背景
某次更新common包的时候笔者踩了很多坑,没想到简单的一个npm install命令背后还有这么多的学问(keng),于是借此机会学习一下,也将个人思考与大家分享。
更新历史:
1、npm@3.0: 包的扁平化
2、npm@5.0:install根据lock文件来,即使更改了package.json文件,只要有lock文件,那么还是会根据lock文件安装
3、npm@5.1:install无视lock文件,只要json文件改了,那么就根据json的来
4、npm@5.4:lock和package文件都兼顾,如果package.json和lock文件不同,就根据package.json文件去更新包,并且更新lock文件,如果他们是一样的,那么会去根据lock文件更新包。
install过程
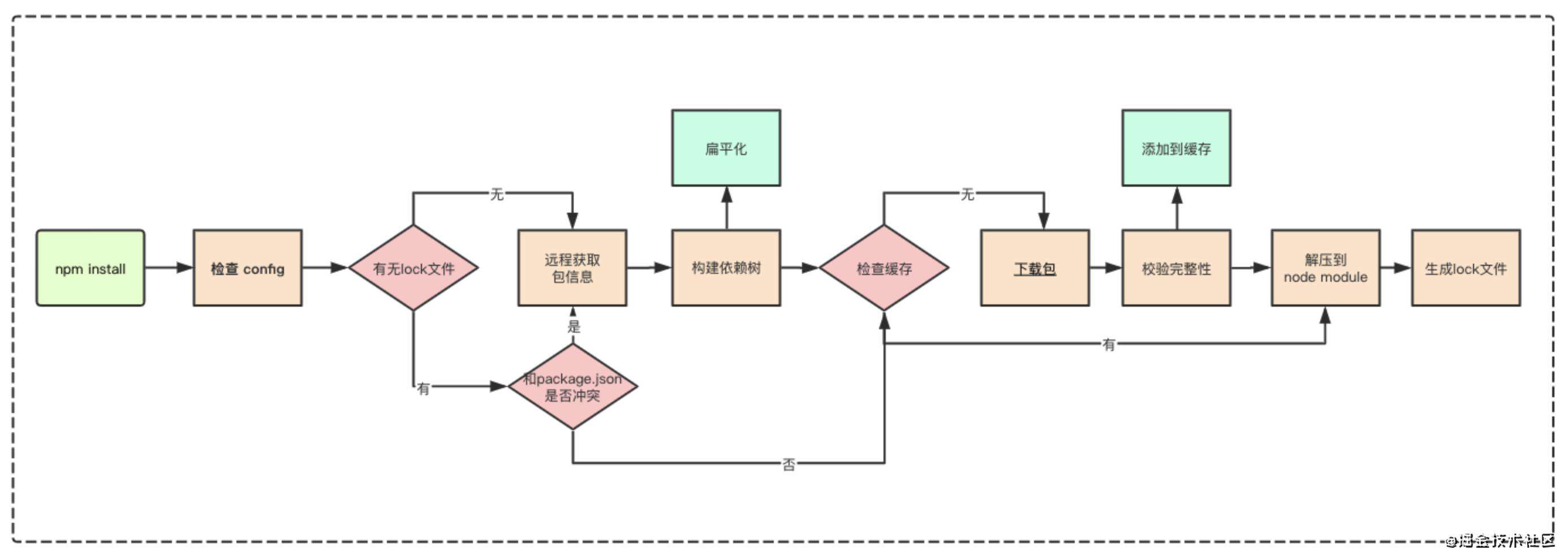
下面是步骤的简单介绍,如果对整个流程有兴趣的话可以看下这个地方。
- 发出npm install命令
- npm 向 registry 查询模块压缩包的网址
- 下载压缩包,存放在~/.npm目录
- 解压压缩包到当前项目的node_modules目录
源码简析
如果电脑上已经全局安装了node,通过npm config get prefix获取到npm安装的全局路径prefixUrl,然后就可以得到npm的代码位置:${prefixUrl}/lib/node_modules/npm。在看install代码时直接跳到到npm文件夹下install.js。看下面部分最好结合源码部分一起看,这样看起来更轻松。
初始化构造函数:
代码截图:

在ndTest文件夹,执行:npm i XXX
得到初始化变量
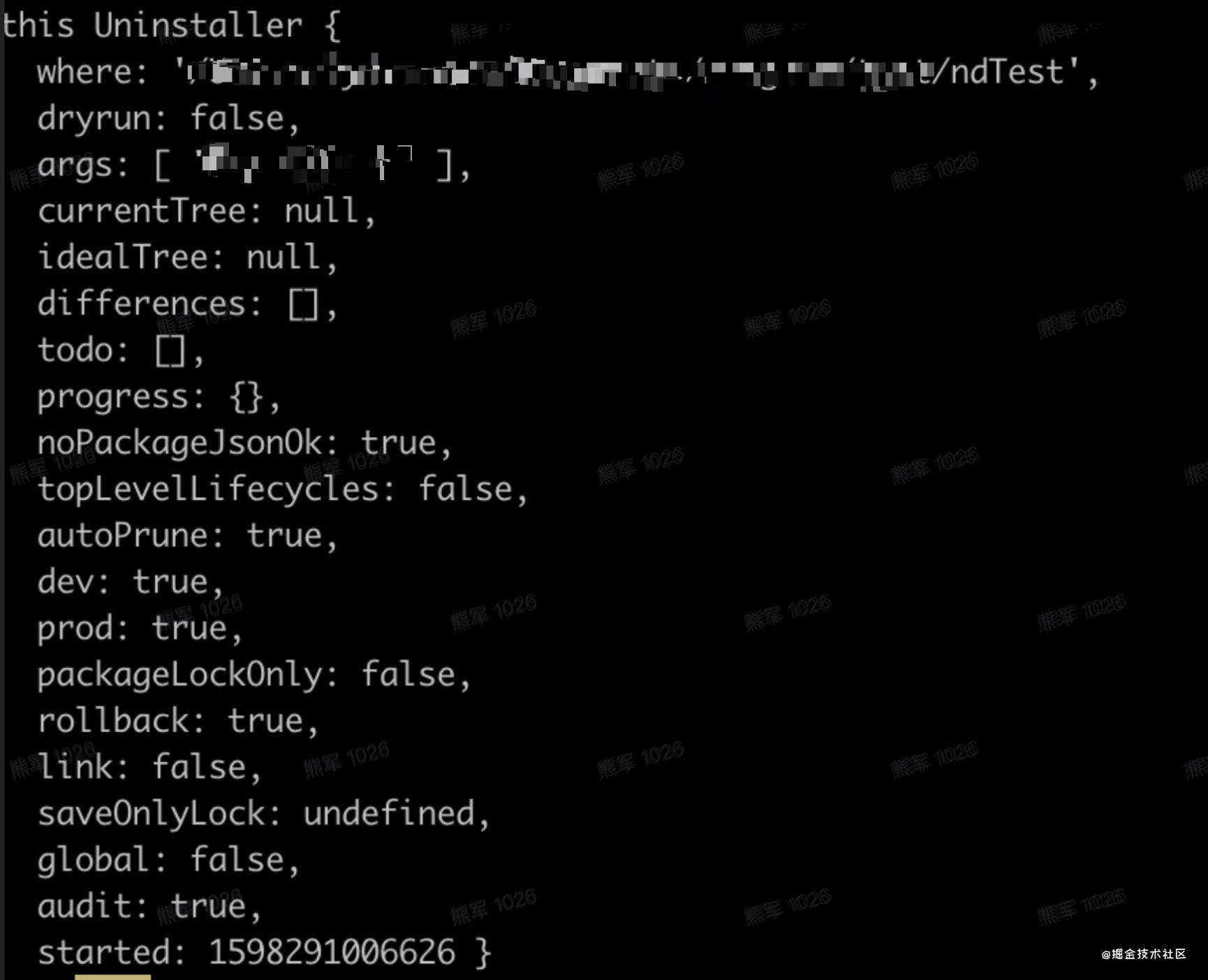
部分变量说明
-
where : 允许安装命令的文件路径
-
dryrun : --dry-run: true不执行安装,是否只打印信息
-
args :参数
-
opts: 选项
-
currentTree: 当前模块的包含的信息,比如node_modules中中包构成的tree
-
idealTree: 安装相应的模块后,经过处理的包信息, 可以看成是目标 tree
-
