前言
文本将和大家一起简单了解一下 v8 内部是如何处理对象的,以及 v8 为了高速化对象属性的访问所做的一些优化的细节。除了结合现有的资料外,本文还链接了一些实现所对应的源码位置,以节约大家后续需要结合源码进行深入时所花的时间
本文的目的是了解 v8 的内部实现细节,大家可以根据自己的情况来决定是否需要先阅读下面的资料:
- A tour of V8: object representation
- Fast properties in V8
TaggedImpl
在 v8 内部实现中,所有对象都是从 TaggedImpl 派生的
下图是 v8 中涉及 Object 实现的部分类的继承关系图示:
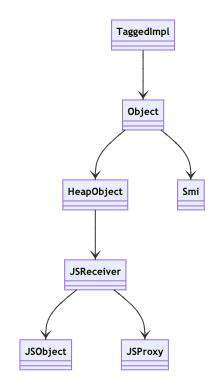
TaggedImpl 所抽象的逻辑是「打标签」,所以我们需要进一步了解「标签」的含义
v8 的 GC 是「准确式 GC,Precise GC」,与之相对的是「保守式 GC,Conservative GC」
GC 的任务就是帮助我们自动管理堆上的内存。当一个对象被 GC 识别为垃圾对象之后,GC 就需要对其占用的内存进行回收,随之而来的问题是 GC 如何判断指针和非指针,因为我们知道对象的属性可能是值属性、或者引用堆上的其他内容(指针):
type Object = Record<string, number>;
const obj = { field1: 1 };
上面的代码我们通过 Record 来模拟对象的数据结构,其实就是简单的键值对。不过我们把值都定义成了 number 类型,这是因为对于值类型,我们直接存放它们的值就可以了,而对于引用类型,我们则存放它们的内存地址,而内存地址也是值,所以就都用 number 表示了
保守式 GC 的优势是与应用之间的耦合性很低,为了达到这样的设计目的,就要让 GC 尽可能少的依赖应用提供的信息,结果就是 GC 无法准确判断某个值表示的是指针还是非指针。比如上面的例子,保守式 GC 无法准确知道 field1 的值 1 是表示数值,还是指针
当然保守式 GC 并不是完全不能识别指针,它可以根据应用具体的使用内存时的行为特点(所以也并不是完全解耦),对指针和非指针进行猜测。简单来说就是硬编码一些猜测的逻辑,比如我们知道应用中的一些确定行为,那么我们就不用和应用交互,直接把这部分逻辑硬编码到 GC 实现中就可以了。比如我们知道身份证的编码格式,如果要验证一串数字是不是身份证,我们可以根据编码格式来验证,也可以调用公安的 API(如果有的话),前者就是保守式 GC 的工作方式,可以验证出一部分,但是对于那些符合格式、但却不存在的号码,则也会被识别为身份证
我们知道如果一个内存地址被意外释放,那么一定会导致应用后续进入错误的状态、甚至崩溃。保守式 GC 为了应对这个问题,当它在标记活动对象时,会把看起来像是指针的地址都标记为活动的,这样就不会发生内存被意外释放的问题了,「保守式」之名也因此而得。不过随之而来的是,某些可能已经是垃圾的对象存活了下来,因此保守式 GC 存在压迫堆的风险
v8 的 GC 是准确式 GC,准确式 GC 就需要和应用进行紧密配合了,TaggedImpl 就是为了配合 GC 识别指针和非指针而定义的。TaggedImpl 使用的是称为 pointer tagging 的技术(该技术在 Pointer Compression in V8 有提及)
pointer tagging 技术简单来说,就是利用地址都是按字长对齐(字长的整数倍)的特性。这个特性是这样来的:
- 首先 CPU 的字长由于硬件设计上的考量,都是偶数
- 然后早期 CPU 由于内部设计的原因,对偶数地址的寻址的效率要高于对基数地址寻址的效率(不过由于硬件设计上的升级,目前来看也并非绝对了)
- 所以大家(编译器,运行时的内存分配)都会确保地址是按字长对齐的
这样延续到现在,基本就当成一个默认规则了。基于这个规则,因为偶数的最低二进制位是 0,所以 v8 中:
- 对于数值统一左移一位,这样数值的最低二进制位为
0 - 对于指针则将最低二进制位置为
1
比如,对于 GC 而言,0b110 表示的是数值 0b11(使用时需右移一位),对于 0b111 表示的是指针 0b110(寻址时需减 1)。
通过打标签的操作,GC 就可以认为,如果某个地址最低二进制位是 0 则该位置就是 Smi - small integer,否则就是 HeapObject
可以参考 垃圾回收的算法与实现 一书来更加系统的了解 GC 实现的细节
Object
Object 在 v8 内部用于表示所有受 GC 管理的对象
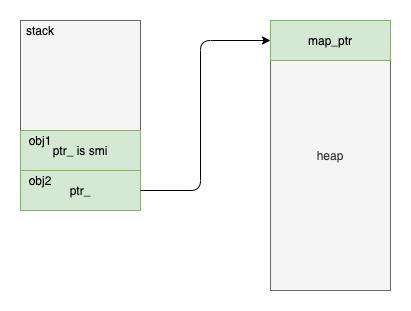
上图演示了 v8 运行时的内存布局,其中:
- stack 表示 native 代码(cpp 或 asm)使用的 stack
- heap 表示受 GC 管理的堆
- native 代码通过
