开头吐个槽。程序员应该都听说过鄙视链,做C的看不起做C++的,做C++看不起做Java的,做Java看不起做.net的。然而这些所有都看不起搞前端的!似乎前端程序员处于程序员鄙视链的最低端。?
由于前端的产出是看的见摸的着的,所以造成了谁都可以提一些意见的现象:
只看得见界面的产品经理可以提意见;
项目经理也可以有一些意见;
啥也不懂的老板也可以提一些意见;
甚至连后端都可以来提一些意见;
这就是前段开发最大的痛... ...
三流程序员写UI,二流程序员写框架,一流程序员写算法。同学们一起加油吧!
废话不多说,现在开始进入正题。为了更好的阅读与理解,本文主要围绕以下三点展开:
- 何为虚拟dom(Virtual DOM),我们为什么采用虚拟dom?
- 虚拟dom相比真实dom的优势在哪里?
- 如何计算dom的变化(diff算法)?
何为虚拟dom,我们为什么采用虚拟dom?
虚拟dom就是我们使用一个原生的 JS 对象去描述一个 DOM 节点,好奇的同学就会问:那这个对象到底长什么样子呢?这里我以 Snabbdom 为例:
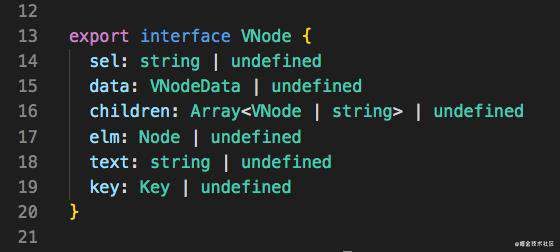
这里的VNode里一共定义了6个属性。为了更直观的对比真实dom,我们尝试把一个简单的 div 元素的属性都打印出来瞧一瞧:
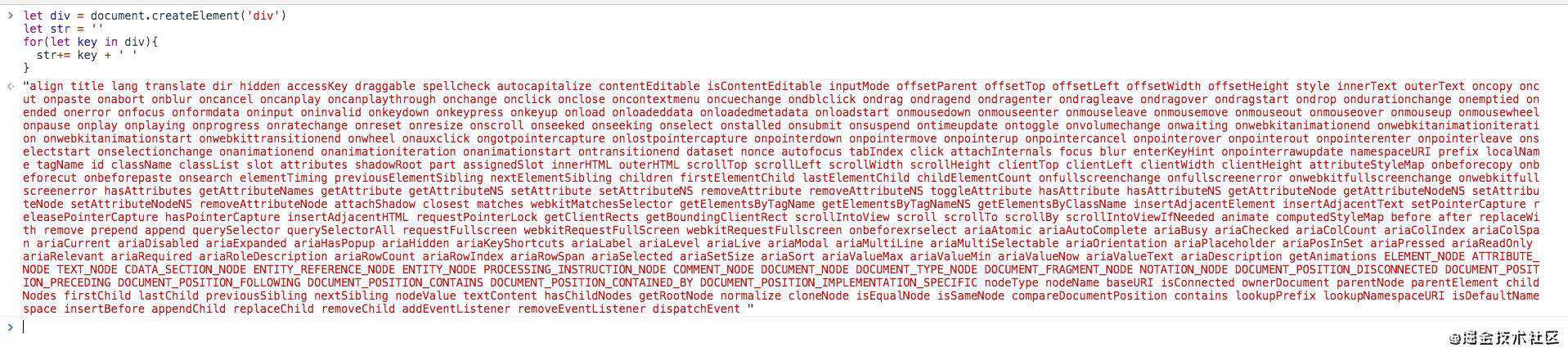
由于真实的dom非常庞大,现代web应用变得越来越复杂和炫酷(操作dom会更加频繁),所以给前端开发的同学们也带来了一些问题:如何优化页面,以及提升我们的web应用的性能呢?
说到页面优化,不得不提现代浏览器的工作原理。以色列开发人员Tali Garsiel、Paul Irish在 浏览器的工作原理:新式网络浏览器幕后揭秘 文中指出HTML渲染大致分为如下几步:
-
Parsing HTML to construct the DOM tree.(html被html解析器解析为DOM Tree,css被css解析器解析成CSSOM Tree。)
-
Render tree construction.(在 DOM Tree构建的同时,浏览器还会构建另一个树结构:呈现树Render tree,这是由可视化元素按照其显示顺序而组成的树,也是文档的可视化表示。它的作用是让浏览器按照正确的顺序绘制内容。)
-
Layout of the Render tree.(Render tree构建完毕之后,进入“布局”(Layout)处理阶段,也就是为每个节点分配一个应出现在屏幕上的确切坐标。在Mozilla中称之为 Reflow,WebKit中称之为 Layout。)
-
Painting the render tree.(最后阶段就是绘制。呈现引擎会遍历呈现树,由用户界面后端层将将每个节点绘制出来。)
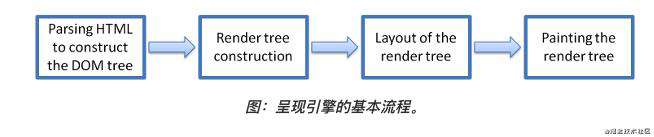
为达到更好的用户体验,呈现引擎会力求尽快将内容显示在屏幕上。它不必等到整个 HTML 文档解析完毕之后,就会开始构建呈现树和设置布局。在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。因此我们需要尽量减少重排、重绘这两个过程对用户造成的不利影响。
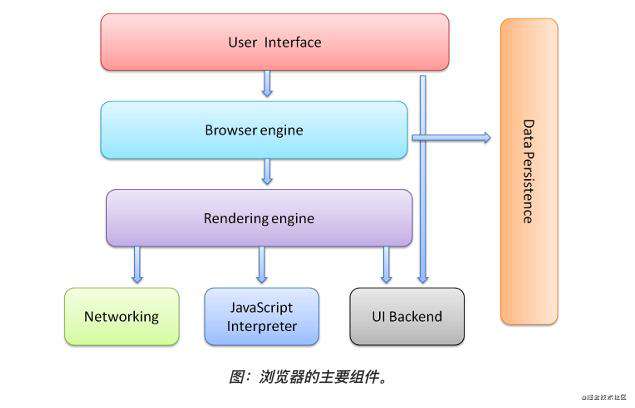
回想当年使用 jQuery,我们需要给一个div元素赋值、取值、改样式都是如何操作的?是不是简单粗暴的在业务代码中写了一堆document.getElementById()?那么我们这样直接操作 DOM 会有什么问题呢?
