此篇大概的内容包含:
- JS是什么语言?
- 什么是常规属性和排序属性?
- 什么是快属性和慢属性?
- 对象内属性是什么?为什么要它?
- 为什么js语言的属性访问速度会比静态语言慢?静态语言如何做到快速访问属性?V8是怎么提升对象属性访问速度的?
- 线性存储和非线性的存储的区别?什么时候回用非线性存储?
此篇幅比较长,在此整理自己的出稿思路,也方便大家能看明白:
- 先通过一例子引出什么是【常规属性 (properties) 和排序属性 (element)】;
- 接着介绍什么是快属性、慢属性、对象内属性,并介绍它们间的区别;
- 再用实例分析对象在内存中是如何布局的
- 同时,通过例子发现其他属性,也给与说明
- 自己设置几道面试题,自问自答
- 再次,给出总结
- 最后,还有个盲点请教下大牛,希望能给出答复
JavaScript 中的对象是由一组组属性和值的集合,从 JavaScript 语言的角度来看,JavaScript 对象像一个字典,字符串作为键名,任意对象可以作为键值,可以通过键名读写键值。然而在 V8 实现对象存储时,并没有完全采用字典的存储方式,这主要是出于性能的考量。因为字典是非线性的数据结构,查询效率会低于线性的数据结构,V8 为了提升存储和查找效率,采用了一套复杂的存储策略。
在开始之前,先看一现象
function testV8() {
this['A'] = 'A'
this[0] = '2'
this['B'] = 'B'
this[4.5] = '4.5'
this['haha'] = 5
this[1.2] = 1.2
this[666] = '6'
this['B'] = 'B'
this[3] = 3
this['4'] = '4'
}
const testObj = new testV8()
for (let key in testObj) {
console.log(`${key}:${testObj[key]}`)
}
0:2
3:3
4:4
666:6
A:A
B:B
4.5:4.5
haha:5
1.2:1.2
明显看结果没按顺序我们设置的顺序来,这是为什么呢?
以上例子中,对象包含整型整数、整型字符串、浮点数、字符串,
其实,得出以上结果的原因是因为V8对对象属性的存储有一定规则。下面开始介绍是什么规则。
排序属性 (elements)和常规属性 (properties)
在 V8 的对象中有两种属性,排序属性 (elements)和常规属性 (properties)。
把对象中的数字属性称为排序属性,在 V8 中被称为 elements。数字属性应该按照索引值大小升序排列。
字符串属性就被称为常规属性,在 V8 中被称为 properties,字符串属性根据创建时的顺序升序排列。
两个属性都有时,排序属性 (elements)先于常规属性(properties)。
在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构 来分别保存排序属性和常规属性。分解成这两种线性数据结构之后,如果执行索引操作,那么 V8 会先从 elements 属性中按照顺序读取所有的元素,然后再在 properties 属性中读取所有的元素,这样就完成一次索引操作。
分析以上实例的内存,如下
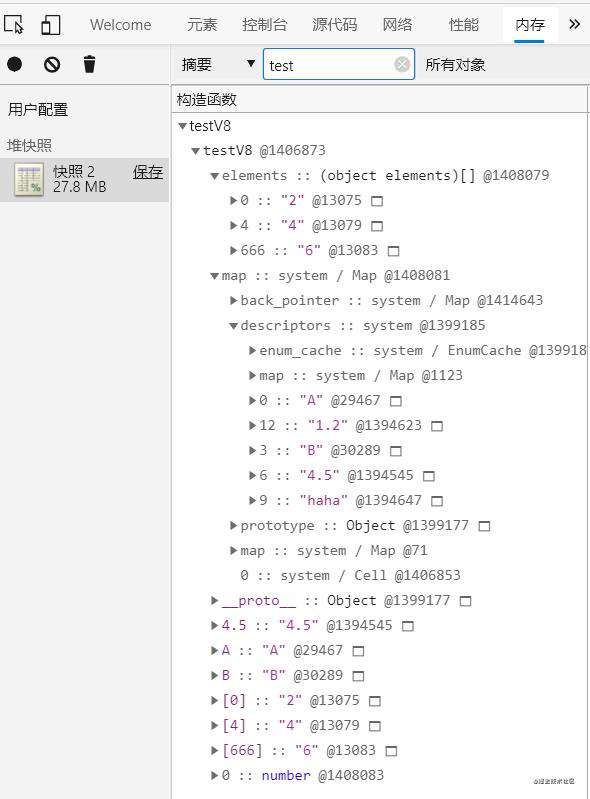
看图,为什么对象内属性没有 properties,因为没超过10个(没达到上限)。别着急,下面例子会有体现。
对象内属性、快属性和慢属性
对象内属性:将部分常规属性直接存储到对象本身。
将不同的属性分别保存到 elements 属性和 properties 属性中,无疑简化了程序的复杂度,但是在查找元素时,却多了一步操作,比如执行 testObj.B这个语句来查找 B 的属性值,那么在 V8 会先查找出 properties 属性所指向的对象 properties,然后再在 properties 对象中查找 B 属性,这种方式在查找过程中增加了一步操作,因此会影响到元素的查找效率。基于这个原因,V8 采取了一个权衡的策略以加快查找属性的效率,这个策略是将部分常规属性直接存储到对象本身,我们把这称为【对象内属性】 (in-object properties)。
