本文背景是公司在很久以前让我研究WebRTC,要实现一些基于WebRTC的功能,经过一番于谷歌查阅资料和看别人的例子文章,于是有了这篇文章,中间各种事情拖到现在才完成(如有错误请指出会及时更新)。
本篇内容整理了以下内容:
- WebRTC基本知识
- WebRTC相关名词
包含例子:
-
WebRTC本地一对一视频通话示例
-
WebRTC本地在线一对一视频通话示例
-
基于peerjs的WebRTC示例
-
基于WebRTC+MediaRecorder实现录音的实例
-
基于WebRTC+WebAUdio实现录音的例子
-
基于WebRTC+WebAUdio实现录音压缩的例子
你能了解到:
-
基于WebRTC实现端对端实时聊天
-
基于WebRTC实现端对端实时视频聊天
-
基于WebRTC实现录音功能
介绍
WebRTC是什么?
WebRTC是一个技术集,就像WebComponent一样,它的API包含三个部分:
- getUserMedia:获取本地媒体资源(摄像头、麦克风)
- RTCPeerConnections:建立本地代理,用于点对点传递媒体流
- RTCDataChannel:点对点的数据连接通道
WebRTC的优势
- 平台和设备的独立。开发人员可以通过支持WebRTC的浏览器开发基于WebRTC的各种应用,无需担心终端和操作系统层面的兼容性问题。另外,WebRTC也提供了标准的API(W3C)和其标准的协议支持(IETF)避免了平台兼容性的问题。
- 语音和视频的安全处理, WebRTC通过SRTP对语音和视频进行加密处理。用户使用浏览器登录访问语音和视频需要比较安全的设置要求,满足了用户场景的安全要求(例如,在无安全保障的wifi环境下的语音和视频),其他人不能对其进行监听。
- 支持高级语言和视频处理,WebRTC支持了最新的编码,语音支持了Opus,视频支持了VP8。内置的编码排除了其他第三方下载的安全隐患,同时能够支持网络环境的调整,实现了比较好的语音或视频质量。
- 支持可靠性传输创建,WebRTC提供了可靠性传输方式,包括了在NAT环境下仍然可以实现传输的稳定性。
- 支持多媒体流处理,WebRTC提供了多媒体和多资源的聚和,提供了RTP和SDP的拓展。
- 支持不同网络环境调节,因为WebRTC在网络平台执行,所以对网络环境和带宽非常敏感。它可以自己检测,调整网络环境和带宽需求,避免网络拥塞。它通过RTCP和SAVPF来保障此功能。
- 和VoIP语音视频有比较好的兼容性,WebRTC实现了和其他媒体的兼容性操作,包括了SIP,Jingle和XMPP对接。同时,如果需要和传统的其他协议对接的话,可以通过WebRTC 网关来实现兼容性的流畅性,保证和传统协议的兼容性。
WebRTC能干什么
- 在线聊天室
- 在线视频聊天
- 远程试试监控
- 屏幕共享
- 大文件点对点传输
- 实时游戏
- 直播
- 。。。
- 等一切需要实时性的应用场景
发展历史
最早的语音通讯协议
提到WebRTC我们可以追溯到最早的语音通讯协议(同时也是最早的互联网流协议)——网络语音协议(英语:Network Voice Protocol,缩写:NVP)最早于1973年有南加州大学信息学院研究院的网络研究员Danny Cohen所实现。此项技术最早的研究目的是展示同时具备数字化的高质量、低带宽、以及具有加密语音处理的能力,以满足一般军事需求中全球加密语音通信的部分。
此协议包含了两个不同的部分,控制协议以及资料传输协议;控制协议包含了相对较基本的电话功能,例如来电显示,铃声,声音编码的交涉,以及结束通话。资料消息则包含了语音的声码,对声码格式来说,一个"页框"(frame)的定义是指在传输交涉间隔中包含一些数字语音样本的数据包。
实时传输协议
WebRTC中采用的实时传输协议(Real-time Transport Protocol或简写RTP),由IETF的多媒体传输工作小组1996年在RFC 1889中公布。
RTP协议详细说明了在互联网上传递音频和视频的标准数据包格式。它一开始被设计为一个多播协议,但后来被用在很多单播应用中。RTP协议常用于流媒体系统(配合RTSP协议),视频会议和一键通(Push to Talk)系统(配合H.323或SIP),使它成为IP电话产业的技术基础。RTP协议和RTP控制协议RTCP一起使用,而且它是创建在UDP协议上的。