ptr_来引用堆上的对象,如果是 smi 则无需访问 GC 的堆 - 如果要操作堆上对象的字段,则需进一步通过在对象所属的类的定义中、硬编码的偏移量来完成
各个类中的字段的偏移量都定义在 field-offsets-tq.h 中。之所以要手动硬编码,是因为这些类的实例内存需要通过 GC 来分配,而是不是直接使用 native 的堆,所以就不能利用 cpp 编译器自动生成的偏移量了
我们通过一个图例来解释一下编码方式(64bit 系统):
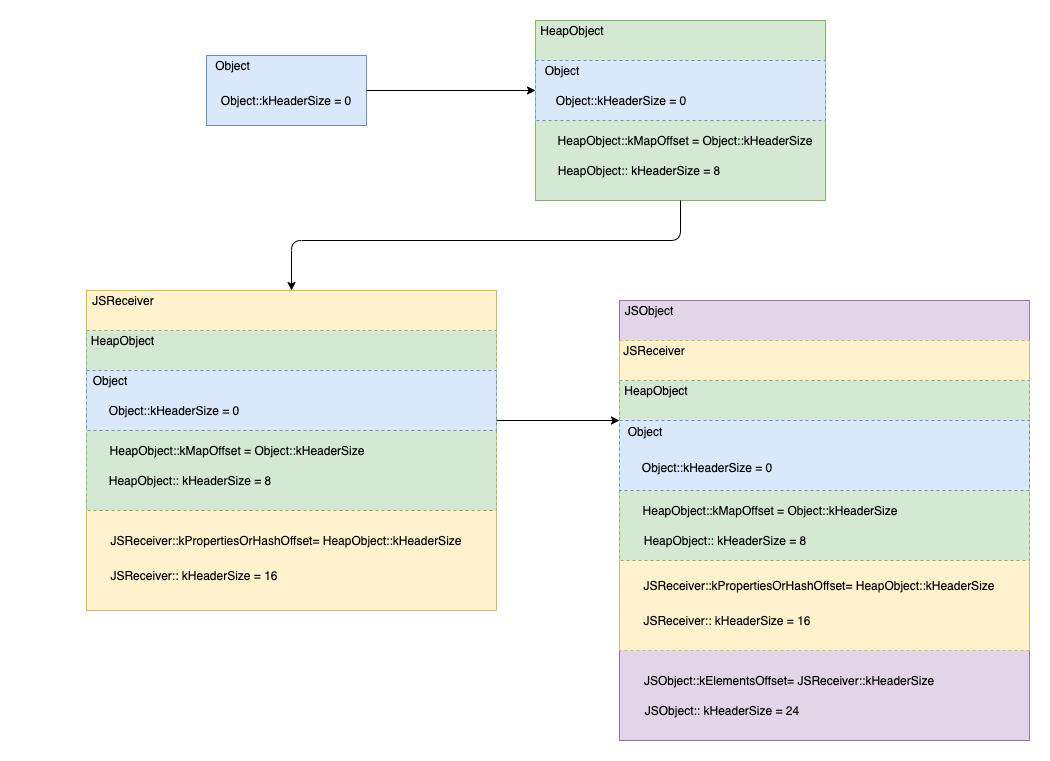
- 图中通过不同的颜色表示对象自身定义的区域和继承的区域
- Object 中没有字段,所以
Object::kHeaderSize是0 - HeapObject 是 Object 类的子类,因此它的字段偏移起始值是
Object::kHeaderSize(参考代码),HeapObject 只有一个字段偏移kMapOffset值等于Object::kHeaderSize即0,因为该字段大小是kTaggedSize(在 64bit 系统上该值为 8),所以HeapObject:kHeaderSize是 8bytes - JSReceiver 是 HeapObject 类的子类,因此它的字段偏移起始值是
HeapObject:kHeaderSize(参考代码),JSReceiver 也只有一个字段偏移kPropertiesOrHashOffset,其值为HeapObject:kHeaderSize即 8bytes,因为该字段大小是kTaggedSize,所以JSReceiver::kHeaderSize为 16bytes(加上了继承的 8bytes) - JSObject 是 JSReceiver 的子类,因此它的字段偏移起始值是
JSReceiver::kHeaderSize(参考代码), JSObject 也只有一个字段偏移kElementsOffset,值为JSReceiver::kHeaderSize即 16bytes,最后JSObject::kHeaderSize就是 24bytes
根据上面的分析结果,最终通过手动编码实现的继承后,JSObject 中一共有三个偏移量:
- kMapOffset
- kPropertiesOrHashOffset
- kElementsOffset
这三个偏移量也就表示 JSObject 有三个内置的属性:
- map
- propertiesOrHash
- elements
map
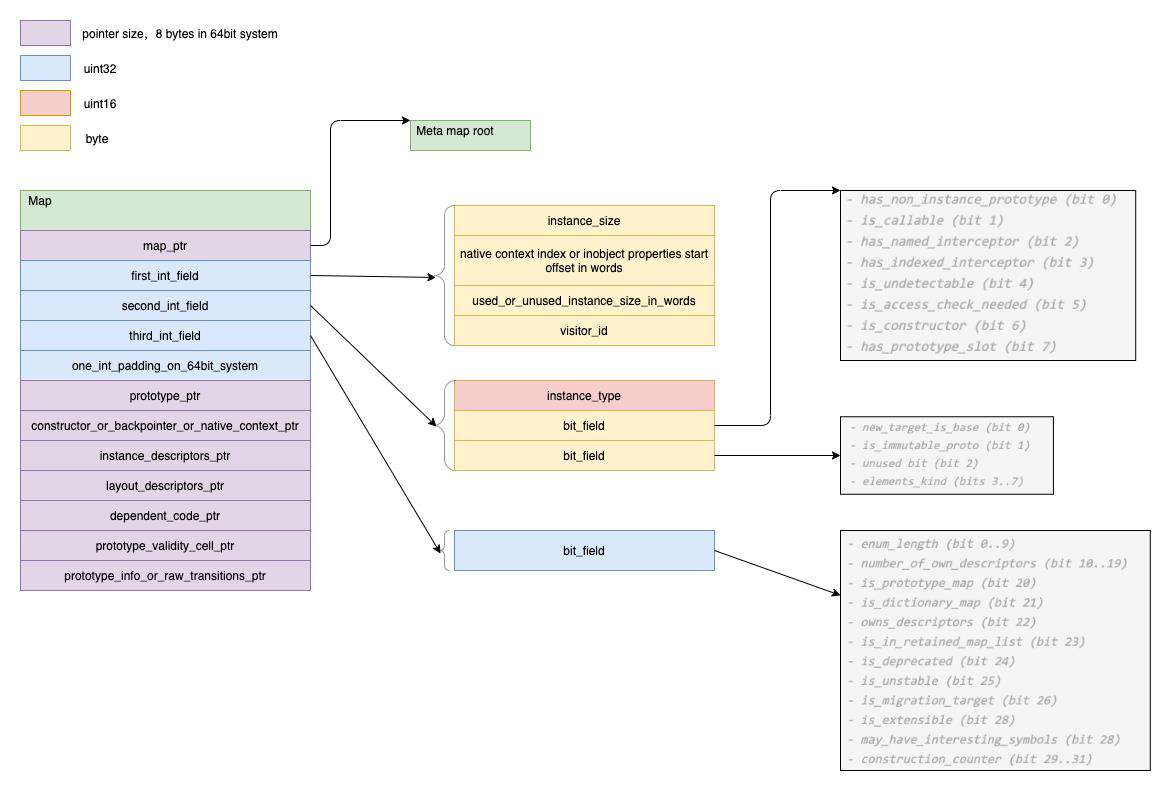
map 一般也称为 HiddenClass,它描述了对象的元信息,比如对象的大小(instance_size)等等。map 也是继承自 HeapObject,因此它本身也是受 GC 管理的对象,JSObject 中的 map 字段是指向堆上的 map 对象的指针
我们可以结合 map 源码中注释的 Map layout 和下图来理解 map 的内存的拓扑形式:
propertiesOrHash,elements
在 JS 中,数组和字典在使用上没有显著的差别,但是从引擎实现的角度,在其内部为数组和字典选择不同的数据结构可以优化它们的访问速度,所以分别使用 propertiesOrHash 和 elements 两个属性就是这个目的
对于命名属性(named properties)会关联到 propertiesOrHash,对于索引属性(indexed properties)则关联到 elements。之所以使用「关联」一词,是因为 propertiesOrHash 和 elements 只是指针,引擎会根据运行时的优化策略,将它们连接到堆上的不同的数据结构
我们可以通过下面的图来演示 JSObject 在堆上的可能的拓扑形式:
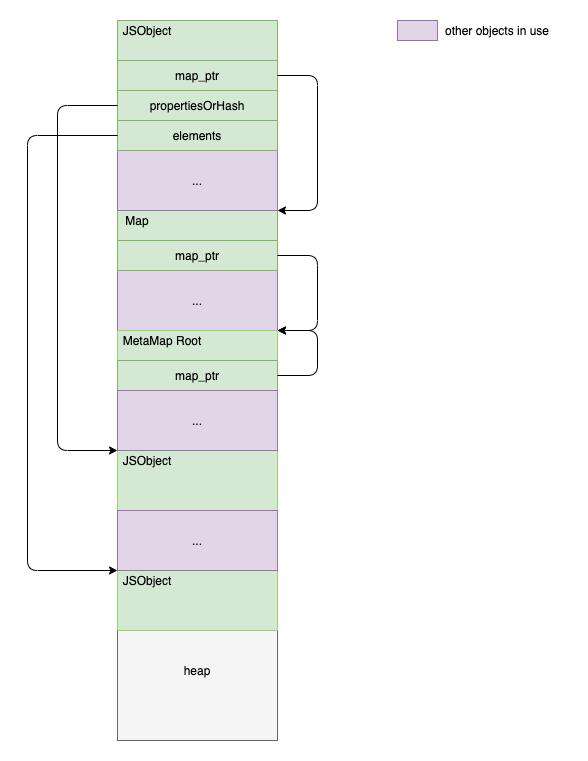
需要说明的是,v8 的分代式 GC 会对堆按对象的活跃度和用途进行划分,所以 map 对象实际会放到专门的堆空间中(所以实际会比上图显得更有组织),不过并不影响上图的示意
inobject、fast
上面我们介绍到 named properties 会关联到对象的 propertiesOrHash 指针指向的数据结构,而用于存储属性的数据结构,v8 并不是直接选择了常见的 hash map,而是内置了 3 种关联属性的形式:
- inobject
- fast
- slow
我们先来了解 inobject 和 fast 的形式,下面是它们的整体图示:
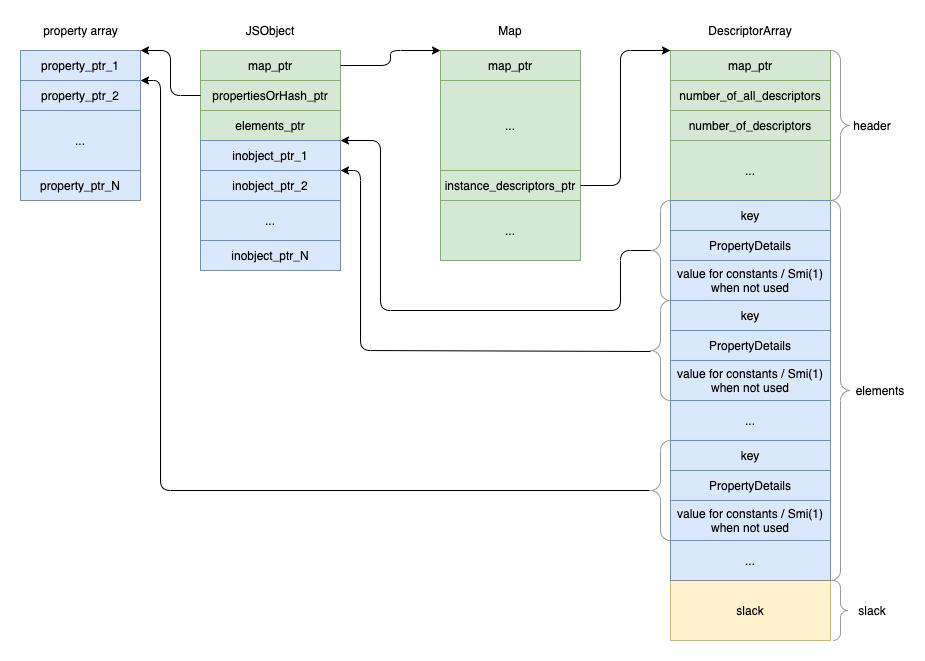
inobject 就和它的名字一样,表示属性值对应的指针直接保存在对象开头的连续地址内,它是 3 种形式中访问速度最快的(按照 fast-properties 中的描述)
注意观察上图中的 inobject_ptr_x,它们只是指向属性值的指针,因此为了按照名称找到对应的属性,需要借助一个名为 DescriptorArray 的结构,这个结构中记录了:
- key,字段名称
- PropertyDetails,表示字段的元信息,比如
IsReadOnly、IsEnumerable等 - value,只有常量时才会存入其中,如果是
1表示该位置未被使用(可以结合上文的标签进行理解)
为了访问 inobject 或者 fast 属性(相关实现在 LookupIterator::LookupInRegularHolder):
-
v8 需要先根据属性名,在
DescriptorArray中搜索到属性值在 inobject array(inobject 因为是连续的内存地址,所以可以看成是数组)或者 property array (图中最左边)中的索引 -
然后结合数组首地址与指针偏移、拿到属性值的指针,再通过属性值的指针,访问具体的属性值(相关实现在 JSObject::FastPropertyAtPut)
inobject 相比 fast 要更快,这是因为 fast 属性多了一次间接寻址:
-
inobject 属性知道了其属性值的索引之后,直接根据对象的首地址进行偏移即可(inobject array 之前的
map_ptr,propertiesOrHash_ptr,elements_ptr是固定的大小) -
而如果是 fast,则需要先在对象的首地址偏移
kPropertiesOrHashOffset拿到 PropertyArray 的首地址,然后在基于该首地址再进行索引的偏移
因为 inobject 是访问速度最快的形式,所以在 v8 中将其设定为了默认形式,不过需要注意的是 fast 和 inobject 是互补的,只是默认情况下,添加的属性优先按 inobject 形式进行处理,而当遇到下面的情形时,属性会被添加到 fast 的 PropertyArray 中:
- 当整体 inobject 属性的数量超过一定上限时
- 当动态添加的属性超过 inobject 的预留数量时
- 当 slack tracking 完成后
v8 在创建对象的时候,会动态地选择一个 inobject 数量,记为 expected_nof_properties(后面会介绍),然后以该数量结合对象的内部字段(比如 map_ptr 等)数来创建对象
初始的 inobject 数量总是会比当前实际所需的尺寸大一些,目的是作为后续可能动态添加的属性的缓冲区,如果后续没有动态添加属性的动作,那么势必会造成空间的浪费,这个问题就可以通过后面介绍的 slack tracking 来解决
比如:
class A {
b = 1;
}
const a = new A();
a.c = 2;
在为 a 分配空间时,虽然 A 只有 1 个属性 b,但是 v8 选择的 expected_nof_properties 值会比实际所需的 1 大。因为 JS 语言的动态性,多分配的空间可以让后续动态添加的属性也能享受 inobject 的效率,比如例子中的 a.c = 2,c 也是 inobject property,尽管它是后续动态添加的
slow
slow 相比 fast 和 inobject 更慢,是因为 slow 型的属性访问无法使用 inline cache 技术进行优化,跟多关于 inline cache 的细节可以参考:
- Inline caching
- Explaining JavaScript VMs in JavaScript - Inline Caches
slow 是和 inobject、fast 互斥的,当进入 slow 模式后,对象内的属性结构如下:
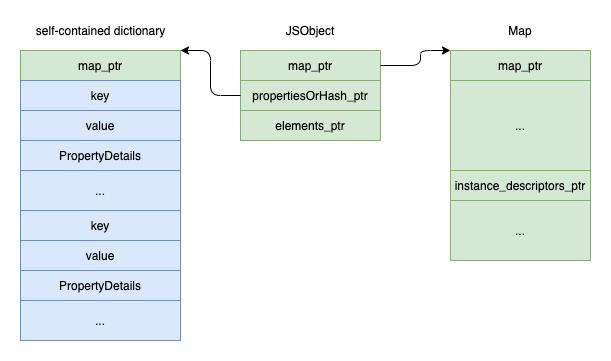
slow 模式不再需要上文提到的 DescriptorArray 了,字段的信息统一都存放在一个字典中
inobject 上限
上文提到 inobject properties 的数量是有上限的,其计算过程大致是:
// 为了方便计算,这里把涉及到的常量定义从源码各个文件中摘出后放到了一起
#if V8_HOST_ARCH_64_BIT
constexpr int kSystemPointerSizeLog2 = 3;
#endif
constexpr int kTaggedSizeLog2 = kSystemPointerSizeLog2;
constexpr int kSystemPointerSize = sizeof(void*);
static const int kJSObjectHeaderSize = 3 * kApiTaggedSize;
STATIC_ASSERT(kHeaderSize == Internals::kJSObjectHeaderSize);
constexpr int kTaggedSize = kSystemPointerSize;
static const int kMaxInstanceSize = 255 * kTaggedSize;
