
一 、前端开发在开发什么
大家在前端开发的过程中,可能会想过这样一个问题:前端开发究竟是在开发什么?在我看来,前端开发的本质是让网页视图能够正确地响应相关事件。在这句话中有三个关键字:"网页视图","正确地响应"和"相关事件"。
"相关事件"可能包括页面点击,鼠标滑动,定时器,服务端请求等等,"正确地响应"意味着我们要根据相关的事件来修改一些状态,而"网页视图"就是我们前端开发中最熟悉的部分了。
按照这样的观点我们可以给出这样 视图 = 响应函数(事件) 的公式:
在前端开发中,需要被处理事件可以归类为以下三种:
● 用户执行页面动作,例如 click, mousemove 等事件。
● 远程服务端与本地的数据交互,例如 fetch, websocket。
● 本地的异步事件,例如 setTimeout, setInterval async_event。
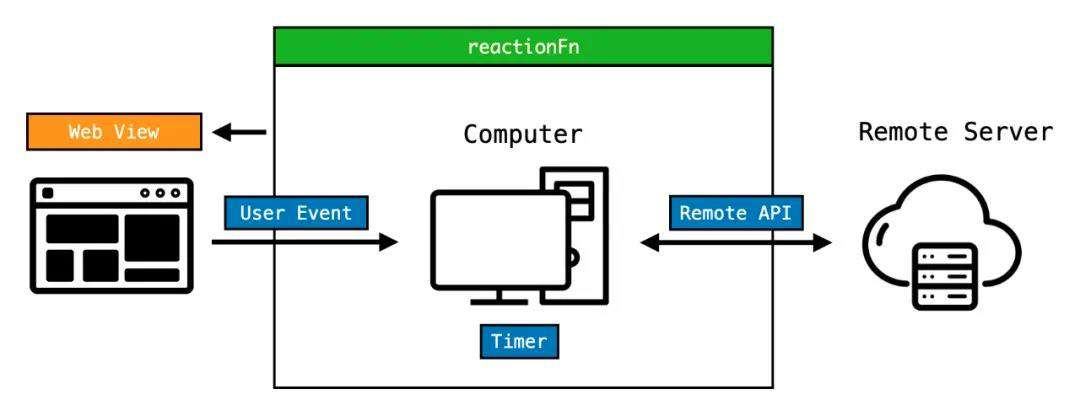
这样我们的公式就可以进一步推导为:
二、应用中的逻辑处理
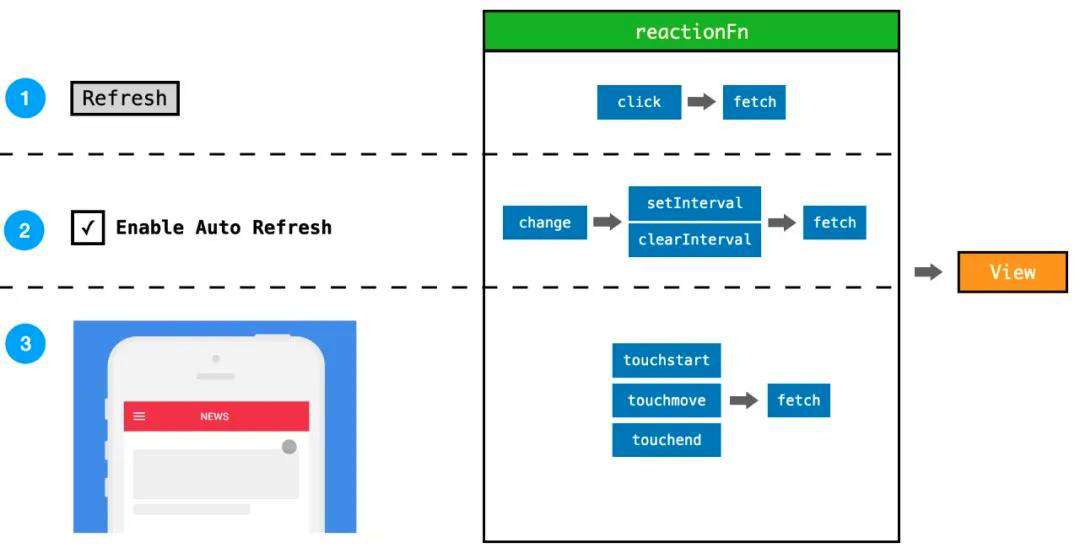
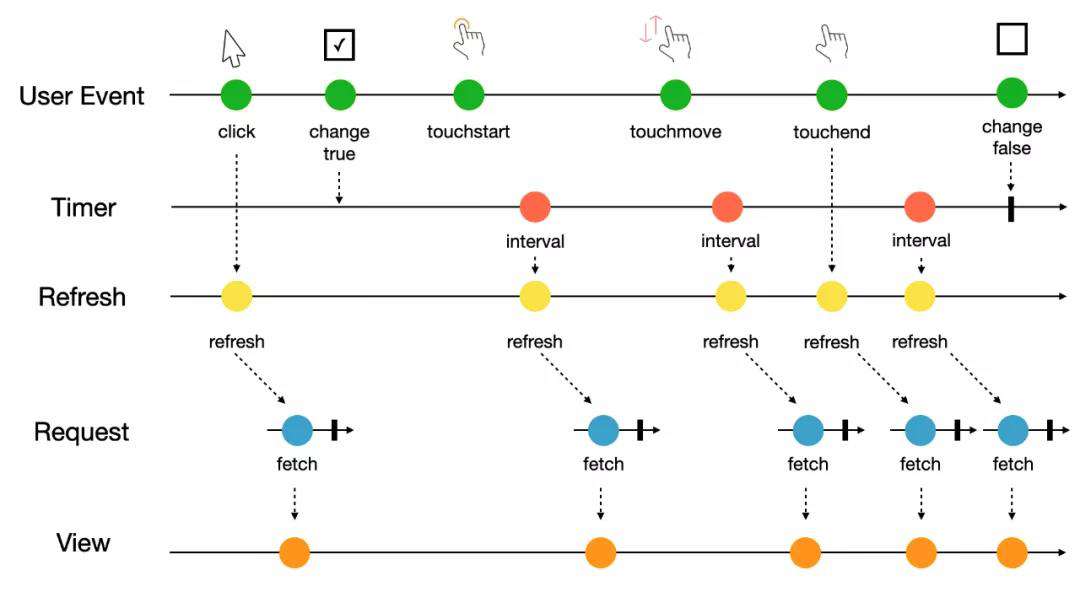
为了能够更进一步理解这个公式与前端开发的关系,我们以新闻网站举例,该网站有以下三个要求:
● 单击刷新:单击 Button 刷新数据。
● 勾选刷新:勾选 Checkbox 时自动刷新,否则停止自动刷新。
● 下拉刷新:当用户从屏幕顶端下拉时刷新数据。
如果从前端的角度分析,这三种需求分别对应着:
● 单击刷新:click -> fetch
● 勾选刷新:change -> (setInterval + clearInterval) -> fetch
● 下拉刷新:(touchstart + touchmove + touchend) -> fetch news_app
1.MVVM
在 MVVM 的模式下,对应上文的响应函数(reactionFn)会在 Model 与 ViewModel 或者 View 与 ViewModel 之间进行被执行,而事件 (Event) 会在 View 与 ViewModel 之间进行处理。
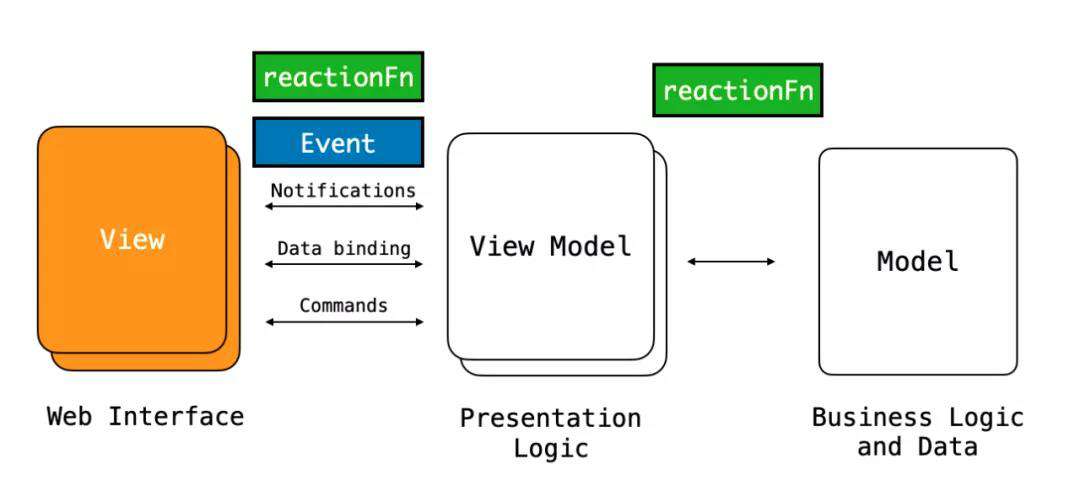
