去特意共享任何对象的时候,应该有线性扩展性。我们不期望两个线程的速度完全是单个线程的两倍,因为我们判断可能会有一些并发产生的开销 ———— 但如果你有两个 CPU,那么两个线程应该比单线程快,而且最好能接近单线程(速度)的两倍。
-
在某些的确共享对象的并行代码库中的线性扩展 ———— 包括对最佳串行基线(best serial baseline)的加速
-
合理的语义,包括一个内存模型,它应该不比任何现代硬件所提供的(内存模型)更弱。
-
兼容性。例如,高并发 Javascript 程序应该知道如何使用 DOM,而不需要重写 DOM 的实现逻辑。
我们的目标实现计划基于 64 位系统,但那主要是因为我们的引擎已经是以 64 位为中心的。
目前还无法从经验上评估这套方案的性能,但我们的实现思路能够有助于直观感受到性能也许看上去像是什么样的。具体来说,我们的方案保证了大多数属性访问最多和一条算术指令所花费的开销差不多(也就是可以几乎忽略不计),还有一些特别复杂的(而且也很罕见) 大概要花费 7 倍左右的开销。本文的最后,把我们的方案和其他实现高并发的技术做了比较。
Strawman 高并发 JS
我们这个 strawman 的高并发 JS 提案只是简单地为了添加线程,线程能拿到相互隔离的栈(separate stacks) 但共享任何其他的部分,线程对于我们的实验来说很不错,因为它们具有相当的通用性。我们可以在线程的基础上,再想像实现很多其他类型的的高并发编程模型。因此,如果能够让我们的 VM 支持线程,那么我们也许能够让它支持许多其他的高并发、并行的编程模型。对于把任何高并发编程模型添加到 Javascript 里去的这种技术可行性来说,本文不会把它作为一个考虑因素。
这一部分让 strawman 有些具体,大部分提供了实现起来或难或易的使用情境。知道 API 长啥样,对于理解它产生了哪些局限,也是有很用的。
每个程序都会由一个线程开始,线程可以启动其他线程,线程位于同一个堆中,而且互相之间可以共享对象。这一部分用来展示 API,描述内存模型,并且展示高并发模型如何与 DOM 交互。
可能的 API
我们建议:
-
一个用来创建线程的简单 API,
-
修改
原子化(Atomic) 对象以支持构建锁对象, -
能够建立在原子化前提之上的一个锁与条件变量的 API,
-
一种创建线程域下变量(thread-local variables)的途径,以及
-
一些用以允许增量应用的辅助方法
本文会利用 strawman 来准确地理解在 JavascriptCore 中实现线程会带来什么
我们希望可以很便捷地创建线程:
new Thread(function() { console.log(""Hello, threads!""); });
它可以开启一个新线程,这个新线程最终会打印""Hello, threads"",请注意:即使是这样一个简单的例子也在线程中共享了许多东西。例如,函数对象会在词法范围(lexical scope)被创建的线程里捕获到它(指 lexical scope),所以当线程访问到 console 变量的时候,这就是一个对共享对象的访问。
线程可以被 join 以等待它们执行完毕,并且能得到结果:
let result = new Thread(() => 42).join(); // returns 42
在浏览器里,主线程不会阻塞,所以 join() 会在以上代码跑在主线程上的时候抛出异常。我们可以支持阻塞操作的异步版本:
new Thread(() => 42).asyncJoin().then((result) => /* result is 42 */)
你总是能够取得当前线程的线程对象:
let myThread = Thread.current;
线程可能需要相互等待以防止竞争,这可以通过锁机制来实现。我们希望通过扩展 Atomics API(前文提到的 Atomics API) 来让用户构建任何他们偏好的锁机制,而不是简单地提供一套锁 API 就完了。我们在提供的 API 里面给出了一套优秀的锁机制实现,但我们希望鼓励创造其他类型的基础同步原型。当前的 SharedArrayBuffer 特案允许开发者们使用 Atomics API 创建自定义的锁机制。这套 API 让你能这样操作:
Atomics.wait(array, index, expectedValue);
以及:
Atomics.wake(array, index, numThreadsToWake);
目前,数组必须是依赖 SharedArrayBuffer 的整型数组,我们提议扩展所有的 Atomics 方法,将它们从原来使用数组/索引,扩展成使用对象与属性名。因为索引就是一个属性名,因此这些改动不会改变原来使用 SharedArrayBuffer API 部分的代码行为。而且,这也意味着,在和常规 Javascript 属性一块使用的时候,目前采用整数值的 Atomics 方法(这是为了在有类型的数组中存储和比较元素),现在将会能够使用任何 Javascript 值。Atomics.wake, Atomics.wait, 和 Atomics.compareExchange 对于只用一个 Javascript 属性的任何一个锁机制来说都已经足够了
另外,我们提议新增一个锁 API:
let lock = new Lock();
lock.hold(function() { /* ...perform work with lock held... */ });
主线程上的锁就有可能做到 promise 的效果:
lock.asyncHold().then(function() { /* ...perform work with lock held... */ });
这是有作用的,因为每个线程都有自己的运行循环(runloop),我们也可以添加一个条件 API(Condition API):
let cond = new Condition();
cond.wait(lock); // Wait for a notification while the lock is temporarily released.
// ...
cond.asyncWait(lock).then(function() { /* ...perform work with lock reacquired... */ });
// ...
cond.notify(); // Notify one thread or promise.
// ...
cond.notifyAll(); // Notify all threads and promises.
Condition.prototype.wait 会在等待以前释放你传给它的锁,然后在返回之前再次获取到它。这样的异步转化把结果的 promise 和条件变量联系起来,使得如果条件被通知了(notify),promise 就会在当前线程实现。
使用 Thread.current 和 WeakMap, 任何人都能实现线程下 (thread-local) 的变量。但有时候,对于底层的运行时 (underlying runtime) 而言,是有可能做些更聪明的事情的。我们不希望一定得让所有的 Javascript 程序员都知道如何用 WeakMap 实现线程下 (thread-local) 的变量。因此,我们提出了一个简单的 API:
let threadLocal = new ThreadLocal();
function foo()
{
return threadLocal.value;
}
new Thread(function() {
threadLocal.value = 43;
print(""Thread sees "" + foo()); // Will always print 43.
});
threadLocal.value = 42;
print(""Main thread sees "" + foo()); // Will always print 42.
最后,如果用户想要声明只在某个线程上保留对象,我们希望能够把这件事情变得简洁:
var o = {f: ""hello""}; // Could be any object.
