概述
正则表达式在我们日程的工作项目中,应该是一个经常用到的技能。在做一些字符的匹配和处理的过程中,发挥了很大的作用。我们这篇文章主要是通过一个我在工作中遇到的性能问题,来探究下正则表达式是如何影响我们的代码性能的。在我们遇到了正则表达式有性能平静的时候,我们应该如何的来对它进行优化?
如果对正则表达式还没有什么概念,或者说不了解的同学,可以先参考我之前写过的博客:
- 正则表达式系列之初级入门篇
- 正则表达式系列之中级进阶篇
问题现状
在我们日常的工作中,如果不需要去调整正则表达式的话,大部分人其实是会选择性忽略它的。这就导致了大部分人对正则表达式其实并不是太了解。在正则表达式出现问题以后也不知道如何去解决。
因为我在美团是负责做大象Web/PC的相关开发,所以在日常的工作中免不了要经常和正则表达式打交道,比如识别文本消息中的URL进行高亮,或者说识别会议室、解析特定格式展示不同的UI等。在这种情况下,我免不了会跟大量的正则表达式打交道。从长时间与正则打交道的经历中,也有了部分的经验总结。
下面我们通过一个工作中具体的例子,来看下正则表达式是如何让你的网页卡住的?
在最近的性能问题优化排查中,我们发现在遇到文字内容较多(约15000字)的文本消息文字处理时,render函数会有一个比较大的性能损耗,每次渲染需要差不多100ms。因为消息每次渲染都是20条一起,因此正则表达式一旦有性能问题,就会因为多次渲染的放大效应,被用户很明显的感知到。如果每条消息处理都需要100ms,那么20条消息处理就会直接卡顿2s,这其实对于用户来说是不可以接受的。
