React server component是什么?
2020年的12月21日,react官方对外宣布了一个还处于打磨阶段的新特性:“React server component”。官网的blog上对于“React server component”的简短描述也赫然于屏幕上:
仅仅凭【Zero-Bundle-Size】寥寥数语,我们无法对这个概念展开理解。那,到底什么是React Server Components?
经过一番研究,我基本弄清楚React server component到底是什么了:
-
首先,“React server component”也是一种“React component”。之所以加入“server”这个词,是因为React server component的代码执行环境是在服务器上的。为了区别与我们日常所写的,组件代码是在浏览器环境被执行的React component,我们把前者称为“React server component”,后者称为“React client component”。
-
其次,我们可以从组件所在文件的命名方式来区分哪些是“React server component”,哪些是“React client component”。 目前而言,官方暂定“React server component”需要以“.server.js(/ts/jsx/tsx)”为后缀,“React client component”需要以“.client.js(/ts/jsx/tsx)”为后缀。虽然这种命名方式是暂定的,但是却反映出了一个基本不变的事实:我们需要在文件命名层面去区分React server component和React client component。这样做的目的是因为Bundlers,linter等相关工具需要对两者作出区分,以便采用不同的操作策略。所以,我们可以反过来从文件命名来理解“什么是React Server Components”。
-
最后,“React server component”狭义上理解是一种React component,广义上理解却是react社区的一种新的渲染技术。 这种渲染技术介于纯客户端渲染(pure client rendering)和 纯服务端渲染(pure server rendering)之间,同时也不等同于SSR(server side rendering)。我们可以称之为“混合渲染”。同时,该特性一旦正式发布,则是标志着服务器正式纳入到的前端编程环境的范畴。
产生的背景
自从以Google为首的大厂大力推广ajax技术以来,前端一直借助浏览器在“胖”客户端(thick client)领域深耕。如今,我们好好地,我们为啥要没事找事呢?实话说,“找不找事”的这个决定权不在我们这些平民的手上,而是在于巨头,或者更准确地说,在React核心团队的手上。React官方无论是在Dan的视频介绍里面,还是在RFC: React Server Components都把研发“react server component”的这个动机交代得挺清楚的。前端开发面临三个方面的取舍:1)用户体验; 2)维护成本; 3)性能。我们在设计实现方案的时候,往往纠结于是要优先考虑“用户体验”多点,还是优先考虑“维护成本”多点,还是优先考虑“性能”多点。现存的技术方案只能支撑我们三者取其一,而React核心团队觉得我们可以三者都要,实现真正的“鱼与熊掌兼得”。这就是“React server component”提出的大背景。简单来说,是前端想要得更多了。
1. 我们想要更小的打包体积
为了性能,为了首屏加载得更快,前端在缩减首屏加载js代码的体积这一块真是绞尽脑汁。按需import ,tree-shaking, ,lazy load和code split都纷纷粉墨登场。这些方案确实或多或少减小了首屏加载js代码的体积。但是,React官方觉得这些方案没有很多地解决一个常见场景所遇到的问题-使用大型第三方类库(比如说,使用一个markdown库去解析markdown或者使用日期库去做格式化)所引入的运行时代码过多问题。
日常开发的过程中,我们没办法做到编写所有的代码,我们往往会使用第三方的类库。如果这个类库的体积很大并且不可tree-shaking的话,那么问题就来了。为了某个计算任务,我们需要把这个体积很大的js类库传输到浏览器上,解析和执行它来创造计算任务所需要的run time。从这个角度来看,为了一个很小的计算任务,我们占用了较大的带宽和CPU资源。用官方给出的demo来举例子,为了渲染一个用markdown写的笔记,我们需要用到240kb的js代码(gzip之后是74kb)充当运行时:
// NoteWithMarkdown.js
// NOTE: *before* Server Components
import marked from 'marked'; // 35.9K (11.2K gzipped)
import sanitizeHtml from 'sanitize-html'; // 206K (63.3K gzipped)
function NoteWithMarkdown({text}) {
const html = sanitizeHtml(marked(text));
return (/* render */);
}
但是一个事实摆在我们的面前。我们加载的首屏中,笔记只是用于查看,此时此刻它是纯静态的(不需要用户与之交互)。那么如果我们能够在服务器上把它渲染成静态内容,我们是不是省掉把大量js代码传输到客户端,解析和执行的成本了呢?有了React server component,我们能够做到这一点。当然,你会说,传统的纯服务端渲染或者SSR也能做到一点啊。确实如此,只不过React server componen不仅能做到这一点,而且还实现了其他的功能,此乃后话。在此,还值得强调的是,React server component在服务端执行之后,返回的不是HTML字符串,而是React自定义的类json字符串。
我们把上面的例子的组件改为React server component之后,在首屏加载的时候,我们能避免将240kb的js代码传输到客户端:
// NoteWithMarkdown.server.js - Server Component === zero bundle size
import marked from 'marked'; // zero bundle size
import sanitizeHtml from 'sanitize-html'; // zero bundle size
function NoteWithMarkdown({text}) {
// same as before
}
其实,这240kb的js代码是在服务器上被执行了,服务器最终会返回这个执行结果(React自定义的类json字符串)给到客户端。只不过,相比240kb,这些类json字符串的体积几乎可以忽略不计或者说不能算是打包后的代码。这就是官方声称【Zero-Bundle-Size】的确切含义。
2. 我们想要服务器能力
