- 以下是我三月里所有面试过的公司问的真实题目
- 后面还有很多没有写答案总结,写了答案的,如果答得不好,请多多指教。
- 我已上岸,希望大家加油!
公司个人问题
- 自我介绍
- 公司团队规模
- 公司的业务
- 你的主要工作
- 前端技术后端技术
- 如何说服上司进行项目重构
- 讲一个你觉得做的不错的项目
- 项目开发流程
- 如何进行项目部署
- 性能监控,数据分析有没有做过
- 主要是通过navigator Timing api进行监控
- 引入的是岳鹰监控平台进行监控
- 团队之间的代码管理和审查
Css
卡片翻转
css盒子模型
盒子模型包括元素的内容,边框(border)、内边距(padding)、外边距(margin)组成 标准盒子模型大小= width(content) + border + padding + margin 怪异盒子大小= width(content+border+padding) + margin
css左右布局的方式
BFC
- 什么是BFC?如何应用?
- Block format context , 块级格式化.上下文
- 一块独立渲染区域 ,内部元素的渲染不会影响边界以外的元素
- 形成BFC的常见条件
- float 不是 none
- position 是 absolute 或 fixed
- overflow 不是 visible
- display是flex inline-block
- BFC的常见应用
- 清除浮动
Js基础
判断数据类型
1. typeof
- 判断所有的值类型(undefined,string,number,boolean,symbol)
- 判断是否是函数 // function
- 判断是否是引用类型 object(null,[1,2,3],{ a : 2 })
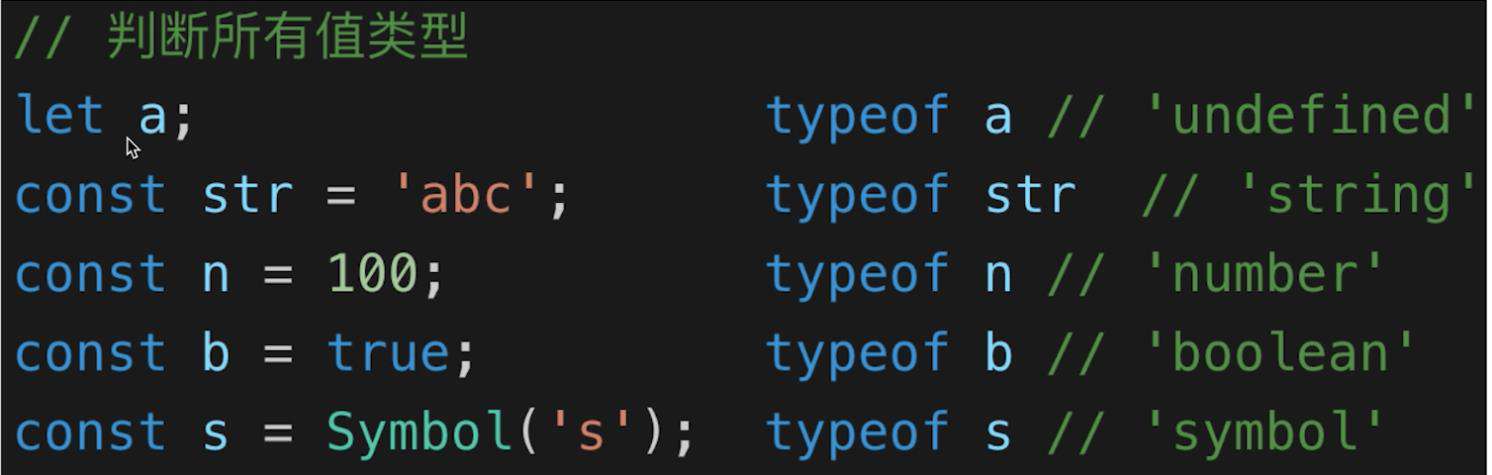

2. instanceof
- 用来判断A是否为B的实例,比如A instanceof B
- instance只能用来判断两个对象是否属于实例关系,而不能判断一个对象实例具体属于哪种类型
- 所以一般用来判断是否是一个数组,[] instanceof Array
3. Object.prototype.toString.call()
developer.mozilla.org/zh-CN/docs/…
- toString()是Object的原型方法,调用该方法,默认返回当前对象的[Class],这是一个内部属性,其格式为[object Xxx],其中Xxx就是对象的类型
- 对于Object对象,直接调用toString()就能返回[object Object],而对于其他对象,则需要通过call/apply来调用才能返回正确的类型信息
let obj = new Object()
obj.toString() // [object Object]
Object.prototype.toString.call('') ; // [object String]
Object.prototype.toString.call(1) ; // [object Number]
Object.prototype.toString.call(true) ; // [object Boolean]
Object.prototype.toString.call(Symbol()); //[object Symbol]
Object.prototype.toString.call(undefined) ; // [object Undefined]
Object.prototype.toString.call(null) ; // [object Null]
Object.prototype.toString.call(new Function()) ; // [object Function]
Object.prototype.toString.call(new Date()) ; // [object Date]
Object.prototype.toString.call([]) ; // [object Array]
Object.prototype.toString.call(new RegExp()) ; // [object RegExp]
Object.prototype.toString.call(new Error()) ; // [object Error]
Object.prototype.toString.call(document) ; // [object HTMLDocument]
Object.prototype.toString.call(window) ; //[object global] window 是全局对象 global 的引用
4. constructor
constructor是原型prototype的一个属性,当函数被定义时,js引擎会为函数添加原型prototype,并且这个prototype中的constructor属性指向函数引用,因此重写prototype会丢失原来的constructor.