RTP标准定义了两个子协议:
- RTP(数据传输协议):用于实时数据传输,此协议提供的信息包含时间戳(用于同步)、序列号(用于丢包和重排序检测)、负载格式(用于说明数据的编码格式)
- RTCP(控制协议):用于QoS反馈和同步媒体流,所占贷款只有RTP的5%
WebRTC发展历程
- 1990年,Gobal IP Solutions成立于瑞典斯德哥尔摩,主要开发VoIP,提供质量极高的语音引擎。Skype、QQ、WebEx、Vidyo等知名应用都是用了他的音频处理引擎,包含了受专利保护的回声消除算法,适应网络抖动和丢包的低延迟算法,以及先进的音频编解码器。Google 在 Gtalk 中也使用了 GIPS 的受权。
- 2010年5月,Google以6820万美元收购VoIP软件开发商Global IP Solutions的GIPS引擎,并改为名为“WebRTC”。WebRTC使用GIPS引擎,实现了基于网页的视频会议,并支持722,PCM,ILBC,ISAC等编码,同时使用谷歌自家的VP8影片解码器;同时支持RTP/SRTP传输等。
- 2012年1月,谷歌已经把这款软件集成到Chrome浏览器中。同时FreeSWITCH项目宣称支持iSAC audio codec。
相关名词
NAT
NAT是网络地址交换协议(Network Address Translation ,简写为NAT )的英文简称,用于给设备映射一个公网IP地址。
一般的网络环境都会处于一个NAT设备(路由器之类的设备)之下。NAT设备会在IP封包经过设备时修改源/目的IP地址。对于家用路由器来讲, 使用的是网络地址端口转换(NAPT), 它不只改IP, 还修改TCP和UDP协议的端口号, 这样就能让内网中的设备共用同一个外网IP。咱们的设备常常是处在NAT设备的后面, 好比在大学里的校园网, 查一下本身分配到的IP, 实际上是内网IP, 代表咱们在NAT设备后面, 若是咱们在寝室再接个路由器, 那么咱们发出的数据包会多通过一次NAT。
NAT机制之一就是,全部外网对内网发送的请求,到达NAT时,都会被NAT屏蔽,如果设备处于NAT设备之下,将无法获取外网数据。这也形成了所谓的内网穿透
网络打洞:A主动往B发送一条数据,A的数据虽然没有发送到B,但是B能够给A发送数据,这个过程称之为打洞。
打洞是解决内网穿透问题的方案,A、B各自在对方NAT设备上打个洞,之后就能够正常通讯了。
NAT网络分为四种:
- 完美锥形NAT
- IP限制锥型NAT
- 对称型NAT
- 端口限制锥型NAT
SDP
SDP是会话信息描述(Session Description Protocol,简写为SDP),SDP用于描述多媒体链接内容,如:分辨率、格式、编码、加密算法等,所以这些内容并不是媒体流本身。
SDP不是一种协议,而是一种数据格式。其数据结构体由一行活着多行UTF-8文本组成,每行以一个字符的类型开头,后跟等号(“ =”),然后是包含值或描述的结构化文本,其格式取决于类型。以给定字母开头的文本行通常称为“字母行”。例如,提供媒体描述的行的类型为“ m”,因此这些行称为“ m行”。
ICE
ICE是交互式连接创建的英文的缩写(Interactive Connectivity Establishment),是一个允许你的浏览器和对端浏览器建立连接的协议框架。
在实际情况下,有很多原因能够导致你的端对端连接不能成功进行,这时候需要绕过防火墙进行连接,给设备分配一个唯一可见的地址。
ICE可集成各种NAT穿透技术,如:STUN、TURN
STUN
STUN是NAT会话穿越功能的简称(Session Traversal Utilities for NAT),它是一种允许唯有NAT后的客户端找出自己的公网地址,阻止直连的限制方法的网络协议。
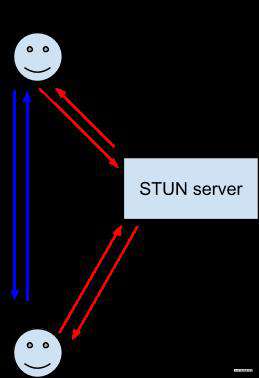
在实际的WebRTC应用中,客户端并不能通过信令服务器顺利的连接到对等端,我们需要通过NAT会话穿越服务获取本地及对等端的公网地址,其大致流程如下(可以理解为媒婆做媒过程中双方交换微信的过程):
TURN
TURN是中继穿越方式(Traversal Using Relay NAT)的英文简称,是一种资料传输协议(STUN/RFC5389的一个拓展),它允许TCP或UDP连接跨域NAT或者防火墙。
