1. 打包结果优化
压缩体积优化:
// js压缩
`UglifyJSPlugin`: 删除所有console语句、最紧凑的输出,不保留空格和制表符、删除所有注释
`Tree-Shaking`: 消除无用代码,减小打包代码体积
// css压缩
`optimize-css-assets-webpack-plugin`
`PurifyCSSPlugin`: 需要配合` extract-text-webpack-plugin` 使用,它主要的作用是可以去除没有用到的CSS代码,类似JS的Tree Shaking。
加速网络请求:
// cdn加速
1. index.html这种放在自己的server上,静态资源js和css等放在cdn
2. 静态资源的文件名在webpack中配置输出成contentHash,只有内容变化,才会重新打包
3. 不同类型资源放在不同域名的CDN上(因为HTTP1.x版本的协议下,浏览器会对于向同一域名并行发起的请求数限制在4~8个)
// 多页面提取公共代码(CommonsChunkPlugin)
网站通常由多个页面组成,每个页面都是一个独立的单页应用,多个页面间会依赖同样的样式文件、技术栈等。
如果不把这些公共文件提取出来,那么每个单页打包出来的chunk中都会包含公共代码,相当于要传输n份重复代码。
如果把公共文件提取出一个文件,那么当用户访问了一个网页,加载了这个公共文件,再访问其他依赖公共文件的网页时,就直接使用文件在浏览器的缓存,这样公共文件就只用被传输一次
// 分割代码以按需加载
单页应用的一个问题在于使用一个页面承载复杂的功能,要加载的文件体积很大,不进行优化的话会导致首屏加载时间过长,影响用户体验。做按需加载可以解决这个问题。具体方法如下:
1. 将网站功能按照相关程度划分成几类
2. 每一类合并成一个Chunk,按需加载对应的Chunk
Tree-Shaking(prod模式下自带的优化)
Tree-Shaking: 能够在模块的层面上做到打包后的代码只包含被引用并被执行的模块,而不被引用或不被执行的模块被删除掉,以起到减包的效果
// math.js
export const add = (a, b) => {
console.log( a + b );
}
export const minus = (a, b) => {
console.log( a - b );
}
//math.js
import { add } from './math.js';
add(1, 2);
这里并未使用minus,但是却被打包到bundle中,Tree-Shaking可以帮我们把没有被使用的minus去除。
备注: Tree-Shaking只针对于prod环境(prod环境默认是开启Tree-Shaking),prod环境下冗余代码minus会被移除;dev环境就算配置了Tree-Shaking依然会把无用代码打包到bundle,但是会附带注释。
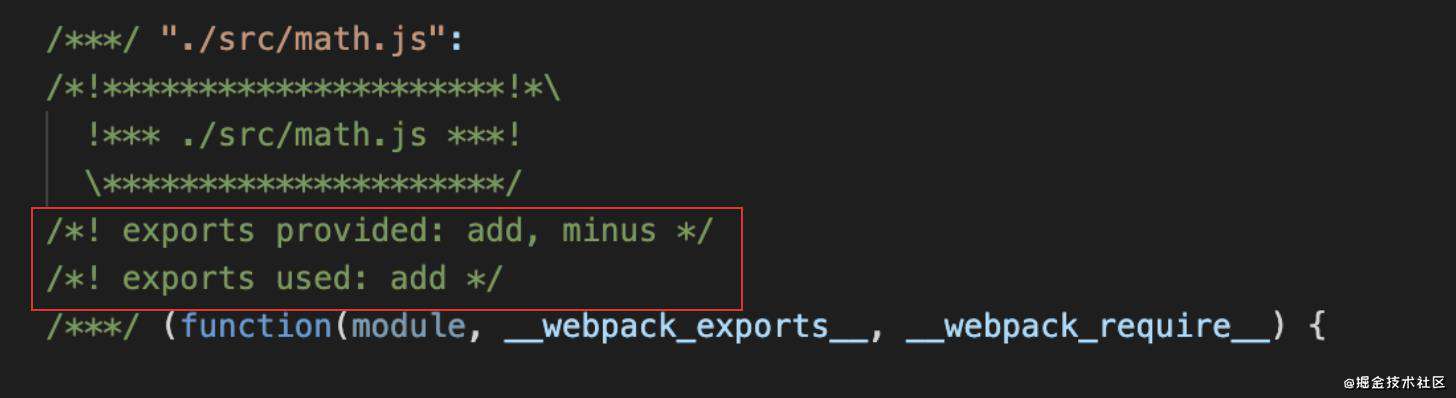
配置:
// package.json 中加上 sideEffects 配置:
{
"name": "webpack",
"version": "1.0.0",
"description": "",
"sideEffects": false, // 对所有的文件都启用 tree_shaking
// ...