Thread.restrict(o);
new Thread(function() {
console.log(o.f); // Throws ConcurrentAccessError
});
任何被 Thread.restrict 了的对象,应该对任何非调用 Thread.restrict 线程的代理操作抛出 ConcurrencyAccessError
内存模型
处理器和编译器都喜欢给内存访问重新排序,而且它们也酷爱从内存_提升(hoist)_负载。之所以会发生这样的情况是因为下面的代码:
let x = o.f
o.g = 42
let y = o.f
可能会被编译器或者处理器这样转化:
let x = o.f
o.g = 42
let y = x
从效果上看,这相当于进入 y 的负载被提升到存储 o.g 之前了,处理器会通过缓存 o.f 以及复用第二次加载的缓存结果,动态地去做同样的优化。
处理器和编译器喜欢_沉入_内存中去,这是因为以下代码:
o.f = 42
let tmp = o.g
o.f = 43
可能会被编译器或处理器这样转化:
let tmp = o.g
o.f = 43
这看上去像是把 o.f = 42 这句语句移动到 o.f = 43 之前,虽然编译器不会做这样的转化,但处理器也许会缓冲存储区,然后在方便的时候再去执行。这也可以被理解成 o.f = 42 可能在 let tmp = o.g 之后执行。
对于我们的 strawman 来说,遵循目前的 SharedArrayBuffer 内存模型是最合理的。现在,我们已经有可能使用 SharedArrayBuffer 来编写具有在有限范围内的不确定性行为的多线程代码了,而且我们不用完全避免这样的代码。但是 Javascript 的对象比一个缓冲区复杂得多,因此在 JS 对象模型面对竞争的时候,保证其基本不变性并不容易。我们提议,修改 Javascript 对象存储的操作应该以原子化去执行。原子操作的作用是,如果许多线程并发地执行这些操作,那么每一个线程会表现得像它们都在某种顺序下、无并发的情形下去执行一样。每一个 JS 可以对对象做的底层操作都应该是原子化的:
-
添加属性
-
删除属性
-
获取某个属性值
-
设置某个属性值
-
改变某个属性的配置
-
给属性名集合记录快照(snapshot)
这不总是意味着 o.f 的表达式是原子化的,因为这个表达式也许远不是止加载某个属性值那么简单。具体来说:
-
如果
o.f是一个直接在o上的普通属性,那么这是一个原子化操作 -
如果
o.f是一个原型链访问 (prototype access),那么加载原型链(loading the prototype) 是独立于从原型链中加载f的 (loadingffrom the prototype)。 -
如果
o.f是一个读方法 (getter),那么加载读方法是一个步骤(如果读方法是直接定义在o上的,那么这个步骤是原子化的),但是调用读方法不是原子化的,因为读方法也许会执行任何代码。
我们提议低层级的对象操作是原子化的。某些操作,比如说读写属性值,或许可以通过使用允许重排序的硬件原始指令来实现。受限于同样的对 SharedArrayBuffer 具有读/写权限的内存模型,我们建议允许读/写权限之间相互的重排序。当我们的 strawman 的确允许竞争和某些内存模型奇异性的时候,那么它就不会允许 Javascript 对象模型的不变性是无效的。对于任何由高并发 JS 程序创建的堆(heap),应该能够做出一个创建不变堆的序列化 JS 程序。
最后,我们认为,高并发 JS 堆的内存管理就像它在其他具有垃圾回收机制的多线程语言中发生的情形一样。坦率地说,垃圾回收必须是原子级地去执行,而且应该只在合适的安全时点进行,比如说回环边界、分配地址的时候,或者是调用本地不会使用堆的代码的时点。这样的需要会由广受欢迎的垃圾回收算法来满足,比如 HotSpot 或是 MMTk 里面的那些算法。同样,它也能由一些经验算法,比如标记-清除算法(mark-sweep)、半空间(semi-space) 算法,甚至在用无全局终止阶段的垃圾收集器也能满足,还包括很大程度上无锁(lock-free)的,以至于甚至不会停下线程来扫描堆的垃圾收集器。Webkit 的 Riptide GC 已经在大多数情况下上支持了多线程,因为我们的 JIT 线程是可以访问堆的。
与 DOM 进行交互
对于所有的 Javascript 来扩展高并发会很难;将其扩展到所有 DOM 上难度更甚。我们拓展了足够的深度,推导出了 DOM 的线程,从而使得这套 strawman (在 DOM 上也是) 有用的。
我们计划默认情况下,DOM 对象会抛出 ConcurrentAccessError,以响应任何来自除主线程以外的所有代理操作,就像是从主线程上调用 Thread.restrict 来作用在其他线程一样。
然而,一些对象需要开放并发权限以使语言本身可以稳定运行。某些显而易见的情形,如:
new Thread(function() { console.log(""Hello, threads!""); });
会需要对某个 DOM 对象拥有并发访问权限。在 Webkit 里,_DOM 全局对象_会负责存储 window 里的变量状态。普通全局对象的 JS 属性(包括 console、Object 等等) 需要能够被并发线程所访问,因为那些属性是脚本的全局变量。来自其他线程对全局对象的其他属性(exotic properties),或是全局对象原型链的属性的访问,将会抛出。尝试从非主线程往全局对象里添加新属性或者删除属性同样也会抛出。这些约束意味着在 Webkit 中,处理 DOM 全局对象的有限类型的并发属性访问权限,相较于处理普通 JS 对象的同样权限来说,不会难太多。
而且,namespace 对象,像是 console,可以被并发线程访问,因为他们刚好可以使用 JS 对象模型。没有理由对主线程限制他们,另外,对于console 来说,能被访问非常重要,因为它具有 debug 的功能。
Strawman 总结
这一部分主要提出了 Javascript 语言线程的 strawman API,这套 API 足够用来实现自定义同步操作,它也足够强大,能够允许竞争程序的执行,但它还没有允许竞争到能够打破语言(限制)的程度。线程的适用性足以能够基于这些功能来实现出许多其他的编程模型。
在 Webkit 中实现并发 JS
这一部分展示了我们可以实现自己的基于线程的 strawman,而不用关闭任何 JavascriptCore 在基础性能优化。我们的计划旨在达成接近零开销的目标,即使是在多线程同时读写同一个对象的情形下。
Javascript 和 Java、.Net 之类的语言有许多共同点,就是已经支持线程。这里给出一些这几种语言和 Javscript 有共性的地方:
-
像 Javascript 一样,那些语言使用基于追踪的(tracing-based) 的垃圾回收器。我们的垃圾回收通常支持多线程,因为 JIT 线程已经允许读取堆。最大的缺失部分是 线程局部分配(thread local allocation),这能使并发分配成为可能。对于我们的垃圾回收机制来说,这意味着每个分配器(allocator)在每个线程上仅有一张独立的
FreeList。垃圾回收器拥有固定数量的分配器,而且我们已经有了快速的线程局部存储,因此这会是一个机制上的改变。 -
像 Javascript 一样,那些语言由多层 JIT 机制实现,也许还有一个解释器。我们的 WebAssembly VM 已经支持了从 BBQ(build bytecode quickly) 到 OMG(optimized machinecode generation) 的多线程层排列(multi-threaded tier-up)。在 Javascript 上,这些才能正常运行。
-
如 Javascript 的实现一样,这些语言使用内联缓存技术(inline caching) 来加速动态操作。我们需要对我们的内联缓存做一些修改,使其能够支持并发,我们会在本文的后面部分描述这些改变。这不是添加并发机制最困难的部分,因为这不是什么新玩意 ———— 以前实现过。
这些相似性暗示很多已经应用在 Java 虚拟机上的用以支持并发的技术可以被重用在实现 Javascript 的并发上。
真正困难的部分在于 Javascript 动态重新配置对象的能力。在 Java 和 .Net 这里,它们有固定大小的对象(一旦分配,对象不会改变大小),而 Javascript 对象则会变成可变大小。静态类型语言的并发,依靠的是对固定大小对象并发访问时,做的是由机器指针长度决定的_默认的原子化操作_(因此,64 位系统默认情况下会执行原子化的 64 位原子访问)。Java 和 .Net 中的指针值是储存对象数据的连续内存切片,它只会做一些地址上的算术处理(比如添加一个偏移量),并且只让单个内存指令读写某个字段。即使内存模型允许意外的重排序,对同字段的竞争访问指令(或是同对象的不同字段)污染整个对象或者引起崩溃的情形决不会发生。但是,Javascript 的可变大小对象意味着,在某些情形下,对象访问需要多个内存访问指令,一系列包含对内存多次访问的操作默认情况下不是原子化的。在最坏的情况下,由于内部对象状态被污染了,虚拟机发生崩溃。即使这没有发生,竞争会引起写操作丢失,或者发生时间旅行(对某个字段先写入 A 再写入 B,会引起对该字段的读操作发生先看到 A,然后是 B,然后又看到 A)
在我们的 strawman 提案中,并发 Javascript 代表着基础操作,例如向对象添加新属性、改变属性的值、读取属性以及删除属性,全都是以原子化进行的。没有竞争应该导致虚拟机崩溃、丢失写入、或者属性值发生时间旅行