TURN服务是一种中继服务,用来中转两端的所有数据,如图所示,这种服务显然开销很大(相亲双方不仅没有微信,而且很内向,只能靠媒婆传递各种讯息,媒婆会有点累),所以WebRTC只有在两端无法建立连接且STUN服务无法使用的情况下才适用:
信令
信令是在两个设备之间发送控制信息以确定通信协议、信道、媒体编解码器和格式以及数据传输方法以及任何所需的路由信息的过程。
**信令在规范中并没有定义。**所以我们需要自己选择信息协议(SIP/XMPP)、双向通道(WebSocket/XMLHttpRequest)与持久连接服务器的API(如数据通道)一起使用。这样设计的原因是规范不可能预测所有WebRTC可能用例,让开发者自己选择合适的网络技术和消息传递协议会更好。
信令期间交换的信息有三种基本类型:
-
控制消息:用于设置、打开、关闭通信通道并处理错误。
-
为了建立连接所需的信息:设备间能够彼此交谈所需的IP寻址和端口信息。
-
媒体能力协商:交互双方可以理解哪些编解码器和媒体数据格式
整个信令过程大致如下:
- 每个Peer创建一个RTCPeerConnection对象,用来表示其WebRTC会话端。
- 每个Peer建立一个icecandidate事件的响应程序,用来在监测到该事件时将这些candidates通过信令通道发送给另一个Peer。
- 每个Peer建立一个track事件的响应程序,这个事件会在远程Peer添加一个track到其stream上时被触发。这个响应程序应将tracks和其消受者联系起来,例如
<video>元素。 - 呼叫者创建并与接收者共享一个唯一的标识符或某种令牌,使得它们之间的呼叫可以由信令服务器上的代码来识别。此标识符的确切内容和形式取决于您。
- 每个Peer连接到一个约定的信令服务器,如WebSocket服务器,他们都知道如何与之交换消息。
- 每个Peer告知信令服务器他们想加入同一WebRTC会话(由步骤4中建立的令牌标识)。
- 描述,候选地址等
信令服务器
信令服务器是用于在两台设备尽可能的暴露少的情况下交换数据,并不需要对数据进行处理,只需要转发到对应设备就可以了,本质上是一个中继服务。
你可以把信令服务想象成现代媒婆:男女双方中的一方提出相亲需求,煤婆给你物色符合条件的对象,在对方同意的情况下,他们交换信息,最终通过媒婆或见面、或线上聊,无论过程、结果怎么样都不需要经过媒婆,而媒婆也会保证两人信息的隐私性。
相关技术点
媒体流与媒体流通道
MediaStreamTrack:单个音频或者视频通道,一般包含于媒体流中;通过多个媒体流通道,能够做到音画同步
MediaStream:媒体内容的流,包含多个音视频轨道
WebRTC通过navigator.mediaDevices.getUserMedia来获取媒体流,通常配合Video或者Audio播放获取到的媒体流:
const { localVideo, peer } = this
this.mediaStream = await navigator.mediaDevices.getUserMedia({
audio: true,
video: true
})
localVideo.srcObject = this.mediaStream
localVideo.onloadedmetadata = async () => {
await localVideo.play()
}
可通过navigator.mediaDevices.enumerateDevices获取媒体输入和输出列表:
const devices:Array<MediaDeviceInfo> = await mediaDevices.enumerateDevices()
if (!devices.find((item:MediaDeviceInfo) => item.kind === 'audioinput')) {
alert('设备不支持音频')
}
if (!devices.find((item:MediaDeviceInfo) => item.kind === 'videoinput')) {
alert('设备不支持视频')
}
媒体流通过getTract()获取媒体通道,通过关闭媒体通道可以关闭媒体流:
const tracks = this.mediaStream?.getTracks() ?? []
