前言
本文来自 2020年4月25日,前端早早聊第五届“前端搞监控”专场分享嘉宾 - 钉钉前端团队监控负责人 烛象(slashhuang) 的分享实录《钉钉前端-如何设计前端实时分析及报警系统》。
正文开始
大家好,我是来自钉钉的烛象,我今天的题目是《钉钉前端团队如何打造亿级流量的监控系统》。

个人介绍
首先来个我的个人介绍。我是 2013 年毕业,2017 年来到钉钉的,入职钉钉的时候是 P6,然后通过做前端监控、做一些模块化代码包、效率等工具,顺利的得到了一些晋升的机会。

关于钉钉前端
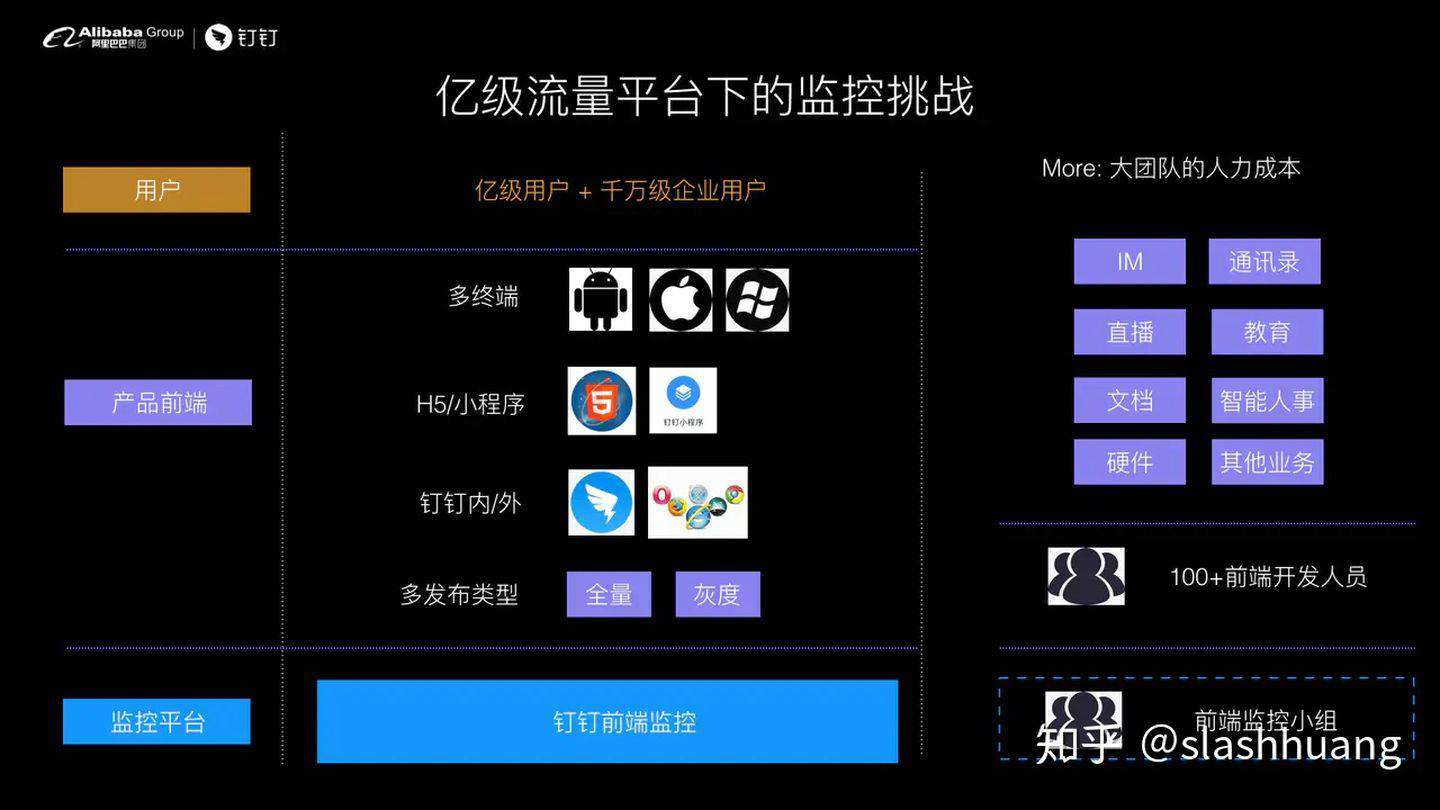
钉钉从 2014 年底创业至今,发展极其迅速,钉钉前端监控也在相应的演进。我们有亿级的用户和千万级的企业用户,前端产品有安卓、iOS、桌面端、小程序、 H5等,前端应用的发布也涵盖全量发布、灰度发布的情况。
亿级流量的挑战
对于这样一个亿级平台,除了做前端监控系统之外,我相信很多小伙伴也有体感,要保证整体钉钉前端的稳定性,还需要有一些技术运营的手段,包括人的一些情况。我们现在整体有 100 多个前端开发成员,然后我们的技术模块上面有 IM、通讯录、直播、教育、文档、硬件等等非常具有 B 端属性的业务。
成果
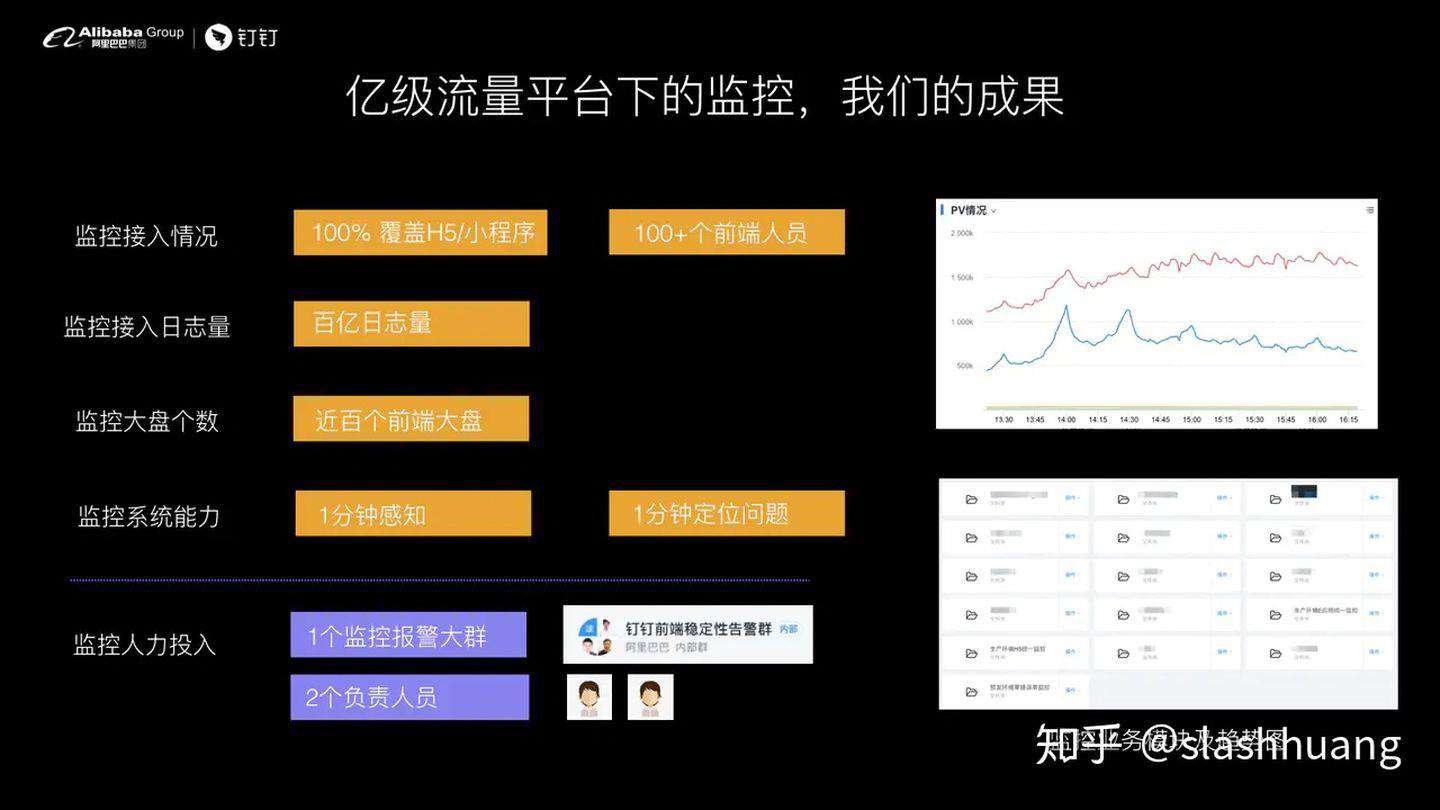
我先说一下我们的成果: 100% 覆盖了我们今天所有的 h5 和小程序、支撑了 100 多个前端人员的监控需求。前端监控的日志量达到百亿,监控大盘个数超过 100 个,能做到线上问题一分钟感知和一分钟模糊问题定位。在人力投入上面,始终维持在两个负责人员以内,大部分情况下是我一个人为主在负责整体的一个监控情况,所以在人力投入上面,我们的成本是相对比较低的。
上图中的两张趋势图是我们监控的主要产品结构,一张是我们的监控趋势图,另一张是我们的业务大盘文件夹用于承载各个业务,同时,我们有一个生产环境的统一小程序、H5 监控大盘。
演进之路

接下来我会讲一下,关于钉钉前端监控,我们是如何对系统进行演进,拿到一个不错的结果。
考虑到有很多小伙伴们不是搞前端监控的,所以这边我会先讲一些基础知识来展开如何设计一个前端监控系统。
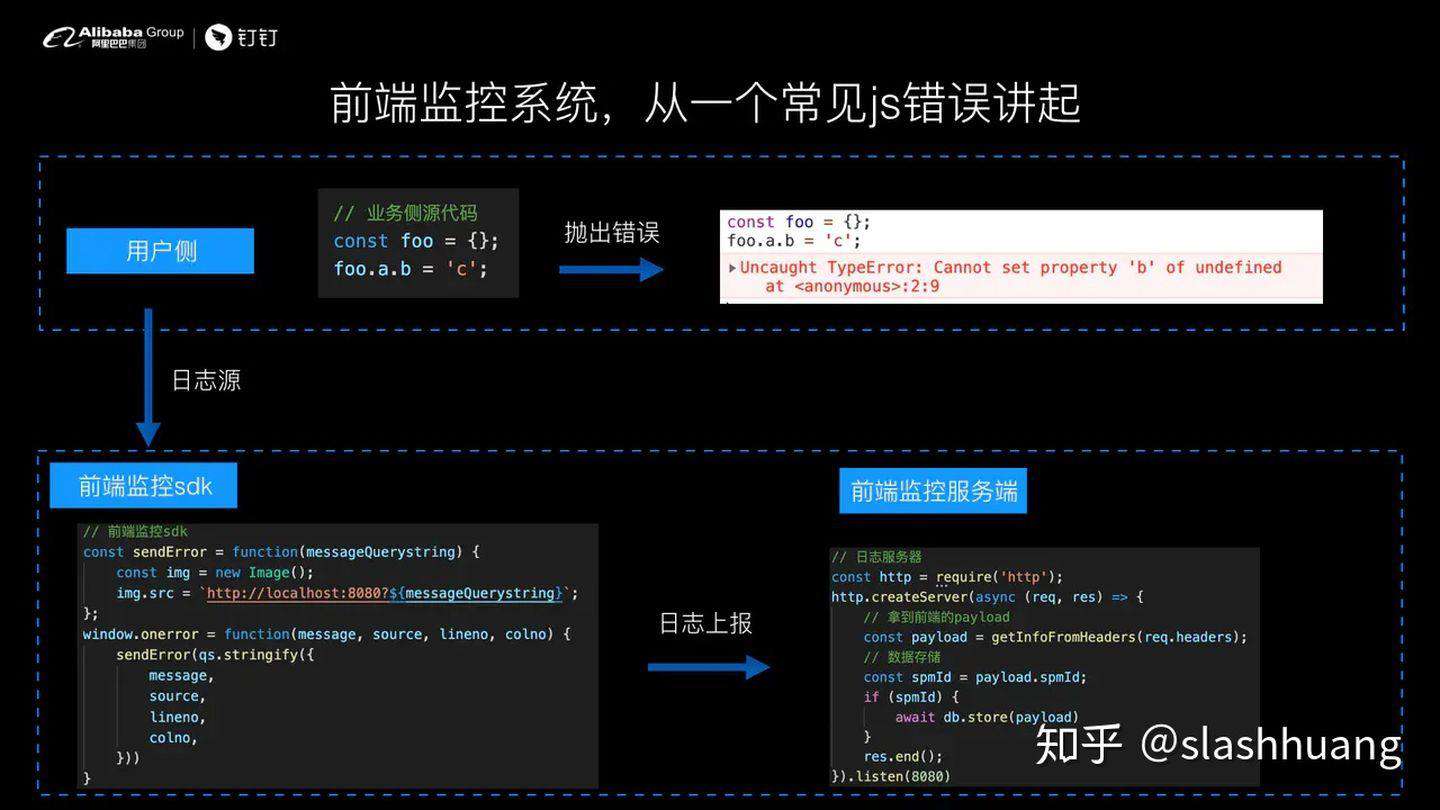