我们提出了一种算法,它允许大多数的 Javascript 对象访问是_不用等待的_(wait-free),并且相较于我们已经存在的序列化 JS 实现来说需要最小的开销。不用等待的操作执行的时候不会阻塞,而且会在有限步数里执行完毕而不用去考虑竞争。这个算法借鉴了实时垃圾回收、锁算法以及类型引用的算法。我们计划使用分层防御(tiered defense) 来防止并发的开销:
-
我们提出使用既有的基于多态内联缓存(polymorphic-inline-cache-based) 的类型引用系统,以得到对象(和它们的类型)在线程域上的不严格概念,这些对象我们称它们作_过渡线性局部_(transition-thread-locality,TTL)的。TTL 对象会使用和今天一样的对象模型,对这些对象的访问的会非常接近零开销。TTL 并不表示真正的线程局部(thread-locality),例如即使是会被多个线程读写的对象也可以被当作是 TTL 的。
-
我们提出使用_碎片化的_(segmented) 对象模型,这样的对象模型适用于不满足 TTL 推论的对象。这个模型会在属性访问的快速路径上引入一个额外的加载指令,以及一些算术操作。我们担心这项技术本身不足以快到满足我们的性能目标 ———— 但因为碎片化的对象模型只会被精准地应用在不满足 TTL 推论的对象(或其类型)上,我们怀疑_网络_代价足以小到应用在实际案例中
-
对于不会受益于碎片化对象模型的非 TTL 对象而言,对它们的操作会使用锁。在我们开发 Riptide 高并发垃圾回收的时期,我们对每个对象添加了一个内部锁。这个锁仅仅占用两个字节,同时允许加锁/解锁快速路径以要求一个原子化的比较交换(compare-and-swap, CAS) 和一个分支。
在进入更多细节以前,我们首先会给出一些硬件要求,我们提出的系统会跑在这样一套硬件上。接下来我们会倒过来描述这个提案,只考虑使用预对象锁(pre-object locking)的代价。然后我们会回顾现存的 JSC 对象模型,并且阐述什么样的操作在这个模型里刚好是原子化的。下一步,我们会引入_segmented butterflies_,它是允许动态重配置对象的关键点。之后我们会继续展示 TTL 模型是如何让我们在大部分的 Javascript 堆上使用现存的对象模型。这个部分会考虑一些开放式的后续,像是怎么去并发地做一些内联缓存、可变大小的数组是怎么适用在 TTL 和 segmented butterflies 上的、怎么使用_本地优化锁_(local optimizer lock,LOL) 来处理大线程计数,以及怎样处理不是线程安全的本地状态。
硬件要求
本文阐述了怎么把 JavascriptCore 转化成支持并发的 Javascript,JSC 目前是为 64 位系统来优化的,绝大部分的并发支持(并发 JIT,并发垃圾回收)只在 64 位系统下生效。这一部分简要总结了我们希望从 64 位系统得到什么收益,以能够应用我们的计划。
JSC 是为 x86-64 和 ARM-64 来优化的,本计划的假定基于这两者内存模型中更弱的那一个(ARM-64),同时还假设以下原子化指令开销小到能够足以应用于在实践中将它们作为一种锁的优化:
-
64 位的读写默认情况下都是原子化的,我们期望这些访问可以围绕其他访问被记录下来。但我们也希望,如果内存访问指令 B 对内存访问指令 A 存在数据流上的依赖,那么 A 将总是在 B 之前出来。比如说,在一个存在依赖的链式锁上,像是
a->f->g这样,a->f将总是在_->g之前执行。 -
64位的 CAS(compare-and-swap)。JSC 使用 64 位的单词作为 Javascript 的属性和对象头中的两个重要的元数据字段:type header 和 butterfly pointer。我们想要原子化地比较和交换(CAS) 任意 JS 属性,以及对象头中的任一元数据属性。
-
128 位 DCAS(double-word compare-and-swap)。有些时候,我们会想要比较和交换(CAS) JS 对象里面的所有元数据,也就是说比较和交换(CAS) 64 位 type header 和紧邻的 64 位 butterfly pointer。
单个对象锁(Per-object Locking)
JSC 中的每个对象已经有了一个锁,我们用这个锁来同步某些基础的含垃圾回收的 Javscript 操作。我们可以使用这个锁来保护任意需要在 Javascript 线程间同步的操作。本文的余下部分会探讨如何优化才能让我们避免这种锁,但先让我们仔细想想这种锁的代价是什么。我们的内部对象锁算法要求给加锁准备一个 CAS 和分支,给解锁准备另外一个 CAS 和分支,最好情况下,CAS 大约会执行至少 10 个周期,这是假定 CAS 成功前提下的平均开销。在某些硬件设备上,开销会更大。假设一个分支是一个周期,那就是说,对于需要锁机制的每个对象操作,至少会有 22 个额外周期。虽然一些罕见的操作开销已经足够大了,相对来说 22 个周期还行,但是许多快速路径操作(path operation) 将无法处理这样的开销负荷。以下我们想到了一些操作,以及如果它们要使用锁的话,它们会受到多大的影响:
-
目前添加一个新属性只需要一次加载、一个分支,以及在优化快速路径上的两次存储。每一个操作都是一次单个周期,因此最快情形下总共会有 4 个周期。加了锁机制以后一下会飙升到 26 个 ———— 会变慢大约 7 倍。在某些情形下,添加一个新属性可以被优化到仅需单次存储,这个例子里,加锁会变慢 23 倍
-
修改已有属性的值需要一次加载、一个分支,以及一次存储,最快情形下也就是三个周期。加两个 CAS 和两个分支会变成 25 个周期 ———— 变慢 8 倍。某些情形下,我们可以把属性的存储优化到只需要一次存储指令,加锁以后会慢到将近 23 倍。
-
加载已有属性的值需要一次加载、一个分支,以及一次额外加载,加锁以后会慢 8 倍,某些情况下优化到单一加载指令的话会慢 23 倍。
-
删除属性已经很慢了,因此加锁其实也能接受,删除属性相对来说不太常见,但我们还是要支持该操作。
-
字典查询 ———— 不用任何内联缓存或编译智能动态执行的属性访问 JSC-speak ———— 会在锁机制中见到一部分小小的间接开销。那部分代码路径开销已经挺大了,因此加锁不太会是一个额外的问题。
-
为属性集做快照没有变化。让并发线程为 JSC 的任何对象的属性集记录快照是完全有可能的,因为我们已经为并发垃圾回收实现了锁机制。
尽管某些操作的开销,比如删除,大到了锁机制不会成为额外的问题,但我们认为对 Javascript 对象访问中的快速情形,额外带来这么多的代价是不切实际的。那样,加锁以后的编程语言就太慢了。
设计一个快速高并发的 JS 实现需要引入对属性访问的新算法,这种算法可以并发地在各自线程上运行,而不需要任何锁机制,除了在一些罕见的情况下。在接下来的部分,我们会阐述这样的一种算法。首先,我们回顾 JavascriptCore 的对象模型;然后我们会展示一些例子,在这些例子里,JavascriptCore 的对象模型的工作方式就好像是已有固定大小的对象一样,这些情形从不需要锁;然后我们会展示一种叫做_segmented_(分片) butterflies 的技术,它能允许绝大多数不用等待的并发对象访问。仅仅单一地使用该技术对于我们的要求来说还是开销太大了,因此,我们会展示怎样去判断哪些对象类型是 transition-thread-local(TTL) 的,以避免传递对象时的同步,它允许我们对大部分对象使用扁平化的(flat) butterflies (现有的对象模型)。接着,我们再讲怎么处理删除、字典查询、内联缓存、数组,以及线程不安全的对象。
JavascriptCore 对象模型
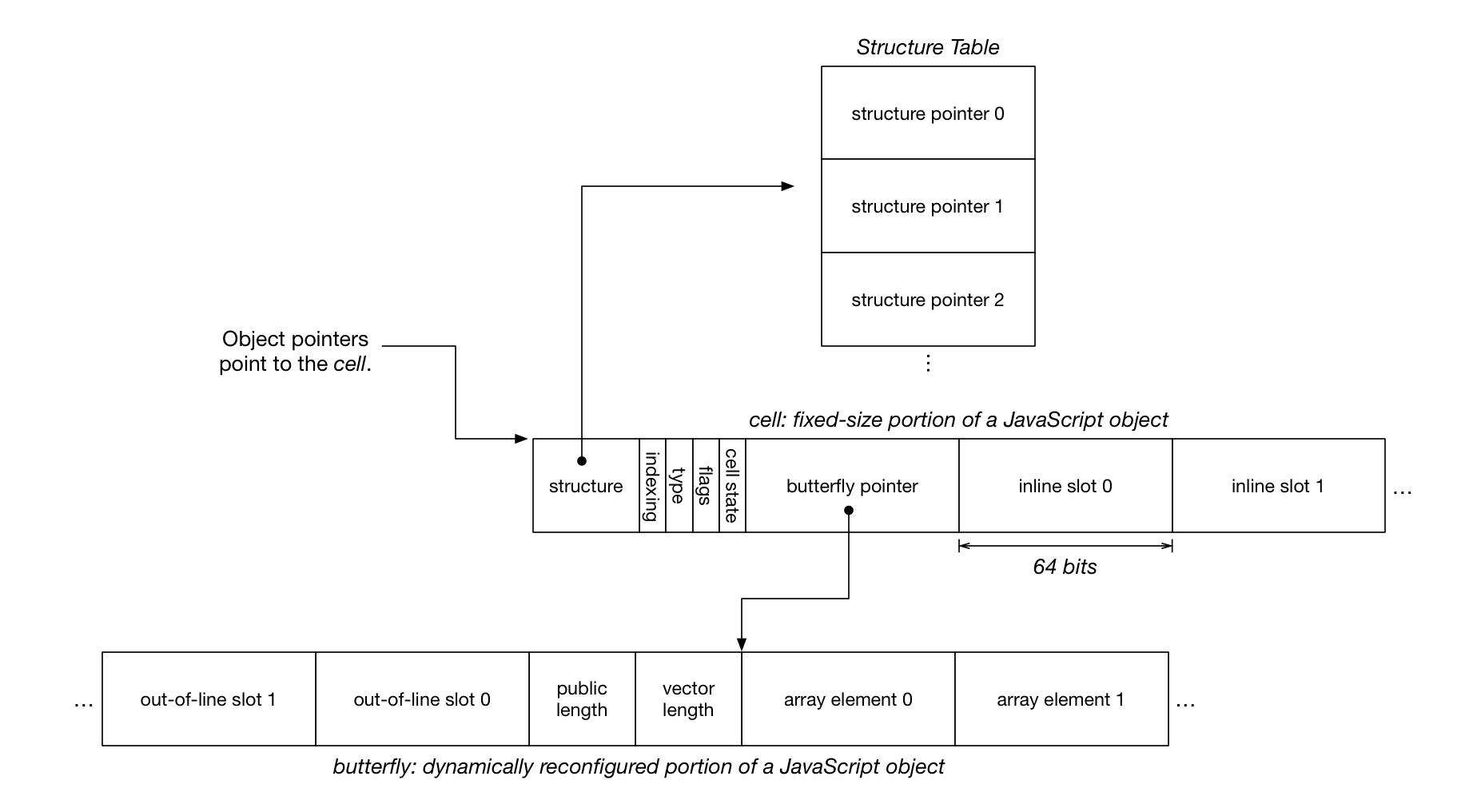
JavaScriptCore 对象模型. Javascript 值和对象指针是由指向 cell 的指针实现的,cell 不会改变位置,也不会大小,但会包含一个指向 butterfly 的指针,这个指针可以向左(对于含名属性,named properties),或向右(对于数组元素)。
JavascriptCore 的对象模型允许四种状态,每一种都是可选的:
-
本地状态代表使用普通 C++ 对象
-
对象可能包含的命名属性的数据(如
o.f) -
动态添加的对象命名属性的数据,强制改变对象的大小
-
对象索引属性的数据,它们能以多种方式改变对象大小
前两种类型的状态不会改变对象的大小,后两种则会改变对象大小。在 JSC 里,固定大小的状态直接存储在对象的_cell_ 里,这里的 cell 的对象指针指向的东西。在 cell 里面,有一个能被用来存储在某个_butterfly_ 中动态分配和可变大小的状态的 butterfly 指针。butterfly 存储 butterfly 指针指向 out-of-line slots 位置左侧的命名属性,同时还存储_数组元素_右侧的索引属性。每一个位置可能存储一个带标签的 Javascript 值,这个值可以是数字、指向另一个 cell 的指针(代表字符串、symbol、或对象),或是一个特殊的值(true、false、null或者undefined)。
每个对象有一个 structure,它包含了用来把名字映射到对象的槽的哈希表。对象一般会和相像的其他对象(这些对象拥有同样顺序的相同属性)共享一个 structure。structure 是在一张 structure 表中,使用 32 位索引来引用的,我们这么做是为了节省空间。索引 和 _cell 状态_字节会有几个多余的位(bit)。我们用两个在_索引_字节里多余的位来支持单个对象锁,同样,我们也使用 _butterfly 指针_里的多余位,因为指针不需要 64 位系统上的全部 64 位。