differences: 上面两棵树的差异队列
-
Todo: 用于存放运行的动作,在安装过程中executeActions中看到它起的作用
-
progress: 在run的newTracker过程中可以看到填充进去的process
-
noPackageJsonOk : 没有packageJson文件是否ok,变量的作用在readLocalPackageData使用到,用于如果直接执行npm install,那么必须要有package.json
-
autoPrune 布尔值,读取配置文件 package-lock 判断是否生成package-lock.json文件
-
packageLockOnly 如果为true,不进行安装动作,如果项目下面不存在lock文件,可以试一下这个命令npm i --package-lock-only体验一把。
-
Started: 记录下运行的时间
Chain
首先先看这个函数,因为这个函数几乎贯穿了整个install的过程中,对于它的了解更有助于接下来的阅读。
chain.first = {} ; chain.last = {}
function chain (things, cb) {
var res = [];
(function LOOP (i, len) {
if (i >= len) return cb(null,res)
if (Array.isArray(things[i]))
things[i] = bindActor.apply(null,
things[i].map(function(i){
return (i===chain.first) ? res[0]
: (i===chain.last)
? res[res.length - 1] : i }))
if (!things[i]) return LOOP(i + 1, len)
things[i](function (er, data) {
if (er) return cb(er, res)
if (data !== undefined) res = res.concat(data)
LOOP(i + 1, len)
})
})(0, things.length) }
function bindActor () {
