
12 月 2 日,Oracle 在其官网正式推出 “MySQL Database Service with Analytics Engine”。作为 MySQL 产品的一个重大增强,这一特性颇引人注目。周末抽空做了个简单了解,各位从中可窥其一二。(部分资料、插图来自 Oracle 官方网站)。
1.MySQL 的天然短板 “数据分析”
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
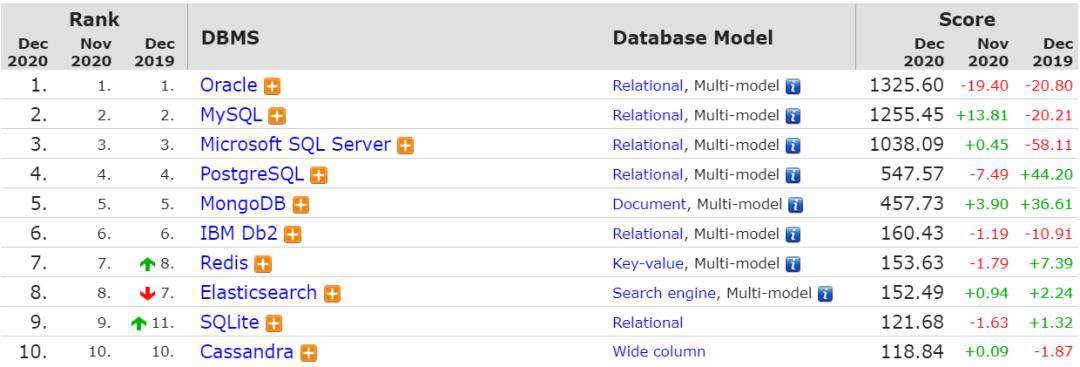
MySQL,作为最为流行的一款开源数据库,已经得到非常广泛地使用。从最新的 db-engines 指数可以看出,其在数据库领域中占据了重要的位置。
但作为一款如此流行的数据库产品,其存在一个明显的短板就是数据分析。相信 MySQL 使用者都有这种感觉,在大规模数据情况下 MySQL 有些力不从心。尽管其内核也在不断加强这方面的能力(如最新 8.0 支持 hash join、直方图等),但相较于其他数据库仍然存在一定劣势。其核心在于 MySQL 原生是为 OLTP 场景设计的,并没有考虑 OLAP 场景。虽然也有一些厂商通过扩展其存储引擎,增强其数据分析能力,但总体来讲还是不尽如人意。于是,通常的一种选择就是在数据分析时,不得不将数据迁移到另一种数据库 / 大数据架构中。通过后者,去完成数据分析工作。在这一过程中,需要开发者自己定义 ETL 逻辑(可能基于日志解析或逻辑数据抽取),完成数据迁移。同时,在运行中需时刻关注数据同步,保证数据有效性。在使用上,还需编写单独的语句(异构数据源的语句),来完成数据分析动作。整个这一过程,无疑对用户来说具有一定的使用门槛,且需要花费额外的精力去解决这一问题。相信 Oracle 原厂也是看到这一问题,因而推出了 MySQL Analytics Engine。