具体我们可以看下火焰图(火焰图就是Chrome的devtools中,分析profile时候的图表,大家可以理解为一个调用时间图谱,如果不了解,推荐看看阮一峰老师的如何读懂火焰图? - 阮一峰的网络日志):
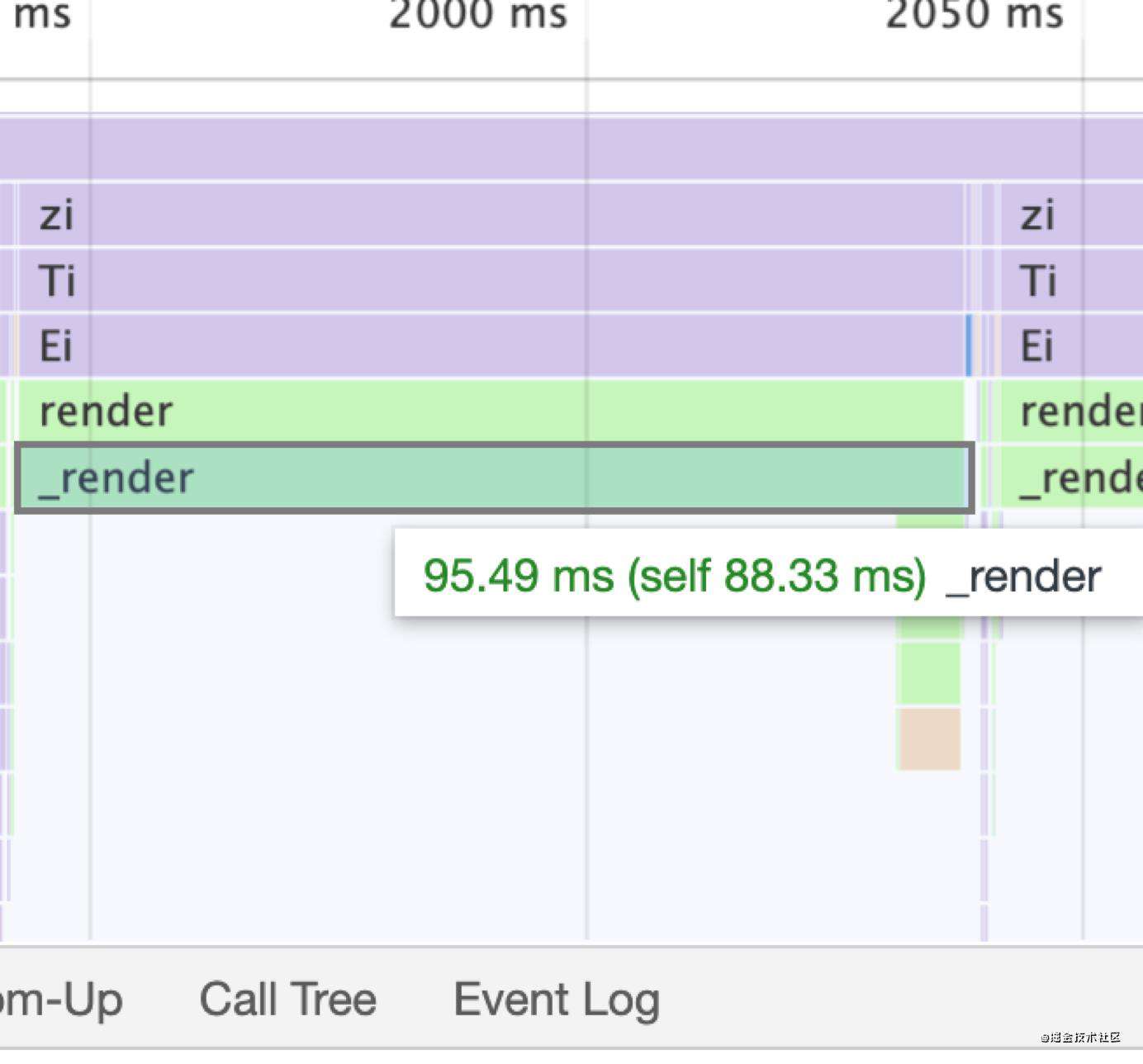
通过上述的火焰图,我们可以看到这个render渲染函数每次执行都差不多100ms。对于JavaScript来说,100ms其实时间已经很长了。那么这一百毫秒中具体干了哪些事情呢?
我们简单的梳理一下当前的代码,发现最有可能的原因就是正则耗时的影响。在消息处理中,有两个需要进行匹配的正则,一个是匹配会议室进行高亮的,一个是匹配引用消息进行格式转换的。这两个正则分别如下:
const QUOTED_MSG_REG = /([^「]*?)「((?:[a-zA-Z0-9\u4E00-\u9FBF_\.\s]{0,40})\:(?:.|\n)*)」\n(—){10}\n((?:\S|\s)*)$/m;
const MEETING_ROOM_REG = /北京厅|天津厅|石家庄厅|济南厅|哈尔滨厅|...(此处省略200+个会议室)|台湾厅/mg;
这个两个正则表达式用来匹配的文本如下:
// 引用格式
「张三:老司机」
——————————
带带我
// 会议室
张三呀,我们去 常德厅 开个会吧,叫上其他人
一开始看,大家可能觉得这两个正则都很正常,我们在正常的工作中也会写出这样的正则表达式,没有发现什么问题。
如果告诉你这两个正则表达式执行有性能问题,那么大家可能还会觉得,会议室匹配的文本正则这么长,需要匹配的会议室这么多,肯定是这个正则有性能问题,导致了执行时间过长。
那么具体情况到底是不是和我们直观感受一样呢?我们来对具体问题进行一个分析。