自从ajax开启了【胖客户端】时候之后,前端在客户端已经勤勤恳恳耕耘了十多年了,能力的挖掘似乎也到了一个瓶颈。而近几年,随着nodejs生态的成熟和应用的广泛化,前端业界纷纷把目光再次聚焦到服务器上-我们尝试从服务器上来获得更多的能力来增强前端能力。如此看来,古人诚不欺我也。天下大势合久必分,分久必合。前端与后端的分化与融合也是如此。从没有前端的这个分工,再到胖客户端大流行,再到目前的BFF(Backend For Frontend),SSR和React server component的前后端再融合,历史总是惊人的相似。
无论是BFF,SSR还是React核心团队所提出的server component,本质上都是想借助服务器的能力来增强前端的能力。 不同的一点是,这次React团队以官方的口吻明确并重点提出想要服务器编程所提供的【数据操作能力】。比如说,他们在RFC中就指出,通过介入服务器,前端可以获得以下的【数据操作能力】:
- 自由整合后端API的能力。这也是BFF中间层提出的初衷。通过自由整合后端API,我们可以解决目前【胖客户端】在数据获取方面的两个问题:【网络往返过多】和【数据冗余】。
- 自由决定数据在服务端的存储方式。比如说,我们可以根据业务场景,自由地决定数据是存储在内存,还是存储在文件,或者存储在数据库里面。
更进一步的话,前端可以拥有自己的数据库,而谁离数据库更近,谁的话语权就更大。介入服务器编程,我们不但能提升前端能力,而且能提升前端在整个软件生产流程中的话语权。
3. 我们想要code split自动化
所谓的code split,就是在打包的时候,把一个大的js文件(bundle)打包成几个小的js文件(chunk),然后在运行时来按需加载。在React生态里面,无论是用React包所提供的lazy() + 动态import,还是使用第三方类库@loadable,它们都有两个不足点:
- code split工作全程需要手动编码来指出切割点所在,比如:
// PhotoRenderer.js
// NOTE: *before* Server Components
import React from 'react';
// one of these will start loading *when rendered on the client*:
const OldPhotoRenderer = React.lazy(() => import('./OldPhotoRenderer.js'));
const NewPhotoRenderer = React.lazy(() => import('./NewPhotoRenderer.js'));
function Photo(props) {
// Switch on feature flags, logged in/out, type of content, etc:
if (FeatureFlags.useNewPhotoRenderer) {
return <NewPhotoRenderer {...props} />;
} else {
return <OldPhotoRenderer {...props} />;
}
}
如上,我们需要手动编码来把我们的原始组建“包裹”两层才能完成一个组件的code split工作。
- 目前的code split的按需加载也是即时加载,也就是说,只有加载到了代码切割点,我们才会去即时加载所切割好的代码。这里还是存在一个加载等待的问题,削减了code split给性能所带来的好处。
React核心团队所提出并初步实现的server componen可以帮助我们解决上面的两个问题。
- 第一,我们通过区分server component和client component来实现自动的code split。具体的实现是:默认把所有的对client component的import来当作代码切割点,由react-server-dom-webpack这个类库来完成代码切割的工作。
// PhotoRenderer.server.js - Server Component
import React from 'react';
// one of these will start loading *once rendered and streamed to the client*:
import OldPhotoRenderer from './OldPhotoRenderer.client.js';
import NewPhotoRenderer from './NewPhotoRenderer.client.js';
function Photo(props) {
// Switch on feature flags, logged in/out, type of content, etc:
if (FeatureFlags.useNewPhotoRenderer) {
return <NewPhotoRenderer {...props} />;
} else {
return <OldPhotoRenderer {...props} />;
}
}
如上,我们像往常没有引入code split的时候去编写代码即可,code split由整合了server component的框架或者工具来自动帮我们实现。
- 第二,因为我们可以介入server component的渲染结果,因此我们可以根据当前请求的上下文来预测用户的下一个动作,从而去【预加载】对应的js代码。通过【预加载】,我们可以解决上面所提到的第二个问题。
4. 我们想要避免高度抽象所带来的性能负担
相比于设计一套新的模板语法,React几乎100%拥抱了javascript。因此,我们可以使用函数组合和function reflection来创建强大的UI抽象。然而,过度的抽象会引入过多的代码和运行时开销。如果,一个UI框架是用静态语言来编写的话,那么按理说,它是可以利用AOT编译技术来剥离抽象层的。因为javascript是一种动态弱类型的语言,所以这对于它来说,效果不大。
react核心团队尝试跟Prepack团队通力合作,尝试利用AOT技术来优化react应用的代码体积,但是最终宣告尝试失败。具体来说,React核心团队意识到许多AOT优化无法正常工作,因为它们要么没有足够的全局方面的上下文,要么就太少了。例如,一个组件实际上可能是静态的,因为它总是从其父级接收一个常量字符串的prop,但是编译器看不到那么远,并认为该组件是动态的。即使我们可以进行优化,但是优化后的代码不具备良好的可调试性和维护性。这种不可靠性不是我们开发者能接受的。
React server component通过在服务器上的实时编译和渲染,将抽象层在服务器进行剥离,从而降低了抽象层在客户端运行时所带来的性能开销。举个例子,如果一个组件为了可配置行,被多个wrapper包了很多层。但事实上,这些代码最终只是渲染为一个<div>。如果把这个组件改造为server component的话,那么我们只需要往客户端返回一个<div>字符串即可。下面例子,我们通过把这个组件改造为server component,那么,我们大大降低网络传输的资源大小和客户端运行时的性能开销:
// Note.server.js
// ...imports...