MVVM 可以很好的抽象视图层与数据层,但是响应函数(reactionFn)会散落在不同的转换过程中,这会导致数据的赋值与收集过程难以进行精确追踪。另外因为事件 (Event) 的处理在该模型中与视图部分紧密相关,导致 View 与 ViewModel 之间对事件处理的逻辑复用困难。
2.Redux
在 Redux 最简单的模型下,若干个事件 (Event) 的组合会对应到一个 Action 上,而 reducer 函数可以被直接认为与上文提到的响应函数 (reactionFn) 对应。
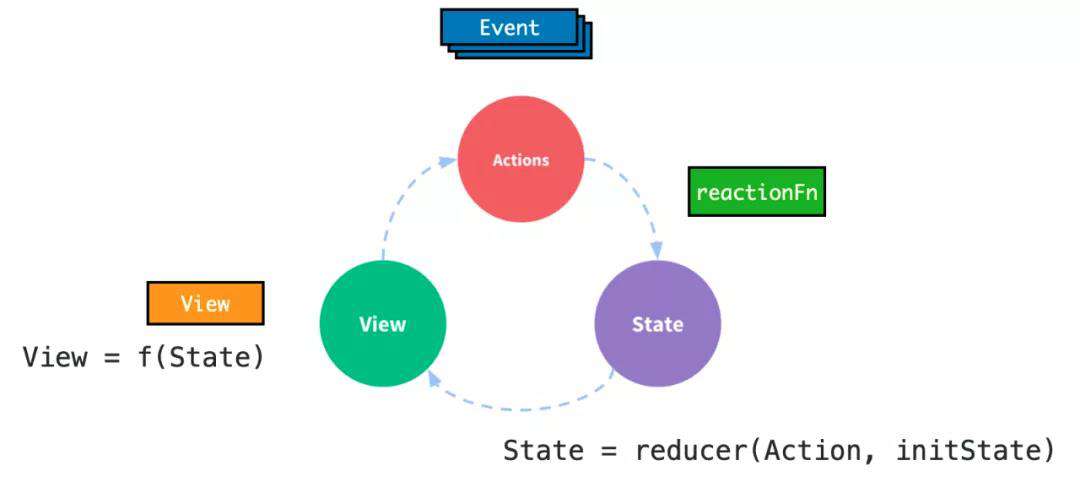
但是在 Redux 中:
● State 只能用于描述中间状态,而不能描述中间过程。
● Action 与 Event 的关系并非一一对应导致 State 难以追踪实际变化来源。
3.响应式编程与 RxJS
维基百科中是这样定义响应式编程:
以数据流维度重新考虑用户使用该应用的流程:
● 点击按钮 -> 触发刷新事件 -> 发送请求 -> 更新视图
● 勾选自动刷新
● 手指触摸屏幕
● 自动刷新间隔 -> 触发刷新事件 -> 发送请求 -> 更新视图
● 手指在屏幕上下滑
● 自动刷新间隔 -> 触发刷新事件 -> 发送请求 -> 更新视图
● 手指在屏幕上停止滑动 -> 触发下拉刷新事件 -> 发送请求 -> 更新视图
● 自动刷新间隔 -> 触发刷新事件 -> 发送请求 -> 更新视图
● 关闭自动刷新
以 Marbles 图表示:
拆分上图逻辑,就会得到使用响应式编程开发当前新闻应用时的三个步骤:
● 定义源数据流 ● 组合/转换数据流 ● 消费数据流并更新视图
我们分别来进行详细描述。
定义源数据流
使用 RxJS,我们可以很方便的定义出各种 Event 数据流。
1)单击操作
涉及 click 数据流。
click$ = fromEvent<MouseEvent>(document.querySelector('button'), 'click');
2)勾选操作
涉及 change 数据流。
change$ = fromEvent(document.querySelector('input'), 'change');
3)下拉操作
涉及 touchstart, touchmove 与 touchend 三个数据流。