- 频繁的操作dom会引起性能问题。从浏览器的高层结构来看呈现引擎与javascript解析器都是互相独立的,我们使用js去频繁操作dom是通过功能接口去实现通信。这样一来必然会有性能损耗。
- 如果我们在js中存在许多的dom操作就会不断触发浏览器的呈现引擎会重走一遍刚才的流程。(重排、重绘)
- 从代码可维护性来看,存在许多与逻辑无关的代码。(增加了维护成本)
那我们如何改变这种状况呢?接下来有请我们的的主角(猪脚,手动滑稽)登场-Virtual DOM
虚拟dom相比真实dom的优势在哪里?
- 减少dom操作(虚拟dom可以将多次操作合并为一次操作。比如你添加1000个节点,传统方法是一个接一个的操作。虚拟dom借助dom diff可以把多余的操作步骤省略掉,比如你添加1000个节点,其实只有10个节点是新增的。)
- 跨平台渲染(虚拟dom不仅可以变成真实dom,还可以变成小程序、IOS应用、安卓应用,因为虚拟dom的本质只是一个js对象。)
- 服务端渲染(SSR)
好家伙!虚拟dom一上来就自带主角光环。那么接下来我们就正式的进入主题了。
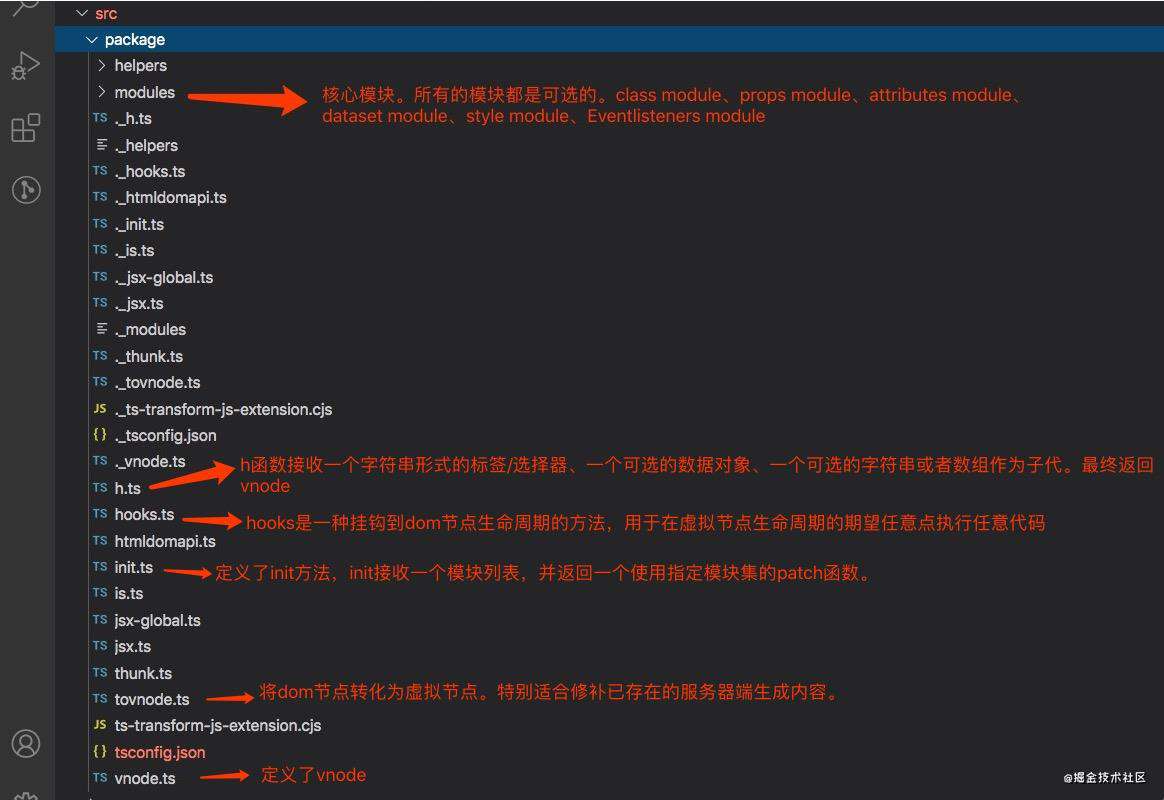
Snabbdom包含一个非常简单、高性能、可扩展的核心,只有≈200行(官方介绍的,但是一看init.ts这个文件有333行代码?)。为了可以通过自定义模块进行扩展它提供了具有功能丰富的模块化体系结构。为了保持核心的简单,所有非必要的功能都委托给了模块。(vue.js里面尤大也是借鉴Snabbdom来改造虚拟dom的。所以要想弄清楚vue.js背后的原理,强烈建议看看Snabbdom的源码。)
抛开模块功能来讲其实原理很简单,Snabbdom从创建虚拟dom到页面上创建真实dom这个过程大致可以分为以下两步:
- 使用 h() 函数创建 VNode(js对象)来记录真实的dom。
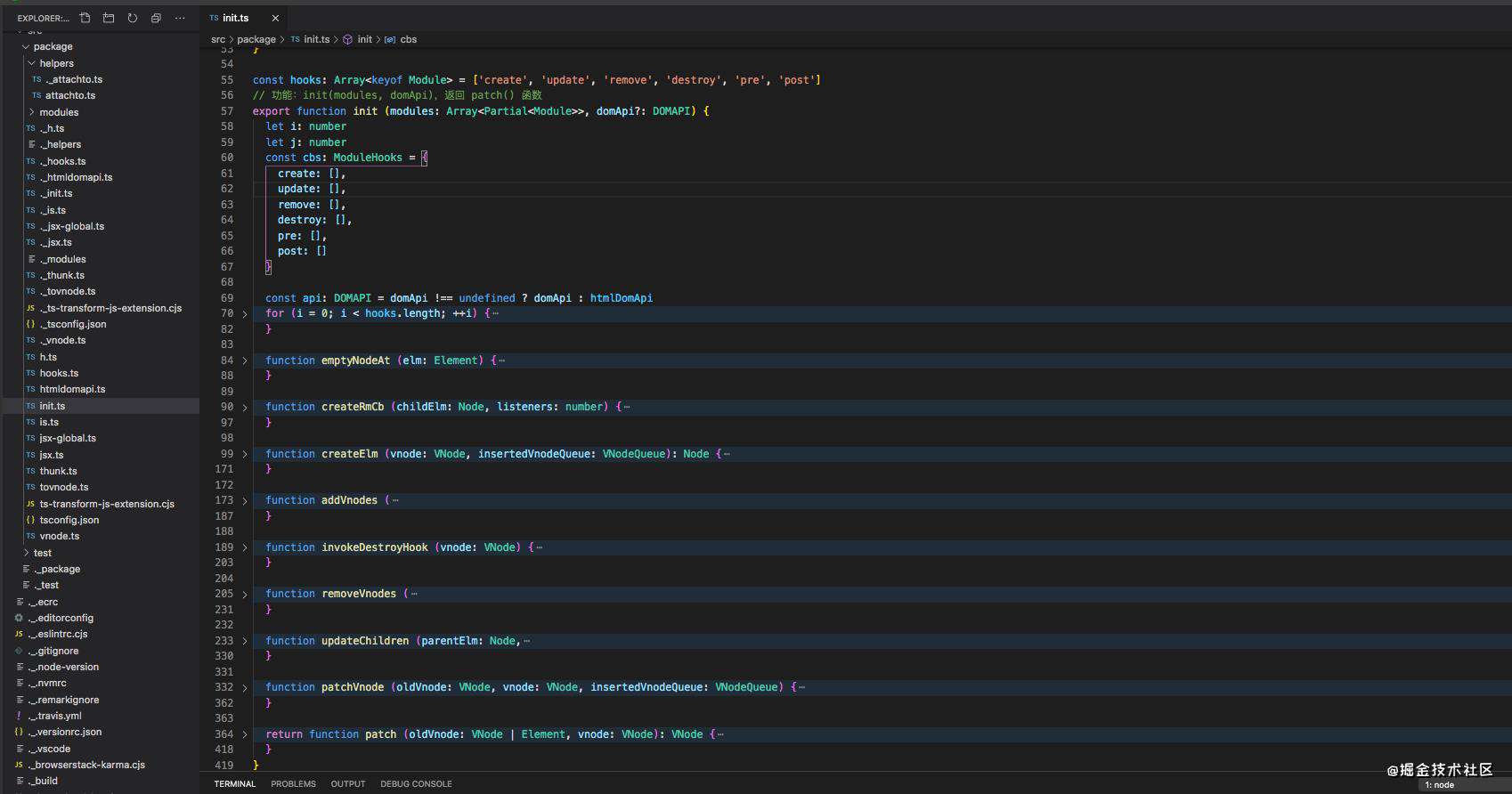
- 使用init() 设置模块返回patch()。(patch函数接收两个参数patch(oldVnode, newVnode)第一个是表示当前视图的DOM元素或vnode。第二个是表示更新后的新视图的vnode。通过patch方法把变化的内容更新到真实 DOM 树上并返回vnode用于下次更新的时候作为oldVnode使用。)
源码( git地址 )目录如下:
init.ts文件:
作为演示,我将写一个简单的例子。新建一个目录diff,在这个文件夹内分别新建index1.js和index.html文件。
index1.js文件:
import { init } from "../../build/package/init.js";
import { classModule } from "../../build/package/modules/class.js";
import { heroModule } from "../../build/package/modules/hero.js";
import { styleModule } from "../../build/package/modules/style.js";
import { eventListenersModule } from "../../build/package/modules/eventlisteners.js";
import { h } from "../../build/package/h.js";
let patch = init([classModule, heroModule, styleModule, eventListenersModule]);
let oldVnode = null;
let app = document.querySelector("#test");
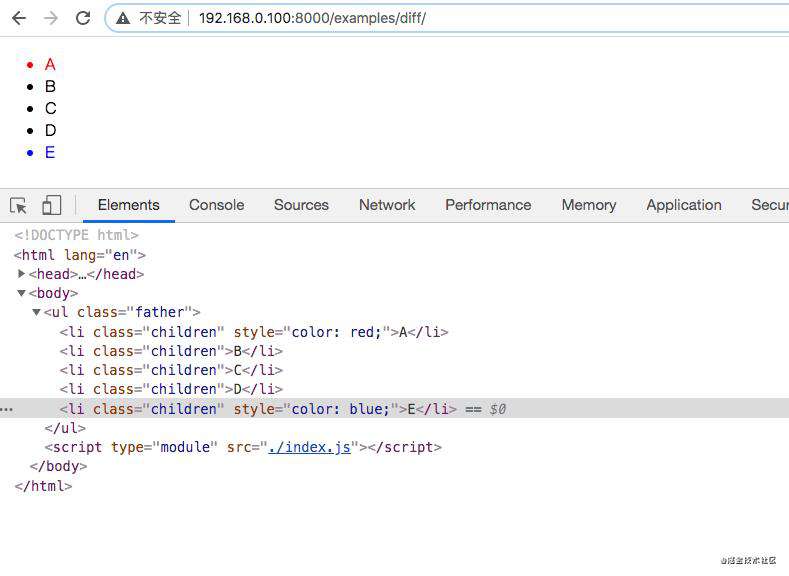
let vnode = h("ul.father", [
h("li.children", { key: 1, style: { color: "red" } }, "A"),
h("li.children", { key: 2 }, "B"),
h("li.children", { key: 3 }, "C"),
h("li.children", { key: 4 }, "D"),
h("li.children", { key: 5, style: { color: "blue" } }, "E"),
]);
oldVnode = patch(app, vnode);
index.html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>diff算法</title>
</head>
<body>
<div id="test"></div>
<script type="module" src="./index1.js"></script>
</body>
</html>
编写完成以后我们在浏览器中打开,可以看到页面上就生成了刚才我们写的一个无序列表。
好了,到此为止我们就认识了虚拟dom从创建到生成真实dom的整个过程(你废了吗?)。那么我们接下来看看什么是dom diff。
如何计算dom的变化(diff算法)?