我们来看一下上面这段代码,const 创建一个对象,然后 foot.a.b = c。可以看到这是段非常经典的 NPE 代码,就是 null point exception,在前端代码中非常容易出现。这边会抛出一个错误:** Uncaught TypeError: Cannot set property 'b' of undefined**。
对于这样一个错误,在用户侧发生之后,我们的前端监控系统是怎样去捕获这个错误,并且在一分钟之内发现?我们来看一下一传统的做法是怎么做的:
- 首先写一个前端监控 SDK,用于进行数据采集
- 选型一个通知方案,将这条前端日志通知到服务端
我这边演示的是用 image 标签,创建一个 image 标签,设置它的 src 指向对应的日志服务器来发送对应的日志。
我们对错误的采集采用的是 window.onerror 来捕获全局错误。然后将捕获的错误通过创建 image 标签形式发送到上图右侧的前端监控服务端。
如上的代码只是一个伪代码演示,我写的比较简单。
对于一个传统的基于日志分析的监控系统,你首先要知道这条日志到底是来自哪里,所以我们对每一条日志在前端采集的时候,都有一个应用 id,姑且我这边称之为 spmId ,通过 spmId 来标识日志源,然后将这条日志存储到对应的监控服务端,这样就完成了一个非常简单的从前到后的一个链路。
从日志发生、采集,然后再到存储的一个闭环,非常简单。其实见微知著,看到这么一个简单的实现,再把日志类型进行丰富,采集和存储做的强大一点,基本上就可以去搭建一个比较简单的前端监控系统了。
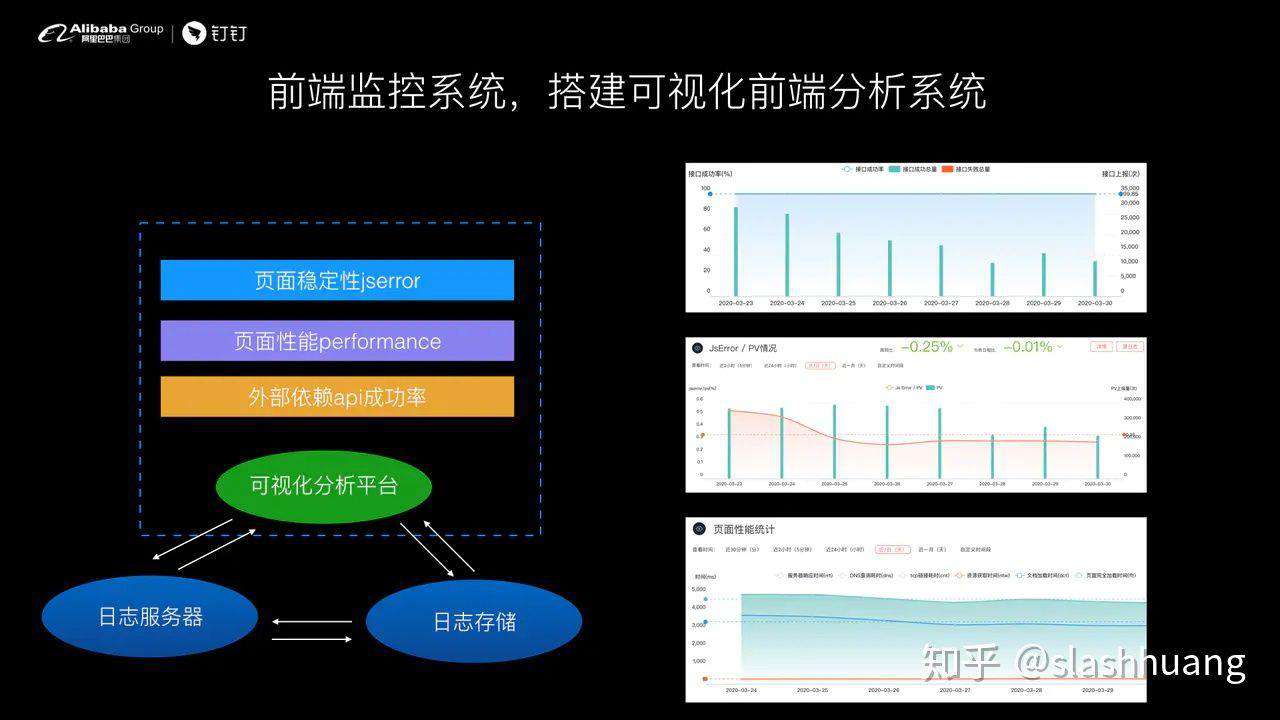
一般而言,一个简单的前端监控分析系统需要包含如下三个维度:
- 第 1 个是稳定性相关的 js error
- 第 2 个是性能相关的 performance
- 第 3 个是 api 成功率相关的
在监控平台,我们需要做一些日志存储,将监控日志提供给可视化平台服务器,通过提供一些 API 服务就可以画出上面这样一个图。比如第 1 个是接口成功率。
我觉得在技术选型上面,对于很多稍微有点 Node 或者服务端基础的前端同学来说,基本上能做出一个简单的 Demo。然而,这样一个看似功能很完备的系统,对于做前端监控来说,有没有什么问题?是不是能够满足钉钉这样一个亿级流量平台的监控需求?