touchstart$ = fromEvent<TouchEvent>(document, 'touchstart');
touchend$ = fromEvent<TouchEvent>(document, 'touchend');
touchmove$ = fromEvent<TouchEvent>(document, 'touchmove');
4)定时刷新
interval$ = interval(5000);
5)服务端请求
fetch$ = fromFetch('https://randomapi.azurewebsites.net/api/users');
组合/转换数据流
1)点击刷新事件流
在点击刷新时,我们希望短时间内多次点击只触发最后一次,这通过 RxJS 的 debounceTime operator 就可以实现。
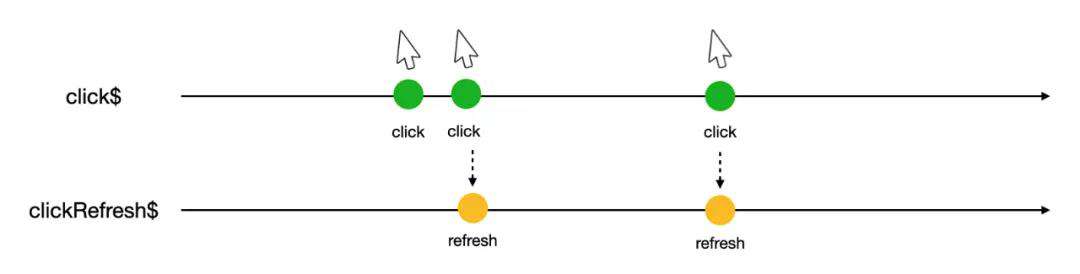
clickRefresh$ = this.click$.pipe(debounceTime(300));
2)自动刷新流
使用 RxJS 的 switchMap 与之前定义好的 interval$ 数据流配合。
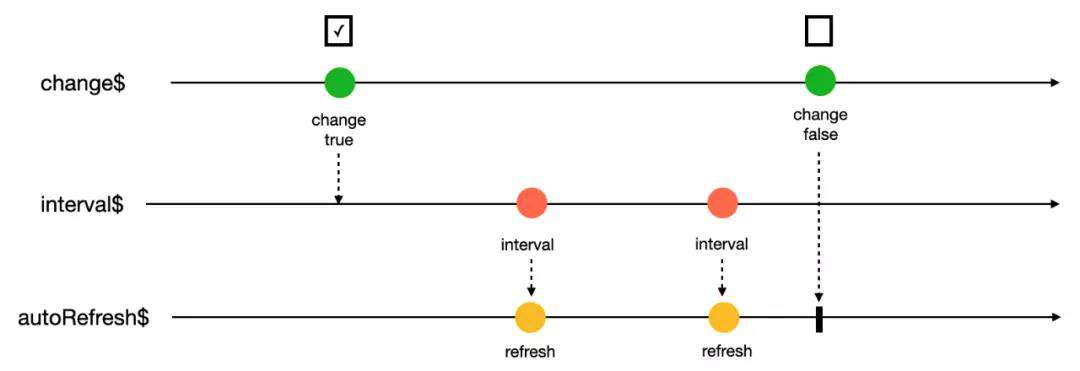
autoRefresh$ = change$.pipe(
switchMap(enabled => (enabled ? interval$ : EMPTY))
);
3)下拉刷新流
结合之前定义好的 touchstarttouchmove 与 touchend$ 数据流。
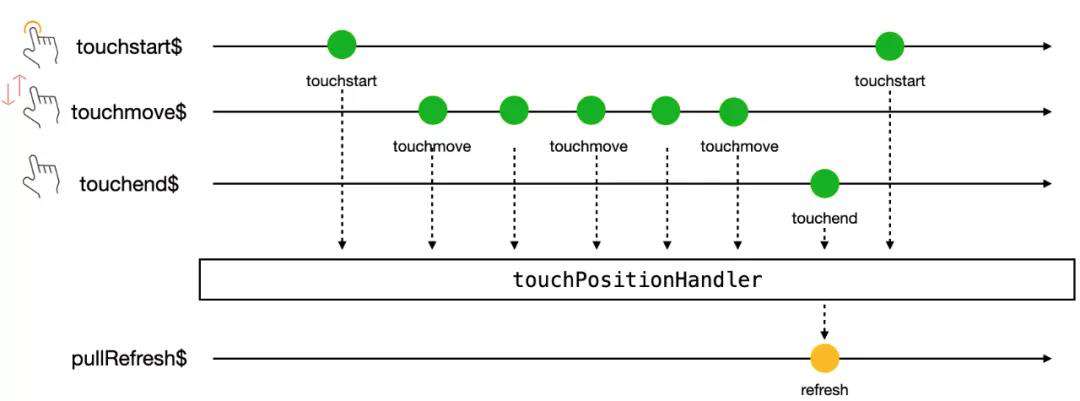
pullRefresh$ = touchstart$.pipe(
switchMap(touchStartEvent =>
touchmove$.pipe(
map(touchMoveEvent => touchMoveEvent.touches[0].pageY - touchStartEvent.touches[0].pageY),
takeUntil(touchend$)
)
),
filter(position => position >= 300),
take(1),
repeat()
);