diff 算法是虚拟DOM技术的必然产物:通过新旧虚拟DOM做对比(diff),将变化的地方更新在真实DOM上。在 DOM 操作的时候我们很少会把一个父节点移动或者更新到某一个子节上,因此diff算法用于在同级别的子节点上依次比较。diff算法的两个特点:
- diff发生同级别节点上(sameVnode:oldVnode.key === newVnode.key && oldVnode.sel === newVnode.sel)**
** - diff算法是深度优先的(沿着dom tree一直向下遍历,先比较同级别的)
snabbdom的diff算法的核心在于updateChildren()。updateChildren()的功能就是对比新旧节点的 children,更新 DOM。
function updateChildren (
parentElm: Node, //oldCh与newCh的共同父元素
oldCh: VNode[],
newCh: VNode[],
insertedVnodeQueue: VNodeQueue) { //用户定义的钩子函数
let oldStartIdx = 0 //老节点的开始标识
let newStartIdx = 0 //新节点的开始标识
let oldEndIdx = oldCh.length - 1 //老节点的结束标识
let oldStartVnode = oldCh[0] //老节点的开始child
let oldEndVnode = oldCh[oldEndIdx] //老节点的结束child
let newEndIdx = newCh.length - 1 //新节点的结束标识
let newStartVnode = newCh[0] //新节点的开始标识
let newEndVnode = newCh[newEndIdx] //新节点的结束child
let oldKeyToIdx: KeyToIndexMap | undefined //根据旧节点数组生成对应的key和index的map对象
let idxInOld: number //在旧节点中找当前newVnode对应的key
let elmToMove: VNode //准备移动的节点
let before: any //参考节点
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode == null) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode might have been moved left
} else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx]
} else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) { //oldStartVnode / newStartVnode (旧开始节点 / 新开始节点)相同 //调用 patchVnode() 对比和更新节点 // 把旧开始和新开始索引往后移动 oldStartIdx++ / oldEndIdx++
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) { //oldEndVnode / newEndVnode (旧结束节点 / 新结束节点)相同 //调用 patchVnode() 对比和更新节点 // 把旧结束和新结束索引往前移动 oldStartIdx-- / oldEndIdx--
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right //oldStartVnode / newEndVnode (旧开始节点 / 新结束节点) 相同 //调用 patchVnode() 对比和更新节点 //把 oldStartVnode 对应的 DOM 元素,移动到右边 //更新索引
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue)
api.insertBefore(parentElm, oldStartVnode.elm!, api.nextSibling(oldEndVnode.elm!))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left // oldEndVnode / newStartVnode (旧结束节点 / 新开始节点) 相同 // 调用 patchVnode() 对比和更新节点 // 把 oldEndVnode 对应的 DOM 元素,移动到左边 // 更新索引
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue)
api.insertBefore(parentElm, oldEndVnode.elm!, oldStartVnode.elm!)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 如果不是以上四种情况
// 遍历新节点,使用 newStartNode 的 key 在老节点数组中找相同节点
// 如果没有找到,说明 newStartNode 是新节点
// 创建新节点对应的 DOM 元素,插入到 DOM 树中
// 如果找到了
// 判断新节点和找到的老节点的 sel 选择器是否相同
// 如果不相同,说明节点被修改了
// 重新创建对应的 DOM 元素,插入到 DOM 树中
// 如果相同,把 elmToMove 对应的 DOM 元素,移动到左边
if (oldKeyToIdx === undefined) {
// 根据旧节点数组生成对应的key和index的map对象
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
}
idxInOld = oldKeyToIdx[newStartVnode.key as string]
if (isUndef(idxInOld)) { // New element
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm!)
} else {
elmToMove = oldCh[idxInOld]
if (elmToMove.sel !== newStartVnode.sel) {
api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm!)