function Note({id}) {
const note = db.notes.get(id);
return <NoteWithMarkdown note={note} />;
}
// NoteWithMarkdown.server.js
// ...imports...
function NoteWithMarkdown({note}) {
const html = sanitizeHtml(marked(note.text));
return <div ... />;
}
// client sees:
<div>
<!-- markdown output here -->
</div>
5. 我们想要一个关于前后端融合的统一技术方案
web技术发展伊始,我们是处于【瘦可客户端】的状态。但是随着对交互体验要求变高和ajax技术的诞生,我们有进入了一个【胖客户端】时代。如今,我们又意识到了,单纯依靠【瘦可客户端】或者【胖客户端】都无法同时满足当今web应用的对交互能力,用户体验和性能的要求。于是,业界开始探索前后端融合的技术方案。目前,前后端融合的技术方案有BFF,SSR,GraphQL等,甚至有些人回退到纯服务端渲染的技术方案。React核心团队在这样的背景下,想要实现前后端融合技术方案的统一。这才有了server component这个技术方案。
React server component技术方案做到了充分利用客户端渲染和服务端渲染利好的同时还支持基于组件粒度来提供一个充满弹性的自定义空间。我们可以通过结合自己的业务场景来决定client component:server component的比例,从而达到在【瘦可客户端】,【胖客户端】,【不胖不瘦客户端】之间随意切换。我把React server component技术方案称之为“游离型”的前后端融合技术方案。
与此同时,借助nodejs的加持,我们可以做到一门语言(javascript)通吃客户端编程和服务端编程。其中的好处(相同逻辑的代码复用,生态公用,跨端编程零心智负担的等),我在这里就不赘述了。写到这里,我仿佛看到了React的未来:meteor.js。
小结
从上面的背景陈述,我们可以得知,React server component能给前端带来以下的好处:
- 更小的首屏加载体积
- 更强大的数据处理能力
- 自动code split
- js chunk的预加载
- 一个统一且充满弹性的前后端融合技术方案
运作原理是什么?
首次加载的流程
下面以官方给出的Demo为研究样本,探索一下React sever component的运作原理。
我把应用的首次加载的流程分为两个阶段:
- 服务启动
- 运行时
服务启动
二话不说,服务启动的命令是npm run start,而start命令对应的是:
$ concurrently \"npm run server:dev\" \"npm run bundler:dev\"
从上面的命令,我们可以看出,服务启动的命令【并行】干了两件事:
npm run server:dev- 启动express服务器。通过阅读源码(api.server.js),我们可以看到,启动express服务器里面主要包含两件事:
1) 注册API路由的事件处理器。Demo中,有以下几个路由:
1. app.get('/',xxx)
2. app.get('/react',xxx)
3. app.post('/notes',xxx)
4. app.put('/notes/:id',xxx)
5. app.delete(/notes/:id',xxx)
6. app.get('/notes',xxx)
7. app.get('/notes/:id',xxx)
8. app.get('/sleep/:ms',xxx)
最值得我们关注的是/react这个路由。
2) 将build和public目录先后设置为静态资源的根目录。注意,在express框架中,这个先后是有讲究的。也就是说,当客户端向服务器请求静态资源的时候,优先考虑顺序上排在前者的目录。比如:
app.use(express.static('build'));
app.use(express.static('public'));
上面的代码中,客户端请求的静态资源,优先在build目录里面找,如果找不到的话,再去public目录里面找。
npm run bundler:dev- 打包客户端代码
通过查看./src/scripts/build.js这个打包脚本,我们可以很明确地知道这是一个客户端代码的打包和构建:
// build.js
entry: [path.resolve(__dirname, '../src/index.client.js')],// index.client.js是客户端代码的入口文件
output: {
path: path.resolve(__dirname, '../build'), // 打包后的main.js放在build目录。
filename: 'main.js',
}
于此同时,我们也知道打包后的静态资源是放在build目录。在这里值得隆重指出的是,客户端代码的打包用到了一个叫【ReactServerWebpackPlugin】的webpack plugin。这个plugin十分的重要。因为仅仅靠通过追踪客户端代码的入口文件的模块依赖树来打包的话,我们只会产出main.js和index.html。但是项目实际运行起来,我们还会看到build目录里面还有一些clientxxx.main.js之类的文件:
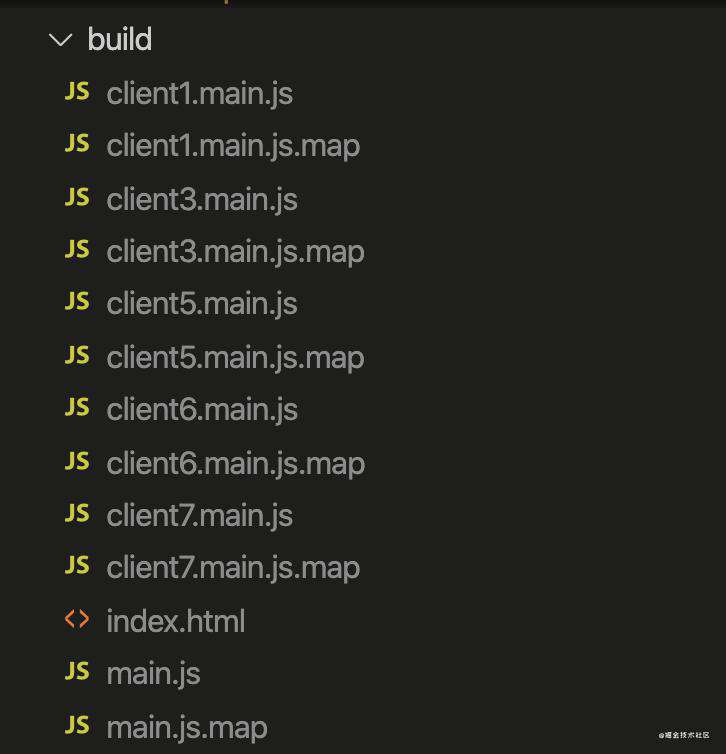
那它们是怎么打包出来的呢?答曰:“它们就是webpack在打包客户端代码的时候,同时通过使用ReactServerWebpackPlugin这个插件打包出来的。”更加具体一点来说,就是遍历项目中的所有的client component文件(因为我们把形如xxx.client.js|jsx|ts的文件约定为client component),打包出对应的chunk文件。我们可以尝试往src目录下添加一个Test.client.js文件:
// ./src/Test.client.js
import React from 'react';
export default function Test(){
return (<h1>I am a client component</h1>)
}
然后重新执行打包命令,你会看到build目录里面会多出个client7.main.js文件,打开里面看看:
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([["client7"],{
/***/ "./src/Test.client.js":
/*!****************************!*\
!*** ./src/Test.client.js ***!