问题分析
为了分析我们上面说到的这两个正则表达式性能到底怎么样,我从网上找了一些文字,来模拟消息的内容。通过使用正则表达式进行匹配,在Node端执行计算耗时,得到的一个字数与时间的关系图如下,表格的横坐标是字数,纵坐标是时间(ms):
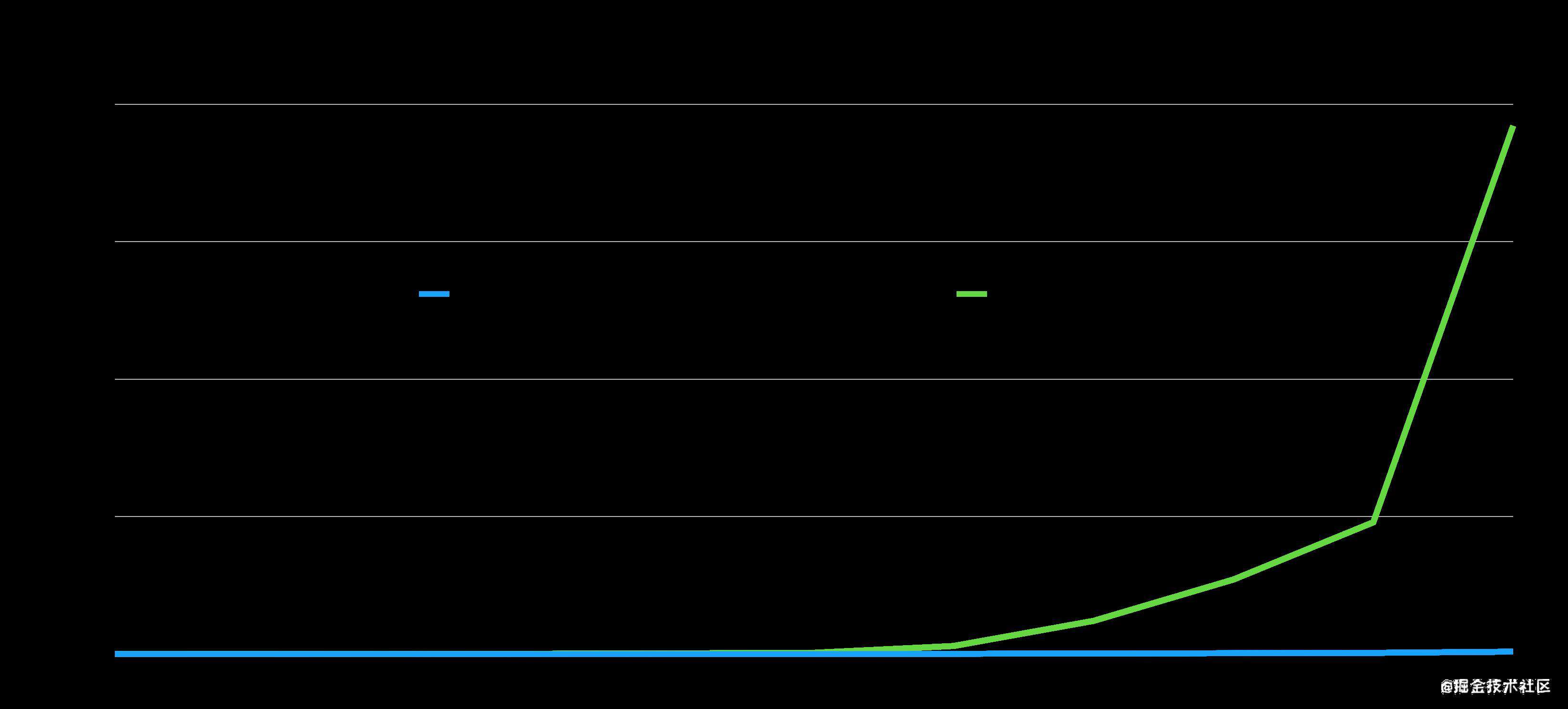 这个和大家的猜测是不是一样?在我之前最早的猜测中,我也以为是正则长度越长,那么性能就越差。但是,这个和我的猜测正好相反,反倒是看上去比较短的。引用正在表达式性能问题最大。
这个和大家的猜测是不是一样?在我之前最早的猜测中,我也以为是正则长度越长,那么性能就越差。但是,这个和我的猜测正好相反,反倒是看上去比较短的。引用正在表达式性能问题最大。
从我们分析的数据来看,在10000字之前,其实差别没有那么大。 但是在超过10,000个字的时候,其实耗时差异就比较明显了。
大家可以看到引用的这个正则表达式,他的耗时其实是发生了指数型的上升。 在超过50,000字,以后其实这个正则你可以认为基本上就不能够再使用了,而且这还是在性能比较好的MacBook情况下。 如果是在一些更老的电脑,或者说Windows的低端本上,那么这个耗时其实还会更大。你想想你,你能够接受你的开发的项目,卡住2秒不动吗?
反倒是我们觉得比较复杂的这个会议室正则表达式,它在匹配的内容字数增加的情况下,性能其实没有明显的增加,一直都稳定在100毫秒以下。
看到这里,有人可能会觉得是不是match方法,它比较吃性能呢?也有人可能会想,我们是不是在match之前增加一个相同正则表达式的test判断?如果符合的话,我们再执行match,这样是不是就能够提高我们的性能呢?