}
// webpack.dev.js(prod下不需要配置)
const devConfig = {
// ...
optimization: {
usedExports: true,
},
// ...
}
// 下面这两种导入,tree_shaking 会认为你没有导出任何模块,在打包过程中,他直接就把它给忽略掉了,所以打包后的文件中根本没有这个 index.less 文件
import './index.less'
import '@babel/polly-fill'
这个时候我们需要配置 sideEffects如下:
// package.json
"sideEffects": [
"*.less",
"@babel/polly-fill",
]
我们碰到上面sideEffects数组中指定的几个模块,我们就不去进行 tree_shaking
tree-shaking 的局限性?
-
只能是静态声明和引用的 ES6 模块,不能是动态引入和声明的。(不支持commonJS)
-
只能处理模块级别,不能处理函数级别的冗余;
因为 webpack 的 tree-shaking 是基于模块间的依赖关系,所以并不能对模块内部自身的无用代码进行删除。
- 只能处理 JS 相关冗余代码,不能处理 CSS 冗余代码。
目前 webpack 只对 JS 文件的依赖进行了处理,CSS 的冗余并没有给出很好的工具。可以借助 PureCss 来完成这个目的。
CommonsChunkPlugin提取公共代码
把多个页面依赖的业务公共代码提取到common.js中:
const CommonsChunkPlugin = require('webpack/lib/optimize/CommonsChunkPlugin');
//...
plugins:[
new CommonsChunkPlugin({
chunks:['a','b'], //从哪些chunk中提取
name:'common', // 提取出的公共部分形成一个新的chunk
})
]
找出依赖的基础库,写一个base.js文件,再与common.js提取公共代码到base中,common.js就剔除了基础库代码(因为conmmon中可能也包含基础库代码import 'react';),而base.js保持不变。
//base.js
import 'react';
import 'react-dom';
import './base.css';
//webpack.config.json
entry:{
base: './base.js'
},
plugins:[
new CommonsChunkPlugin({
chunks:['base','common'],
name:'base',
//minChunks:2, 表示文件要被提取出来需要在指定的chunks中出现的最小次数,防止common.js中没有代码的情况
})
]
得到基础库代码base.js,不含基础库的公共代码common.js,和页面各自的代码文件xx.js。
页面引用顺序如下:base.js--> common.js--> xx.js
下面3种插件都是打包公共代码的,是打包公共代码插件的进化版
CommonsChunkPlugin ——> SplitChunksPlugin ——> DllPlugin
CommonsChunkPlugin的问题:
假如我们的文件是这么配置的:
minChunks: 2
entryA: vuex vue Acomponent
entryB: vue axios BComponent
entryC: vue vuex axios CComponent
// 那么产出的文件为:
vendor-chunk: vuex vue axios
chunkA~chunkC: only the Component
带来的问题:entryB 并没有使用 vuex,entryA 并没有使用 axios ,但是从产出的文件上来看,entryA 与 entryB 都引入了部分“脏”模块,这并不太好。
SplitChunksPlugin:在CommonsChunkPlugin的基础上,并不是把所有被引用的都打包到一个chunk,对于那些部分共有但是阈值过小的文件其不会创建单独的输出文件,因为其大小不值得去新开一个请求。(缓存策略配置在 cacheGroup 中)
DLLPlugin: 除了 webpack.config.js,项目中还会新建一个webpack.dll.config.js文件来配置 dll 的打包。
webpack.dll.config.js 作用是把所有的第三方库依赖打包到一个 bundle 的 dll 文件里面,还会生成一个名为manifest.json文件。
该 manifest.json 的作用是用来让 DllReferencePlugin 映射到相关的依赖上去的。
SplitChunksPlugin 虽然也是将公共模块抽离,但是其每次打包的时候还是会去处理一些第三方依赖库,只是它能把第三方库文件和我们的代码分开掉,生成一个独立的 js 文件。但是它还是不能提高打包的速度。