注意:
1:null 和 undefined 无constructor,这种方法判断不了。
2:还有,如果自定义对象,开发者重写prototype之后,原有的constructor会丢失,因此,为了规范开发,在重写对象原型时一般都需要重新给 constructor 赋值,以保证对象实例的类型不被篡改。

什么是闭包
- 在内层函数中可以访问到外层函数的作用域就是闭包
箭头函数和普通函数的区别
www.jianshu.com/p/231a6f58e…
- 箭头函数是匿名函数,不能作为构造函数,不能使用new
- 箭头函数不能绑定arguments,取而代之用rest参数...解决
- 箭头函数的this永远指向其上下文的this,没有办改变其指向,普通函数的this指向调用它的对象
- 箭头函数不绑定this,会捕获其所在的上下文的this值,作为自己的this值
简单说一下this指向问题
1、普通函数调用 this指向windows; 2、对象函数调用 this指向这个对象; 3、构造函数调用 this指向当前实例本身(新创建的对象); 4、call和apply,bind调用 传入什么指向什么,传入的参数;(call可以传多个参数,apply可以传二个参数,第二个数组,不然报错TypeError) 5、箭头函数调用 this指向上级作用域的值(当前函数上下文);
Js数组
数组中查找指定元素
juejin.cn/post/687784…
1. includes
developer.mozilla.org/en-US/docs/…
includes() 方法用来判断一个数组是否包含一个指定的值,如果包含则返回 true,否则返回 false。
var a = [1,2,3,4,5,6]
a.includes(2) // true
a.includes(2,3) // false
a.includes(5,-2) // true
a.includes(5,-1) // false
2. indexOf
developer.mozilla.org/en-US/docs/…
indexOf() 方法返回指定元素在数组中的第一个索引,如果不存在,则返回-1。
var array = [2, 5, 9];
array.indexOf(2); // 0
array.indexOf(7); // -1
array.indexOf(9, 2); // 2
array.indexOf(2, -1); // -1
array.indexOf(2, -3); // 0
3. lastIndexOf
developer.mozilla.org/en-US/docs/…
lastIndexOf() 方法返回指定元素在数组中的最后一个的索引,如果不存在则返回 -1。从数组的后面向前查找,从 fromIndex 处开始。
var array = [2, 5, 9, 2];
array.lastIndexOf(2); // 3
array.lastIndexOf(7); // -1
array.lastIndexOf(2, 3); // 3
array.lastIndexOf(2, 2); // 0
array.lastIndexOf(2, -2); // 0
array.lastIndexOf(2, -1); // 3
4. some
developer.mozilla.org/zh-CN/docs/…
some() 方法测试数组中是不是至少有1个元素通过了被提供的函数测试。它返回的是一个 Boolean 类型的值。
function isBiggerThan10(element, index, array) {
return element > 10;
}
[2, 5, 8, 1, 4].some(isBiggerThan10); // false
[12, 5, 8, 1, 4].some(isBiggerThan10); // true
5. every
developer.mozilla.org/zh-CN/docs/…
every() 方法测试一个数组内的所有元素是否都能通过某个指定函数的测试。它返回一个布尔值。
function isBigEnough(element, index, array) {
return element >= 10;
}
[12, 5, 8, 130, 44].every(isBigEnough); // false
[12, 54, 18, 130, 44].every(isBigEnough); // true
6. filter
developer.mozilla.org/zh-CN/docs/…
filter() 方法创建一个新数组, 包含通过所提供函数实现的测试的所有元素。
function isBigEnough(element) {
return element >= 10;
}
var filtered = [12, 5, 8, 130, 35].filter(isBigEnough);
// filtered is [12, 130, 35]
7.find
developer.mozilla.org/zh-CN/docs/…
find() 方法返回数组中满足提供的测试函数的第一个元素的值。否则返回 undefined。
var inventory = [
{name: 'apples', quantity: 2},
{name: 'bananas', quantity: 0},
{name: 'orange', quantity: 5}
];
function findOranges(fruit) {
return fruit.name === 'orange';
}
console.log(inventory.find(findOrange));