那么我们把match方法换成test方法来看一下,这样能不能够提升我们正则匹配的性能呢?下图是我们使用会议室正则表达式来进行匹配的一个耗时图。我们从图中可以看到相关的执行耗时情况:
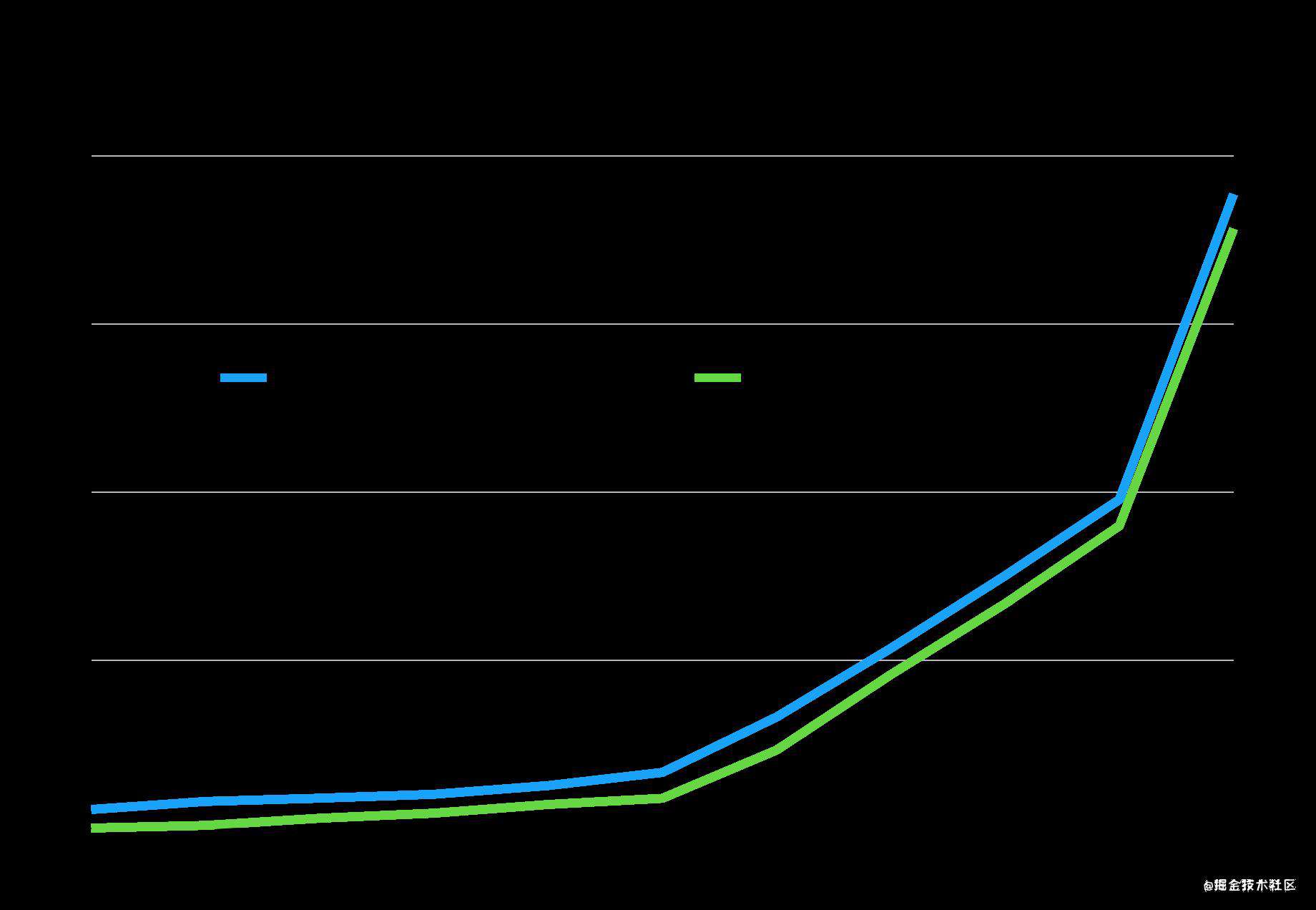 从图中可以看到,test方法并不会比match方法节省更多的时间,相反来看他的耗时其实比match还略微有增加。不过可能就是几个毫秒。我尝试了一下性能问题更明显的引用正则表达式,得到了结论也是一样的。所以我们想到的先使用test方法来进行判断,如果test方法命中的话再进行match。这个不但没有优化,反倒是可能会损耗双倍的性能。
从图中可以看到,test方法并不会比match方法节省更多的时间,相反来看他的耗时其实比match还略微有增加。不过可能就是几个毫秒。我尝试了一下性能问题更明显的引用正则表达式,得到了结论也是一样的。所以我们想到的先使用test方法来进行判断,如果test方法命中的话再进行match。这个不但没有优化,反倒是可能会损耗双倍的性能。
既然相同的正则表达式使用任意一个方法执行的时候都会有比较明显的性能问题,那么我们就只能从正则表达式本身的优化入手了。我们来看一下,为什么我们觉得比较复杂的正则表达式,耗时没有什么变化。反而我们认为比较简单的正则表达式时间的增长却这么明显呢?