最后,我们通过 merge 函数将定义好的 clickRefreshautoRefresh 与 pullRefresh$ 合并,就得到了刷新数据流。
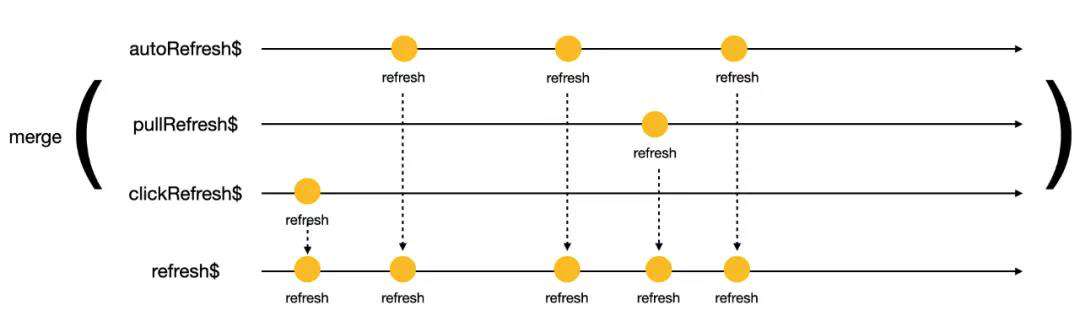
refresh$ = merge(clickRefresh$, autoRefresh$, pullRefresh$));
消费数据流并更新视图
将刷新数据流直接通过 switchMap 打平到在第一步到定义好的 fetch$,我们就获得了视图数据流。
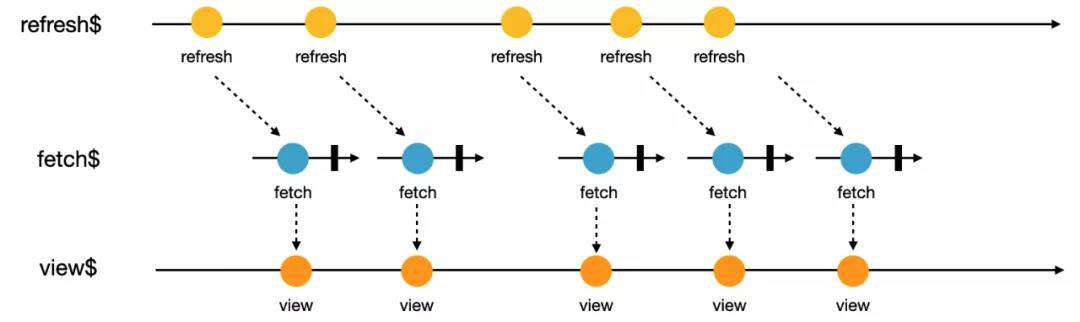
可以通过在 Angular 框架中可以直接 async pipe 将视图流直接映射为视图:
<div *ngFor="let user of view$ | async">
</div>
在其他框架中可以通过 subscribe 获得数据流中的真实数据,再更新视图。
至此,我们就使用响应式编程完整的开发完成了当前新闻应用,示例代码[1]由 Angular 开发,行数不超过 160 行。
我们总结一下,使用响应式编程思想开发前端应用时经历的三个过程与第一节中公式的对应关系:
1)描述源数据流
与事件UserEvent | Timer | Remote API 对应,在 RxJS 中对应函数分别是:
● UserEvent: fromEvent ● Timer: interval, timer ● Remote API: fromFetch, webSocket
2)组合转换数据流
与响应函数(reactionFn)对应,在 RxJS 中对应的部分方法是:
● COMBINING: merge, combineLatest, zip ● MAPPING: map ● FILTERING: filter ● REDUCING: reduce, max, count, scan ● TAKING: take, takeWhile ● SKIPPING: skip, skipWhile, takeLast, last ● TIME: delay, debounceTime, throttleTime
3)消费数据流更新视图
与 View 对应,在 RxJS 及 Angular 中可以使用:
● subscribe ● async pipe
响应式编程相对于 MVVM 或者 Redux 有什么优点呢?