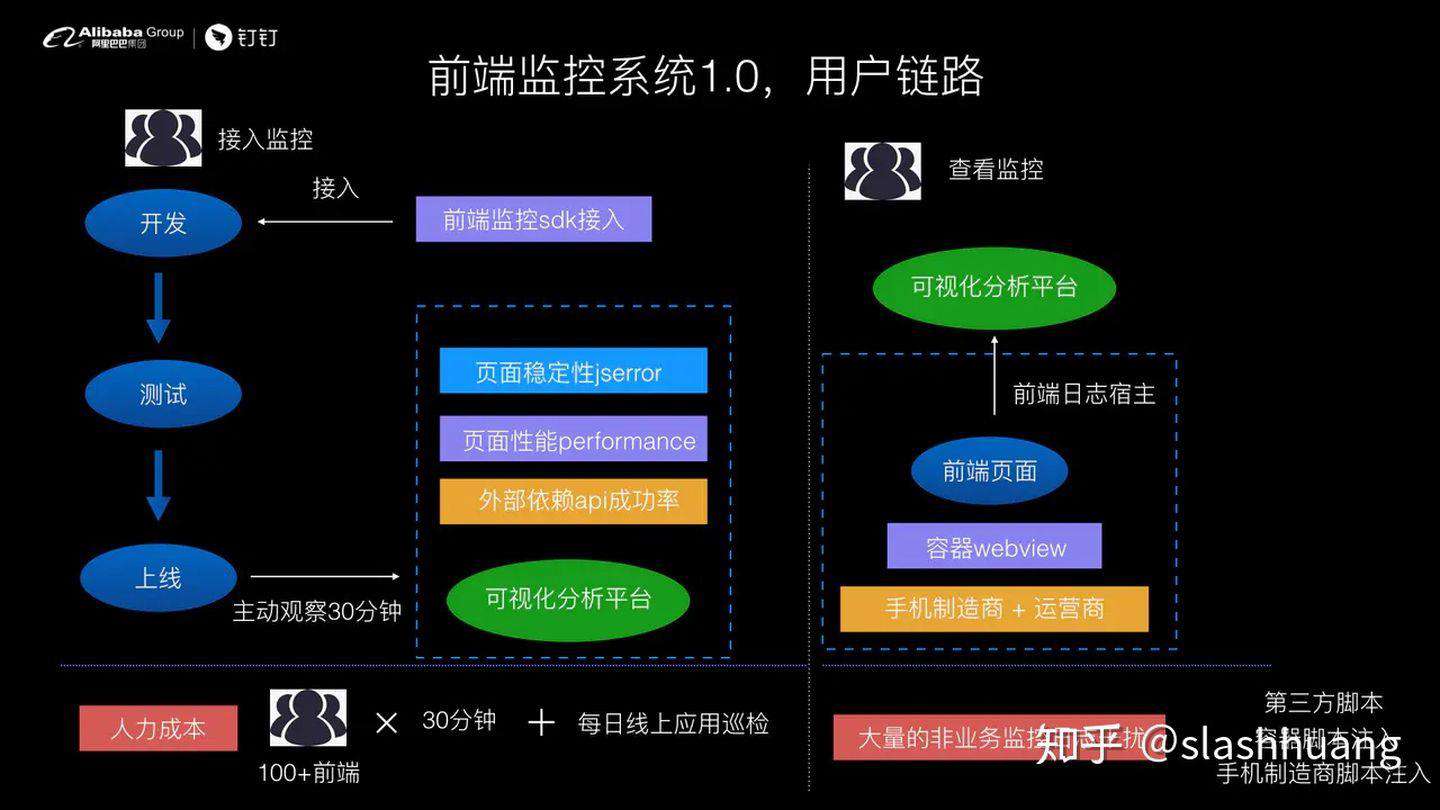
上图左边展示的是我们的开发人员接入前端监控的过程,包括开发阶段、测试阶段、上线阶段。 在前端监控推行的过程中,我们要求所有的开发人员在应用迭代上线后,要主动观察监控大盘至少 30 分钟,观察三个指标:
- js error
- performance
- api 成功率
对于目前我们 100 多个前端同学的团队规模来说,人力成本是 100 乘以 30 分钟,同时对于钉钉这个企业级产品而言,我们对线上的稳定性要求是非常高的,对线上故障容忍度极低,因此还要求每日对线上应用进行巡检,因此人力成本非常高。
从开发人员的体验角度看,一个开发人员查看监控的时候:第 1 个他会去可视化分析平台上去看有没有错误日志。这边有一个非常重要的点,就是说我们监控分析平台看到的日志,是不是"前端页面"的日志?
不一定是。为什么?因为对于用户来说,它不仅仅是打开了前端页面,这个前端页面背后还有容器的 webview、应用容器、运营商等。
举个例子,我们一个页面可以在微信的容器里面打开、可以在头条的容器里面打开、可以在钉钉容器里面打开。所以你采集的日志源不仅仅是一个前端页面,还有容器的 webview,同时我们还会面临很多的运营商。比如说我们经常看到前端页面里插了一段广告,然后我们还有一些手机的制造商,比如vivo、华为等,也会在我们的页面里面插入相关的脚本。所以监控分析平台采集到的日志不仅仅是前端日志,他采集到的范围实际上是前端页面对应的用户终端日志。
