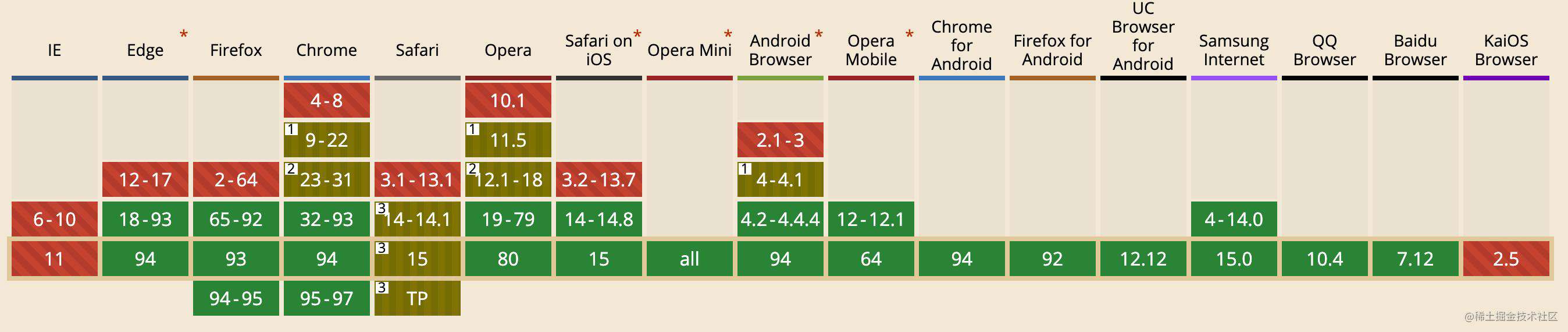
前言
前端优化方案
在过去的经验中,我认为:首先需要知道哪些页面需要优化,需要怎么样的优化,然后才能针对性的优化。所以我会将前端优化分为以下几个步骤:
- 确认哪些页面需要优化
- 建立监控体系
- 确定监控指标
- 根据监控信息分析页面
- 针对性优化
- 资源优化
- 构建优化
- 传输优化
- 网络优化
确认哪些页面需要优化
建立监控体系
第一步我们需要建立一套前端的性能监控体系。前端性能监控目前主要有两种方案:
- 第三方提供的成熟服务:例如 阿里云ARMS、听云、监控宝等
- 自主搭建
这里就不赘述各类第三方平台提供的服务了,主要讲明下自主搭建前端性能监控平台大概的实现思路。
确定采集指标
在前端监控方面,一般我们关注两个方向,性能和稳定。所以我们需要采集的指标大概有一下4个指标。
-
RUM (Real User Monitoring) 指标:包括 FP, TTI, FCP, FMP, FID, MPFID。
-
Navigation Timing:包括 DNS, TCP, DOM 解析等阶段的指标。
-
JS Error:解析后可以细分为运行时异常、以及静态资源异常。
-
请求异常:采集ajax请求异常。
那么接下来我们来逐个分析各个指标如何采集
RUM指标
LCP 、FID、CLS
最大内容绘制 (LCP):即 Largest Contentful Paint,测量加载性能。为了提供良好的用户体验,LCP 应在页面首次开始加载后的2.5 秒内发生。
首次交互时间(FID):即 First Input Delay,记录页面加载阶段,用户首次交互操作的延时时间。FID 指标影响用户对页面交互性和响应性的第一印象。
累积布局偏移 (CLS):即 Cumulative Layout Shift,测量视觉稳定性。为了提供良好的用户体验,页面的 CLS 应保持在 0.1 或更少。
对于LCP、FID、CLS我们可以直接使用web-vitals来进行采集,采集代码如下
import { getLCP, getFID, getCLS } from 'web-vitals';
getLCP((data) => console.log('LCP', data))
getFID((data) => console.log('FID', data))
getCLS((data) => console.log('CLS', data))

除开上述的 3个指标,我们还可以通过以下指标进行监控
FP、FCP
首次绘制时间( FP ) :即 First Paint,为首次渲染的时间点。
首次内容绘制时间( FCP ) :即 First Contentful Paint,为首次有内容渲染的时间点。
这两个指标看起来大同小异,但是 FP 发生的时间一定早于等于 FCP。FP 指的是绘制像素,比如说页面的背景色是灰色的,那么在显示灰色背景时就记录下了 FP 指标。但是此时 DOM 内容还没开始绘制,可能需要文件下载、解析等过程,只有当 DOM 内容发生变化才会触发,比如说渲染出了一段文字,此时就会记录下 FCP 指标。因此说我们可以把这两个指标认为是和白屏时间相关的指标,所以肯定是最快越好。
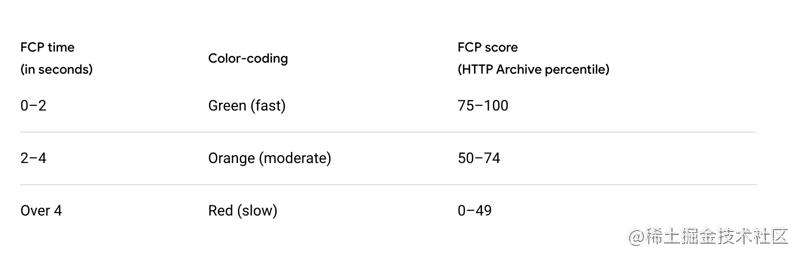
根据官方推荐的时间,我们应该把 FP 和 FCP 压缩到2秒内。
采集代码如下
window.performance.getEntriesByType('paint')
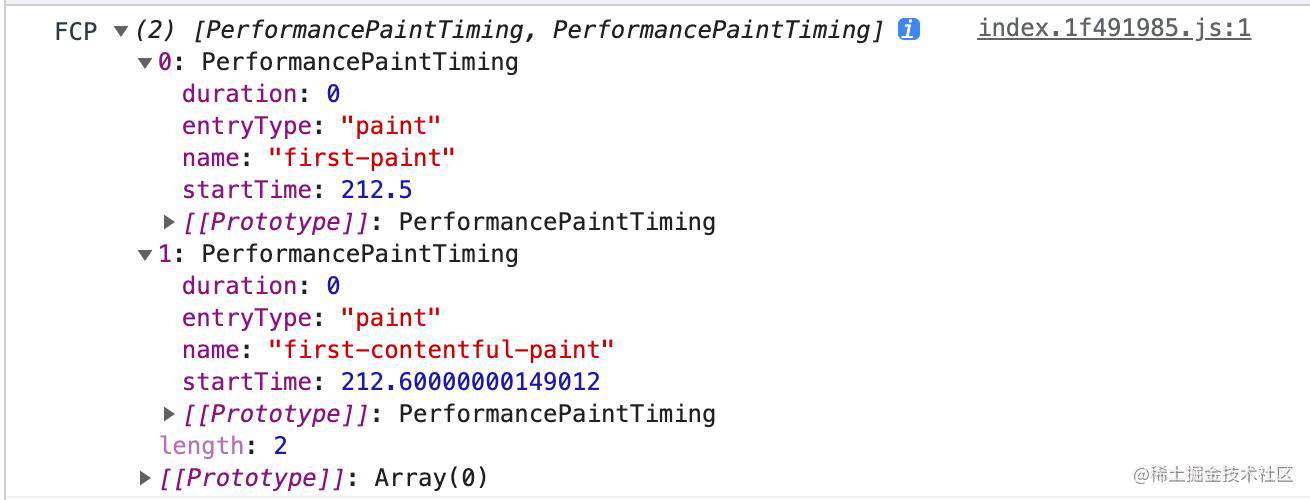
TTI
完全可交互时间(TTI):即 Time to interactive,记录从页面加载开始,到页面处于完全可交互状态所花费的时间。
获取 TTI 的规则如下:
-
从首次内容绘制(
FCP)开始 -
向前搜索 5秒,没有长任务,且不能超过2个get请求
-
向后搜索最后一个长任务(耗时超过
50毫秒的任务),如果没有长任务被发现就到FCP停止 -
TTI的时间是最后一个长任务的时间,如果没有长任务的话,则等于FCP时间
Google 希望将 TTI 指标标准化,并通过 PerformanceObserver 在浏览器中公开,但目前并不支持。
目前只能通过一个 polyfill,检测目前的 TTI,适用于所有支持 Long Tasks API 的浏览器。

根据官方推荐的时间,我们应该把 TTI 控制在到3.8秒内
采集代码如下
import ttiPolyfill from 'tti-polyfill'
// collect the longtask
if (PerformanceLongTaskTiming) {
window.__tti = { e: [] };
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
// observe the longtask to get the time to interactive (TTI)
if (entry.entryType === 'longtask') {
window.__tti.e.concat(entry);
}
}
});
observer.observe({ entryTypes: ['longtask'] });
}
ttiPolyfill.getFirstConsistentlyInteractive().then((tti) => {
console.log('TTI', tti)
});
Navigation Timing
这里我们关注的指标主要有
DNS查询耗时TCP链接耗时request耗时- 解析
DOM树耗时 - 白屏时间
domready时间onload时间
获取的方式很简单,我们可以直接通过PerformanceTiming来得到他们
window.addEventListener('load', () => {
setTimeout(() => {
const timing = window.performance.timing;
console.log('DNS查询耗时:', timing.domainLookupEnd - timing.domainLookupStart)
console.log('TCP链接耗时:', timing.connectEnd - timing.connectStart)
console.log('request耗时:', timing.responseEnd - timing.responseStart)
console.log('解析DOM树耗时:', timing.domComplete - timing.domInteractive)
console.log('白屏时间:', timing.domLoading - timing.fetchStart)
console.log('domready时间:', timing.domContentLoadedEventEnd - timing.fetchStart)
console.log('onload时间:', timing.loadEventEnd - timing.fetchStart)
}, 0);
})
JS Error
在采集JS Error这块,我们可以采用error和unhandledrejection这两个事件来捕获 JS 错误及Promise未处理的rejection异常。
下面附上简易代码
window.onerror = (errorMsg, url, lineNumber, columnNumber, errorObj) => {
let errorStack = errorObj ? errorObj.stack : null;
// 这里进行上报
console.log(errorMsg, url, lineNumber, columnNumber, errorStack)
};
window.onunhandledrejection = (e) => {
let errorMsg = "", errorStack = "";
if (typeof e.reason === "object") {
errorMsg = e.reason.message;
errorStack = e.reason.stack;
} else {
errorMsg = e.reason;
}
// 这里进行上报
console.log(errorMsg, errorStack)
}
请求异常
捕获请求异常,我们可以通过重写window.fetch及XMLHttpRequest来实现。
根据监控信息分析页面
当我们拥有一套完整的监控体系,那么接下来可以基于上面给出的监控指标来对页面进行针对性优化。哪个页面需要优化并没有一个标准的答案,这一切都需要根据自身业务及投入产出比来看。
这里也给出一个优化目标的建议 目标:比你最快的竞争对手至少快20%
根据用户心理学研究,如果想让用户感觉你的 web 网站比其它竞品快,那你必须比它们快 20% 以上。研究你的主要竞争对手,收集它们在移动设备和台式机上的性能指标,并设置阈值来帮助你超越竞争对手。但是,要获取准确的性能指标并制定目标,务必先通过研究分析来全面了解用户体验。然后,你可以根据 90% 的主要用户的反馈和经验来模拟测试。
针对性优化
资源优化
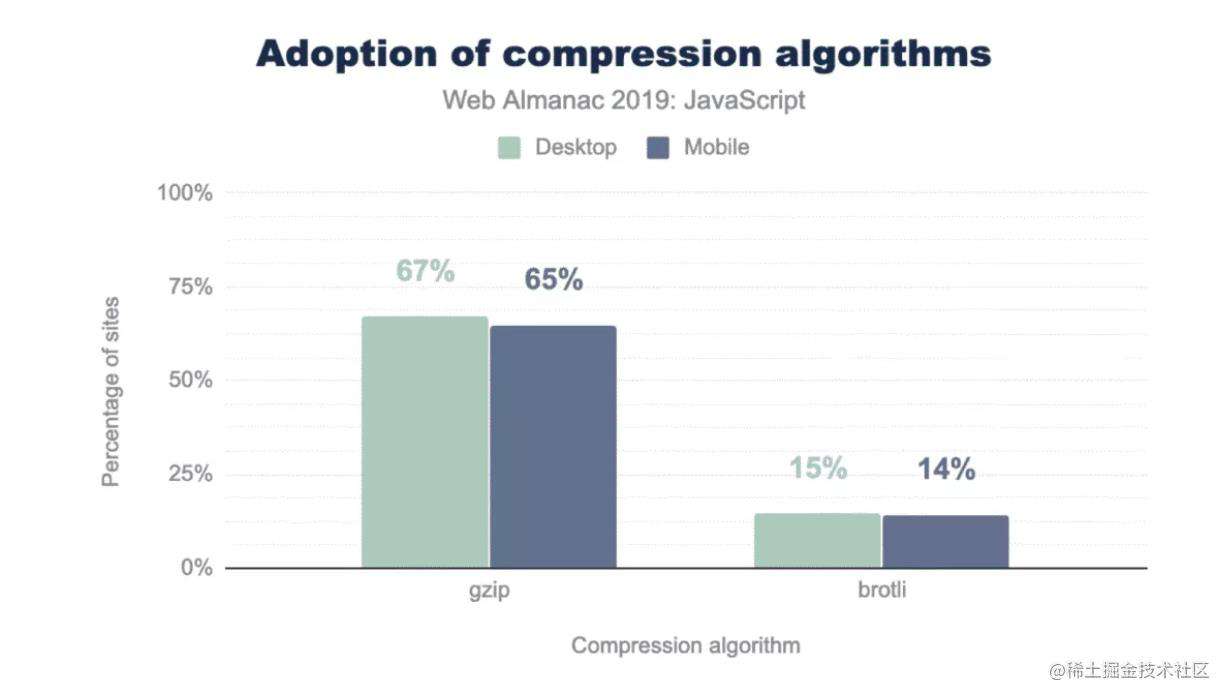
使用 Brotli 进行纯文本压缩
2015 年,Google推出了Brotli,这是一种全新的开源无损数据格式,并被现在所有现代浏览器支持。
Brotli有比Gzip和Deflate更高的压缩率,但是同时也需要更长的压缩时间,所以在请求的时候实时进行压缩并不是一个很好的办法。但我们可以预先对静态文件进行压缩,然后直接提供给客户端,这样我们就避免了 Brotli 压缩效率低的问题,同时使用这个方式,我们可以使用压缩质量最高的等级去压缩文件,最大程度的去减小文件的大小。
另外,由于不是所有浏览器都支持 Brotli 算法,所以在服务端我们需要同时提供两种文件,一个是经过 Brotli 压缩的文件,一个是原始文件,在浏览器不支持 Brotli 的情况下,我们可以使用 gzip 去压缩原始文件提供给客户端。
Brotli可用于任何纯文本的内容如 HTML,CSS,SVG,JavaScript 等。
使用最高压缩比配置的Brotli + Gzip 预压缩静态资源,并使用 Brotli 配置 3~5 级压缩比来快速压缩 HTML。确保服务器正确处理 Brotli 或 gzip 的内容协商头。
使用响应式图像和 WebP
WebP图片是一种新的图像格式,由 Google 开发。与 png、jpg 相比,相同的视觉体验下,WebP 图像的尺寸缩小了大约30%。另外,WebP图像格式还支持有损压缩、无损压缩、透明和动画。理论上完全可以替代png、jpg、gif等图片格式,不过目前WebP的还没有得到全面的支持,但是我们还是能够通过兜底方案来使用它。
所以在使用图片时尽可能使用具有 srcset,sizes 和 <picture> 元素的响应式图像。在使用它的同时,还可以通过 <picture> 元素和 JPEG 兜底来使用WebP 格式。
但是WebP并非毫无缺点,它不支持像 JPEG 那样的渐进式渲染,这就是为什么用户使用 JPEG 可能会更快地看到实际图像!尽管 WebP 图像的网络加载速度可能会更快。使用 JPEG 我们可以用一半甚至四分之一的时间就提供给用户一个比较「像样」的体验,并在后续加载其余数据,而不是像 WebP 那样只有半空的图像。所以这就看我们想要的是什么:使用 WebP,将减少图像大小;使用 JPEG,将提高图像的可感知性。
图像是否经过适当优化?
