DNS 介绍
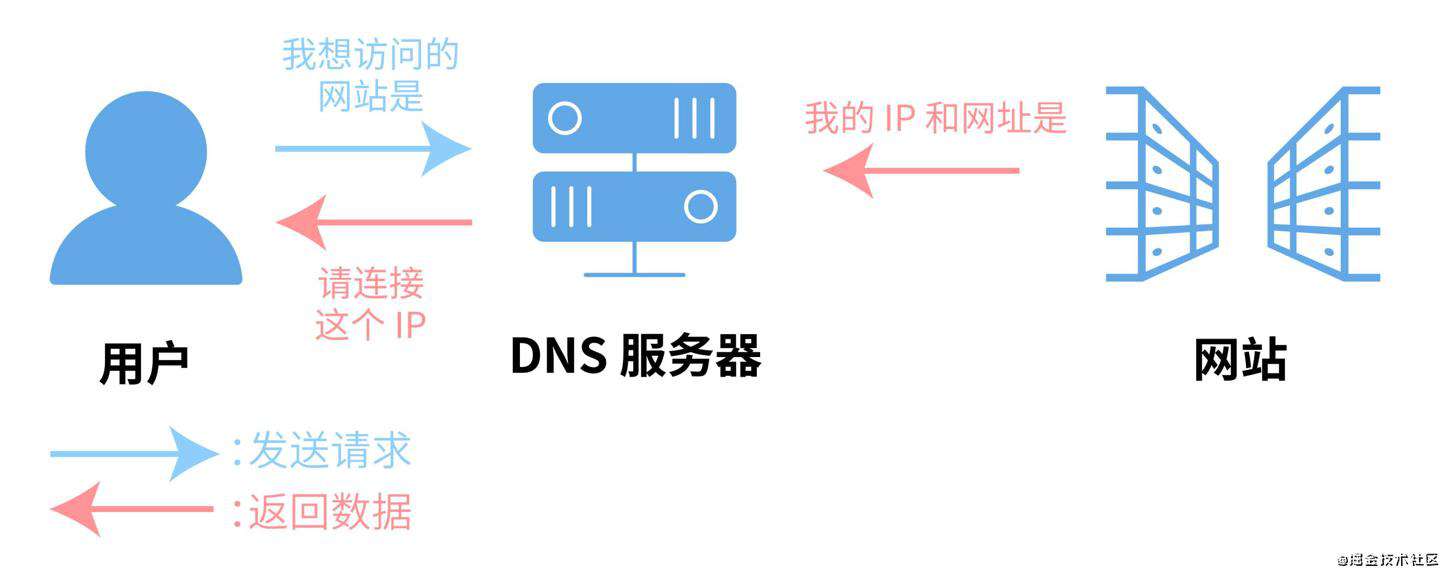
- DNS(Domain Name System,域名系统),DNS 服务用于在网络请求时,将域名转为 IP 地址。能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的 IP 数串。
- 传统的基于 UDP 协议的公共 DNS 服务极易发生 DNS 劫持,从而造成安全问题。
DNS 劫持问题?
- 1、对于互联网,域名是访问的第一跳,而这一跳很多时候会“失足”(尤其是移动端网络),例如访问错误内容、失败连接等,让用户在互联网上畅游的爽快瞬间消失;
- 2、经常会出现域名缓存、劫持、跨网
- DNS缓存问题 dns缓存指向旧的IP 导致用户连接不上服务器
移动端DNS收敛 走7层nginx做转发 因为移动端解析成本高
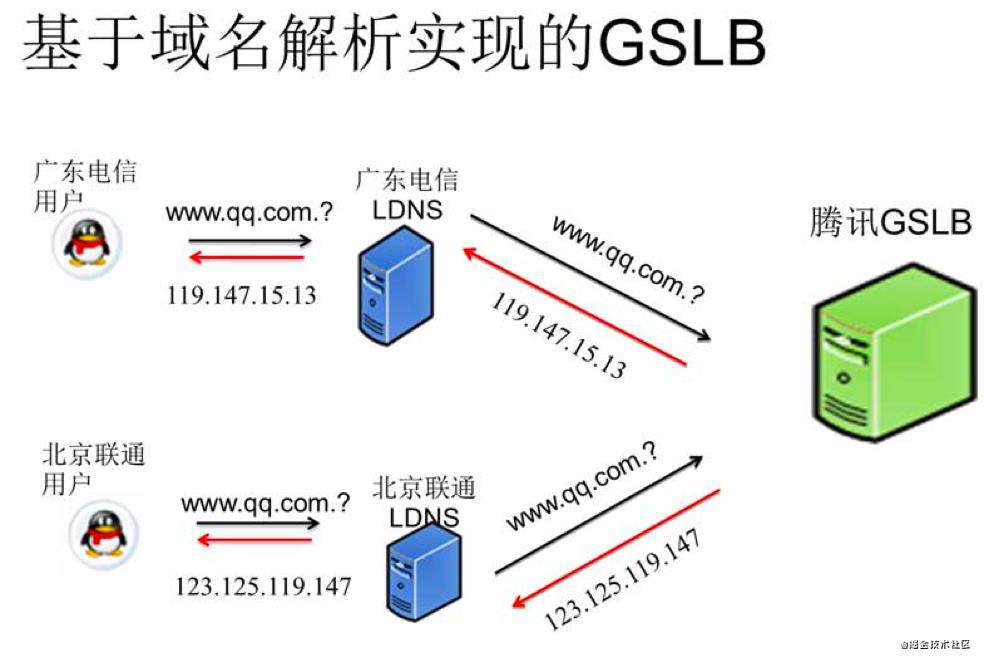
通过域名找到IP 找到边缘节点
域名查询过程
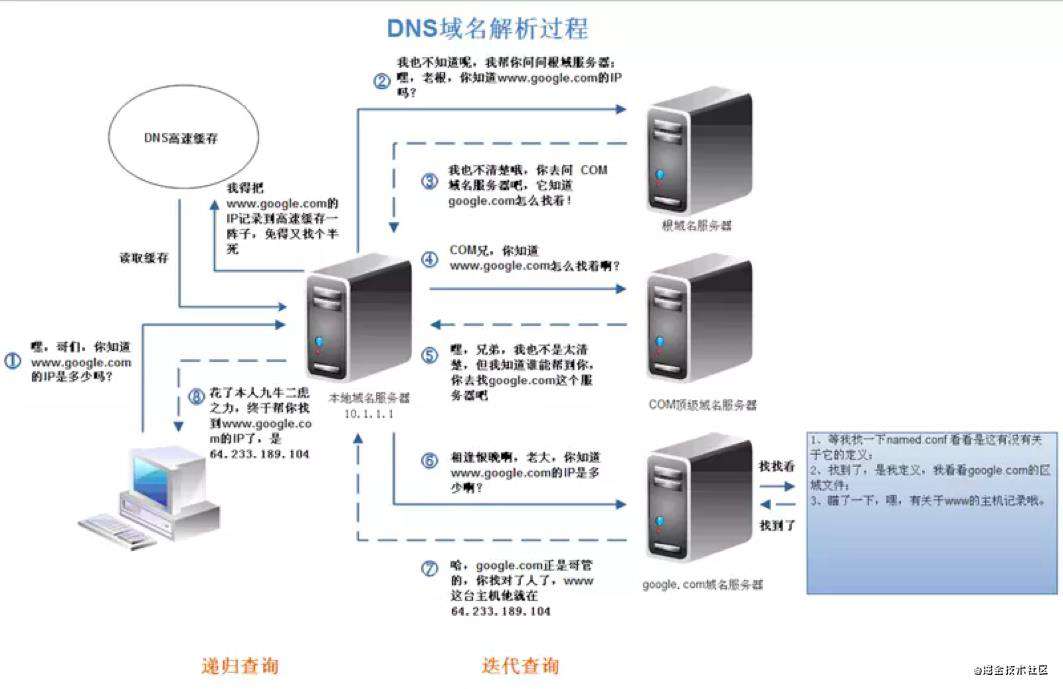
递归查询
如果主机所询问的本地域名服务器不知道被查询域名的 IP 地址,那么本地域名服务器就以 DNS 客户的身份,向其他根域名服务器继续发出查询请求报文,而不是让该主机自己进行下一步的查询。
迭代查询
当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的 IP 地址,要么告诉本地域名服务器:你下一步应当向哪一个域名服务器进行查询。然后让本地域名服务器进行后续的查询,而不是替本地域名服务器进行后续的查询。
客户端到 Local DNS 服务器,Local DNS 与上级 DNS 服务器之间属于递归查询;
DNS 服务器与根 DNS 服务器之前属于迭代查询。
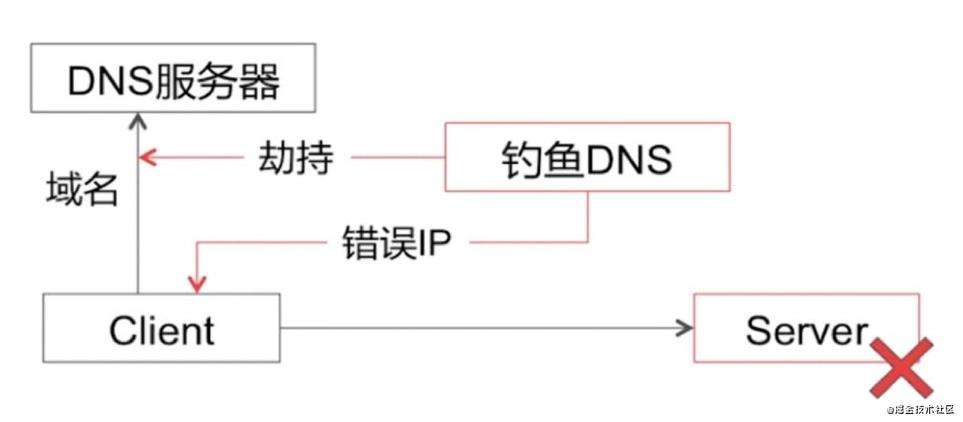
DNS 问题
Local DNS 劫持: Local DNS 把域名劫持到其他域名,实现其不可告人的目的。
 1、记录是随机的、每条记录引来有基本相同的数量请求;
2、SRV记录权重(HTTP不支持);
3、一般是维护物理位置对应的对照表,按照”最近“原来回复;
1、记录是随机的、每条记录引来有基本相同的数量请求;
2、SRV记录权重(HTTP不支持);
3、一般是维护物理位置对应的对照表,按照”最近“原来回复;
域名缓存就是 LocalDNS 缓存了业务的域名的解析结果,不向权威 DNS 发起递归。
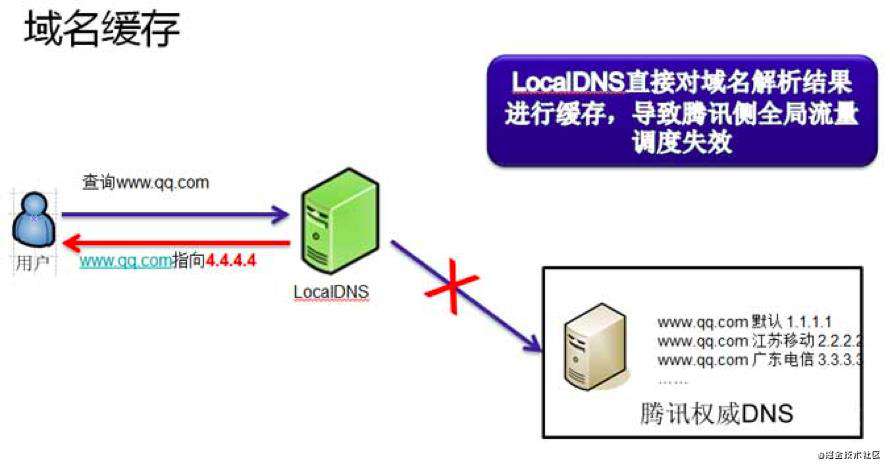
