虽然 Cocos 属于游戏开发范畴,但与前端开发中遇到的性能问题还是有很多共通之处,无非是加载速度、CPU、内存这三个指标。接下来分别从这三个指标来阐述一些优化手段。
1. 加载速度优化
Cocos 的启动大致可以分为5个阶段:

其中 Cocos 引擎加载和运行的耗时,业务侧是无法改动的,这部分黑屏时间无法优化。那么黑屏时间优化就只剩 Cocos 静态资源加载了。
静态资源加载的手段有两个:
资源压缩主要是针对图片资源的压缩,tinify支持 png 和 jpg 格式图片的在线压缩,一般可以压缩掉 75% 的大小,并且在视觉上不会有明显的差异,十分推荐。
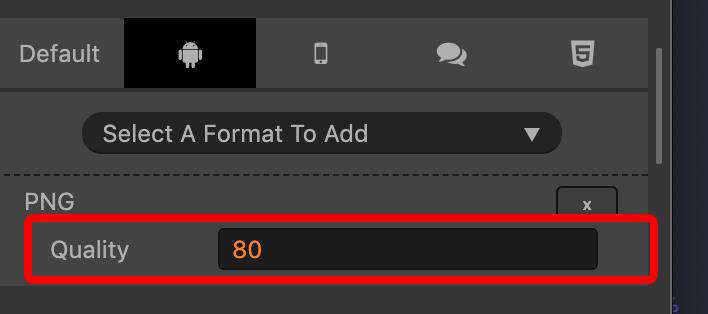
如果接受一定程度的失真,在 cocos creator 编辑器中也能够对 png 和 jpg 图片进行压缩。
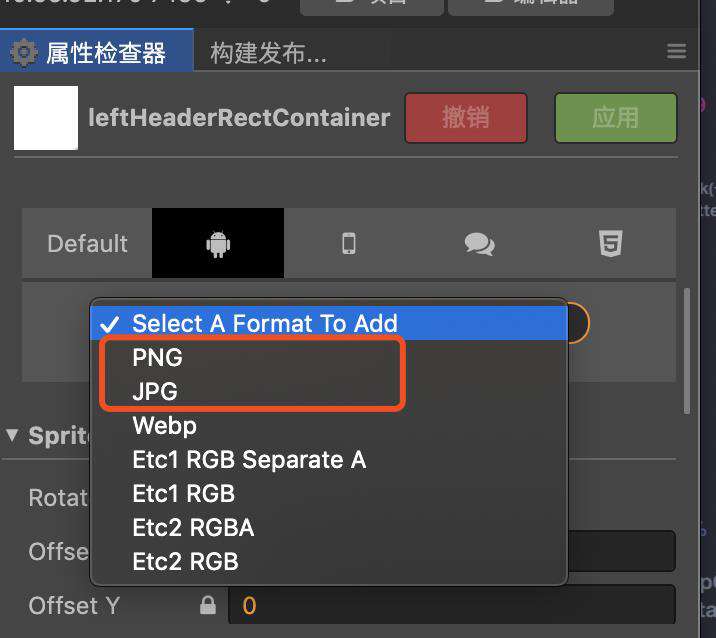
如果是 png 格式图片就 png,jpg 格式则选 jpg,选择后可以调整图片质量,图片质量越低,大小越小,失真也会越多。
资源缓存分为硬盘缓存和内存缓存。
对于原生端,资源本身是存在本地的。对于 Web 端,可以通过 http 的缓存,或者 PWA 来实现资源在硬盘的缓存。
资源还可以缓存在内存中,一般来说,游戏中会有多个场景,例如游戏中会有很多关卡,每个关卡一个场景。如果一个场景不会重复进入,那么场景资源可以不用缓存。如果场景需要重复进入,那么缓存一下,可以加速第二次打开的速度。
一般来说,硬盘的存储空间比较大,多做硬盘的存储问题不大。但是内存一般空间比较宝贵,不能啥资源都一股脑往里塞,容易造成内存占用率高,并且可能存在内存泄漏的风险,所以一般来说只缓存一些常驻的资源。
2. CPU 优化
由于游戏中需要大量的计算与绘制,本身是比较吃cpu的。所以在游戏过程中, CPU 的优化是非常重要的。如果 CPU 负载过高,会造成设备发热严重、帧率降低甚至是卡退。
CPU 是负责解析执行指令的,那么cpu高负载的原因主要就是需要执行的指令过多,尤其是一些耗时的指令。在游戏中,主要是绘制指令的调用,也就是 drawcall。还有其他的一些计算量比较大的系统,例如物理系统、碰撞系统。另外就是结点的创建与销毁,以及业务代码中一些 update 逻辑。
对于 drawcall 的优化,理想的情况是 drawcall 的次数越少越好。要了解优化 drawcall 的意义和方法,首先要知道在执行 drawcall 后, CPU 做了什么操作。
CPU 对于图形处理不太擅长,所以一般都是将图形处理丢给 GPU (Graphics Processing Unit,图形处理器)去做,这就是为什么打大型游戏需要比较好的显卡的原因,其实就是需要性能更强大的gpu。
CPU 要将数据交给 GPU 渲染,也不是啥都不用干的。CPU 需要把要渲染的数据,写入到数据缓冲区(显存),并设置渲染状态(纹理、着色器等),然后 GPU 才去取数据计算并渲染。
由于 GPU 的图形处理能力强,所以每次给一点数据和一次性给一堆数据处理速度是差不多的。但是对于 CPU 来说,如果频繁调用 drawcall,每次一点点数据,那么 CPU 就会忙得焦头烂额。所以优化 drawcall 的最有效方式就是批处理了。
批处理的方式就是合图了。所谓合图,就是将要渲染的纹理图合成一个大的图集,一次性送给 GPU 去渲染。例如有 3 个 sprite,3 个 sprite 有自己的纹理,如果不合图,那么就需要 3 次 drawcall。如果开启了合图,那么只需要 1 次 drawcall。