// { name: 'orange', quantity: 5 }
8. findIndex
developer.mozilla.org/zh-CN/docs/…
findIndex() 方法返回数组中满足提供的测试函数的第一个元素的索引。若没有找到对应元素则返回-1。
var inventory = [
{name: 'apple', quantity: 2},
{name: 'banana', quantity: 0},
{name: 'orange', quantity: 5}
];
function findOrange(fruit) {
return fruit.name === 'orange';
}
console.log(inventory.findIndex(findOrange));
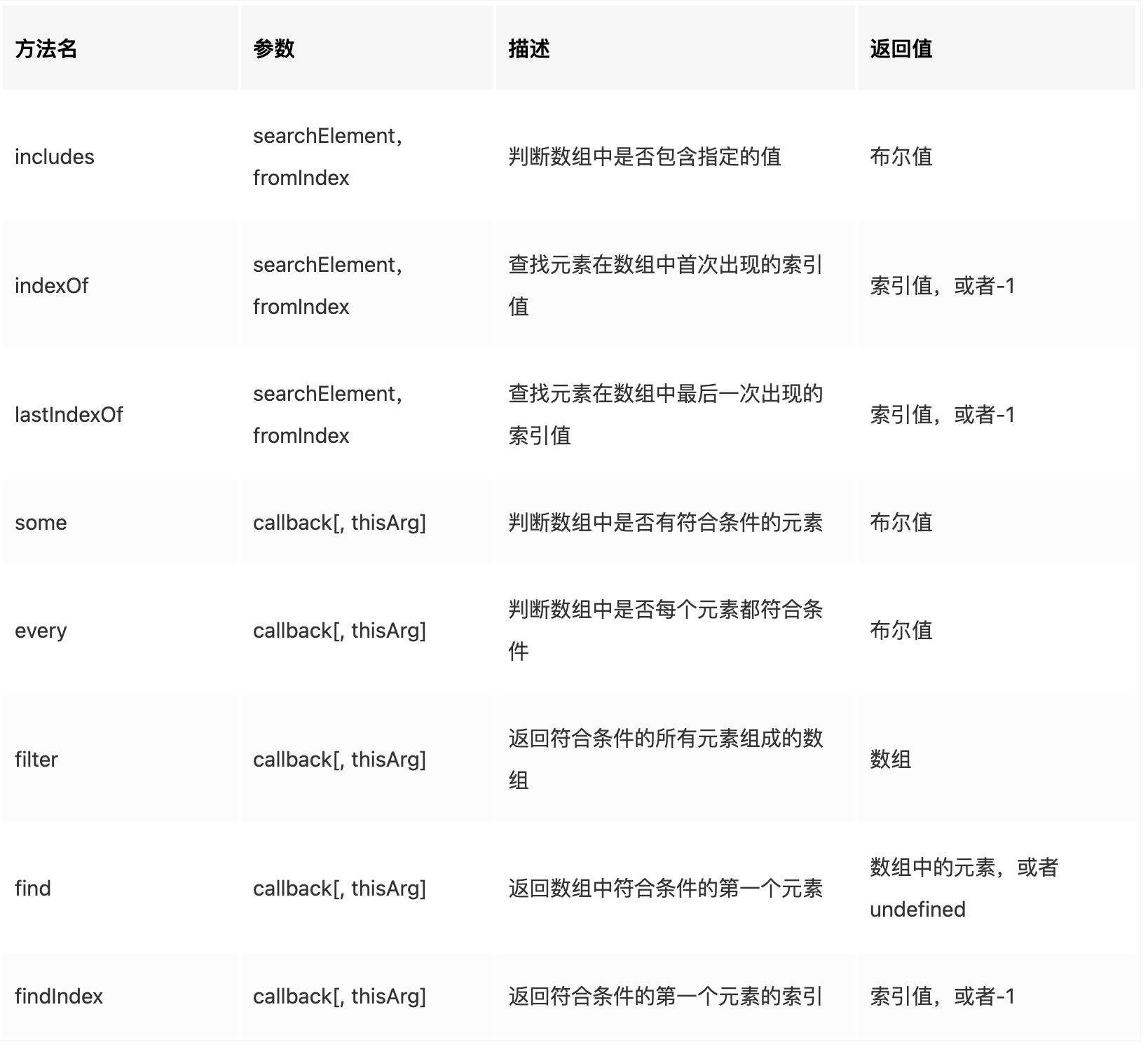
数组对象排序
对以下数据进行排序
var person = [{name:"Rom",age:12},{name:"Bob",age:22},{name:"Ma",age:5},{name:"Tony",age:25}]
sort
developer.mozilla.org/zh-CN/docs/…
- 升序排列是把数据从小到大进行排列(1、2、3、4、5)
- 降序排列是把数据从大到小进行排列(5、4、3、2、1)
person.sort((a,b)=>{ return a.age-b.age})//升序
person.sort((a,b)=>{ return b.age-a.age})//降序
1.如果没有指明 compareFunction ,那么元素会按照转换为的字符串的诸个字符的Unicode位点进行排序。 2.如果指明了 compareFunction ,那么数组会按照调用该函数的返回值排序。即 a 和 b 是两个将要被比较的元素:
a.如果 compareFunction(a, b) 小于 0 ,那么 a 会被排列到 b 之前; b.如果 compareFunction(a, b) 等于 0 , a 和 b 的相对位置不变。(ECMAScript 标准并不保证这一行为,而且也不是所有浏览器都会遵守,例如 Mozilla 在 2003 年之前的版本); c.如果 compareFunction(a, b) 大于 0 , b 会被排列到 a 之前。 d. compareFunction(a, b)必须总是对相同的输入返回相同的比较结果,否则排序的结果将是不确定的。(利用这一特性,可实现随机排序)
for-of 和 for-in 的区别
for-in是ES5标准,遍历的是key(可遍历对象、数组或字符串的key);for-of是ES6标准,遍历的是value(可遍历对象、数组或字符串的value)
for-in
var arr = [1, 2, 4, 5, 7];
for (var index in arr) {
console.log(myArray[index]);
}
for-in弊端
1.index索引为字符串型数字(注意,非数字),不能直接进行几何运算。 2.遍历顺序有可能不是按照实际数组的内部顺序(可能按照随机顺序)。 3.使用for-in会遍历数组所有的可枚举属性,包括原型。例如上例的原型方法method和name属性都会被遍历出来,通常需要配合hasOwnProperty()方法判断某个属性是否该对象的实例属性,来将原型对象从循环中剔除。
- 所以for-in更适合遍历对象,通常是建议不要使用for-in遍历数组。
for (var key in myObject) {
if(myObject.hasOwnProperty(key)){
console.log(key);
}
}
for-of
for-of可以简单、正确地遍历数组(不遍历原型method和name)。 因此建议是使用for-of遍历数组,因为for-of遍历的只是数组内的元素,而不包括数组的原型属性method和索引name。
var myArray = [1, 2, 4, 5, 6, 7];
myArray.name = "数组";
myArray.getName = function() { return this.name; }
for (var value of myArray) {
console.log(value);
}
区别总结
- for in遍历的是数组的索引(即键名),而for of遍历的是数组元素值。
- for-in总是得到对象的key或数组、字符串的下标。
- for-of总是得到对象的value或数组、字符串的值,另外还可以用于遍历Map和Set。
数组去重
segmentfault.com/a/119000001…
1. ES6 Set去重
function unique (arr) {
return Array.from(new Set(arr))
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {}, {}]
// 简化
[...new Set(arr)]
2. for嵌套for,然后splice去重
{}和NaN无法去重
function unique(arr) {
for (let i = 0; i < arr.length; i++) {
for (let j = i + 1; j < arr.length; j++) {
if (arr[i] === arr[j]) {
arr.splice(j, 1)
j-- // 删除一个数据,索引关系变了,需要减1找到没有判断过的那个数据
}
}
}
return arr
}
var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}]