- 保证用户访问流量在本网内消化:国内的各互联网接入运营商的带宽资源、网间结算费用、IDC机房分布、网内 ICP 资源分布等存在较大差异。为了保证网内用户的访问质量,同时减少跨网结算,运营商在网内搭建了内容缓存服务器,通过把域名强行指向内容缓存服务器的 IP 地址,就实现了把本地本网流量完全留在了本地的目的。
- 推送广告:有部分 LocalDNS 会把部分域名解析结果的所指向的内容缓存,并替换成第三方广告联盟的广告。
- 除了域名缓存以外,运营商的 LocalDNS 还存在解析转发的现象。
- 解析转发是指运营商自身不进行域名递归解析,而是把域名解析请求转发到其它运营商的递归 DNS 上的行为。
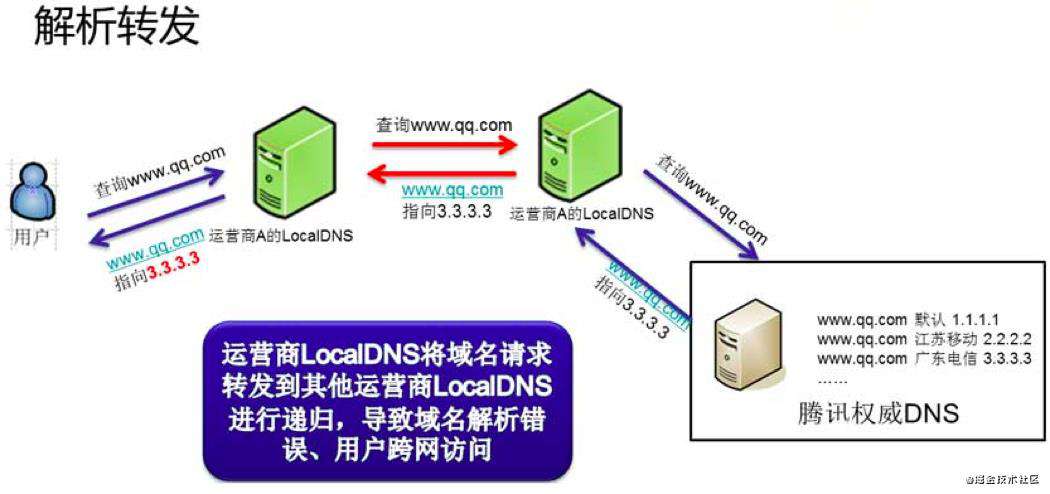
- 而部分小运营商为了节省资源,就直接将解析请求转发到了其它运营的递归 LocalDNS 上去了。
- 这样的直接后果就是权威 DNS 收到的域名解析请求的来源 IP 就成了其它运营商的 IP,最终导致用户流量被导向了错误的 IDC,用户访问变慢。
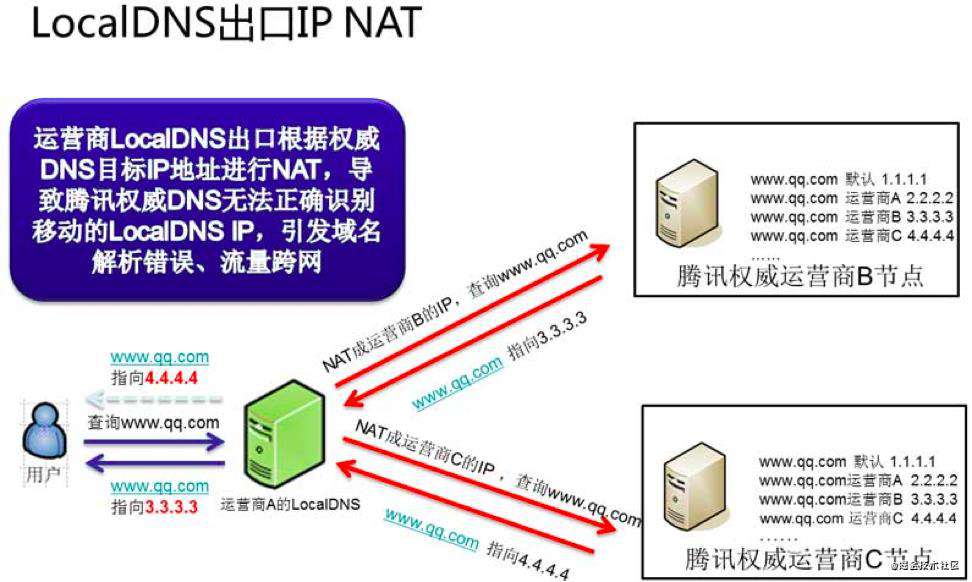
- LocalDNS 递归出口 NAT 指的是运营商的 LocalDNS 按照标准的 DNS 协议进行递归,但是因为在网络上存在多出口且配置了目标路由 NAT,结果导致 LocalDNS 最终进行递归解析的时候的出口 IP 就有概率不为本网的 IP 地址。
- 这样的直接后果就是 DNS 收到的域名解析请求的来源 IP 还是成了其它运营商的 IP,最终导致用户流量被导向了错误的 IDC,用户访问变慢。
高可用的 DNS 设计
实时监控 + 商务推动: 这种方案就是周期比较长,毕竟通过行政手段来推动运营商来解决这个问题是比较耗时的。 另外我们通过大数据分析,得出的结论是 Top3 的问题用户均为移动互联网用户。对于这部分用户,我们有什么技术手段可以解决以上的问题呢? 绕过自动分配 DNS,使用 114DNS 或 Google public DNS: 如何在用户侧构造域名请求:对于 PC 端的客户端来说,构造一个标准的 DNS 请求包并不算什么难事。但在移动端要向一个指定的 LocalDNS 上发送标准的 DNS 请求包,而且要兼容各种 iOS 和 Android 的版本的话,技术上是可行的,只是兼容的成本会很高。 推动用户修改配置极高:如果要推动用户手动修改 PC 的 DNS 配置的话,在 PC 端和手机客户端的 WiFi 下面还算勉强可行。但是要用户修改在移动互联网环境下的 DNS 配置,其难度不言而喻。
HTTPDNS
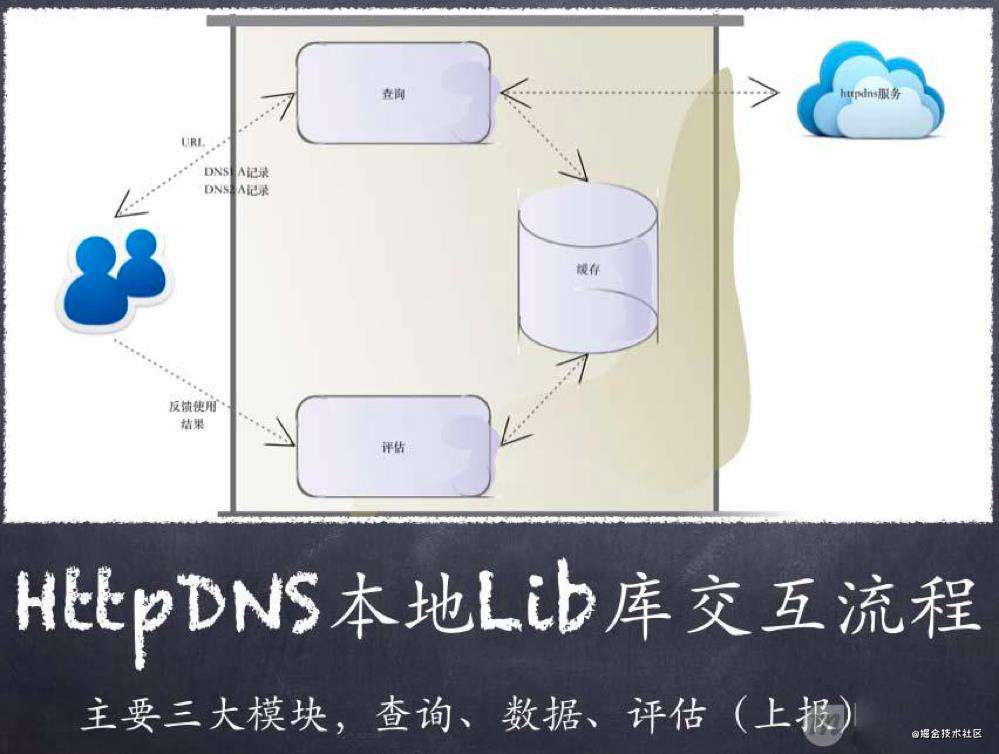
完全抛弃域名,自建 HTTPDNS 进行流量调度: 如果要采用这种这种方案的话,首先你就得要拿到一份准确的 IP 地址库来判断用户的归属,然后再制定个协议搭个服务来做调度,然后再对接入层做调度改造。 这种方案和2种方案一样,不是不能做,只是成本会比较高,尤其对于大体量业务规模如此庞大的公司而言。 当前主流的解决方案:HTTPDNS出现了!
