起步
学了一段时间的three.js之后,就可以尝试做一个VR全景效果出来。
当时已经靠近2020年的年底了,那就做一个过年的场景效果吧,就类似于网页上的VR全景

那就要有一个目标,VR全景需要确定一个地点,我身处在江南,那就拿江南的小镇来做three.js的背景布局啦! 而江南小镇繁多,但与互联网有关的恐怕典型就是乌镇了,地点get
下面先提前展示一下效果:
在2020年年底已经完成了效果的制作,因为不能上传太大的图片,所以gif制作时帧图被我删减了,看起来有些卡顿
项目可在网盘中下载:pan.baidu.com/s/1cmDsGEUl…
提取码: yvjq
效果:


布局
three.js需要一个场景,这个场景的制作是以Scene的background属性来设置的,这样的设置能够让摄像头不超出背景,如果只是把摄像头camera放在一个立方体盒子中,就可能出现“穿模”的现象
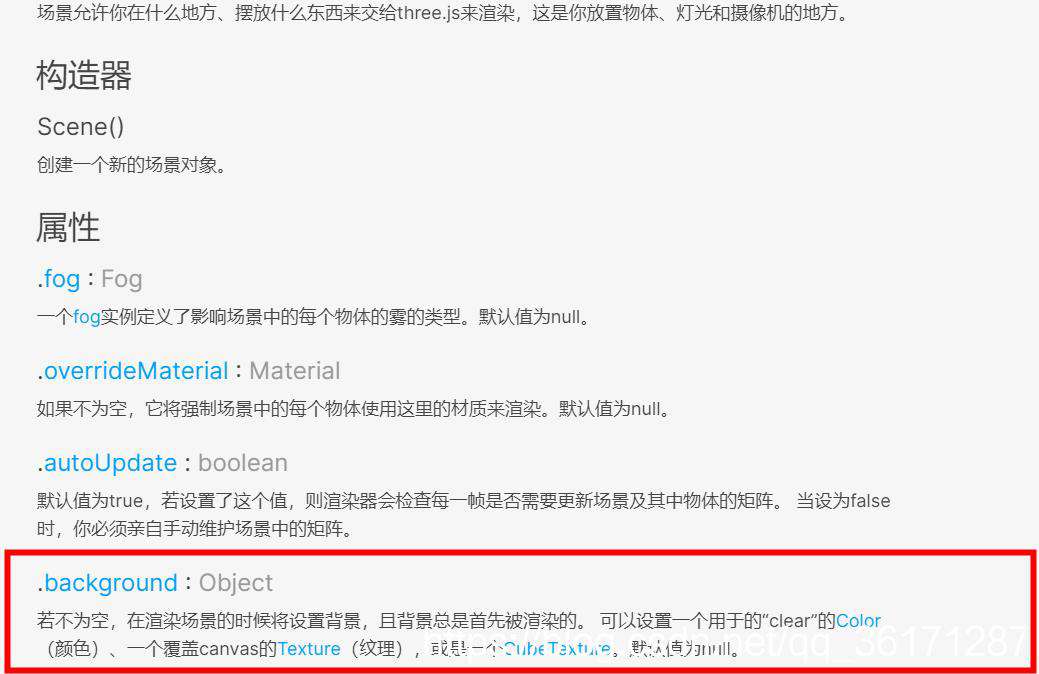
场景可以使用THREE.CubeTextureLoader设置为:
var scene = new THREE.Scene();
scene.background = new THREE.CubeTextureLoader()
.setPath( 'img/' ) // 地址
//图片 顺序为 前 后 上 下 左 右
.load( [ 'w04.png', 'w05.png', 'w06.png', 'w02.png', 'w01.png', 'w03.png' ] );
图片 ----- 在本文最后
不过我提供的图片上传到CSDN会出现水印,如果想要无水印的图片也可以从百度网盘中项目中找,或者通过我之后的方法去获取适合的图片(python爬虫获取网上的图片)
场景布置好了之后,如果想要左右旋转查看可以使用OrbitControls.js
<script src="js/OrbitControls.js" type="text/javascript" charset="utf-8"></script>
// 鼠标控件
var controls = new THREE.OrbitControls(camera, render.domElement); //创建控件对象
controls.update(); //更新方法,写在动画方法内
图片的获取 (python)
制作VR场景对图片的要求很高,虽然场景的实质是一个立方体盒子,但是立方体六个面上的图片之间需要无缝衔接,并且我选择了乌镇作为背景,所以我首选是从网上找图片,从网站上“偷”图