butterfly 是可选的。许多对象没有 butterfly。当一个 butterfly 被分配的时候,它的任意一边都是可选的。butterfly 的左边容纳了 out-of-line slots,可以只分配这个 out-of-line slots;在这种情况下,butterfly 指针会把 8 字节指向 butterfly 内存末端的右侧。butterfly 的右侧包含了数组元素和数组头部(原文 array header,可能是指数组头指针?译者注)。所谓_公共长度_是指从 array.length 来的长度,而_向量长度_是指数组元素 slot 被分配的数量(这里的数量可能是指内存大小,译者注)。
Freebies
在对象模型中,对 cell 里面任何内容的访问默认是原子化的,正如对 Java 对象的访问默认是原子化的一样。这很重要,因为我们的优化策略在把最重要的对象字段放到 cell 里这个意义上基本成功的。大部分依赖在 cell 里结束的数据的并发 JS 程序会体验到几乎零额外开销,相对于他们的序列化等价变量来说。
而且,如果我们知道 butterfly 不会被再次重新分配的话(例如,butterfly 指针是不可变的),那么我们可以直接访问它,没有任何问题。那些访问默认下自然是原子化的。
或者,如果我们知道只有当前线程会改变 butterfly 的大小,所有其他线程只会读取 butterfly,那么对 butterfly 的访问默认也是原子化的。
当线程尝试 transition 一个对象(例如,添加属性,且/或重新配置 butterfly),同时另一个线程在对其写入的时候(或者也在 transition 它),问题出现了。如果我们使用当前在并发设置里对对象访问的实现,在一个线程上的 transition 可能引起竞争,这会导致行为不符合我们预期的特定行为。
-
另一个线程发起的写操作会消失,或者发生之前提到过的时间旅行。竞争之所以会发生是因为当另一个线程在这两个步骤之间做写操作的时候,对线程做 transition 会首先对 butterfly 做一个拷贝,然后 transition 对象。如果有第三个线程在观察,不断重复读取写入字段的状态发生了什么,那么它首先会看到任何写操作之前的状态,然后是写操作,紧接着一旦 transition 完成,它将再次看到初始的状态。
-
并发地执行两次 transition 可能引起 butterfly 指针和对象的类型不匹配。butterfly 的格式是由对象头部里的字段决定的,这个对象头部并不像 butterfly 指针那样是存储在同一个 64 位单词里的。我们不能允许 butterfly 和头部发生不同步,因为这会导致内存污染(memory corruption)。
-
并发执行两次 transition 会引起某个微小的堆污染,即使是在 butterfly 没有参与的情况下。如果一个 transition 将内联属性分成两步 ———— 首先,改变对象类型,然后,存储新的属性 ———— 那么两个添加两个不同属性的竞争 transition 可能导致一个属性加上去了,它的值由另一个属性的期望值结束。比如,
o.f = 1和o.g = 2之间的竞争可能导致o.f == 2和""g"" in o == false。
下一部分中,我们会展示如何创建一个没有这种竞争的对象模型,但会有些代价。之后,我们会展示如何在大部分情况下,甚至是在线程间共享对象的程序里,使用 TTL 推断来使用我们现有的对象模型。
Segmented Butterflies
对一个对象做 transition 表示分配一个新的 butterfly,并且在其它线程可能在旧的 butterfly 上读或写的时候,把之前 butterfly 的内容拷贝到新的里面去。我们想要拷贝出来的副本看上去就像是发生在原子化操作中一样。很多研究已经开始支持在实时垃圾回收的上下文中并发拷贝对象。我们提出的这种方法基于 Schism 实时垃圾回收器的 arraylet 对象模型。这一部分部分会回顾 arraylet 对象模型,然后展示怎样将其用作 butterfly transition。
Schism 一直致力于想要解决实现一个拷贝垃圾回收器的问题,它的拷贝阶段对应用来是完全并发的。这是基于这样一种观察:将该对象并发地拷贝至读取它的其他线程,在该对象是不可变的情况下挺简单,只有当该对象会被写入其他线程的时候,拷贝才会变得困难。Schism 通过将可变状态封装在一个小小的固定大小的 fragments (32 位)中,解决了并发地拷贝_可变_状态的问题。被拷贝的对象实际是作为查询 fragments 索引的 spine (个人理解有点像指向指针的指针,译者注)。所有对象访问都使用一个额外的间接方式来查询 fragment,这个 fragment 包括了被访问的数据。这里的 Spines 是不可变对象因为它们所指向的 fragments 从不改变位置。
Webkit 也已经使用一些像 arraylets 之类的东西,它们是在 WTF::SegmentedVector 类模板里。在向量大小改变的时候,我们用它来不让 C++ 对象改变位置。我们也用它来实现 JSGlobalObject 的变量存储(全局下的 var 语句)。术语 arraylets 来自 Bacon, Cheng, and Rajan,他们使用 arraylets 来控制 Metronome 垃圾回收器的 fragmentation。很多 arraylet 的研究显示额外的间接指令会产生很大的开销(一般是 10% 甚至更多)。也就是说,如果你把加了一条额外间接指令的数组访问开销翻倍,那么你会把程序的全部运行时间增加 10%。
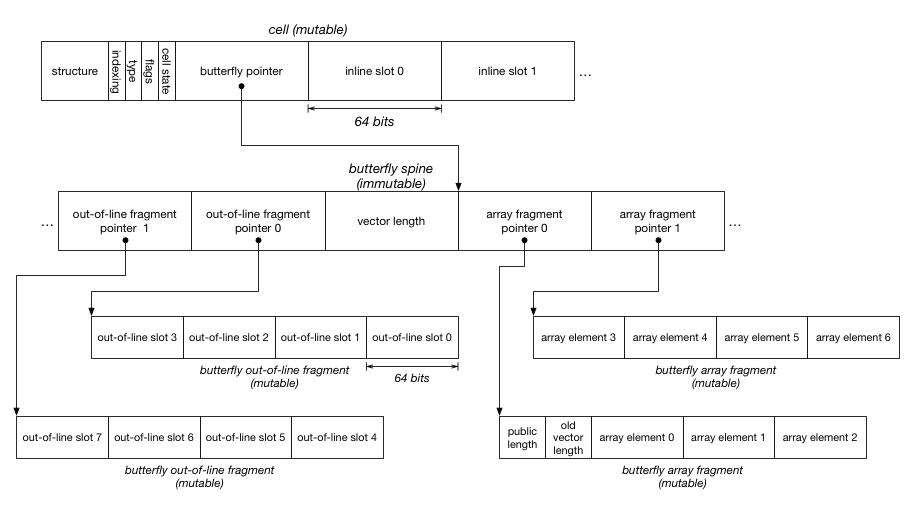
Segmented Butterflies. segmented butterfly 由一个 spine (它会改变大小但只包括不变状态)和 0 个或多个 fragments (它不改变大小但是可变的) 组成。将改变大小的状态从可变状态中分离出来,可以使并发布局的改变是一个在并发垃圾回收中可信的技术。fragment 的形状可以匹配未 segemented butterfly 的形状,我们将会使用它做一些额外的优化。
我们可以将这种技巧应用于 butterfly。一个 segemented butterfly 有一个 spine,它包括了指向含有可变数据 fragment 的指针。如果我们需要添加新属性,并且那些属性不满足现有的 fragment,那我们可以扩展 spine 且分配 更多的 fragment。扩展 spine 是指重新分配它。我们可以安全地分配一个新的 spine,然后把旧的内容 memcpy(应该是 memory copy,类似 C 里的 memcpy,译者注)进去,因为 spine 的内容从没改变。在这个世界里,当某个 butterfly 被 transition 的时候,没有写操作会丢失或历经时间旅行。和 transition 竞争的访问要么用旧的 spine,进到 fragment 里去,要么用新的 spine 进去;因为这两个 spine 都包含了同一块 fragment 属性地址,这些属性在 transition 以前就已经存在了,每一次可能的交错都会导致线程读写相同的 fragment。
实现 segmented butterfly 最自然的方式可能是用像 Schism 里的 32 位切片那样,因为这也是我们垃圾回收中的最有效部分。_向量长度_在 butterfly spine 里面,因为这是那块 spine 的不可变属性。向量长度允许 spine 自己去识别它的右侧有多大。公共长度_是可变的,所以我们想把它放到诸多 fragment 的某一块里面去。注意第一块 fragment 同样包括_旧的向量长度,当我们使用 segemented butterfly 的时候,该属性并未使用。它通过让 spine 指向整块 butterfly (原文 flat butterfly) 的某些切片,让我们把一整块 butterfly 转化为 segmented butterfly;我们会在稍后一些的部分讨论这个优化。
这里还是没有讨论并发 transition 的问题。transition 必须要重新分配 spine、改变类型头部的一些数据,然后储存一个属性值。重新分配 spine 是可选的,因为通常来说,某个 fragment 会有多余的槽。改变类型是可选的,比如在数组改变大小的情境下。类型头部和 butterfly 可以用 DCAS(double-world compare-and-swap;64 位系统一般都支持 128 位 CAS) 去原子化地设置,但这还不够,因为无论我们是否在 DCAS 之前还是之后设置了属性值,我们都会有一个竞争。属性槽可以是内存中的任何位置,因此不可能去同步地用 CAS 完成整个 transition。
如果我们在改变任意内容前设置新加的值 slot,那就会有竞争风险,在该竞争中,一个线程企图使用某个对象 slot 以添加字段 f,而另一个线程试图使用同一个 slot 的字段 g。如果不仔细的话,第二个线程可能赢得类型的竞争(所有人以为加上了属性 g),而第一个线程赢得了属性的竞争(也就是说线程 1 里希望对属性 f 修改的值出现在了线程 2 里,就好像是设置给线程 2 的属性 g 一样)。
如果我们在所有修改完成后去设置新添加的值,那么所有的加载不得不去防止这样一种可能性,那就是 slot 会有 ""holes""。换句话说,在任何时间,某个对象可能声明了一个包含属性 f 的类型,即使该对象还没有给 f 的值。我们可以调整以让语言允许这种操作:把一个新属性放到对象里,会首先将其定义为 undefined,然后存储真实值。