DLLPlugin 它则是提前将公共的包构建出来,使得在 build 时过滤掉这些构建过的包,使得在正是构建时的速度缩短。所以其相对来说打包速度会更快
分割不同chunk按需加载
juejin.cn/post/695585…
2. 构建过程优化
从以下方面入手:
1. 缩小文件的搜索范围
2. 减少基础模块编译次数(使用DllPlugin)
3. 开启多进程Loader转换(HappyPack)
4. 多进程压缩JS文件(ParallelUglifyPlugin)
include/exclude
使用 loader 的时候,我们需要在尽量少的模块中去使用。 我们可以借助 include 和 exclude 这两个参数,规定 loader 只在那些模块应用和在哪些模块不应用。
// webpack.common.js
const commonConfig = {
...
module: {
rules: [
{
test: /\.js|jsx$/,
exclude: /node_modules/,
include: path.resolve(__dirname, '../src'),
use: ['babel-loader']
},
...
]
},
}
// exclude: /node_modules/:排除 node_modules 下面的文件
// include: path.resolve(__dirname, '../src'):只对 src 下面的文件使用
resolve告诉webpack怎么去搜索文件
resolve.extensions:
如果我们想在导入模块时不写后缀,如下:
import List from './list/list';
打包一下 npm run dev,会报一个错误,说是 list 找不到
这个时候我们可以在配置文件中增加resolve参数,增加一个 extensions 属性,我们配置 ['.js', '.jsx'],意思是我们会先去找指定目录下面以 .js 结尾的文件,再去找.jsx结尾的文件,如果还是找不到就返回找不到
// webpack.common.js
...
const commonConfig = {
...
resolve: {
extensions: ['.js', '.jsx'],
},
...
}
...
但是这里我们要尽量少配置,因为如果配置多了,我们把诸如 css、jpg 结尾的都配置进去了,这会调用多次文件的查找,这样就会减慢打包速度。
resolve.mainFiles: 设置尽量少的值可以减少入口文件的搜索步骤
第三方模块为了适应不同的使用环境,会定义多个入口文件,mainFields定义使用第三方模块的哪个入口文件,由于大多数第三方模块都使用main字段描述入口文件的位置,所以可以设置单独一个main值,减少搜索
如果我们想在 index.js 中直接使用下面这种引用方式进行引用:
import List from './list';
// webpack.common.js
const commonConfig = {
...
resolve: {
mainFiles: ['index', 'list']
},
}
mainFiles表示在查找 from './list' 目录时,会先查找./list/index.js,如果没找到,则接着查找./list/list.js
有一些第三方模块会针对不同环境提供几分代码。 例如分别提供采用 ES5 和 ES6 的2份代码,这2份代码的位置写在 package.json 文件里,如下:
{
"jsnext:main": "es/index.js",// 采用 ES6 语法的代码入口文件
"main": "lib/index.js" // 采用 ES5 语法的代码入口文件
}
Webpack 会根据 mainFields 的配置去决定优先采用那份代码;Webpack 会按照数组里的顺序去package.json 文件里寻找,只会使用找到的第一个。
假如你想优先采用 ES6 的那份代码,可以这样配置
mainFields: ['browser', 'main'] // mainFields默认值
// webpack.config.js配置
resolve:{
mainFields: ['jsnext:main', 'browser', 'main']
}
-
resolve.alias:略过 -
resolve.modules
设置resolve.modules:[path.resolve(__dirname, 'node_modules')]避免层层查找。
resolve.modules告诉webpack去哪些目录下寻找第三方模块,默认值为['node_modules'],会依次查找./node_modules、../node_modules、../../node_modules。
// webpack.common.js
const commonConfig = {
...
