原文
简介
布隆过滤器(Bloom Filter) 是 1970 由布隆提出,它是一种多哈希函数映射的快速查找算法 (存储结构),可以实现用很小的空间和运算代价,来实现海量数据的存在与否的记录(黑白名单判断)。特点是高效的插入和查询,可以判断出一定不存在和可能存在
布隆过滤器
布隆过滤器是一个 bit 向量或者 bit 数组
"添加"元素
如果要将一个"添加"射到布隆过滤器中,需要使用多个 hash 函数生成多个 hash 值,每个 hash 值对应位数组上的一个点,然后将位数组对应的位置标记为 1。
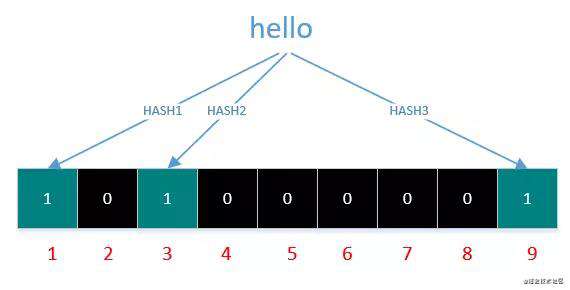
如下图,字符串 'hello' 就通过 3 种 hash 函数生成了哈希值 1,3,9
字符串‘word’就生成了 1,5,7
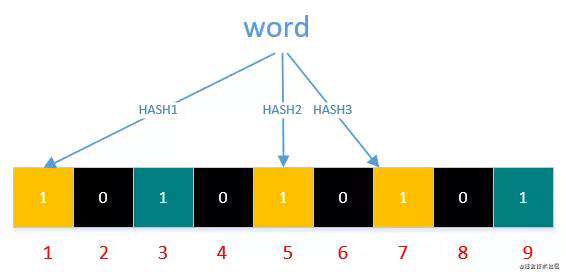
注:由于 hello 和 word 都返回了 bit 位 1,所以前面的 1 会被覆盖
查询元素
查询元素是否存在集合中的时候,同样的方法将元素通过哈希映射到位数组上的 3 个点。
如果 3 个点的其中有一个点不为 1,则可以判断该元素一定不存在集合中。
如果 3 个点都为 1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在,可能存在一定的误判率。 因为新增的元素越来越多,被置为 1 的 bit 位也会越来越多,这样即使某个元素没有被存储过,但是万一哈希函数算出来的三个 bit 位都被其他元素置为 1 了,那么 布隆过滤器(Bloom Filter) 还是会判断这个元素存在。
比如:单词 flink 三个 hash 值为 1,3,7, 就能说明 flink 一定存在于集合中吗?
优缺点
优点
相比于传统的 List、Set、Map 等数据结构,布隆过滤器(Bloom Filter) 更高效、占用空间更少,能确切判断出元素不在集合中
缺点
- 只能判断出元素有概率在集合中,因此使用 布隆过滤器(Bloom Filter) 判断元素出元素在集合中的结果是不可靠的
- 已经加入集合中的元素被删除时, 布隆过滤器(Bloom Filter) 无法"刷新"该元素对应的hash位置的值。因为这些位置有概率也是其他元素的hash位置。因此使用 布隆过滤器(Bloom Filter) 的集合无法删除元素。
如何减少误差
-
加大布隆过滤器的长度,否则很容易就所有的 bit 位都为 1 了
-
哈希函数的个数要考虑,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误差会变高。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?
![[路飞]_leetcode-227-基本计算器 II - 掘金](/ripro/timthumb.php?src=/images/titlepic.png&h=200&w=300&zc=1&a=c&q=100&s=1)
![[路飞]_leetcode-636-函数的独占时间 - 掘金](/ripro/timthumb.php?src=https://img.qiyuandi.com/img/20211125/[lf]_rj305yatcu3.jpg&h=200&w=300&zc=1&a=c&q=100&s=1)


发表评论
还没有评论,快来抢沙发吧!