static const int kMaxInObjectProperties = (kMaxInstanceSize - kHeaderSize) >> kTaggedSizeLog2;
根据上面的定义,在 64bit 系统上、未开启指针压缩的情况下,最大数量是 252 = (255 * 8 - 3 * 8) / 8
allow-natives-syntax
为了后面可以通过代码演示,这里需要穿插介绍一下 --allow-natives-syntax 选项,该选项是 v8 的一个选项,开启该选项后,我们可以使用一些私有的 API,这些 API 可以方便了解引擎运行时的内部细节,最初是用于 v8 源码中编写测试案例的
// test.js
const a = 1;
%DebugPrint(a);
通过命令 node --allow-natives-syntax test.js 即可运行上面的代码,其中 %DebugPrint 就是 natives-syntax,而 DebugPrint 则是私有 API 中的一个
更多的 API 可以在 runtime.h 中找到,它们具体的用法则可以通过搜索 v8 源码中的测试案例来了解。另外,DebugPrint 对应的实现在 objects-printer.cc 中
上面的代码运行后显示的内容类似:
DebugPrint: Smi: 0x1 (1) # Smi 我们已经在上文介绍过了
构造函数创建
上文提到 v8 创建对象的时候,会动态选择一个预期值,该值作为 inobject 属性的初始数量,记为 expected_nof_properties,接下来我们看下该值是如何选择的
在 JS 中有两种主要的创建对象的方式:
- 从构造函数创建
- 对象字面量
我们先看从构造函数创建的情况
将字段作为 inobject properties 的技术并不是 v8 首创的,在静态语言的编译中,是常见的属性处理方案。v8 只是将其引入到 JS 引擎的设计中,并针对 JS 引擎做了一些调整
从构造函数创建的对象,因为在编译阶段就能大致获得属性的数量,所以在分配对象的时候,inobject 属性数就可以借助编译阶段收集的信息:
function Ctor1() {
this.p1 = 1;
this.p2 = 2;
}
function Ctor2(condition) {
this.p1 = 1;
this.p2 = 2;
if (condition) {
this.p3 = 3;
this.p4 = 4;
}
}
const o1 = new Ctor1();
const o2 = new Ctor2();
%DebugPrint(o1);
%DebugPrint(o2);
「大致」的含义就是,对于上面的 Ctor2 会认为它有 4 个属性,而不会考虑 condition 的情况
我们可以通过运行上面的代码来测试:
DebugPrint: 0x954bdc78c61: [JS_OBJECT_TYPE]
- map: 0x0954a8d7a921 <Map(HOLEY_ELEMENTS)> [FastProperties]
- prototype: 0x0954bdc78b91 <Object map = 0x954a8d7a891>
- elements: 0x095411500b29 <FixedArray[0]> [HOLEY_ELEMENTS]
- properties: 0x095411500b29 <FixedArray[0]> {
#p1: 1 (const data field 0)
#p2: 2 (const data field 1)
}
0x954a8d7a921: [Map]
- type: JS_OBJECT_TYPE
- instance size: 104
- inobject properties: 10
- elements kind: HOLEY_ELEMENTS
- unused property fields: 8
- enum length: invalid
- stable_map
- back pointer: 0x0954a8d7a8d9 <Map(HOLEY_ELEMENTS)>
- prototype_validity cell: 0x0954ff2b9459 <Cell value= 0>
- instance descriptors (own) #2: 0x0954bdc78d41 <DescriptorArray[2]>
- prototype: 0x0954bdc78b91 <Object map = 0x954a8d7a891>
- constructor: 0x0954bdc78481 <JSFunction Ctor1 (sfi = 0x954ff2b6c49)>
- dependent code: 0x095411500289 <Other heap object (WEAK_FIXED_ARRAY_TYPE)>
