为什么要进⾏性能优化?
- 57%的⽤户更在乎⽹⻚在3秒内是否完成加载
- 52%的在线⽤户认为⽹⻚打开速度影响到他们对⽹站的忠实度
- 每慢1秒造成⻚⾯ PV(页面浏览量或点击量) 降低11%,⽤户满意度也随之降低降低16%
- 近半数移动⽤户因为在10秒内仍未打开⻚⾯从⽽放弃
http缓存机制
试想,如果每个用户每次拿数据都直接向服务器请求,不论该数据有没有改变,这样显然是不合理的。所以浏览器中有缓存这个概念,合理的运用浏览器的缓存可以达到访问性能优化的效果
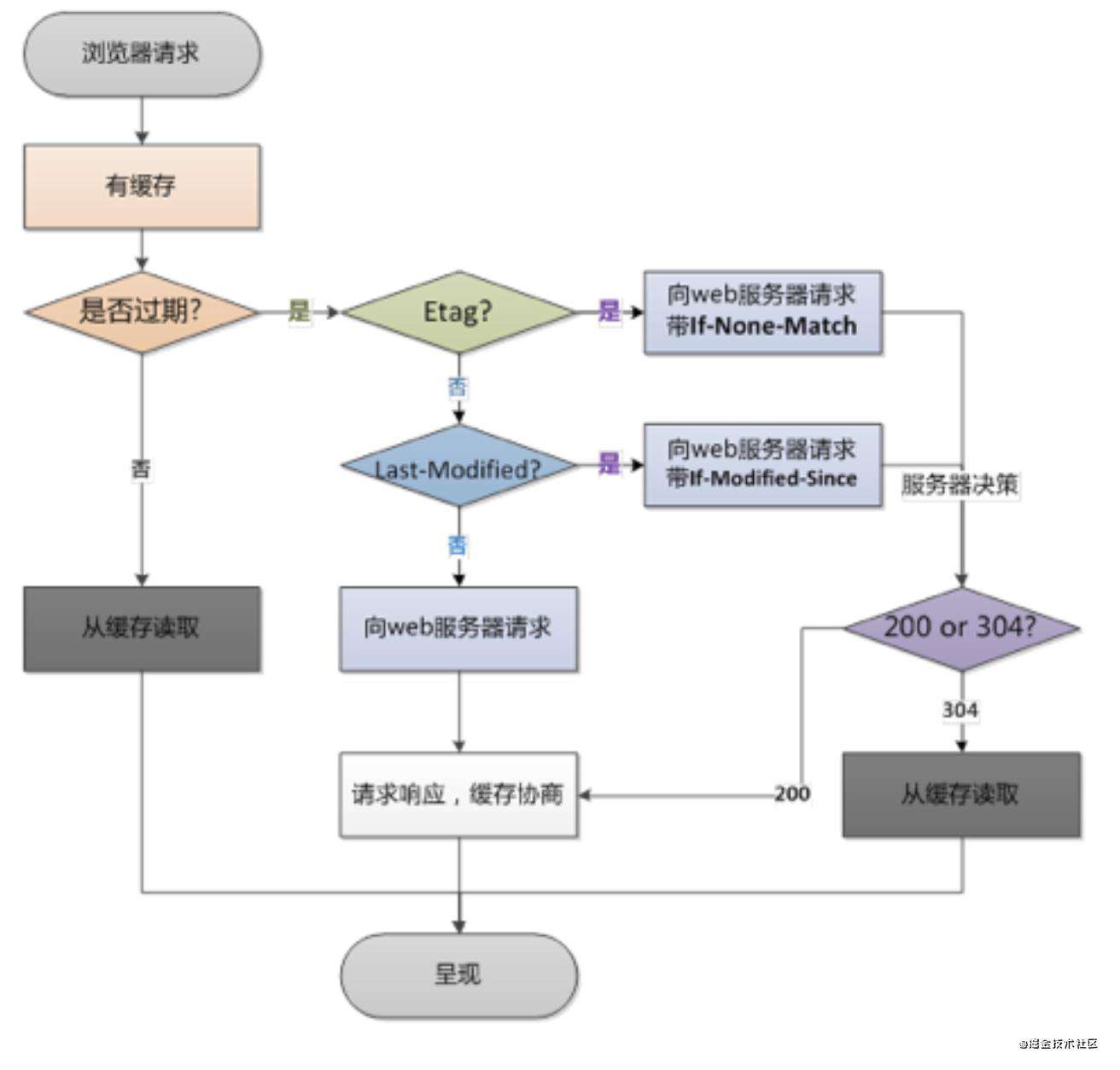
首先了解一下缓存的优先级,以下由优先级低到高依次介绍
last-modified / if-modified-since
这是⼀组请求/相应头
响应头: last-modified: Wed, 16 May 2020 02:57:16 GMT
请求头: if-modified-since: Wed, 16 May 2020 05:55:38 GMT
服务器端返回资源时,如果头部带上了 last-modified,那么 资源下次请求时就会把值加⼊到请求头 if-modified-since 中,服务器可以对⽐这个值,确定资源是否发⽣变化,如果 没有发⽣变化,则返回 304。
etag / if-none-match
这也是⼀组请求/相应头 响应头:
etag: "D5FC8B85A045FF720547BC36FC872550"
请求头: if-none-match: "D5FC8B85A045FF720547BC36FC872550"
原理类似,服务器端返回资源时,如果头部带上了 etag,那么资源下 次请求时就会把值加⼊到请求头 if-none-match 中,服务器可以对⽐ 这个值,确定资源是否发⽣变化,如果没有发⽣变化,则返回 304。
expires
expires: Thu, 16 May 2019 03:05:59 GMT
在 http 头中设置⼀个过期时间,在这个过期时间之前,浏览器的请求都不会发出,⽽是⾃动从缓存中读取⽂件,除⾮缓存被清空,或者强制刷新。缺陷在于,服务器时间和⽤户端时间可能存在不⼀致,所以 HTTP/1.1 加⼊了 cache-control 头来改进这个问题。
cache-control
设置过期的时间⻓度(秒),在这个时间范围内,浏览器请求都会直 接读缓存。当 expires 和 cache-control 都存在时,cache-control 的优先级更⾼。
总结
了解以上缓存的优先级后,我们大概可以复现浏览器在请求数据时所经过的步骤