2. MAE 到底是个啥?
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
MySQL Analytics Engine(简称 MAE),笼统来说是一款内置的分析引擎。通过它与 MySQL Database 的组合,可以使得数据库管理员和应用程序开发人员能够直接将 MySQL 数据库作为 OLTP 和 OLAP 工作负载的统一服务。其提供的 “MySQL Database Service with Analytics Engine”,是由一个 MySQL DB 实例和多个分析节点组成。当分析功能被启用时,分析服务将被安装在 DB 实例上,其负责集群管理、数据加载、查询执行等。从用户角度来看,可以通过标准的 MySQL JDBC/ODBC Connector 来连接使用。下面我们详细展开看看
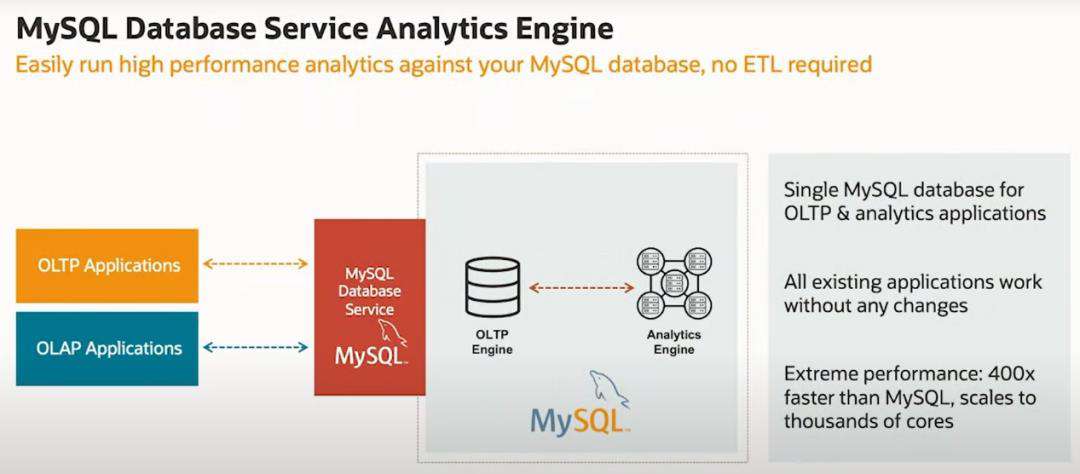
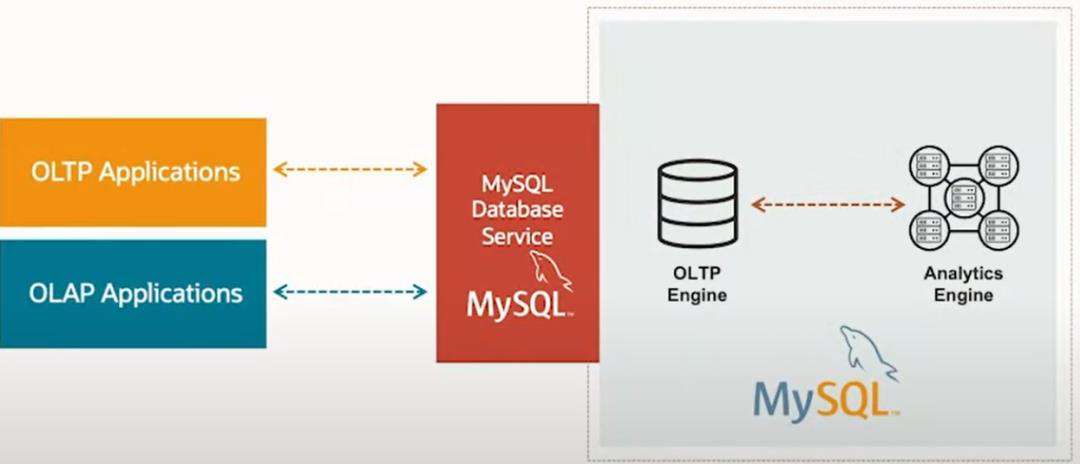
首先从整体使用来看,对外提供统一的 MySQL Database Service。用户仍然是通过传统的方式去使用它,无论是 OLTP 还是 OLAP 场景。在这个服务的内部,是包括了传统的 OLTP 引擎和新的 Analytics 引擎。在数据上,也是存在两份。前者仍然保存在例如 InnoDB 这样的存储引擎之中,后者则保存在一组节点构成集群的内存之中。