被我不幸选中的网站 -------- 全景视觉
 我选择的场景:乌镇 - 西山风景区
我选择的场景:乌镇 - 西山风景区
但是该怎么盗图呢,场景中的标签是canvas,不能直接复制下来图片
这里就可以看network中对方服务器提供的图片了,又一次计划通,哈哈哈
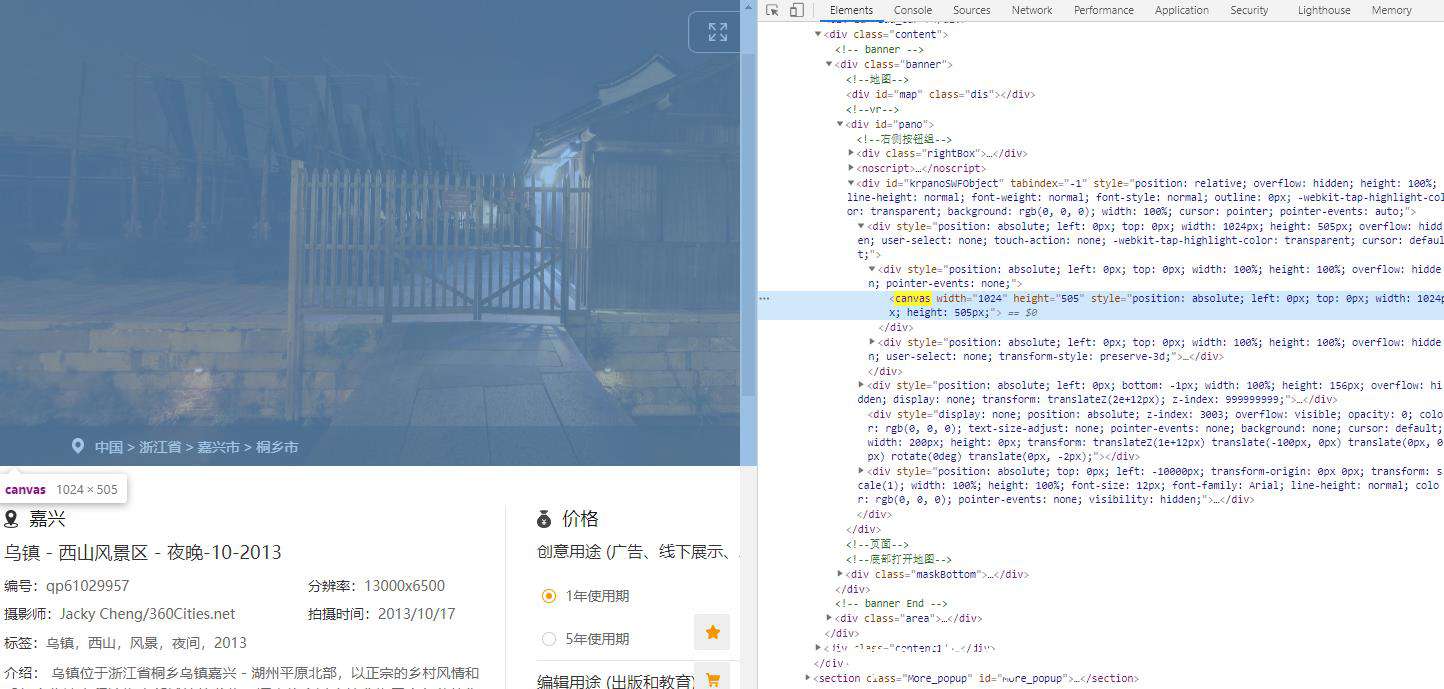
但是对方怎么可能不防备一手,六面的图片被切碎了,一张图片切成了9份(这也是我后来爬下图片重组后才发现的)。 九等分的防盗…

