商品详情页是手淘内流量最大的模块之一,它加载了数十亿级商品的详细信息,是用户整个决策过程必不可少的一环。这个区块不仅要承接用户对当前商品充分感知的诉求,同时也要能肩负起其他来源导流流量的留存,最终尽可能地激活平台内部流量以及外部流量在整个生态中的活跃度。同时,商品详情页也是众多场景乃至平台链接的纽带,用户在平台中的行为轨迹总会在多场景和详情页间不断交替,并在详情页产生进一步的行为决策(加购/购买等)。因而详情页上除了具备承接用户的“了解更多”的诉求,也应同时满足平台“起承转合中间件”的诉求。
详情页内流量具备两个显著的特性:
- 流量大,常是用户购买决策环节;
- 承接了大量的外部引流。
出于这两个重要特性,同时也出于提升平台黏度,尽可能地提升用户行为的流畅度的产品设计考量,我们在详情页内部设立了一些全网分发场景,并基于这些场景特点进行了一些算法探索。
背景
信息爆炸导致用户对于海量信息的触达寥若晨星,对于有效信息的触达更是凤毛麟角。如果说社交媒体是无声者的发声者,那推荐系统俨然可以看作是海量信息的发声者,同时也是平台用户被曝光信息的制造者。所以我们有责任与义务做到推荐内容的保质与品控,这对于推荐系统是极大的诉求与挑战。当下的推荐系统通过深度挖掘用户行为,对用户进行个性化需求挖掘与实时兴趣捕捉,旨在于帮助用户在海量信息中快速,精准地定位,从而更好的完成智能化服务。
详情页的分发推荐肩负着【服务商家】,【提升用户使用体验】以及【利好平台分发效能】的重要责任。这给我们场景提出了三个方面不同侧重的需求,它们需要被统筹兼顾,以期能够打造出一个更好的流量分发阵地。我们解决这三个需求的方式是开辟同店商品推荐前置的全网分发模块,在极大程度保证商家权益的同时,让用户能够在一个聚焦的页面快速定位海量商品中“猜你喜欢”的商品。详情页内的推荐和公域推荐有一个最大的差异:每个详情页面都是主商品的信息衍生场,推荐内容受到它较强的约束。现有的大多数研究缺乏对具有先验信息的场景的探索:它们只强调用户的个性化兴趣。有一些重要的、直接相关的先验信息被直接忽略。我们观察到,在单个商品/主题唤醒的推荐页面上,用户的点击行为和主商品(唤醒推荐页面的商品/主题)是高度同质的。在这些场景下,用户已经通过主商品给模型传达了一个很聚焦很明确的意图,所以推荐的相关结果不能肆意泛化。但同时,一味的聚集又回降低分发的效能,使得用户在浏览过程中产生疲劳感。因而这些场景的推荐内容,应当遵循“意图明确,适度发散”的策略。当然,因为有主商品信息的加持,我们在模型调优时能够因地制宜地架构推荐策略,做出一些和其他场景相比,更明确更可解释的用户体验,这是我们写这篇文章的初衷。如果对这样的“以品推品”场景想要知道更多的细节,本篇文章将带您一起来看我们的探索问题——“用户即时兴趣强化与延伸”,以及模型解法和线上工程实践。