resolve: {
extensions: ['.js', '.jsx'],
mainFiles: ['index', 'list'],
alias: {
alias: path.resolve(__dirname, '../src/alias'),
},
modules: [path.resolve(__dirname, 'node_modules')]
},
...
}
使用DllPlugin减少基础模块编译次数
DllPlugin动态链接库插件,其原理是把网页依赖的基础模块抽离出来打包到dll文件中,当需要导入的模块存在于某个dll中时,这个模块不再被打包,而是去dll中获取。为什么会提升构建速度呢? 原因在于dll中大多包含的是常用的第三方模块,如react、react-dom,所以只要这些模块版本不升级,就只需被编译一次
使用HappyPack开启多进程Loader转换
在整个构建流程中,最耗时的就是Loader对文件的转换操作了,而运行在Node.js之上的Webpack是单线程模型的,也就是只能一个一个文件进行处理,不能并行处理。HappyPack可以将任务分解给多个子进程,最后将结果发给主进程。
npm i -D happypack
// webpack.config.json
const path = require('path');
const HappyPack = require('happypack');
module.exports = {
//...
module:{
rules:[{
test:/\.js$/,
use:['happypack/loader?id=babel']
exclude:path.resolve(__dirname, 'node_modules')
},{
test:/\.css/,
use:['happypack/loader?id=css']
}],
plugins:[
new HappyPack({
id:'babel',
loaders:['babel-loader?cacheDirectory']
}),
new HappyPack({
id:'css',
loaders:['css-loader']
})
]
}
}
noParse
比如项目中依赖了一些底层模块jquery,webpack打包解析的过程中看到导入了jquery,就会再解析jquery,看看jquery里面是否还引入其他的第三方模块,但是我们知道jquery是底层的库,jquery中已经不会再引入其他第三库了,这时候就可以配置webpack不用再去解析jquery了,节省时间
import $ from jquery
// webpack.config.js
module.exports = {
module: {
// 表示不需要再去解析jquery
noParse: /jquery/
}
}
externals
如果我们想引用一个库,不想让webpack打包,也就是不想npm install安装,但是又不能影响我们在程序中以CMD、AMD或者window/global全局等方式进行使用,那就可以通过配置externals。因为打包进去就会体积太大
使用lodash:
import _ from 'lodash';
配置externals:
externals: {
"lodash": {
commonjs: "lodash",//如果我们的库运行在Node.js环境中,import _ from 'lodash'等价于const _ = require('lodash')
commonjs2: "lodash",//同上
amd: "lodash",//如果我们的库使用require.js等加载,等价于 define(["lodash"], factory);
root: "_"//如果我们的库在浏览器中使用,需要提供一个全局的变量‘_’,等价于 var _ = (window._) or (_);
}
}
Tapable
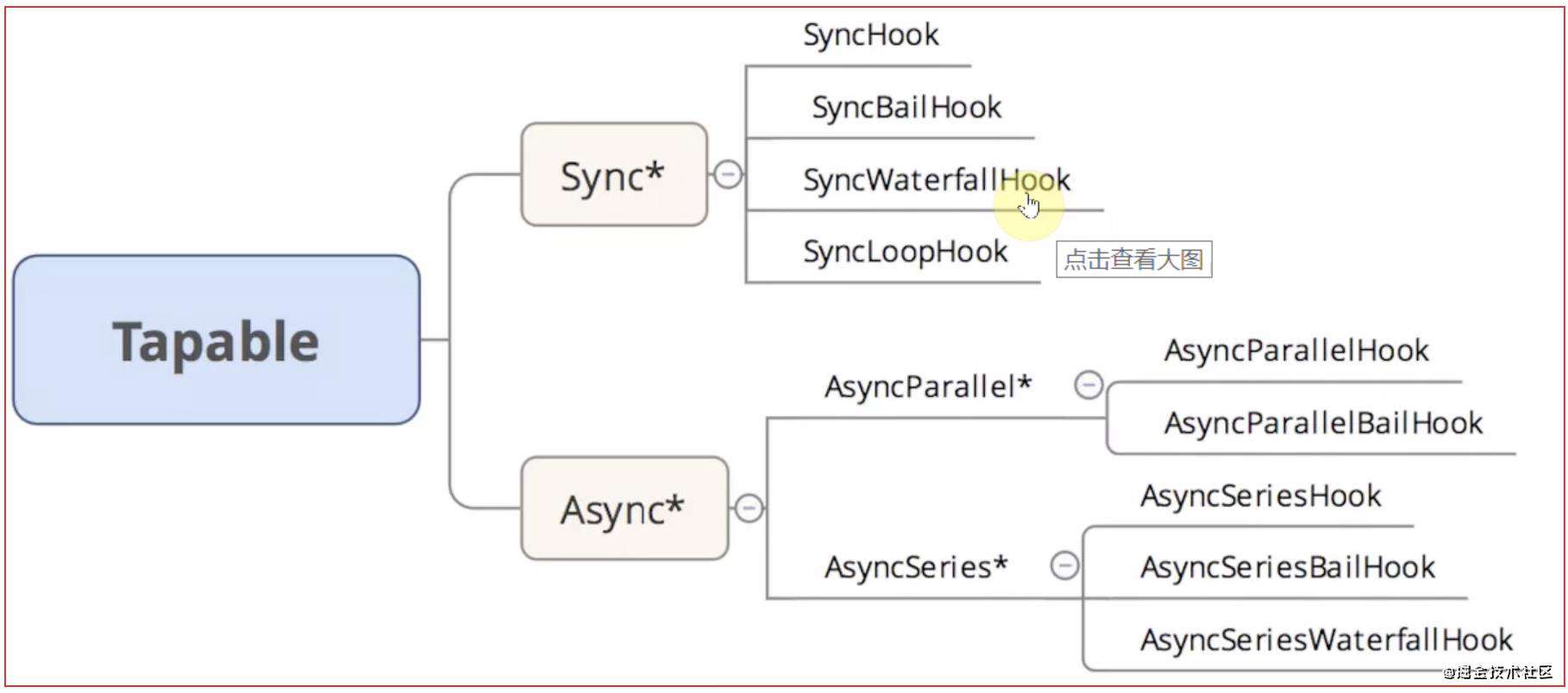
webpack本质上是一个事件流,工作流程就是将各个插件串联起来;而实现这一切的核心是Tapable,核心原理是依赖发布订阅模式
同步钩子
1. 同步钩子SyncHook
// 基本使用示例:
let { SyncHook } = require('tapable')
class Lesson{
constructor(){
this.hooks = {
arch: new SyncHook(['name'])
}
}
tap(){
// tap函数用于给hook上注册监听回调函数
this.hooks.arch.tap('vue', function(name){
console.log('vue', name)