当然,有时候缓存也是一个令人头痛的东西,在日常开发中,常常遇到以下这种场景。
以上问题纯属虚构,现实中用户并不会主动去清理缓存。出现上述问题完全是缓存造成的原因,你虽然构建完毕了,但是存在强缓,并不会去服务器拉取最新构建的代码,其实解决方法也很简单,简单粗暴,直接在index.html中禁用强缓
<meta http-equiv="Cache-control" content="no-cache,max-age=0, must-revalidate,no-store">
<meta http-equiv="Pragma" content="no-cache" />
<meta http-equiv="Expires" content="0" />
这时你会发现,构建完毕,就直接是最新的代码
HTTP2多路复⽤
我们都知道http是架构在TCP上的协议,为了保证传输的可靠性,在建立连接的时候需要经历三次握手。如果一次请求完成就会关闭本次的 Tcp 连接,下个请求又要从新建立 Tcp 连接传输完成数据再关闭,造成很大的性能损耗。
Keep-Alive
Keep-Alive解决的核心问题是: 一定时间内,同一域名多次请求数据,只建立一次 HTTP 请求,其他请求可复用每一次建立的连接通道,以达到提高请求效率的问题。 Keep-Alive还是存在一些问题,如串行的文件传输、同域并行请求限制带来的阻塞(6~8)个
管线化
HTTP 管线化可以克服同域并行请求限制带来的阻塞,它是建立在持久连接之上,是把所有请求一并发给服务器,但是服务器需要按照顺序一个一个响应,而不是等到一个响应回来才能发下一个请求,这样就节省了很多请求到服务器的时间。不过,HTTP 管线化仍旧有阻塞的问题,若上一响应迟迟不回,后面的响应都会被阻塞到。
多路复用
多路复用代替原来的序列和阻塞机制。所有就是请求的都是通过一个 TCP 连接并发完成。因为在多路复用之前所有的传输是基于基础文本的,在多路复用中是基于二进制数据帧的传输、消息、流,所以可以做到乱序的传输。多路复用对同一域名下所有请求都是基于流,所以不存在同域并行的阻塞。
参考Http2中的多路复用
一些性能指标及概念
FP 、 FCP
FPFirst Paint, ⾸次绘制FCPFirst Contentful Paint, ⾸次有内容的绘制
通过 Paint Timing API 来获取性能指标
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
console.log(entry);
}
});
observer.observe({ entryTypes: ["paint"] });