var args =
Array.prototype.slice.call
(arguments) *// jswtf.*
, obj = null
, fn
if (typeof args[0] === "object") {
obj = args.shift()
fn = args.shift()
if (typeof fn === "string")
fn = obj[ fn ]
} else fn = args.shift()
return function (cb) {
fn.apply(obj, args.concat(cb)) }
}
安装过程(run)主要步骤
run的过程就是对上面那张图的具体实现了,从构建逻辑树到去网络获取包,从校验包的完整性到解压包到项目的node_modules文件夹,最后生成或者更新package-lock.json文件。
这里先简单介绍这些步骤,其中loadCurrentTree、loadIdealTree用于构建得到逻辑树,generateActionsToTake比较两棵树生成需要执行的动作存储到TODO中,executeActions真正的执行TODO中的动作。我们在install过程中如果使用verbose级别的log也可以看到各个阶段的日志。
loadCurrentTree
这个步骤主要经历读取PackageData和序列化读取到的结果。
初步currentTree:读node_modules里面的包和npm-shrinkwrap.json构成初步tree。
readPackageTree(self.where, iferr(cb, function (currentTree)从node_modules里面读包。以下是不存在node_modules时的截图,这个时候得到的树应该是最简单的,如果存在node_modules,那么这些信息会被放在children中。在读取node_modules信息时,会过滤首字母为"."的文件夹,比如.bin。
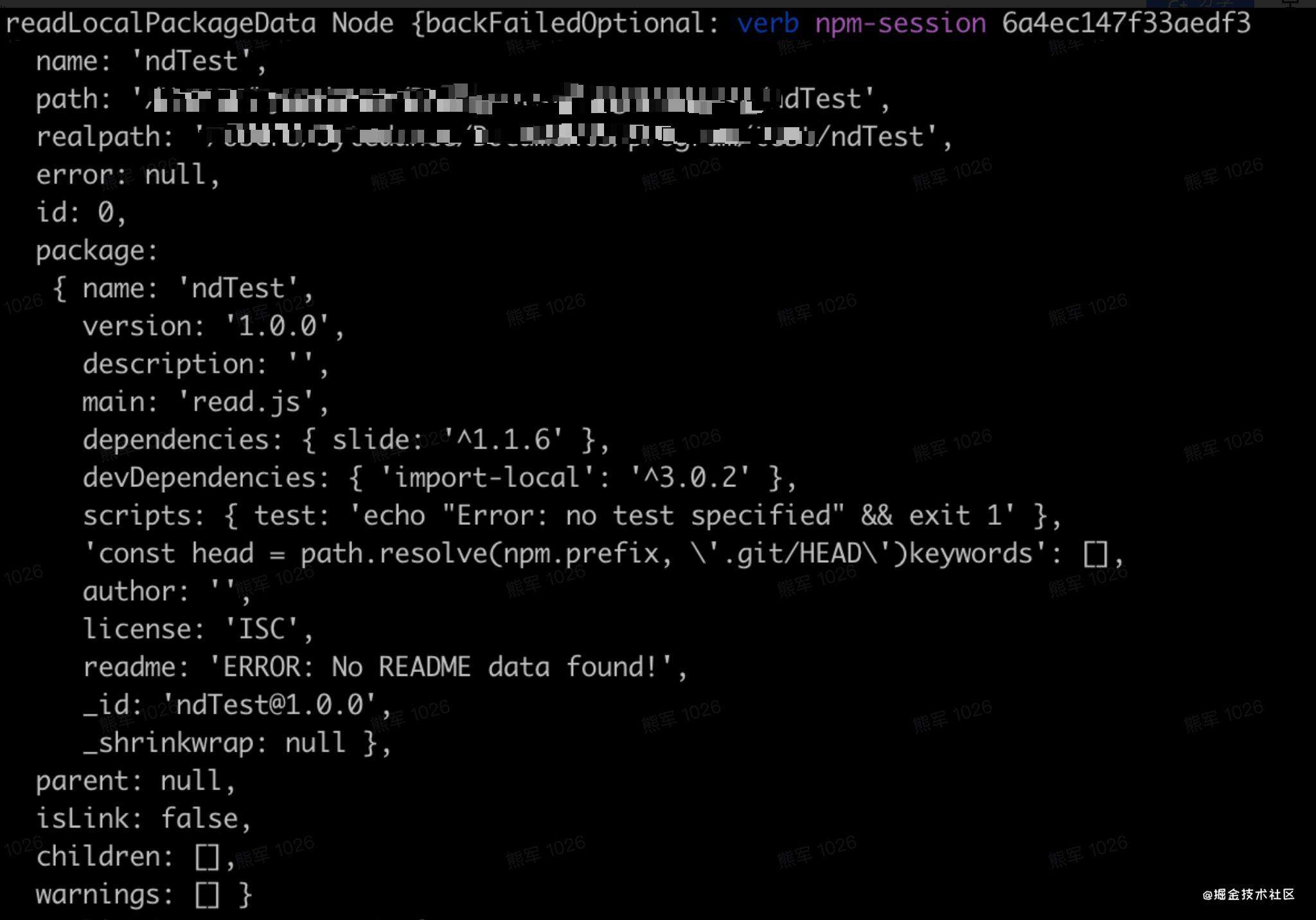
在获取到self.loadArgMetadata(cb如果是带args的安装,那么会去获取这个args的元信息,元信息的结果demo:

获取args信息的过程中出现一个很重要代码,如下,详细可以看lib/fetch-package-metadata.js代码,这块代码用于获取指定包的信息,
pacote.manifest(dep, pacoteOpts({
annotate: true,
fullMetadata: opts.fullMetadata,
log: tracker || npmlog,
memoize: CACHE,
where: where
})).then(
normalize之后:this.currentTree.isTop = true算是给idealTree打基础
computeMetadata(this.currentTree)挂missingDeps和missingDevDeps:计算当前得到的currentTree中是否含有package.json中dependencies和devDependencies的包,如果没有则把它放入对应的missing数组中。当然也会做其他的事情,比如computeMetadata中的resetMetadata会给它和所有的child节点初始化上,如下:
child.isTop = false
child.requiredBy = []
child.requires = []
child.missingDeps = {}
child.missingDevDeps = {}
child.phantomChildren = {}
child.location = null
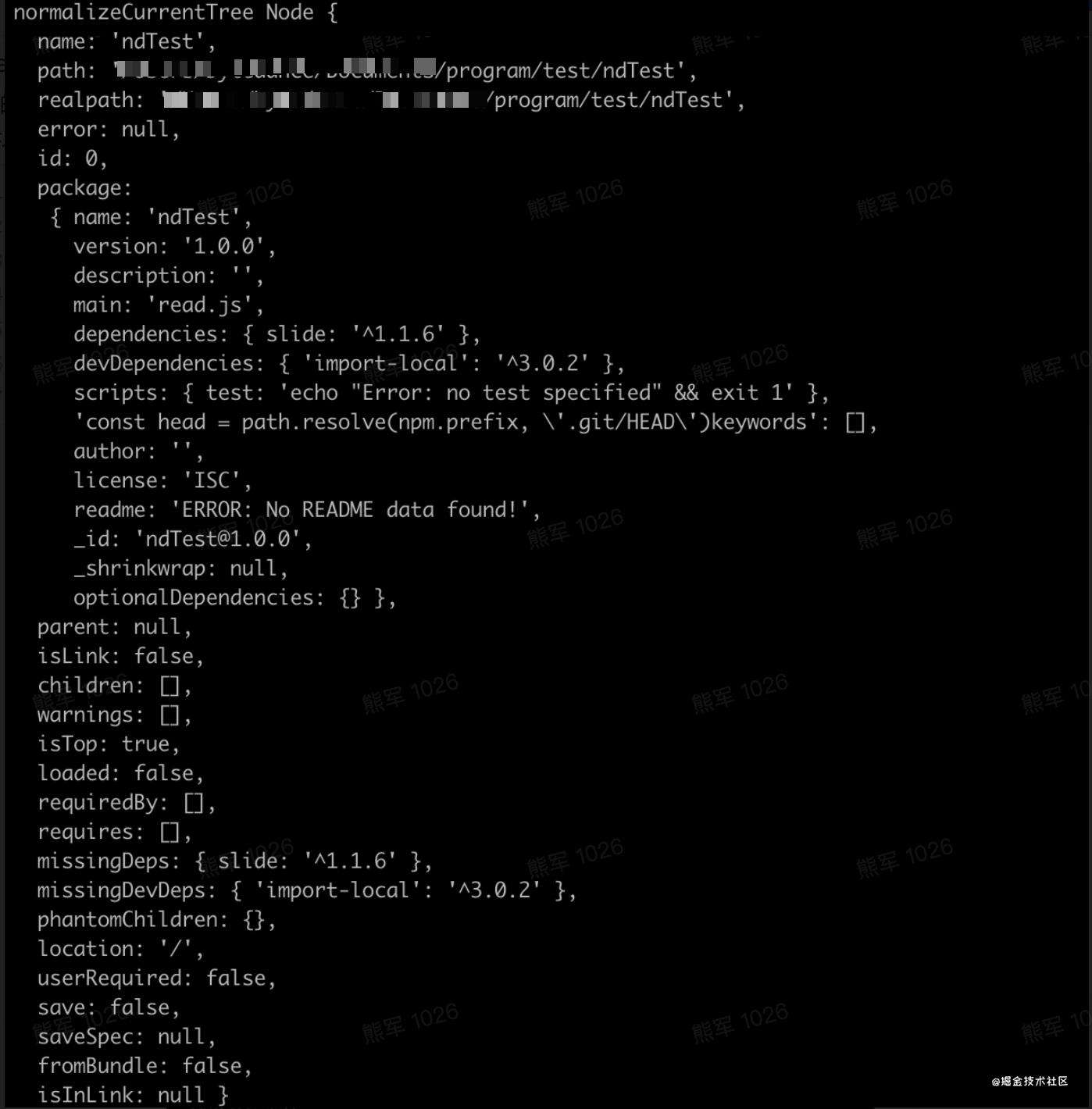
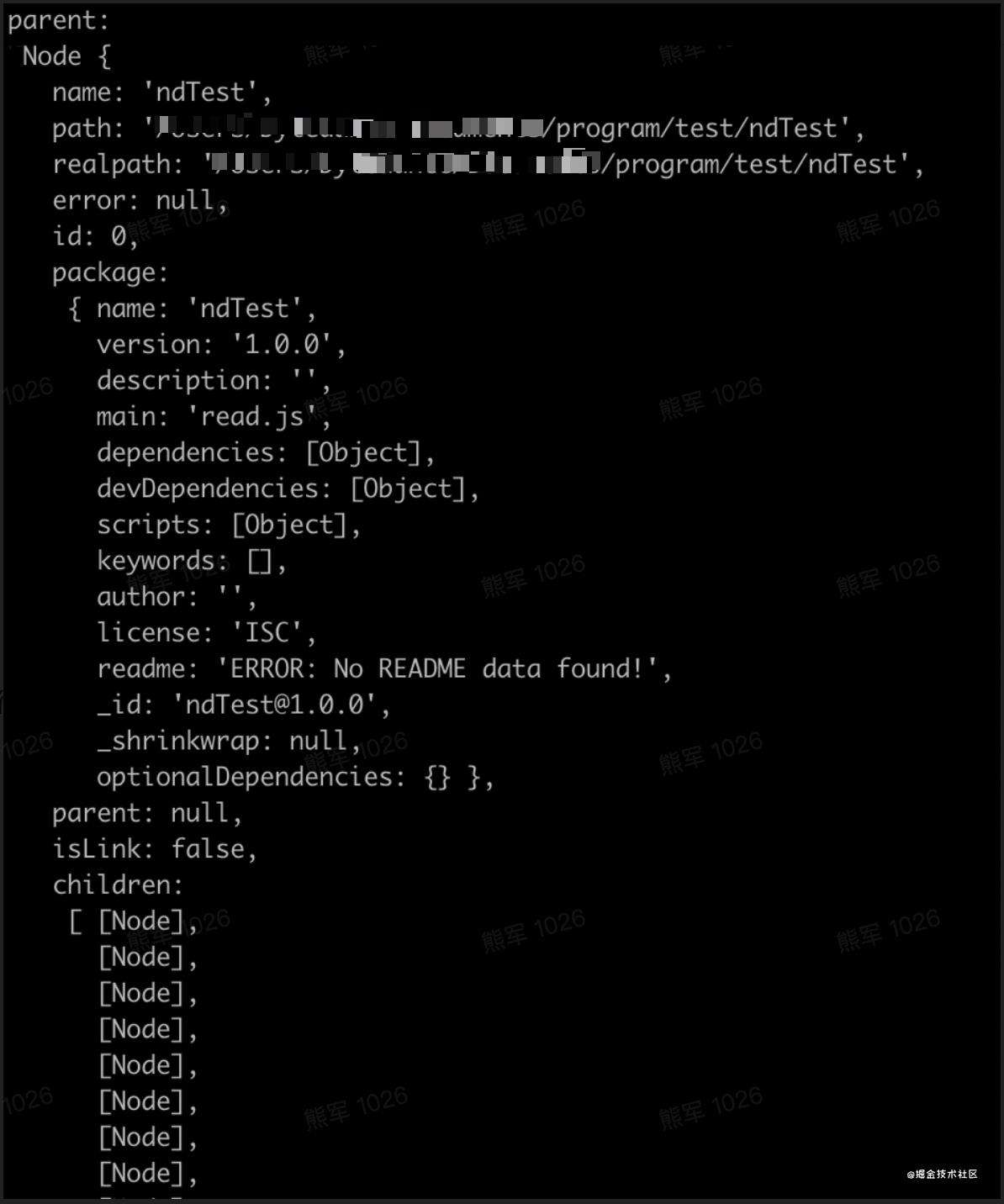
如果执行命令时已经存在了node_modules,那么会形成child和parent的循环引用,如图:
loadIdealTree
这个步骤主要执行三个:cloneCurrentTreeToIdealTree、loadShrinkwrap、loadAllDepsIntoIdealTree。
cloneCurrentTreeToIdealTree:
this.idealTree = copyTree(this.currentTree):把currentTree复制给IdealTree,代码比较短,是个递归调用,具体可以在install/copy-tree.js中看到。