我们选择用锁包裹信 transtion,这个锁不是为了保护 transition 和其他访问的竞争,因为通过 segemented butterfly 的作用,它们是默认原子化的 ———— 它是为了保护 transition 之间(的竞争)。为了确保对象没有 hole,transition 在改变类型前存储新属性的值。transition 可以使用这样的算法:
-
无论内存需要被分配什么,都执行分配
-
请求锁
-
决定是否分配了正确数量的内存;如果没有,释放掉锁然后返回步骤 1
-
储存新属性的值
-
改变类型和 butterfly
-
释放锁
这不形成了以下的开销模型:
-
transition 的代价大概会变成 7 倍,因为现在它们需要锁了
-
读写已经属性 slot 需要一次额外的加载
-
删除和字典查询还是能正常工作(我们会在之后的部分详细描述细节)
回忆一下,arraylet 的研究表明如果数组使用了 segmented 对象模型,代价会增加 10% 或更多。我们也想对普通属性使用它,如果那些属性被以一种足够微妙的、我们无法在 cell 里内联它们的方式被添加的话。假定我们从字面上被实现了这部分功能,我们承受了至少 10% 的性能降速。我们想要的是接近零开销,下一部分会讲述我们达成这项目标的方法。
Transition Thread Locality(TTL) 与 Flat Butterflies
Segmented butterflies 只有在这些时候是必要的:
-
除了分配对象以外的某个线程,试图 transition 对象的时候
-
被分配对象的线程尝试 transition 该对象,而且其它线程可能在写入的时候
我们可以用整块的 butterfly (flat butterfly) ———— 我们现在的对象模型 ———— 在我们知道这些可能性还未发生的时候。这部分会讲一种混合的对象模型,它使用 flat 或 segmented butterfly,取决于我们是否检测到可能的写 transition 的竞争(write-transition races)。这种对象模型也让我们可以在执行多次 transition 避免锁机制。
在 64 位系统上,butterfly 指针有 48 个位的指针信息,在高 16 位上都是 0。16 位足够用来存:
-
分配对象的线程 ID。我们把它叫做 butterfly TID。
-
有一个位用来表示,除了分配线程以外,是否还有其它线程尝试向 butterfly 发起写操作。我们把它叫做 butterfly shared-write(SW) 位
一些系统有不止 48 个指针位. 在之后的部分,我们会讲即便我们能用的位更少,怎么让这种做法起作用。而且,我们会把 butterfly 的分配限制到低于 248 个地址,如果我们真的想要 16 个多余位的话。
假设被以如下方式编码:
static const uint16_t mainThreadTID = 0; // 某些情况下,我们可以对主线程优化地更多一些
static const uint16_t notTTLTID = 0x7fff; // 对于线程不再是 TTL 的情形
static inline uint64_t encodeButterflyHeader(uint16_t tid, bool sharedWrite)
{
ASSERT(tid <= notTTLTID); // Only support 2^15 tids.
return (static_cast<uint64_t>(tid) << 48)
| (static_cast<uint64_t>(sharedWrite) << 63);
}
static inline uint64_t encodeButterfly(Butterfly* butterfly, uint16_t tid, bool sharedWrite)
{
return static_cast<uint64_t>(bitwise_cast<uintptr_t>(butterfly))
| encodeButterflyHeader(tid, sharedWrite);
}
我们可以使用 flat butterfly ———— 现有的对象模型 ———— 在任何 TID 匹配当前线程的时候。我们设置了 SW 位,而且使用了一个 magic TID 值(所有的位都被设置了)来表明 butterfly 被 segmented 了。这部分会展示如何使用这些位,可以在任何我们知道的没有 transition 竞争发生的时间,来容许 flat butterfly 的使用。我们把叫做 transition thread locality 推断。
任何时候,当一个线程尝试写入 butterfly,并且 TID 匹配当前线程的时候,它可以简单地向 butterfly 写入,而不用做任何特别的事情。
任何时候,当一个线程尝试写入 butterfly,TID 不匹配,但 SW 位被设定的时候,它也可以简单地向 butterfly 写入。
任何时候,当一个线程尝试读取 butterfly,它只需要检查 TID 以确认该读取是否应该被 segmented (额外间接指令)。
任何时候,当读写操作遇到 TID = notTTLTID,且 SW = true 的时候,它知道该使用 segemnted 对象模型了。
下面的情况需要特殊处理:
-
某个线程,除了被 TID 标识的那个,尝试写入 butterfly,且 SW 位还未设定,这种情况下,它需要设定 SW 位。这并不意味着 butterfly 需要被 segement,这只是说 SW 位必须被设定,因此任何未来从运行线程(owning thread) transition butterfly 的尝试都会触发向 segmented butterfly 对象模型的 transition。
-
某个线程,除了被 TID 标识的那个,尝试 transition butterfly。这种情况下,它需要设定 SW 位和所有的 TID 位,并进行一次 segmented butterfly transition。我们会在下面具体描述该过程。
-
某个线程尝试 transition 设定好 SW 位的 butterfly,这也会强制做一次 segmented butterfly transition。
-
即使是 TID = current 且 SW = false 的 transition 也需要锁,以确保在 transition 过程中假设不会被违背。
接下来的部分会更进一步展示更大程度上减小开销的提炼内容。首先,我们考虑怎么避免在每次操作中都去检查 TID 和 SW 位。然后我们展示怎么使用 structure 检测点来避免在最常用的 transition 上的锁。接着展示怎么处理数组重设大小。最后我们会解释 flat butterfly 是如何能被 transition 成 segmented 的更多细节。
快速检查 TID 和 SW 位
这部分将展示如何通过简单地扩展 JavascriptCore 已经使用的优化方案,让并发 JS 和串行 JS,在大多数重要情形下一样快。
JSC 使用_内联缓存_来优化访问堆的代码。 我们使用内联缓存来访问命名属性(像 o.f)和访问数组(像 a[i])。
在相同偏移量下,有同样属性的对象通过会共享同一个 structure,它通过对象类型头部的 32 位来识别。倘若一个属性访问可能看到同样的 structure,那么我们会为这次属性访问生成新的机器码,它会检查对象是否有期待的 structure,然后直接访问属性,错误的判断会引发内联缓存的重新编译。如果内联缓存在很长一段时间保持稳定(没有重编译太多次),并且包含它的函数符合优化的 JIT 编译条件,那么最佳 JIT 编译器也许会在它的 IR 上直接表达成内联缓存的代码,这会有两种结果:如果失败(引起优化代码执行的突然终止),structure 检查会被分流到 OSR 出口,并且所有内联缓存的代码(structure 检查、内存访问、其他步骤)都会具有用我们的 DFG 和 B3 JIT 编译器 pipeline 来低级编译的资格。我们的编译器擅长出色地执行类型稳定的 Javascript 的属性访问。
数组访问使用类似的技术来检测对象是否有数组元素,如果有,它们是怎样被格式化的。我们支持数组元素的多种存储,这取决于它们被使用的方式。内联缓存检测每个数组正在访问哪种数组,然后,我们可以发送推断出该种数组访问的代码。
另一种我们已经在使用的技术是虚拟内存。举个例子,我们的 WebAssembly 实现方案 使用虚拟内存技巧来免费地检查线性内存访问的边界。我们可以用 POSIX 信号处理器,或 Mach 异常来抓取页面错误。这个处理器会在发生错误的时点上知道确切的机器状态,也有能力转化执行成它喜欢的任何状态。WebAssembly 会用这种方式来抛出异常,但我们可以用它来把控制流转换到缓慢路径上去,这些缓慢可以处理内存访问的一般情形。从本质上说,这意味着我们可以在安全检查上保存周期,如果我们可以把检查条件表达出来的话,这里的条件是指某样能引起虚拟内存系统发布页面错误的地方。并发 JS 需要内联缓存和虚拟内存技巧相结合来使得 TID 和 SW 检查代价不要太大。
内联缓存指的是对于每个属性访问发射不同的代码,然后当我们了解到这个属性访问可以做什么的信息的时候,可能会多次重新编译每个每个属性访问。内联缓存能够每个属性访问行为的极为精确的信息,这是因为我们问题传输一个快速路径访问,这条路径仅会处理那么我们至今为止看到的实际例子。我们通过记录了解的这条路径上失败的所有内容来获取新信息。访问失败的完整日志之后会被 LUB (least-upper-bounded) 以创建一个AccessCase 的最小集合。我们可以给新型的属性访问实现优化 ———— (这些属性访问)如必须检查 TID 和 SW 位的那些 ———— (要实现这种优化)我们应该考虑一个特定的访问地址可能以何种方式显得特殊而要专门去优化它。下面是一张我们可能遇到的列表,里面列出了内联缓存是如何测试这个条件并处理它的策略:
-
可能很多对象访问问题会发现 TID = current 且 SW = false。这些访问只要在进行之前从 butterfly 里扣掉
encodeButterflyHeader(currentTID, 0)这部分就好。如果推断出错了,虚拟内存子系统会因为非零高位而发布一个页面错误。我们可以捕获这个错误,将其作为一个 Mach 异常或是 POSIX 信号,并将执行转移到慢路径上。这个常量的扣除经常经常会直接编码在后面的 butterfly 访问指令里,因此,这些类型的访问,相较于目前有的东西来说,不会体会到任何并发 JS 中的过多开销。注意,这种优化手段不会应用到 transition,当原子化地声明没有不好的情况发生的时候,transition 必须安装一个新 butterfly ———— 我们会在下面进一步考虑那些问题。注意,这种优化会稍稍有利于主线程(以及所有单线程的程序),因为如果 currentTID = 0,那么我们不用添加任何东西。 -
可能很多对象访问会总是看到 TID = current 且 SW = true。这些问题可以和前一种情形采用同样的优化策略。我们可以从很多线程中向我们已经知道的对象状态进行写入,但那只会在最后一次当前线程 transition 对象之后发生。
-
可能很多对象的读操作会发现 TID != notTTLTID 且 SW = 任意值的情况。这种情况下,我们只需要去检查 butterfly 的高位不是 notTTLTID,这可以由单一的 compare/branch 来完成。除此以外,它们也可以继续我们在当前引擎里执行的方式。
-
可能很多对象的写操作会发现 TID != notTTLTID 且 SW = true 的情况。这意味着对象正在被很多线程写入,我们也在对它写入,但我们不需要设置 SW 位因为它已经设置好了。这个检查同样可以由 compare/branch 来完成。和上面的读操作优化一起,这表明共享对象的 JS 程序通常只会遇到一个给 butterfly 访问的额外周期(这个周期是给融合的 compare/branch 的)。
-
有时候,一个对象的写操作会发现 TID != notTTLTID 且 SW = false。这表示需要使用 DCAS 来设定 SW 位,DCAS 会在声明类型头部不改变的时候设定 SW 位。这些访问会比它们的朋友有更大的代价,但这只会在第一次任何线程写入共享对象的时候发生。我们内联缓存设施可能会这么做,以使得写入会是 branchy 的,这里的写入有时会看到 SW = false,有时会看到 SW = true(而且不一定会看到 TID = current,但决不会是 notTTLTID):会有一条快速路径给 SW= true,以及稍微慢一点但是内联的路径给 SW = false。在下一节,我们会描述需要唤醒 structure 上函数的优化方式,在该 structure 的任意对象的 SW 位被首次设定的时候。因为内联缓存在生成的时候知道其 structure,所以它能保证 structure 已经被告知了其类型的对象可能要设定 SW 位。
-
可能很多对象访问会发现 TID = notTTLTID 且 SW = true。照常理来讲,我们觉得不太可能发生 TID = notTTLTID 且 SW = false 的情况(在我们的 VM 内部,transition 一个对象而不""writing""它在技术上是可能的,但我们假装认为它们是写入)。这部分访问会在进行前从 butterfly 里扣除
encodeButterflyHeader(notTTLTID, true),然后它们必须在从 butterfly 读取的时候执行一次额外的加载,这次额外的加载是必要的,因为 segmented 对象模型:butterfly 指针指向一个 spine,我们可以用这个 spine 来查询包含我们关心的值的 fragment。这比一次额外加载的开销稍微多些,因为它引入了一个 load-load 依赖。
这些优化留下了未解决的问题:transitions。transition 现在需要请求和释放锁。我们必须在所有我们添加任何属性的时候都能这样做。下一节,我们会展示怎么使用_watchpoints_解决这个问题。然后我们会讲怎么实现需要创建在 flat butterfly 之外的 segmented butterfly 的 transition 的方法。
Watchpoint 优化
transition 很难优化。每一个 transition,包括那些发现 TID = current 的 transition,需要请求对象的内部锁,以确认设置了 butterfly,调整了对象的类型头部,且在一个原子操作步中存放了新的属性值。幸运的是,我们可以通过 使用我们的引擎 structure watchpointing 设施来极大地提升 transition 的性能。
每个对象都有一个 structure。很多对象会共享同一个 structure。大部分内联缓存优化从一个检查开始,它会去检视对象的 structure 是否匹配内联缓存的期望。这表示当内联缓存被编译的时候,它有一个指针指向当前对象的 Structure。每个 structure 都有任意数目的 watchpoint 集。一个 watchpoint 集就是一个 bool 型的字段(从 valid 开始,变成 invalid),和一组 watchpoint。当这个集合被触发的时候(字段从 valid 变成 invalid),所有的 watchpoint 都被唤醒。我们可以向 Structure 中添加两组 watchpoint 集:
-
transitionThreadLocal. 只要所有含有这个 structure 的对象有 TID != notTTLTID,这就能保持有效 -
writeThreadLocal. 只要所有含有这个 structure 的对象有 SW = false,这就能保持有效
这使得下面的这种优化在内联缓存的优化策略中是上面描述的最佳策略:
-
满足 TID = currrent 和 SW = false 的 transition 可以像它们在现有的引擎里那样工作,只有 structure 的
transitionThreadLocal和writeThreadLocalwatchpoint 集都还是有效的。这就是说,在做 transition 对象的时候,不用任何额外的锁或 CAS,即使其他线程正在并发地读取对象的时候,这也可以正常工作。甚至在组装一个最终会被读写的对象的时候,这也是有用的,因为在这种情况下,writeThreadLocalwatchpoint 集只会触发用来组装对象的最终 transition 目标的 structure。最后的 transition 可以继续工作而不用锁,因为 transition 源的 watchpoint 集仍旧是有效的 -
如果 structure 的
transitionThreadLocalwatchpoint 集仍旧有效,且一个 watchpoint 已经安装的话,任何检查 TID != notTTLTID 的部分都可以删除 -
如果 structure 的
writeThreadLocalwatchpoint 集仍旧有效,且 watchpoint 已安装的话,所有检查 SW == false 的部分都可以删除
对于可以删掉 TID != notTTLTID 和 SW == false 检查这样的结果来说,这表示对这些对象的读写实际上不用检查任何东西,它们只需要屏蔽掉 butterfly 的高位就可以了
最重要的是,这意味着只要包含的 structure 具有有效的 transitionThreadLocal 和 writeThreadLocal watchpoint 集,那么发生在被分配了对象的同一个线程上的 transition,不需要任何锁机制。structure 是由我们的引擎来动态推断的,这是为了能够紧贴创建那些对象的代码。因此,如果你写了一个 constructor,它往 this 加了很多字段但并没有摆脱 this,那么发生在 constructor 里的 transition 链的相应 structure 都会有一个有效的 transitionThreadLocal 和 writeThreadLocal watchpoint 集。为了确保对象仍然拥有 flat butterfly,你要么别往对象里动态添加属性,要么别往不是构造它的线程上写入对象。遵循这些规则的对象会感受到几乎没有并发负载,因为属性访问将在快速路径上至多只有一条额外指令(一个掩码)
watchpoint 和引起它们触发的操作,会在安全点下执行:如果我们执行了一些操作,它发现必须要让一个 watchpoint 失效,它会在其他线程都停下以后再去操作,就像一个垃圾回收一样。如果某块优化代码正在做含有 structure 的非原子化 transition,同时还有其他线程尝试写入或 transition 使用那些 structure 的对象,那么直到优化代码触及了一个安全点且被无效化后,它才会去实际执行写入。大多数时候,watchpoint 集会告诉我们它们已经被无效化了,甚至会在优化 JIT 编译器试图安装任何 watchpoint 之前。我们希望在稳定态下几乎不会有 watchpoint 无效化。