console.log(unique(arr)) //NaN和{}没有去重
3. indexOf去重
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('is not array')
return
}
let array = []
for (let i = 0; i < arr.length; i++) {
if (array.indexOf(arr[i]) === -1) {
array.push(arr[i])
}
}
return array
}
var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}]
console.log(unique(arr)) // [1, "true", true, 15, false, undefined, null, NaN, NaN, "NaN", 0, "a", {…}, {…}] //NaN、{}没有去重
4. includes去重
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return
}
var array =[];
for(var i = 0; i < arr.length; i++) {
if( !array.includes( arr[i]) ) {//includes 检测数组是否有某个值
array.push(arr[i]);
}
}
return array
}
var arr = [1,1,'true','true',true,true,15,15,false,false, undefined,undefined, null,null, NaN, NaN,'NaN', 0, 0, 'a', 'a',{},{}];
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}] //{}没有去重
5. filter + hasOwnProperty去重(可以去重所有)
function unique(arr) {
let obj = {}
return arr.filter((item, index, arr) => {
console.log(typeof item + item)
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)
})
}
var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}]
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}] //所有的都去重了
// if (obj.hasOwnProperty(typeof item + item)) {
// return false
// } else {
// obj[typeof item + item] = true
// return obj[typeof item + item]
// }
// if (!obj.hasOwnProperty(typeof item + item)) {
// obj[typeof item + item] = true
// return obj[typeof item + item]
// }
6. filter + indexOf
function unique(arr) {
return arr.filter((item, index, arr) => {
//当前元素,在原始数组中的第一个索引==当前索引值,否则返回当前元素
return arr.indexOf(item,0) === index
})
}
var arr = [1, 1, 'true', 'true', true, true, 15, 15, false, false, undefined, undefined, null, null, NaN, NaN, 'NaN', 0, 0, 'a', 'a', {}, {}]
console.log(unique(arr))
//[1, "true", true, 15, false, undefined, null, "NaN", 0, "a", {…}, {…}]
Js进阶
深拷贝和浅拷贝的区别
拷贝对象
const obj1 = {
age: 20,
name: 'xxx',
address: {
city: 'beijing'
},
arr: ['a', 'b', 'c']
}
浅拷贝:
- 只拷贝第一层的对象的属性
- 是对对象地址的复制,并没有开辟新的栈
- 复制的结果是两个对象指向同一个地址,修改其中一个对象的属性,则另一个对象的属性也会改变
for...in实现
function simpleCopy(obj) {
// 判断结果是对象还是数组
let result = Array.isArray(obj) ? [] : {}
for (let i in obj) {
// for...in遍历的是key
// console.log(i)
result[i] = obj[i]
}
return result
}
let obj2 = simpleCopy(obj1)
console.log(obj2)
Object.assign实现
let obj2 = Object.assign(obj1)
console.log(obj2)
obj2.address.city = 'shanghai'
obj2.arr[0] = 'a1'
console.log(obj1.address.city)
console.log(obj1.arr[0])
直接赋值