for (const track of tracks) {
track.stop()
}
WebRTC本地代理
RTCPeerConnection用于创建一个由本地设备到远端WebRTC的一个连接代理,RTCPeerConnection提供了创建、保持、监控、关闭连接的方法。此外RTCPeerConnection也是数据通道的基础,只有本地代理连接了远端,才能创建数据通道。
RTCPeerConnection简历点对点连接是WebRTC中最难的部分,虽然WebRTC内部已经帮我们简化了很多操作,但是新手依然容易踩中很多坑,如内网穿透。
其大致过程为(为了方便理解,我从其他地方盗来一个时序图?):
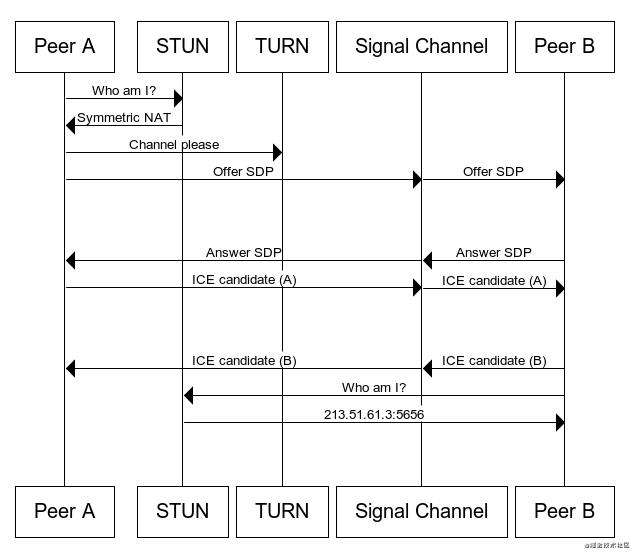
具体例子可以看这里
数据通道
WebRTC使用RTCDataChannel接口在两个代理之间创建双向数据通道连接,利用这个连接我们可以传输DOMString、string、ArrayBuffer、Blob、ArrayBuuferView等数据。一般配合RTCPeerConnection使用(通过RTCPeerConnection.createDataChannel创建数据通道)。
数据通道只需要呼叫端创建数据通道,而对等端只需要监听数据通道连接即可。
创建数据通道:
const dc = this.peer.createDataChannel(this.$socket.id)
发送数据:
dc.send(message)
监听对等端发送数据:
dc.onmessage = (e:MessageEvent) => {
this.messages.push({
sender: '对方',
message: e.data
})
}
对等端监听数据通道连接:
this.peer.ondatachannel = (e:RTCDataChannelEvent) => {
const dc = this.dataChannel = e.channel
dc.onmessage = (e:MessageEvent) => {
this.messages.push({
sender: '对面的',
message: e.data
})
}
}
具体例子请点击这里
浏览器支持情况

根据CanIse中显示的支持情况来看,现代浏览器支持良好,至于IE,所有前端的共识(其父微软弃之,另设小号Edge):
原生的WebRTC小例子
有一点很重要
想要获取媒体设备,必须开启Https,否则无法获取到
本地视频通话模拟
通过这个在线例子可以查看模拟本地视频通话(当然,你的设备得支持视频通话),效果如下:

代码可以点击这里查看
其大致流程如下图(只不过将信令服务器省略为本地直接设置):
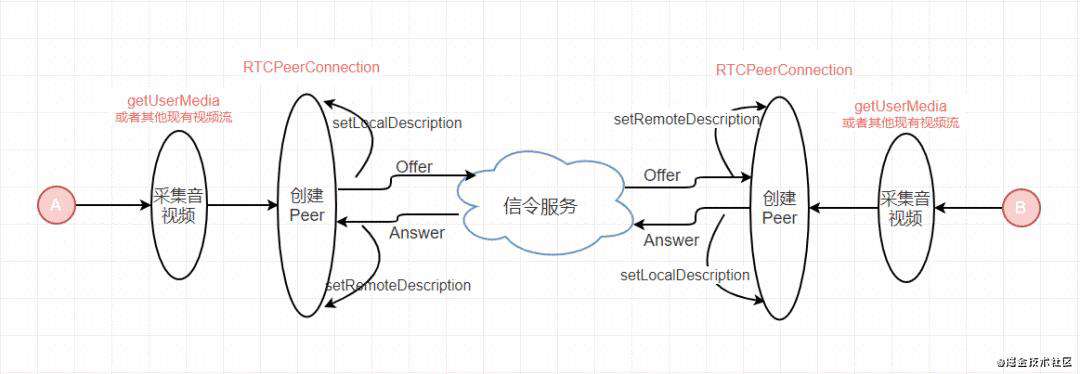
本地模拟端对端视频通话+数据通道例子
和本地视频类似,不同的是,增加了数据通道连接,具体例子请点击这里
项目中使用
如果你自己做过前面本地例子,你会发现,虽然原生WebRTC已经帮我们实现了很多复杂的东西,但是连接WebRTC连接还是还是步骤颇多,而且一旦哪个步骤出问题很难排查;简而言之,WebRTC坑多
所以一般在项目我们会使用第三方封装库,我们选择的是peerjs,peerjs能够帮我们许多问题,如浏览器兼容、连接流程、错误定位等,同时peerjs还提供了默认的中转服务(一般我们会自己搭,可以通过peerjs-server搭建自己的中转服务)
准备工作
peer服务
WebRTC虽然是端对端的通讯,但是也需要通过服务器交换一些信令、候选等信息。
我们有三种选择:
- 使用peerjs自带的中转服务
- 使用peerjs-server自己搭建搭建中转服务
- 由后端搭建中转服务
我选择的是第二种作为演示例子的中转服务,本次例子中直接开启服务:
全局下载包:
npm install peer -g
然后直接开启服务(如果不需要开启https,):
peerjs --port 9000 --key peerjs --path /appName
如果需要开启https,则需要--sslkey、--sslcert参数,这里使用Nginx证书