总结一下,如果我们的优化子能够猜到你会在分配的时候往对象里添加哪些属性,那么对象访问的代价模型根本不会改变,因为内联属性可以免费地获取并发能力。如果你真的有外部属性,那么只要对象只被创建它的线程写入(任意线程读取也一样),或者不在创建之后向对象里添加新的属性(这种情形下可以被任何线程读写),它们会几乎和现有的执行方式一模一样(偶尔,一个额外的算术指令会涉及到计算 butterfly 的读写)。倘若你违反了这种模式,那么 transition 的速度会慢 7 倍,而且所有其它对象的访问都会慢 2 倍。这种衰减是目标非常明确的:只有涉及到 segmented butterfly 的访问会感受到速度减缓。这个系统被设计成能让你动态、并发地往对象里加内容,并且初衷是希望如果你适当地这么做,你会发现没有太多性能上的改变。
Arrays
数组元素访问会从 TTL 获准,类似于命名访问做的事情:
-
对于 TTL 数组的访问和现在的速度一样
-
对于非 TTL 的数组会需要一条额外的间接指令
我们处理数组 transition 的方式会有一点特殊。很多 JavascriptCore 里数组 transition 已经用了锁,因为它们需要避免和垃圾回收的竞争。对剩余的数组 transition 加锁可能会引起性能问题,因此这部分考虑替代方案。
对数组重新分配大小以应对超出边界的存储或是类似array.push的东西是最常见的数组 transition。幸运的是,这种 transition 不会改变对象头部的任何内容 ———— 它只会改变 butterfly 指针。butterfly 是否有数组元素会反映在 structure 上。因此,我们可以只用 butterfly 指针上的 CAS(compare-and-swap),然后制定一条规则,它规定任何对于有数组的对象 butterfly 指针的修改都需要做 CAS 即使对象锁已经在那了。由于数组 structure 的 transitionThreadLocal 和 writeThreadLocal watchpoints 不太可能是完整的(任何共享数组的使用都会使其无效,因为数组共享 structure),我们希望即使在 TTL 数组上的 transition 也需要在一般情况下使用 CAS。这个 butterfly 指针 CAS 足以确保使得非 TLL 数组不会和改变大小的操作混淆,且是同步的尝试。
一个数组改变大小的 CAS 可能对于实际来说代价足够小了。CAS 可能对于当前改变大小的操作来说开销小一点,毕竟目前的改变大小的操作包括了分配、复制数据,以及初始化新分配的内存。
同时有命名属性和数组元素的对象现在在某些涉及命名属性的 transition 上会都有锁和 CAS。还好,具有数组元素和命名属性的对象足够特殊,从而使我们可能避免增长其命名属性 transition 的一点点代价。
从 Flat 到 segemented 的快速 transition
把 flat butterflye 转变成 segmented butterfly 需要一种特殊的 transition。幸运的是,这种 transition 代价不大。butterfly fragment 只有数据,它们看上去像 flat butterfly 负载的 fragment(固定大小的切片)。因此,我们可以通过分配一个 spine 并将其 fragment 指针指向原始的 flat butterfly 来把一个 flat butterfly transition 成一个 segmented butterfly。
当 butterfly 被从 flat 转成 segemented 的时候,任何对于这块 flat butterfly 的读写对于 segmented butterfly 的使用者来说像是发生在 fragments 上一样。也就是说,尽管某些线程可能会错误地认为 butterfly 仍旧是 flat 的,但它们访问 butterfly 仍然是安全的即使在 butterfly 已被 segmented 之后。
让这部分正常工作需要确认 segmented butterfly 的 fragment 要和转化源头的 flat butterfly 一样,共享相同的内存布局。由于这个原因,每一个数组 fragment 包含了公共长度和_旧的_向量长度;它将记入 flat butterfly 一直使用的向量长度,以及将会出现在 segmented butterfly spine 里真实向量长度。这保证了如果在 flat butterfly 数组访问和 flat-to-segmented transition 之间存在竞争,那么 flat butterfly 的访问会正确地知道 flat butterfly 的大小,因为它的向量长度不会改变。为了整理对象模型,我人也会在外部 fragment 里倒序存储外部属性,以匹配 flat butterfly 做的事。
只要 flat butterfly 访问在 transition 发生前就加载 butterfly 指针,那么这种机制就会起作用。如果 flat butterfly 访问加载其指针的时机晚了一点,那么访问的 TID 检查就会失败,可能是在访问 butterfly 的时候,以一种页面错误的形式。
删除与字典查询
JavaScriptCore 想让对象在任何可能的时候共享 structure。这只需要 structure 有两个特性:
-
Structures 是不可变的
-
当需要一个新的 structure 的时候,我们一般会 hash cons 它。
如果它真的可以让对象重用 structure 的话,这是很棒的优化。但有些对象会有其特定的 structure,无论 VM 想对它做什么。JavascriptCore 试图检测这种情况发生的时机,然后把对象放到_字典_模式里面去。在字典模式里,structure 有一个 1-1 的到对象的映射。而且,structure 也会变成可变的。添加和删除属性意味着先后编辑 structure 和对象。
删除和字典模式联系很紧密,因为删除会立即把对象放到字典模式里。
对字典的修改需要保持 structure 锁的状态,这已经是既成事实了。为了支持并发 JIT 和并发垃圾回收,这是必要的。
为了支持并发 JS,我们只需要做以下改动:
-
我字典读取需要保持 structure 锁的状态,以防其他某个线程修改字典
-
对象进入字典模式前添加的属性必须被删除特殊处理
我们不担心获取字典所有的读操作锁的性能问题,相对于读取一个字典来说,其代价会大一点。
现有的安全地 transition 对象的设施会很自然地支持对字典的 transition。通常来说,字典 transition 不包括删除属性。当我们发现程序正在往对象添加巨多属性,以至于它可能比字典表现性能更佳的时候,删除才会发生。在这种情况下,其他某个线程也许正在访问这个对象的过程中而没有保持任何锁,这无关紧要。对于非字典对象来说,我们只需要 transition 有锁就可以了。读写包括了检查对象类型、载入 butterfly、然后访问 butterfly 的诸多独立步骤。但如果没有属性在字典 transition 被删除之前添加进来的话,那么其他线程在访问旧属性的时候发起竞争是没问题的。我们把这种现象叫做迟缓访问(tardy access)。即使 tardy access 不做任何的锁,在对象变成一个字典前,它们是正确的,基于这个相同的原因,它们都是正确的。这个问题取决于 butterfly 对象模型,它要么是 flat 的,要么是 segment 的,具体是哪个在于对象是否仍旧是 TTL 的。字典模式正交地操作(原文,operates orthogonally to TTL inference and butterflies) 于 TTL 推断和 butterfly。
但如果在字典 transition 被删除之前添加任何属性的话,那我们必须要特殊处理这种删除情形。正常来说,删除会导致被删掉的 slot 变成可复用的。我们不能在这里这么做,因为对某个被删除的属性f做迟缓读取 (tardy read) 可能会导致覆盖某个新加的属性g的值。我们可以通过简单地不去复用删除属性后多余出的空间来预防这些非预期的结果,如果那些属性已经在字典 transition 之前添加的话。
这不会导致使用无界内存。当垃圾回收在它的安全点的时候,它已经知道所有的内存访问都完成了。因此,最简单的实现方法是当垃圾回收访问对象的时候,让它改变那些删除属性的状态。一旦垃圾回收在安全点的时候标识了那些属性 slot,之后的属性添加可以复用这些 slot。
内联缓存
一旦我们让并发生效以后,重新编译一块内联缓存会更加困难,因为你需要在修改当前可能执行在另一个 CPU 上的代码的时候仔细一点。我们计划布置一个分层的防御方案以防止这个问题:我们会推测代码的 thread-locality 以使用尽可能和现在相同的内联缓存,我们会在任何安全的时候缓冲内联缓存,最后如果某个内联缓存迫切需要被重置的时候,我们会依靠安全点(safepoint)。
我们希望在很多程序里,内联缓存会在代码执行在一个以上的线程上之前,达到稳定状态。因此,我们计划让每块代码追踪其 thread-locality。只要它只在一个线程上执行过,它会记住并且在入口检查这种情况。如果结果是 true 的话,任何那块代码里的内联缓存都可以被修改而不用任何额外的同步。我们可以在喜好的粒度层次上追踪 thread-locality,例如它甚至可以是每块基础代码块。如果我们用 JavascriptCore 的CodeBlock记号作为粒度层次,这可能是最自然的;这大致上相当于源码里的函数层级。
一旦代码的 thread-locality 被打破了,我们可以开始缓冲内联缓存修改。我们的PolymorphicAccess内联缓存设施已然缓冲了修改,因为即使我们不做代价昂贵的同步,这也是最有效率的。对于可能全局执行的内联缓存,我们可以全局缓冲修改。例如,VM 会执行每微秒一次的安全点(safepoint)以把修改刷新到全局内联缓存中。