深拷贝:
- 递归拷贝所有层级的属性,
- 是开辟新的栈
- 两个对象对应两个不同的地址,修改一个对象的属性,不会改变另一个对象的属性
递归实现
function deepClone(obj) {
// 判断是否是对象,不是对象,返回结果(返回值类型)
// obj == null判断了null和undefined两种情况 null==undefined
if (typeof obj !== 'object' || obj == null) {
return obj
}
// 初始化结果数据,如果是数组赋值为[],否则为{}
let result = Array.isArray(obj) ? [] : {}
for (let key in obj) {
// 判断是否是自己的属性方法,而不是原型属性方法
// 如果是递归复制
if (obj.hasOwnProperty(key)) {
result[key] = deepClone(obj[key])
}
}
return result
}
let obj2 = deepClone(obj1)
console.log(obj2)
obj2.address.city = 'shanghai'
obj2.arr[0] = 'a1'
console.log(obj1.address.city)
console.log(obj1.arr[0])
function deepClone(obj){
let objClone = Array.isArray(obj)?[]:{};
if(obj && typeof obj==="object"){
for(key in obj){
if(obj.hasOwnProperty(key)){
//判断ojb子元素是否为对象,如果是,递归复制
if(obj[key]&&typeof obj[key] ==="object"){
objClone[key] = deepClone(obj[key]);
}else{
//如果不是,简单复制
objClone[key] = obj[key];
}
}
}
}
return objClone;
}
let a=[1,2,3,4],
b=deepClone(a);
a[0]=2;
console.log(a,b);
Reflect法
function isObject(obj) {
if (typeof obj !== 'object' || obj == null) {
return false
}
return true
}
function deepClone(obj) {
// 如果Reflect.ownKeys()方法的第一个参数不是对象,会报错。
if (!isObject(obj)) {
throw new Error('obj 不是一个对象')
}
let result = Array.isArray(obj) ? [...obj] : { ...obj }
Reflect.ownKeys(result).forEach(key => {
console.log(key)
// 是对象进行递归遍历,不是则直接赋值
result[key] = isObject(obj[key]) ? deepClone(obj[key]) : obj[key]
})
return result
}
let obj2 = deepClone(obj1)
console.log(obj2)
JSON实现
缺点: 无法实现对对象中方法的深拷贝,会显示为undefined
function deepClone2(obj) {
var _obj = JSON.stringify(obj),
objClone = JSON.parse(_obj);
return objClone;
}
lodash函数库实现深拷贝
let result = _.cloneDeep(test)
封装的通用 js 函数有哪些
判空、格式化日期、防抖节流、本地存储、axios二次封装、获取url参数、生成随机数、await处理promise返回参数、判断浏览器环境手机系统信息、校验函数
简单介绍下js垃圾回收机制
www.cnblogs.com/fundebug/p/…
介绍
一般来说没有被引用的对象就是垃圾,就是要被清除, 有个例外如果几个对象引用形成一个环,互相引用,但根访问不到它们,这几个对象也是垃圾,也要被清除。 基本的垃圾回收算法称为**“标记-清除”**,定期执行以下“垃圾回收”步骤:
- 垃圾回收器获取根并**“标记”**(记住)它们。
- 然后它访问并“标记”所有来自它们的引用。
- 然后它访问标记的对象并标记它们的引用。所有被访问的对象都被记住,以便以后不再访问同一个对象两次。
- 以此类推,直到有未访问的引用(可以从根访问)为止。
- 除标记的对象外,所有对象都被删除。
js垃圾回收器的性能
因为js垃圾回收器是每隔一个周期就执行一次垃圾回收。 如果为变量分配的内存数量不大的话,那么垃圾回收器的回收工作量就不大。但是,当垃圾回收器的工作量过大的时候,就很可能会出现卡顿的情况。
js内存机制
event loop(事件循环/事件轮询)
什么是event loop
- js是单线程运行的
- 异步就要基于回调来实现
- event loop就是异步实现的原理
event loop过程
整个过程包含
- Call stack(调用栈)、
- WebApis(浏览器api)、
- Callback Queue(回调函数队列)、
- event loop(事件轮询)
过程1
- 同步代码一步一步放在call stack
- 遇到异步,会先记录,等待时机(可能是同步代码执行完)
- 时机到了,就移动到callback Queue
过程2
- 如果同步代码执行完了,Event loop开始工作