在我们的项目中,快速加载图像非常重要,所以在使用到图片的时候需要注意:
-
确保
JPEG是渐进式渲染的,并使用mozJPEG或Guetzli压缩。 -
使用
Pingo压缩png -
使用
SVGO或SVGOMG对SVG进行压缩 -
对图片或者
iframe进行懒加载 -
如果可能建议使用循环播放的
video或者WebP代替gif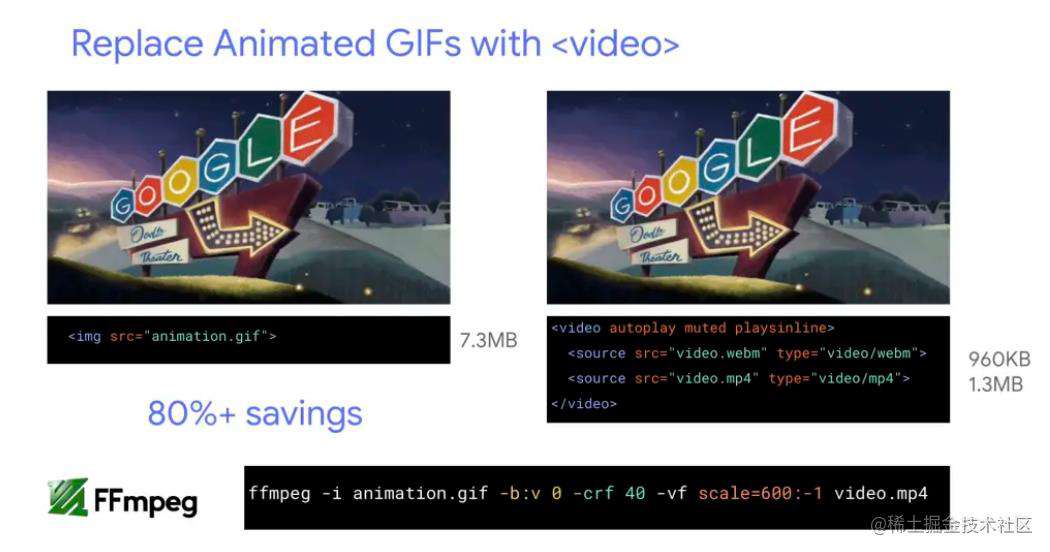
[使用 ffmpeg 将 gif 转成 MP4 后的性能优化]
网络字体是否经过优化?
很多时候,我们使用的字体包并不需要适配所有的文字,尤其是中文字体动不动 10M+ 大小的情况下。所以
- 如果条件允许,我们可以对字体进行子集化(可以采用subfont来帮助我们对项目进行分析)
- 使用
preload来预加载字体 - 如果有必要的话,将字体缓存在
Service Worker中
构建优化
你正在使用 tree-shaking、scope hoisting 和 code-splitting 吗?
-
tree-shaking 是一种清理构建包中无用依赖的方法,它让构建结果只包含生产中实际使用的代码,并消除
Webpack中未使用的引入。借助Webpack和Rollup,我们还可以实现 scope hoisting ,这两个工具都可以检测到import链可以在哪个位置终止并转换为一个内联函数,而不破坏代码。借助Webpack,我们还可以使用 JSON Tree Shaking -
code-spliting 是
Webpack的另一个功能,可以把你的代码拆分为按需加载的chunk。并不是所有JavaScript都必须立即下载、解析和编译。一旦在代码中定义了分割点,Webpack就可以处理依赖关系和输出文件。它可以让浏览器保持较小的初始下载量,并在应用程序请求时按需请求代码。 -
考虑使用 preload-webpack-plugin,这个插件可以根据你代码的分隔方式,让浏览器使用
<link rel="preload">或<link rel="prefetch">对分隔的代码chunk进行预加载。Webpack 内联指令还可以对preload/prefetch进行一些控制(但是请注意优先级问题。)
能否将 JavaScript 抽离到 Web Worker?
为了缩短可交互时间的耗时,最好将有繁重计算的 JavaScript 抽离到 Web Worker 中或通过 Service Worker 进行缓存。因为 DOM 操作是与 JavaScript 一起运行在主线程上。使用 Web worker 可以将这些昂贵的操作转移到后台其他线程上运行。可以通过 Web Worker 预先加载和存储一些数据,以便后续在需要时使用它。可以使用 Comlink 来简化与 Web Worker 之间的通信。
能否将频繁执行的功能抽离到 WebAssembly?
我们可以将繁重的计算任务抽离 到 WebAssembly(WASM)执行,它是一种二进制指令格式,被设计为一种用高级语言(如 C / C ++ / Rust)编译的可移植的对象。而且大多数现代浏览器都已经支持了 WebAssembly,并且随着 JavaScript 和 WASM 之间的函数调用变得越来越快,这个方式会变得越来越可行。WebAssembly 的目的并不是替代 JavaScript,而是可以在你发现当 CPU 占用过高时作为 JavaScript 的补充JavaScript 更适合大多数 Web 应用程序,而 WebAssembly 最适合用于计算密集型 Web 应用程序,例如 Web 游戏。
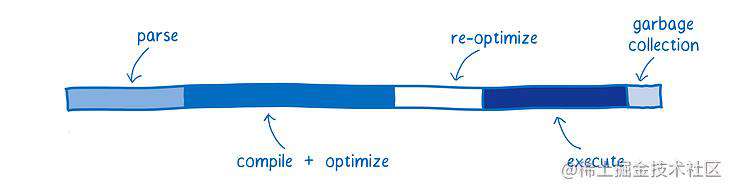
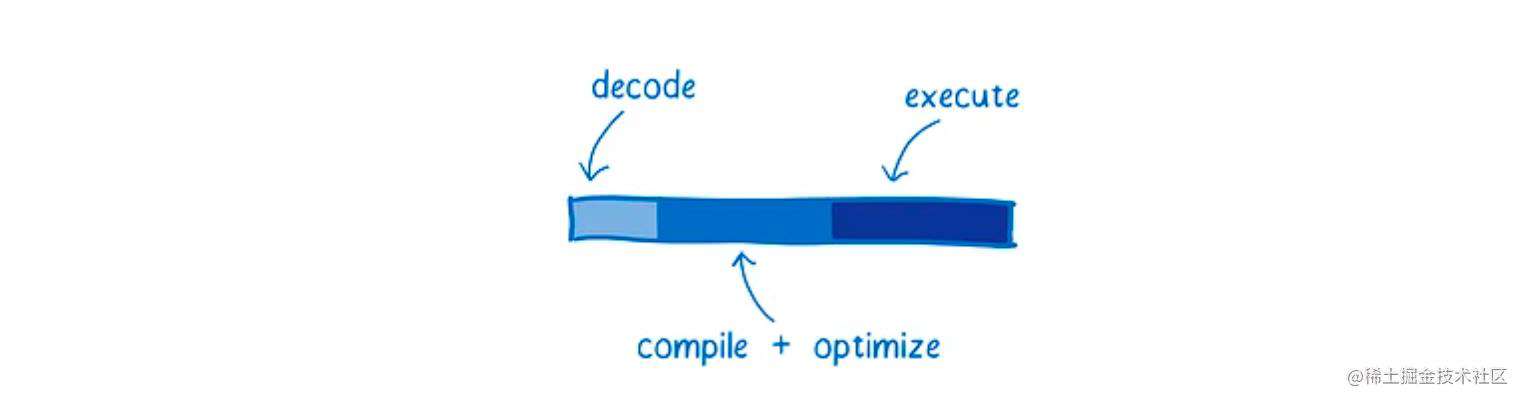
下面附上 JavaScript 及 WebAssembly 的处理过程对比:
你有在 JavaScript 中使用 module/nomodule 模式吗?