3 个星星图标的 sprite,显示 drawcall 是 4,为什么不是 3 呢,因为相机的背景本身需要一次 drawcall,所以星星总共需要 3 次 drawcall。

添加图集后,可以看到 drawcall 就变成 2 了,说明星星现在只需要 1 次 drawcall。

除了 sprite 可以合图,label 组件 (font) 也能支持合图。实际上,渲染字体也是将纹理送到gpu去渲染。
字体分为两种实现方式,一种是位图字体 (Bitmap font),一种是 Free type 字体。
所谓位图字体,就是将所有字符全部都打到一张图片中,这样做简单粗暴,效率也比较高,因为相当于字体都是预渲染好的。缺点是在字符集比较大时,例如所有汉字,那么字符的图片可能会比较大,内存占用率会比较高。并且不够灵活,因为图片的分辨率固定,在高分屏中,位图字体会出现一些锯齿。
另外一种是 Free type 字体,例如ttf格式的字体。不同于位图字体使用像素来表示字体,Free type 字体只是定义了字体的渲染数据,需要在运行时实时计算然后渲染。这样的字体就不存在放缩问题,但需要一定的计算消耗,所以一般需要通过缓存来优化。
对于只有数字和英文字母,并且文本结点比较多或者经常变化的情况,可以考虑使用位图字体进行优化,可以有效降低文字渲染造成的 drawcall 数。
我们来看看这样一个简单例子。场景中有 3 个 label 结点,字体的格式为 ttf 格式。
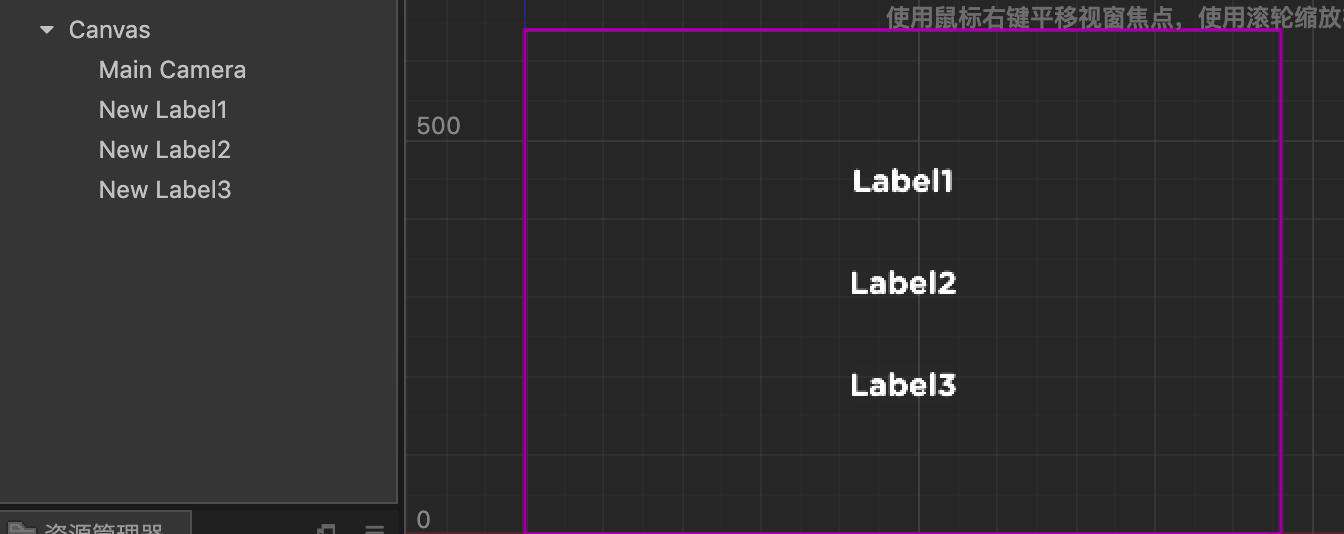
预览一下,发现 drawcall 是 4,前面提到了相机默认会有一次 drawcall,说明 3 个文本结点带来了 3 次 drawcall,如果是大量文本结点或者文本结点经常变化,将会造成大量的 drawcall。

如果我们使用 BMFont,可以看到 drawcall 立即降为 2,也就是 3 个结点只绘制了 1 次,带来的 drawcall 优化非常可观。

对于系统自带字体,Cocos 也会为每个 label 组件创建字符纹理,并且默认不参加合图。
Cocos 为 label 组件提供了类似 BMFont 的功能,我们可以使用 Cache Mode 来优化 CPU 。

Cache Mode 值为 NONE 的时候,Cocos 会为每个 label 组件的文本创建字符纹理,并且默认不参加合图。
值为 BITMAP 的时候,Cocos 会为每个 label 组件的文本创建字符纹理,但是可以参加动态合图(后面会讲到),批量绘制。
值为 CHAR 的时候,Cocos 会为字体生成一张单独的字符图集,并缓存起来。后续的新的文本,可以直接从字符图集缓存中获取,不需要重新渲染。(事实上 Cocos 官方文档对此的描述是”下次遇到相同字符不再重新绘制”,但就我的理解来说还是需要绘制的,否则为什么屏幕显示的文字会更新呢,所以应该只是复用了渲染的数据)。
相较于自动图集这种静态合图方式, Cache Mode 为 BITMAP 使用的是动态合图。静态合图的方式是在构建时生成合图,而动态合图是运行时生成合图。静态合图会减少一些运行时的消耗,但是一些动态加载图片资源没办法应用静态合图,这时候可以通过动态合图进行优化。关于如何使用动态合图,Cocos 官方文档已经讲得很详细,这里不再赘述,可以直接查看:docs.cocos.com/creator/man…
前面我们说到合图是降低 drawcall 是一种常见并且有效的手段,但是使用合图的方式会占用一定的内存,所以同时要关注内存指标。另外需要注意的是,合图之后并不意味着就能够批量渲染,参与合图的 sprite 或者 label 结点的需要是连续的。还是上面那个星星的例子,场景中有 3 颗星星,也就是 3 个 sprite,原本需要 3 次 drawcall,合图之后只需要 1 次 drawcall。我们在第一和第二个星星中间,加入一个 sprite 结点,批量渲染就会被打破:
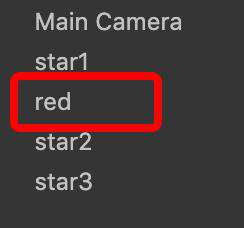