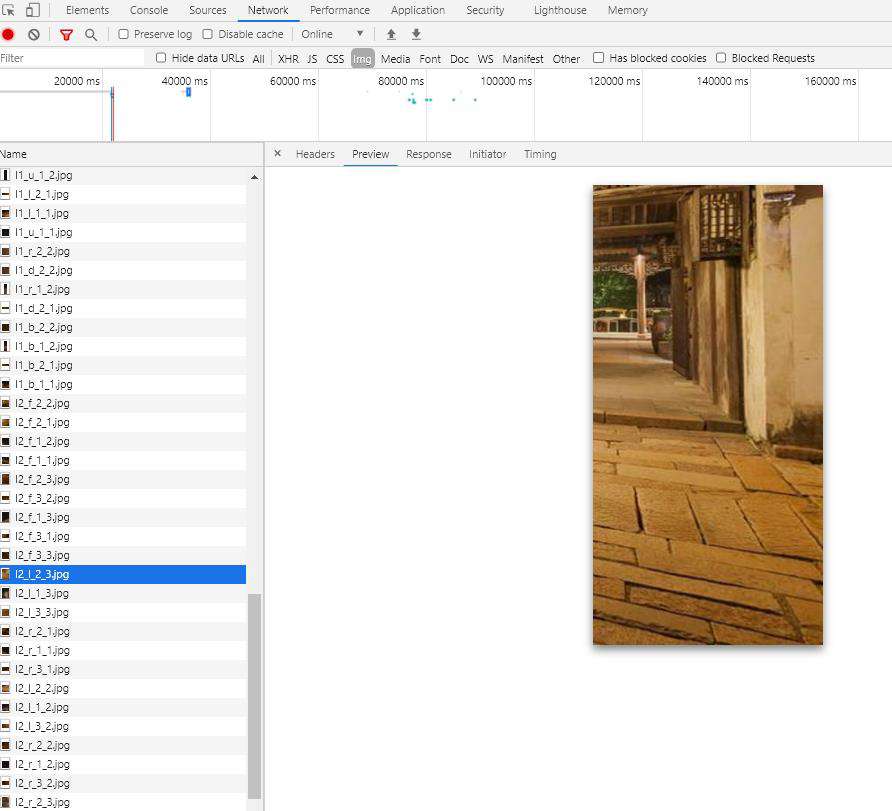
当时我一脸懵,哇,那要怎么办,用鼠标点击一张张下载下了不到10张我就受不了了,下载的全部删除。
那就选个省力些的方法,不会python的前端程序员不是一个好的摸鱼专家。
开始python盗图之路:
first
选择图片,查看这些图片URL之间的规律,这些图片必然有其规律
看了几张之后,我发现图片有一个共同的前缀: https://360.quanjing.com/ul/nd/QP61029957/
之后的是由[‘r’,‘l’, ‘u’, ‘d’, ‘b’, ‘f’] 六个字母中某一个组成
之后组成分析后为[’/l1/1/l1_’, ‘/l2/1/l2_’, ‘/l1/2/l1_’, ‘/l2/2/l2_’, ‘/l1/3/l1_’, ‘/l2/3/l2_’]中的某一个
最后是图片的名称后两位 1_1 到 3_3 之间
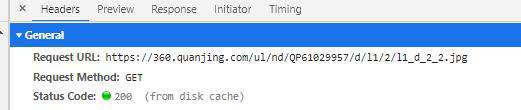
这样就能写出遍历所有图片URL地址的方法了
arr = []
def getArr():
rootPath = 'https://360.quanjing.com/ul/nd/QP61029957/';
for i in ['r','l', 'u', 'd', 'b', 'f']:
for j in ['/l1/1/l1_', '/l2/1/l2_', '/l1/2/l1_', '/l2/2/l2_', '/l1/3/l1_', '/l2/3/l2_']:
for z in range(1,4):
for k in range(1,4):
arr.append(rootPath + i + j + i + "_" + str(z) + "_" + str(k) + ".jpg" )
# print(arr)
second
知道了图片的URL,那就好办了,python爬虫最擅长的就是访问URL地址了
在python中存在一个urllib库,可以直接通过urllib.request方法的urlretrieve去完成下载步骤。
使用此方法时需要给定一个下载后图片存储的地址
以下直接上python爬虫的代码:
import requests
import re
import time
import random
import urllib.request
import os
arr = []
def getArr():
rootPath = 'https://360.quanjing.com/ul/nd/QP61029957/';
for i in ['r','l', 'u', 'd', 'b', 'f']:
for j in ['/l1/1/l1_', '/l2/1/l2_', '/l1/2/l1_', '/l2/2/l2_', '/l1/3/l1_', '/l2/3/l2_']:
for z in range(1,4):
for k in range(1,4):