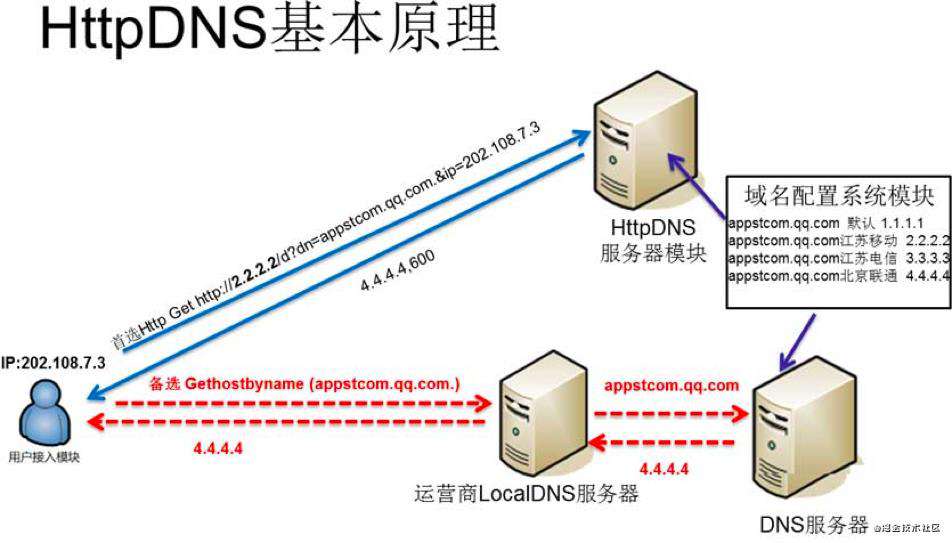
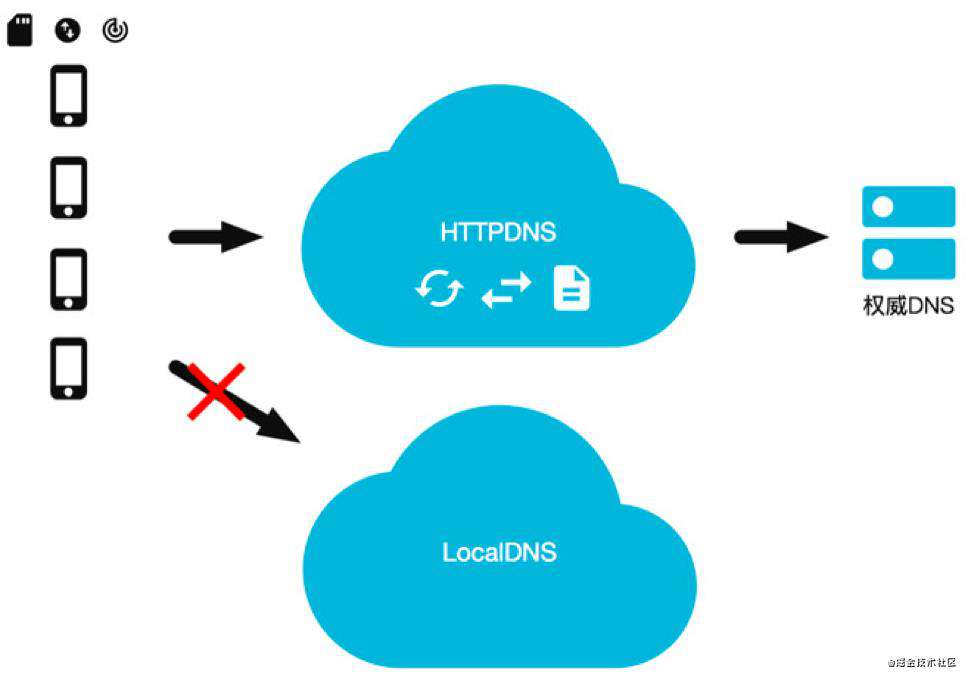 HTTPDNS 利用 HTTP 协议与 DNS 服务器交互,代替了传统的基于 UDP 协议的 DNS 交互,绕开了运营商的 Local DNS,有效防止了域名劫持,提高域名解析效率。
另外,由于 DNS 服务器端获取的是真实客户端 IP 而非 Local DNS 的 IP,能够精确定位客户端地理位置、运营商信息,从而有效改进调度精确性。
HTTPDNS 利用 HTTP 协议与 DNS 服务器交互,代替了传统的基于 UDP 协议的 DNS 交互,绕开了运营商的 Local DNS,有效防止了域名劫持,提高域名解析效率。
另外,由于 DNS 服务器端获取的是真实客户端 IP 而非 Local DNS 的 IP,能够精确定位客户端地理位置、运营商信息,从而有效改进调度精确性。
 DNS---> 边缘节点---> 中心机房
多活切换流量的时候 修改边缘节点的路由配置 7层转发
DNS---> 边缘节点---> 中心机房
多活切换流量的时候 修改边缘节点的路由配置 7层转发
https -> http ( token ,自己定义验证) -> net/rpc, grpc
 由于 HTTP DNS 是通过 ip 直接请求 http获取服务器 A 记录地址,不存在向本地运营商询问 domain 解析过程,所以从根本避免了劫持问题。
平均访问延迟下降:
由于是 ip 直接访问省掉了一次 domain 解析过程。
用户连接失败率下降:
通过算法降低以往失败率过高的服务器排序
通过时间近期访问过的数据提高服务器排序
通过历史访问成功记录提高服务器排序
由于 HTTP DNS 是通过 ip 直接请求 http获取服务器 A 记录地址,不存在向本地运营商询问 domain 解析过程,所以从根本避免了劫持问题。
平均访问延迟下降:
由于是 ip 直接访问省掉了一次 domain 解析过程。
用户连接失败率下降:
通过算法降低以往失败率过高的服务器排序
通过时间近期访问过的数据提高服务器排序
通过历史访问成功记录提高服务器排序
 根治域名解析异常:由于绕过了运营商的LocalDNS,用户解析域名的请求通过 HTTP 协议直接透传到了 HTTPDNS 服务器 IP 上,用户在客户端的域名解析请求将不会遭受到域名解析异常的困扰。
调度精准:HTTPDNS 能直接获取到用户 IP,通过结合 IP 地址库以及测速系统,可以保证将用户引导的访问最快的 IDC 节点上;