插入红色小方块后,drawcall 变成4。分别是相机背景 drawcall + 第一个星星 drawcall + 红色方块 drawcall + 第三和第四个星星的 drawcall。第一个星星本来可以和第三和第四个星星一起批量渲染的,被红色方块的渲染打断了。
我们再将小方块的位置调整一下,调到第一个星星的前面。
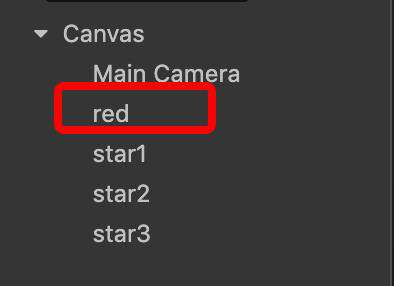

可以看到,尽管显示上没有任何变化,但是 drawcall 变成了3次。
所以,尽量让参与合图的结点连续,中间不插入其他的 sprite 类的结点,以免打破批次渲染。
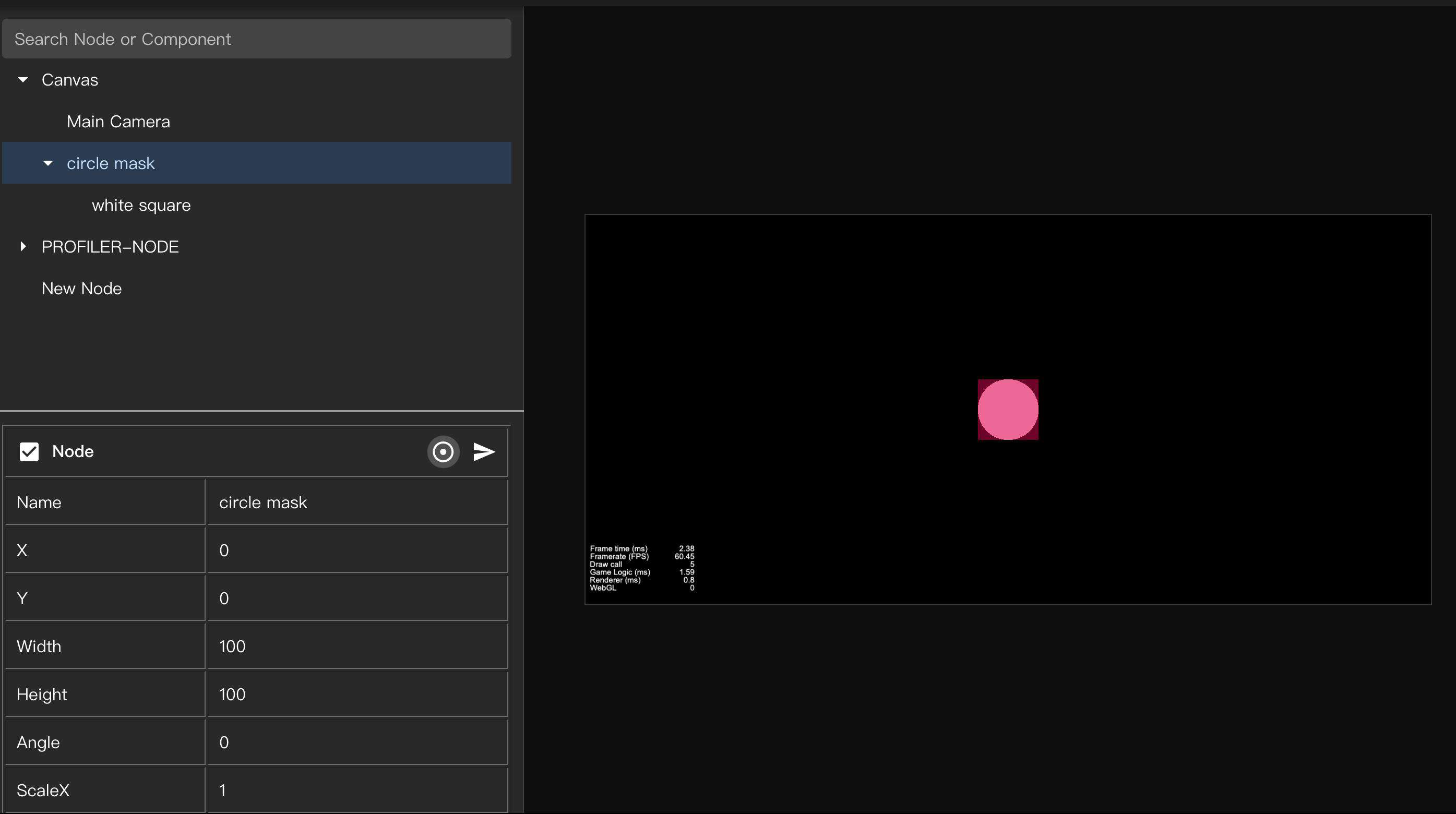
此外,mask 组件也可能是 drawcall 数量上升的元凶之一。mask 在 Cocos 中,主要是用来实现一些形状,例如圆角。
为什么这么说呢,我们来看个例子:
场景中有一个白色方块。