我们只想通过网络发送必要的 JavaScript,但这意味着对这些资源的交付要更加专注和细致。module/nomodule 的思想是编译并提供两个单独的 JavaScript 包:“常规”构建的构建方式是,一个包含 Babel 转换和 polyfills,仅提供给实际需要它们的旧版浏览器,另一个包(相同功能)不包含 Babel 转换和 polyfills。
JS module(或者称作ES module,ECMAScript module)是一个主要的新特性,或者说是一系列新特性。你可能已经使用过第三方的模块加载系统。CommonJs 如 nodeJs 、 AMD 如 requireJs 等等。这些模块加载系统都有一个共同点:它们允许你执行导入导出操作。
能够认识type=module语法的浏览器会忽略具有nomodule属性的scripts。也就是说,我们可以使用一些脚本服务于支持module语法的浏览器,同时提供一个nomodule的脚本用于哪些不支持module语法的浏览器,作为补救。

识别并删除未使用的 CSS / JS
Chrome 中的 CSS 和 JavaScript 代码覆盖率工具(Coverage) 可以让我们了解哪些代码已执行或应用,哪些未执行。我们可以启动一个覆盖率检查,然后查看覆盖率结果。一旦检测到未使用的代码,找出那些模块并使用 import() 延迟加载。然后重复代码覆盖率检查确认现在在初始化时加载代码有变少。
你可以使用 Puppeteer 来收集代码覆盖率,Puppeteer 还有许多其他用法,例如在每次构建时监视未使用的 CSS。
此外,purgecss,UnCSS 和 Helium 可以帮助你从 CSS 中删除未使用的样式。
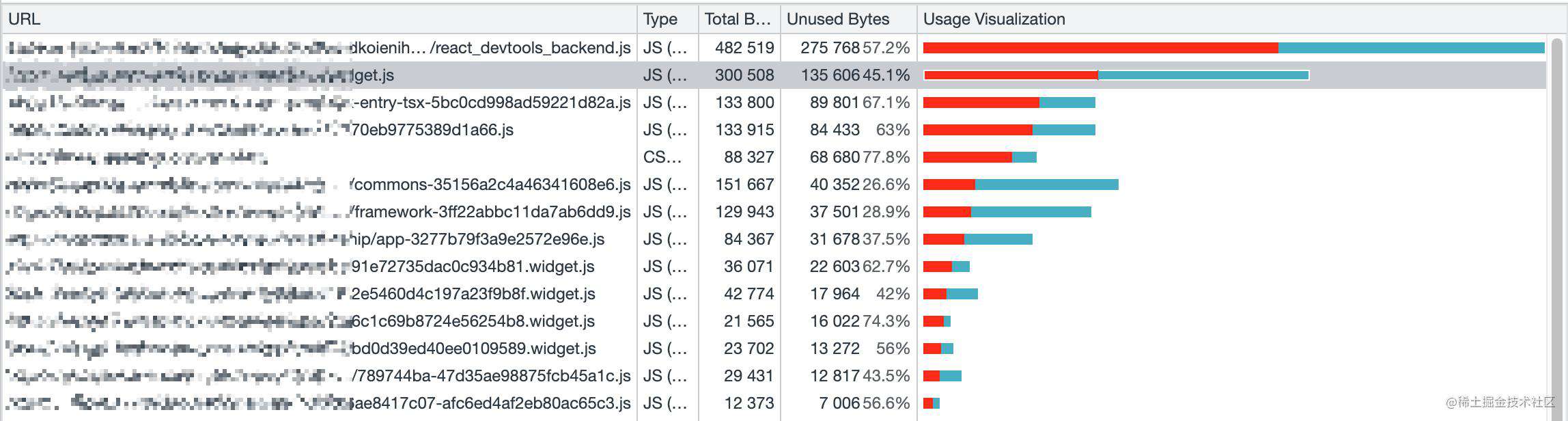
修剪 JavaScript 包大小
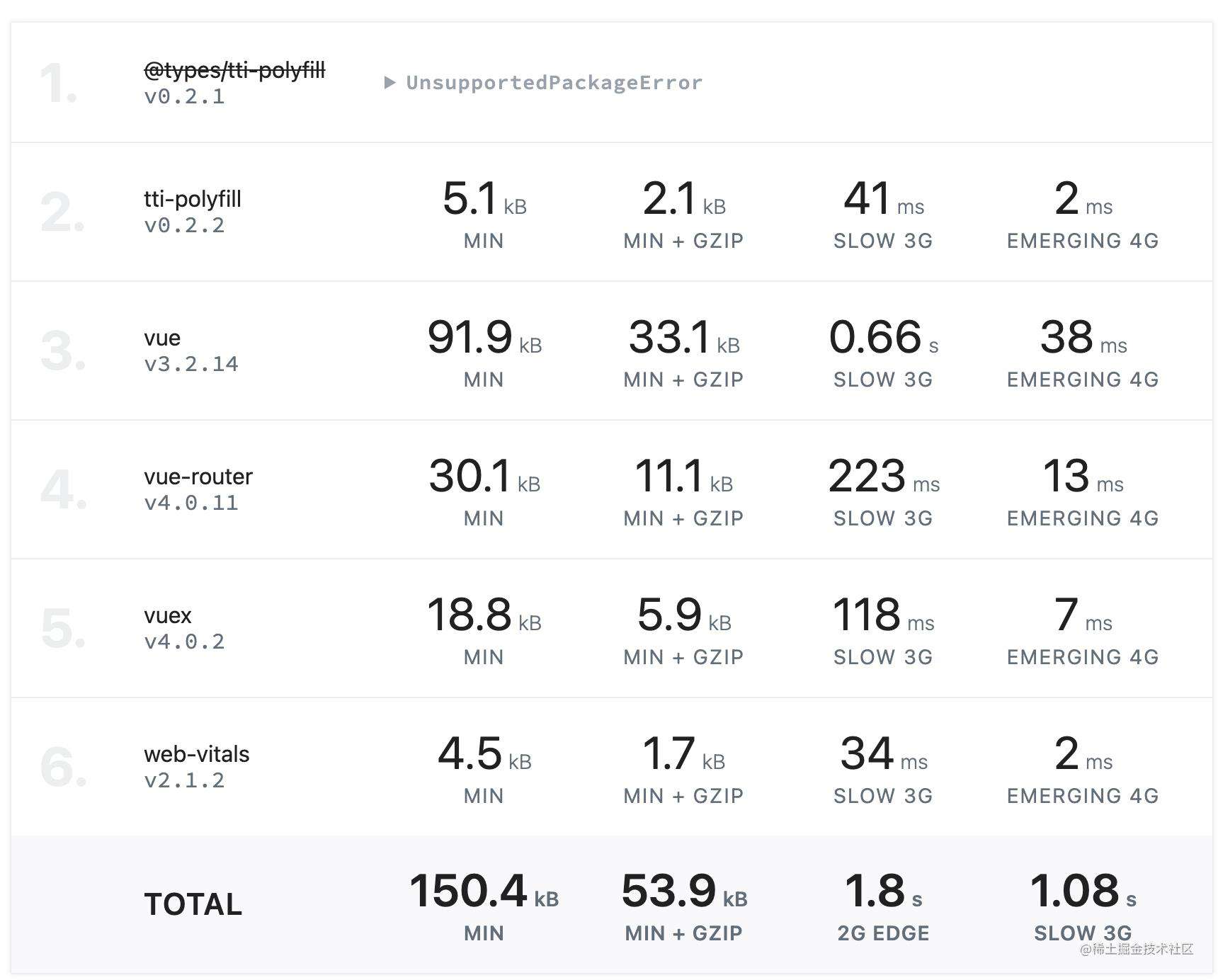
将依赖包审核添加到日常的工作流程中。使用更小巧轻便的库替换你可能在几年前添加的一些大型的库,例如使用 Day.js 替换 Moment.js
使用 Bundlephobia 之类的工具可以帮助你了解添加一个 npm 包的代价。size-limit 不仅会包检查大小,还会展示 JavaScript 的执行时长。
使用针对目标 JavaScript 引擎的优化。
看下哪些 JavaScript 引擎在你的用户群中占主导地位,然后探索对其进行优化的方法。例如,当针对 Blink 浏览器、Node.js 运行时和 Electron 中使用的 V8 进行优化时,可以使用脚本流来处理整体脚本。
下载开始后,脚本流允许 async 或 defer scripts 在单独的后台线程上进行解析,因此在某些情况下,页面加载时间最多可缩短 10%。而且,在 header 中使用 script defer,可以使浏览器更早的发现资源,然后在后台线程解析它。
警告:Opera Mini 不支持脚本延迟,因此,如果你的主要用户是使用 Opera Mini, defer 则将被忽略,从而导致渲染被阻塞,直到脚本执行完毕。
客户端渲染还是服务器端渲染?
使用客户端渲染还是服务端渲染?这都得由应用程序的性能来决定。最好的方法是设置某种渐进式引导:使用服务端渲染来快速获得第一个有意义的图形(FCP),同时包括一些最小体积的必需的 JavaScript,尽量让可交互时间(TTI)紧挨着第一个有意义的图形的绘制。如果 JavaScript 执行在 FCP 之后太晚,浏览器会在解析、编译和执行后来执行的 JavaScript 时锁定主线程,从而削弱了网站或应用程序的交互性。
为了避免这种情况,我们务必将函数的执行分解为单独的异步任务,并尽可能使用 requestIdleCallback。使用 WebPack 的动态import()支持,延迟加载部分 UI,避免在用户真正需要它们之前因为加载、解析和编译造成的成本消耗。
进入可交互状态后,我们可以按需或在时间允许的情况下启动应用程序的非必需部分。不过框架通常没有面向开发者提供简单的优先级概念,因此,对于大多数库和框架而言,实现逐步启动并不容易。
下面我们来分析下目前的几种渲染机制:
-
完全客户端渲染 (CSR)
所有的逻辑、渲染、启动均在客户端上完成。结果通常是
TTI和FCP之间的间隔加大。由于整个应用程序必须在客户端上启动才能呈现任何内容,因此应用程序感觉很比较呆滞。通常来说SSR 比 CSR 快。但是对于许多应用程序来说,CSR是最常见的实现方式。附上传统
CSR的链路图: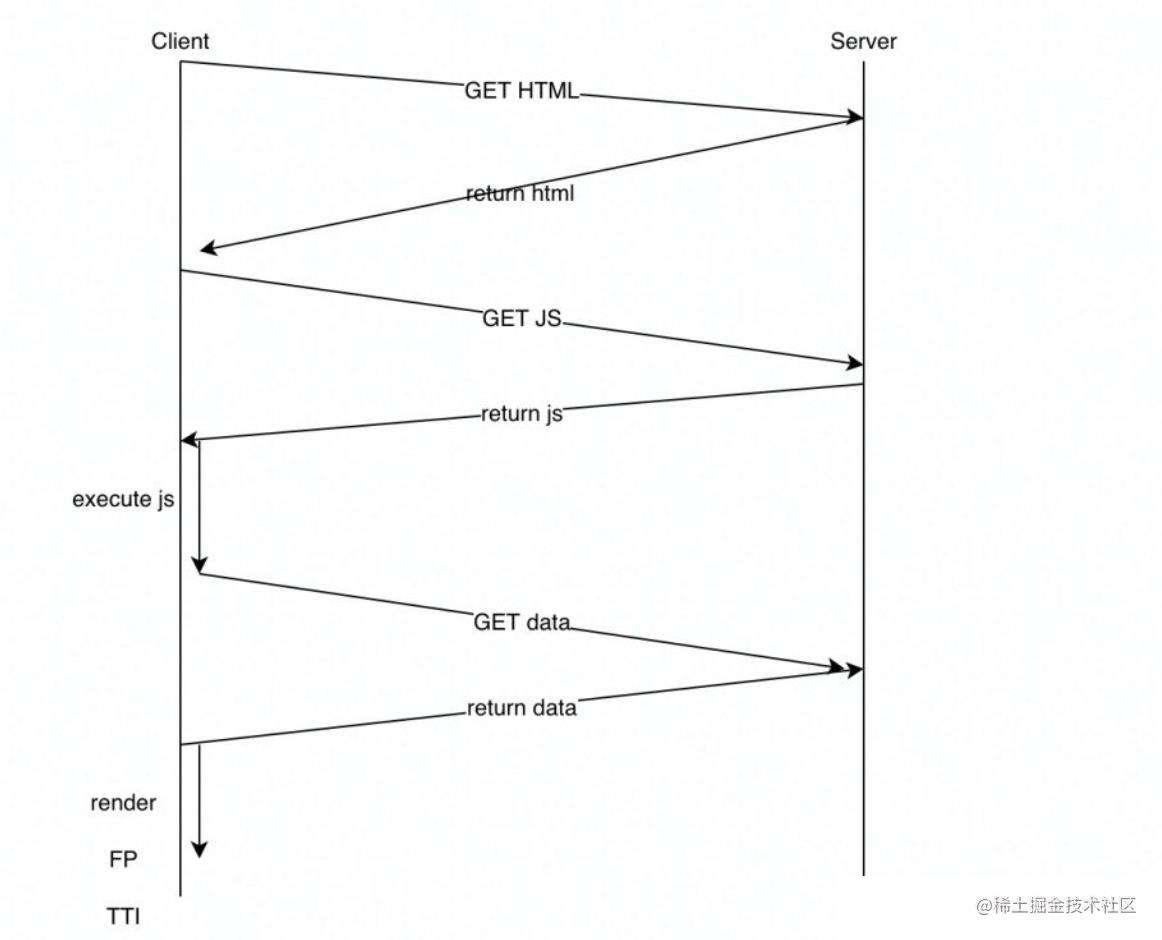
-
完全服务器端渲染(SSR)
服务器呈现响应于导航,为服务器上的页面生成完整的
HTML。这样可以避免在客户端进行数据获取和模板化的其他往返过程,因为它是在浏览器获得响应之前进行处理的。FP和FCP的差距通常很小,在服务器上运行页面逻辑和呈现可以避免向客户端发送大量JavaScript,这有助于实现快速的可交互时间(TTI)。而且可以将HTML以流式传输到浏览器并立即呈现页面。不过,我们需要花费更长的时间去做解析,导致第一个字节到达(TTFB)浏览器的时间加长,并且我们没有利用现代应用程序的响应式功能和其他丰富的功能。 -
静态站点生成(SSG)
静态网站生成类似于服务器端渲染,不过是在构建时而不是在请求时渲染页面。与服务器渲染不同,由于不必动态生成页面的
HTML,因此它还可以保持始终如一的快速到第一字节的时间(TTFB)。通常,静态呈现意味着提前为每个URL生成单独的HTML文件。借助预先生成的HTML响应,可以将静态渲染器部署到多个CDN,以利用边缘缓存的优势。因此,我们可以快速显示页面,然后为后续页面提前获取SPA框架。但是这种方法只适用于页面生成不依赖于用户输入的场景。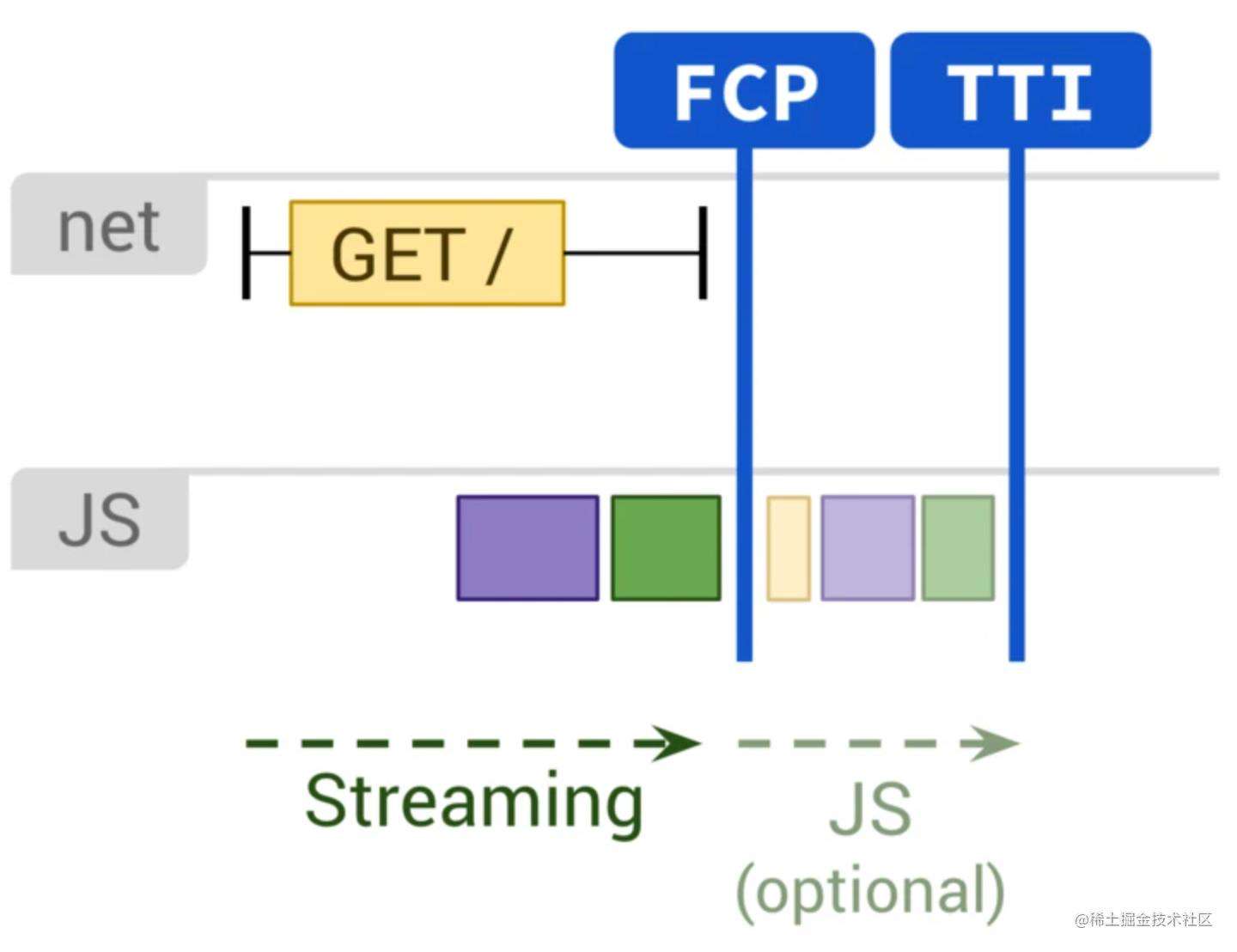
-
带有 (Re)Hydration 的服务端渲染(SSR + CSR)
Hydration译为水合。是不是一脸懵逼!说人话,对曾经渲染过的HTML进行重新渲染的过程称为水合。导航请求(例如整页加载或重新加载)由服务器处理,服务器将应用程序呈现为
HTML,然后将JavaScript和用于呈现的数据嵌入到生成的文档中。理想状态下,就像服务端渲染一样可以得到快速的FCP,然后通过使用称为(Re)Hydration的技术在客户端上再次渲染来修补。借助