上面代码会输出两段 DebugPrint,上面为其中的第一段:
- 紧接着
DebugPrint:打印的是我们传入的对象o1 - 随后的
0x954a8d7a921: [Map]是该对象的 map 信息 - 我们已经介绍过 map 是对象的元信息,因此诸如
inobject properties都记录在其中 - 上面的
inobject properties是10 = 2 + 8,其中 2 是编译阶段收集到的属性数,8 是额外预分配的属性数 - 因为对象 header 中总是有指向
map、propertiesOrHash、elements的三个指针,所以整个对象的大小(instance size)就是headerSize + inobject_properties_size即104 = (3 + (2 + 8)) * 8
大家可以根据上面的过程验证下 %DebugPrint(o2) 的输出
空构造函数
为了避免大家在试验的过程中产生疑惑,下面再解释一下空构造函数时分配的对象大小:
function Ctor() {}
const o = new Ctor();
%DebugPrint(o);
上面的打印结果显示 inobject properties 数量也是 10,按照前文的计算过程,因为编译阶段发现该构造函数并没有属性,数量应该是 8 = 0 + 8 才对
之所以显示 10 是因为,如果编译阶段发现没有属性,那么默认也会给定一个数值 2 作为属性的数量,这么做是基于「大部分构造函数都会有属性,当前没有可能是后续动态添加」的假定
关于上面的计算过程,可以通过 shared-function-info.cc 进一步探究
Class
上文我们都是直接将函数对象当做构造函数来使用的,而 ES6 中早已支持了 Class,接下来我们来看下使用 Class 来实例化对象的情况
其实 Class 只是一个语法糖,JS 语言标准对 Class 的运行时语义定义在 ClassDefinitionEvaluation 一节中。简单来说就是同样会创建一个函数对象(并设置该函数的名称为 Class 名),这样随后我们的 new Class 其实和我们 new FunctionObject 的语义一致
function Ctor() {}
class Class1 {}
%DebugPrint(Ctor);
%DebugPrint(Class1);
我们可以运行上面的代码,会发现 Ctor 和 Class1 都是 JS_FUNCTION_TYPE
我们之前已经介绍过,初始的 inobject properties 数量会借助编译时收集的信息,所以下面的几个形式是等价的,且 inobject properties 数量都是 11(3 + 8):
function Ctor() {
this.p1 = 1;
this.p2 = 2;
this.p3 = 3;
}
class Class1 {
p1 = 1;
p2 = 2;
p3 = 3;
}
class Class2 {
constructor() {
this.p1 = 1;
this.p2 = 2;
this.p3 = 3;
}
}
const o1 = new Ctor();
const o2 = new Class1();
const o3 = new Class2();
%DebugPrint(o1);
%DebugPrint(o2);
%DebugPrint(o3);
在编译阶段的收集的属性数称为「预估属性数」,因为其只需提供预估的精度,所以逻辑很简单,在解解析函数或者 Class 定义的时候,发了一个设置属性的语句就让「预估属性数」累加 1。下面的形式是等价的,都会将「预估属性数」识别为 0 而造成 inobject properties 初始值被设定为 10(上文有讲道过,当 estimated 为 0 时,总是会分配固定的个数 2,再加上预分配 8,会让初始 inobject 数定成 10):
function Ctor() {}
// babel runtime patch
function _defineProperty(obj, key, value) {
if (key in obj) {
Object.defineProperty(obj, key, {
value: value,
enumerable: true,
configurable: true,
writable: true,
});
} else {
obj[key] = value;
}
return obj;
}
class Class1 {
constructor() {
_defineProperty(this, "p1", 1);
_defineProperty(this, "p2", 2);
_defineProperty(this, "p3", 3);
}
}
const o1 = new Ctor();