loadShrinkwrap:
readShrinkwrap.andInflate(this.idealTree:依次读取npm-shrinkwrap.json、package-lock.json、package.json,如果存在lock文件或者shrinkwrap文件,读取到内容之后挂载到_shrinkwrap字段,然后在install/inflate-shrinkwrap.js中重新构建一颗新的树,形成了ideaTree的雏形。
具体代码可以看install/inflate-shrink-wrap.js的inflatableChild方法:1、判断已经存在包信息和lock文件中要求的是否一直,如果一直,就用这个包的信息,2、如果不存在,但是满足构造信息的条件,比如存在integrity,那么fake一个包信息,3、都不满足,利用前面讲的fetchPackageMetadata去获取之后创建一个节点信息。
这里也会运行computeMetadata(this.idealTree),类似上面normalize步骤,看lock文件中是否有dependencies和devDependencies的包信息,如果没有那么将信息存储到对应的missing数组中。
loadAllDepsIntoIdealTree:这个步骤里面还是嵌套了chain,根据是否制定了安装参数链进去不同的步骤,不过做的事情其实算是大同小异吧,主要代码在install/deps.js文件。这里针对指定了参数的分支进行介绍:
首先开场部分,获取到这次安装的类型,如:optionalDependencies、devDependencies、、dependencies等等,这里可以看见,如果没有指定安装类型,那么默认作为dependencies。
再去校验参数的有效性,将前面已经获取到的args信息去validate-args.js文件校验,这里也体现了代码的严谨性吧。
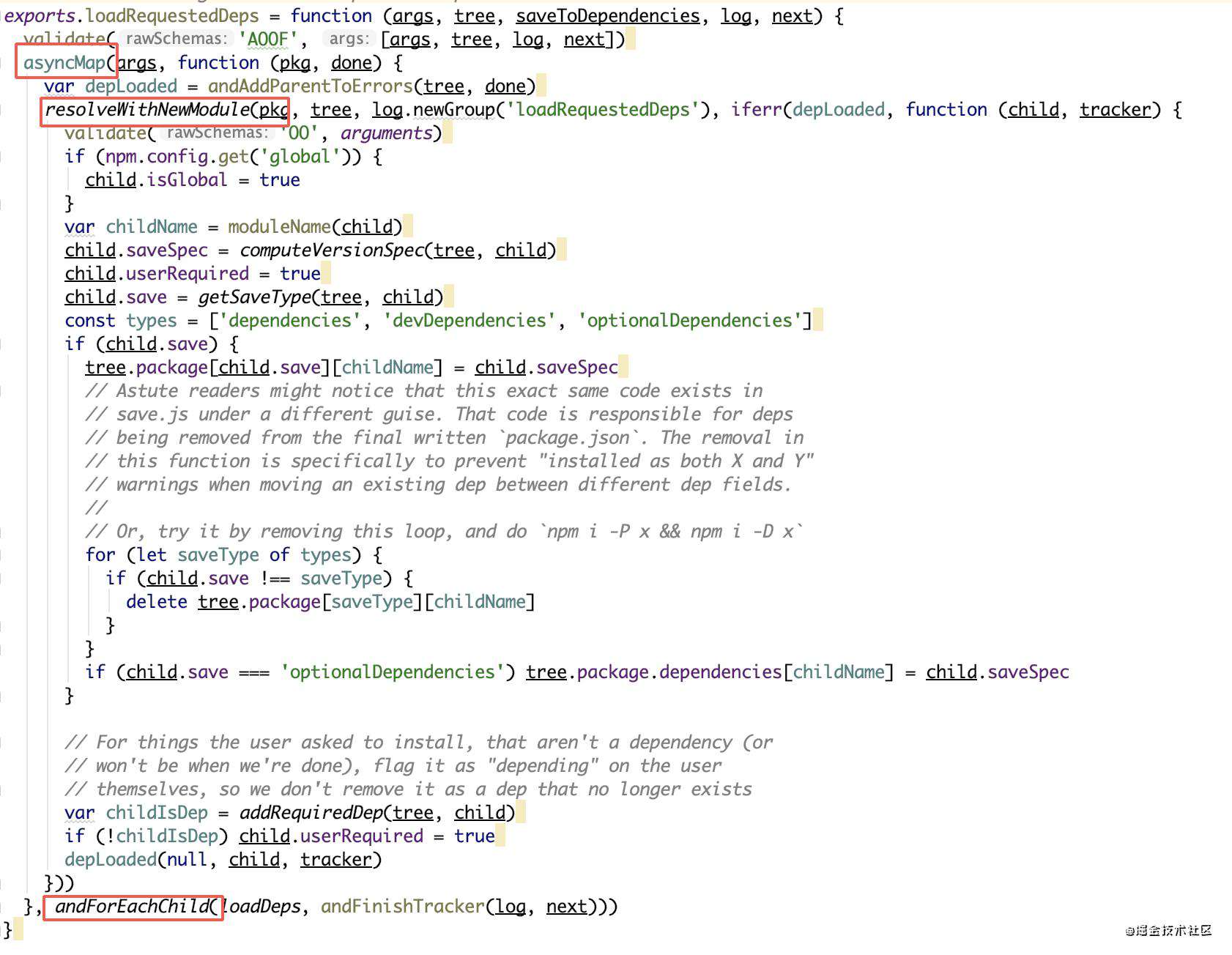