\****************************/
/*! exports provided: default */
/***/ (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
__webpack_require__.r(__webpack_exports__);
/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, "default", function() { return Test; });
/* harmony import */ var react_jsx_dev_runtime__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(/*! react/jsx-dev-runtime */ "./node_modules/react/jsx-dev-runtime.js");
/* harmony import */ var react_jsx_dev_runtime__WEBPACK_IMPORTED_MODULE_0___default = /*#__PURE__*/__webpack_require__.n(react_jsx_dev_runtime__WEBPACK_IMPORTED_MODULE_0__);
/* harmony import */ var react__WEBPACK_IMPORTED_MODULE_1__ = __webpack_require__(/*! react */ "./node_modules/react/index.js");
/* harmony import */ var react__WEBPACK_IMPORTED_MODULE_1___default = /*#__PURE__*/__webpack_require__.n(react__WEBPACK_IMPORTED_MODULE_1__);
var _jsxFileName = "/Users/samliu/dayuwuxian/server-components-demo/src/Test.client.js";
function Test() {
return /*#__PURE__*/Object(react_jsx_dev_runtime__WEBPACK_IMPORTED_MODULE_0__["jsxDEV"])("h1", {
children: "I am a client component"
}, void 0, false, {
fileName: _jsxFileName,
lineNumber: 4,
columnNumber: 13
}, this);
}
/***/ })
}]);
//# sourceMappingURL=client7.main.js.map
没错,这就是我们添加的Test.client.js文件所打包构建出来的文件。这些client component的chunk文件是有别于main.js这种客户端代码的。因为客户端代码是index.html通过<script>标签发送请求获得的,而client component打包后的chunk文件是通过客户端代码(这里是指打包后产出的main.js)发送/react请求获得的,client component的源码并不一定需要存在(当然也可以存在)于入口文件的依赖树里面。这种chunk文件加载的时候,其实也没有马上执行我们的React component代码(这里是Test component),而只是把它挂在window对象的webpackJsonp属性上等待后续来使用(见上面的Test.client.js的chunk代码)。
下面做个总结。也就是说npm run bundler:dev命令做了两件事:
- 打包客户端代码(以/src/index.client.js为入口文件)
- 打包所有的client component文件。(如果clent component文件被客户端代码引用了,那么它们就会被打包到main.js里面。与此同时还是会单独打包出一个clientxxx.main.js。)
打包后的js代码跟模板文件index.html一起放在了build目录,其他比如样式的静态资源放在了public目录,一切静态资源准备完毕,等待着应用运行时来自于浏览器的请求。
运行时
二话不说,从浏览器和服务器的视角来看,官方Demo首屏加载的时序图如下:
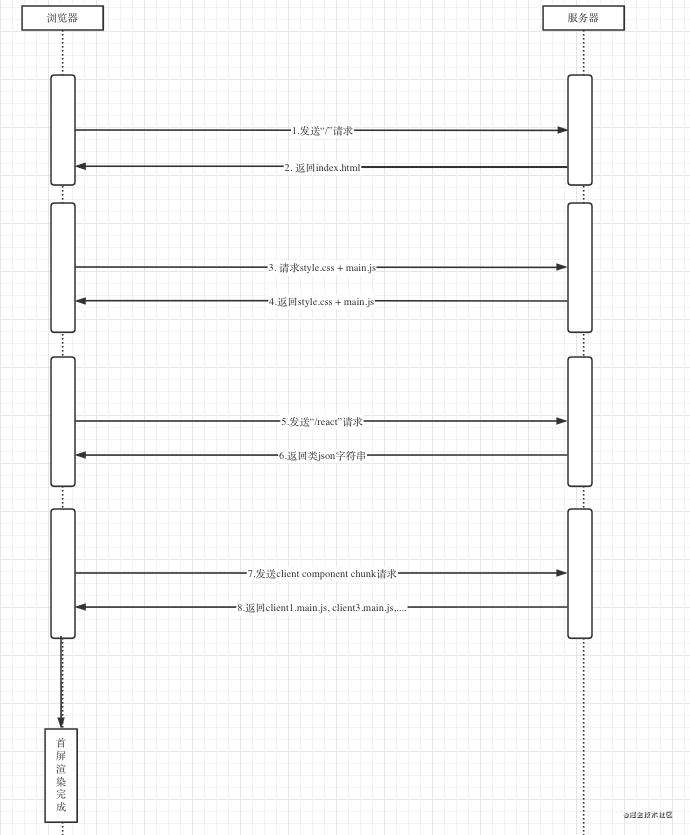
下面简单介绍一下各个环节的技术实现细节:
-
浏览器发起“/”请求。当用户在浏览器的地址栏输入网站URL-
http://localhost:4000/的时候,浏览器向express服务器发出了path为“/”的请求。在服务启动阶段,我们早就注册好对应的handler:app.get('/',handleErrors(async function(_req, res) { await waitForWebpack(); const html = readFileSync( path.resolve(__dirname, '../build/index.html'), 'utf8' ); // Note: this is sending an empty HTML shell, like a client-side-only app. // However, the intended solution (which isn't built out yet) is to read // from the Server endpoint and turn its response into an HTML stream. res.send(html); }) ); -
express服务器返回
build文件夹的index.html文件给浏览器。index.html是我们在服务启动阶段就打包好的,这里就不赘述了。 -
浏览器接收到
index.html文件,解析文件,构建DOM树。在这个过程中,它会遇到两个标签:<link rel="stylesheet" href="style.css" /> <script src="main.js"></script>
于是乎,浏览器又会向请求style.css(style.css放在了public目录)和main.js。
-
express服务器返回stye.css和main.js。浏览器在执行main.js的时候,会向express服务器发出