const o2 = new Class1();
%DebugPrint(o1);
%DebugPrint(o2);
Class1 构造函数中的 _defineProperty 对于目前的预估逻辑来说太复杂了,预估逻辑设计的简单并不是因为从技术上不能分析上面的例子,而是因为 JS 语言的动态性,与为了保持启动速度(也是动态语言的优势)让这里不太适合使用过重的静态分析技术
_defineProperty 的形式其实是 babel 目前编译的结果,结合后面会介绍的 slack tracking 来说,即使这里预估数不符合我们的预期,但也不会有太大的影响,因为我们的单个类的属性个数超过 10 的情况在整个应用中来看也不会是大多数,不过如果我们考虑继承的情况:
class Class1 {
p11 = 1;
p12 = 1;
p13 = 1;
p14 = 1;
p15 = 1;
}
class Class2 extends Class1 {
p21 = 1;
p22 = 1;
p23 = 1;
p24 = 1;
p25 = 1;
}
class Class3 extends Class2 {
p31 = 1;
p32 = 1;
p33 = 1;
p34 = 1;
p35 = 1;
}
const o1 = new Class3();
%DebugPrint(o1);
因为继承形式的存在,很可能经过多次继承,我们的属性数会超过 10。我们打印上面的代码,会发现 inobject properties 是 23(15 + 8),如果经过 babel 编译,则代码会变成:
"use strict";
function _defineProperty(obj, key, value) { if (key in obj) { Object.defineProperty(obj, key, { value: value, enumerable: true, configurable: true, writable: true }); } else { obj[key] = value; } return obj; }
class Class1 {
constructor() {
_defineProperty(this, "p11", 1);
_defineProperty(this, "p12", 1);
_defineProperty(this, "p13", 1);
_defineProperty(this, "p14", 1);
_defineProperty(this, "p15", 1);
}
}
class Class2 extends Class1 {
constructor(...args) {
super(...args);
_defineProperty(this, "p21", 1);
_defineProperty(this, "p22", 1);
_defineProperty(this, "p23", 1);
_defineProperty(this, "p24", 1);
_defineProperty(this, "p25", 1);
}
}
class Class3 extends Class2 {
constructor(...args) {
super(...args);
_defineProperty(this, "p31", 1);
_defineProperty(this, "p32", 1);
_defineProperty(this, "p33", 1);
_defineProperty(this, "p34", 1);
_defineProperty(this, "p35", 1);
}
}
const o1 = new Class3();
%DebugPrint(o1);
上面的 inobject properties 数量只有 14 个,原因是 Class3 的 inobject 属性数预估值、还需要加上其祖先类的 inobject 属性数的预估值,其两个祖先类的预估值都是 2(因为编译期没有收集到数量而默认分配的固定数量 2),因此 Class3 的 inobject 属性预估值就是 6 = 2 + 2 + 2,加上额外分配的 8 个,最后是 14 个
而我们实际的属性数量是 15 个,这就导致第 15 个属性 p35 被分配成了 fast 型,回顾没有经过 babel 编译的代码,所有属性都会是 inobject 型的
最初发现 babel 和 tsc 的编译结果不同,后者未使用 _defineProperty 的形式,以为是 babel 编译实现有瑕疵。后面发现 babel 的结果其实是标准中规定的行为,见 Public instance fields - 实例字段是使用 Object.defineProperty 添加的。对于 tsc 来说,开启 useDefineForClassFields 后可以达到相同的编译结果(在目前的 deno-v1.9 中这个选项被默认开启了)