peerjs --port 9000 --key peerjs --path /appName --sslkey sslKeyPath --sslcert sslCertificate Path
如果需要有更高自由度或者结合现有的NodeJS服务可以在应用中使用peer中间件,如:
const express = require('express')
const { ExpressPeerServer } = require('peer')
const app = express()
app.get('/', (req, res, next) => res.send('Hello world!'))
const server = app.listen(9000)
const peerServer = ExpressPeerServer(server, {
path: '/myapp'
});
app.use('/peerjs', peerServer)
// 或者这样
const http = require('http')
const server = http.createServer(app)
const peerServer = ExpressPeerServer(server, {
debug: true,
path: '/myapp'
});
app.use('/peerjs', peerServer)
server.listen(9000)
验证信令服务是否开启:点击http://127.0.0.1:9000/myapp,如果返回下面格式的JSON数据,则代表成功:
{
"name": "PeerJS Server",
"description": "A server side element to broker connections between PeerJS clients.",
"website": "http://peerjs.com/"
}
通过peerServer的事件监听可以监听到设备连接和断开连接:
peerServer.on('connection', (client) => { ... })
peerServer.on('disconnect', (client) => { ... })
需要注意的是:如果SSL证书对应的域名没有解析到peer服务对应的服务器公网IP,第一次访问服务时需要访问测试连接,而且会过期。
stun、turn服务
当设备在不同的NAT网络环境下,需要由stun服务进行网络穿透,当stun服务用不了时使用turn服务进行数据中转。
stun服务搭建
stun服务搭建有很多种方式,window可以使用STUNTMAN快速搭建,并且STUNTMAN提供了客户端测试程序,具体教程请点击传送门。还有一个需要注意,如果你在云服务而非本地测试,stun需要有双公网IP服务器。
turn服务搭建
turn有很多种搭建方式,其中很多人使用coturn,但是如果你的服务器是window系统,就会显得很麻烦,需要安装一大堆东西,对于对于学习和快速交付例子是很不利的;所以我们使用node-turn,使用node快速搭建应用,具体教程直接看官网就行,或者查看例子
例子
一个使用peerjs视频聊天的例子,及源码
需要注意的坑
WebRTC需要开启https
http被认为是不安全的,新版本的WebRTC需要开启Https才能使用,如果没有开启https获取用户摄像头/麦克风权限时会报如下错误:
Uncaught (in promise) TypeError: Cannot read property 'getUserMedia' of undefined
stun服务需要在双公网IP服务器中才能使用
在测试过程中,发现在本地搭建的stun服务能够正常使用,然而在云服务器中搭建的服务使出浑身解数还是不正常使用,后来查了很久的资料才发现,原来是需要双公网IP才能够正常使用。所以如果项目中真的需要使用WebRTC,推荐使用turn服务。
信令服务需要将SSL证书绑定的域名解析到服务器的IP上
搭建完peer服务之后通常会测试下服务是否可用,然后在客户端中使用。
如果搭信令服务搭建在本地,或者SSL证书对应的域名没有解析到服务器公网IP,在其他设备中测试时,会发现无法访问peer服务,并且报错误如下:
ERROR PeerJS: Error: Lost connection to server.