React,我们可以在 Node 上使用ReactDOMServer模块,然后调用renderToString方法将顶级组件生成为静态HTML字符串。使用Vue的话,我们可以使用 vue-server-renderer ,调用renderToString方法来将Vue实例渲染为HTML。该方法也有其缺点,我们确实保留了客户端的全部灵活性,同时提供了更快的服务器端渲染,但是
FCP和TTI之间的间隔也越来越大,并且FID也增加了。Hydration 非常昂贵,带有水合的SSR页面通常看起来具有欺骗性,并且具有交互性,但是在执行客户端JS并附加事件处理程序之前,实际上无法响应输入。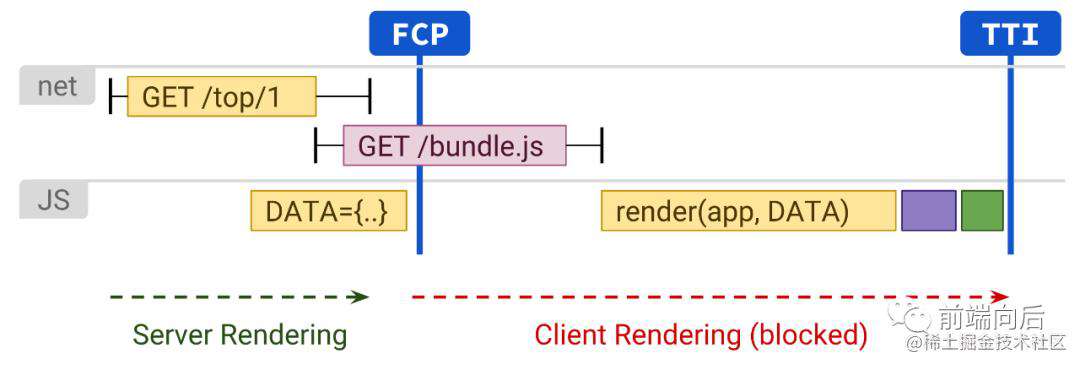
-
使用渐进 (Re)Hydration 进行流式服务端渲染(SSR + CSR)
为了最大程度地缩短
TTI与FCP之间的间隔,我们可以发起多个请求,并在生成内容时分批发送内容(返回的响应体是流)。因此,在将内容发送到浏览器之前,我们不必等待完整的HTML字符串,还可以缩短第一个字节的时间(TTFB)。在
React中,我们可以使用 renderToNodeStream 而不是renderToString来通过管道返回响应并将HTML分块发送。在Vue中,我们可以使用 renderToStream 来实现管道和流传输。随着React Suspense的到来,我们也可以使用异步渲染来达到相同目的。在客户端,我们不是一下启动整个应用程序,而是逐步启动组件。首先将应用程序的各个部分分解功能放到独立脚本中,然后逐步 “激活” (按优先级顺序)。我们可以先将关键组件激活,而其余的则随后激活。然后,可以针对每个组件定义为客户端还是服务器端渲染。然后,我们还可以延迟某些组件的激活,直到它们出现在可视区域或用户交互需要或浏览器处于空闲状态时。
对于
Vue,当在用户交互时使用 hydration 或使用 vue-lazy-hydration(可以定义组件可见的时机或特定用户交互时激活组件)可以减少SSR应用程序的交互时间。你也可以使用 Preact 和 Next.js 实现部分 hydration。理想中的流式服务端渲染流程如下:
- 请求
HTML,服务器先返回骨架屏的HTML,之后再返回所需数据,或者带有数据的HTML,最后关闭请求。 - 请求
js,js返回并执行后就可以交互了。
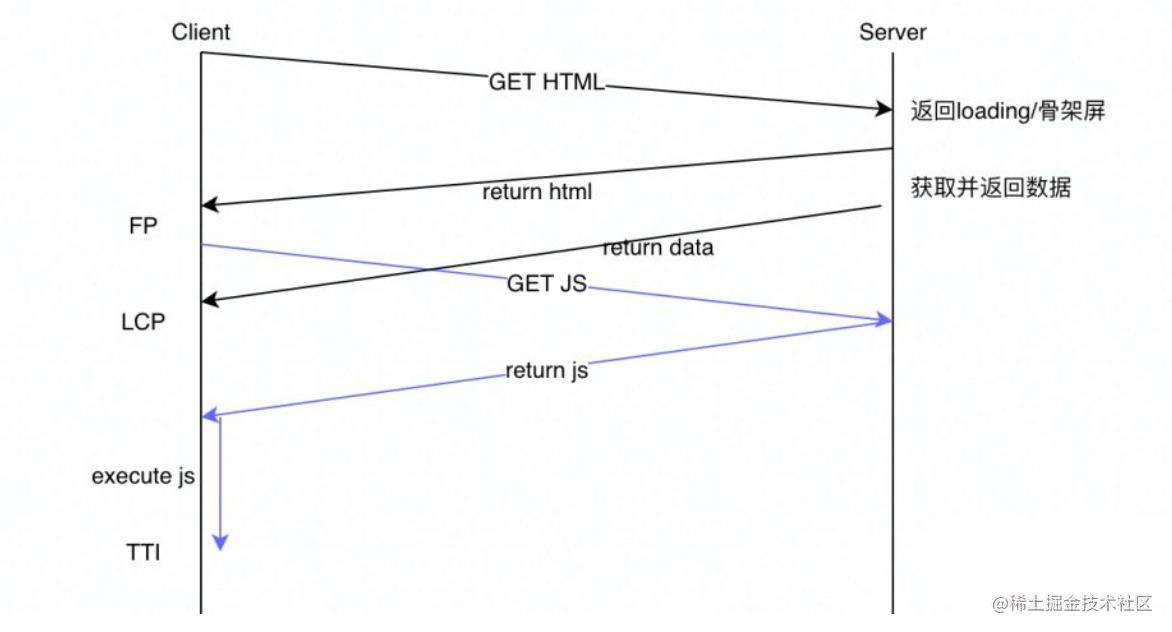
- 请求
-
客户端预渲染
与服务端预渲染相似,但不是在服务器上动态渲染页面,而是在构建时就将应用程序渲染为静态
HTML。在构建过程中使用
renderToStaticMarkup方法而不是renderToString方法,生成一个没有data-reactid之类属性的静态页面,这个页面的主JS和后续可能会用到的路由会做预加载。也就是说,当初打包时页面是怎么样,那么预渲染就是什么样。等到JS下载并完成执行,如果页面上有数据更新,那么页面会再次渲染。这时会造成一种数据延迟的错觉。结果是
TTFB(第一字节到达时间)和FCP时间变少,并且缩短了TTI和FCP之间的间隔。如果预期内容会发生很大变化,那么就无法使用该方法。另外,必须提前知道所有URL才能生成所有页面。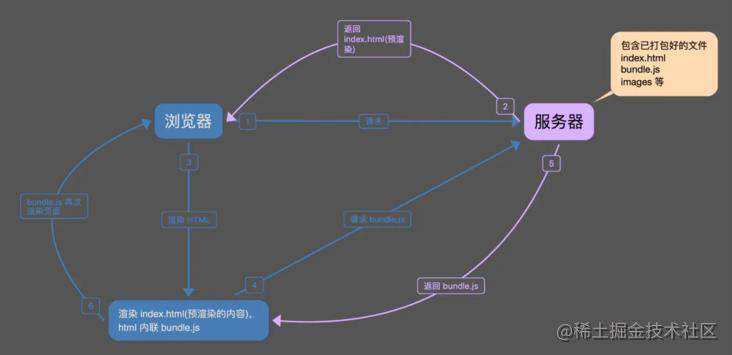
-
三方同构渲染
如果可以使用
Service Worker,三方同构渲染也可能派上用场。这个技术是指:利用流式服务器渲染初始页面,等Service Worker加载后,接管HTML的渲染工作。这样可以让缓存的组件和模板保持最新,还可以启用像单页应用一样的导航用以在同一会话中预渲染新视图。当可以在服务器、客户端页面和Service Worker之间共享相同模板和路由代码时,此方法最有效。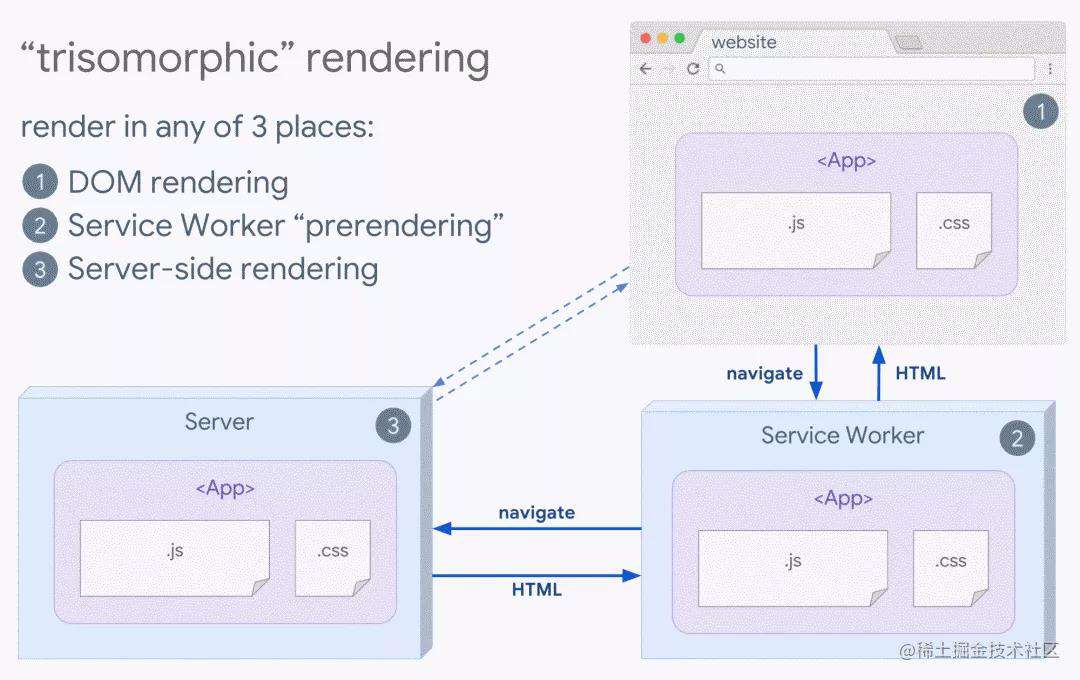
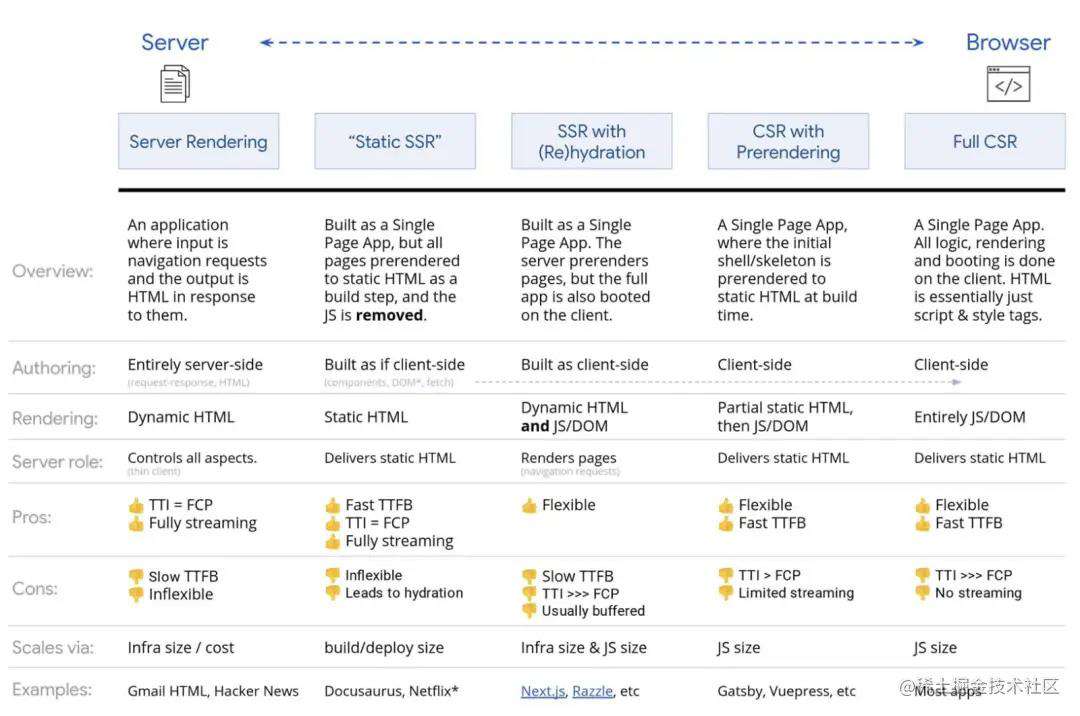
至于如何选择, 这里也给出一些不成熟的建议:
- 对
SEO要求不高,同时对操作需求比较多的项目,比如一些管理后台系统,建议使用CSR。因为只有在执行完bundle之后, 页面才能交互,单纯能看到元素,却不能交互, 意义不大,而且SSR会带来额外的开发和维护成本。 - 如果页面
无数据,或者是纯静态页面,建议使用SSG。 因为这是一种通过预览打包的方式构建页面,也不会增加服务器负担。 - 对
SEO有比较大需求同时页面数据请求多的情况,建议使用SSR。
正确设置HTTP缓存报文头
仔细检查 expires、max-age、cache-control 和其他 HTTP 缓存报文头是否已正确设置。一般来说,资源可以在很短的时间内或无限期缓存,并且可以在需要时通过 URL 中更改其版本。
使用Cache-control: immutable,用于表示响应正文不会随时间变化。资源如果未过期,在服务器上不会改变,因此浏览器不会发送缓存验证(例如:If-None-Match或If-Modified-Since)来检查更新,即便是用户刷新了页面。
我们可以使用Cache-Control响应头指定了缓存时间,例如 Cache-Control: max-age=60。经过 60秒后,浏览器就会重新去获取资源,但是这会导致页面加载速度变慢。所以我们可以通过使用 stale-while-revalidate 来避免这种问题;例如:Cache-Control: max-age=60, stale-while-revalidate=3600 是说,这个缓存在 60 秒内是「新鲜」的,从 60 秒到 3660 秒的这一个小时内,虽然缓存是过期了,但仍可以直接使用这个过期缓存,同时进行异步更新,在 3660 秒之后,就是完全过期了,那么需要进行传统的同步资源获取了。
在2019年6月至7月,Chrome 和 Firefox 开始对 HTTP Cache-Control stale-while-revalidate 支持,由于过期的资产不会再堵塞渲染,所以它可以提高后续的页面加载速度。效果:对于重连的视图,RTT 为零。
此外,确保没有发送不必要的报头(例如 x-powered-by,pragma,x-ua-compatible,expires等)和确保报文中包含有用的安全和性能相关报文头(如 Content-Security-Policy,X-XSS-Protection,X-Content-Type-Options 等)。最后,请注意单页应用程序中 CORS 请求的性能成本。
传输优化
是否对 JavaScript 库进行了异步加载?