});
this.hooks.arch.tap('node', function(name){
console.log('node', name)
})
}
start(){
// hook的call方法用于触发hook上的回调函数,这里的hello作为回调的参数传入
this.hooks.arch.call('hello')
}
}
let lesson = new Lesson()
lesson.tap()
// 打印 vue hello
// 打印 node hello
lesson.start()
// SyncHook同步钩子实现原理
class SyncHook{
constructor(args){
this.tasks = [];
}
// 事件订阅监听
tap(eventName, taskCallback){
this.tasks.push(taskCallback)
}
// 事件发布触发
call(...args){
this.tasks.forEach(taskCallback => {
taskCallback(...args)
})
}
}
let sh = new SyncHook()
sh.tap('vue', function(arg){
console.log('vue', arg)
})
sh.tap('node', function(arg){
console.log('node', arg)
})
sh.call('hello') // 打印 vue hello; 打印 node hello
2. 同步钩子SyncBailHook
SyncBailHook是保险钩子,决定是否向下执行;如果tap的回调函数返回值是非undefined,那么就不会向下执行了。
// 基本使用示例:
let { SyncBailHook } = require('tapable')
class Lesson{
constructor(){
this.hooks = {
arch: new SyncBailHook(['name'])
}
}
tap(){
// tap函数的参数 ——> 回调函数返回非undefined了,所以下面的 node回调就不执行了
this.hooks.arch.tap('vue', function(name){
console.log('vue', name)
return '停止执行'
});
this.hooks.arch.tap('node', function(name){
console.log('node', name)
})
}
start(){
this.hooks.arch.call('hello')
}
}
let lesson = new Lesson()
lesson.tap()
// 只打印 vue hello;因为vue hello的回调函数返回了非undefined,所以不会打印node hello;
lesson.start()
// SyncBailHook同步钩子实现原理
class SyncBailHook{
constructor(args){
this.tasks = [];
}
// 事件订阅监听
tap(eventName, taskCallback){
this.tasks.push(taskCallback)
}
// 事件发布触发
call(...args){
let index = 0; // 当前要执行的第一个函数的下标
let ret; // ret是回调函数的返回值
do{
ret = this.tasks[index++](...args)
}while(ret === 'undefined' && index < this.tasks.length)
}
}
let sh = new SyncBailHook()
sh.tap('vue', function(arg){
console.log('vue', arg)
return '停止执行'
})
sh.tap('node', function(arg){
console.log('node', arg)
})
// 只打印 vue hello;因为vue hello的回调函数返回了非undefined,所以不会打印node
sh.call('hello')
3. 同步钩子SyncWaterfallHook
SyncWaterfallHook会将tap的回调函数扯上关系,上一个回调函数的返回值,会作为下一个回调函数的参数;瀑布流
// 基本使用示例:
let { SyncWaterfallHook } = require('tapable')
class Lesson{
constructor(){
this.hooks = {