// PerformancePaintTiming {
// duration: 0
// entryType: "paint"
// name: "first-paint"
// startTime: 62.43499999982305
// }
// PerformancePaintTiming {
// duration: 0
// entryType: "paint"
// name: "first-contentful-paint"
// startTime: 62.43499999982305
// }
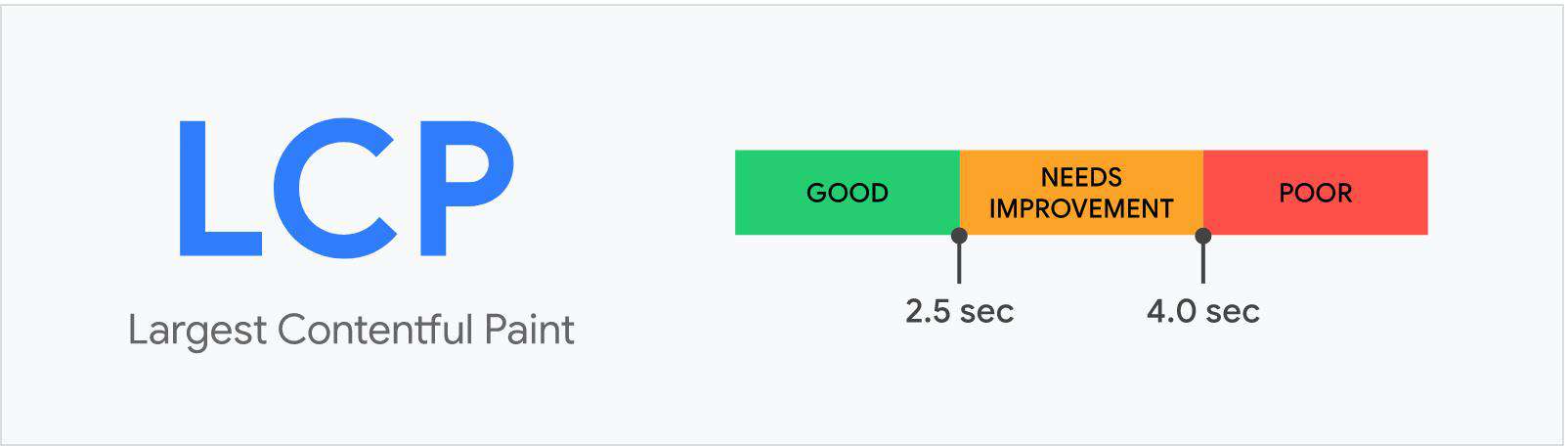
LCP
- LCP指标代表的是视窗最大可见图片或者文本块的渲染时间。
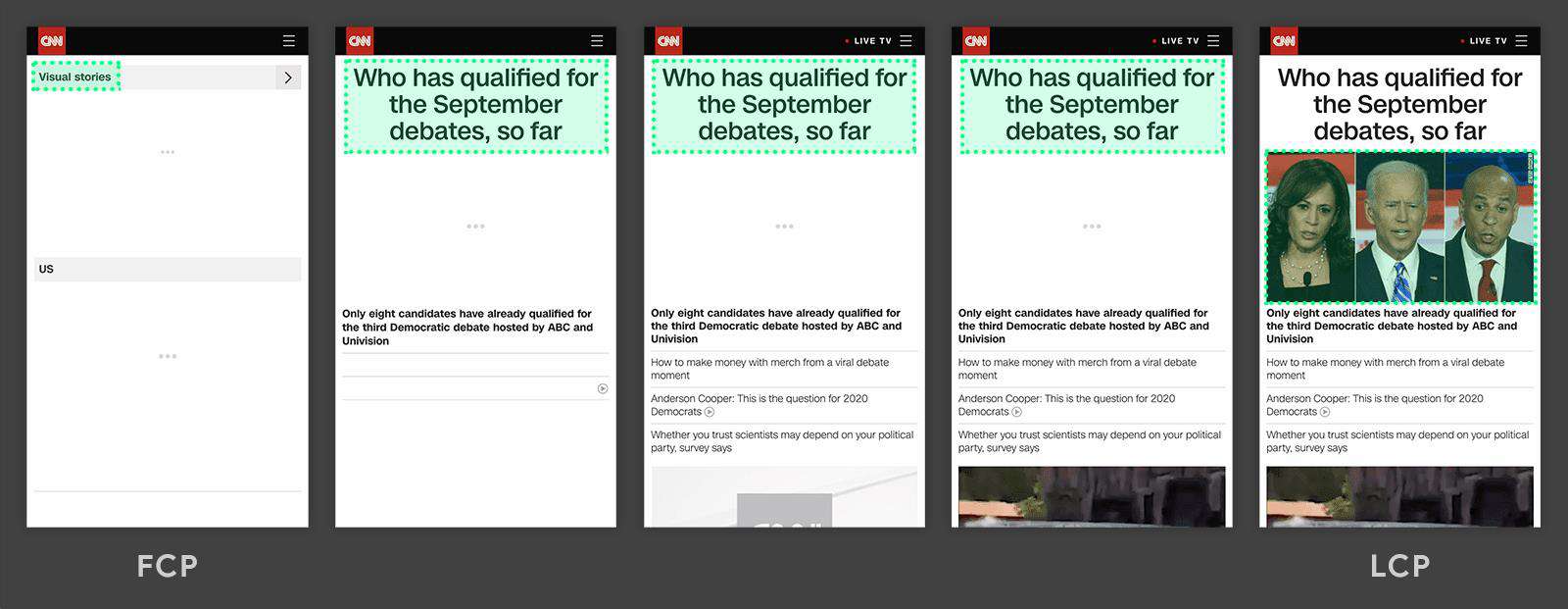
根据google建议,为了给用户提供更好的产品体验,LCP应该低于2.5s。
可以通过 Largest Contentful Paint API 来获取
const observer = new PerformanceObserver((list) => {
let perfEntries = list.getEntries();
let lastEntry = perfEntries[perfEntries.length - 1];
console.log(lastEntry)
});
observer.observe({entryTypes: ['largest-contentful-paint']});
// LargestContentfulPaint {
// duration: 0
// element: img
// entryType: "largest-contentful-paint"
// id: ""
// loadTime: 300.39
// name: ""
// renderTime: 0
// size: 457824
// startTime: 300.39
// url: "https://imgconvert.csdnimg.cn/aHR0cHM6Ly9wMS1qdWVqaW4uYnl0ZWltZy5jb20vdG9zLW
// }
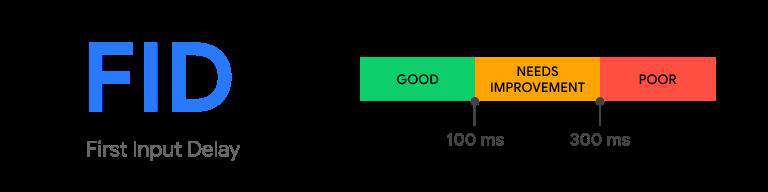
FID
First Input Delay 首次输入延迟,衡量的是从用户第一次与页面进行交互(即当他们单击链接,点击按钮或使用自定义的JavaScript驱动的控件)到浏览器实际上能够开始处理事件处理程序的时间。回应这种互动。