一般我们会碰到如下三种干扰日志:
- 第 1 个是第三方脚本注入
- 第 2 个是容器脚本的注入
- 第 3 个是由手机制造商脚本注入
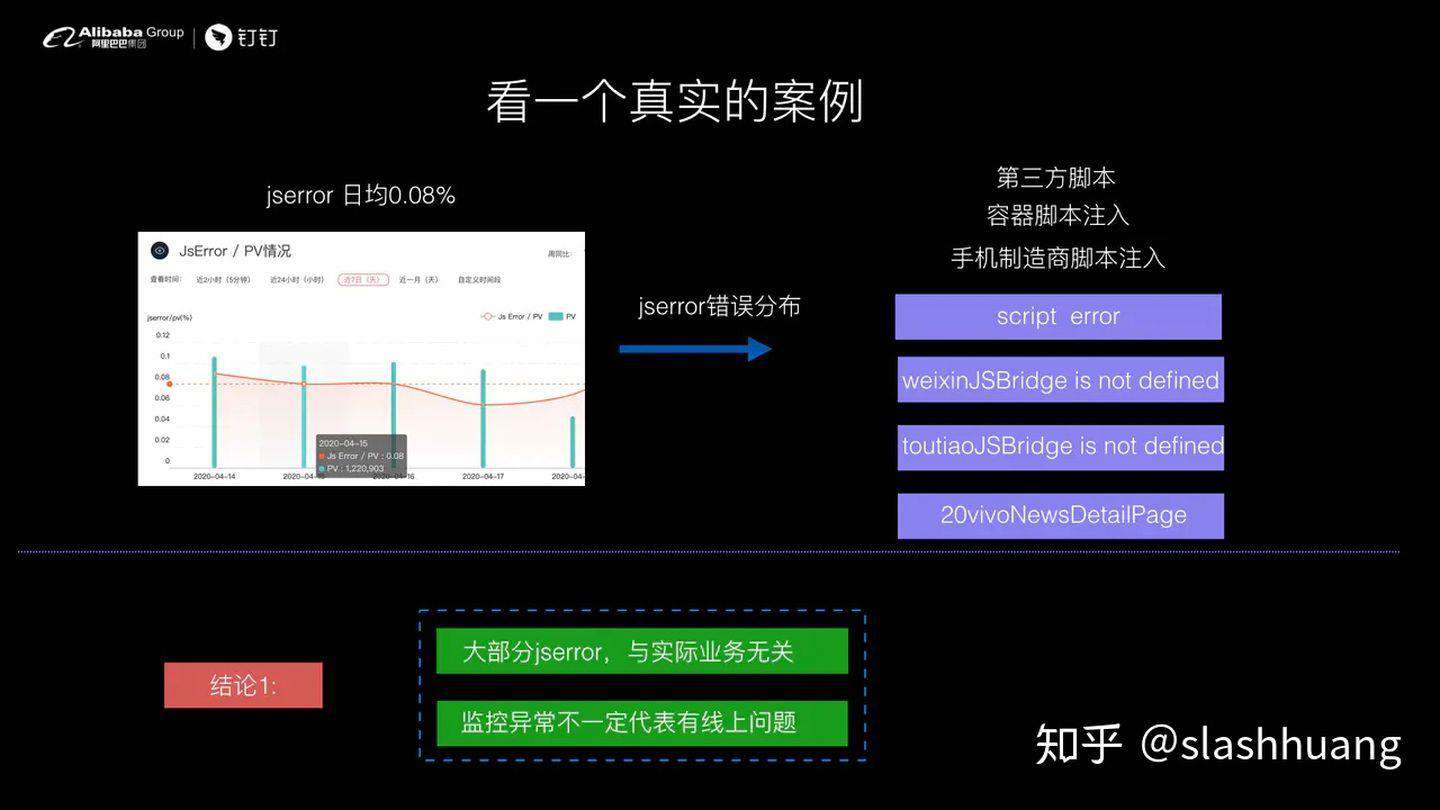
举个例子,如上是我们线上的一个应用,大概 js error 率是 0.08%, 对于钉钉这样的体量来说,这个错误率影响用户的数量已经非常大了。
我们来看一下它对应的错误实际上是什么?Script error,WeixinJSBridge is not defined, toutiaoJSBridge is not defined, 20 vivoNewsDetailPage,这些东西从错误信息基本上可以判断跟业务错误基本没啥关系。
所以我们可以得到第 1 个结论,就是前端监控产生的一部分错误实际上跟业务无关,这个可能跟很多人的认知是相悖的。
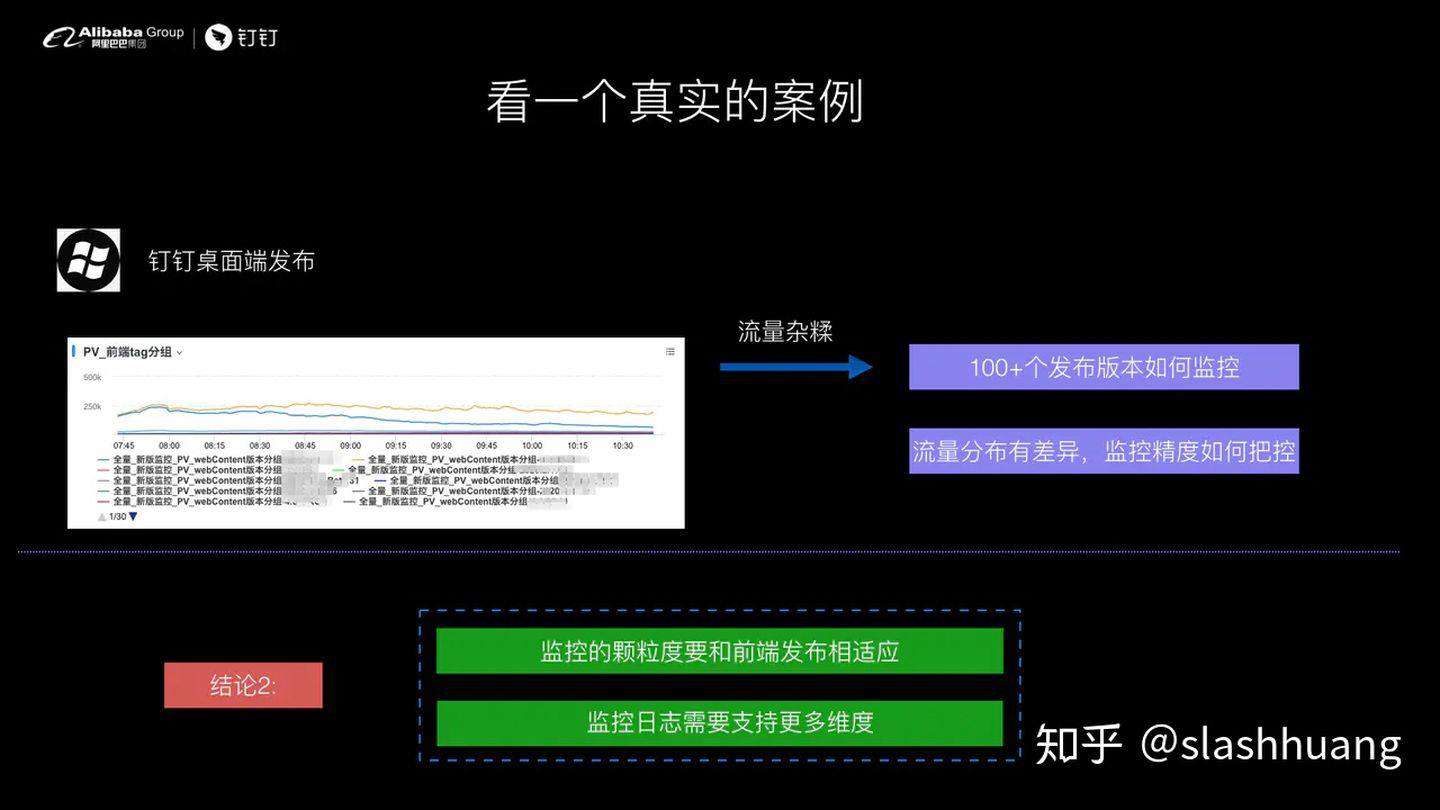
我们再来看一个问题,左图是我们桌面端的发布曲线,钉钉是国内甚至是全球为数不多的非常重桌面端的平台。钉钉桌面端基本上是一个礼拜或者两个礼拜一个迭代,由于桌面端的前端代码是采用离线包的形式,因此代码的更新修复是比较困难的,对前端稳定性的要求非常的高。
对于我们今天的桌面端而言,已经有 100 多个线上发布版本了,这么多的版本上报的日志采用的是同一个应用id,我们如何去做分层监控,线上流量的不均如何做好分层监控,避免小流量的发版监控被淹没?