采用对象内属性之后,常规属性就被保存到 testObj 对象本身了,这样当再次使用testObj.B来查找 B 的属性值时,V8 就可以直接从 testObj 对象本身去获取该值就可以了,这种方式减少查找属性值的步骤,增加了查找效率。
不过 对象内属性的数量是固定的,默认是 10 个,如果添加的属性 超出了对象分配的空间,则它们将被保存在常规属性存储中。虽然属性存储多了一层间接层,但可以自由地扩容。
通常,我们将保存在线性数据结构中的属性称之为“【快属性】”,因为线性数据结构中只需要通过索引即可以访问到属性,虽然访问线性结构的速度快,但是如果从线性结构中添加或者删除大量的属性时,则执行效率会非常低,这主要因为会产生大量时间和内存开销。
因此,如果一个对象的属性过多时,V8 就会采取另外一种存储策略,那就是“【慢属性】”策略,但慢属性的对象内部会有独立的非线性数据结构 (词典) 作为属性存储容器。所有的属性元信息不再是线性存储的,而是直接保存在属性字典中。
以上知道V8是怎么存储对象的,下面结合Chrome的内存快照,来看看对象在内存中是如何分配的。
实例分析对象在内存中是如何布局的
小于等于10个
function testObj() {}
var test10 = new testObj()
for (var i = 0; i < 10; i++) {
test10[i+'x'] = 'xxx'
}
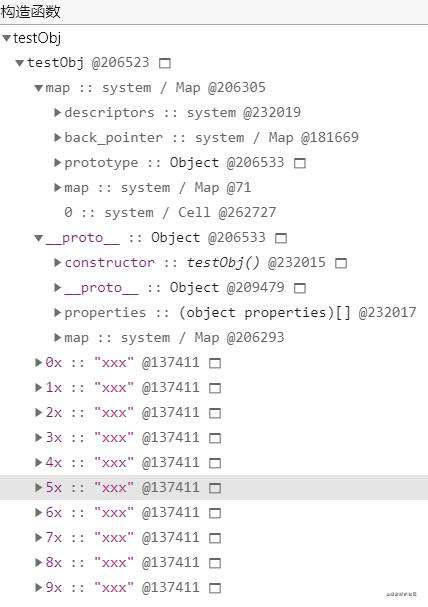
这时候属性的内存布局:
10 属性直接存放在 testObj 的对象内;
结合上图,并没有 properties 属性 而是直接保存在对象内的,为了减少查找这些属性查找流程,在对象内直接生成映射,快速查找,但是最多 10 个。
大于 10 个
function testObj() {}
var test20 = new testObj()
for (var i = 0; i < 20; i++) {
test20[i+'x'] = 'xxx'
}
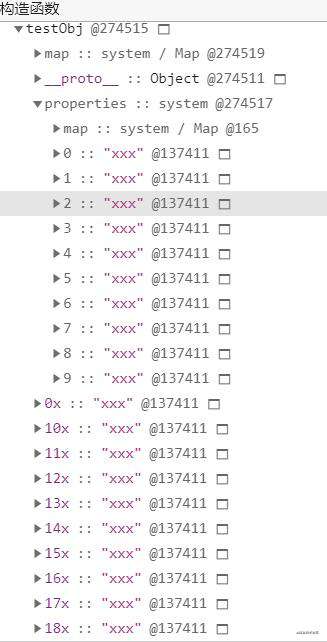
这时候属性的内存布局:
10 属性直接存放在 testObj 的对象内;
其他常规属性以线性数据结构方式存放在 properties 属性里面;
结合上图,当对象内属性放满(属性超过了 10 个)之后,会以快属性的方式,在 properties 下按创建顺序存放(0、1...9),注意因为 properties 中只有 10 个属性,所以依然是线性的数据结构,我们可以看其都是按照创建时的顺序来排列的。
相较于对象内属性,快属性需要额外多一次 properties 的寻址时间,之后便是与对象内属性一致的线性查找(properties 的属性是有规律的类似数组、链表存放)
大于 20 个
function testObj() {}
var test50 = new testObj()
for (var i = 0; i < 50; i++) {
test50[i+'x'] = 'xxx'
}

这时候属性的内存布局:
10 属性直接存放在 testObj 的对象内;
其他常规属性以非线性字典的数据结构方式存放在 properties 属性里面;
结合上图,我们可以看到,当数据量大起来以后,在 properties 里的属性已经不线性(119、120),而是以非线性的散列表(字典)(哈希-分离链路)形式存储的。
附:分离链路是哈希 key+链表 value 的结构
其他属性(map 属性和 proto 属性)
现在我们知道 V8 是怎么存储对象的了,不过看下图:
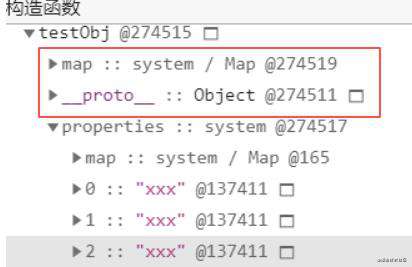
图中,发现除了 elements 和 properties 属性,V8 还为每个对象实现了 map 属性和 proto 属性。__proto__ 属性就是原型,是用来实现 JavaScript 继承的;而 map 则是隐藏类,关于对它的理解,下一篇梳理就是它了。
设置几道面试题
为什么要用对象内属性?