然后就是核心部分了,loadRequestedDeps将这个args加到idealTree上去,这个步骤会涉及到包的打平。可以将在args看成是一颗小tree,把小tree上的节点加载到idealTree上的过程中就会涉及到包比较:这个包信息是否已经存在idealTree上了或者满足是符合semver规则,也可以看见安装包的版本是怎样变化的,所安装包a的依赖b是不是和在开发包a时指定需要的依赖包b一样,也可以看见怎么为一个包找到它可以挂载的最高的父节点。下面是这个方法重要的几个部分,大致是:slide包里面asyncMap并行去处理参数,resolveWithNewModule处理小tree的最顶层节点,andForEachChild在之后对每个自节点进行处理,这个过程是比较耗时的*。*
debugTree、debugActions
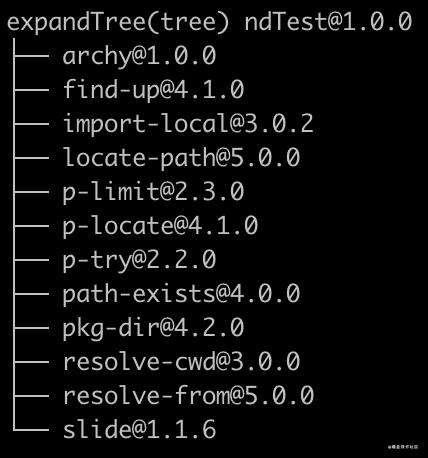
这两个步骤没有进行很重要的处理,debugTree对currentTree和IdealTree使用archy进行处理,对依赖形成一个树形依赖结构,类似:
同样,debugActions也是对得到的actions进行类似log的处理:

generateActionsToTake
这个步骤主要进行的动作有:
1、validateTree:遍历idealTree,查看当前包进行安装安装的时候,是否满足peer dependencies,如果不满足那么输出warning;
2、diffTrees:比较currentTree和idealTree,首先将这两棵树使用flattenTree打平,从根结点的“/”key值开始,每个key都是相对于根结点的路径,比如/@babel/plugin-proposal-dynamic-import。两棵树初步对比会得到那些包add、哪些包remove、哪些包update等等。如下图:

然后把这些数据进行过滤,具体的过滤可看filterActions方法,得到的结果放入this.differences,这个步骤有个有意思的方法,function *pkgAreEquiv*(aa, bb) 比较两个包是否相同。differences截图示例,如果不存在node_modules的项目,那么应该全是“add”,如果是安装指定的包,那么可能有“add”、"update"、"remove"、“move”等。