这些问题在钉钉的业务场景是经常碰到的,我们的监控颗粒度需要和前端的发版相适应,并且监控的日志需要支持更多的维度。比如说以应用和发布版本,这两个变量为单位进行监控。
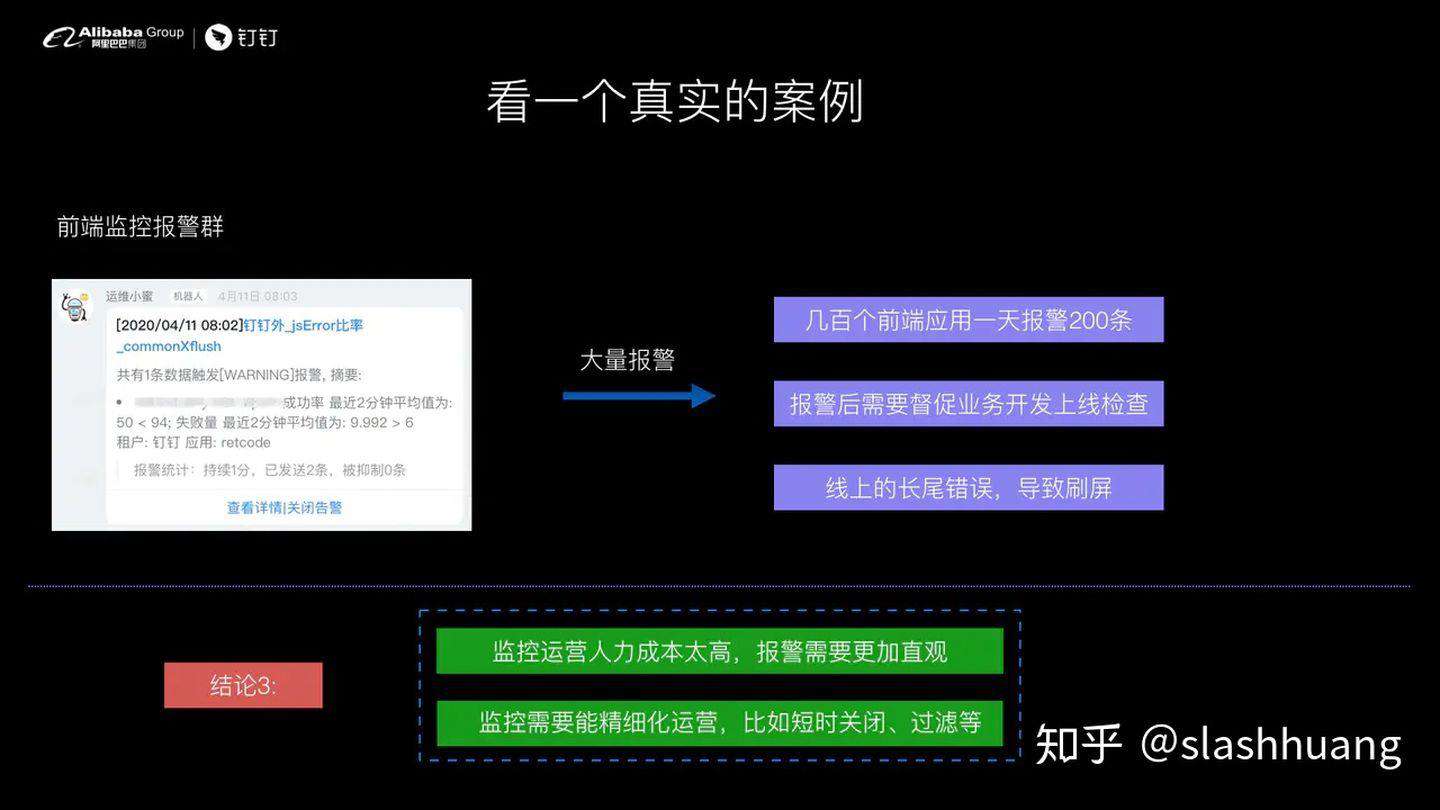
我们再看一个案例,钉钉有几百个前端应用,每个应用报警 1 次就非常夸张了,基本上一天报警群就有 500 多条日志,刷屏现象非常严重,而且很多错误是线上的长尾错误。也就是它虽然有报警,但是不需要去修改等等。长尾错误出现的原因是我虽然修复了问题,但是用户那边不一定完全访问的是最新的版本。
所以结论 3 就是我们监控运营的人力成本非常高,对于前端监控的要求不仅仅是要报警报出来,还需要你的报警是直观的、实时的,同时要支持一些短时关闭和错误过滤等等手段。
看完上面这三个案例后,我们来看一下究竟该如何设计一个能够服务 3 亿体量的监控系统。
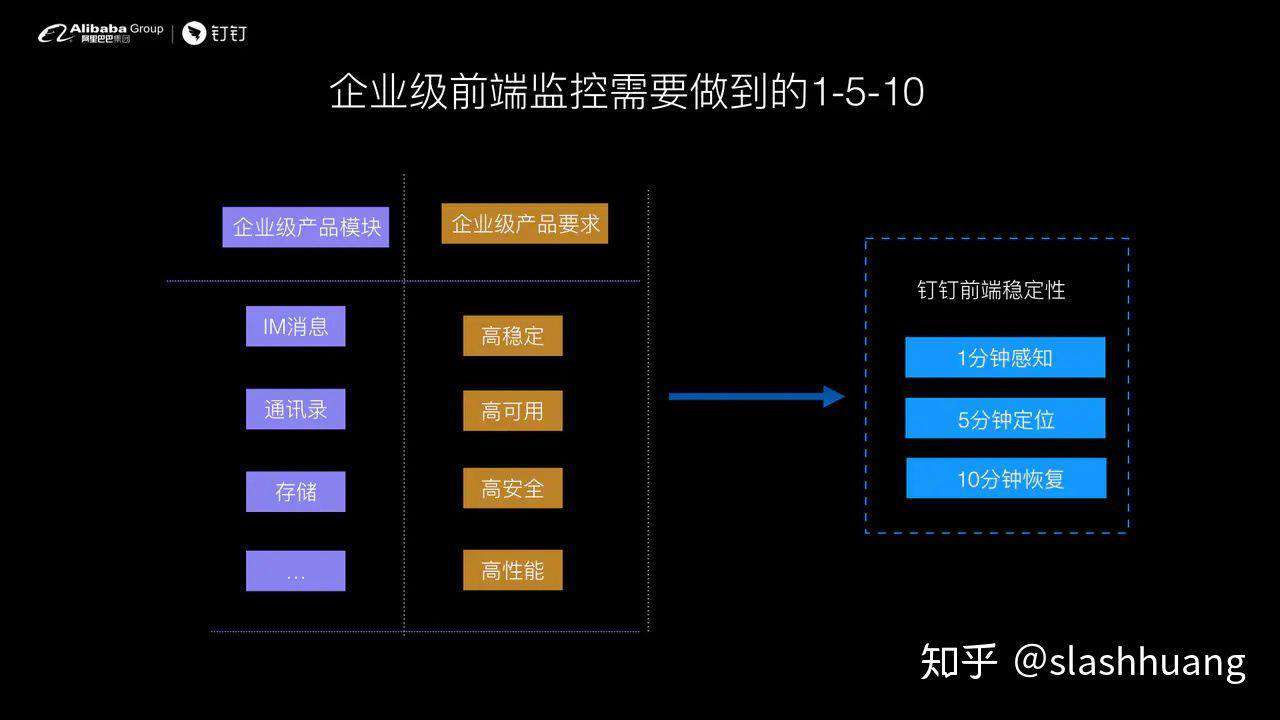
首先,我们先界定监控设计的目标,钉钉企业级前端监控需要做到的事情是: 一分钟感知、5 分钟定位、10 分钟恢复。姑且称这个监控系统为 2.0 系统。
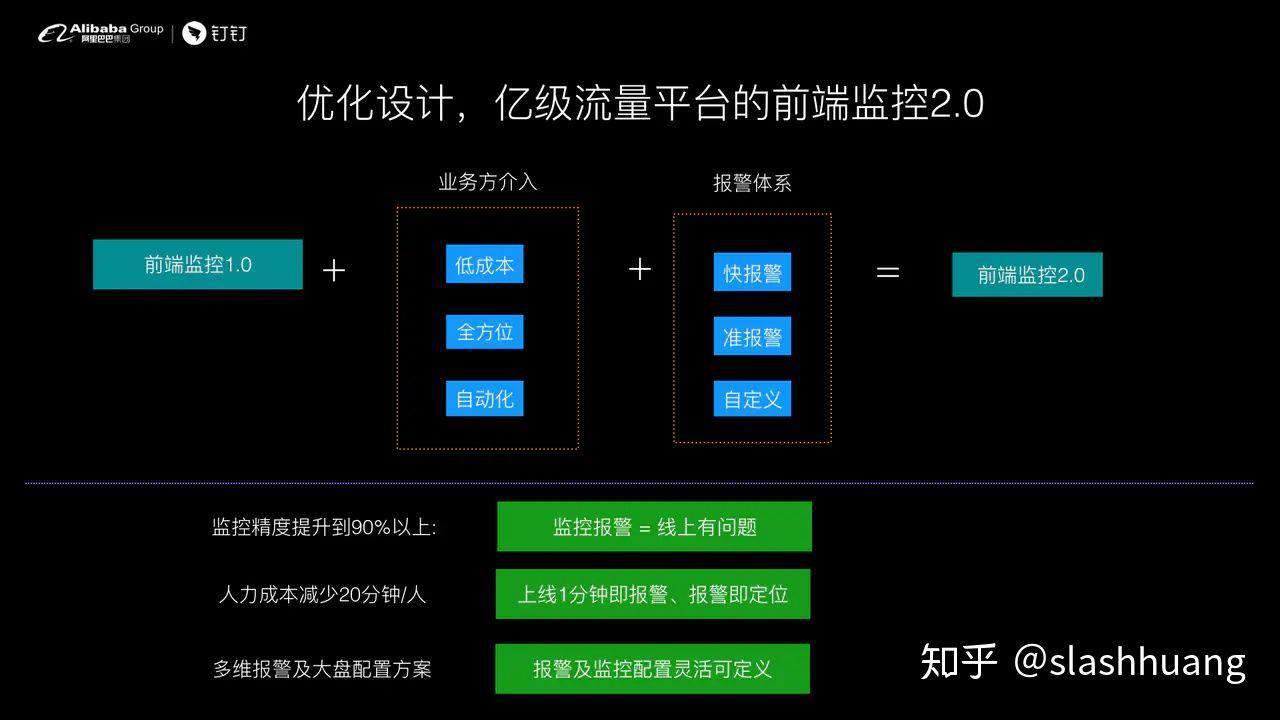
我们对于前端监控 2.0 在 1.0 的基础上定义了如下的能力水位。
第 1 个是要贴近实际业务,降低人力运营成本、业务方能够低成本介入。同时对于报警体系,要求做到快报警、准报警,并且支持自定义报警。我们内部定了一个基准线,就是前端监控精度必须达到 90% 以上,人力成本必须减少 20 分钟每一个人,并且报警和大盘需要能够支持自定义配置。