为了提供良好的用户体验,页面的FID应该小于100毫秒
可以使用Event Timing API 来获取
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
const delay = entry.processingStart - entry.startTime;
console.log('FID candidate:', delay, entry);
}
}).observe({type: 'first-input', buffered: true});
// FID candidate: 2.064999978756532
//
// PerformanceEventTiming {
// cancelable: true
// duration: 1512
// entryType: "first-input"
// name: "mousedown"
// processingEnd: 1163.139999989653
// processingStart: 1163.124999991851
// startTime: 1161.0600000130944
// target: img
// }
CLS
Cumulative Layout Shift 累积版式移位(CLS)是衡量用户视觉稳定性的一项重要的以用户为中心的度量标准,因为它有助于量化用户经历意外的版式移位的频率-较低的CLS有助于确保页面令人愉悦。 CLS会测量在页面整个生命周期中发生的每个意外的版式移位的所有单独版式移位分数的总和。
 为了提供良好的用户体验,网站应努力使CLS得分不超过0.1
为了提供良好的用户体验,网站应努力使CLS得分不超过0.1
可以通过Layout Instability API 来获取
let cls = 0;
new PerformanceObserver((entryList) => {
for (const entry of entryList.getEntries()) {
if (!entry.hadRecentInput) {
cls += entry.value;
console.log('Current CLS value:', cls, entry);
}
}
}).observe({type: 'layout-shift', buffered: true});
Long tasks
Long tasks 超过了 50ms 的任务
可通过Long Tasks API 来获取