● 描述事件发生的本身,而非计算过程或者中间状态。
● 提供了组合和转换数据流的方法,这也意味着我们获得了复用持续变化数据的方法。
● 由于所有数据流均由层层组合与转换获得,这也就意味着我们可以精确追踪事件及数据变化的来源。
如果我们将 RxJS 的 Marbles 图的时间轴模糊,并在每次视图更新时增加纵切面,我们就会发现这样两件有趣的事情:
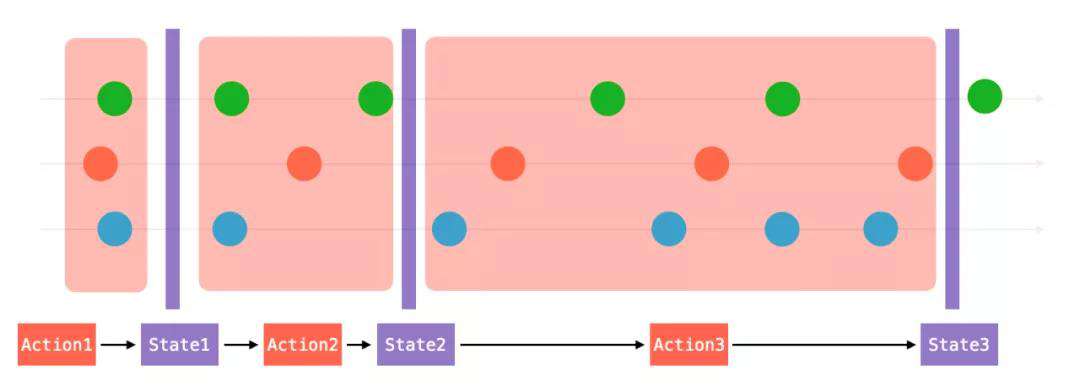
● Action 是 EventStream 的简化。
● State 是 Stream 在某个时刻的对应。
难怪我们可以在 Redux 官网中有这样一句话:如果你已经使用了 RxJS,很可能你不再需要 Redux 了。
写到这里,我们对网页视图能够正确地响应相关事件这句话是否可以进行进一步的抽象呢?
而按时间顺序发生的事件,本质上就是数据流,进一步拓展就可变成:
这正是响应式编程在前端能够完美工作的基础思想。但是该思想是否只在前端开发中有所应用呢?
答案是否定的,该思想不仅可以应用于前端开发,在后端开发乃至实时计算中都有着广泛的应用。
三、打破信息之墙
在前后端开发者之间,通常由一面叫 REST API 的信息之墙隔开,REST API 隔离了前后端开发者的职责,提升了开发效率。但它同样让前后端开发者的眼界被这面墙隔开,让我们试着来推倒这面信息之墙,一窥同样的思想在实时计算中的应用。
1.实时计算 与 Apache Flink
在开始下一部分之前,让我们先介绍一下 Flink。Apache Flink 是由 Apache 软件基金会开发的开源流处理框架,用于在无边界和有边界数据流上进行有状态的计算。它的数据流编程模型在有限和无限数据集上提供单次事件(event-at-a-time)处理能力。
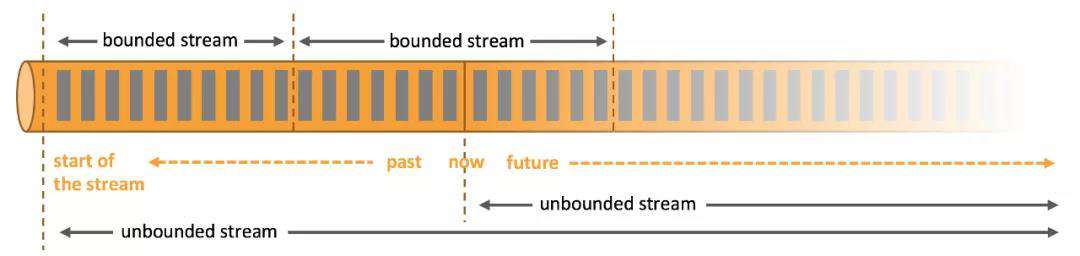
在实际的应用中,Flink 通常用于开发以下三种应用:
● 事件驱动型应用 事件驱动型应用从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。场景包括基于规则的报警,异常检测,反欺诈等等。
● 数据分析应用 数据分析任务需要从原始数据中提取有价值的信息和指标。例如双十一成交额计算,网络质量监测等等。
● 数据管道(ETL)应用 提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
我们这里以计算电商平台双十一每小时成交额为例,看下我们在之前章节得到方案是否仍然可以继续使用。
在这个场景中我们首先要获取用户购物下单数据,随后计算每小时成交数据,然后将每小时的成交数据转存到数据库并被 Redis 缓存,最终通过接口获取后展示在页面中。
在这个链路中的数据流处理逻辑为:
与之前章节中介绍的:
思想完全一致。
如果我们用 Marbles 描述这个过程,就会得到这样的结果,看起来很简单,似乎使用 RxJS 的 window operator 也可以完成同样的功能,但是事实真的如此吗?