正常事务操作带来的数据变化,会透明地传播到后面的分析集群中,以加速分析处理。这样就使得客户可以在单个数据库平台上同时运行 OLTP 和 OLAP 工作负载。简言之,就是两个计算引擎、两份数据存储。
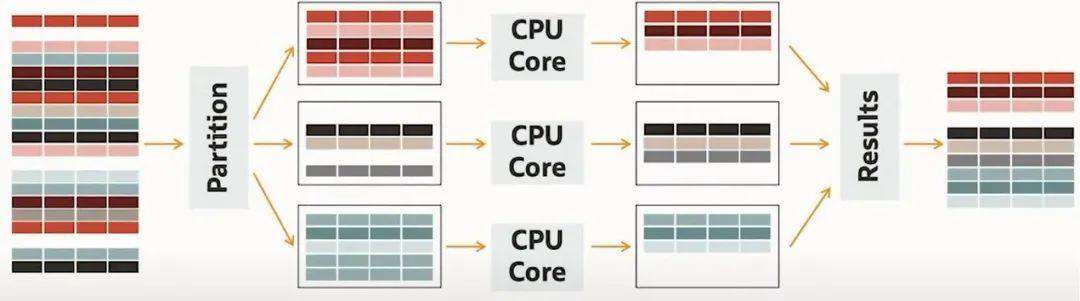
MAE 的核心工作思想就是 “化大为小”,通过分区机制,将数据打散后利用独立的 CPU 资源进行处理。处理后的结果统一返回。
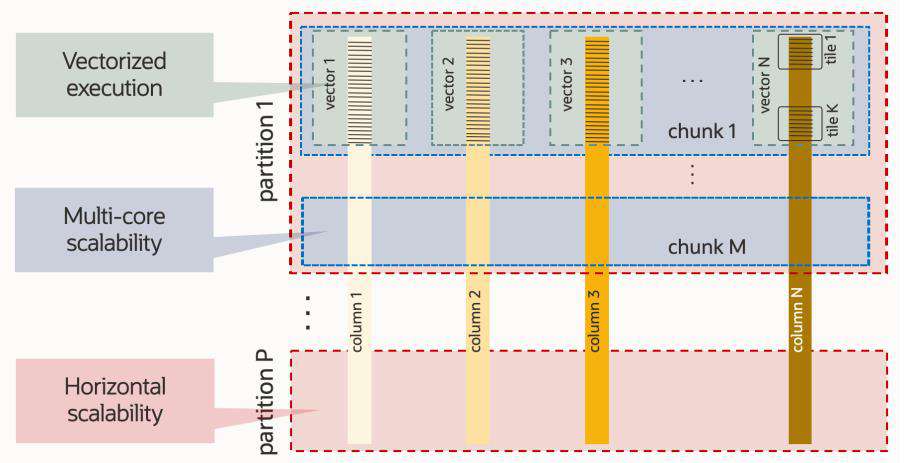
在 MAE 内部,由多个分析节点组成。其具体节点数量,可由 MySQL 分析引擎提供的自动配置顾问自动获得。在节点中,数据以一种混合列压缩的格式存储。这有助于向量化处理,从而获得非常好的查询性能。数据在内存中运行之前被编码和压缩。这种压缩和优化的内存使用,对于数值和字符串数据尤为显著,可提高性能并减少内存占用,从而为客户降低成本。同时在每个节点中使用并行操作技术,这为分析提供了高缓存命中率,并提供良好的节点间可伸缩性。集群内的每个分析节点和节点内的每个核心都可以并行处理分区数据,包括并行扫描、连接、分组、聚合和 top-k 处理。
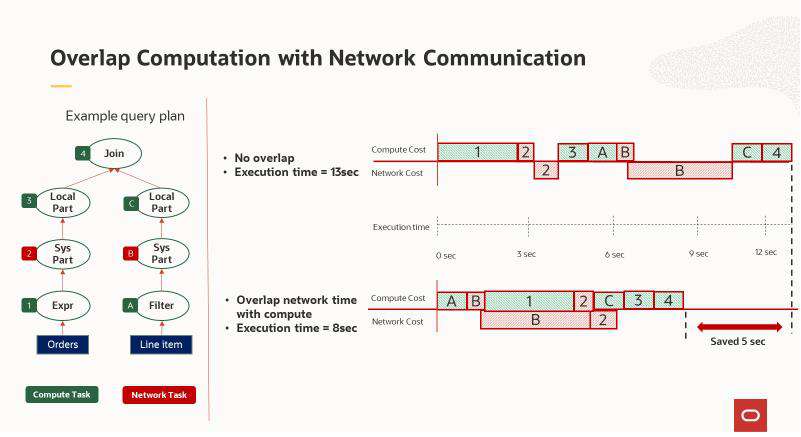
MySQL 分析引擎为分布式内存分析处理实现了最新的算法。通过使用向量化的构建和探测连接内核,可以快速处理分区内的连接。通过使用异步批处理 I/O,优化了分析节点之间的网络通信。算法的设计是为了使计算时间与跨节点的数据通信重叠,这有助于实现良好的可伸缩性。