3、computeLinked:如果diff不为空,那么检测缓存,链接到合适的全局包,如果在全局存在,那么将它从tree中移除
4、checkPermissions:如果diff不是空,检测当前执行的动作在需要执行的目录下面的权限,对于add、update\remove、move动作进行对应的权限检测。
5、decomposeActions:如果diff不为空,对diff进行区别处理,根据cmd的不同,add、update、move、remove以及默认类型,对它进行不同处理之后加入到todo中。todo截图示例:

startAudit
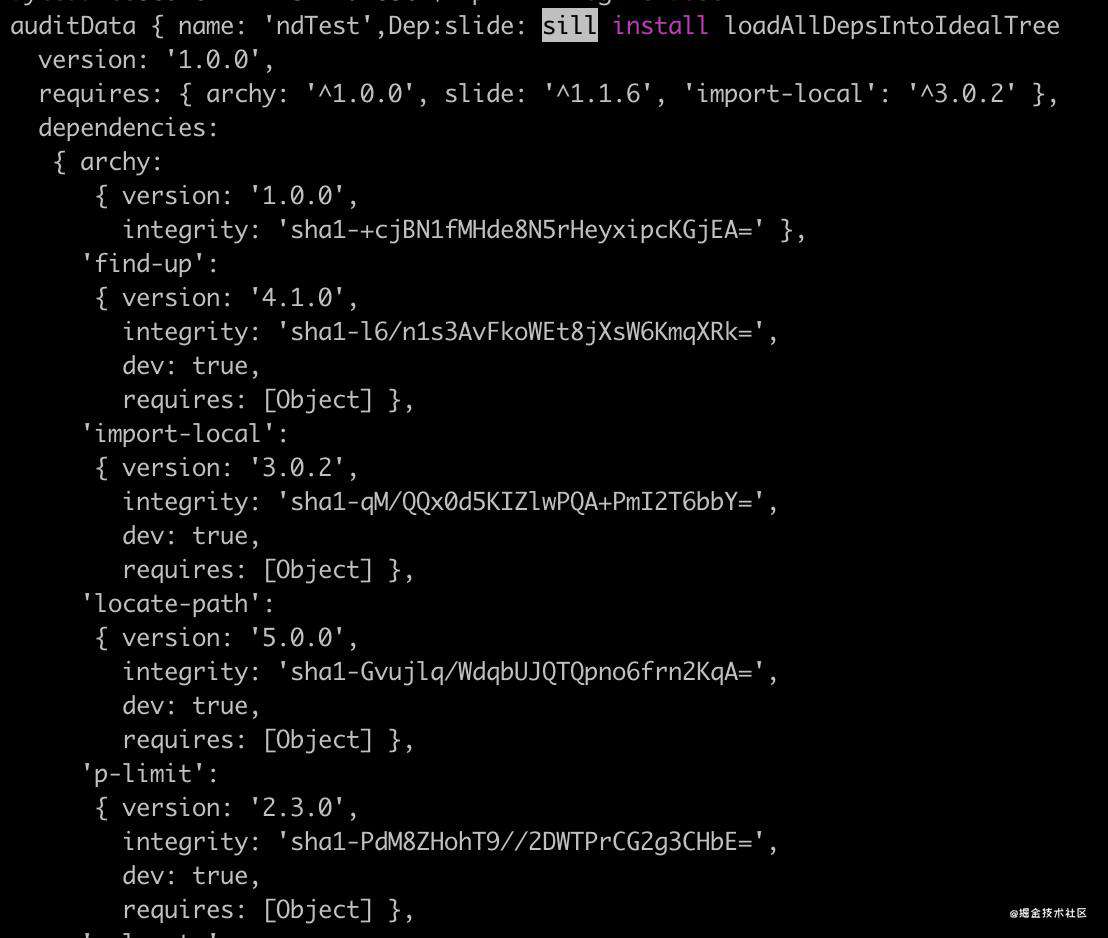
对安装的包进行audit,function *generateFromInstall* (tree, diffs, install, remove)根据前面得到的actions和diffs,更新metaData。下面是auditData部分截图:
并且返回 generateMetadata()这个promise,在后面executeActions步骤中使用。
executeActions
开始真正的安装动作,执行todo里面所有的动作。里面的动作分:doParallelActions、doSerialActions、lock、rimraf四种。
执行过程部分输出截图demo:


这里对install源码进行简单介绍,对于这种过程复杂的代码使用调试手段辅助应该会更好,可以去node官网看一圈。介绍一种简单的调试方法,新建一个node项目之后,在package.json的script中添加脚本:"npm-debug":“node --inspect-brk=5858 ${prefixUrl}/lib/node_modules/npm/bin/npm-cli.js install [option react@16.8.0]”。在调试的过程中一边调试一边看控制台的输出信息以及node_modules中的变化应该可以对安装过程有更多的了解。
npm缓存文件夹
一直都比较好奇npm的缓存是把文件存在哪里的,然后文件存放路径选择的依据是什么,现在来根据缓存里的数据倒推一下:npm的缓存文件夹.npm中存在_cacache文件夹,里面存在content-v2、index-v5、tmp。index-v5索引文件夹,content-v2存放压缩包的文件夹。