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
console.log(entry);
}
});
observer.observe({ entryTypes: ['longtask'] });
// 通过循环来触发
for(var i=0; i < 10000; i++) {
console.log(1)
}
// PerformanceLongTaskTiming {
// attribution: [TaskAttributionTiming]
// duration: 173
// entryType: "longtask"
// name: "self"
// startTime: 93.09499998926185
// }
网页渲染的整体过程

- 获取dom 分割层
- 根据每层节点计算样式结果(Recalculate Style)
- 为每个节点生成图形和位置 (Layout)
- 将每个节点绘制填充到当前帧的图层位图中 (Paint)
- 将图层上传到gpu
- 将符合要求的多个图层合并成图像 (Composite Layers)
黑科技
我们写一个小球运动的动画
@keyframes run-around {
0%{
left: 0;
top: 0;
}
25%{
top: 0;
left: 200px;
}
50%{
left: 200px;
top: 200px;
}
75%{
left: 0;
top: 200px;
}
}
打开Chrome的performance面板刷新页面查看相关参数
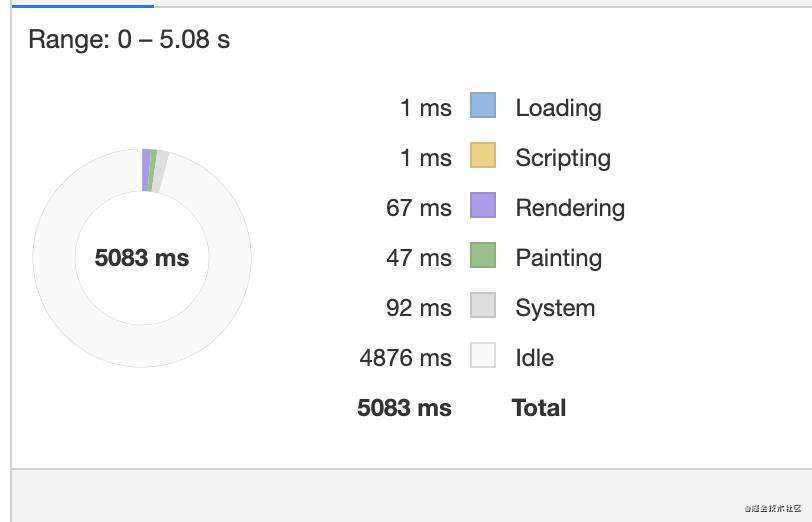
换一种写法
@keyframes run-around {
0% {
transform: translate(0,0);
}
25% {
transform: translate(200px,0);
}
50% {
transform: translate(200px,200px);
}
75% {
transform: translate(0,200px);
}
}
再看一下performance
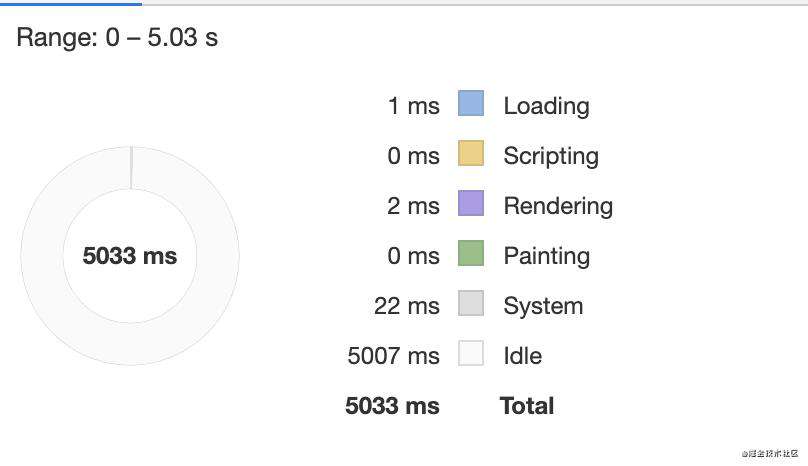
你会发现,换了一种写法,总体加载速度变快了。这是为什么呢?
答案就是 transform,使用transform 后GPU直接参与渲染, 从而跳过Layout和 Paint 这两个步骤

永久原文地址(你的star是我最大的动力?)
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!