对象内属性,比在properties中的常规属性需要额外少一次 properties 的寻址时间。
为什么需要慢属性,不直接使用快属性?
假设查找 100 多个属性,要进行 100 多次运算,还不如一次哈希计算(假如 50 次简单运算)+链路检索(小于 50 次)来得更快。
为什么js语言的属性访问速度会比静态语言慢?
因为js语言是动态语言,它的对象的属性是可以被修改的,因此当要使用一些属性时,V8引擎需要知道这个属性相对于对象的偏移量才能读取对应的属性,而这个过程是需要时间的,因此V8引擎有提供了一个快属性来提升速度,但是其他的慢属性,仍然会有执行速度慢的问题。
静态语言如何做到快速访问属性?
静态语言相对于动态语言,在对象属性的读取方面,效率更高。主要原因是静态语言如java在声明一个对象时,需要提前定义好该对象的结构,也就是形状。然后在编译的过程中,引擎就可以通过这个数据来提前计算好该属性相对于对象地址的偏移值,在后面需要用到该对象的属性时,直接根据偏移值来读取该内容,因此执行效率更高。
V8如何优化对象属性访问速度?
通过对静态特性的借鉴,V8为js的对象引入了隐藏类技术,通过对每个对象创建一个隐藏类,对象的隐藏类记录了对象的一些基本的布局信息,这些信息包括了对象的所有属性,每个类型相对于对象的偏移量。通过这两个特性,V8引擎可以快速查找对象的属性。而V8针对多个对象,如果用的是同一个形状的话,就会将该形状对应的隐藏类复用。
在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构来分别保存排序属性和常规属性。
线性和非线性(散列表)存储模式比较
| 结构 | 数据类型 | 线性结构 | 数组、链表 | 快 | 非线性解构 | 哈希 Map(分离链路) | 慢 |
|---|
-
线性储存主要是时间复杂度比较小,而且代码可读性也比较好,非线性结构实现起来很多时候都是以递归实现,所以能用线性储存的数据最好不用非线性结构。
-
非线性结构就是存储联系复杂的数据,这些数据之间一般都有较大的相关性,线性链表是不能实现的。
总结
结论
- 排序顺序数字按大小排序,字符串按先后执行顺序排序
- 在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构来分别保存排序属性和常规属性。分解成这两种线性数据结构之后,如果执行索引操作,那么 V8 会先从 elements 属性中按 照顺序读取所有的元素,然后再在 properties 属性中读取所有的元素,这样就完成一次索引操作。
- 对象内属性,将部分常规属性 直接存储到对象本身, 对象内属性的数量是固定的,默认是 10 个(也就是说属性小于等于10个会生成内部属性),如果添加的属性超出了对象分配的空间,它们将被保存在常规属性properties存储中(大于10个在 properties 里线性存储, 数量再大的情况改为散列表存储)。
- 如果对象中的属性过多时(没有确定的数),或者存在反复添加或者删除属性的操作,那么 V8 就会将线性的存储模式降级为非线性的字典存储模式,这样虽然降低了查找速度,但是却提升了修改对象的属性的速度。
对于日常应用开发中的启发?
要注意尽量减少让V8引擎触发隐藏类的重构,而它重构建的触发条件是:如果对象的形状发生改变就会重新触发构建,而对象的形状变化一般都是由于给一个对象增加或者删除属性,或者改变属性的数据类型和顺序都会触发重建,因此,在日常开发中,要避免这几种情况:
-
尽量使用字面量一次性来初始化完整的对象属性
-
尽量避免使用delete方法
-
在多次用字面量初始化对象时,要保证属性的顺序是一致的
疑问
var line = {}
for (var i = 0; i < 10; i++) {
line[i+'x'] = 'xxx'
}
这个为什么不能生成快照,难道一定要是函数吗?
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!