- 轮询查找callback queue,如有则移动到call stack执行
- 然后继续轮询查找
Vue基础
1. vue 组件通信
2. vue 按需加载组件
- 异步组件
- import函数
- 按需加载,异步加载大组件
<!-- 异步组件 -->
<FormDemo v-if="showFormDemo"/>
<button @click="showFormDemo = true">show form demo</button>
components: {
FormDemo: () => import('../BaseUse/FormDemo'),
},
data() {
return {
showFormDemo: false,
}
}
- 按需加载路由组件
{
path: '/home',
name: 'Home',
component: () => import(/* webpackChunkName: "tabbar" */ '@/views/tabBar/home/index.vue'),
meta: { title: '首页', keepAlive: false, showTab: true } as IRouterMeta
},
3. 封装的通用组件有哪些
4. 组件如何实现 v-model
- 自定义v-model
- 主要是组件上的model属性(prop,event)
- prop是要绑定的数据
- event要绑定的事件
自定义 v-model -->
<!-- <p>{{name}}</p>
<CustomVModel v-model="name"/>
<template>
<!-- 例如:vue 颜色选择 -->
<input type="text"
:value="text1"
@input="$emit('change1', $event.target.value)"
>
<!--
1. 上面的 input 使用了 :value 而不是 v-model
2. 上面的 change1 和 model.event1 要对应起来
3. text1 属性对应起来
-->
</template>
<script>
export default {
model: {
prop: 'text1', // 对应 props text1
event: 'change1'
},
props: {
text1: String,
default() {
return ''
}
}
}
</script>
5. computed和watch的区别
计算属性computed
- 支持缓存,只有依赖数据发生改变,才会重新进行计算
- 不支持异步,当computed内有异步操作时无效,无法监听数据的变化
3.computed 属性值会默认走缓存,计算属性是基于它们的响应式依赖进行缓存的,也就是基于data中声明过或者父组件传递的props中的数据通过计算得到的值 4. 如果一个属性是由其他属性计算而来的,这个属性依赖其他属性,是一个多对一或者一对一,一般用computed 5.如果computed属性属性值是函数,那么默认会走get方法;函数的返回值就是属性的属性值;在computed中的,属性都有一个get和一个set方法,当数据变化时,调用set方法。
侦听属性watch
- 不支持缓存,数据变,直接会触发相应的操作;
2.watch支持异步; 3.监听的函数接收两个参数,第一个参数是最新的值;第二个参数是输入之前的值; 4. 当一个属性发生变化时,需要执行对应的操作;一对多; 5. 监听数据必须是data中声明过或者父组件传递过来的props中的数据,当数据变化时,触发其他操作,函数有两个参数, immediate:组件加载立即触发回调函数执行, deep: 深度监听,为了发现对象内部值的变化,复杂类型的数据时使用,例如数组中的对象内容的改变,注意监听数组的变动不需要这么做。注意:deep无法监听到数组的变动和对象的新增,参考vue数组变异,只有以响应式的方式触发才会被监听到。 6.当需要在数据变化时执行异步或开销较大的操作时,这个方式是最有用的
使用场景
computed 当一个属性受多个属性影响的时候就需要用到computed 最典型的例子: 购物车商品结算的时候 watch 当一条数据影响多条数据的时候就需要用watch 搜索数据
生命周期有什么,哪些在页面第一次加载执行
第一次渲染
- beforeCreate
- created
- beforeMount
- mounted
更新
- beforeUpdate
- updated
销毁
- beforeDestroy
- destroyed
keep-live
- activated 组件激活
- deactivated 组件停用
什么时候进行异步请求
- mounted
- dispatch一个action
vue修饰符有哪些
- 表单修饰符
- .lazy 懒加载
- .trim 去除首尾空格
- .number 转换成number
- 事件修饰符
- .stop 阻止冒泡
- .prevent 阻止默认行为
- .self 触发自身元素
- .once 只触发一次
- .capture 事件捕获阶段
- .passive 懒触发事件
- **.native **把一个vue组件转化为一个普通的HTML标签,触发事件
- 鼠标按键修饰符
- .left 左键点击
- .right 右键点击
- .middle 中键点击
- 键值修饰符
- **.keyCode **对应ASCII码
- v-bind修饰符(实在不知道叫啥名字)
- **.sync **对props进行双向绑定
data为什么是一个函数
- .vue组件编译完之后实际上是一个Class
- 每次使用这个组件相当于是对组件的实例化