原理分析
其实,正则表达式性能最大的影响来自于正则表达式的回溯。如果一个正则表达式回溯的越多,那么它的性能损耗就越明显。我们可以去看一下上面两个正则表达式的情况。
其实上面两个正则表达式都有回溯的问题。如果大家不了解,回溯,可以去看下我之前的那一篇 正则表达式系列之中级进阶篇。在这里我们简单介绍一下回溯回溯的原因:正则表达式在匹配的过程中需要往回走重新进行匹配,这就会导致回溯。一般产生回溯的有这么几种情况,一种是分支,一种是量词。
我们可以看看上面两个正则表达式,会议是这个正则比较简单,他其实是很多分支的集合体;引用的这个正则就不同了,他的回溯主要是来源于量词。尤其是[^「]*这种的存在,导致了大量的回溯情况。
所以说一个正则表达式性能好不好跟他的长短没有必然的联系。而是跟他具体的写法有关。如果这个正则表达式很多地方都有回溯的情况,那么他的性能必然就好不了。反过来说,如果一个正则表达式虽然很长很复杂,但是它能够尽可能的避免回溯。需要匹配的文本也尽可能的清晰,那么这种情况下它的性能其实是很不错的。
解决方案
遇到这个问题,我们一般会有以下两个解决方案。
优化正则表达式本身
第一个解决方案就是尽可能的去优化这个正则表达式本身,去尽可能消除里面一些回溯的情况。这个也是我们一般最常用的一个解决方案。具体有以下2个操作:
- 在明确匹配规则的情况下,使用
\d{1, 30}来替换.*,尽可能的去明确我们需要匹配的类型与长度。 - 在需要进行不明确数量匹配的时候,尽可能的使用非贪婪匹配,而不是使用贪婪匹配。
同时,还有个规则:在不需要捕获组的情况下,括号尽可能的使用非捕获组(与回溯无)。
总体上来说就是:如果一个正则表达式越精确,捕获的元素越少,那么它的性能就会越好。反之,如果有大量的模糊匹配跟回溯的情况,那么它的性能大概率就不怎么好。
在一般的场景中,我们使用了这个方法,基本上我们的性能问题就能够迎刃而解了。
但是,那么如果我们继续要匹配比较复杂的正则,同时这个正则又没有办法避免回溯的情况,我们应该怎么去优化这个性能的?