实现成本低廉:接入 HTTPDNS 的业务仅需要对客户端接入层做少量改造,无需用户手机进行 root 或越狱;而且由于 HTTP 协议请求构造非常简单,兼容各版本的移动操作系统更不成问题;另外 HTTPDNS 的后端配置完全复用现有权威 DNS 配置,管理成本也非常低。
根治域名解析异常:由于绕过了运营商的LocalDNS,用户解析域名的请求通过 HTTP 协议直接透传到了 HTTPDNS 服务器 IP 上,用户在客户端的域名解析请求将不会遭受到域名解析异常的困扰。
调度精准:HTTPDNS 能直接获取到用户 IP,通过结合 IP 地址库以及测速系统,可以保证将用户引导的访问最快的 IDC 节点上;
实现成本低廉:接入 HTTPDNS 的业务仅需要对客户端接入层做少量改造,无需用户手机进行 root 或越狱;而且由于 HTTP 协议请求构造非常简单,兼容各版本的移动操作系统更不成问题;另外 HTTPDNS 的后端配置完全复用现有权威 DNS 配置,管理成本也非常低。
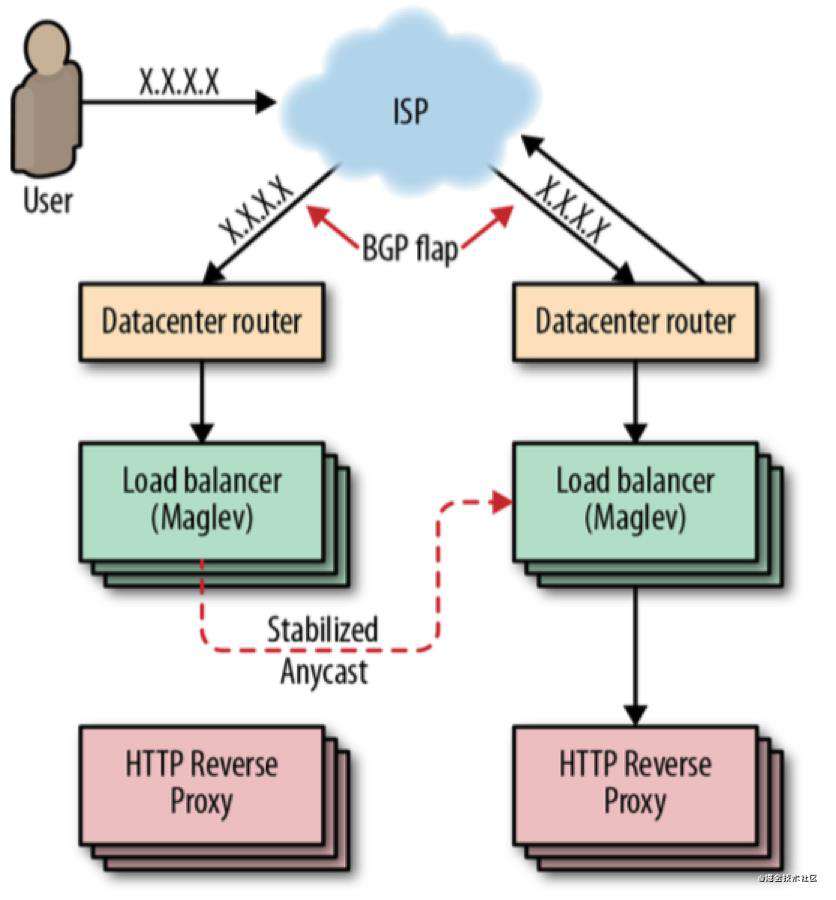 如果只有一个 VIP,即可以增加 DNS 记录的TTL,减少解析的延迟。
Anycast 可以使用一个 IP,将数据路由到最近的一组服务器,通过 BGP 宣告这个 IP,但是这存在两个问题:
如果某个节点承载过多的用户会过载
BGP 路由计算可能会导致连接重置
因此需要一个 “稳定 Anycast” 技术来实现。
如果只有一个 VIP,即可以增加 DNS 记录的TTL,减少解析的延迟。
Anycast 可以使用一个 IP,将数据路由到最近的一组服务器,通过 BGP 宣告这个 IP,但是这存在两个问题:
如果某个节点承载过多的用户会过载
BGP 路由计算可能会导致连接重置
因此需要一个 “稳定 Anycast” 技术来实现。
CDN 系统架构
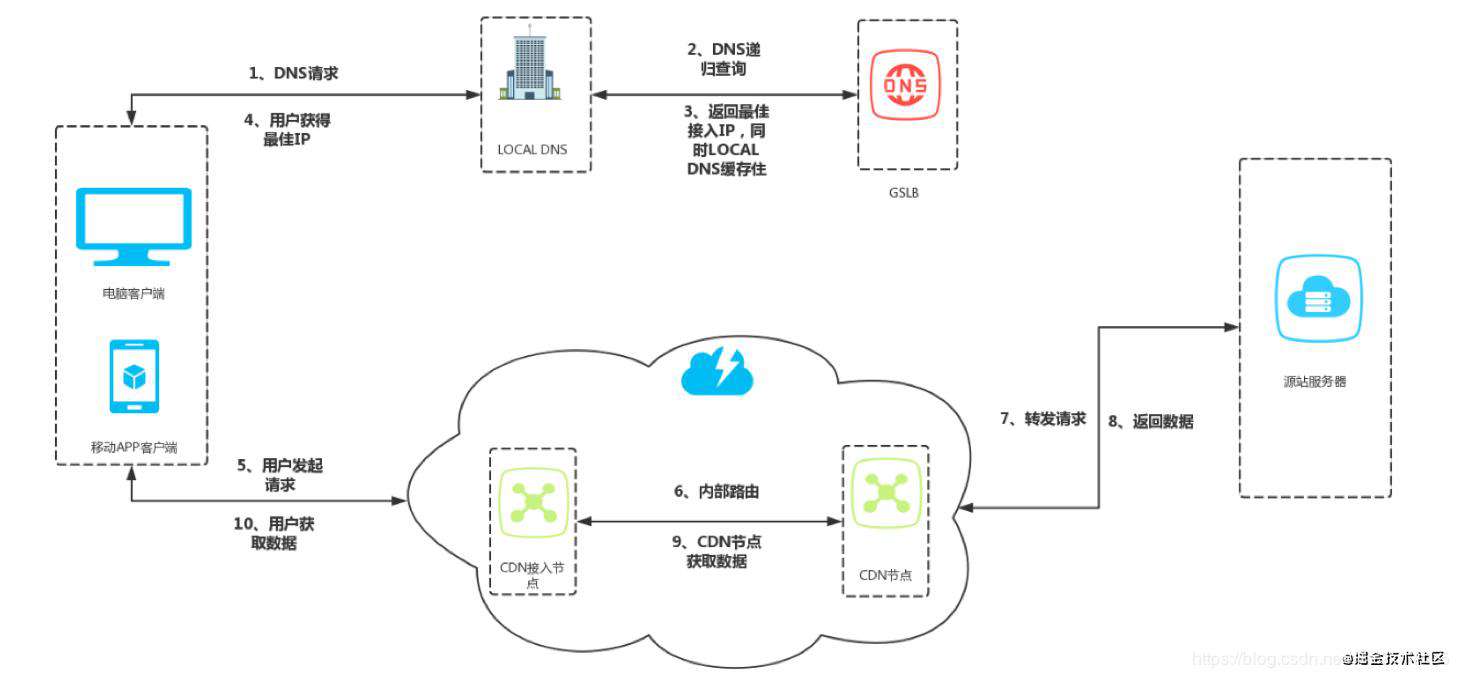
用户DNS--请求 local DNS --> DNS递归查询 ---> local DNS缓存数据---> 用户拿到最佳IP 然后连接边缘节点--> 连接中心机房
缓存代理
通过智能 DNS 的筛选,用户的请求被透明地指向离他最近的省内骨干节点,最大限度的缩短用户信息的传输距离。
路由加速
利用接入节点和中继节点或者多线节点互联互通。
安全保护
无论面对是渗透还是 DDoS攻击,攻击的目标大都会被指向到了 CDN,进而保护了用户源站。
节省成本
CDN 节点机房只需要在当地运营商的单线机房,或者带宽相对便宜的城市,采购成本低。
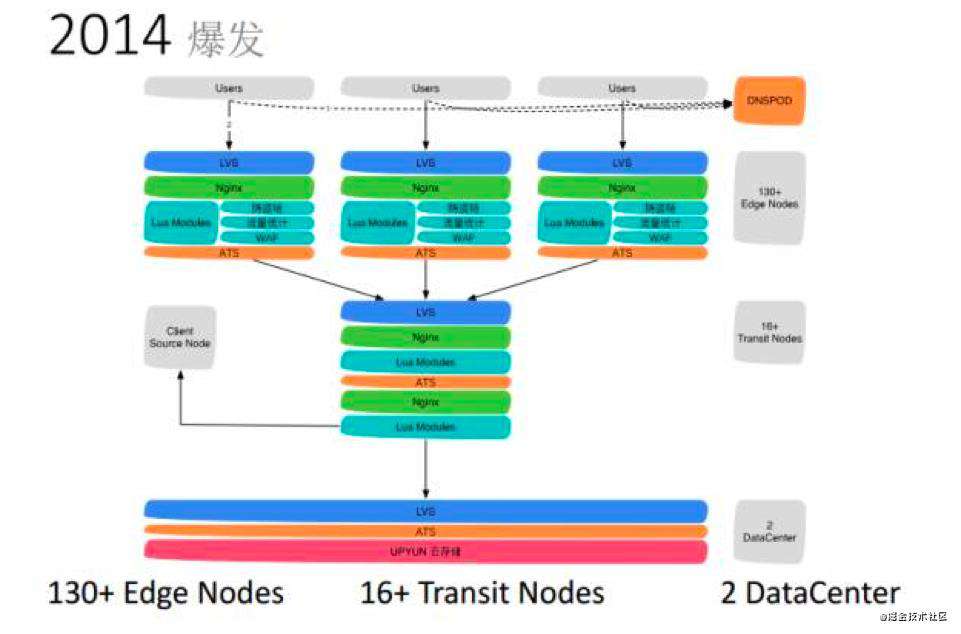
内容路由
DNS系统、应用层重定向,传输层重定向。
内容分发