- 实例化的时候去执行data
- 如果data不是一个函数,那么每一个组件实例的数据都一样的,也就数据共享了
- 一个组件的数据进行修改时,其他组件数据也会进行修改
v-show和v-if的区别
- v-show通过CSS display控制显示和隐藏
- v-if组件真正的渲染和销毁,而不是显示和隐藏
- 模板编译成render,with语法,转换成了三元运算
- 频繁切换显示状态用v-show , 否则用v-if
v-for为什么用key
www.jianshu.com/p/4bd5e745c…
- 必须用key ,且不能是index和random(随机数)
- diff算法中通过tag和key来判断,是否是sameNode
- 减少渲染次数,提升渲染性能
key重复了会怎么样
- 如果key重复了,在进行增加删除操作时,索引和数组数据关系会错乱
- diff算法会认为当前节点后的所有节点都进行了更新,会造成多次重复渲染
defineProperty重写了数组方法会不会影响正常使用数组方法
- 不会
- 通过Object.create()创建一个新的对象,原型指向数组原型
- 扩展的数组方法执行时调用的是数组原型上的方法,以及视图更新
keep-live的属性和生命周期
include- 字符串或正则表达式。只有名称匹配的组件会被缓存。exclude- 字符串或正则表达式。任何名称匹配的组件都不会被缓存。max- 数字。最多可以缓存多少组件实例。
1.activated:页面第一次进入的时候,钩子触发的顺序是created->mounted->activated 2.deactivated :页面退出的时候会触发deactivated,当再次前进或者后退的时候只触发activated
components的name有什么用,场景
blog.csdn.net/weixin_3901…
- 当使用组件递归调用时,被递归调用的组件必须定义name属性,因为在组件里面调用自己时,不是使用的在components里注册的组件,而是使用根据name属性查找组件
- keep-alive包裹动态组件时,会缓存不活动的组件实例,会出现include和exclude属性,包含或者排除指定name组件
- 封装通用组件时,可以通过获取组件实例的name属性,定义为组件名字,方便管理
- vue-tools插件调试时没有name属性会报错或警告
如何进行用户鉴权,设计动态路由
juejin.cn/post/684490… addrouter的坑 blog.csdn.net/weixin_3417…
Vue原理
$nexttick内部实现
computed和watch内部实现原理
router的路由方式以及实现原理
- hash - window.onhashchange
- H5 history - history.pushState 和 window.onpopstate
- H5 history 需要后端支持
event-bus实现原理,自己设计一个on,emit
性能优化
1. 性能优化有哪些
通用的性能优化:
- 让加载更快:
- 减少资源体积:代码压缩
- 减少访问次数:合并代码,SSR服务器渲染,缓存(http缓存,本地缓存)
- 使用更快的网络:CDN
- 让渲染更快
- CSS放在head,JS放在body最下面
- 尽早执行JS,用DOMContentLoaded触发
- 懒加载(图片懒加载,上滑加载更多,分页)
- 对DOM查询进行缓存
- 频繁DOM操作,合并到一起插入DOM结构
- 防抖debounce和节流throttle
Vue性能优化
- 合理使用v-show和v-if
- 合理使用computed和watch
- v-for时加唯一key,避免和v-if同时使用
- 自定义事件、DOM事件及时销毁
- 合理使用异步组件
- 合理使用keep-live
- data层级不要太深
- 使用vue-loader在开发环境做模板编译
- 使用SSR
WebPack性能优化
www.yuque.com/docs/share/… 《Webpack和babel面试题》
2. 防抖和节流的区别
www.jianshu.com/p/c8b86b09d… zhuanlan.zhihu.com/p/72923073 segmentfault.com/a/119000001…
防抖debounce
对于短时间内连续触发的事件(如滚动事件),防抖的含义就是让某个时间期限(如上面的1000毫秒)内,事件处理函数只执行一次。 所谓防抖,就是指触发事件后在 n 秒内函数只能执行一次,如果在 n 秒内又触发了事件,则会重新计算函数执行时间
- 持续触发不执行
- 不触发一段时间后再执行
<input type="text" id="input1">
const input1 = document.getElementById('input1')
// 不能用箭头函数
input1.addEventListener('keyup', debounce(function (e) {
console.log(e.target)
console.log(input1.value)
}, 600))
// 防抖
function debounce(fn, delay = 500) {
// timer 是闭包中的
let timer = null
return function () {
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
fn.apply(this, arguments)
timer = null
}, delay)
}
}
节流throttle