arr.append(rootPath + i + j + i + "_" + str(z) + "_" + str(k) + ".jpg" )
def getimg(arr,topath):
for url in arr:
# 把图片下载到本地存储
path = os.path.join(topath, url.rsplit("/",maxsplit=1)[1])
print(path)
try:
urllib.request.urlretrieve(url, filename=path)
except Exception as e:
print(e)
# time.sleep(1)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'
}
getArr()
toPath = r'E:\工作文件04\图片素材\乌镇'
getimg(arr, toPath)
爬取下来的图片:
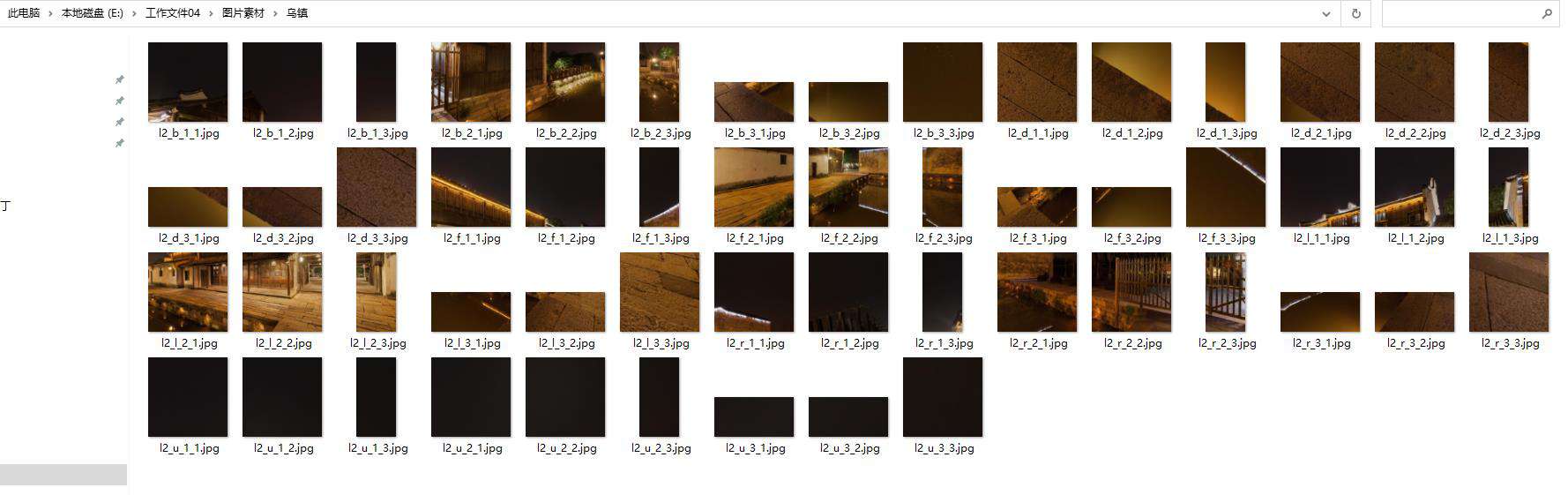
third
但是盗下来的图是碎的怎么办,three.js中CubeTextureLoader方法参数只能传递6张图片,不能把这一堆碎图全部传进去
接下来就只能把图片重新组合起来了
- 路子1: 使用ps把图片一张张拼接起来。但是我是一个懒人,这样做好像效率太低了,而且图片也是有规律的,那肯定有更方便的方法呀
- 路子2: 使用canvas拼接图片,然后把canvas中的复制下来
方法:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>canvas合成图片</title>
<style type="text/css">
#app {
margin: 80px;
border: 1px solid black;
}
#aa{
width: 500px;
height: 400px;
}
</style>
</head>
<body>
<canvas id="app" width="1280" height="1280">
</canvas>
<button onclick="createImg()">下载</button>
<img id="aa" />
<script type="text/javascript">
var abc = ['l2_b_', 'l2_d_', 'l2_f_', 'l2_l_', 'l2_r_', 'l2_u_'];
var imgSrcArray = [];
for (var i = 0; i < abc.length; i++) {
for (var j = 1; j < 4; j++) {
for (var k = 1; k < 4; k++) {
// 图片地址,前缀可以是碎图存放的地方
let jpgsrc = '../img/wuzhen/' + abc[i] + j + '_' + k + '.jpg';
imgSrcArray.push(jpgsrc);
}
}
}