} else {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue)
oldCh[idxInOld] = undefined as any
api.insertBefore(parentElm, elmToMove.elm!, oldStartVnode.elm!)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx <= oldEndIdx || newStartIdx <= newEndIdx) {
if (oldStartIdx > oldEndIdx) { //如果老节点的数组先遍历完(oldStartIdx > oldEndIdx),说明新节点有剩余,把剩余节点批量插入到右边
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else { //老节点有剩余,把剩余节点批量移除
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
}
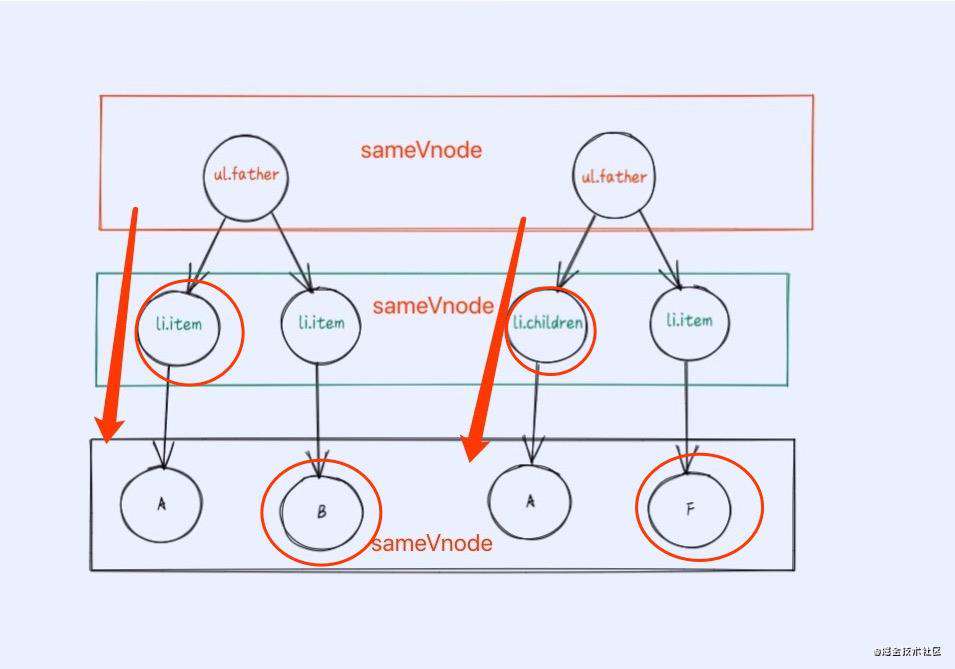
我们其实可以把新、旧两个children看作是两个数组,这样在排序和比较的时候理解起来更加形象。如图:
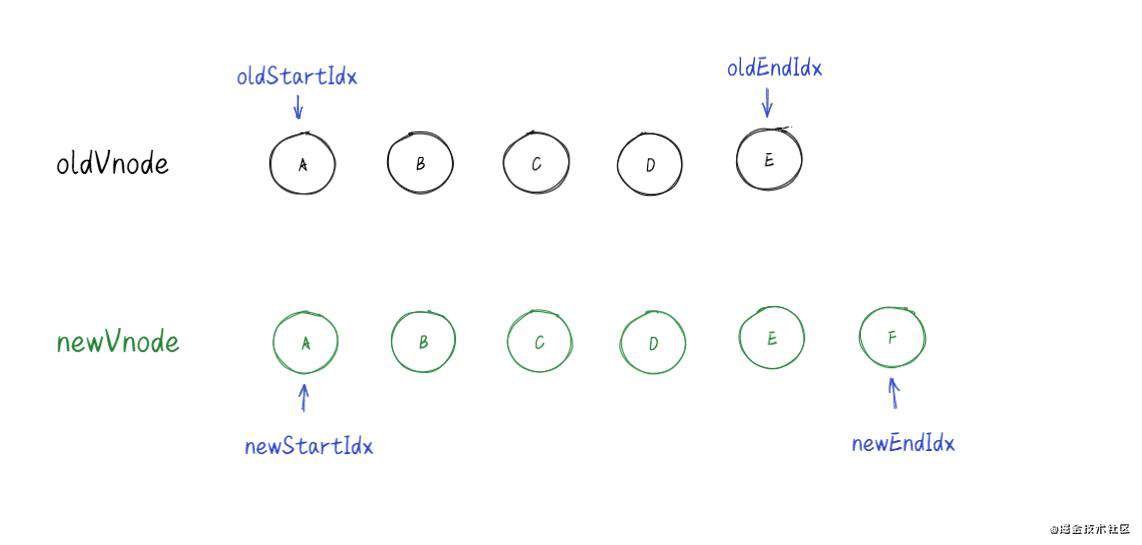
在diff的过程中其实可以分为5种情况,下面依次介绍:
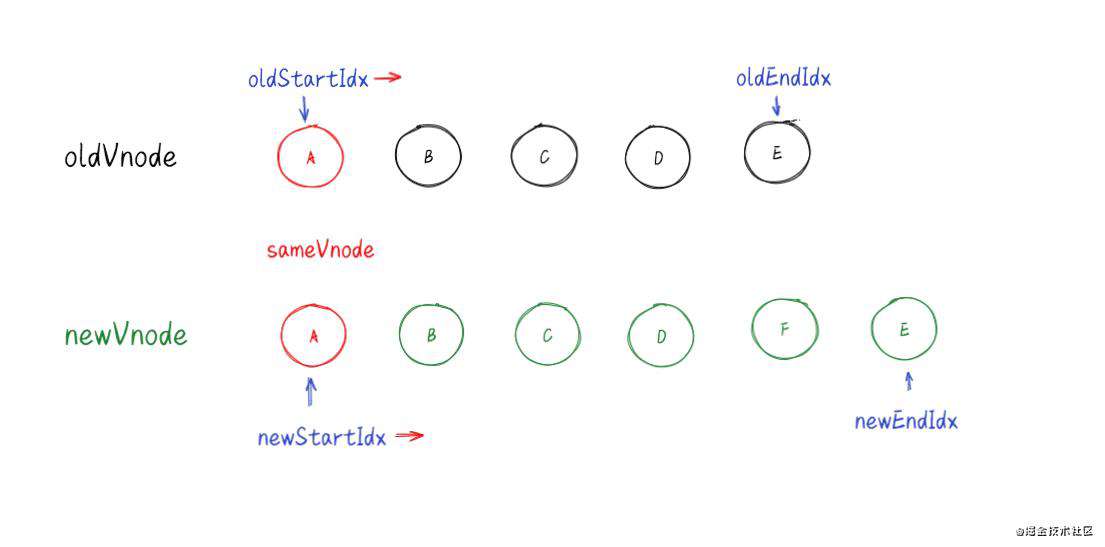
(一)、旧开始节点和新开始节点相同----sameVnode(oldStartVnode, newStartVnode)。判断sameVnode的依据主要是判断oldStartVnode.key === newStartVnode**.key &&** oldStartVnode**.sel ===** newStartVnode**.sel)**
处理步骤:
-
调用 patchVnode() 对比和更新节点
-
把旧开始和新开始索引往后移动 (++oldStartIdx/ ++newStartIdx)
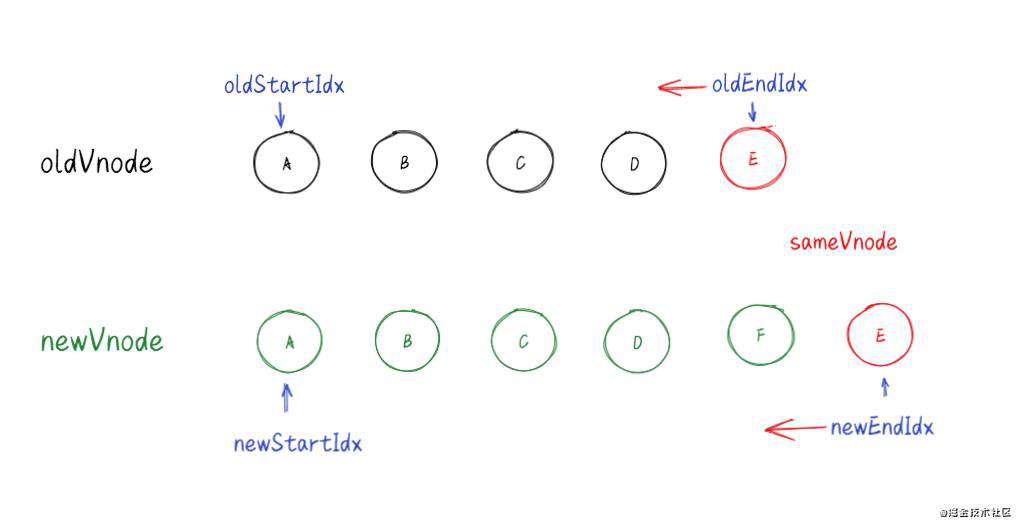
**(二)、****旧结束节点和新结束节点相同----**sameVnode(oldEndVnode, newEndVnode)
处理步骤:
-
调用 patchVnode() 对比和更新节点
-
把旧结束和新结束索引往前移动 (--oldStartIdx / --oldEndIdx)