当用户请求一个页面时,浏览器获取 HTML 构造 DOM,获取 CSS 构造 CSSOM,然后通过匹配 DOM 和 CSSOM 生成一个渲染树。但是只要需要解析 JavaScript 时,浏览器就会延迟渲染页面的时间。所以作为开发人员,我们必须明确地告诉浏览器立即开始渲染页面。可以通过给脚本添加 HTML 中的 defer 和 async 属性。
然而,我们应该选用 defer,慎用 async。使用 async 的脚本一旦获取到,就会立即执行。假如这个 async 脚本获取的非常快,当脚本处于缓存就绪状态时,它实际上会阻塞 HTML 渲染。使用 defer,浏览器在解析 HTML 之前不会执行脚本。因此,除非在开始渲染之前需要执行 JavaScript,否则最好都使用 defer。
另外,要限制第三方库和脚本的影响,特别要注意:例如社交分享按钮 SDK 和 iframe 标签(如地图)的使用。可以使用 size-limit 库防止 JavaScript 库膨胀:如果不小心添加了一个大的依赖项,这个工具将通知你并抛出一个错误。
使用 IntersectionObserver 和图片懒加载
一般来说,我们应该把所有耗性能的组件都做延迟加载,比如大的 JavaScript、视频、iframe、小组件和潜在的要加载的图片。例如:Native lazy-loading 可以帮助我们延迟加载图片和 iframe。
延迟加载脚本的最有效方式是使用 Intersection Observer API,这个 API 可以异步观察目标元素与祖先元素或文档的 viewport 之间交集的变化。我们需要创建一个 IntersectionObserver 对象,它接收一个回调函数和相应的参数,然后我们添加一个观察目标。如下
let options = {
root: document.querySelector('#scrollArea'),
rootMargin: '0px',
threshold: 1.0
}
let observer = new IntersectionObserver(callback, options);
let target = document.querySelector('#listItem');
observer.observe(target);
// threshold = 1.0 意味着 target 元素完全出现在 root 选项指定的元素中可见时,回调函数将会被执行。
当目标变成可见或不可见时,回调函数就会执行,所以当它和 viewport 相交时,我们可以在元素变得可见之前执行一些操作。所以,我们可以通过 rootMargin(围绕根的边距)和 threshold (一个数字或一组数字,表示目标的可见性的百分比)对何时调用观察者的回调进行细粒度控制。
渐进加载图片
我们可以通过在页面中使用渐进式图片加载将延迟加载效果提升到新的高度。与 Facebook、Pinterest 和 Medium 类似,我们可以先加载低质量甚至模糊的图片,然后随着页面继续加载,使用 LQIP(低质量图片占位符)技术将它们替换为高质量的完整版本。
配合懒加载,我们可以使用现成的库:lozad.js
给个最简单的演示代码:
<img data-src="https://assets.imgix.net/unsplash/jellyfish.jpg?w=800&h=400&fit=crop&crop=entropy"
src="https://assets.imgix.net/unsplash/jellyfish.jpg?w=800&h=400&fit=crop&crop=entropy&px=16&blur=200&fm=webp"
>
<script>
function init() {
var imgDefer = document.getElementsByTagName('img');
for (var i=0; i<imgDefer.length; i++) {
if(imgDefer[i].getAttribute('data-src')) {
imgDefer[i].setAttribute('src',imgDefer[i].getAttribute('data-src'));
}
}
}
window.onload = init;
</script>
你发送了关键 CSS 吗?
为了确保浏览器尽快开始渲染页面,只包含首屏渲染可见部分所需的所有 CSS 称为"关键 CSS"。将它内联在页面的 <head> 标签中,从而减少往返请求传输。由于在慢启动阶段 TCP 交换的包的大小有限,所以关键 CSS 的大小应该不超过14KB。(这个特定的限制不适用于 TCP BBR,但是优先处理关键资源并尽早的去加载它们总是不会错的)。如果超出这个限制范围,浏览器将需要额外的传输往返用于获取更多样式。
尝试重新组合你的 CSS 规则
根据CSS and Network Performance的研究,按照媒体查询条件把 CSS 文件进行拆分可能对我们的页面性能有一定提升。这样,浏览器会使用高优先级检索关键CSS,使用低优先级处理其他的所有内容。
例如:
<link rel="stylesheet" href="all.css" />
我们把所有的css放在一个文件中,浏览器会这样处理他:
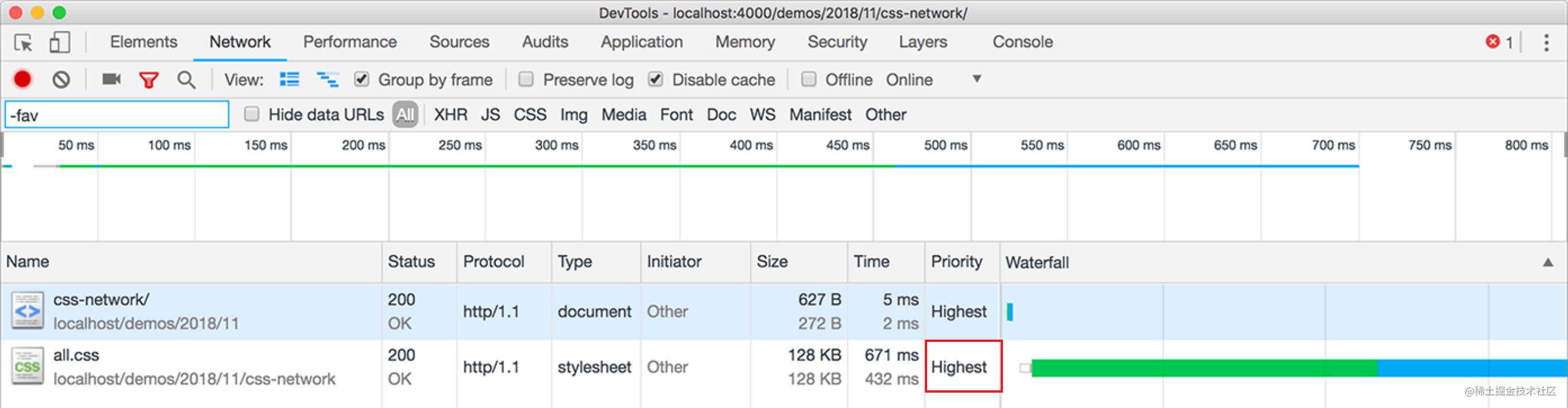
<link rel="stylesheet" href="all.css" media="all" />
<link rel="stylesheet" href="small.css" media="(min-width: 20em)" />
<link rel="stylesheet" href="medium.css" media="(min-width: 64em)" />
<link rel="stylesheet" href="large.css" media="(min-width: 90em)" />
<link rel="stylesheet" href="extra-large.css" media="(min-width: 120em)" />
<link rel="stylesheet" href="print.css" media="print" />
当我们将其拆分成按 media 查询的时候,浏览器会这样:
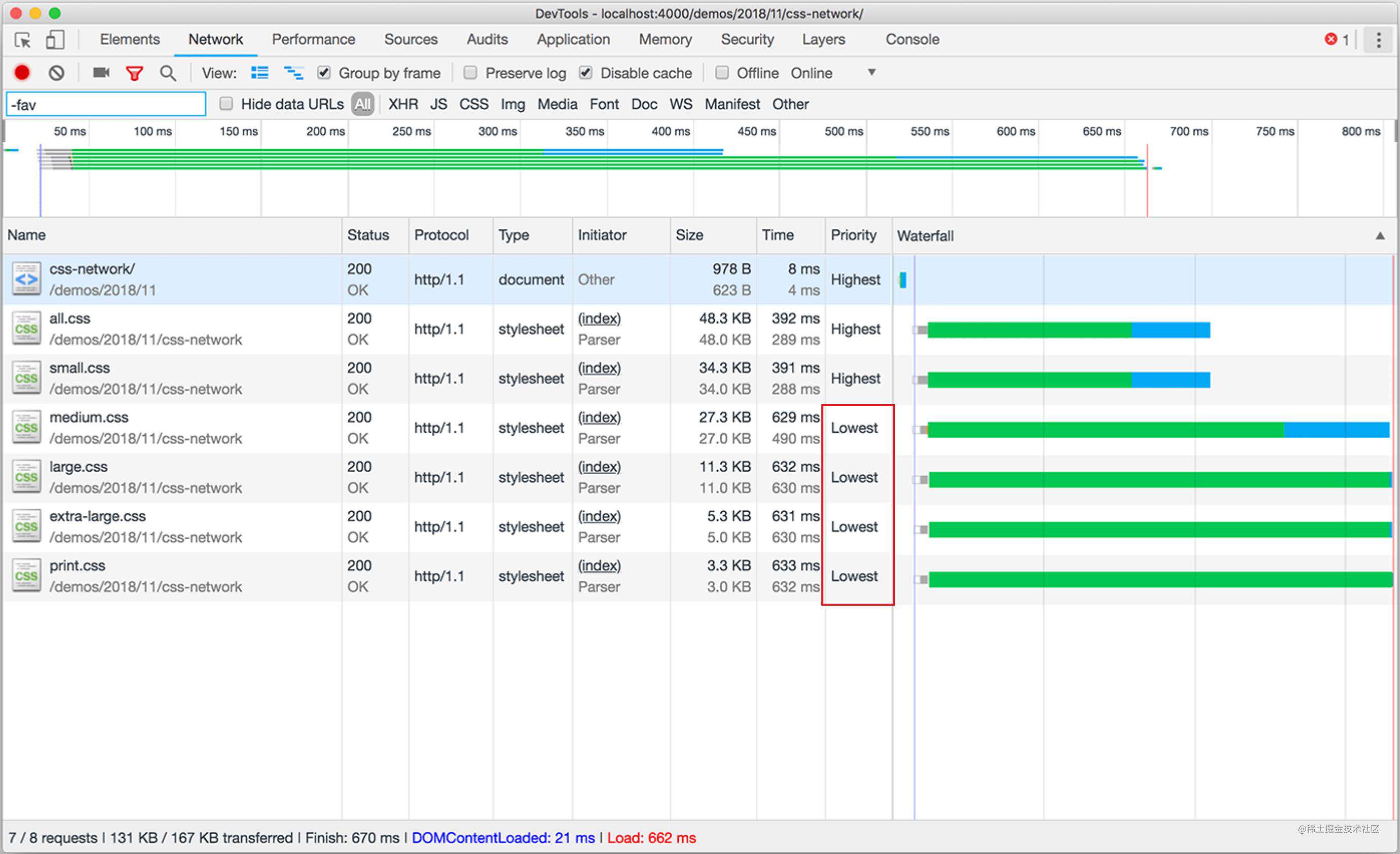
避免在 CSS 文件中使用 @import,因为它的工作原理,会影响浏览器的并行下载。不过目前我们更多使用的是 scss、less他们会将 @import 的文件直接包含在 CSS 中,并不会产生额外的 HTTP 请求。
另外,不要将 <link rel="stylesheet"> 放在 async 代码段之前。如果 JavaScript 脚本不依赖于样式,可以考虑将异步脚本置于样式之上。如果存在依赖,可以将 JavaScript 分成两部分,将它们分别放到 CSS 的两边来加载。
动态样式也可能会有很高的代价,虽然因为 React 的性能很好,所以通常只会发生在大量组合组件并行渲染时才会出现这种情况。根据 The unseen performance costs of modern CSS-in-JS libraries in React apps 的研究,在 production 模式开启时,通过 CSS-in-JS 创建的组件可能会比常规的 React 组件多花一倍的渲染时间。所以在应用 CSS-in-JS 时,可以采用以下方案来提升你的程序性能:
- 不要过度的组合嵌套样式组件:这可以让
React需要管理的组件更少,可以更快的完成渲染工作 - 优先使用“静态”组件:一些
CSS-in-JS库会在你的CSS没有依赖主题或props的情况下优化其执行。你的标签模板越是 「静态」,你的CSS-in-JS运行时就越有可能执行得更快。 - 避免无效的React重新渲染:确保只在需要的时候才渲染,这样可以避免
React和CSS-in-JS库的运行时工作。 - 零运行时的 CSS-in-JS 库是否能适用于你的项目:有时我们会选择在
JS中编写CSS,因为它确实提供了一些很好的开发者体验,同时我们又不需要访问额外的JS API。如果你的应用程序不需要对主题的支持,也不需要使用大量复杂的CSS props,那么零运行时的CSS-in-JS库可能是一个很好的选择。使用零运行时的库,你能从你的bundle文件中减少 12KB,因为大多数CSS-in-JS库的大小在 10KB-15KB 之间,而零运行时的库(如 linaria)小于1KB。
预热连接用于加速传输
使用 资源提示(resource hint) 节省时间:
dns-prefetch: 提示浏览器该资源需要在用户点击链接之前进行 DNS 查询和协议握手。
preconnect: 向浏览器提供提示,建议浏览器提前打开与链接网站的连接,而不会泄露任何私人信息或下载任何内容,以便在跟随链接时可以更快地获取链接内容。
prefetch: 提示浏览器,用户未来的浏览有可能需要加载目标资源,所以浏览器有可能通过事先获取和缓存对应资源,优化用户体验。
preload: 告诉浏览器下载资源,因为在当前导航期间稍后将需要该资源。
然后发现这里是不是还少了个 prerender?(建议浏览器事先获取链接的资源,并建议将预取的内容显示在屏幕外,以便在需要时可以将其快速呈现给用户。)
但是在实际中使用是它确很困难。因为它会使浏览器除了去获取资源,还可能会预处理该资源,而该 HTML 页面依赖的其他资源,像<script>、<style> 等页面所需资源也可能会被处理。预处理会由于浏览器或当前机器、网络情况的不同而被不同程度地推迟。例如,会根据 CPU、GPU 和内存的使用情况,以及请求操作的幂等性而选择不同的策略或阻止该操作。