如果短时间内大量触发同一事件,那么在函数执行一次之后,该函数在指定的时间期限内不再工作,直至过了这段时间才重新生效。 节流的意思是让函数有节制地执行,而不是毫无节制的触发一次就执行一次。什么叫有节制呢?就是在一段时间内,只执行一次。
- 持续触发并不会执行多少次
- 到一定时间再去执行
<div id="div1" draggable="true">可拖拽<div>
const div1 = document.getElementById('div1')
div1.addEventListener('drag', throttle(function (e) {
console.log(e.offsetX, e.offsetY)
}))
// 节流
function throttle(fn, delay = 100) {
let timer = null
return function () {
if (timer) {
return
}
timer = setTimeout(() => {
fn.apply(this, arguments)
timer = null
}, delay)
}
}
应用实例
resize、scroll、mousemove、输入框持续输入,将输入内容远程校验、多次触发点击事件
工程化
git rebase 和 git merge 有啥区别
www.jianshu.com/p/4079284dd…
手写题
大写转小写小写转大写
Array.prototype.map.call(str,a=>a.toUpperCase(a)==a?a.toLowerCase():a.toUpperCase()).join('');
function upLower(str) {
return str.split('').map(item => {
console.log(item)
return item.toUpperCase() === item ? item.toLowerCase() : item.toUpperCase()
})
}
console.log(upLower('ABc'))
算法题
1. 找出数组中出现次数最多的数
// 找出数组中出现次数最多的数
const arr = [1, 2, 3, 4, 5, 2, 1]
function fn(arr) {
let map = new Map()
let maxIndex = 0
for (let i = 0; i < arr.length; i++) {
if (!map.get(arr[i])) {
map.set(arr[i], 1)
} else {
map.set(arr[i], map.get(arr[i]) + 1)
}
maxIndex = Math.max(maxIndex, map.get(arr[i]))
}
let result = []
for (let [key, value] of map) {
if (value === maxIndex) {
result.push(key)
}
}
return result
}
console.log(fn(arr))
- 前端跨域的方式
- cors
- 数据劫持
- diff算法,虚拟DOM真实DOM、
- html5、css3新特性
- es6新特性
- webpack常见loader
- 原型链
- es5实现继承、es6实现、继承、
- 2个手写代码:
- 深拷贝
- URL字符串转换成对象
- 原理:Vue框架的东西问的比较多
- 赋值组件通信
- 组件定义钩子鉴定,怎么执行
- promise原理
- vuex是什么
- 小程序的页面通信
- 小程序的性能优化(页面加载太慢怎么办)
- 小程序的数据存储方式
- 小程序直播
- 小程序的双向绑定和vue的双向绑定区别
- 小程序用户鉴权方式(如何判断用户是否登陆)
- token,token解析,token的加密方式
- 你会用uniapp吗
- cookie和storage的区别
- set是用来做什么的
- Generator 函数
- promise和await的区别,解决了什么问题
- ajax是通过什么api实现的
- Reflect
- 数组的方法有哪些,some和every的区别
- vuex刷新页面之后没有数据了怎么办
- 跨域如果不看控制台,如何判断
- 公司团队规模
- 公司的业务
- 前端技术后端技术
- 如何说服上司进行项目重构
- 讲一个你觉得做的不错的项目
- 项目开发流程
- 你的主要工作
- 如何进行项目部署
- 性能监控,数据分析有没有做过
- 团队之间的代码管理和审查
- git用的merge还是base
- 20000s不用api换算成时分秒 求模 求余
- 技术选型你有做过哪些工作
- Eslint使用的规范
- v-for如果没有加key的话会报错吗
- 你有做过哪些组件的开发
- 使用第三方库封装的组件,你是如何保证它的灵活性的,比如富文本的封装
- 如果一个搜索组件,我需要两个或多个输入框,如果保证灵活性
- 传入options,遍历options然后渲染,这里面会不会有一些坑
- Vue3和Vue2有什么区别
- 什么是重排和重绘
- flex有哪些属性,子元素flex的三个属性都是什么意思
- flex处理列表换行
- css中有哪些属性可以继承
- Es6常用的属性方法
- let、const和var的区别
- 箭头函数和普通函数的区别
- this指向问题
- 使用asyn/await如何进行错误处理
- 宏任务和微任务的区别
- 常用的生命周期分别做什么
- addEventListenter和传统的事件监听的区别
- v-for的key有什么作用,用index行不行
- 虚拟dom是什么
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!