场景介绍
其中,全网流量分发场景主要包括详情页底部信息流(邻家好货),主图横滑(新增),加购弹层(新增)。这些场景打破了商家私域画地为牢的局面,充分地提升了私域全网分发的能效。当然为了兼顾商家利益,这些场景将分为两个部分(同店内容推荐模块和跨店内容推荐模块)。
技术探索
算法问题定义——即时兴趣强化
进入详情页是用户主动发起的行为,因而用户对于当前页面的主商品有着较强的兴趣聚焦。主商品的信息能够帮助我们快速地定位用户的即时兴趣,这对于推荐算法来说是至关重要的。虽然现在有很多方法将行为序列的末位替代即时兴趣,或是使用模型挖掘即时兴趣,但这些方法均是在不确定事件中进行推理,没有详情页天然带有主商品这样的强意图信息。基于此,我们的工作将从推荐技术的不同方面,将这部分信息建模并加以强化,以期使得详情页分发场景能够结合场景特点,尽可能地满足用户的即时需求。
召回
背景
随着深度学习技术在多个领域的普及以及向量检索技术的兴起,一系列基于类似思想的深度学习召回技术相继涌现。Youtube在2016年提出了DNN在推荐系统做召回的思路,它将用户历史行为和用户画像信息相结合,极大地提升了匹配范围的个性化和丰富性。我们的工作基于同组师兄的召回工作《SDM: 基于用户行为序列建模的深度召回》,《User-based Sequential Deep Match》 也是这一思路的一脉相承。SDM能够很好地建模用户兴趣的动态变化,并且能够综合长短期行为在不同维度进行用户表征,从而更好的使用低维向量表达用户和商品,最终借助大规模向量检索技术完成深度召回。SDM上线较base(多路i2i召回merge)ipv指标提升了2.80%。较SDM模型,CIDM模型IPV提升4.69%。在此基础上,为了契合详情页分发场景的特点,我们丰富并挖掘了主商品相关信息,并将其作为即时兴趣对召回模型进行结构改良。
模型——CIDM(Current Intention Reinforce Deep Match )
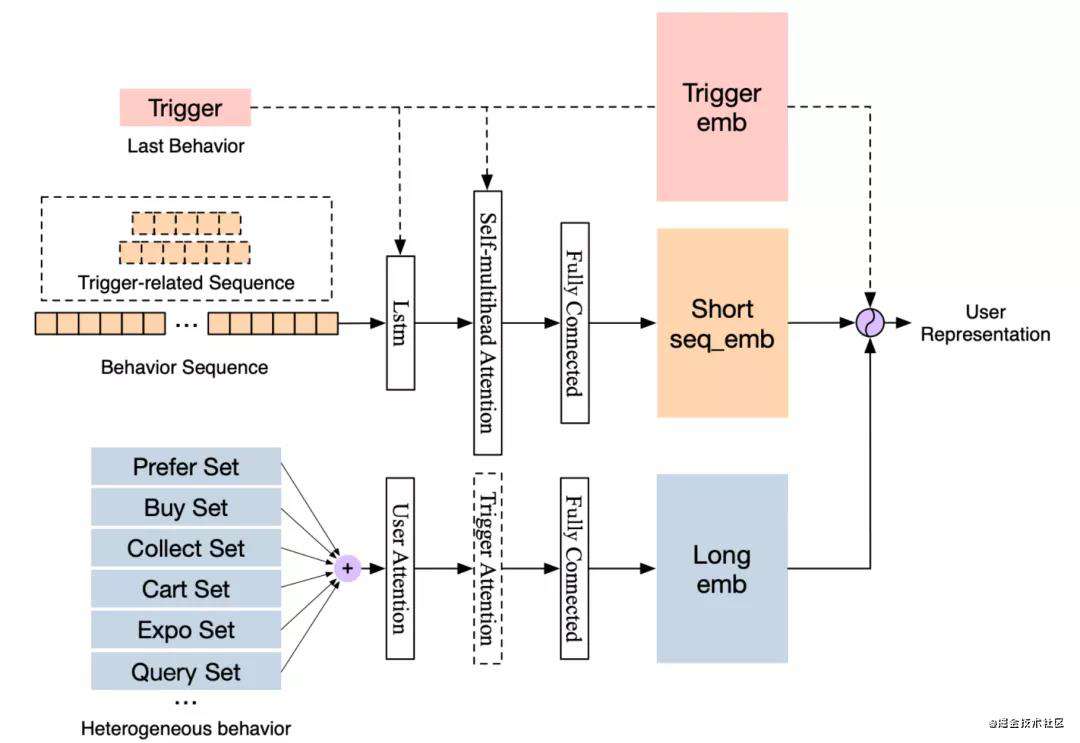
为了能够让模型SDM能够将主商品信息catch到并与用户行为产生交互,我们设计了如下的模型结构,其中trigger即为详情页中的主商品,我们从几个方面对它进行表征及强化:
- Trigger-Layer:启发于论文1,对主商品显式建模:除SDM中建模用户长、短期偏好之外,引入用户即时偏好层将主商品特征与长短期偏好融合作为用户最终表达;