上图是整体的监控的组件编排方案。左边是一个图例,蓝色部分代表的是 1.0 的监控组件,墨绿色的部分代表 2.0新增的监控组件。
自定义采集
第 1 个在日志采集端,除了采集常规的业务数据和监控数据之外,支持自定义采集。
分析智能化
分析智能化这一块增加了分析可自定义的能力。
报警实时化
在报警实时化这一块,增加了线上1分钟报警和5分钟定位的要求。
最关键的技术实现
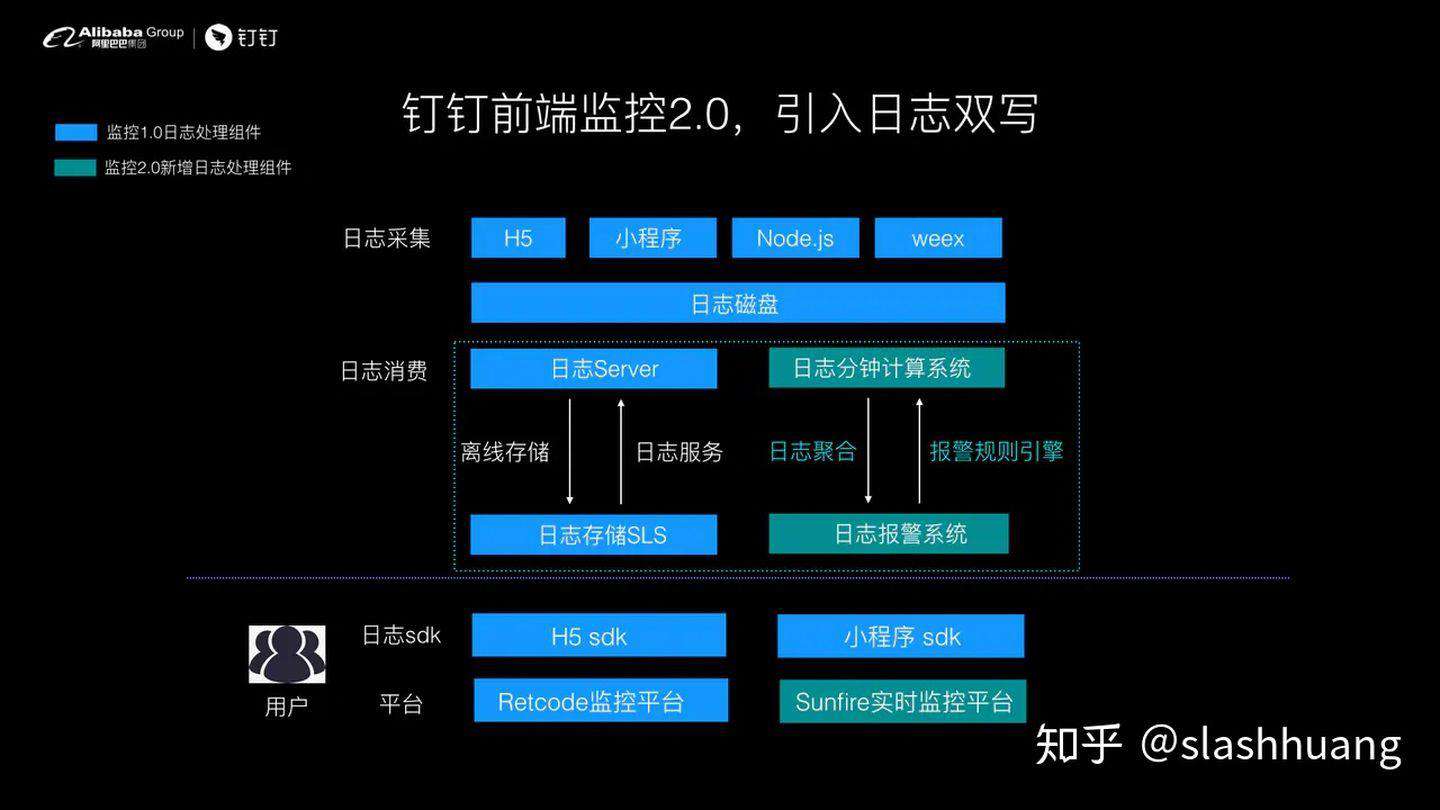
同样,蓝色部分是原有的 1.0 的一个体系,墨绿色部分是我们新增的体系。我们会发现在日志采集在和日志消费端,我们增加了一个模块叫做日志双写。
一份日志被两个系统所消费,一份系统用于实时去报警,一份系统用于去做分析:
- 服务器拿到日志后,一块去做存储分析以便做一些监控报表服务;
- 第二块引入了日志分钟计算系统去做实时的报警。
很多同学会觉得日志双写其实是一个非常大的系统的浪费,一份日志被两个系统所消费了。实际上钉钉前端监控借助了阿里非常成熟的日志消费系统和基础设施。通过日志分发两路被快速消费,让分钟计算系统在整个监控体系里面的编排是前置的,达到 1 分钟报警的要求,这是我们在这一块里面最核心的一个技术思路。
在上图的紫色虚线下方,是我们的用户视角。用户侧触碰到的是两块,第 1 块是前端监控 SDK,我们有 H5 和小程序的 SDK,第二块是平台,包括分析平台和报警平台。
真实案例
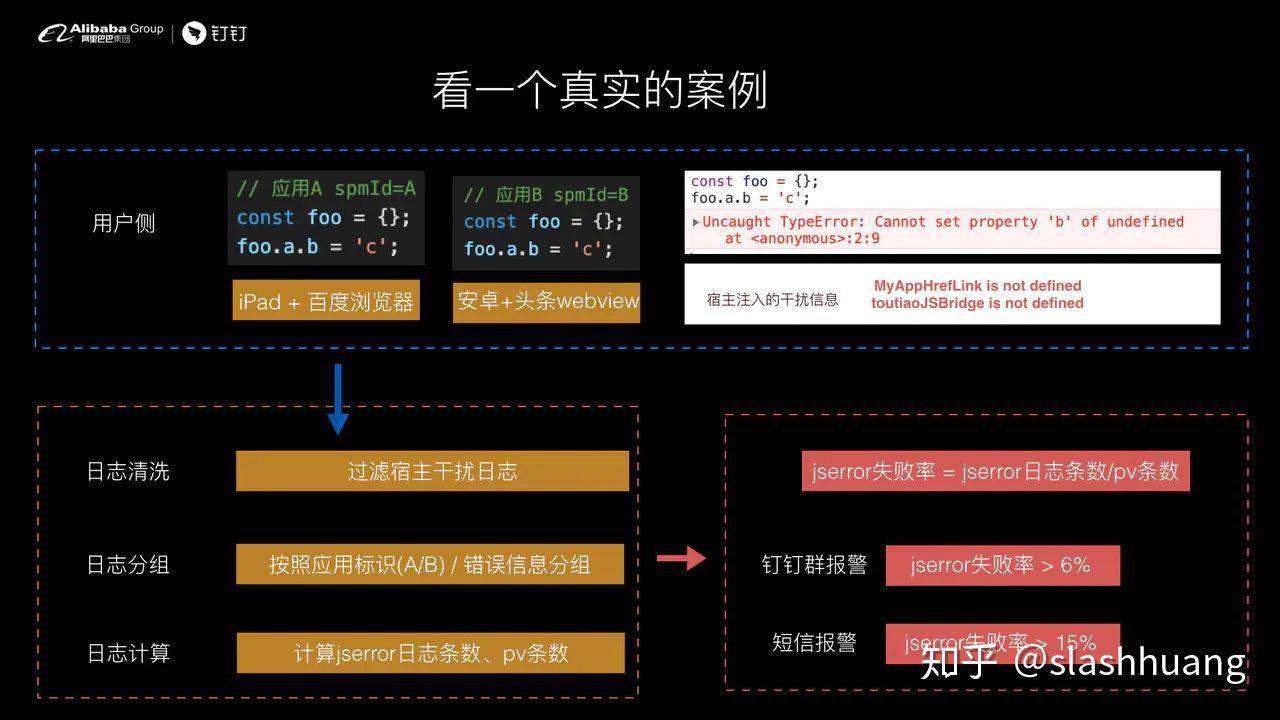