/react请求。main.js是客户端代码打包和构建出来,我们不妨沿着打包的入口文件去查看一下发起/react请求的源码在哪里。在Root.client.js的<Content />组件的源码中:function Content() { const [location, setLocation] = useState({ selectedId: null, isEditing: false, searchText: '', }); const response = useServerResponse(location); return ( <LocationContext.Provider value={[location, setLocation]}> {response.readRoot()} </LocationContext.Provider> ); }我们可以继续往useServerResponse函数的声明处追踪。通过代码导航,我们最终跳转到
Cache.client.js文件,useServerResponse函数声明如下:export function useServerResponse(location) { const key = JSON.stringify(location); const cache = unstable_getCacheForType(createResponseCache); let response = cache.get(key); if (response) { return response; } response = createFromFetch( fetch('/react?location=' + encodeURIComponent(key)) ); cache.set(key, response); return response; }到这里,我们可以看到,我们的“/react”请求是通过调用原生的fetch方法(当然,这个方法被使用monkey patch来封装过,源码见于index.html文件)来发起的。
-
express服务器接受到“/react”请求后,进入对应的路由handler:
// api.server.js app.get('/react', function(req, res) { sendResponse(req, res, null); }); function sendResponse(req, res, redirectToId) { const location = JSON.parse(req.query.location); if (redirectToId) { location.selectedId = redirectToId; } res.set('X-Location', JSON.stringify(location)); // 调用栈:renderReactTree -> pipeToNodeWritable -> createRequest -> resolveModelToJSON // 流式响应 renderReactTree(res, { selectedId: location.selectedId, isEditing: location.isEditing, searchText: location.searchText, }); } async function renderReactTree(res, props) { await waitForWebpack(); const manifest = readFileSync( path.resolve(__dirname, '../build/react-client-manifest.json'), 'utf8' ); const moduleMap = JSON.parse(manifest); pipeToNodeWritable(React.createElement(ReactApp, props), res, moduleMap); }到这里,我们可以看到很关键的三行代码:
const {pipeToNodeWritable} = require('react-server-dom-webpack/writer'); const ReactApp = require('../src/App.server').default; pipeToNodeWritable(React.createElement(ReactApp, props), res, moduleMap);我们先不深入研究这三行代码。当前,我们只需要知道它总体上干了一件事即可:渲染服务端组件
<App />,生成一份类json的数据( a JSON description of the UI)。下面我们来看看这份类json的数据的数据结构: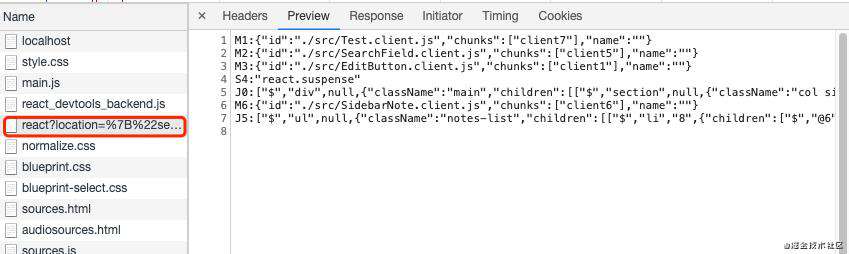
这份数据本质上就是一个普通的字符串,只不过通过加入了换行符
\n来格式化。每一行都是独立的数据单元,他们遵循共同的数据结构是:`${数据类型}${数据单元ID}:${可解析的json序列}`数据类型
从react-server-dom-webpack类库中负责解析类json字符串的方法
processFullRow()的实现来看:function processFullRow(response, row) { if (row === '') { return; } var tag = row[0]; // When tags that are not text are added, check them here before // parsing the row as text. // switch (tag) { // } var colon = row.indexOf(':', 1); var id = parseInt(row.substring(1, colon), 16); var text = row.substring(colon + 1); switch (tag) { case 'J': { resolveModel(response, id, text); return; } case 'M': { resolveModule(response, id, text); return; } case 'S': { resolveSymbol(response, id, JSON.parse(text)); return; } case 'E': { var errorInfo = JSON.parse(text); resolveError(response, id, errorInfo.message, errorInfo.stack); return; } default: { throw new Error("Error parsing the data. It's probably an error code or network corruption."); } } }数据类型有四种:
- M - client component chunk的引用信息。client component chunk就是我们前面启动服务时webpack(更准确地说是react-server-dom-webpack)通过遍历所有的client component文件所打包出来chunk文件;