- Trigger-Attention: 即将原模型中使用的self-attention改为由trigger作为目标的target-attention;
- Trigger-Lstm:借鉴论文2中的建模思路,我们将lstm的结构中引入了trigger信息,并添加trigger-gate让lstm倾向于记住更多关于主商品的内容;
- Trigger-filter-sequence:实验发现,使用主商品的叶子类目,一级类目过滤得到的序列作为原序列的补充进行召回建模,能够增加收益,故在数据源中添加了cate-filter-seq以及cat1-filter-sequece。
其中前两个点都是比较显而易见的,这里就不再赘述,我们将三四两个创新点详细阐述。
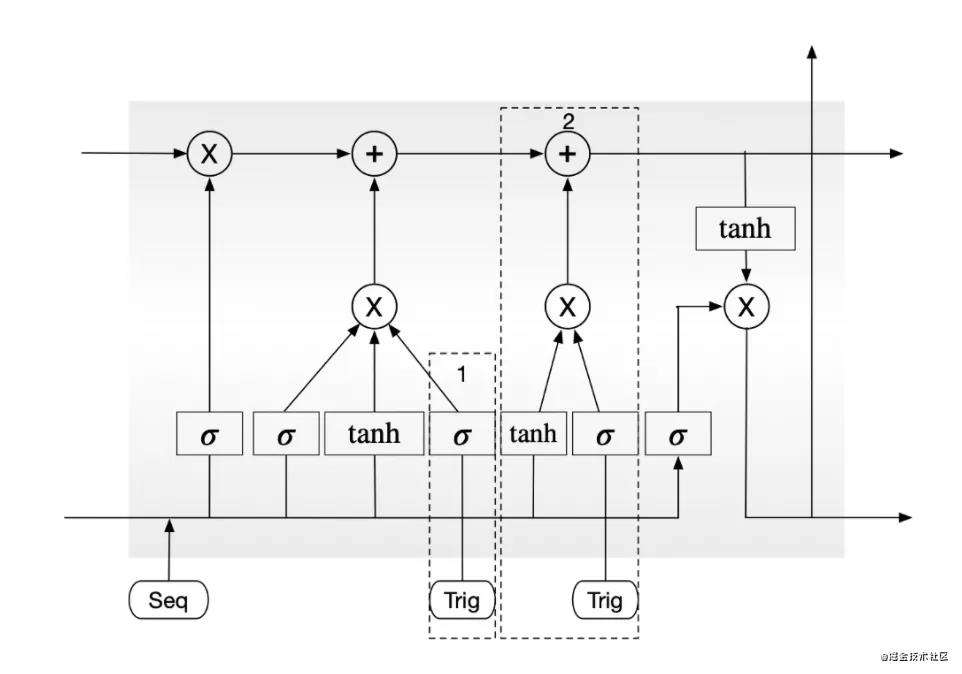
论文2中论证了添加时间门能够更好地捕捉用户的短期和长期兴趣,基于这个结论,我们尝试设计一个trigger-gate用于在模型捕获序列特征中引入trigger信息的影响。我们尝试了多种结构变体,比较work的两种方式(如图):
- 将trigger信息作为记忆门的一路输入,即通过sigmoid函数后与之前想要更新的信息相乘;
- 平行于第一个记忆门,添加一个新的即时兴趣门,其输入为细胞输入以及当前主商品,和记忆门结构一致。
这样的方式能够将主商品的信息保留的更充分。
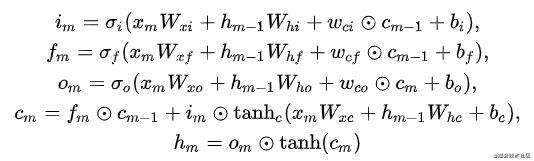
第一种方法,仅是对记忆门进行了修改:
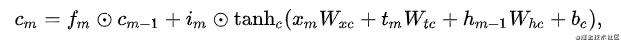
第二种方法,新加了一个即时兴趣门:
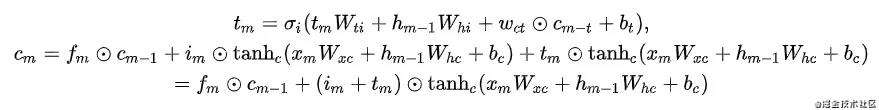
这两个实验在离线hr指标分别增长+1.07%. 1.37%,最优版本线上指标ipv+1.1%。
出于我们自己的实验结论:"使用主商品的叶子类目和一级类目过滤得到的序列作为原始序列的补充,作为模型输入能够提升预测准度“。这说明,主商品的结构信息是具有明显的效益的,以它为条件能够对序列样本产生正向约束。究其根本,原始序列中一些和当前主商品相关性较小的样本被过滤掉了,这相当于对数据进行去噪处理。沿着这个思路,联想到自编码机的主要应用为数据降噪与特征降维,故考虑采用基于AE结构的模型对序列进行处理,更多的,由于我们是定向去噪(即剔除与主商品不相关的行为),我们使用变分自编码机(VAE),借主商品信息在隐变量空间对序列表达进行约束,以确保隐层能较好抽象序列数据的特点。