这时候访问一下测试连接服务又能访问了,导致这个问题的原因是浏览器认为这不是安全的链接,会阻止链接访问(新开页面访问会先阻止访问链接,并询问是否访问)。
解决:将域名解析到服务对应的服务器公网IP即可。
WebRTC实现录音功能
有两种方案实现录音功能:
- WebRTC+MediaRecorder+WebAudio
- WebRTC+WebAudio
相关知识点
MediaRecorder+MediaStream录制音频
这种方式实现录音要简单点,因为直接使用浏览器提供的录制音频接口,但是缺点是只能兼容部分浏览器:

MediaStream可以通过navigator.mediaDevices.getUserMedia()接口获取,具体可以看前面音视频通话的例子。
需要用到的事件或函数:
-
MediaRecorder()构造函数传入一个MediaStream,并对传入的媒体流进行录制。 -
MediaRecorder.ondataavailable事件处理程序用于处理录制器触发的dataavailable事件,时间的回调会提供录音的Blob对象,dataavailable事件在以下情况下触发并返回包含Blob数据的对象: -
媒体流结束
-
录制器主动停止录制
-
调用
MediaRecorder.requestData()时 -
如果开始录制时设定了录音分割间隔,则会每隔这段时间触发一次
-
MediaRecorder.onend事件处理程序会在录制器录制结束时触发 -
MediaRecorder.strt():开始录制,可传入单位为毫秒的分割时间间隔,将录音分割成多个单独的区块 -
MediaRecorder.stop():停止录制音频
录制过程:
-
通过
navigator.mediaDevices.getUserMedia()获取媒体流 -
使用媒体流创建
MediaRecorder实例,指定采样比特率和录制类型 -
添加对应的事件,如:dataavailable、end等事件
-
在合适的时机调用
MediaRecorder.strt()开始录制 -
在合适的时机调用
MediaRecorder.stop()结束录制
例子:
// 获取麦克风媒体流
const stream = this.mediaStream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: 48000,
channelCount: 2
},
video: false
})
// eslint-disable-next-line @typescript-eslint/ban-ts-comment
// @ts-ignore
// 创建录制器
const recorder = this.recorder = new MediaRecorder(stream, {
audioBitsPerSecond: 256000,
mimeType: 'audio/webm'
})
// 当得到数据时的处理回调
recorder.ondataavailable = async (e: { data:Blob }) => {
console.log(e.data)
this.audioData.push(e.data)
}
// 当录制停止时
recorder.onstop = () => {
const time = (new Date()).toISOString().replace('T', ' ')
// 根据二进制文件对象生成文件对象
this.currentFile = new File(this.audioData, `${time}.mp3`, { type: 'audio/mpeg' })
this.audioData = []
}
// 每隔10毫秒进行一次录制数据切割
recorder.start(10)
//当我们需要停止录制时
this.recorder.stop()
更多文档请点击这里
MediaStream+WebAudio录制音频
AudioContext
AudioContext是WebAudio中用于处理音频的类,表示链接在一起的音频模块(AudioNode)构建的音频处理图;音频的何种操作都需先创建一个AudioContext的实例,因为所有的音频操作都是基于AudioContext
const ac = new AudioContext()
AudioNode
AudioNode是一个处理音频的通用模块(Audio、Video、MediaStream等输入源),既有输入也有输出,在这里我们读取MediaStream输入源,然后连接到AudioContext上:
const ac = new AudioContext()
const mediaNode = this.mediaNode = ac.createMediaStreamSource(stream)
mediaNode.connect(jsNode)
ScriptProcessorNode
ScriptProcessorNode用于生成、处理、分析音频,继承自AudioNode;它 连接着两个缓冲区音频处理模块, 其中一个缓冲区包含输入音频数据,另外一个包含处理后的输出音频数据;实现了AudioProcessingEvent接口的onaudioprocess时间,能够监听到音频流入缓冲区。
我们利用这一特性监听音频流入,然后将数据保存:
const creator = ac.createScriptProcessor.bind(ac)
const jsNode = this.jsNode = creator(16384, 2, 2)
jsNode.connect(ac.destination)
jsNode.onaudioprocess = (e: AudioProcessingEvent) => {
const audioBuffer = e.inputBuffer
const leftData = audioBuffer.getChannelData(0)