arch: new SyncWaterfallHook(['name'])
}
}
tap(){
//
this.hooks.arch.tap('vue', function(name){
console.log('vue', name)
return 'vue学的不错'
});
// 上一个回调函数的返回值 ——> vue学的不错 会作为下面这个回调函数的data的值
this.hooks.arch.tap('node', function(data){
console.log('node', data)
})
}
start(){
this.hooks.arch.call('hello')
}
}
let lesson = new Lesson()
lesson.tap()
// 打印:vue hello
// 打印:node vue学的不错
lesson.start()
// SyncWaterfallHook同步钩子实现原理
class SyncWaterfallHook{
constructor(args){
this.tasks = [];
}
tap(eventName, taskCallback){
this.tasks.push(taskCallback)
}
call(...args){
let [firstTask, ...otherTasks] = this.tasks
let ret = firstTask(...args)
otherTasks.reduce((item, task) => {
return task(item)
}, ret)
}
}
let sh = new SyncWaterfallHook()
sh.tap('vue', function(arg){
console.log('vue', arg)
return 'vue学的不错'
})
sh.tap('node', function(arg){
console.log('node', arg)
})
// 打印:vue hello
// 打印:node vue学的不错
sh.call('hello')
4. 同步钩子SyncLoopHook
SyncLoopHook会循环 不返回undefined的回调函数
// SyncLoopHook同步钩子实现原理
class SyncLoopHook{
constructor(args){
this.tasks = [];
}
tap(eventName, taskCallback){
this.tasks.push(taskCallback)
}
call(...args){
this.tasks.forEach(task => {
let ret;
do{
ret = task(...args)
}while(ret != 'undefined')
})
}
}
let sh = new SyncLoopHook()
let total = 0;
sh.tap('vue', function(arg){
console.log('vue', arg)
return ++total == 3 ? undefined : '继续学习'
})
sh.tap('node', function(arg){
console.log('node', arg)
})
// 打印3次:vue hello
// 打印:node hello
sh.call('hello')
异步钩子
异步:当需要多个并行的请求都执行完之后,再执行回调。
异步有分两类:串行和并行; 串行有的可能需要知道上一步的结果,才能进行下一步;并行是需要等待所有并发的异步事件执行后再执行回调方法
1. AsyncParallelHook
AsyncParallelHook等待所有异步事件执行完毕之后再执行传入的回调cb()
// AsyncParallelHook基本使用
let { AsyncParallelHook } = require('tapable')
class Lesson{
constructor(){
this.hooks = {
arch: new AsyncParallelHook(['name'])
}
}
tap(){
this.hooks.arch.tapAsync('vue', function(name, cb){
setTimeout(() => {
console.log('vue', name)
cb() // 告诉外界这个异步setTimeout执行完了
}, 1000)
});
this.hooks.arch.tapAsync('node', function(name, cb){
setTimeout(() => {
console.log('node', name)