变分自编码机是具有对偶结构(包括编码器和解码器)联合训练的系列模型,它借鉴变分推断的思路,在隐变量空间进行个性化定制,比较契合我们即使兴趣建模的需求。首先我们有一批数据样本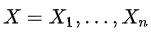 ,其似然分布可以表示为
,其似然分布可以表示为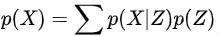 ,最大化其对数似然时后验概率分布
,最大化其对数似然时后验概率分布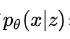 是不可知的,因而VAEs用自定义分布
是不可知的,因而VAEs用自定义分布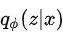 来近似真实的后验概率
来近似真实的后验概率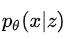 计算,使用KL散度作为两个分布的相似程度的度量。整体的优化函数可以表示为:
计算,使用KL散度作为两个分布的相似程度的度量。整体的优化函数可以表示为:
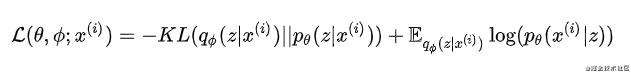
具体推导可以参见论文5。其中第一项作为使假设的后验分布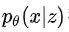 和先验分布
和先验分布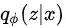 尽量接近,第二项为重构损失,保证自编码结构整体的稳定性。其中,先验分布
尽量接近,第二项为重构损失,保证自编码结构整体的稳定性。其中,先验分布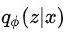 是我们自定义的,这里想要将主商品的信息融入其中,因而我们假设
是我们自定义的,这里想要将主商品的信息融入其中,因而我们假设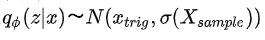 ,即使用主商品的表示作为高斯分布的均值,采样batch的二阶矩作为高斯分布的方差带入其中。因此,模型的优化函数变为:
,即使用主商品的表示作为高斯分布的均值,采样batch的二阶矩作为高斯分布的方差带入其中。因此,模型的优化函数变为:
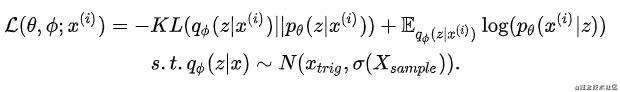
启发于论文3、4, 我们将网络结构设计为如下形式,使用主商品的特征向量作为mu和sigma引入到变分自编码网络中,规范隐空间中序列特征的表达,并将学习得到的序列隐空间变量seq_hid作为用户的强意图序列表达trigger_emb,和长短期偏好融合。