- PUSH:主动分发,内容管理系统发起,将内容从源分发到 CDN 的 Cache 节点。
- PULL:被动分发技术,用户请求驱动,用户请求内容中 miss,从源中或者其他 CDN 节点中实时获取内容。
内容存储
随机读、顺序写、小文件的分布式存储。
内容管理
提高内容服务的效率,提高CDN的缓存利用率。
CDN 数据一致性
PUSH
不存在数据一致性问题。
PULL
缓存更新不及时,数据一致性问题,可设置缓存的失效时间,可以达到最终一致性。如果用户对一致性要求比较高也可以使用 ?version=xx 的技术,也可以每次上传图片返回的url是不同的方式来代替版本号。 CDN 存储的资源复本指定过期时间,因而缓存图像文件可在一个小时,一个月有效的。任何资源缓存在 CDN 上,是潜在历史版本,因为在源数据与副本之间总是有一个更新与传输的延迟。
Expires
即在 HTTP 头中指明具体失效的时间(HTTP/1.0)
Cache Control
max-age 在 HTTP 头中按秒指定失效的时间,优先级高于Expires(HTTP/1.1)
Last-Modified / If-Modified-Since
文件最后一次修改的时间(精度是秒,HTTP/1.0),需要 Cache-Control 过期。
Etag
当前资源在服务器的唯一标识(生成规则由服务器决定)优先级高于Last-Modified
静/动态 CDN 加速
CDN 最佳实践
多活系统
业务分级
按照一定的标准将业务进行分级,挑选出核心的业务,只为核心业务核心场景设计异地多活,降低方案整体复杂度和实现成本。例如:1、访问量;2、核心场景;3、收入;避免进入所有业务都要全部多活,分阶段分场景推进。
数据分类
挑选出核心业务后,需要对核心业务相关的数据进一步分析,目的在于识别所有的数据及数据特征,这些数据特征会影响后面的方案设计。常见的数据特征分析维度有:1、数据量;2、唯一性;3、实时性;4、可丢失性;5、可恢复性;
数据同步
确定数据的特点后,我们可以根据不同的数据设计不同的同步方案。常见的数据同步方案有:1、存储系统同步;2、消息队列同步;3、重复生成;
异常处理
无论数据同步方案如何设计,一旦出现极端异常的情况,总是会有部分数据出现异常的。例如,同步延迟、数据丢失、数据不一致等。异常处理就是假设在出现这些问题时,系统将采取什么措施来应对。常见的异常处理措施:1、多通道同步;2、同步和异步访问;3、日志记录;4、补偿;
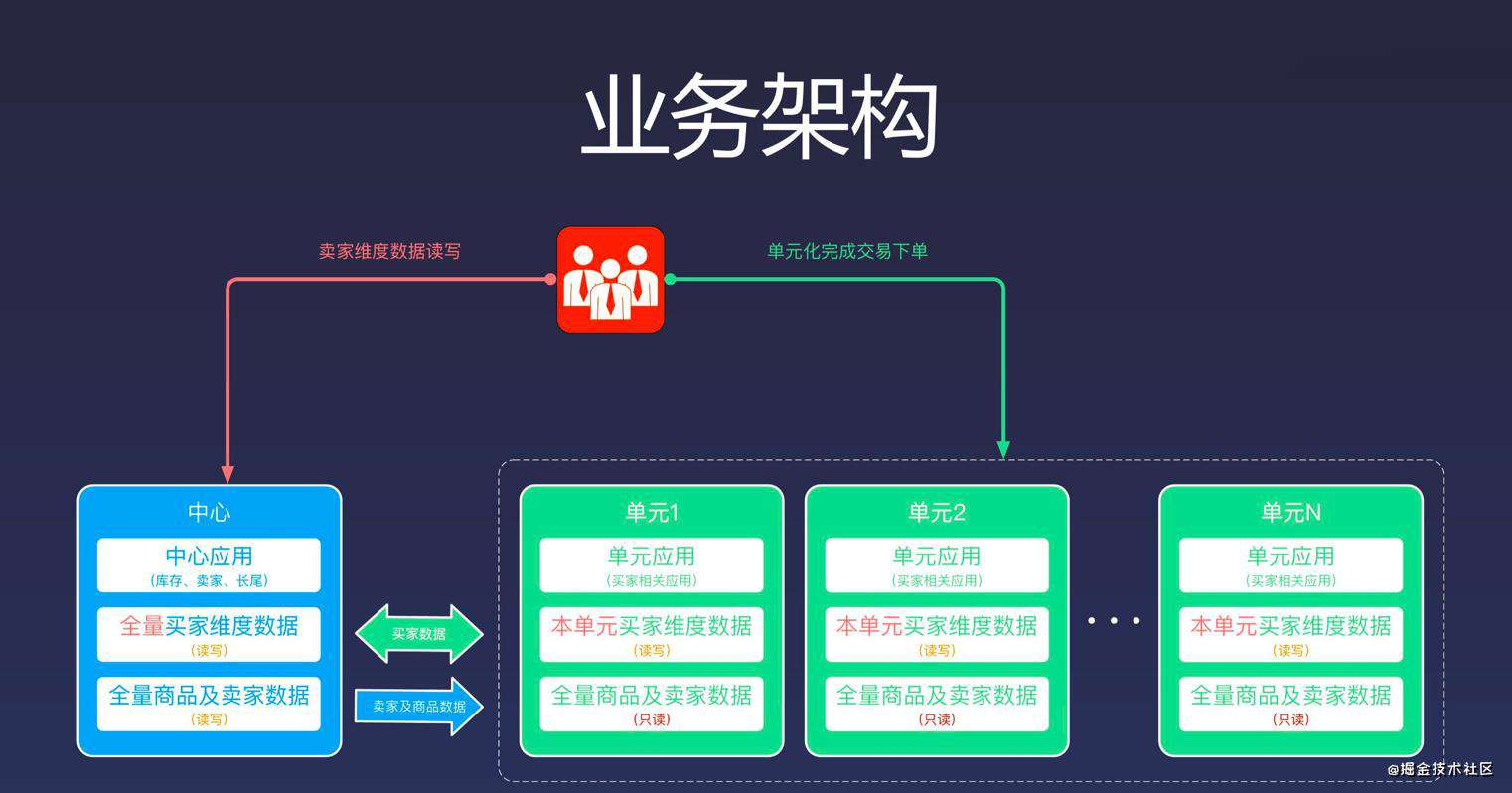
多活不是整个体系业务的多活,而是分成不同维度,不同重要性的多活,比如我们业务观看体验为主(淘宝以交易单元,买家为维度),那么第一大前提就是浏览、观看上的多活。我们将资源分为三类:
- Global 资源:多个 Zone(机房)共享访问的资源,每个 Zone 访问本 Zone 的资源,但是 Global 层面来说是单写 Core Zone(核心机房),即:单写+多读、利用数据复制(写Zone 单向)实现最终一致性方案实现;
- Multi Zone 资源:多个 Zone 分片部署,每个 Zone 拥有部分的 Shard 数据,比如我们按照用户维度拆分,用户 A 可能在 ZoneA,用户 B 可能在 ZoneB,即:多写+多读、利用数据复制(写 Zone 双向复制)方案实现;
- Single Zone 资源:单机房部署业务;
核心主要围绕:PC/APP 首页可观看、视频详情页可打开、账号可登陆、鉴权来开展,我们认为最合适我们观看类业务最合适的场景就是采用 Global 资源策略,对于社区类(评论、弹幕)可能会采用 Multi Zone 的策略。
饿了么多活
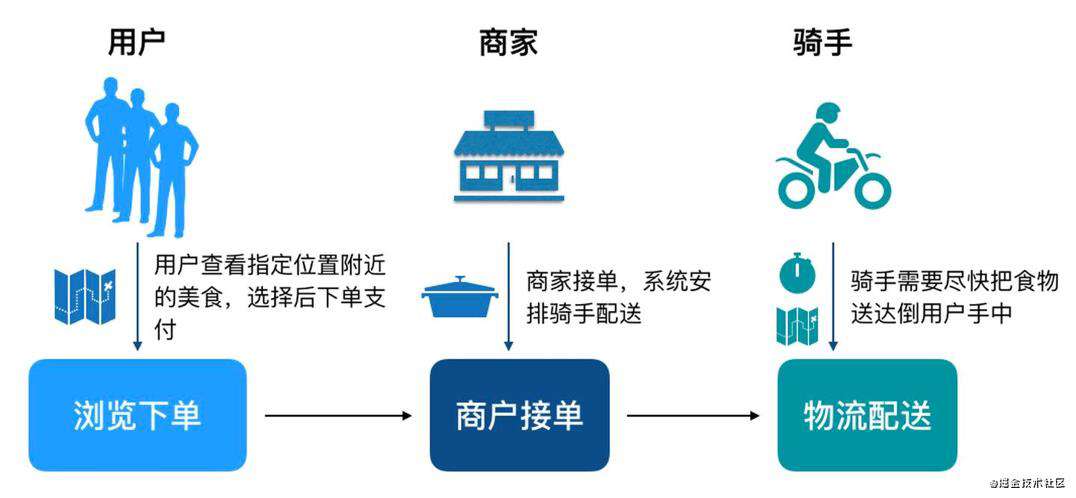
业务过程中包含3个最重要的角色,分别是用户、商家和骑手,一个订单包含3个步骤:
- 用户打开我们的APP,系统会推荐出用户位置附近的各种美食,推荐顺序中结合了用户习惯,推荐排序,商户的推广等。用户找到中意的食物 ,下单并支付,订单会流转到商家。
- 商家接单并开始制作食物,制作完成后,系统调度骑手赶到店面,取走食物。
- 骑手按照配送地址,把食物送到客户手中。
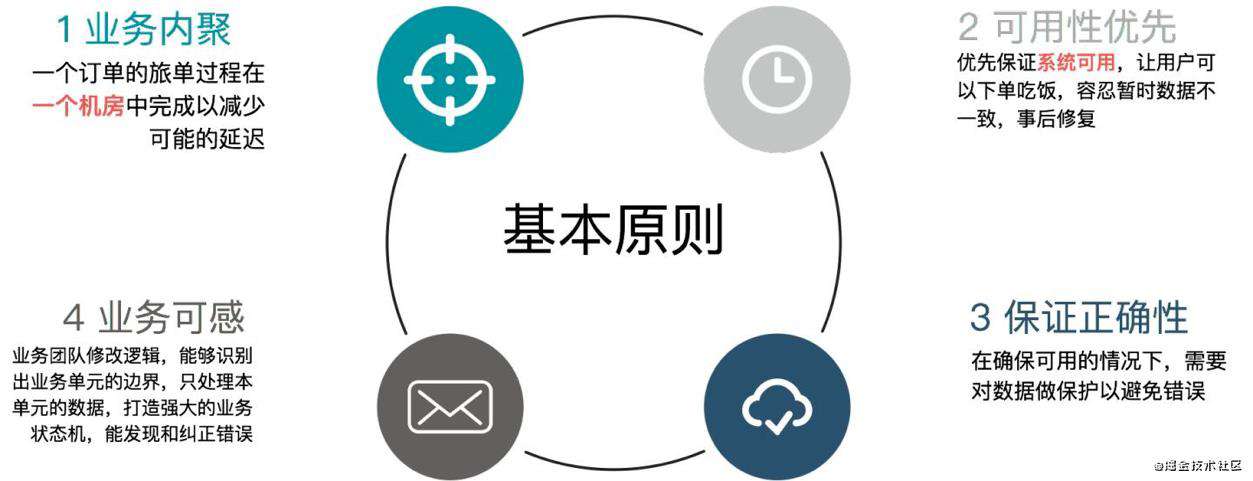
业务内聚
单个订单的旅单过程,要在一个机房中完成,不允许跨机房调用。
- 这个原则是为了保证实时性,旅单过程中不依赖另外一个机房的服务,才能保证没有延迟。
- 我们称每个机房为一个 ezone,一个 ezone 包含了饿了么需要的各种服务。
- 一笔业务能够内聚在一个 ezone 中,那么一个定单涉及的用户,商家,骑手,都会在相同的机房,这样订单在各个角色之间流转速度最快,不会因为各种异常情况导致延时。
- 恰好我们的业务是地域化的,通过合理的地域划分,也能够实现业务内聚。
可用性优先
- 当发生故障切换机房时,优先保证系统可用,首先让用户可以下单吃饭,容忍有限时间段内的数据不一致,在事后修复。
- 每个 ezone 都会有全量的业务数据,当一个 ezone 失效后,其他的 ezone 可以接管用户。
- 用户在一个ezone的下单数据,会实时的复制到其他ezone。
保证数据正确
在确保可用的情况下,需要对数据做保护以避免错误,在切换和故障时,如果发现某些订单的状态在两个机房不一致,会锁定该笔订单,阻止对它进行更改,保证数据的正确。
业务可感
因为基础设施还没有强大到可以抹去跨机房的差异,需要让业务感知多活逻辑,业务代码要做一些改造,包括:需要业务代码能够识别出业务数据的归属,只处理本 ezone 的数据,过滤掉无关的数据。完善业务状态机,能够在数据出现不一致的时候,通过状态机发现和纠正。