索引:在index-v5中搜索archy,获取它的索引信息,得到哈希值:9323fd73c05db8792d37c9c0729f5f570e2d231672968fb966ba05443b446bc6,这个哈希值就是存储的路径了,不过为什么会是这个哈希呢,下面找下原因:
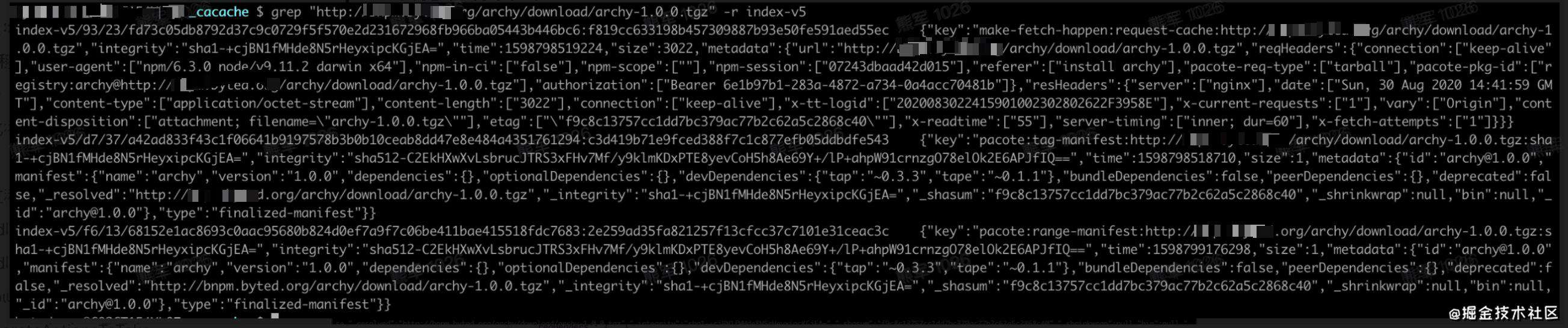
打开文件index-v5/93/23/fd73c05db8792d37c9c0729f5f570e2d231672968fb966ba05443b446bc6:f819cc633198b457309887b93e50fe591aed55ec获取到key:make-fetch-happen:request-cache:http://bnpm.byted.org/archy/download/archy-1.0.0.tgz,然后实验常用hash算法,得到使用sha256对这个key计算之后得到的索引存储位置,也就是得到这个哈希值。
压缩包:得到索引之后,将文件格式化得到:

观察它们的值,貌似只有etag有可能是需要的,etag为f9c8c13757cc1dd7bc379ac77b2c62a5c2868c40,那么找到content-v2/sha1/f9/c8/c13757cc1dd7bc379ac77b2c62a5c2868c40果然看见了这个文件,显示的信息和metadata里面的其他信息符合。
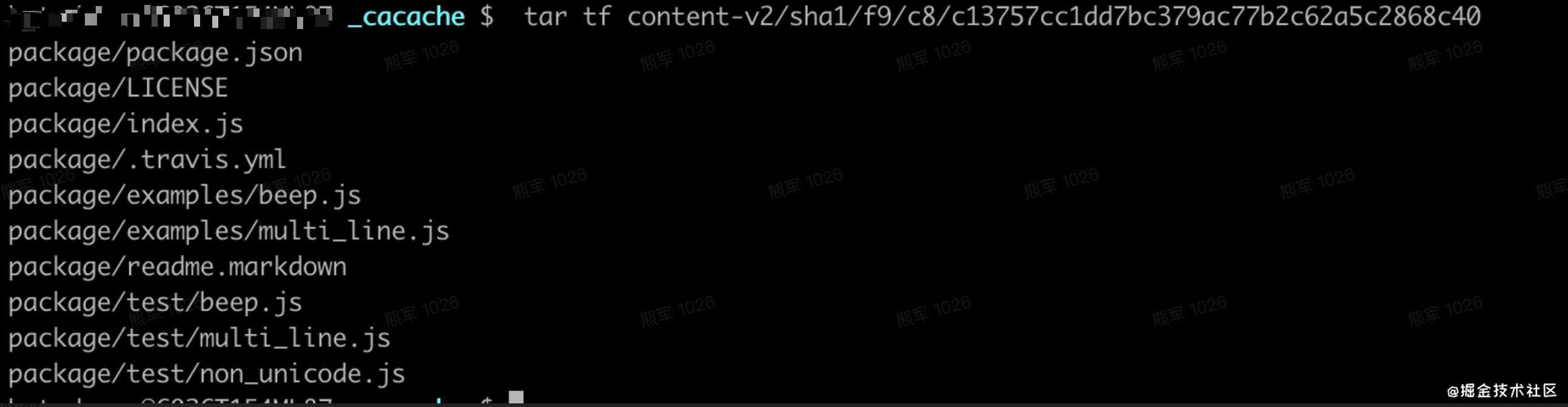
解压它:tar tf content-v2/sha1/f9/c8/c13757cc1dd7bc379ac77b2c62a5c2868c40,得到:
里面的内容和archy相同。
在有package-lock的情况下,根据lock里面的包名、版本、integrity拼一个key出来去找meta信息。没有lock就只能去请求registry了,请求下来也有一样的meta信息
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!