我们来看一个真实的案例。用户碰到了两个 js error 。这两个 js error 都是前端经典的 NPE 错误。
第 1 个是发生在 iPad + 百度浏览器。第 2 个是发生在安卓 + 头条 webview ,结果我们会发现,我们客户端上报过来的错误有两种:
- 真实错误: Uncaught TypeError: Cannot set property 'b' of undefined。
- 宿主注入的很多干扰信息,比如说百度浏览器会注入 MyAppHrefLink is not defined。
可能很多同学没有观察过。我们是仔细去排查过的。百度浏览器会注入 MyAppHrefLink is not defined。头条的也会去注入一些头条 jsBridge 。
日志到达服务端后,我们先对日志进行清洗,把所有宿主的干扰日志都过滤掉,确保我们的报警系统是消费的真正的业务发生的日志错误。这是黄色区域的第一个模块: 日志清洗
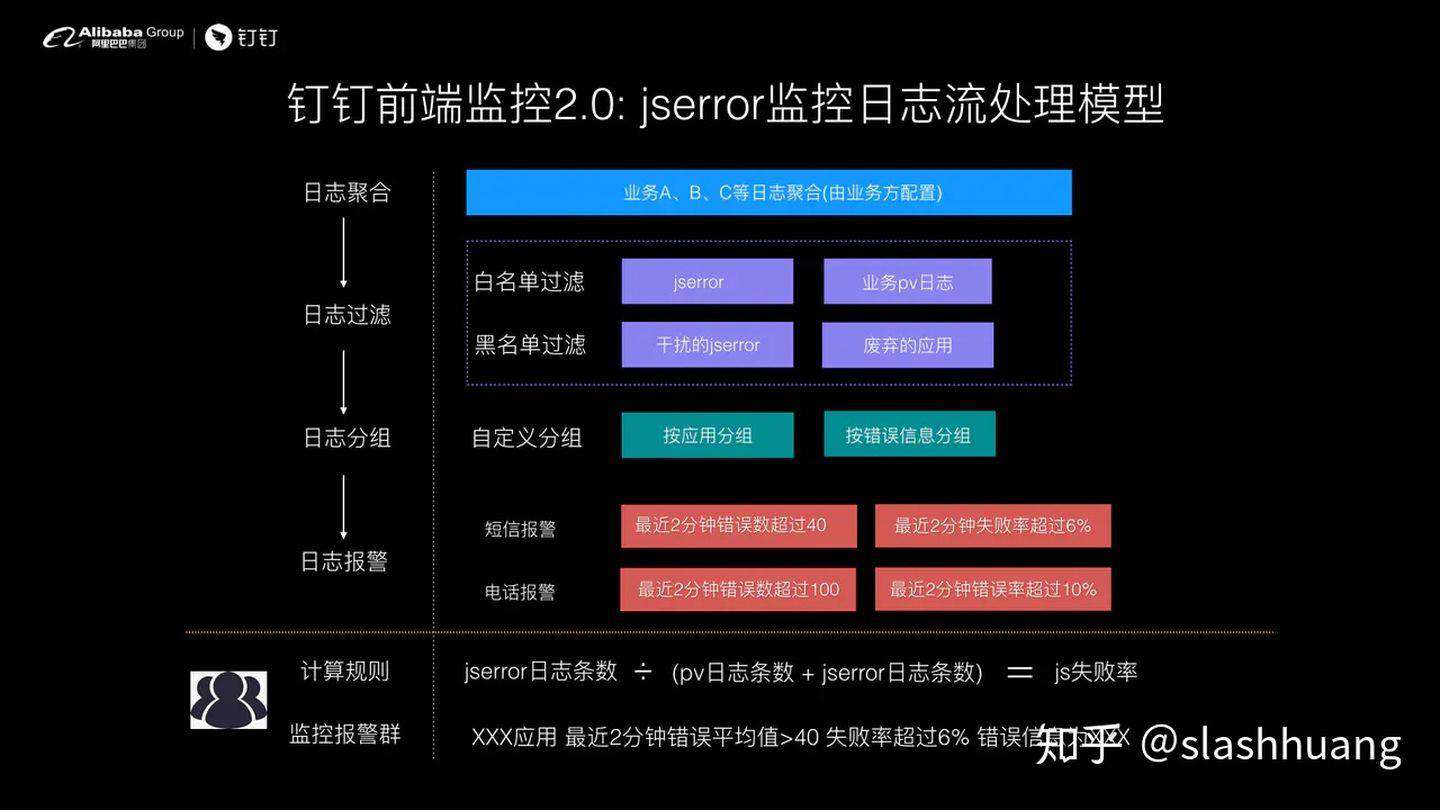
接下来我们进行日志分组,将应用 A spmId=A 和应用 B 的日志进行分组,通过应用标识 A 和 B 进行分组。将过滤过来的日志进行实时计算。
经过这一步后,再将日志流转到报警指标项进行实时计算,这个报警规则引擎下发相关的指令到 Map Reduce 对应的机器上去做一些处理。
比如 JS Error 失败率= JS Error 日志条数除以 PV 条数。当对日志进行计算的结果大于 6%,则进行钉钉群报警 ,当失败率大于 15% 则进行短信报警。