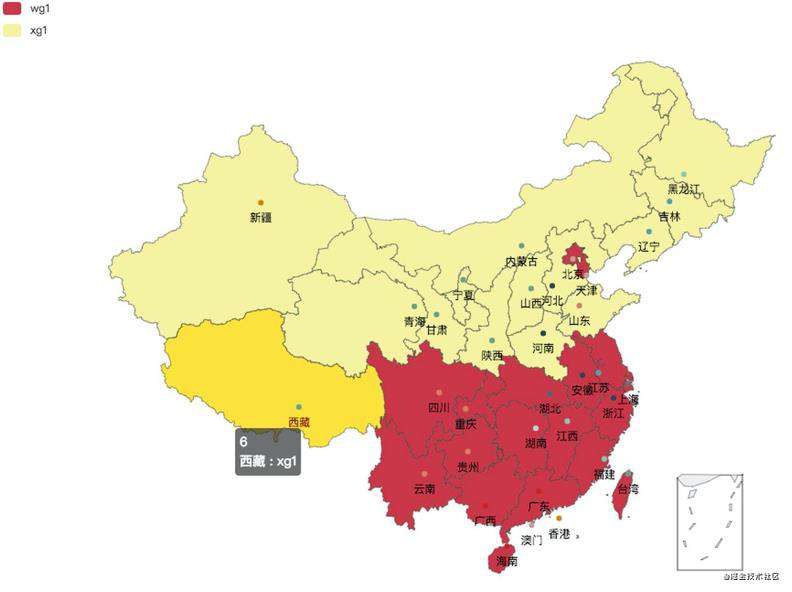
为了实现业务内聚,我们首先要选择一个划分方法(Sharding Key),对服务进行分区,让用户,商户,骑手能够正确的内聚到同一个 ezone 中。分区方案是整个多活的基础,它决定了之后的所有逻辑。
根据饿了么的业务特点,我们自然的选择地理位置(地理围栏,地理围栏主体按照省界划分,再加上局部微调)作为划分业务的单元,把地理位置上接近的用户,商户,骑手划分到同一个ezone,这样一个订单的履单流程就会在一个机房完成,能够保证最小的延时,在某个机房出现问题的时候,也可以按照地理位置把用户,商户,骑手打包迁移到别的机房即可。
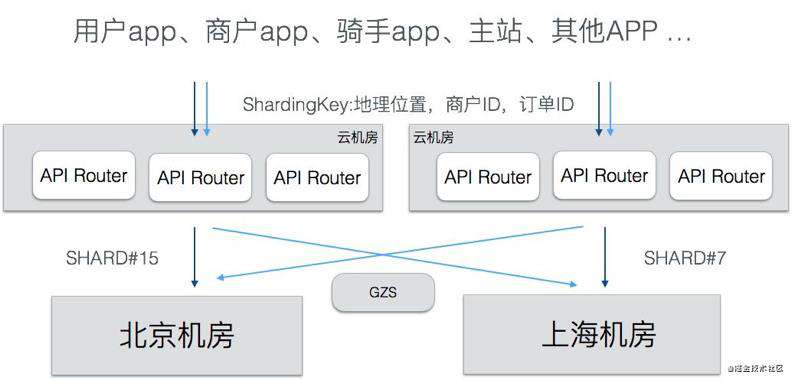
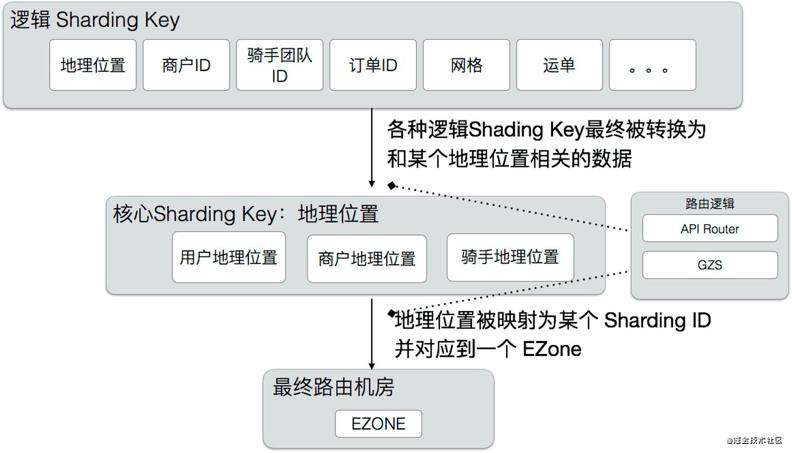 基于地理位置划分规则,开发了统一的流量路由层(API Router),这一层负责对客户端过来的 API 调用进行路由,把流量导向到正确的 ezone。API Router 部署在多个公有云机房中,用户就近接入到公有云的API Router,还可以提升接入质量。
基于地理位置划分规则,开发了统一的流量路由层(API Router),这一层负责对客户端过来的 API 调用进行路由,把流量导向到正确的 ezone。API Router 部署在多个公有云机房中,用户就近接入到公有云的API Router,还可以提升接入质量。
最基础的分流标签是地理位置,有了地理位置,AR 就能计算出正确的 shard 归属。但业务是很复杂的,并不是所有的调用都能直接关联到某个地理位置上,我们使用了一种分层的路由方案,核心的路由逻辑是地理位置,但是也支持其他的一些 High Level Sharding Key,这些 Sharding Key 由 APIRouter 转换为核心的 Sharding Key,具体如下图。这样既减少了业务的改造工作量,也可以扩展出更多的分区方法。除了入口处的路由,我们还开发了 SOA Proxy,用于路由SOA调用的,和API Router基于相同的路由规则。
阿里多活

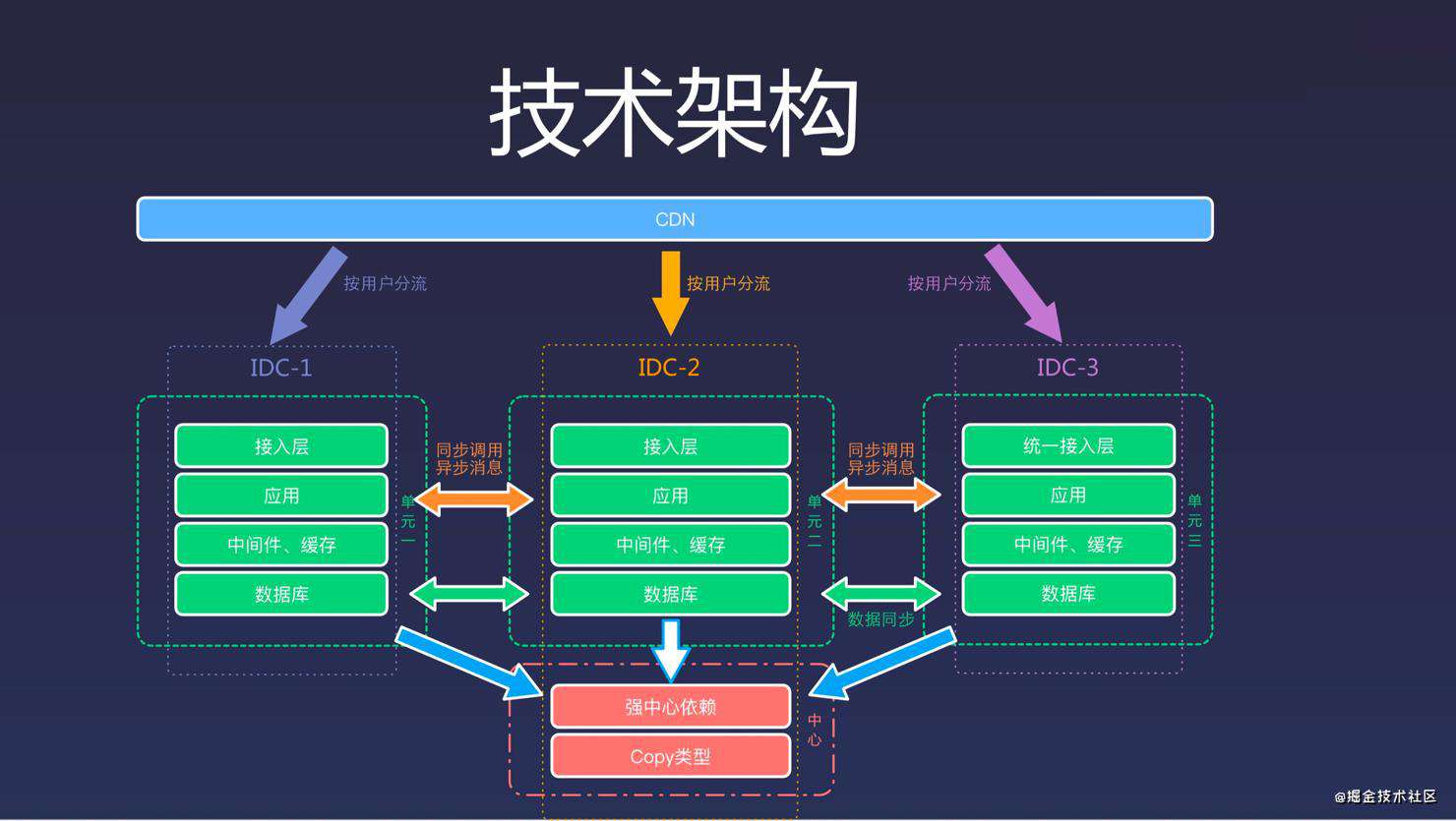
苏宁多活
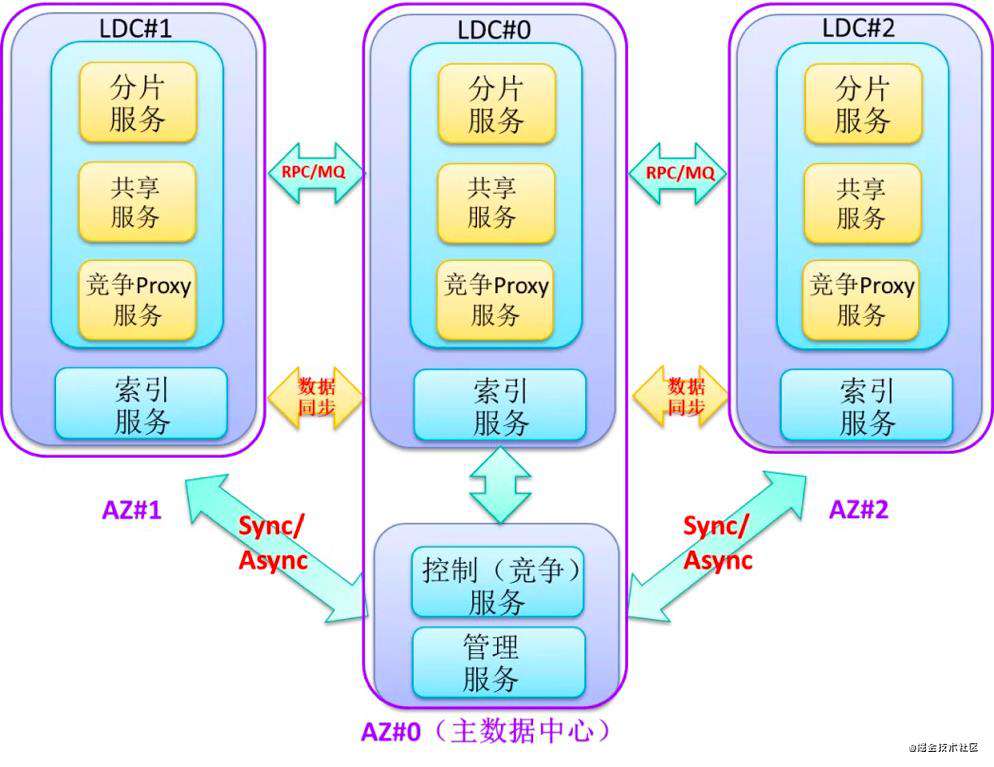
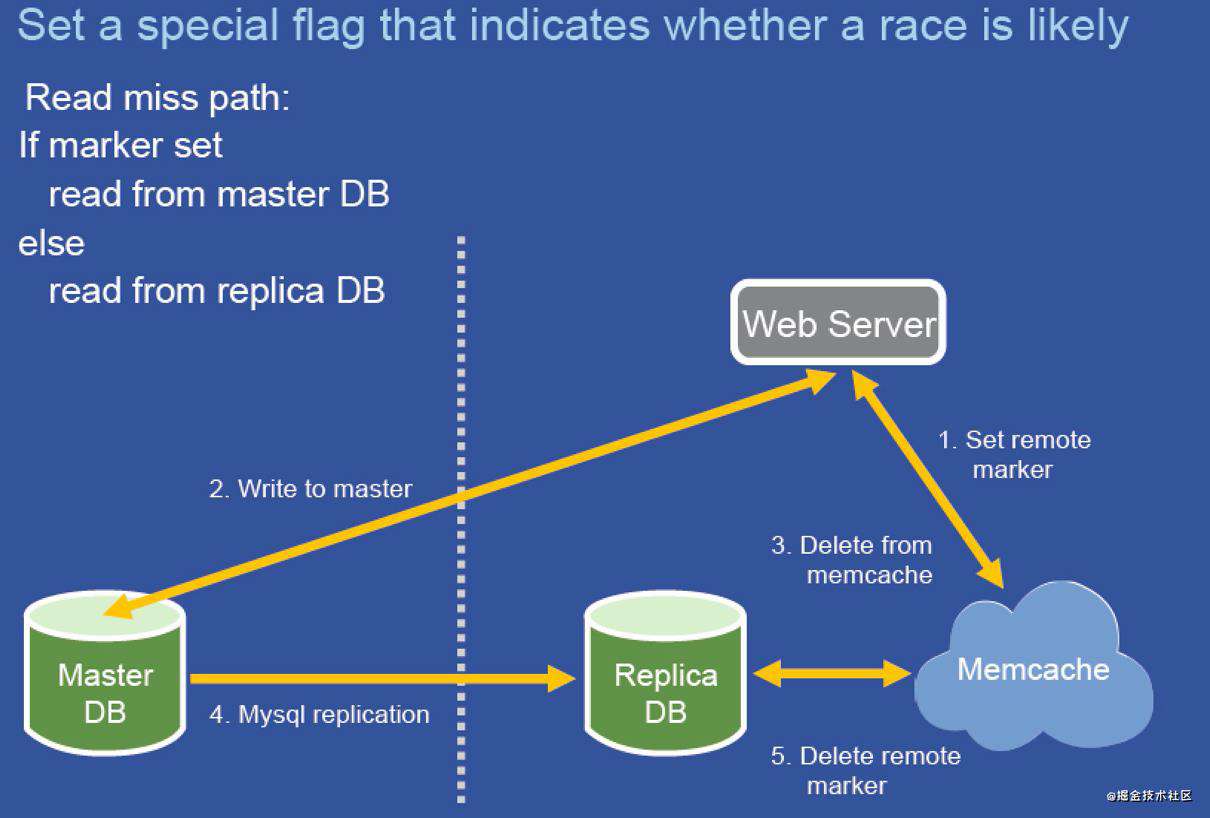
Facebook Memcache一致性
References
https://zhuanlan.zhihu.com/p/32009822
https://zhuanlan.zhihu.com/p/32587960