var canvas = document.getElementById('app');
var ctx = canvas.getContext('2d');
// 定义一个图片对象
function ImageDraw(x, y, src, callback) {
this.img = new Image();
this.img.src = src;
var self = this;
this.x = x;
this.y = y;
this.img.onload = function(){
console.log(self.img, self.x, self.y)
ctx.drawImage(self.img, self.x, self.y);
ctx.save();
if(typeof callback == "function") callback();
}
}
function createImg(){
var strDataURI = canvas.toDataURL("image/png"); //toDataURL方法可以将canvas内容变成图片
var dataImg = new Image();
dataImg.src = strDataURI; //strDataURI是组合出的图片地址
document.getElementById('aa').src = strDataURI;
// 之后的下载方法不想写了,可以直接从网页上下载了
}
// 每9张可以组成一张完整的图
var img1 = new ImageDraw(0, 0, imgSrcArray[0]);
var img2 = new ImageDraw(512, 0, imgSrcArray[1]);
var img3 = new ImageDraw(1024, 0, imgSrcArray[2]);
var img4 = new ImageDraw(0, 512, imgSrcArray[3]);
var img5 = new ImageDraw(512, 512, imgSrcArray[4]);
var img6 = new ImageDraw(1024, 512, imgSrcArray[5]);
var img7 = new ImageDraw(0, 1024, imgSrcArray[6]);
var img8 = new ImageDraw(512, 1024, imgSrcArray[7]);
var img9 = new ImageDraw(1024, 1024,imgSrcArray[8]);
</script>
</body>
</html>
通过这一系列步骤,我就完成了从全景视觉网站上把VR图盗取下来的过程

写到这里太累了,先告一段落了
未完待续… (黄金镇魂曲:你永远到达不了完结的真实)

拼接好的图片
- w01

- w02

- w03

- w04

- w05

- w06

常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!