所以,不出所料,它被弃用了。但 Chrome 团队基于此提出了 NoState Prefetch 机制。在 Chrome 63 版本以上,Chrome 已经把 prerender 当作了一个 NoState Prefetch,它的表现就像 prerender 一样,NoState Prefetch 会提前获取资源;但与 prerender 不同的是,它不执行 JavaScript,也不提前渲染页面的任何部分。NoState Prefetch 只使用约 45MiB 的内存,且子资源处理的优先级只是 空闲(IDLE) 级别。从 Chrome 69 开始,NoState Prefetch 就在所有的请求中加入了请求头 Purpose: Prefetch,以便它们区别于普通的浏览。
实际上,我们至少会使用 preconnect 和 dns-prefetch,会谨慎使用 prefetch, preload 和 prerender。需要注意的是:只有在你确认用户下一步将需要什么资源(例如:购买流程,注册流程)时,才应该使用 prerender。
即使使用了 preconnect 和 dns-prefetch,浏览器也会限制并行连接的主机数量,所以,根据优先级对它们进行排序会更好。
使用 resource hint 可能是提高性能的最简单的方法,而且它确实能给你带来性能提升。
下面附上各个阶段资源的请求优先级对照表:
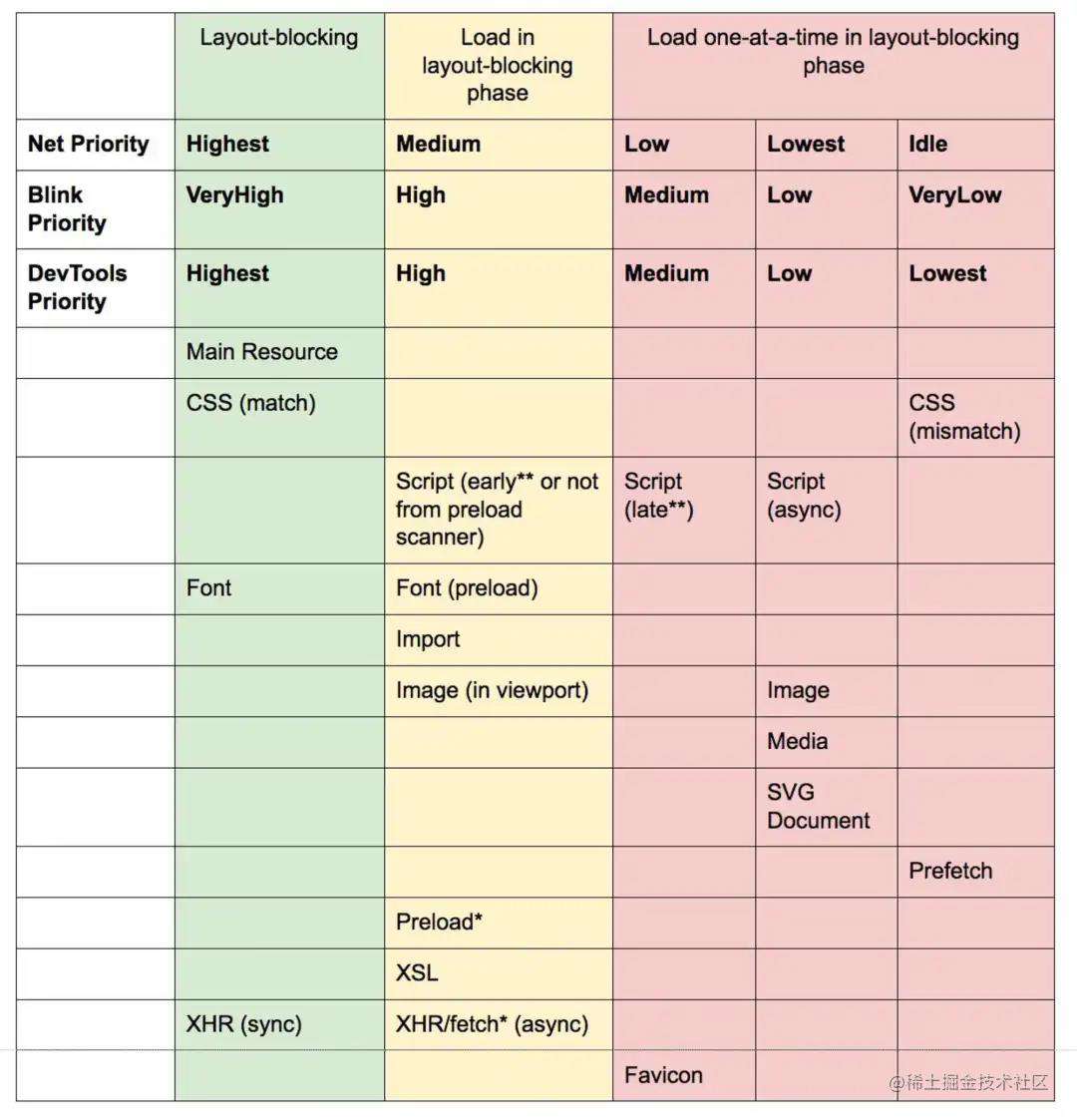
由于字体文件一般是页面上的重要资源,有时通过 preload 提示浏览器下载重要字体是一个比较好的方法。但是,需要仔细看下这样做是否真的能提升性能,因为在预加载字体时存在一个优先级的难题:由于预加载被视为非常重要,它可以跳过甚至更关键的资源,如关键 CSS。
您还可以动态加载 JavaScript,有效地延迟加载执行。此外,由于 <link rel="preload"> 接受 media 属性,所以可以根据 @media 查询规则选择性的对资源进行优先级排序。
最后,有几个需要注意的问题:
preload 有助于将资源的开始下载时间提前到更接近初始请求的时间,但是预加载资源会占用与页面的内存缓存。
preload 可以很好地处理 HTTP 缓存:如果资源已经在 HTTP 缓存中,则永远不会发送网络请求。
因此,preload 对于后续触发加载的资源,如 background-image 加载的图片、内联关键的 CSS(或 JavaScript)并预加载其余的 CSS(或 JavaScript)非常有用。此外,只有在浏览器从服务器接收到 HTML 并且解析器找到 preload 标记之后,preload 标记才能初始化预加载。
另外还有一些新的提案,例如:Early Hint 可以在 HTML 的响应头之前,就可以启用 preload,Priority Hints 为开发人员提供了一种向浏览器表明资源优先级的方法,允许我们更好的控制资源加载的顺序。

优化渲染性能
使用 CSS 的 will-change 通知浏览器哪些元素和属性将会改变。
will-change: auto
will-change: scroll-position
will-change: contents
will-change: transform
will-change: opacity
will-change: left, top
will-change: unset
will-change: initial
will-change: inherit
CSS 大部分样式是通过 CPU 来计算的,但 CSS 中也有一些 3D 的样式和动画的样式,计算这些样式会有有很多重复且大量的计算任务,可以交给 GPU 来跑。
浏览器在处理下面的 CSS 的时候,会使用 GPU 渲染:
transformopacityfilterwill-change
这里要注意的是 GPU 硬件加速是需要新建图层的,而把该元素移动到新图层是个耗时操作,界面可能会闪一下,所以最好提前做。will-change 就是提前告诉浏览器在一开始就把元素放到新的图层,方便后面用 GPU 渲染的时候,不需要做图层的新建。
你是否了解如何避免回流和重绘?
说道回流和重绘,我们先来回顾下浏览器的渲染流程:
-
构建 DOM 树
HMTL词法语法分析,转成对应的AST树
-
样式计算
-
格式化样式属性,例如:
rem->px、white->#FFFFFF等 -
计算每个节点样式属性:根据
CSS选择器与DOM 树共同构建render 树
-
-
生成布局树
- 这里去除一些
dispy:none等隐藏样式的元素,因为它们不在render树中
- 这里去除一些
-
建立图层树
- 主要分为「显式合成」和「隐式合成」
- 当重绘时就只需要重绘当前图层
- 主要分为「显式合成」和「隐式合成」
-
生成绘制列表
- 将图层树转换成绘制的指令列表
-
生成图块和位图
-
绘制列表交付给合成线程,进行图层分块。
-
渲染进程中专门维护了一个栅格化线程池,专门负责把图块交由
GPU渲染 -
GPU渲染后将位图信息传递给合成线程,合成线程将位图信息在显示器显示
-
-
显示器显示内容
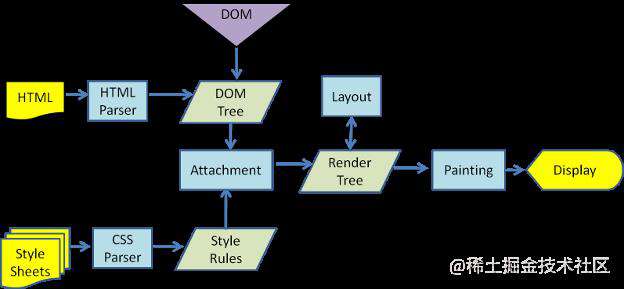
其中第四步建立图层树很重要,我们再着重的讲一下。浏览器从 DOM 树画质到屏幕图形上,需要做树结构到层结构的转化。这里介绍4个点:
-
渲染对象(RenderObject)
一个
DOM节点对应了一个渲染对象,渲染对象维持着DOM树的树形结构。渲染对象知道怎么去绘制DOM节点的内容,它通过向一个绘图上下文(GraphicsContext)发出必要的绘制指令来绘制DOM节点。 -
渲染层(RenderLayer)
浏览器渲染时第一个构建的层模型,位于同一个层级坐标空间的渲染对象都会被归并到同一个渲染层中,所以根据层叠上下文,不同层级坐标空间的的渲染对象将会形成多个渲染层,以此来体现它们之间的层叠关系。所以,对于满足形成层叠上下文条件的渲染对象,浏览器会自动为其创建新的渲染层。通常以下几种常见情况会让浏览器为其创建新的渲染层:
document元素position: relative | fixed | sticky | absoluteopacity< 1will-change | fliter | mask | transform != none | overflow != visible
-
图形层(GraphicsLayer)
图形层是一个负责生成最终准备呈现出来的内容图形的层模型,它拥有一个图形上下文(GraphicsContext),图形上下文会负责输出该层的位图。存储在共享内存中的位图将作为纹理(可以把它想象成一个从主存储器移动到图像存储器的位图图像)上传到
GPU,最后由GPU将多个位图进行合成,然后绘制到屏幕上,此时,我们的页面也就展现到了屏幕上。所以图形层是一个重要的渲染载体和工具,但它并不直接处理渲染层,而是处理合成层。
-
合成层(CompositingLayer)
满足某些特殊条件的渲染层,会被浏览器自动提升为合成层。合成层拥有单独的图形层,而其他不是合成层的渲染层,则会和第一个拥有图形层的父层共用一个。
那么一个渲染层满足哪些特殊条件时,才能被提升为合成层呢?这里也列举一些常见情况:
3D transformsvideo、canvas、iframeopacity动画转换position: fixedwill-changeanimation或transition设置了opacity、transform、fliter、backdropfilter
上面提到满足一些特殊条件的渲染层最终会被浏览器提升了合成层,称为显式合成。除此之外,浏览器在合成阶段还存在一种隐式合成。下面我们通过举例来看下:
- 假设,我们有两个
absolute定位的div在屏幕上交叠了,根据z-index的关系,其中一个div就会”盖在“了另外一个上边。

- 这时候,如果我们给
z-index: 3设置transform: translateZ(0),让浏览器将其提升为合成层。提升后z-index: 3这个合成层就会在docuemnt上方,那么按理来说z-index: 3就会在z-index: 5上面,我们设置的z-index就会出现交叠关系错乱的情况
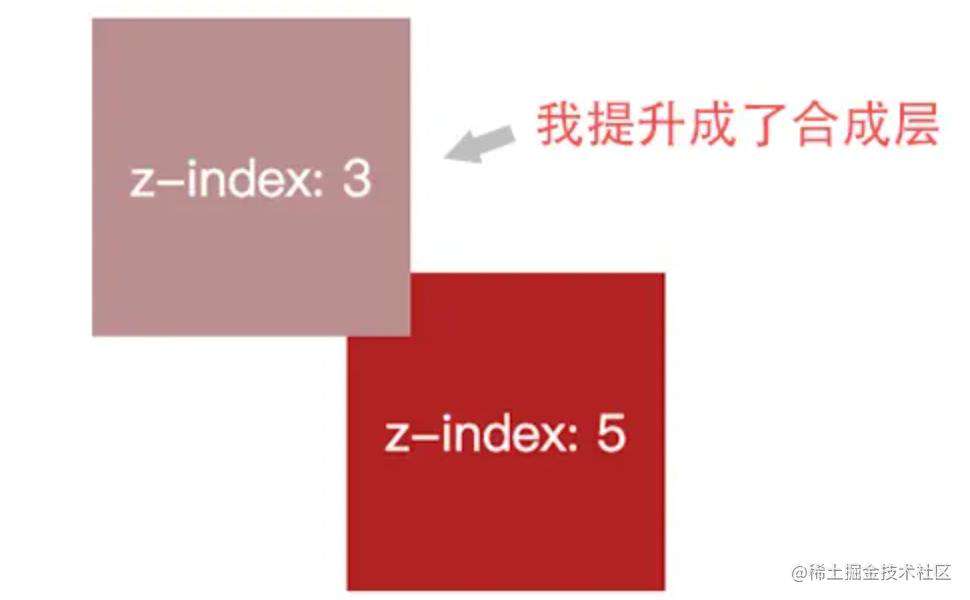
- 为了纠正这种错误的交叠顺序,浏览器必须让原本应该”盖在“它上边的渲染层也同时提升为合成层。这称为隐式合成
渲染层提升为合成层之后,会给我们带来不少好处:
- 合成层的位图,会交由
GPU合成,比CPU处理要快得多; - 当需要重绘时,只需要重绘本身,不会影响到其他的层;
- 元素提升为合成层后,
transform和opacity才不会触发重绘,如果不是合成层,则其依然会触发重绘。
当然了,任何东西滥用都是会有副作用,例如:
- 绘制的图层必须传输到
GPU,这些层的数量和大小达到一定量级后,可能会导致传输非常慢,进而导致一些低端和中端设备上出现闪烁; - 隐式合成容易产生过量的合成层,每个合成层都占用额外的内存,形成层爆炸。占用
GPU和大量的内存资源,严重损耗页面性能。而内存是移动设备上的宝贵资源,过多使用内存可能会导致浏览器崩溃,让性能优化适得其反。
OK,大概知道了浏览器的渲染原理后,我们来看下如何在实际中去减少回流和重绘:
- 始终在图像上设置宽度和高度属性:浏览器会在默认情况下会分配框并保留空间,后续图片资源加载完成后不需要回流。
- 避免多次修改:例如我们需要修改一个
DOM的height/width/margin三个属性,这时候我们可以通过cssText去修改,而不是通过dom.style.height去修改。 - 批量修改 DOM:将
DOM隐藏或者克隆出来修改后再替换,不过现在浏览器会用队列来存储多次修改,进行优化。 这个是适用范围已经不是那么广了。 - 脱离文档流:对于一些类似动画之类的频繁变更的
DOM.可以使用绝对定位将其脱离文档流,避免父元素频繁回流。
网络优化
启用 OCSP stapling 了吗?