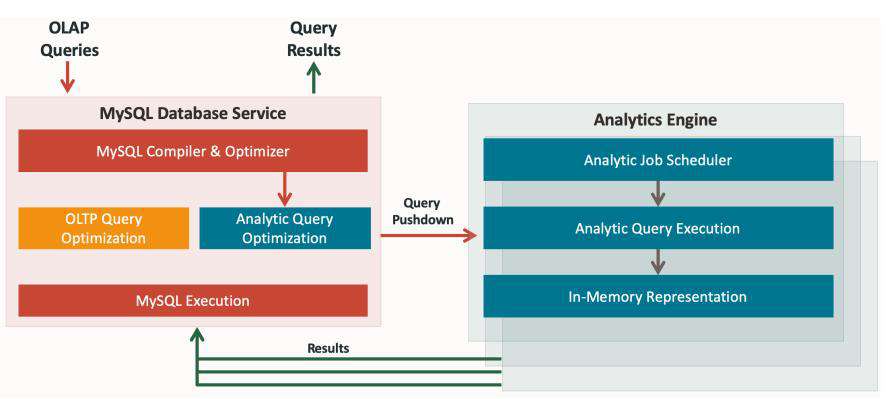
MySQL 分析引擎与 MySQL 数据库服务的集成为企业的所有 OLTP 和分析需求提供了一个单一的数据管理平台。MySQL 分析引擎被设计成一个 MySQL 可插拔存储引擎,它完全屏蔽了存储层的所有底层实现细节,不让最终用户看到。用户和应用程序通过集群中的 MySQL 数据库节点与 MySQL 分析交互。用户通过标准工具和基于标准的 ODBC/JDBC 连接器连接到 MySQL 分析引擎。MySQL 分析引擎支持与 MySQL 相同的 ANSI SQL 标准和 ACID 属性,并支持不同的数据类型。这使得现有的应用程序无需对其应用程序进行任何更改就可以利用 MySQL 分析引擎,从而实现简单快速的集成。一旦用户向 MySQL 数据库提交查询,MySQL 查询优化器就会透明地决定是否将查询卸载到分析集群以加速执行。这是基于 MySQL 分析引擎是否支持查询中引用的所有操作符和函数并且使用分析引擎处理查询的估计时间比在 MySQL 中更少时,查询将被下推到分析节点进行处理。处理之后,结果被发送回 MySQL 数据库节点并返回给用户。
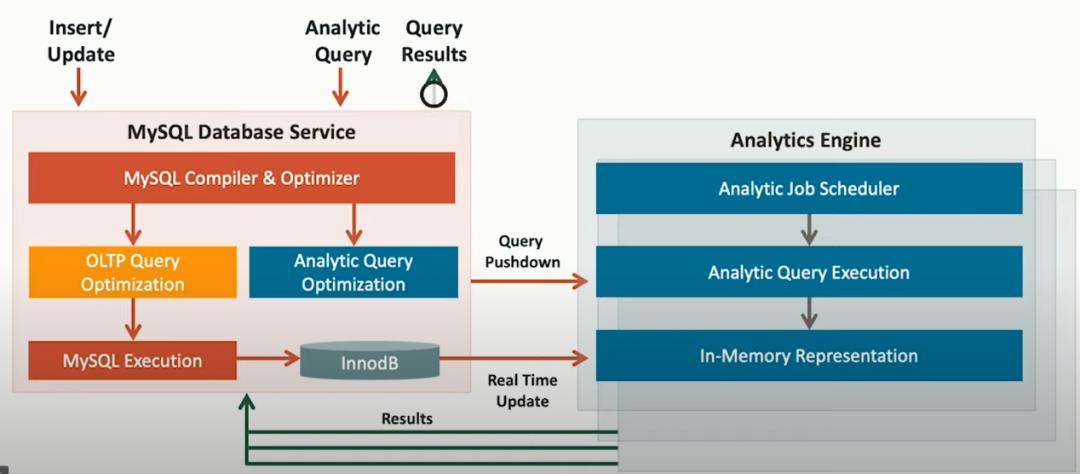