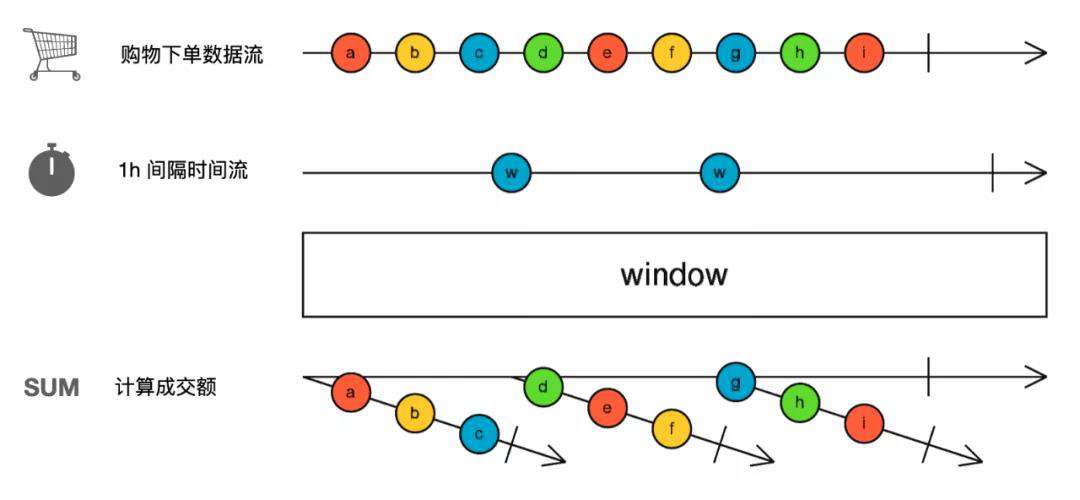
2.被隐藏的复杂度
真实的实时计算比前端中响应式编程的复杂度要高很多,我们在这里举几个例子:
事件乱序
在前端开发过程中,我们也会碰到事件乱序的情况,最经典的情况先发起的请求后收到响应,可以用如下的 Marbles 图表示。这种情况在前端有很多种办法进行处理,我们在这里就略过不讲。
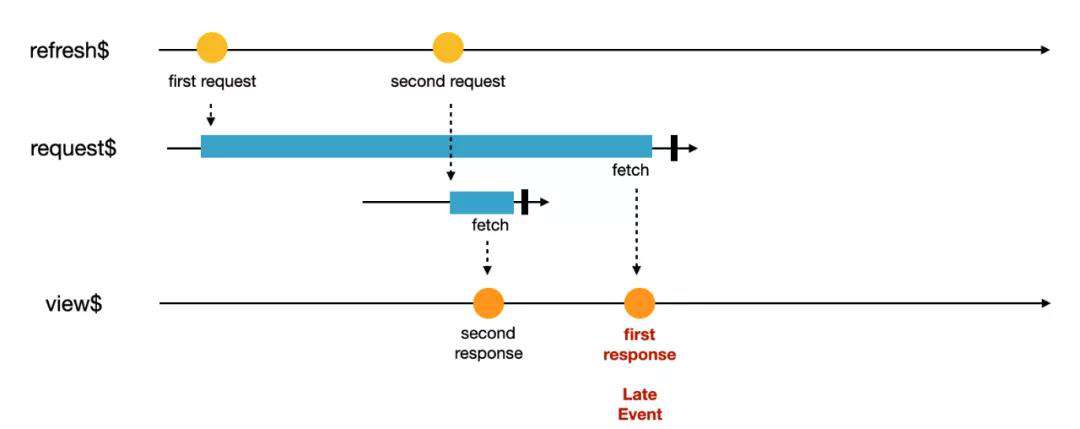
我们今天想介绍的是数据处理时面临的时间乱序情况。在前端开发中,我们有一个很重要的前提,这个前提大幅度降低了开发前端应用的复杂度,那就是:前端事件的发生时间和处理时间相同。
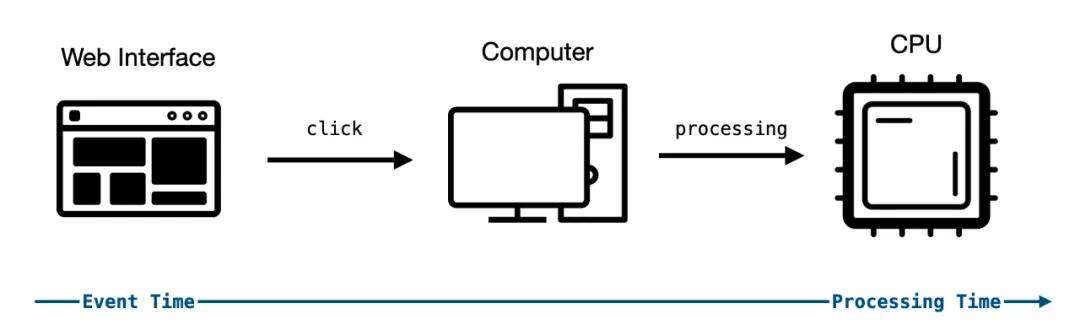
想象一下,如果用户执行页面动作,例如 click, mousemove 等事件都变成了异步事件,并且响应时间未知,那整个前端的开发复杂度会如何。
但是事件的发生时间与处理时间不同,在实时计算领域是一个重要的前提。我们仍以每小时成交额计算为例,当原始数据流经过层层传输之后,在计算节点的数据的先后顺很可能已经乱序了。
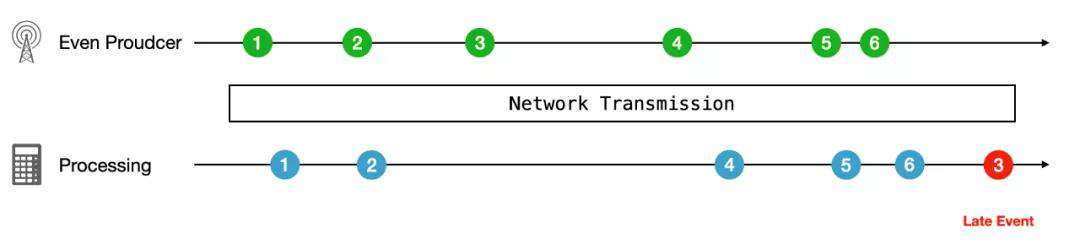
如果我们仍然以数据的到来时间来进行窗口划分,最后的计算结果就会产生错误:
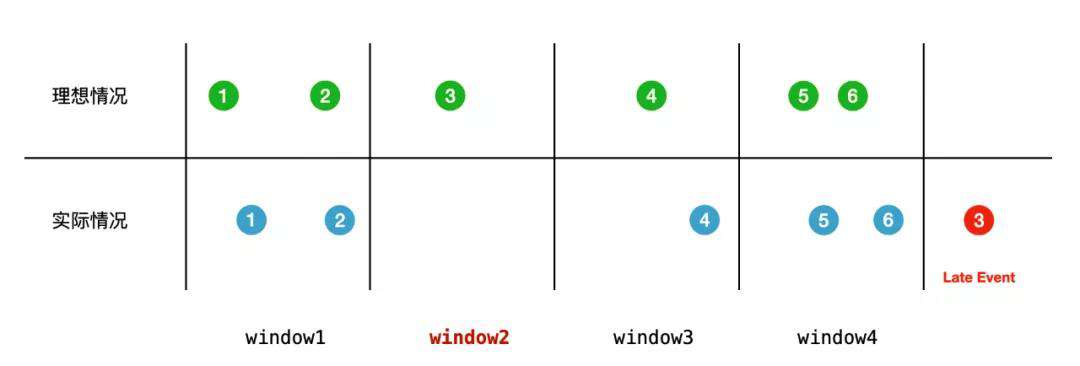