通过在服务器上启用 OCSP stapling,可以加快 TLS 握手的速度。「在线证书状态协议」(OCSP)是「证书吊销列表」(CRL)协议的替代品。两种协议都用于检查 SSL 证书是否已被吊销。但是,OCSP 协议不需要浏览器花时间下载和搜索证书信息列表,因此减少了握手所需的时间。
是否针对HTTP协议做了正确的优化?
随着 HTTPS 及 HTTP/2 的流行,很多 HTTP/1.1 时代的优化策略已经不奏效了,甚至还有反优化的作用。
这里我们顺带把各个版本的 HTTP 协议做一下简单的分析:
-
HTTP/1.0
- 浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接(TCP连接的新建成本很高,因为需要客户端和服务器三次握手),服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求
-
HTTP/1.1
- 管道化(Pipelining):提出管道化方案解决连接延迟,服务端可设置
Keep-Alive来让连接延迟关闭时间,但因为浏览器自身的Max-Connection最大连接限制,同一个域名下的请求连接限制(同域下谷歌浏览器是一次限制最多6个连接),只能通过多开域名来实现,这也就是我们的静态资源选择放到CDN上或其它域名下,来提高资源加载速度。管道化方案需要前后端支持,但绝大部分的HTTP代理器对管道化的支持并不友好。 - 只支持GET/HEAD:管道化只支持
GET/HEAD方式传送数据,不支持POST等其它方式传输。 - 头部信息冗余:
HTTP是无状态的,客户端/服务端只能通过HEAD的数据维护获取状态信息,这样就造成每次连接请求时都会携带大量冗余的头部信息,头部信息包括COOKIE信息等。 - 超文本协议:
HTTP/1.X是超文本协议传输。超文本协议传输,发送请求时会找出数据的开头和结尾帧的位置,并去除多余空格,选择最优方式传输。如果使用了HTTPS,那么还会对数据进行加密处理,一定程度上会造成传输速度上的损耗。 - 队头阻塞:管道化通过延迟连接关闭的方案,虽然可同时发起对服务端的多个请求,但服务端的
response依旧遵循FIFO(先进先出)规则依次返回。举个例子客户端发送了1、2、3、4四个请求,如果1没返回给客户端,那么2,3,4也不会返回。这就是所谓的「队头阻塞」。高并发高延迟的场景下阻塞明显。
- 管道化(Pipelining):提出管道化方案解决连接延迟,服务端可设置
-
HTTP/2.0
- 多路复用:一个域只要一个
TCP连接,实现真正的并发请求,降低延时,提高了带宽的利用率。 - 头部压缩:客户端/服务端进行渐进更新维护,采用
HPACK压缩,节省了报文头占用流量。- 相同的头部信息不会通过请求发送,延用之前请求携带的头部信息。
- 新增/修改的头部信息会被加入到
HEAD中,两端渐进更新。
- 请求优先级:每个流都有自己的优先级别,客户端可指定优先级。并可以做流量控制。
- 服务端推送:例如我们加载 index.html, 我们可能还需要index.js, index.css等文件。传统的请求只有当拿到index.html,解析html中对index.js/index.css的引入才会再请求资源加载,但是通过服务端数据,可以提前将资源推送给客户端,这样客户端要用到的时候直接调用即可,不用再发送请求。
- 二进制协议:采用二进制协议,区别
与HTTP/1.X的超文本协议。客户(服务)端发送(接收)数据时,会将数据打散乱序发送,接收数据时接收一端再通过streamID标识来将数据合并。二进制协议解析起来更高效、“线上”更紧凑,更重要的是错误更少。
- 多路复用:一个域只要一个
-
HTTP/3.0
采用
QUIC协议,基于UDP协议,避免了TCP协议的一些缺点,采用TLS1.3将HTTPS所需的RTT降至最少为0。-
TCP 协议的不足
-
TCP 可能会间歇性地挂起数据传输:如果一个序列号较低的数据段还没有接收到,即使其他序列号较高的段已经接收到,
TCP的接收机滑动窗口也不会继续处理。这将导致TCP流瞬间挂起,在更糟糕的情况下,即使所有的段中有一个没有收到,也会导致关闭连接。这个问题被称为TCP流的行头阻塞(HoL)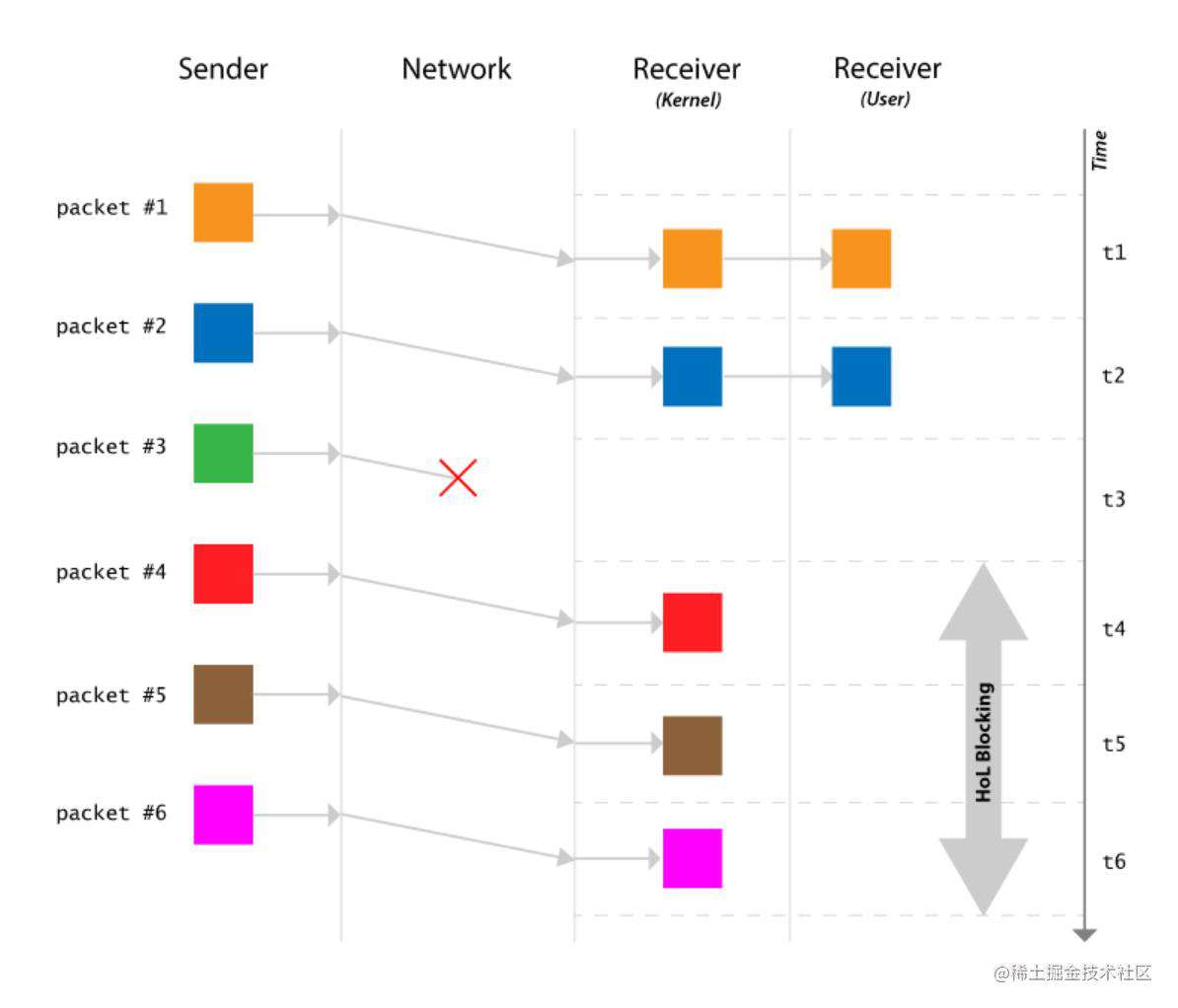
-
TCP 不支持流级复:虽然
TCP确实允许在应用层之间建立多个逻辑连接,但它不允许在一个TCP流中复用数据包。使用HTTP/2时,浏览器只能与服务器打开一个TCP连接,并使用同一个连接来请求多个对象,如CSS、JavaScript等文件。在接收这些对象的同时,TCP会将所有对象序列化在同一个流中。因此,它不知道TCP段的对象级分区。 -
TCP 会产生冗余通信:
TCP连接握手会有冗余的消息交换序列,即使是与已知主机建立的连接也是如此。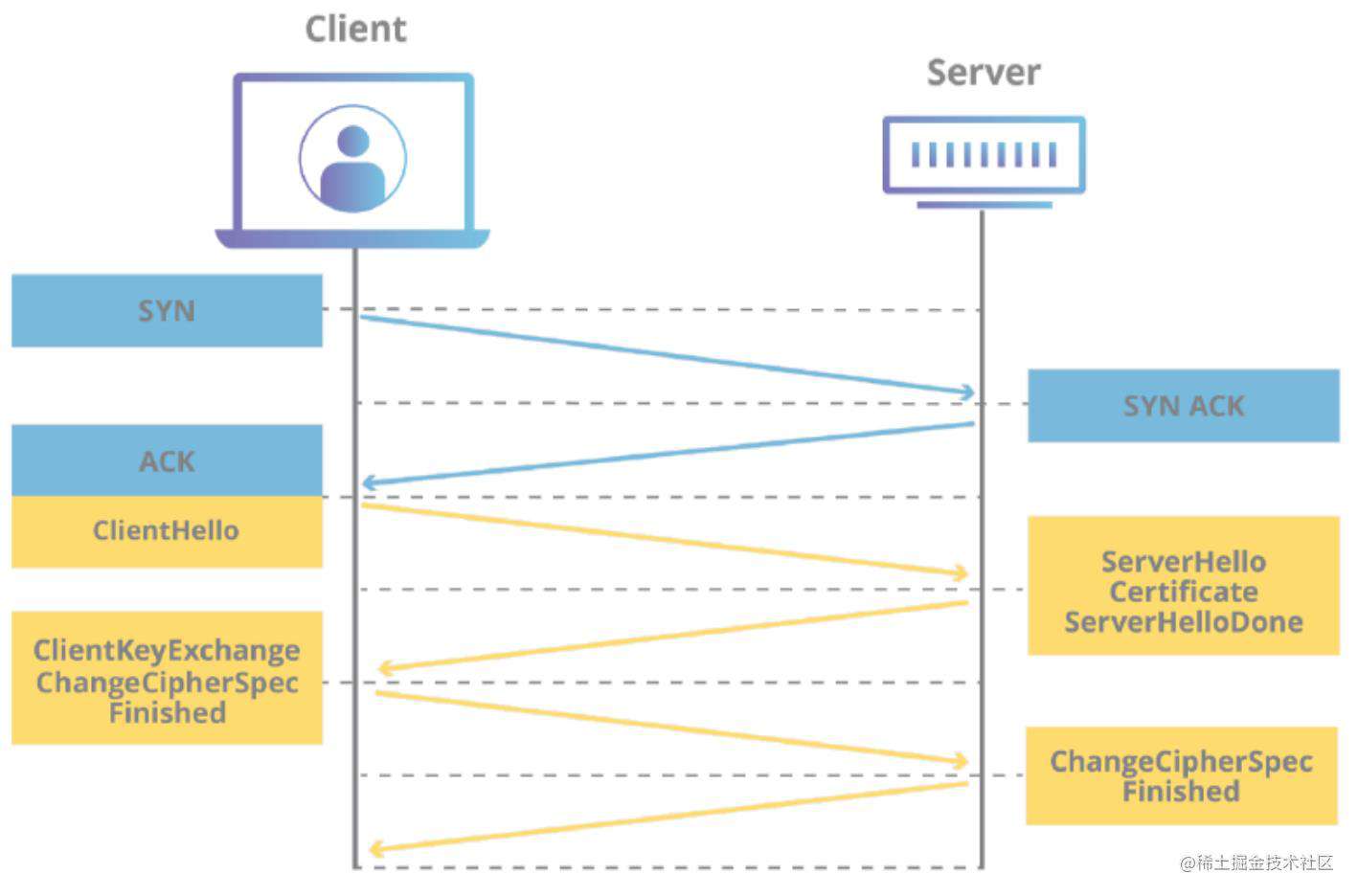
-
-
QUIC 协议的优势
-
选择UDP作为底层传输层协议:在
TCP之上建立新的传输机制,将继承TCP的上述所有缺点。因此,UDP是一个明智的选择。此外,QUIC是在用户层构建的,所以不需要每次协议升级时进行内核修改。 -