cb() // 告诉外界这个异步setTimeout执行完了
}, 1000)
})
}
start(){
this.hooks.arch.callAsync('hello', function(){
console.log('end')
})
}
}
let lesson = new Lesson()
lesson.tap()
// 打印:vue hello
// 打印:node hello
// 打印:end
lesson.start()
// 备注:这里end只打印了一次,因为在cb函数内部,会判断
// AsyncParallelHook原理实现之回调函数cb版
class AsyncParallelHook{
constructor(args){
this.tasks = []
}
tapAsync(eventName, taskCallback){
this.tasks.push(taskCallback)
}
callAsync(...args){
let finalCallback = args.pop()
let index = 0;
// done函数判断如果触发的监听函数的异步事件都处理完了,那么这里的done调用的此时就等于task的长度,这时候再调用传入的finalCallback;所以上述基本示例中end才打印了一次
let done = () => {
index++;
if (index === this.tasks.length){
finalCallback()
}
}
this.tasks.forEach(taskCallback => {
taskCallback(...args, done)
})
}
}
let aph = new AsyncParallelHook(['name'])
aph.tapAsync('vue', function(name, cb){
setTimeout(() => {
console.log('vue', name)
cb() // 告诉外界这个异步setTimeout执行完了
}, 1000)
})
aph.tapAsync('node', function(name, cb){
setTimeout(() => {
console.log('node', name)
cb() // 告诉外界这个异步setTimeout执行完了
}, 1000)
})
aph.callAsync('hello', function(){
console.log('end')
})
// AsyncParallelHook原理实现之promise版
class AsyncParallelHook{
constructor(args){
this.tasks = []
}
tapPromise(eventName, taskCallback){
this.tasks.push(taskCallback)
}
callAsync(...args){
let finalCallback = args.pop()
let index = 0;
// done函数判断如果触发的监听函数的异步事件都处理完了,那么这里的done调用的此时就等于task的长度,这时候再调用传入的finalCallback;所以上述基本示例中end才打印了一次
let done = () => {
index++;
if (index === this.tasks.length){
finalCallback()
}
}
this.tasks.forEach(taskCallback => {
taskCallback(...args, done)
})
}
}
let aph = new AsyncParallelHook(['name'])
aph.tapAsync('vue', function(name, cb){
setTimeout(() => {
console.log('vue', name)
cb() // 告诉外界这个异步setTimeout执行完了
}, 1000)
})
aph.tapAsync('node', function(name, cb){
setTimeout(() => {
console.log('node', name)
cb() // 告诉外界这个异步setTimeout执行完了
}, 1000)
})
aph.callAsync('hello', function(){
console.log('end')
})
参考
juejin.cn/post/684490…
webpack.wuhaolin.cn/4%E4%BC%98%…
monocy.site/2019/05/23/…
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!