- J - server component在服务端渲染的结果。这个结果是一个类react element格式的字符串。
- S - Suspense component。
- E - 服务端渲染过程所发生的错误信息。它的内容会被react-server-dom-webpack类库解析出来,并使用组件的FallbackComponent(
<Error />组件)显示出来。
数据单元ID
数据单元ID是react-server-dom-webpack在服务端从上到下“渲染”整个React tree的过程中从0递增得到的。在Demo,App.server.js里面的
<App />是这样的(<Test name="sam liu" />是我添加上去):<div className="main"> <section className="col sidebar"> <Test name="sam liu" /> <section className="sidebar-header"> <img className="logo" src="logo.svg" width="22px" height="20px" role="presentation" /> <strong>React Notes</strong> </section> <section className="sidebar-menu" role="menubar"> <SearchField /> <EditButton noteId={null}>New</EditButton> </section> <nav> <Suspense fallback={<NoteListSkeleton />}> <NoteList searchText={searchText} /> </Suspense> </nav> </section> <section key={selectedId} className="col note-viewer"> <Suspense fallback={<NoteSkeleton isEditing={isEditing} />}> <Note selectedId={selectedId} isEditing={isEditing} /> </Suspense> </section> </div>首先,
<App />是一个server component,所以,我们会得到一个【J】类型的key,它的ID是0,合起来就是【J0】。遇到host类型的component,都会把解析结果放在【J0】所对应的字符串值上。然后,继续往后走,遇见了我添加上去的<Test />组件,因为它是client component,所以,我们会得到一个【M】类型的key,它的ID是在0上递增1得1,合起来就是【M1】。再往下走,我们会遇到<SearchField />,因为它是client component,同样我们会得到一个【M】类型的key,它的ID是在1上递增1得2,合起来就是【M2】,后面的组件遍历,以此类推.....这里值得指出的一点是,因为server component是可以嵌套client component的,所以,在作为server component解析结果的类react element字符串中,你会看到这些client component的占位符:“@”,Suspense component的占位符:“$”(占位符后面还会跟着一个数字ID)。比如:
J0:["$","div",null,{"className":"main","children":[["$","section",null,{"className":"col sidebar","children":["$","@1",null,{"name":"sam liu"}],...]上面的字符串中出现了“@1”,那么这里面意思就是告诉react-server-dom-webpack浏览器运行时在解析到此处的时候去加载chunk ID为1的client component chunk,并在浏览器端“渲染”它,最后将“渲染”结果(类react element字符串)填充到这里。跟client component的占位符一样,类react element字符串中的“$+数字”,这个数字就是Suspense component在类json数据中的数据单元ID,我就不赘述了。
可解析的json序列
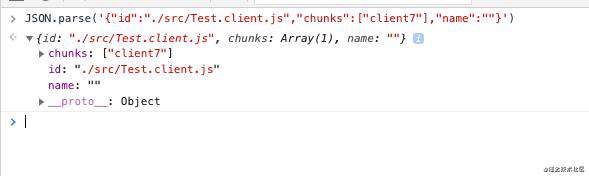
类json数据中,每一行除了数据类型+数据单元ID组成的【key】之外,那么剩下的可以称之为这个key的【值】。这个【值】是一个可以被JSON.parse()方法解析的字符串。不信?我们可以把上面截图中的数据解析一下:
解析M1的值:
解析J0的值:
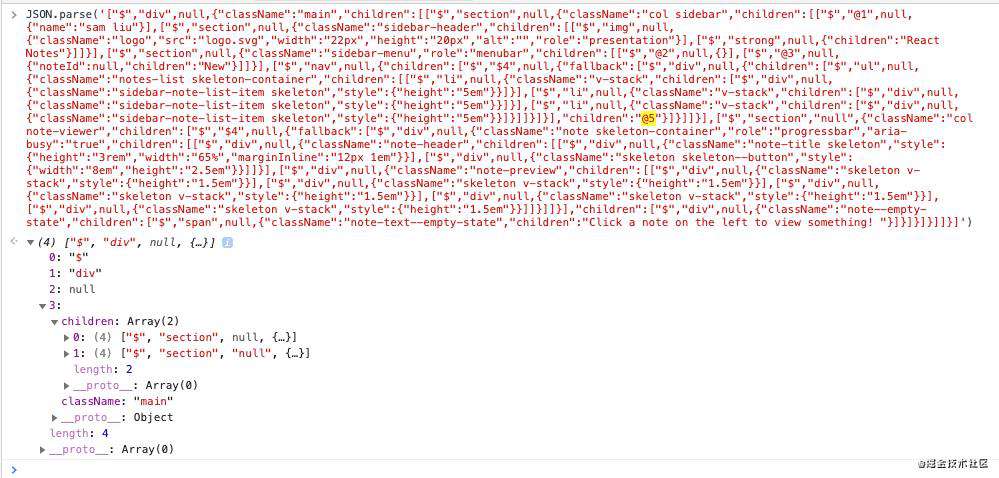
可以看出,
J*的值是一个类react element格式的字符串。相比于真正的react element,它是用一个包含四个数组元素的数组来表示一个react elment。这里面的具体格式就不深入探究了,日后有空再讨论。 -
浏览器接收到服务器返回的类json数据后,就使用react-server-dom-wepack浏览器运行时对它进行解析。在源码中,有这么几行代码可以佐证:
// cache.client.js import {createFromFetch} from 'react-server-dom-webpack'; export function useServerResponse(location) { // .... response = createFromFetch( fetch('/react?location=' + encodeURIComponent(key)) ); // ... }可以看出,服务端返回的类json字符串是由react-server-dom-webpack浏览器运行时所提供的
createFromFetch()方法来承接的。createFromFetch()方法调用结果是一个response对象(该对象将初步的解析结果就是放在response对象的_chunks字段上):
然后,我们会调用response对象的readRoot()方法得到真正的react element。最后,通过react-dom这个render将它渲染成浏览器的DOM结构。以上的整个过程可以用一张图来表示:

如果你想深入从类json数据到真正的react element的这个解析过程的细节,无疑,我们需要过一遍react-server-dom-webpack浏览器运行时的源码了。这里限于篇幅,不做深入探究。
-