由于 MySQL 分析引擎是一个内存处理引擎,数据被持久化到 MySQL InnoDB 存储引擎中。对表的任何更新都会自动实时地传播到分析节点的内存中。这使得后续查询始终能够访问最新的数据。这是通过一个轻量级的更改传播算法在后台完成的,该算法可以跟上 MySQL 的数据更新率。同步原理未说明?
3. MAE 能为我们带来什么?
人生基本上就是两件事,选题和解题。最好的人生是在每个关键点上,既选对题,又解好题。人生最大的痛苦在于解对了题,但选错了题,而且还不知道自己选错了题。正如人生最大的遗憾就是,不是你不行,而是你本可以。
从产品角度来看,MySQL Analytics Engine 是一种云原生服务,专门在 Oracle 云基础设施中提供,为分析工作负载提供了令人信服的性能和成本。使用 MySQL 数据库管理企业数据的组织现在可以使用 MySQL 分析引擎运行分析查询,性能显著提高,成本更低,不需要 ETL,并且支持实时分析。该服务可以只部署在云中,也可以部署在混合环境中,它简化了事务和分析应用程序的管理。从其推出产品上,可归纳为以下几个理念:
❖ ONE DB
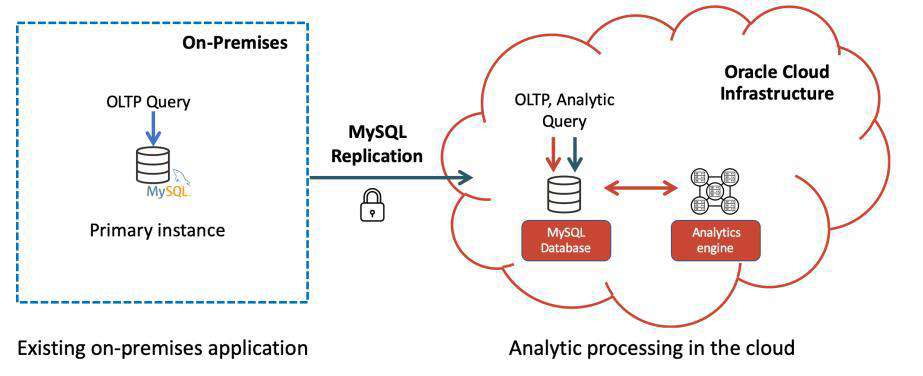
这一产品最核心价值点就是统一处理场景。之前 MySQL 的在处理混合业务场景是不得不使用下面方式(如下图)
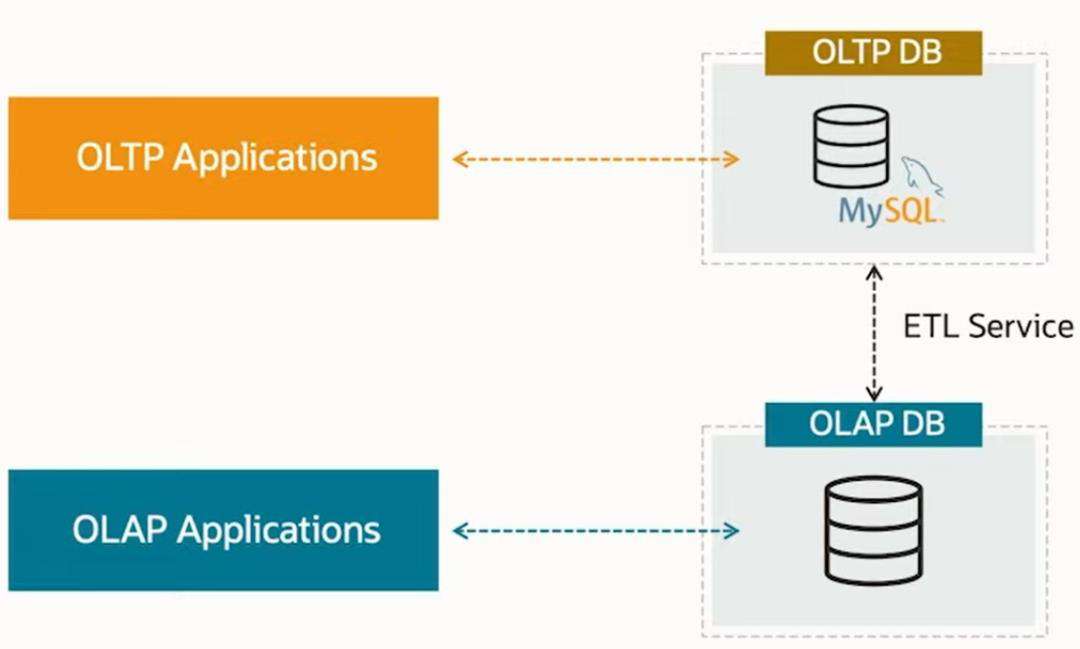
通过引入 MAE,增强 MySQL 能力,达到统一效果。
❖ ONE SQL