总的 drawcall 是 2,所以渲染方块需要 1 次 drawcall。

如果想要显示圆形,可以通过加 mask 组件来遮罩。
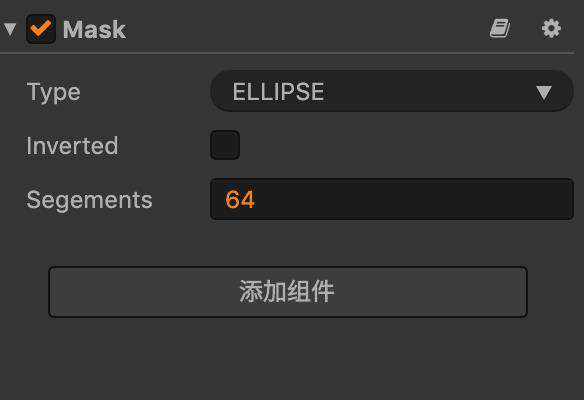
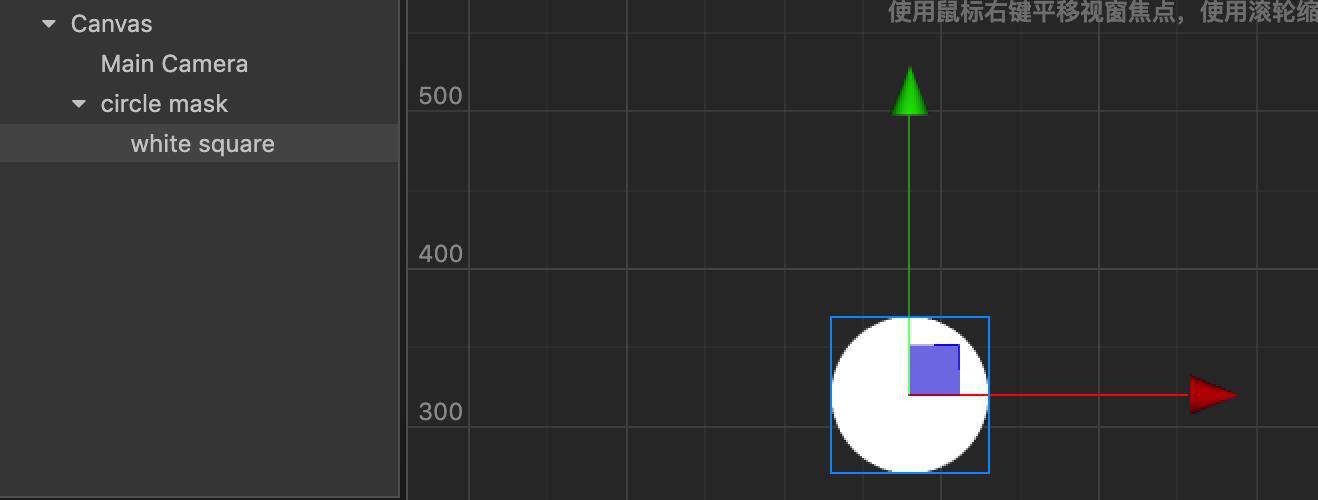

可以看到 drawcall 从 2 变成了 4,说明使用了 mask 之后,会产生 2 次 drawcall。很神奇哦,这是什么原理呢?
cocos文档中的解释是这样的:

结论就是使用 mask 组件的结点,绘制总共需要 3 次 drawcall,使用 mask 组件不能与相邻的结点合批渲染,即使它们使用的是相同的图集。所以,尽量少用 mask,如果要实现圆角等效果,结点的尺寸也比较固定,可以让设计同学直接给图。
当然如果你和我一样想细扣里面的细节,什么是模板缓冲?为什么一定要 3 次 drawcall ?可以看接下的详细解释,需要一点 OpenGL 知识,如果不想深入细节可以直接跳过:
-
什么是模板测试?
模板测试其实就是通过模板缓冲区中的设置,来决定某些区域要不要渲染。
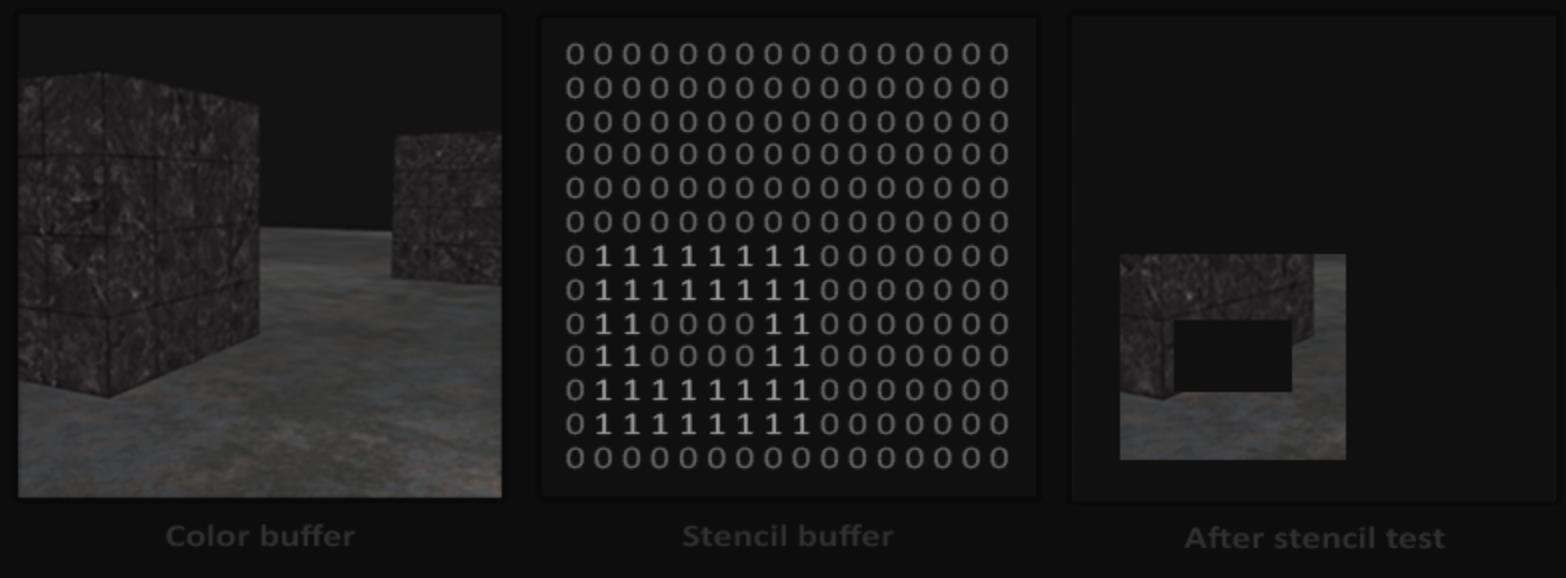
详细学习请见:[learnopengl-cn.readthedocs.io/zh/latest/0…learnopengl-cn.readthedocs.io/zh/latest/0… Advanced OpenGL/02 Stencil testing/)
-
使用 mask 组件的结点渲染三步骤
可以通过spector.JS来查看渲染帧信息。这是圆形渲染相关的三个帧:
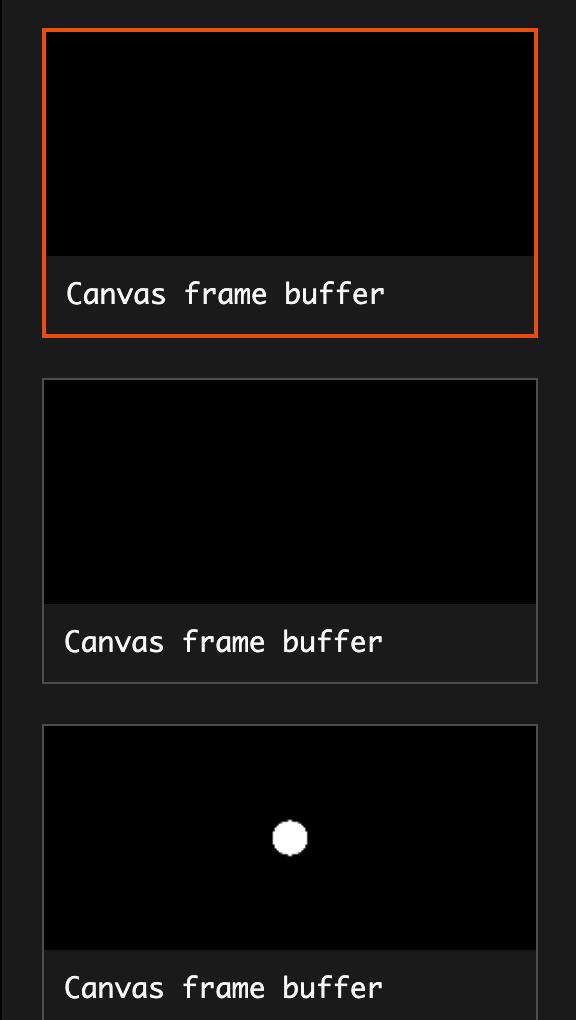
第 1 帧渲染:
渲染命令如下,意思是通过 6 个顶点画出 2 个三角形,实际上就是原本的小方块。