有时候,我们需要立即修改内联缓存,在这个时候,我们会用 safepoint 系统的能力 ———— 即在某一点上停掉所有线程,在这个点上,我们可以处理每一个线程状态。在有许多线程的时候,这可不是一项快速操作。Java 虚拟机已经需要为类层级失效、锁偏向做一些类似的事情。设计上来说,这些迫切的无效化不太可能发生。我们只去做会导致迫切无效化的优化,如果我们有测量数据表明可能性不大的话。
本地锁优化工具
目前为止,这个算法需要能够把 16 位的信息偷偷地放到 butterfly 指针的高位里去。某些硬件不允许我们这么做,比如说,少于 16 个高指针位可能会被用来做虚拟内存里的全零检查。如果系统只允许 8 个选中的高位,那我们将只能支持 127 个线程。即使并发 Javascript 具有严格的 127 个线程的上限,它可能还是有实用价值的,但这是一个需要在语言层面上加强的重要下限。这部分展示如何克服这个限制。
如果对象模型只能处理 127 个线程的 thread-locality,那我们可以选择让第 127 个线程不做 thread-locality 推断,或者可以尝试着把一个以上的逻辑线程映射到同一个线程识别器上。映射到同一个 TID 上的线程将不能够在互相之间并发执行。为了实现这个目的,我们可以借鉴 python 里的 GIL (global interpreter lock) 的想法。这种 CPython 实现只允许单个本地线程单次地解释 python 代码,通过用一个保护解释器的锁(所谓的 GIL),CPython 达到了这个目的。这个锁会被阶段性地释放然后重新请求,这能显现出并发的现象。因为我们也可以在任何潜在阻塞的操作中释放锁,所以我们可以甚至避免由于不足并发的所引起死锁。我们可以把这种技术应用在这里:如果我们最多有 127 个线程,那我们可以有 127 个锁来保护 JS 的执行。只要有 127 个或者少于 127 个线程,那锁什么都不做;任何我们想要释放它的时候,我们什么都不用做因为锁会告诉我们没有人在等待获取这个锁。""释放和重新获取""锁的确是代价低廉的加载和 branch,因此没必要释放它。
这个锁对于线程池来说是局部的而不是对于全引擎全局的,而且它会保护我们所有的优化路径,而不是仅仅保护解释器。因此有了这个名字:局部锁优化工具,或者简称 LOL(Local Optimizer Lock)。
线程不安全的对象
DOM 对象像 Javascript 对象的行为一样,但实际上是一个以 C++ 实现的复杂逻辑的代理。那部分逻辑通常不是线程安全的。支持 DOM 传递的本地代码使用了很多本地 API,这些 API 只会被主线程使用,要确保 DOM 完全是线程安全的会花很多工夫。我们的 strawman 提案只需要让 DOM 全局对象能够处理自己属性的查询,我们需要它来允许线程像Object和Thread一样访问全局 Javascript 属性。
在 Webkit 中,JSDOMWindow上的变量解析和自属性解析很大程度上遵循一种依赖现有 JS 属性查询机制的模式,在 window 有一个 null 的frame 的时候,它使用外部行为。我们已经在非 null 的frame上安装了 watchpoint。因此,通过使用现有的 wathcpoint 集,给frame特殊情形的时候,我们可以支持对JSDOMWindow属性的快速并发访问,这意味着JSDOMWindow的部分慢路径会需要锁,但这是可以接受的,因为大多数全局对象访问是内联缓存的。
想要深入并发 JS 的原生应用也可能希望限制共享其中的某些类。对象访问的线程关系检查会需要由 VM 自己实现,以将优化的能力赋予编译器,这表示将功能暴露给 C/Object-C API 客户端是可能的。
总结
我们认为如果提供了在开发者使用这项特性时能够足够满意的性能时,我们可以在 Webkit 里并发地执行 Javascript。这项技术的核心是 segmented butterfly、transition TTL 推断、以及很多性能优良的单对象锁。只要程序遵守某些特定的行为,那它们就能体验到极小的开销:属性访问和目前的开销差不多,而且对象不需要任何额外的内存。如果某些对象不遵守我们的规则,它们的代价会稍高一些。
相关工作
segmented butterfly 是一种 Schism 垃圾回收中的数组对象模型和我们在 JavascriptCore 中使用了很长时间的 butterfly 对象模型的简单结合。
TTL 推断是受到了锁偏向工作的启发。在 HotSpot biased locking 计划 里,我们使用类型来判断我们是否能够保证 thread locality。但和那份计划不一样的是,我们不依赖逆优化来打破线程-对象的关系。我们用来告知其他线程某个对象不再是 TTL 的主要机制是在 butterfly 指针里保持不同的标识 bit。
segmented butterfly、TTL 推断,以及在出现奇怪现象时,这两套计划在单对象锁上的回退机制,这三者的结合在之前我们没有见到过。大多数面向对象且允许并发的系统实现避免这些现象的方式,要么是通过一种对象模型,它可以自然地避免解析代价过大的竞争,像 Java 里的方式那样,或者是通过使用某些机制来限制语言中的并发数量。
例如,CPython 用一个全局的解释器锁(GIL —— global interpreter lock) 来确保解释器永远不会和自己竞争。这是一种强大的技术,它抓住了并发的某些核心:一旦 I/O 或其他类型的阻塞发生的时候,你希望你的其他线程能够在此时做一些有用的工作。GIL 机制就会允许该种可能的发生,因此它能让线程对于很多类型的应用来说都是有用的。可惜的是,它并不能让程序发展出并行特性。GIL 最出色的特性是易于实现。举例来说,它可以用来实现在任何 JS 引擎下我们所希望的线程语义。本文的内容全部是关于为 64 位平台去做优化的全并发。
还有一种尝试,叫做 Gilectomy,目前正在进行中,它试图移除 CPython 的 GIL 并将其替代为细粒度的锁和智能化的原子化算法。Gilectomy 尚未能在速度上匹及目前的 CPython;单线程和多线程程序在 Gilectomy 里都会运行得很慢。性能问题貌似和分配器(我们计划使用 thread-local 的分配缓冲)与引用计数器(我们没有引用计数)里的锁有关。Gilectomy 不会从对象访问里删掉锁。像 Javascript 的对象一样,Python 的对象是能动态重新分配大小的字典。我们提案中的大部分内容是关于在多线程读取同一个对象的时候,如何快速访问这些对象的。
PyPy 也有一个正在进行中的删除 GIL 的尝试,但他们没有说太多关于计划如何处理除使用锁以外的同步对象访问。我们也会有锁的,但我们也考虑到了怎么去做优化才能在大多数情况下避免锁。
另一个方法是 SpiderMonkey 的_title locking_计划,它已经被删除了。那个计划也包括了单线程锁,但没有做我们在大多数情况下避免锁的那部分优化。
Cohen, Tal, 和 Petrank 最近引入了 layout lock(布局锁),它容许对象的快速读写,那些对象可能会使得自己的布局被改变。读取需要一次额外的加载(它必须是隔离的或是有所依赖的),写入必须拿到读取的锁(它的代价和一对隔离的读取和分流差不多小),transition 必须拿到写入锁并做一些额外的簿记(book-keeping)。我们怀疑这和 segmented butterfly 的代价模型相近,除了写入的部分。segmented butterfly 只需要一块额外的用来写入的依赖性加载,它比请求读取锁的开销稍低一些,读取锁会需要两次围绕某个 store 的加载。围绕 store 的加载不太方便;比如说强制让一个 store 在 x86 的加载之前发生会需要一条给 store 的xchg指令,它比只做一次mov的开销要大。在 ARM 上,它需要使用 load 和 store 的 acq/rel 变量。另一方面,写入 segmented butterfly 的额外依赖性加载不需要额外的在 x86 或是 ARM 上的围栏(fencing)。transition 和读取可能在使用 segmented butterfly 和布局锁的时候速度相同,但写入对我们很重要。写入发生的次数足够频繁,以至于 segmented butterfly 可能比 Javascript 对象模型的布局锁要明显地快一些。而且,segmentation 的方法不太会重现在很多不同类型的数据结构中。因其更具适用性,布局锁对于像SparseArrayValueMap和Map/WeakMap/Set这样更复杂的数据 JSC 数据结构来说可能挺有用的。那些数据结构也许对于 segmentation 来说太复杂了,但对于布局锁来说不太复杂。像 segmented butterfly 一样,布局锁可能会和 TTL 推断结合起来使用以避免任何的锁,直到需要用它来保护竞争的 transition。
结论
本文展示了 Webkit 的 Javascript 实现是通过何种方式的修正来支持线程的。我们的计划允许所有的 Javascript 都可以共享,我们的计划避免在快速路径上的锁,如属性访问的快速路径。我们希望它能够用较低的开销实现这个计划。序列化代码会体验到零开销,并发代码只会在它往对象里添加属性的时候体验到较大开销,前提是这个对象正在被多个线程写入。
这个狂野想法的下一步是尝试着实现它,然后看看有没有用。我们会在 bug 174276 底下跟踪进度。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!