第二个价值点在于,不仅仅是统一平台,而且使用同样的交互方式。原有的逻辑,不需要做任何的改变。无论是前端的事务交易场景,还是后端的数据可视化分析,均不需要做改变。这无疑对用户的吸引力很大,可以有效保护用户的已有软件资产。
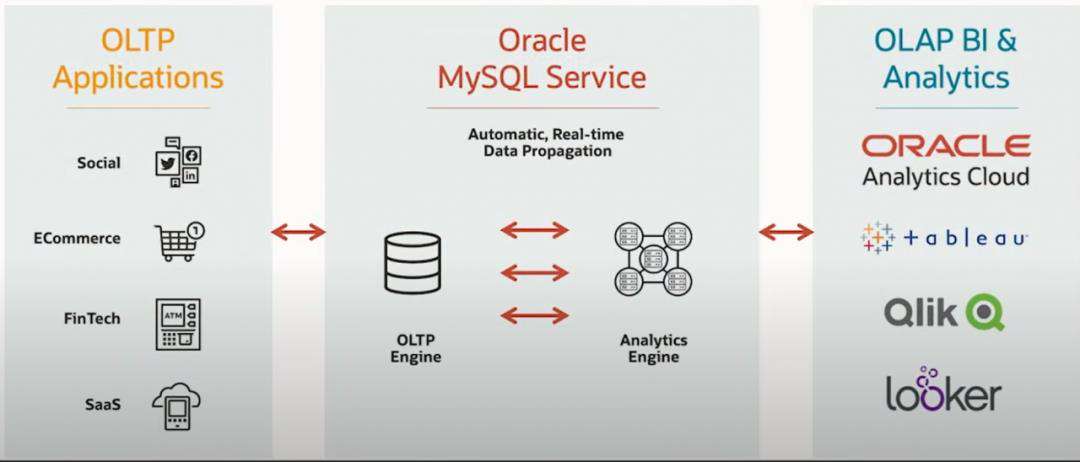
❖ NO ETL
对用户来说,不在需要关心数据同步的细节,不需要编写额外的 ETL 作业。这将大大减少用户的负担。
❖ NO TUNING
在 MAE 之前,用户如果想解决数据分析问题,无外乎两种。要么在库内解决,要么在库外解决。在库内解决的话,需要对 MySQL 做大量的优化工作或者采取针对分析场景的存储引擎,这些都带来了优化的工作量。对于库外方案同样如此,用户需要自己完成优化工作。而使用 MAE 则不需要顾虑这点。其利用了 Oracle 实验室开发的自动机器学习 (AutoML) 功能来自动化服务的各个方面。由于这种自动化是基于机器学习的,系统可以智能地预测各种场景并采取行动,包括自动估算工作负载所需的分析节点数量。当服务启动时,需要将运行分析查询的数据库表加载到 MySQL 分析集群内存中。所需集群的大小取决于加载所需的表和列,以及此数据在内存中实现的压缩。在传统的配置中,用户需要猜测集群的大小。由于空间限制,低估会导致数据加载或查询执行失败。高估会导致不必要资源的额外成本。因此,用户会不断迭代,直到确定正确的集群大小,当更新表时,这种大小估计就会变得不准确。而 MAE 则可自动完成上述过程。