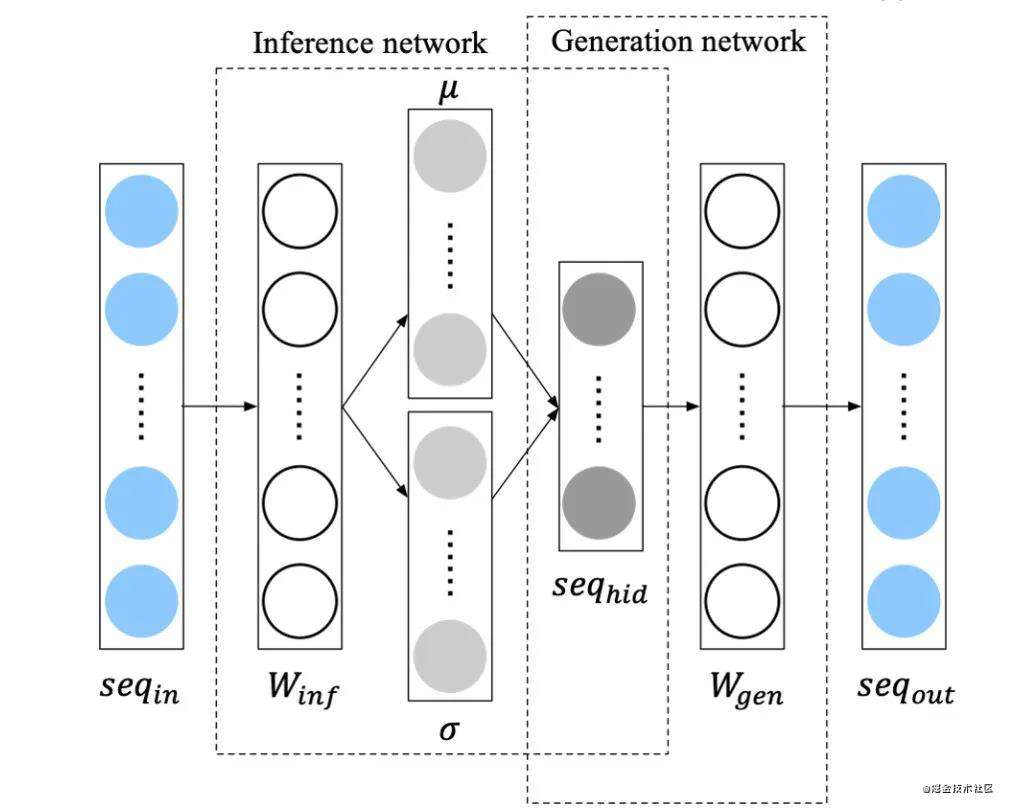
这实验在离线hr指标增长+2.23%,线上未测试。
效果
较SDM模型,CIDM模型线上效果IPV提升4.69%。
精排
背景
精排模型基于DIN(Deep Interest Networks)进行探索与发展,我们的想法是在序列信息基础之上融入主商品更多的信息。序列信息挖掘和主商品信息强化其实是我们场景两个需求的外化,主商品信息强化能够很好地抓住用户即时意图,满足用户即时的聚焦需求;而序列信息挖掘是基于当前意图的延伸,能够一定程度上对意图进行发散,使推荐结果不会产生过于集中而带来体验疲劳。当然这两方面需要权衡,让模型识别其中“聚”,“散”的时机与程度。在此基础上,我们进行了1、挖掘主商品更多的语义信息;2、强化主商品信息对于序列特征抽取的指引与影响。
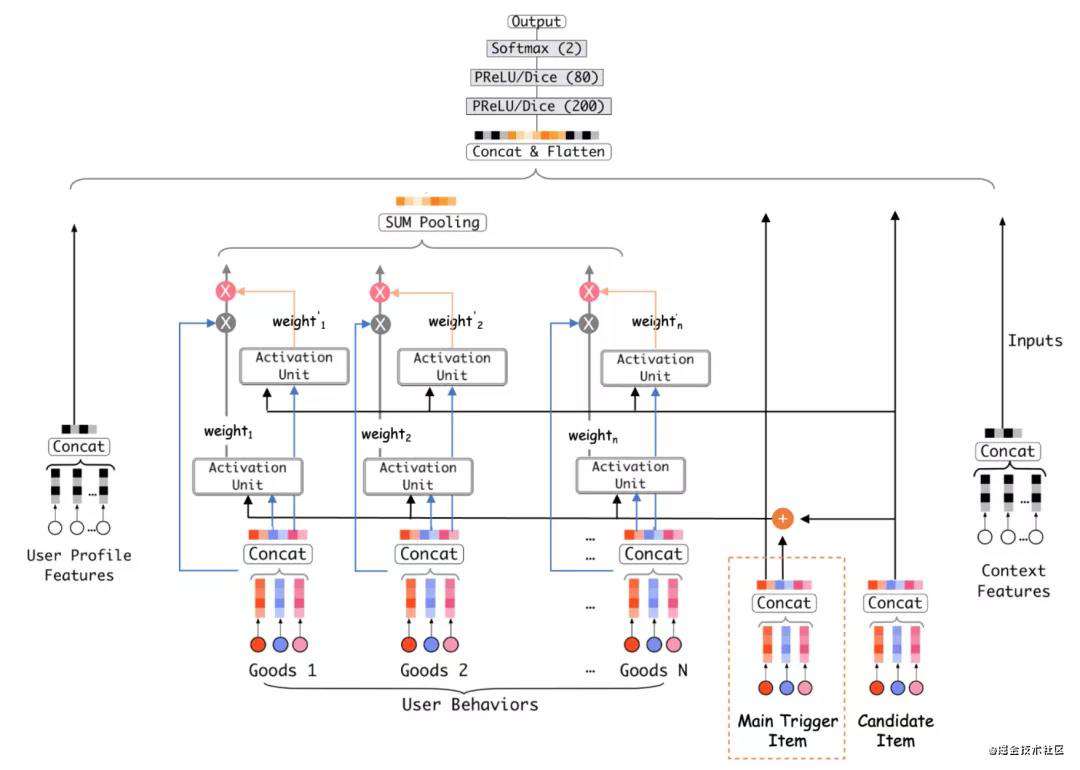
精排模型——DTIN(Deep Trigger-based Interest Network)
首先,我们希望能够挖掘主商品更多的语义信息,这一部分,我们将主商品(trigger)相关的特征和待打分商品(candidate)对齐,然后将这部分特征直接拼到模型的wide侧,让模型提升对于主商品表征的敏感度。
其次,由于DIN的motivation是引入注意力机制来更精准的捕获用户的兴趣点,作为比待打分商品更强的用户兴趣点体现,我们设计了一个双attention结构来强化这部分信息。如图所示,首先,将trigger和candidate商品特征concat,传入第一层attention结构中,学得第一层加权向量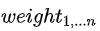 。这部分权值融合了trigger和candidate的信息,它可以被看作基于主商品及待打分商品交叉的用户兴趣提取。然后,仅使用主商品信息作为查询query传入第二层attention结构中,学得第二层加权向量
。这部分权值融合了trigger和candidate的信息,它可以被看作基于主商品及待打分商品交叉的用户兴趣提取。然后,仅使用主商品信息作为查询query传入第二层attention结构中,学得第二层加权向量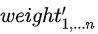 ,它可以被看作仅基于即时兴趣的延伸兴趣捕获。之后这两个权重向量按位相乘作为序列加权向量。模型结构设计这部分经历了大量的探索实验,如果有兴趣欢迎大家一起来讨论,这里只呈现我们实验中效果最佳版本。