流复用和流控:
QUIC引入了连接上的多路流复用的概念。QUIC通过设计实现了单独的、针对每个流的流控,解决了整个连接的行头阻塞问题。 -
灵活的拥塞控制机制:
TCP的拥塞控制机制是刚性的。该协议每次检测到拥塞时,都会将拥塞窗口大小减少一半。相比之下,QUIC的拥塞控制设计得更加灵活,可以更有效地利用可用的网络带宽,从而获得更好的吞吐量。 -
更好的错误处理能力:
QUIC使用增强的丢失恢复机制和转发纠错功能,以更好地处理错误数据包。该功能对于那些只能通过缓慢的无线网络访问互联网的用户来说是一个福音,因为这些网络用户在传输过程中经常出现高错误率。 -
更快的握手:
QUIC使用相同的TLS模块进行安全连接。然而,与TCP不同的是,QUIC的握手机制经过优化,避免了每次两个已知的对等者之间建立通信时的冗余协议交换。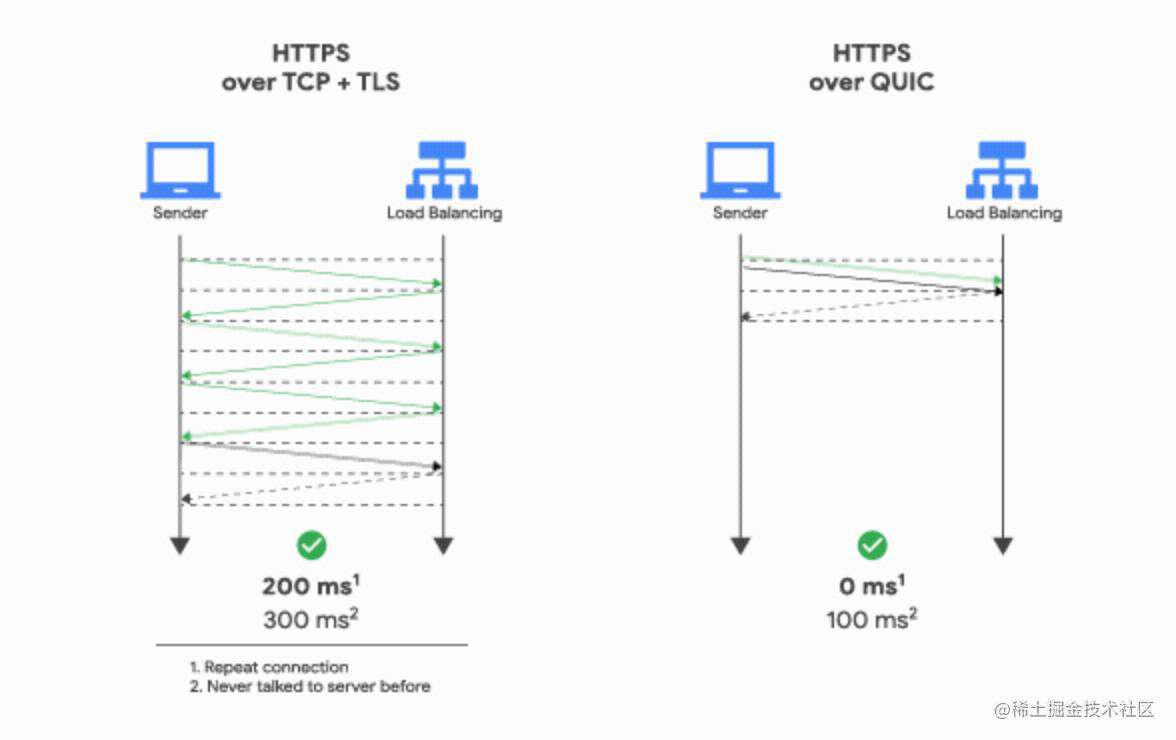
-
-
OK,大概了解的 HTTP 协议的版本特点后,我们来看在目前主流 HTTP2 + HTTPS 的时代下,哪些优化策略已经过时了甚至是反优化呢
- 减少请求数:
HTTP/1.1因为存在「队头阻塞」,所以我们通常会采用合并资源,捆绑文件(雪碧图等)等方式来减少请求数。但在HTTP/2中我们更需要注重网站的缓存调优,传输轻量、细粒度的资源,方便独立缓存和并行传输。 - 多域名存储:
HTTP/1.1因为浏览器有最大连接数限制,所以我们会将资源分发到不同的域名下存放以此来增大最大连接数。但在HTTP/2中一个域只有一个链接,所以我们不需要去分多个域名存储,多域名存储甚至还会造成额外的TLS消耗。
减小请求头的大小
减小请求头的大小,常见的情况是 Cookie 。例如我们的主站中(如:www.test.com ) 存储了很多的 Cookie,我们的 CDN 域名(cdn.test.com)与我们主域一样,此时我们去请求时会附带上 .test.com域下的 Cookie。而且这些 Cookie 对于 CDN 毫无用处,会增大我们请求的包大小。所以我们可以将 CDN 域名与主域区分开,例如:淘宝(https://www.taobao.com)的 CDN 域名为 https://img.alicdn.com。
总结
优化工具
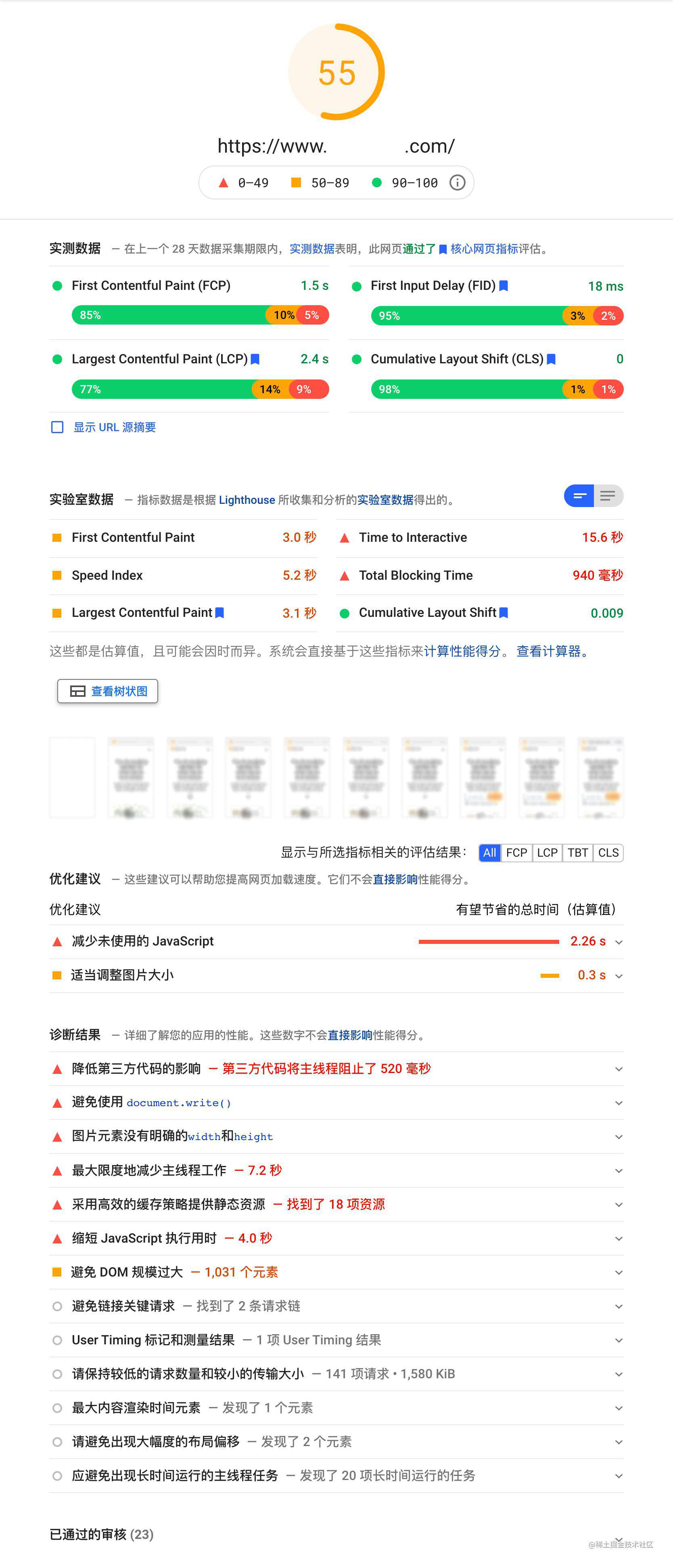
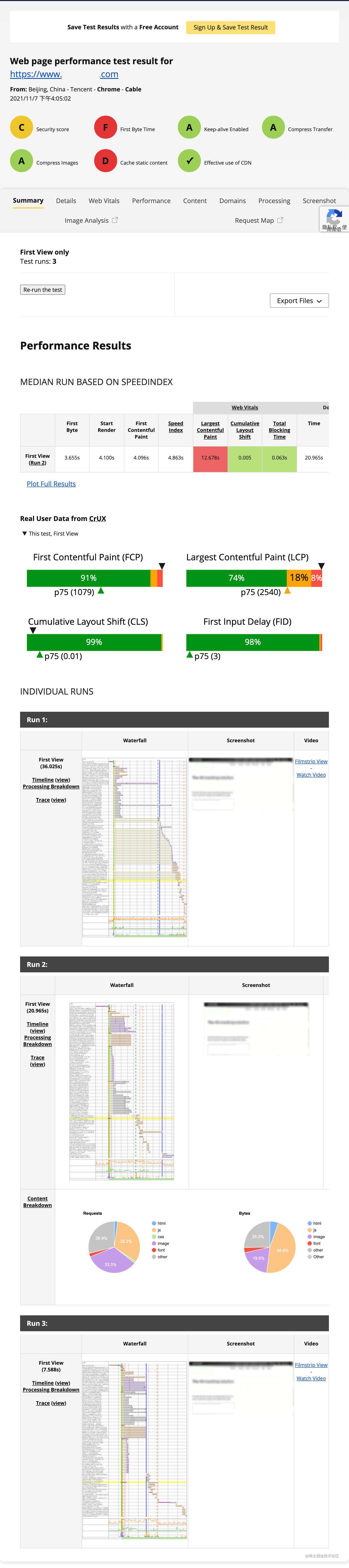
上面我们长篇大论的简述了许多前端优化的点,这里再推荐 PageSpeed Insights 和 WebPageTest 这两个工具。
速成方案
这个清单很庞大,如果要完成所有的优化可能需要很长时间。所以,如果你只有很有限的时间来进行优化,你会怎么做呢?让我们把它浓缩成15个比较容易实现的点。
- 根据实际经验制定合适的目标。一个比较合理的目标是:可视区域渲染 < 1s,页面渲染 < 3s,弱网 3G 的可操作时间 < 5s,重复访问的可交互时间(TTI) < 2s。
- 为首屏准备关键 CSS,并将其内联在页面。对于
CSS/JS,关键文件大小控制在最大为压缩后 170KB内。 - 抽离、优化、延迟加载尽可能多的脚本,选轻量级替代方案(如用
DayJs代替MomentJs),并限制第三方脚本的影响。 - 仅向具有
<script type="module">和 module/nomodule 模式的旧版本浏览器提供旧版本代码。 - 尝试重新组合
CSS规则。 - 添加资源提示(
resource hints)以提升页面加载速度,例如dns-prefetch、preconnect、prefetch、preload、prerender等。 - 设置 Web 字体子集并异步加载,并利用
CSS中的font-display实现快速的首次呈现。 - 使用mozjpeg、 guetzli、 pingo 和 SVGOMG优化图像,并考虑使用图像
CDN为WebP服务。 - 检查
HTTP缓存头和安全头是否设置正确。 - 在服务器上启用
Brotli压缩。(如果不行,那么请启用Gzip压缩。) - 只要服务器运行在
Linux内核版本 4.9+上,就启用TCP BBR拥塞。 - 如果可能,启用
OCSP stapling。 - 如果
HTTP/2可用,则启用HPACK压缩。如果激进一点可以尝试启用HTTP/3。 - 在
Service worker中缓存字体、样式、JavaScript 和图像等资源。 - 尝试使用渐进式
hydration和流服务器渲染你的单页应用。
参考文章
www.smashingmagazine.com/2021/01/fro…
juejin.cn/post/701064…
juejin.cn/post/684490…
segmentfault.com/a/119000002…
www.jianshu.com/p/1ad439279…
zhuanlan.zhihu.com/p/364991981
zhuanlan.zhihu.com/p/102382380
web.dev/vitals/
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!