为了让 window2 的窗口的计算结果正确,我们需要等待 late event 到来之后进行计算,但是这样我们就面临了一个两难问题:
● 无限等下去:late event 可能在传输过程中丢失,window2 窗口永远没有数据产出。
● 等待时间太短:late event 还没有到来,计算结果错误。
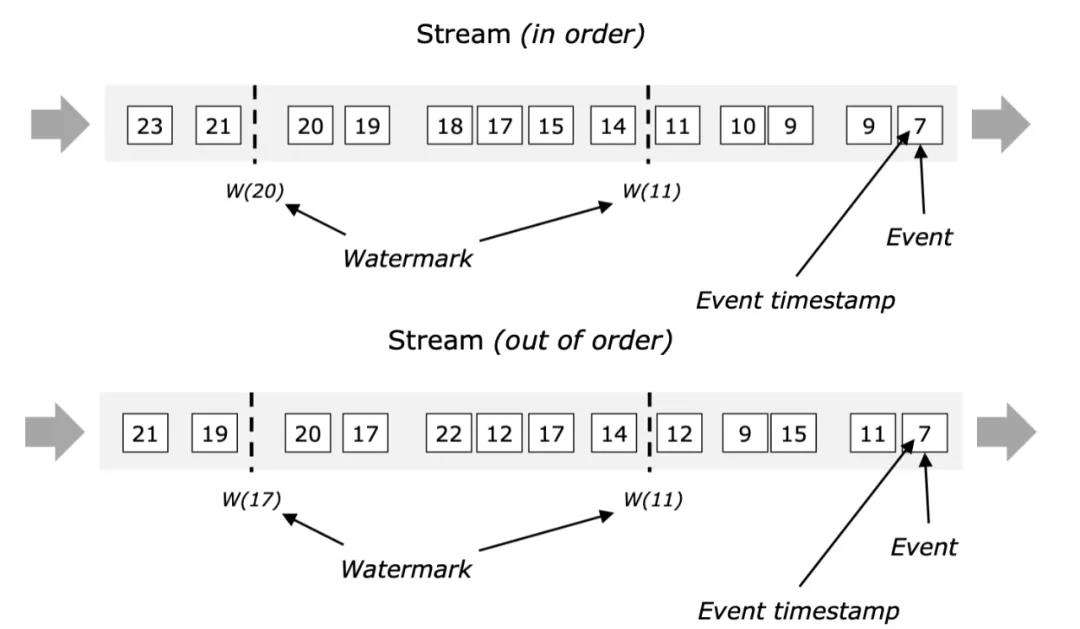
Flink 引入了 Watermark 机制来解决这个问题,Watermark 定义了什么时候不再等待 late event,本质上提供了实时计算的准确性和实时性的折中方案。
关于 Watermark 有个形象的比喻:上学的时候,老师会将班级的门关上,然后说:“从这个点之后来的同学都算迟到了,统统罚站“。在 Flink 中,Watermark 充当了老师关门的这个动作。
数据反压
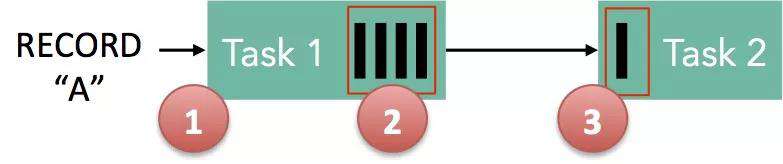
在浏览器中使用 RxJS 时,不知道大家有没有考虑这样一种情况:observable 产生的速度快于 operator 或者 observer 消费的速度时,会产生大量的未消费的数据被缓存在内存中。这种情况被称为反压,幸运的是,在前端产生数据反压只会导致浏览器内存被大量占用,除此之外不会有更严重的后果。
但是在实时计算中,当数据产生的速度高于中间节点处理能力,或者超过了下游数据的消费能力时,应当如何处理?