,它可以被看作仅基于即时兴趣的延伸兴趣捕获。之后这两个权重向量按位相乘作为序列加权向量。模型结构设计这部分经历了大量的探索实验,如果有兴趣欢迎大家一起来讨论,这里只呈现我们实验中效果最佳版本。
效果
较DIN模型,DTIN模型IPV提升9.34%, 对应离线实验auc提升4.6%,gauc提升5.8%。
粗排
动机
粗排模型为的是解决推荐系统应用于工业界的特殊问题,在召回集合较大时,精排模型因复杂度太高而无法保证打分效率。因而粗排模型应运而生。由于详情页分发场景需要从全网亿级商品中进行商品召回,且召回阶段使用了多种召回方式的组合(包括i2i, 向量召回等)。这使得召回数量级较大,而且多路召回存在交叉使得匹配特征不在同一尺度上,这给后续的精排模型带来了较大的压力。基于此,我们开发了桥接召回和精排两部分的粗排模块,它的目标是对召回结果进行初筛,不仅需要兼顾效率与精度,也需要具有兼容多尺度召回方式的能力。基于我们的场景特点,在粗排初筛阶段进行了基于主商品的即时意图的建模。
模型——Tri-tower(Triple-tower Preparatory Ranking Framework)
出于粗排模型对于效率的要求不能构建过于复杂的结构,基于双塔粗排模型,我们针对强化即时兴趣的方向新添加了一个主商品塔trigger-tower,该塔和商品塔的特征保持一致,在顶端输出logits后和商品塔做交叉,作为之前双塔模型的补充添加在sigmoid函数的输入中。模型结构如下:
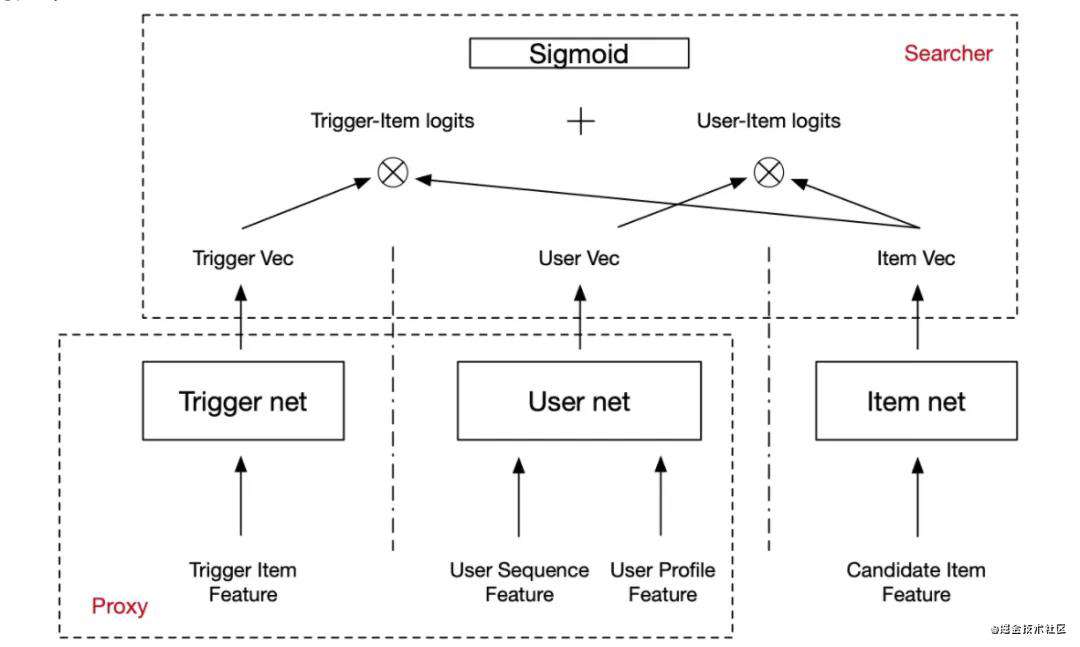
其中 Trigger net 和 Item net 使用 item 侧更轻量的一些统计类特征,User net也在deep match的基础上对大规模的id类特征进行了筛检。确保粗排模型轻量且服务快速。最终三塔粗排模型较无粗排模型,IPV指标提升3.96%。
总结
总体来看,详情页分发场景的优化思路比较统一,都是对主商品信息进行挖掘,并在模型中将用户历史行为进行关联加强。我们和传统的兴趣挖掘网络相比,附增了一道关口(即时兴趣强化),将那些明确的,和当前最相关的意图保留下来。通过这样的方式,推荐的结果就有一定程度的收敛。同时,多元兴趣在模型中并没有被完全抹去,只是通过attention网络动态调权来影响结果的发散程度,这也确保我们推荐结果一定的个性化和可发散性。