如果react-server-dom-webpack在解析类json数据的时候,遭遇的某些client component chunk是浏览器没有加载过的话,那么浏览器起就会向服务器发起相关资源的请求。比如,在这个Demo中就是client4.main.js,client0.main.js和client5.main.js等。对于一个client component而言,它一旦被server component嵌套了,那么它在服务端被渲染后就被分离成两部分:一部分是静态的client component chunk,一部分是动态的props。静态部分是在服务启动阶段就准备(打包)好的,动态部分是放在类json的数据中。静态的client component chunk是存在缓存机制的,即一旦请求过就并不会再次请求了,否则就向服务器发起请求。动态部分会随着服务端渲染的结果发生动态变化。client component chunk的核心就是一个返回react element的js函数。类json数据中client componnet部分的解析过程的心智模型可以总结为:
// js函数来自于client component chunk,动态props来于【类react element】字符串 // js函数(动态props)的结果是react elment // 最后把react elment放回"@"占位符所在的位置。 js函数(动态props)=> react element => "@"占位符 -
服务端返回提前打包好的client component chunk文件。
界面更新流程
就官方体提供的Demo而言,界面随后的更新流程其实跟首屏加载流程相差无几。也就是说,浏览器想更新界面还是得通过发出/react请求来进行。服务端每接受到一个/react请求都要重新根据新的请求参数去完整地从根节点对整个server component“渲染”(其实用“计算”这个术语会更准确点)一遍,最后产出类json数据,并返回给客户端。
不同点在于浏览器这边。主要体现在两个方面:
-
浏览器对client component chunk的请求存在缓存机制。所以,在界面更新流程中,浏览器解析类json数据的时候,如果某个client component chunk已经下载过了,那么浏览器就不会再次发出该chunk的请求了。
-
界面更新阶段,类json数据解析过程中,存在一个叫“协调(reconciles)”行为。这是首屏加载阶段所不存在的行为。这个“协调”的概念跟我们在CSR时期react所提出的“协调”的概念应该是差不多的。目的都是为了尽量地减少DOM操作,与此同时还能保存界面的相关UI状态,比如:输入框的focus状态,页面元素的CSS transitions 动画状态等。引入server component之后,react应用还能在界面更新的时候去完整地保留UI状态,这也是server component实现之所以返回类json数据而不是HTML片段的关键原因。
小结
关键词:
- 动静分离
- 本质上还是客户端渲染
- 中间层思想
上面已经对两个阶段所对应的流程梳理一遍,现在我们来总结一下server component实现的基本原理。
server component的基本原理就是把【组件渲染】的工作从客户端挪到服务端。
我们可以拿【组件状态的数据源是服务端API】这么一个场景进行比较。在这种场景下,如果组件的渲染是由客户端来完成的话,那么这个过程是这样的:

如果组件是由服务端来渲染的话,这个过程是这样的:

可以看出,相比与客户端的组件渲染,服务端组件渲染的结果并不是真正的react element,而是一份描述UI界面的类json数据,这里面的工作是由react-server-dom-webpack服务器运行时来完成的。因为diff操作是基于react element的,所以react通过react-server-dom-webpack浏览器运行时完成了对类json数据到react element的转化。
综上所述,react为了实现我们在【产生背景】所提到的目标,加入了react-server-dom-webpack这个中间层来实现了一份关于客户端+服务端协调渲染的协议。从有没有完整地返回一个html文档来作为【是否是服务端渲染】的评判标准来看,server component仍然是属于客户端渲染技术。
以上是server component的基本原理,更细致的原理肯定是藏在react-server-dom-webpack这个中间层里面。这里面包含了react在服务端是如何实现从JSX编译到类json字符串的细节,react在客户端是如何实现对类json字符串的解析的细节,这个话题留给日后再探索。
跟以往的技术有什么区别
server component跟SSR相比
简单来说,SSR就是将首屏所对应的组件渲染成一个html markup,然后塞到模板里面,形成一个完整的html文档再返回给浏览器。而server component是将组件渲染成一个react自定义的类json的字符串并返回给浏览器,由浏览器上的react运行时去解析并继续渲染。上面提到了,server component本质上还是客户端渲染技术。另外,官方也提到了,我们也可以将类json的字符串转换为html markup,从这个角度来说,server component技术可以是SSR技术的子集。
server component跟CSR相比
对于web这个平台而言,所谓的客户端渲染技术就是指页面内容完成依靠javascript来生成的。从这个角度来说,server component跟CSR本质上是一样的。但是从浏览器与服务器交互的方式来看,CSR应用从服务端取回的是【json格式的业务数据】,然后所有的组件渲染都是在浏览器端渲染完成;而server component框架下的应用从服务端取回的是【类json格式的UI描述数据】。而组件又分为client component和server component。client component渲染是在浏览器端完成,server component渲染是跨端完成的(服务端完成jsx到类json字符串的编译,浏览器端完成类json字符串到react element的编译)。
server component跟纯服务端渲染相比
纯服务端渲染是指jsp,php时代的渲染技术,浏览器每发起一个http请求,服务器都会返回一个完整的html文档,浏览器都会重新走一遍html文件解析流程。显然,这是最原始的页面渲染技术,也是最纯正的服务端渲染。server component并不是纯服务端渲染技术,而是属于客户端渲染技术。
server component跟GraphQL相比
GraphQL发明的初衷是跨语言边界的类型安全查询和后端API的聚合。而server component指代的是一种页面渲染技术。两者不是同一个维度的技术,而是两种可以结合到一块来使用的技术。比如说,在facebook内部,他们就将relay,GraphQL和server component结合来使用。
如何应用
client component 还是 server component?