本来是想说大家可以选择 tsc 的,但现在看来在一些对性能有极致要求的场景下,避免引入编译环节或许是最好的方法
从对象字面量创建
const a = { p1: 1 };
%DebugPrint(a);
运行上面的代码,会发现 inobject properties 数量是 1,这里没有 8 个的预留空间,是因为从对象字面量创建经过的是 CreateObjectLiteral 方法,其内部没有预留空间的策略,而是 直接使用 编译收集的信息,这与从构造函数创建经过的 JSObject::New 方法内部的策略不同
从对象字面量创建会使用字面量中的属性数作为 inobject properties 的数量,因此后续添加的属性会是 fast 型
空对象字面量
和空构造函数的情况类似,空对象字面量的大小也需要另外讨论:
const a = {};
%DebugPrint(a);
运行上面的代码,会发现 inobject properties 数量是 4,这是因为:
- CreateObjectLiteral 内会调用 Factory::ObjectLiteralMapFromCache
- Factory::ObjectLiteralMapFromCache 的逻辑是,当空字面量时,使用
object_function().initial_map()来做成创建对象的模板 object_function()自身的创建在 Genesis::CreateObjectFunction 中,其中的kInitialGlobalObjectUnusedPropertiesCount是 4
所以 4 是一个硬编码的值,当创建空对象的时候,就使用该值作为初始的 inobject properties 的数量
另外 CreateObjectLiteral 源码中也 提及,如果使用 Object.create(null) 创建的对象,则直接是 slow 模式
inobject、fast、slow 之切换
inobject、fast、slow 三种模式的存在,是基于分而治之的理念。对有静态性的场景(比如构造函数创建),则适用 inobject、fast,对动态性的部分,则适用 slow。下面我们来简单看一下三者之间的切换条件
- 在 inobject 配额足够的情况下,属性优先被当成 inobject 型的
- 当 inobject 配个不足的情况下,属性被当成是 fast 型的
- 当 fast 型的配额也不足的情况下,对象整个切换成 slow 模式
- 中间某一步骤中,执行了
delete操作删除属性(除了删除最后一个顺位的属性以外,删除其余顺位的属性都会)让对象整个切换成 slow 模式 - 如果某个对象被设置为另一个函数对象的
property属性,则该对象也会切换成 slow 模式,见 JSObject::OptimizeAsPrototype - 一旦对象切换成 slow 模式,从开发者的角度,就基本可以认为该对象不会再切换成 fast 模式了(虽然引擎内部的一些特殊情况下会使用 JSObject::MigrateSlowToFast 切换回 fast)
上面的切换规则看起来好像很繁琐(并且也可能并不是全部情况),但其实背后的思路很简单,inobject 和 fast 都是「偏静态」的优化手段,而 slow 则是完全动态的形式,当对象频繁地动态添加属性、或者执行了 delete 操作,则预测它很可能未来还会频繁的变动,那么使用纯动态的形式可能会更好,所以切换成 slow 模式
关于 fast 型的配额我们可以稍微了解一下,fast 型是存放在 PropertyArray 中的,这个数组以每次 kFieldsAdded(当前版本是 3)的步长扩充其长度,目前有一个 kFastPropertiesSoftLimit(当前是 12)作为其 limit,而 Map::TooManyFastProperties 中使用的是 >,所以 fast 型目前的配额最大是 15
大家可以使用下面的代码测试:
const obj = {};
const cnt = 19;
for (let i = 0; i < cnt; i++) {
obj["p" + i] = 1;
}
%DebugPrint(obj);
分别设置 cnt 为 4,19 和 20,会得到类似下面的输出:
# 4
DebugPrint: 0x3de5e3537989: [JS_OBJECT_TYPE]
#...
- properties: 0x3de5de480b29 <FixedArray[0]> {
#19
DebugPrint: 0x3f0726bbde89: [JS_OBJECT_TYPE]
#...
- properties: 0x3f0726bbeb31 <PropertyArray[15]> {
# 20
DebugPrint: 0x1a98617377e1: [JS_OBJECT_TYPE]
#...