钉钉前端监控 2.0
监控日志
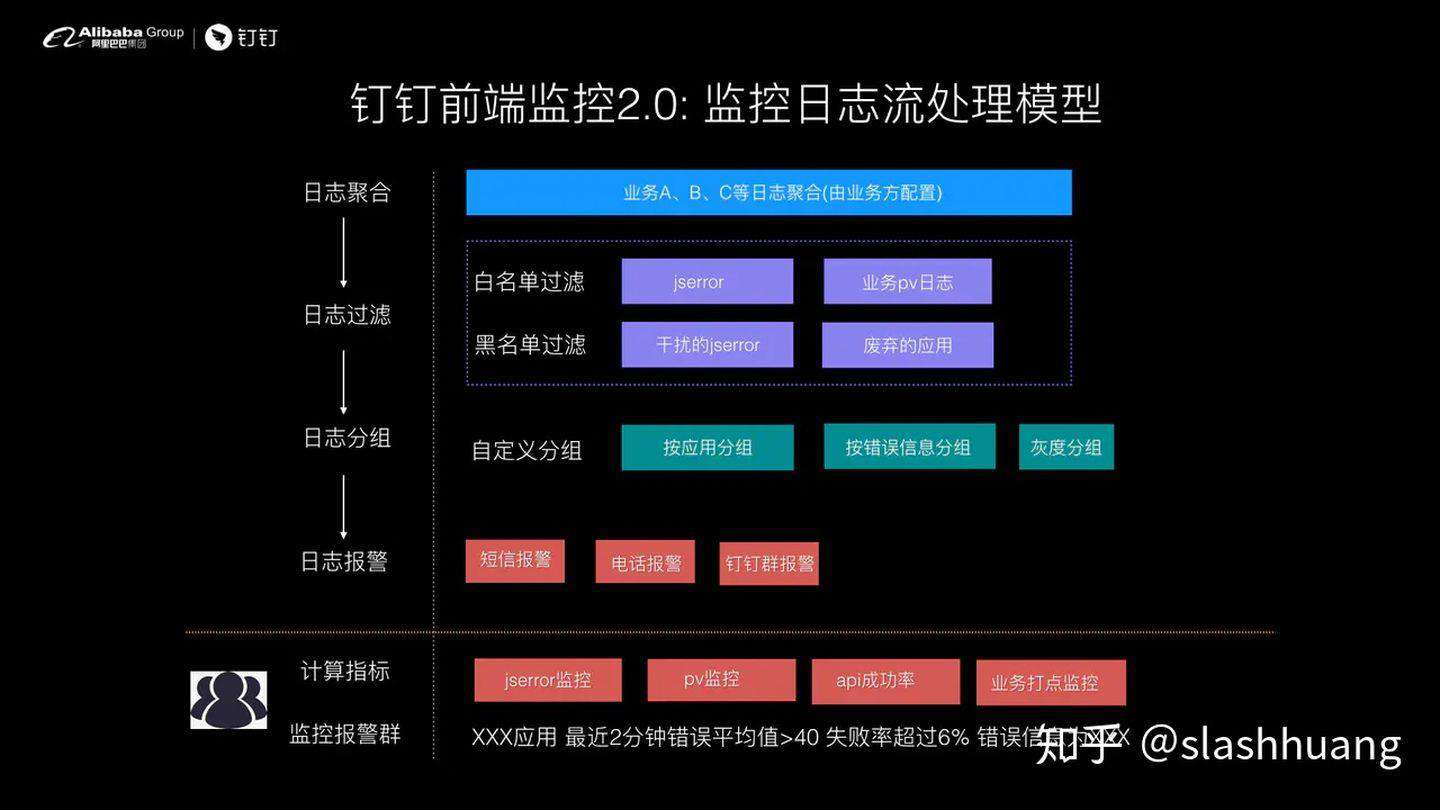
通过将同样的流程应用到各个不同的指标项,比如 api 成功率、js error 失败率、pv 数据等我们就可以在分钟计算系统搭建出一套满足 1 分钟感知的监控系统。
报警系统架构
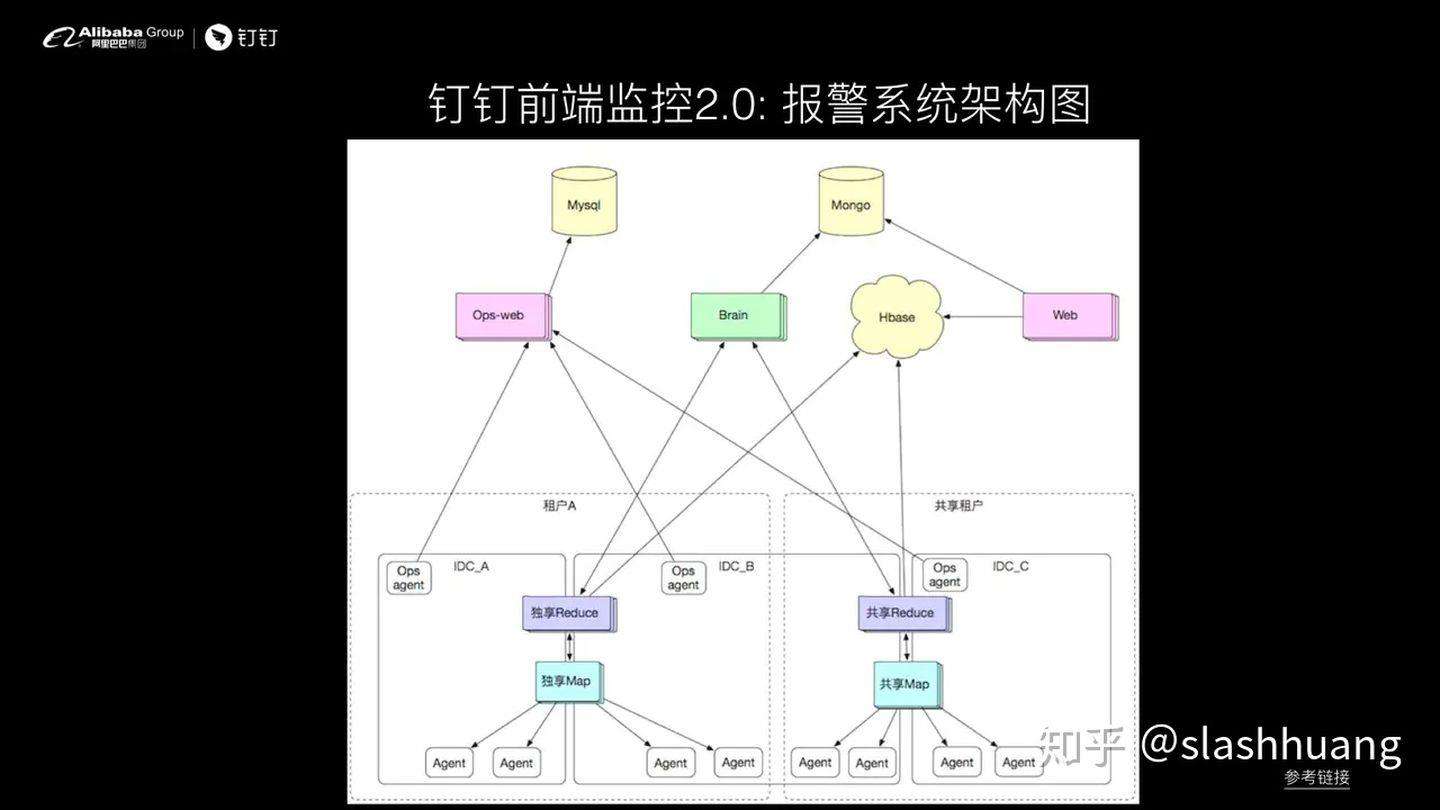
关于报警系统,上图我们阿里研发事业部那边的一个非常经典的监控系统,有兴趣的同学可以在 infoQ 上搜索 sunfire 看到更详细的架构介绍,这里不做过多展开。
整体日志架构总结
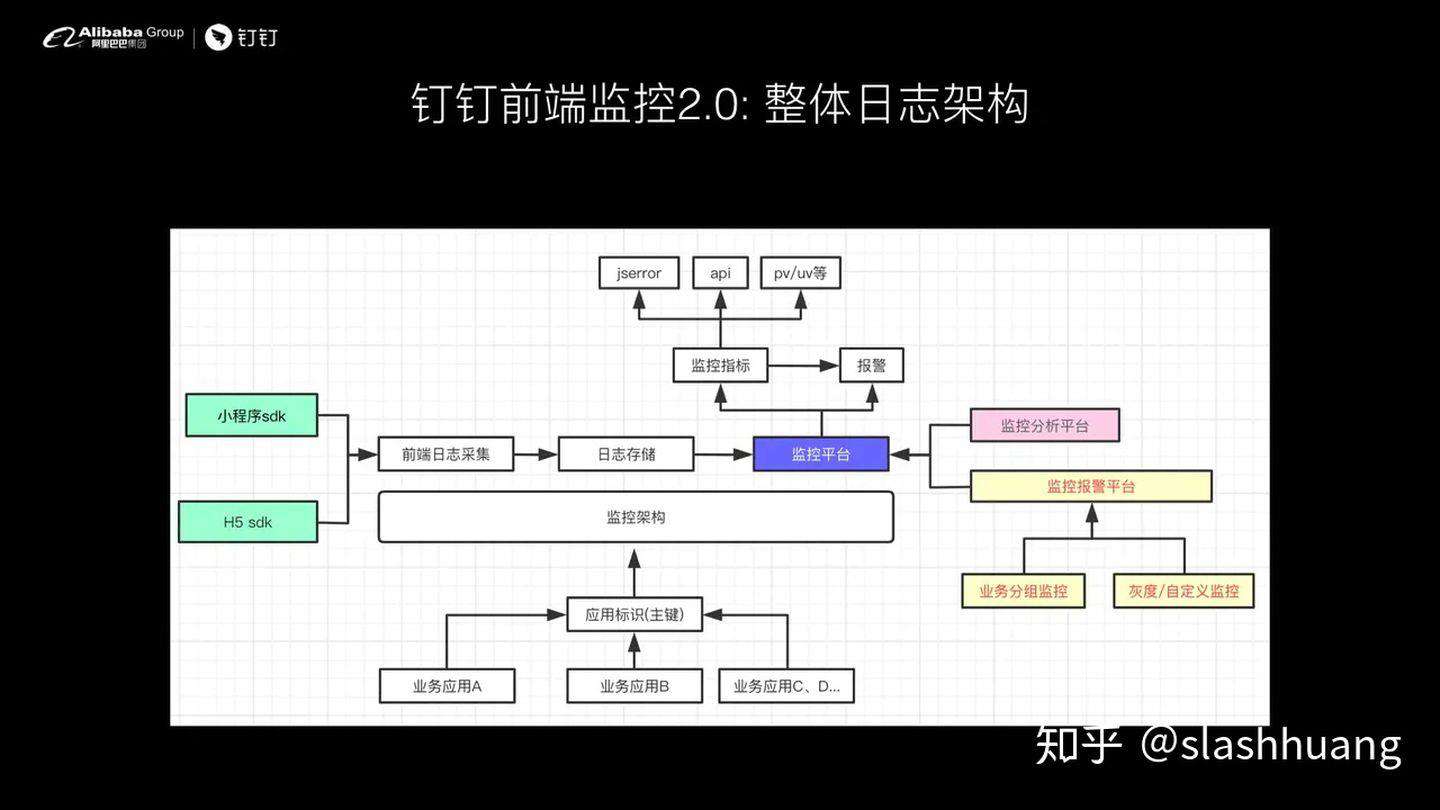
基本上这就是我今天想要分享的,钉钉前端监控在从 1.0 演进到 2.0 的过程中,我们是如何思考和如何落地的。这边的话我给大家稍微简单总结一下:
- 最关键的技术思路是将日志报警组件的编排进行前置,我们的实现是采用日志双写到分析系统和报警系统。
- 在报警平台支持报警规则引擎,真正做到报警自定义、报警可分级等。
- 对于前端而言,我们不仅仅是前端页面,我们更多的面对的是用户终端。
结束语
好,这就是我今天想要分享的,钉钉前端监控是如何赋能钉钉这样一个亿级体量、100 多个前端、600 多个前端页面的线上稳定性的。
下面是钉钉前端的技术专栏,有知乎专栏、有掘金专栏,我们一直在广纳贤才,欢迎联系我。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!