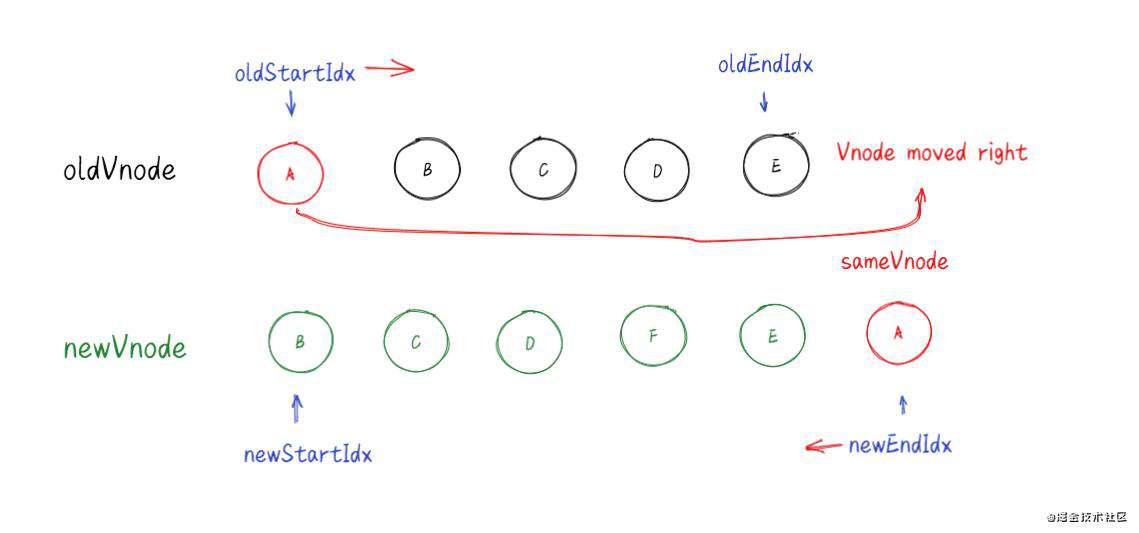
**(三)、旧开始节点和新结束节点相同----**sameVnode(oldStartVnode, newEndVnode)
处理步骤:
-
调用 patchVnode() 对比和更新节点
-
将旧开始节点移动到最后
-
把旧开始索引往后移动,新结束索引往前移动(++oldStartIdx / --newEndIdx)
**(四)、旧结束节点和新开始节点相同----**sameVnode(oldEndVnode, newStartVnode)
处理步骤:
-
调用 patchVnode() 对比和更新节点
-
将旧结束节点移动到最前
-
把旧结束索引往前移动,新结束索引往后移动(--oldEndIdx / ++newStartIdx)
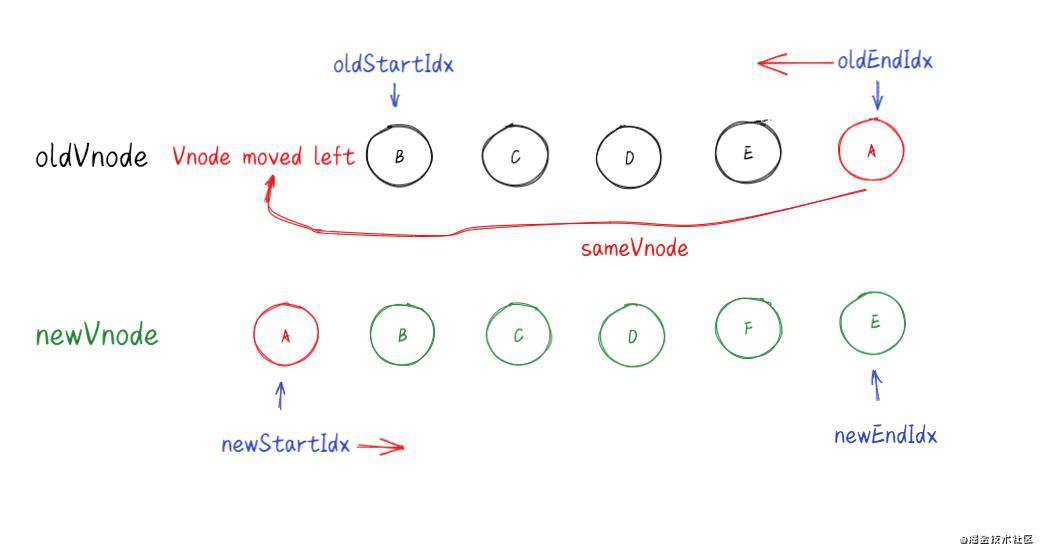
(五)、以上四种情况都不符合
**处理步骤:
**
- 使用newStartNode 的 key 在老节点数组中找相同节点
- 如果没找到,说明是新增加的节点。把newStartNode插入到oldStartVnode的前面。
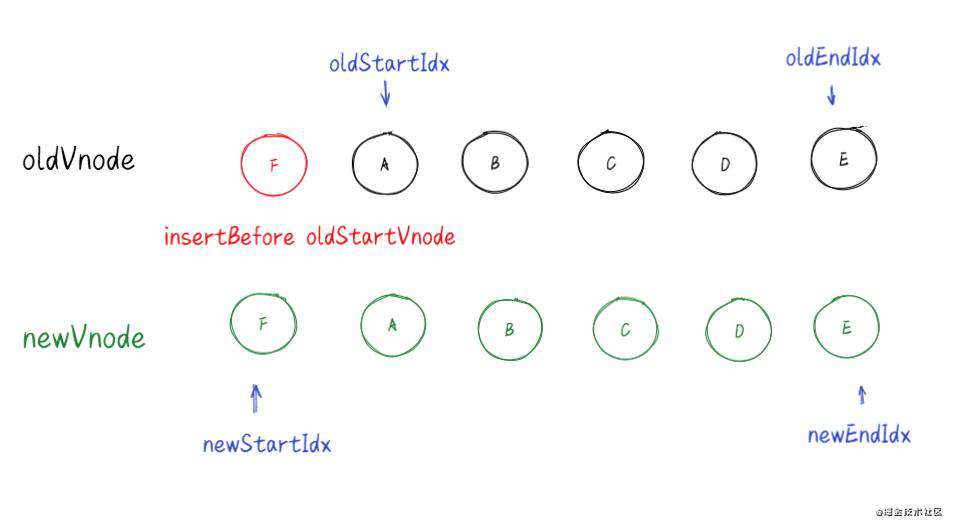