对于许多流应用程序来说,数据丢失是不可接受的,为了保证这一点,Flink 设计了这样一种机制:
● 在理想情况,在一个持久通道中缓冲数据。
● 当数据产生的速度高于中间节点处理能力,或者超过了下游数据的消费能力时,速度较慢的接收器会在队列的缓冲作用耗尽后立即降低发送器的速度。更形象的比喻是,在数据流流速变慢时,将整个管道从水槽“回压”到水源,并对水源进行节流,以便将速度调整到最慢的部分,从而达到稳定状态。
Checkpoint
实时计算领域,每秒钟处理的数据可能有数十亿条,这些数据的处理不可能由单台机器独立完成。事实上,在 Flink 中,operator 运算逻辑会由不同的 subtask 在 不同的 taskmanager 上执行,这时我们就面临了另外一个问题,当某台机器发生问题时,整体的运算逻辑与状态该如何处理才能保证最后运算结果的正确性?
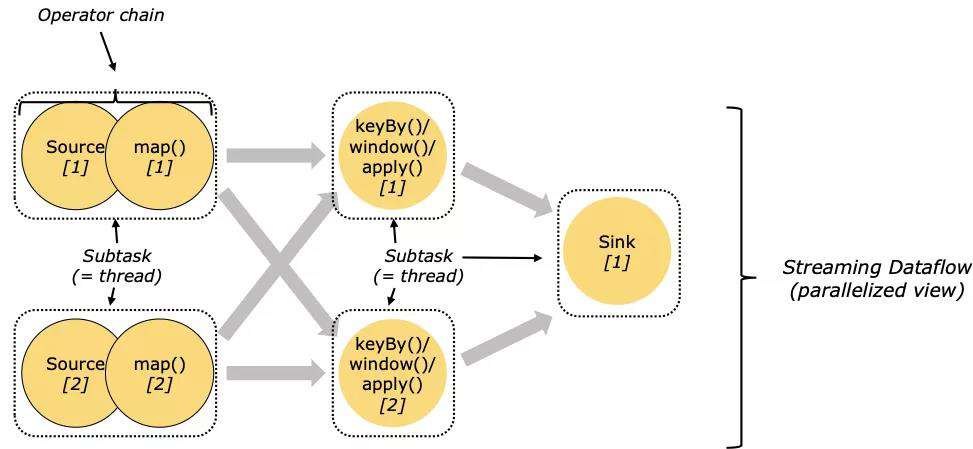
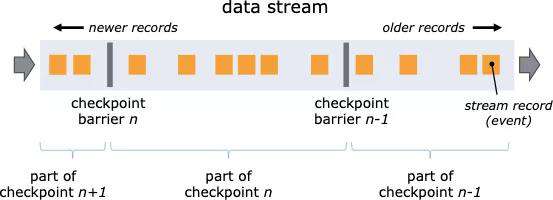
Flink 中引入了 checkpoint 机制用于保证可以对作业的状态和计算位置进行恢复,checkpoint 使 Flink 的状态具有良好的容错性。Flink 使用了 Chandy-Lamport algorithm 算法的一种变体,称为异步 barrier 快照(asynchronous barrier snapshotting)。
当开始 checkpoint 时,它会让所有 sources 记录它们的偏移量,并将编号的 checkpoint barriers 插入到它们的流中。这些 barriers 会经过每个 operator 时标注每个 checkpoint 前后的流部分。
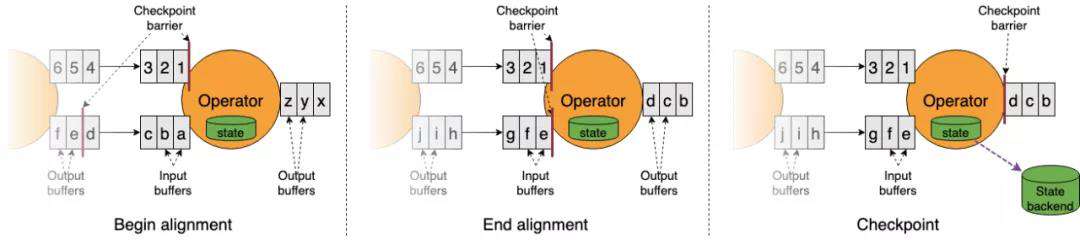
当发生错误时,Flink 可以根据 checkpoint 存储的 state 进行状态恢复,保证最终结果的正确性。
冰山一角
由于篇幅的关系,今天介绍的部分只能是冰山一角,不过:
的模型无论在响应式编程还是实时计算都是通用的,希望这篇文章能够让大家对数据流的思想有更多的思考。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?




发表评论
还没有评论,快来抢沙发吧!