https://zhuanlan.zhihu.com/p/33430869
https://zhuanlan.zhihu.com/p/34958596
https://mp.weixin.qq.com/s/ooPLV039BAGBsiDZagWNHw
https://mp.weixin.qq.com/s/VPkQhJLl_ULwklP1sqF79g
https://mp.weixin.qq.com/s/ty5GltO9M648OXSWgLe_Sg
https://mp.weixin.qq.com/s/GdfYsuUajWP-OWo6lbmjVQ
https://developer.aliyun.com/article/57715
https://mp.weixin.qq.com/s/RQiurTi_pLkmIg_PSpZtvA
https://mp.weixin.qq.com/s/LCn71j3hgm5Ij5tHYe8uoA
http://afghl.github.io/2018/02/11/distributed-system-multi-datacenter-1.html
https://zhuanlan.zhihu.com/p/42150666
https://zhuanlan.zhihu.com/p/20827183
https://myslide.cn/slides/733
https://blog.csdn.net/u012422829/article/details/83718296
https://blog.csdn.net/u012422829/article/details/83932829
https://www.cnblogs.com/king0101/p/11908305.html
https://mp.weixin.qq.com/s/WK8N4xFxCoUvSpXOwCVIXw
https://mp.weixin.qq.com/s/jd9Os1OAyCXZ8rXw8ZIQmg
https://cloud.tencent.com/developer/article/1441455
https://mp.weixin.qq.com/s/RQiurTi_pLkmIg_PSpZtvA
https://help.aliyun.com/document_detail/72721.html
https://mp.weixin.qq.com/s/h_KWwzPzszrdGq5kcCudRA
https://www.cnblogs.com/davidwang456/articles/8192860.html
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!