- properties: 0x1a9861738781 <NameDictionary[101]>
- 上面的输出中,当使用了 4 个属性时,它们都是 inobject 型的
FixedArray[0] - 当使用了 19 个属性时,已经有 15 个属性是 fast 型
PropertyArray[15] - 当使用了 20 个属性时,因为超过了上限,对象整体切换成了 slow 型
NameDictionary[101]
至于为什么 inobject 显示的是 FixedArray,只是因为当没有使用到 fast 型的时候 propertiesOrHash_ptr 默认指向了一个 empty_fixed_array,有兴趣的同学可以通过阅读 property_array 来确认
slack tracking
前文我们提到,v8 中的初始 inobject 属性的数量,总是会多分配一些,目的是让后续可能通过动态添加的属性也可以成为 inobject 属性,以享受到其带来的快速访问效率。但是多分配的空间如果没有被使用一定会造成浪费,在 v8 中是通过称为 slack tracking 的技术来提高空间利用率的
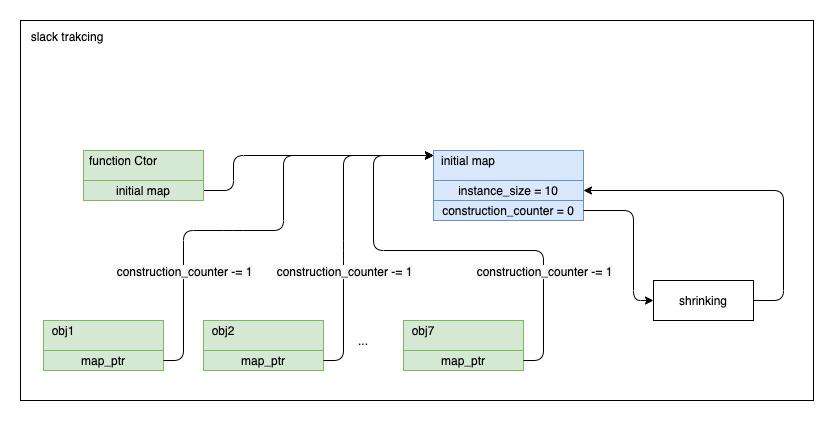
这个技术简单来说是这样实现的:
- 构造函数对象的 map 中有一个
initial_map()属性,该属性就是那些由该构造函数对象创建的模板,即它们的 map - slack tracking 会修改
initial_map()属性中的instance_size属性值,该值是 GC 分配内存空间时使用的 - 当第一次使用某个构造函数 C 创建对象时,它的
initial_map()是未设置的,因此初次会设置该值,简单来说就是创建一个新的 map 对象,并设置该对象的construction_counter属性,见 Map::StartInobjectSlackTracking - construction_counter 其实是一个递减的计数器,初始值是 kSlackTrackingCounterStart 即 7
- 随后每次(包括当次)使用该构造函数创建对象,都会对 construction_counter 递减,当计数为 0 时,就会汇总当前的属性数(包括动态添加的),然后得到最终的 instance_size
- slack tracking 完成后,后续动态添加的属性都是 fast 型的
construction_counter 计数的形式类似下图:
slack tracking 是根据构造函数调用的次数来的,所以使用对象字面量创建的对象无法利用其提高空间利用率,这也侧面说明了上文提到的空字面量的创建,默认预分配的是 4 个而不像构造函数创建那样预留 8 个(因为无法利用 slack tracking 后续提高空间利用率,所以只能在开始的时候就节流)
可以通过 Slack tracking in V8 进一步了解其实现的细节
小结
我们可以将上文的重点部分小结如下:
- 对象的属性有三种模式:inobject,fast,slow
- 三种模式的属性访问效率由左往右递减
- 属性默认使用 inobject 型,超过预留配额后,继续添加的属性属于 fast 型
- 当继续超过 fast 型的配额后,对象整个切换到 slow 型
- 初始 inobject 的配额会因为使用的是「构造函数创建」还是「对象字面量」创建而不同,前者根据编译器收集的信息(大致属性数 + 8,且上限为 252),后者是固定的 4
- 使用
Object.create(null)创建的对象直接是 slow 型 - 对于任意对象 A,在其声明周期内,使用
delete删除了除最后顺位以外的其余顺位的属性,或者将 A 设置为另一个构造函数的prototype属性,都会将对象 A 整个切换为 slow 型 - 目前来看,切换到 slow 型后将不能再回到 fast 型
在实际使用时,我们不必考虑上面的细节,只要确保在有条件的情况下:
- 尽可能使用构造函数的方式创建对象,换句话说是尽可能的减少属性的动态创建。实际上,像这样尽可能让 JS 代码体现出更多的静态性,是迎合引擎内部优化方式以获得更优性能的核心原则,同样的操作包括尽可能的保持变量的类型始终唯一、以避免 JIT 失效等
- 如果需要大量的动态添加属性,或者需要删除属性,直接使用 Map 对象会更好(虽然引擎内部也会自动切换,但是直接用 Map 更符合这样的场景,也省去了内部切换的消耗)
本文简单结合源码介绍了一下 v8 中是如何处理对象的,希望可以有幸作为大家深入了解 v8 内存管理的初始读物
参考资料
- 垃圾回收的算法与实现
- A tour of V8: object representation
- V8 引擎 JSObject 结构解析和内存优化思路
- Fast properties in V8
- Pointer Compression in V8
- Slack tracking in V8
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!