3.如果找到了,并且新节点和找到的老节点的选择器(sel)相同。调用patchVnode()并把 elmToMove对应的节点移动到左边。
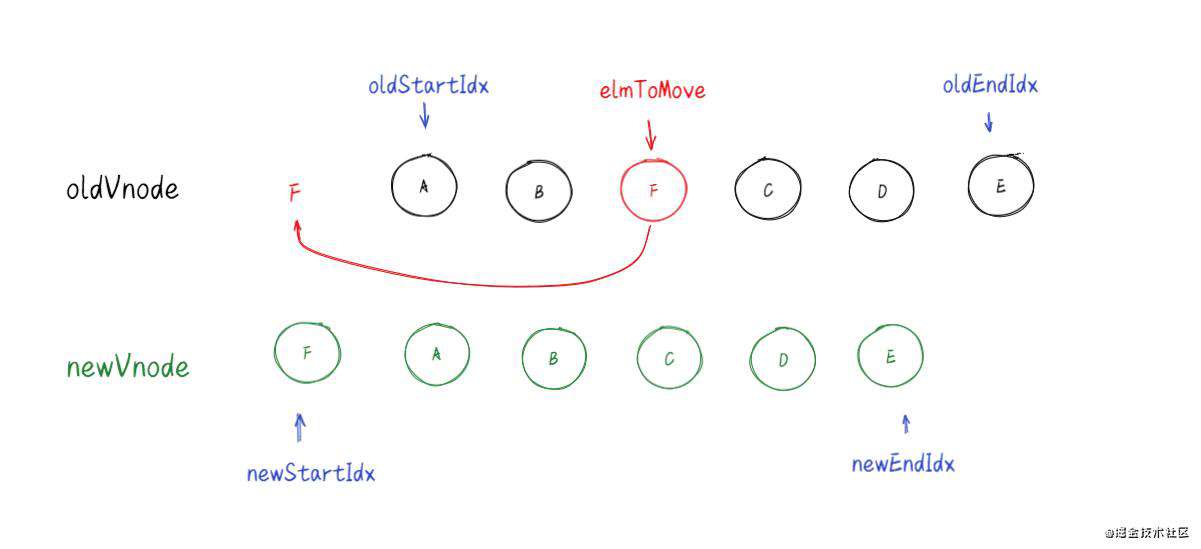
4.如果找到了,并且新节点和找到的老节点的选择器(sel)不相同。说明老节点被修改了,重新创建一个与vnode对应的真实 DOM 元素放入到当前位置中。
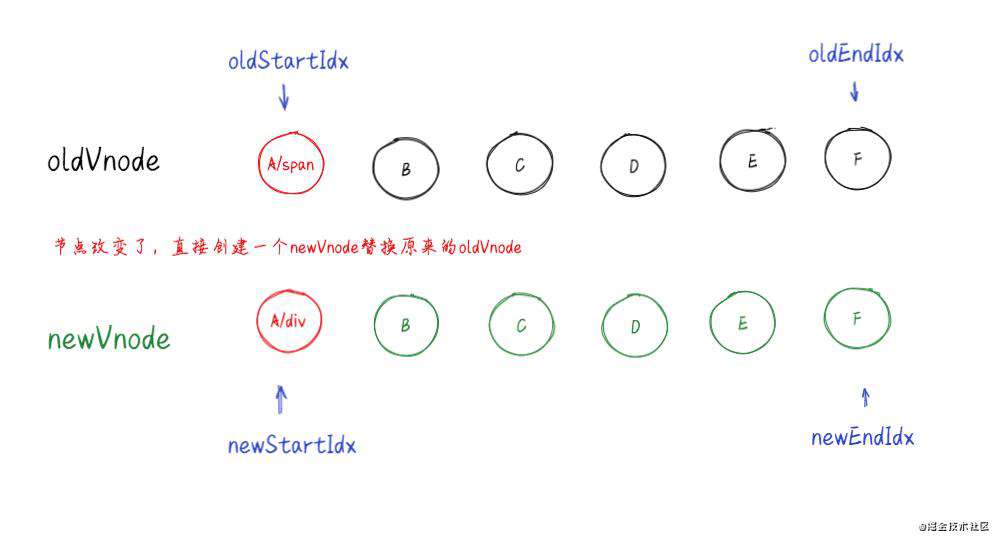
5.循环结束并且老节点的所有子节点先遍历完(oldStartIdx > oldEndIdx),说明新节点有剩余,把剩余节点批量插入到右边。
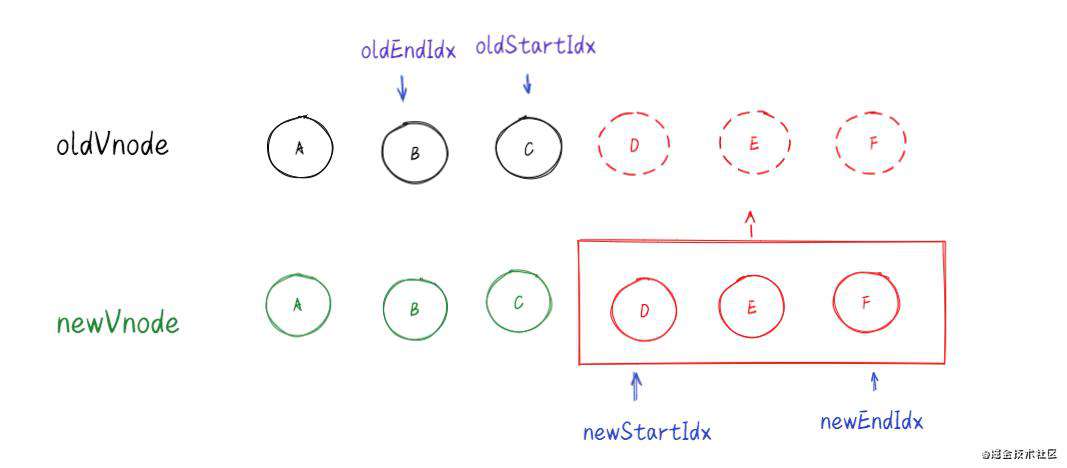
6.循环结束并且新节点的所有子节点先遍历完(oldStartIdx <= oldEndIdx),说明老节点有剩余,把剩余节点批量删除。
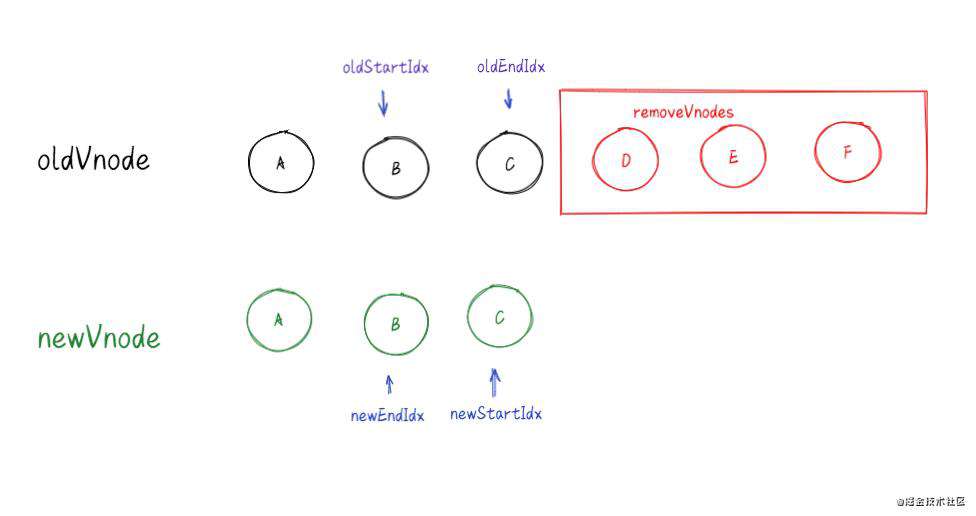
到此为止diff算法的整体思路就理清楚了。码字不易,如有错误之处请帮忙指出。谢谢!
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!