❖ HIGH PERFORMANCE
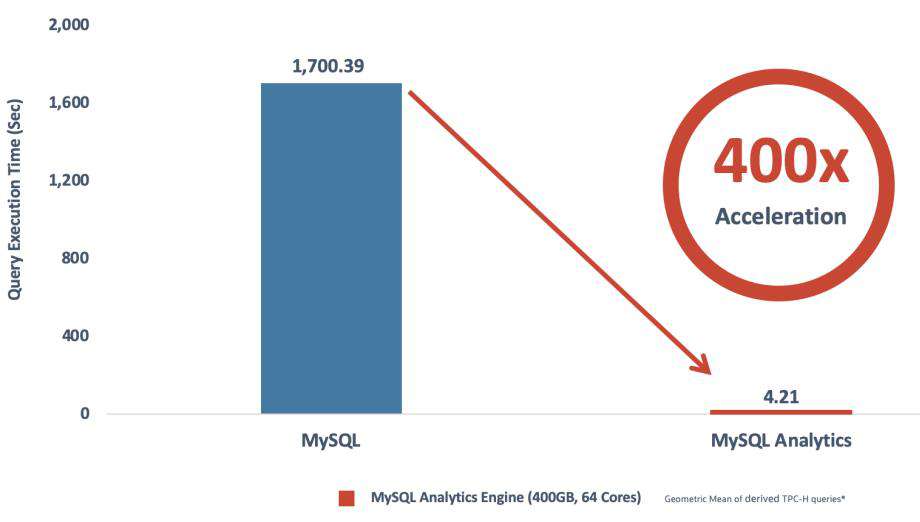
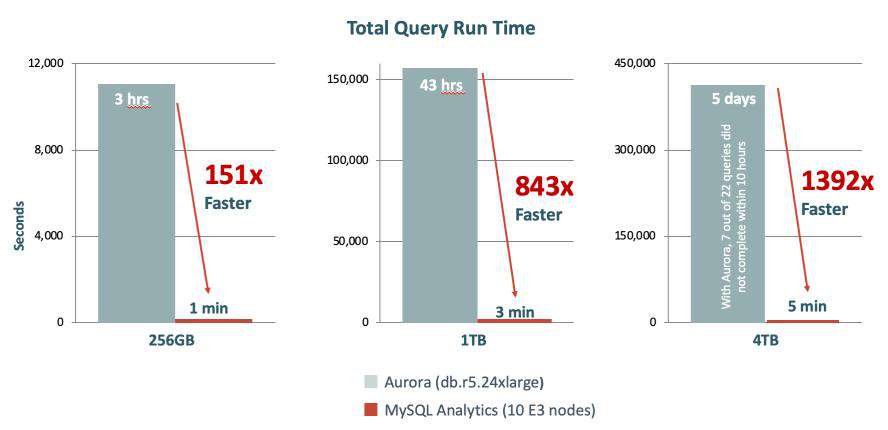
MAE 作为一种分布式、可伸缩、内存型、混合列式查询引擎,其通过内存中的矢量化处理及大规模节点间和节点内并行处理来极速性能。同时查询处理已针对 Oracle 云基础设施做了优化,包括节点间网络带宽优化等。通过上述能力,MAE 提供了强大的分析能力。下面是针对其主要竞品的性能对比。
- MySQL Analytics vs MySQL
- MySQL Analytics vs Amazon Aurora
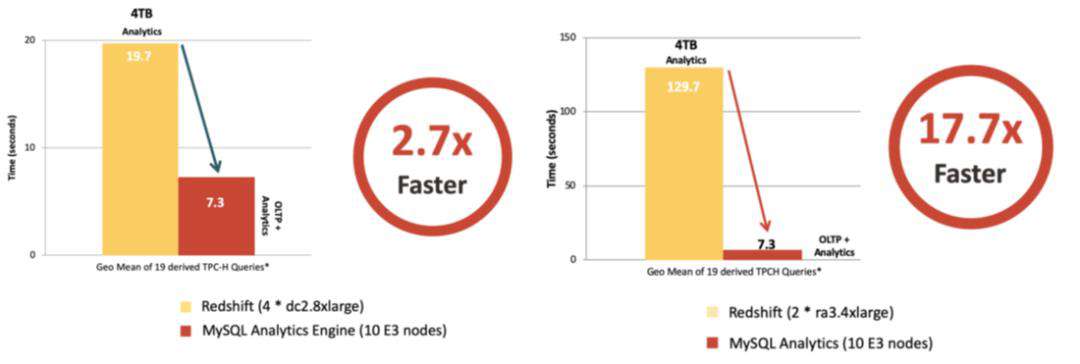
- MySQL Analytics vs Amazon Redshift
❖ LOW COST
使用带有分析引擎的 MySQL 数据库服务的成本取决于配置的分析节点的数量。分析集群的大小取决于数据集的大小和工作负载的特性。一个分析节点可以容纳大约 400GB 的数据。当客户使用 Analytics Engine 迁移到 MySQL 数据库服务时,他们的成本有望大幅降低。与 Amazon Aurora 和 Redshift 相比,MySQL 分析引擎的成本是其成本的 1/3。
❖ EASY SCALE