优化正则表达式匹配顺序
也就是说在这种情况下,这个正则表达式其实是没有办法再进行优化了,但是我们又需要在日常的项目中使用,不能直接废弃。这就需要我们使用另外的优化方案了。
在正则没有办法修改的情况下,我们可以做正则匹配的分级,尽可能使用一些性能比较高的正则表达式,先进行一些过滤匹配。在命中我们需要匹配的条件以后,再使用比较复杂的正则表达式进行匹配。从而避免复杂的正则表达式频繁的被调用。
我举一个简单的例子,还是以上面的引用正则表达式来分析。如果这个正则表达式我没有办法再进行进一步优化了情况下,我们可以先把他的一些特定的规则摘取出来,进行一个前置校验。我们可以简单的来看一下下面一个代码示例:
let str = 'xxxxxx'; //长文本
const LINE_REG = /\n(—){10}\n/m;
const QUOTED_MSG_REG = /([^「]*?)「((?:[a-zA-Z0-9\u4E00-\u9FBF_\.\s]{0,40})\:(?:.|\n)*)」\n(—){10}\n((?:\S|\s)*)$/m;
if(LINE_GER.test(str)) {
let result = str.match(QUOTED_MSG_REG);
// do something
}
不要在主线程中执行
如果一个正则表达式没有办法通过上述两种方案进行优化(这个概率其实已经很低了,感觉和彩票中奖差不多了),那么我们还有一个最终的解决方案,就是使用Web Workder,来进行耗时的操作计算。
这样的话,我们至少在主线程执行过程中,不会有卡住影响用户操作的问题。
不过,在这个方案中,需要考虑到大量数据通过postMessage传递到Web Worker中的性能损耗问题。
这个方案本质上比较简单,我在具体项目中也没有使用到,因此不展开讲了,有兴趣了解的同学可以自行上网查阅相关资料,或者评论私信留言讨论。
从上面的代码中我们可以看到,我们可以选取一个没有回溯的明确特征条件来先进行一次快速的匹配。一般情况来说没有回溯的正则匹配效率都是特别高,即使是在大量文本处理的情况下也不会对性能有什么太大的影响。在进行了第一次正则表达式匹配后,如果这个文本还是符合当前的条件,那么说明有较大概率它其实是需要我们命中的,那么我们再执行正则匹配即可。
这样的话,我们就能够避免大部分的无意义的性能消耗。
服务端数据处理
如果一个数据量太过庞大(超过1M的文本)时,我推荐对数据进行分页,不要一次性处理所有数据(这个时候正则已经不是瓶颈了,JS执行引擎才是瓶颈)。
但是,有些神奇的项目就是会有这种诉求,遇到这种情况时,我们必须(不是可以,是必须)借助服务端来进行数据处理,前端只做简单的展示逻辑(即使是展示这么大量的数据,渲染也会有比较明显的卡顿和耗时)。
如果没有后端的支持,那么自己用Node搭建一个简单的中转处理服务都行。这个时候需要关注的,就是自己的Node服务如何能够弹性扩容了。
效果验证
在我的项目遇到的性能问题中,只使用了前两个方案对引用的正则表达式进行了优化。我们可以来看一下优化后的渲染耗时情况:
 在通过对正则表达式进行优化后,我们的每次文本渲染时间从100ms直接降到了不到2ms。 这可是50倍的性能提升。对于15000字的文本来说,这个速度可以算是没有任何的性能影响了。
在通过对正则表达式进行优化后,我们的每次文本渲染时间从100ms直接降到了不到2ms。 这可是50倍的性能提升。对于15000字的文本来说,这个速度可以算是没有任何的性能影响了。
我们还试了试极限情况下1000000字的情况,渲染也能够控制在20ms以内,这和之前相比,进步还是很明显的。
总结
正则表达式在我们的日常代码使用中其是很常见的。但是稍有不慎我们就会遇到性能问题。大部分在写代码的过程中,不会去考虑这个正则表达式性能怎么样,都会下意识觉得反正处理的文本长度不大,写的再差也没有什么影响。但是,在项目逐渐发展过程中,有可能由于产品策略调整或者数据的积累,某一个不起眼的正则表达式,就会对整个项目的性能产生决定性影响。
因此我们在具体开发的过程中一定要有性能的意识,我们写的任意一个正则表达式都有可能会导致整个系统的性能问题。因此我们写的每一个正则表达式都应该尽可能的准确,尽可能的减少执行次数。
再遇到正则的性能问题时,正则表达式的优化手段主要有3个:
- 我们需要尽可能的去让我们的正则表达式准确化,越准确的正则表达式匹配时,他的回溯情况就越少,所以它的性能就越高。
- 在正则表达式已经没有办法再进行优化的情况下,我们可以先选取一些没有回复情况的特征值进行先置条件判断,这样的话,我们能够尽量多的去避免一些无意义的好事匹配,优化我们的性能。
- 借助其他线程或者服务来进行正则处理,避免用户卡顿。
希望能够通过上述的具体实战优化,能够让大家了解正则表达式在项目中对性能的影响,也欢迎大家在遇到正则表达式相关的问题时,随时讨论交流,大家一起解决问题,一起进步。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!