但是实际上这里并没有将小方块真正渲染出来。
模板缓冲状态为
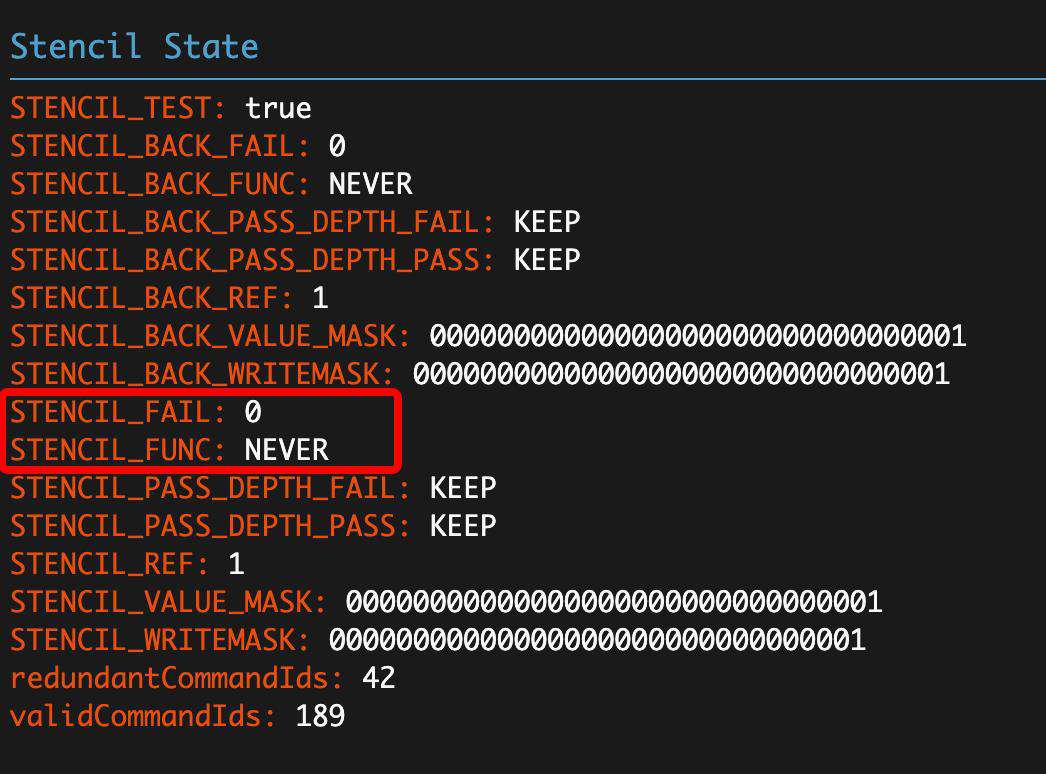
这里的意思是将小方块区域对应的模板缓冲区位置的值直接置为 0,也就是刷新该区域的模板缓冲区。
第 2 帧渲染:
渲染命令如下,意思是通过 186 个顶点,画出 n(很多)个三角形,其实就是画出圆形,因为在 OpenGL(Webgl)中,各种形状都是通过三角形去拼出来的。