至此已阐述完“用户即时兴趣强化与延伸”课题在私域分发场景三个主要环节:召回-粗排-精排上面的有收益的尝试,当然这个过程也伴随着很多失败的探索,无论是模型优化和工程实践上的阻塞,都给我们带来了丰硕的实践经验。除了这三个主要模型外,我们在策略和其他环节的模型上也都针对该问题进行了优化,这里不再赘述。如果您对细节或者后续的优化方向感兴趣,欢迎与我们联系。
引用
- Tang, Jiaxi, et al. "Towards neural mixture recommender for long range dependent user sequences." The World Wide Web Conference. 2019.
- Zhu, Yu, et al. "What to Do Next: Modeling User Behaviors by Time-LSTM." IJCAI. Vol. 17. 2017
- Liang, Dawen, et al. "Variational autoencoders for collaborative filtering." Proceedings of the 2018 world wide web conference. 2018.
- Li, Xiaopeng, and James She. "Collaborative variational autoencoder for recommender systems." Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 2017.
- Zhao, Shengjia, Jiaming Song, and Stefano Ermon. "Towards deeper understanding of variational autoencoding models." arXiv preprint arXiv:1702.08658 (2017).
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?
![[路飞]_leetcode-227-基本计算器 II - 掘金](/ripro/timthumb.php?src=/images/titlepic.png&h=200&w=300&zc=1&a=c&q=100&s=1)
![[路飞]_leetcode-636-函数的独占时间 - 掘金](/ripro/timthumb.php?src=https://img.qiyuandi.com/img/20211125/[lf]_rj305yatcu3.jpg&h=200&w=300&zc=1&a=c&q=100&s=1)


发表评论
还没有评论,快来抢沙发吧!