在server component架构下,react应用是由client component和server component组成的。在这个架构下,我们首先要面临的决策是,哪些组件实现为client component,哪些组件实现为server component。当一个react component满足以下条件之一,我们可以将它实现为server component:
- 组件参与首屏渲染,并且对应的渲染结果为静态内容;
- 组件内部依赖大型的第三方类库来进行计算;
- 组件内部为了获取业务数据而产生过多的网络往返;
- 组件内部存在大量抽象层,也就是说包含大量的非渲染型子组件。
编写组件代码需要遵守的规则
取决于client component和server component所运行的环境(浏览器和服务端),我们在编写对应的组件代码的时候要遵循相应的规则。
对于server component而言,我们要遵守一下规则:
-
不能使用state。因为只有server component的渲染只能由客户端请求来触发并执行一次,所以server component是没有内部状态可言的。所以,我们也不能使用useState()和useReducer等跟state相关的hook;
-
不能使用生命周期相关的effect。useEffect()和useLayoutEffect()是不被允许的;
-
不能使用只适用在浏览器端的API,比如DOM,CSSOM等;
-
不能使用基于state或者effect的自定义hook;
-
server component可以嵌套client component
-
server component可以访问本地数据库,内部(微),文件系统等等。
对于client component而言,我们要遵守一下规则:
-
client component不能【import】并在jsx中使用【真正的】server component。但是可以【嵌套】server component。当然,这个嵌套是有前提的。如果一个client component被server component所嵌套,那么另外一个server componnet可以被当作children被这个client component所嵌套。比如下面的代码是合法的:
<ServerApp> <ClientTabBar> <ServerTabContent /> </ClientTabBar> </ServerApp>与上面的示例,下面的代码是非法的:
// App.server.js <ServerApp> <ClientTabBar /> </ServerApp> // ClientTabBar.client.js import ServerTabContent from './ServerTabContent.server.js' function ClientTabBar(){ return (<div><ServerTabContent /></div>) } -
client component不能访问仅服务端可用的API;
-
client component可以使用state;
-
client component可以使用effects;
-
client component可以使用基于state和effects来实现的自定义hook;
-
client component可以使用浏览器相关的能力;
未决事宜
server component的基本原理算是定调的,但是还有很多技术细节和周边生态的整合工作还是在进行中。比如,RFC罗列出来的就有以下这些:
- Developer Tools
- Routing
- Bundling
- Pagination and partial refetches
- Mutations and invalidations
- Pre-rendering
- Static Site Generation
详情可以参考RFC的Open Areas of Research小节。
总结
总的来说,如果单纯谈论react server component的话,它跟当前主流的CSR是一样的,本质上都是属于基于javascript的客户端渲染技术。只不过它相比我们当前主流采用的CSR而言,多了以下几个优点:
- 更小的首屏加载体积
- 更强大的数据处理能力
- 自动code split
- js chunk的预加载
- 一个统一且充满弹性的前后端融合技术方案
如果,单独看待其中的一点的话,可能其他技术方案也是能做到的。react server component的独特之处在于它的总体优势,即它能通过一个技术方案同时解决所有的问题。更难能可贵的是,它跟其他技术并不是互斥的,而是可以结合到一块,从而组成一个更完整和强大框架。
当然,react server component并不是银弹。它解决了问题,但是带来了其他问题,比如跨端开发的环境复杂性所带来的的维护成本变高,加入中间层所带来的理解成本变高等问题。所以,我们需要根据具体的业务场景,辩证地看待和采用react server component。
不过,react server component还有很多技术细节和周边生态的整合工作还没有完全确定,万一它跟别的生态(比如next.js)整合出一个完整的,适用于多业务场景(支持CSR,SSR,静态网站生成等)框架而成为了行业的统一标准呢?届时,那么它有可能就成为了react前端的一颗“银弹”(因为我们只需要它这么一个框架就好)。
不管怎么说,react server component将会是前端社区的一个里程碑,它标志着前端这个岗位的职能边界已经扩大到服务端编程了。与此同时的一个事实是:也许react.js还可以称之为一个【类库】,但是“react”早就是一个【框架】了。
参考资料
-
Introducing Zero-Bundle-Size React Server Components;
-
RFC: React Server Components;
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!