模板缓冲状态为
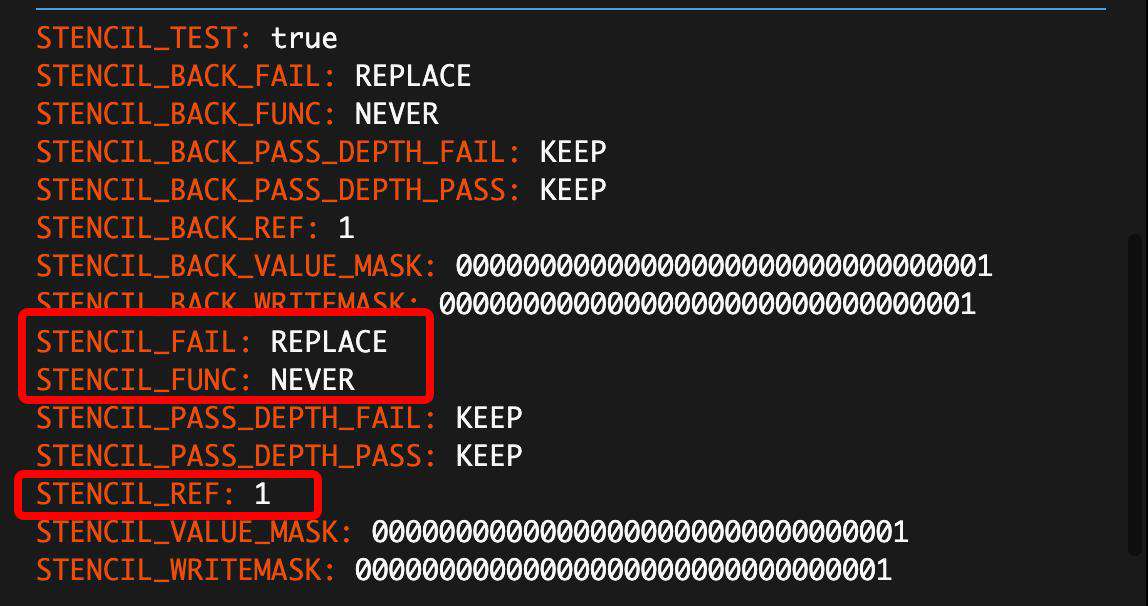
直接将圆形遮罩对应的模板缓冲区位置的值设成 1。
第 3 帧渲染:
渲染命令如下,与第一帧一样,都是渲染出小方块,这次会将方块渲染出来。
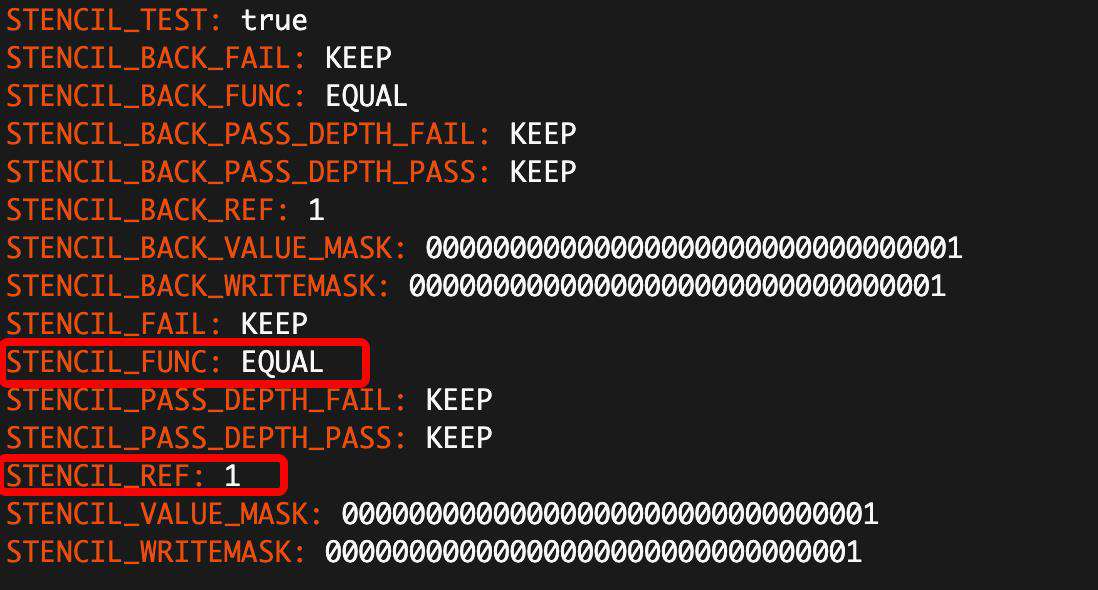
模板缓冲状态如下,意思是只有缓冲区对应位置的值为 1,才会渲染出来,所以方形被遮罩出了圆形。
除了 drawcall,一些逻辑计算也会影响cpu的使用率。例如 widget 组件的计算时机:
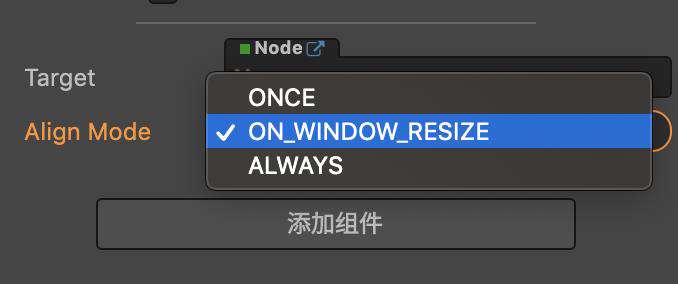
如果选择了 ALWAYS,那么每一帧都会重新计算结点的位置、大小,所以比较耗计算。可以只选择 ON_WINDOW_RESIZE,只在窗口大小变化时,才会重新计算。如果还需要在其他时机计算 widget,可以按需手动调用 widget.updateAlignment。
另外,由于 update 这个生命钩子在每一帧都会调用,所以也需要注意在 update 中的逻辑是否执行过于频繁,例如不停地打 log,或者不停地计算,都会影响 CPU 的性能。
结点的创建以及销毁也是比较耗费性能的,所以要避免频繁地进行结点的创建和销毁操作,并且应该尽量减少结点的数量。
由于 Cocos 在 Web 中通过 canvas 进行绘制,没办法使用浏览器的开发者调试工具去查看结点,这里推荐一个 Cocos 插件 ccc-devtools,github 地址:github.com/potato47/cc…
如果发现结点数量过多,并且结点频繁创建销毁,例如游戏中的小怪、子弹等数量比较多的重复物体,通常可以通过回收工厂进行优化。回收工厂就是结点用完之后,不销毁,而是缓存起来,下次获取结点可以直接复用缓存中的结点,而不需要重新创建。Cocos 本身提供了回收工厂的接口 NodePool,可以了解一下:docs.cocos.com/creator/man…
游戏中的碰撞检测,也会比较耗性能。我们可以尽量使用box或者circle碰撞器,而少用多边形碰撞器。
3. 内存优化
游戏中比较占用资源的主要是资源的缓存,例如图片资源缓存。而资源分为静态资源和动态资源。
静态资源指的是,场景一开始进入时便立即加载的资源。动态资源是指在场景中异步加载的资源,例如一些网络图片、音频等通过 cc.loader.load 或者 cc.loader.loadRes 加载的资源。
我们可以通过 cc.loader._cache 查看当前场景下面的资源列表
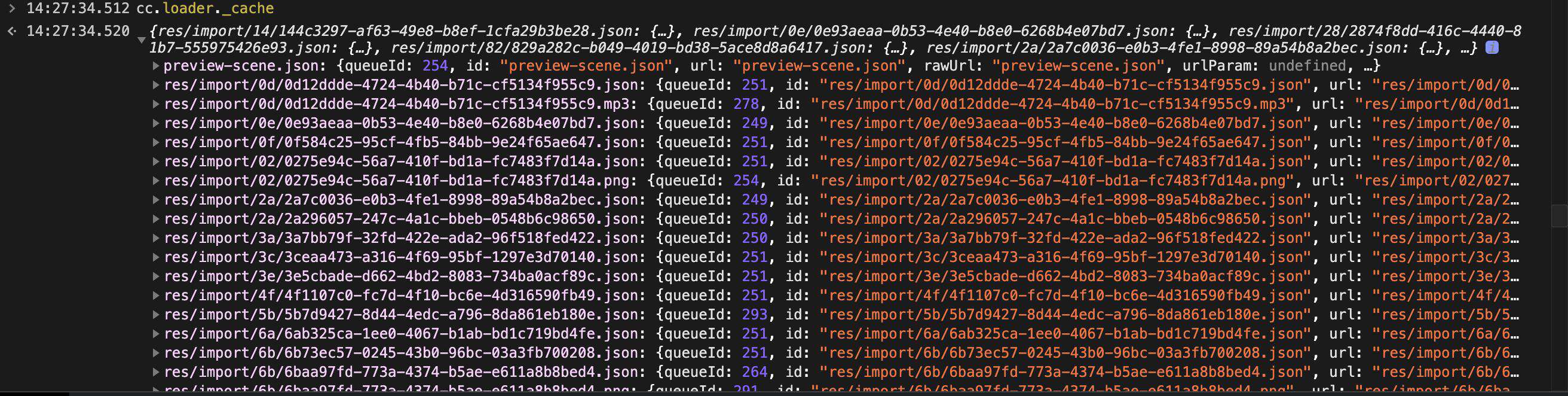
也可以通过前面提到的 ccc-devtool 可视化地查看资源列表,并且还能看到纹理资源的大小:
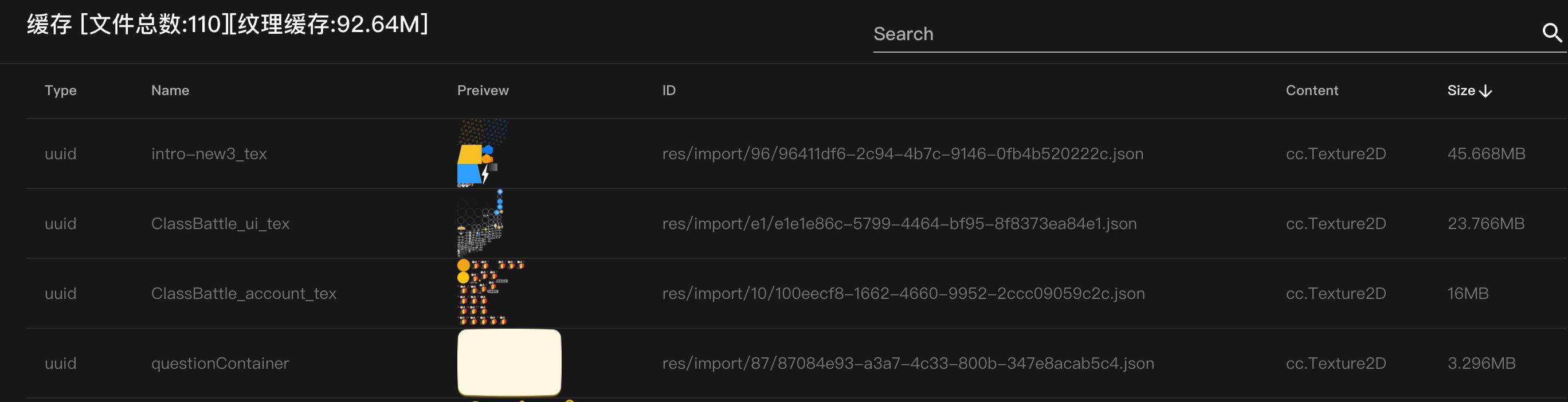
注意到一张图片在内存中是比存在磁盘中要大很多的,因为在图片存在磁盘中时,是经过编码的,例如使用 png 和 jpg,数据量会小很多。但是存在内存中时,是解码成像素值的,所以需要占据的空间比较大。
内存要降下来,也无非两种方式,一是减少不必要的资源、二是资源压缩。
减少不必要的资源,例如:场景中的背景图,在移动端中是一套,在 PC 端是一套。那么应该是通过代码判断是什么平台,然后再动态加载对应资源的方式实现,而不是在场景中同时放置移动端和 PC 端的背景,然后控制显隐的方式实现。这样可以减少一套资源的内存占用。
对于背景,一般来说由设计直接给图会比较大,如果是只是纯色或者通过简单的背景重复或者变换可以实现,可以由开发来实现,这样可以把大背景图优化掉。
另外,合图的时候我们注意只将比较相关的图片进行合图,否则意味着可能加载一整张合图,只是用到其中的一个小图,会造成很多内存空间的浪费。
资源压缩,主要是指对图片资源的压缩,也称纹理压缩。
单纯使用 tinify 等工具,对图片大小进行压缩,如果不改变图片尺寸,是不会减少图片资源在内存中的体积的,只能减小图片在磁盘中的存储体积。对于分辨率要求不高的资源,可以使用2倍图或者1倍图,可以减小资源在内存中的体积。
纹理压缩算法,例如 Etc1, Etc2, PVRTC 等,可以优化图片在内存中的体积。jpg 和 png 格式虽然能够对图片数据进行压缩,但是并不能被gpu读取,所以是需要 CPU 解码之后再给到 GPU 渲染的。而经过纹理压缩算法压缩后的数据,是能够直接给gpu渲染的,所以纹理压缩不仅能够优化内存,还能优化 CPU。
需要注意的是,纹理压缩一般都是有损压缩,可以选择压缩率。另外,纹理压缩的算法依赖于设备的 GPU 能否解码,所以针对不同的平台,需要使用不同的纹理压缩算法。
关于纹理压缩算法的介绍,推荐看这篇文章:zhuanlan.zhihu.com/p/237940807…
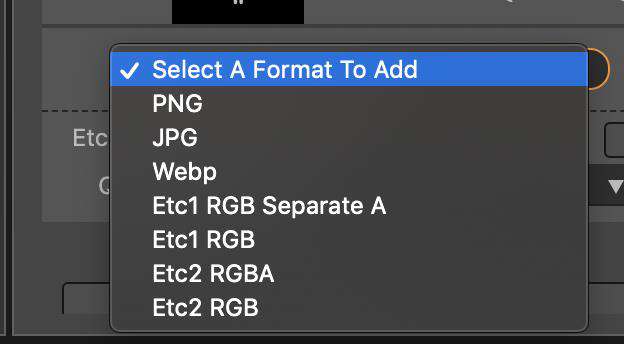
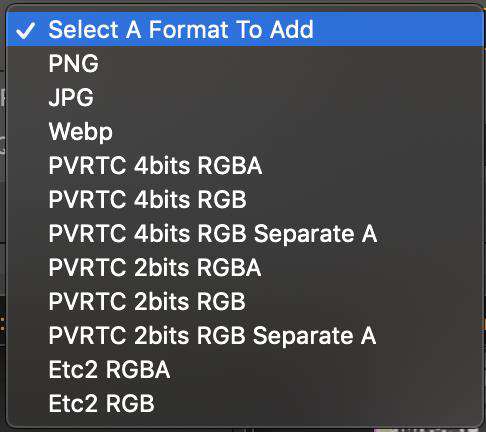
Etc1 绝大部分的安卓设备支持,PVRTC 所有的 iOS 设备支持。
如果图片不需要支持 alpha 通道,安卓选择 Etc1 RGB、iOS 选择 PVRTC 4bits RGB 即可。如果需要支持 alpha 通道,安卓选择 Etc1 RGB Separate A,iOS 选择 PVRTC 4bits RGBA Separate A。
对于不用的内存,我们也要及时释放,防止内存泄漏。分自动释放和手动释放两种。
对于静态资源的释放,可以通过勾选场景自动释放选项来实现:

这样在场景切换后,场景中的静态资源就会被自动释放了。
如果不想等到切换场景才释放静态资源,也可以使用 cc.assetManager.releaseAsset 进行手动释放。
有一个坑点是,动态加载的资源无法在场景切换时,跟随静态资源自动释放。需要通过 cc.setAutoReleaseRecursively 手动设置一下:
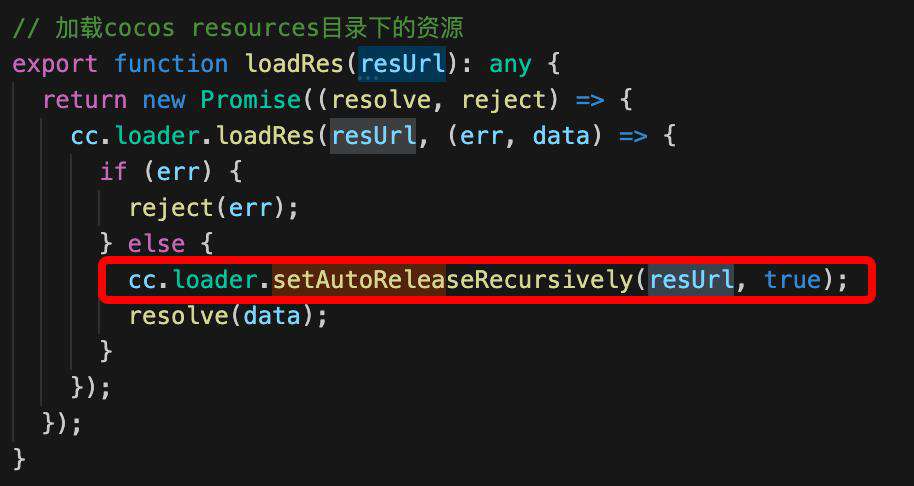
这样资源在场景切换时,会自动释放这部分动态加载的资源。也可以通过 cc.loader.releaseRes 手动释放动态加载资源。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!