MAE 目前在一个集群中支持最多 24 个分析节点(上千个 Core),处理能力约为 10 TB 的分析数据。10TB 是在给定时刻可以填充到分析节点内存中的大约数据量。MySQL 数据库中存储的数据量没有限制,客户可以选择从 MySQL 数据库模式中加载哪些表或列到分析节点的内存中。如果查询不再需要这些表,用户可以从内存中删除这些表,为其他数据腾出空间。
❖ EASY USE
MAE 将大量细节隐藏在后面,对于前端客户来讲使用非常简单。只需要根据推荐大小配置分析集群、配置预加速查询的对象、手工完成第一次加载。后面即可享受到分析集群带来的加速能力。

通过查看执行计划,可以直观看出是否使用了分析集群(下图中的 Using secondary engine RAPID)

此外,针对混合云场景(即无法将数据部署到云端的客户),可以利用 MySQL 复制将本地 MySQL 数据复制到 MySQL 分析引擎,同样不需要 ETL。目前 MAE 仅在 Oracle Cloud Infrastructure (OCI) Gen 2 hardware 平台提供。
写在最后
MAE 的出现,很好地弥补了 MySQL 原生在数据分析场景的短板。相信,这一特性将更加扩大 MySQL 的使用范围,为其在更大规模、更为重要的企业化应用铺平道路。比较遗憾的是,MAE 目前仅能在 OCI 中使用,目前国内的广大线下用户还无法使用。

常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!