const rightData = audioBuffer.getChannelData(1)
this.volume = rightData[rightData.length - 1] + 1
// 这里有个坑,如果不进行深拷贝的话,录制出来的音频会有问题
this.leftAudioData.push(leftData.slice(0))
this.rightAudioData.push(rightData.slice(0))
}
具体流程
- 通过
navigator.mediaDevices.getUserMedia获取媒体流 - 创建AudioContext
- 通过媒体流创建AudioNode,将其连接到AudioContext
- 创建ScriptProcessorNode,并添加数据流入事件,将其连接到AudioNode上
- 添加停止录制按钮并添加事件,对数据进行处理
例子
录制:
// 获取麦克风媒体流
const stream = this.mediaStream = await navigator.mediaDevices.getUserMedia({
audio: {
sampleRate: 48000,
channelCount: 2
},
video: false
})
// 通过WebAudio保存录音
const ac = new AudioContext()
// 通过媒体流创建一个audioNode
const mediaNode = this.mediaNode = ac.createMediaStreamSource(stream)
// 绑定createScriptProcessor的this为AudioContext,然后创建一个处理了音频的节点
const creator = ac.createScriptProcessor.bind(ac)
const jsNode = this.jsNode = creator(16384, 2, 2)// 设置的更小的话会造成有杂音
// 连接到AudioContext
jsNode.connect(ac.destination)
// audioNode连接到jsNode
mediaNode.connect(jsNode)
// 添加音频流入事件
jsNode.onaudioprocess = (e: AudioProcessingEvent) => {
const audioBuffer = e.inputBuffer
const leftData = audioBuffer.getChannelData(0)
const rightData = audioBuffer.getChannelData(1)
this.volume = rightData[rightData.length - 1] + 1
// 这里有个坑,如果不进行深拷贝的话,录制出来的音频会有问题
this.leftAudioData.push(leftData.slice(0))
this.rightAudioData.push(rightData.slice(0))
}
停止录制:
const { mediaStream } = this
// 获取所有的媒体通道并停止他们
const tracks = mediaStream.getTracks()
clearInterval(timer)
tracks.forEach(track => {
track.stop()
})
// 停止录音
this.jsNode.disconnect()
this.mediaNode.disconnect()
// 合并数据
const left = mergeArray(this.leftAudioData)
const right = mergeArray(this.rightAudioData)
const audioData = mergedProvincialHighway(left, right)
this.currentFile = createAudioFile(audioData)
this.leftAudioData = []
this.rightAudioData = []
播放录音
经过处理之后我们得到一个File类型的数据,通过FileReader读取这个数据,读取后的结果是一个ArrayBuffer,我们使用AudioContext进行解码,通过AudioNode可以播放这个音频:
function playAudio (file: File, errMsg: string): Promise<void> {
if (!file) {
return Promise.reject(errMsg)
}
// 创建一个文件读取器
const fileReader = new FileReader()
// 通过AudioContext播放音频
fileReader.onload = async () => {
// 创建一个AudioContext
const audioContext = new AudioContext()
// 创建一个AudioNode通过AudioContext
const audioNode = audioContext.createBufferSource()
// AudioContext对二进制文件进行解码
audioNode.buffer = await audioContext.decodeAudioData(fileReader.result as ArrayBuffer)
audioNode.connect(audioContext.destination)
audioNode.start(0)
}
// 读取选中的文件
fileReader.readAsArrayBuffer(file)
return Promise.resolve()
}
下载到本地
我们有了File类型的数据,可以使用URL.createObjectURL()方法创建包含该数据对象的URL,然后绑定到动态创建的超链接元素,然后触发其单击事件:
function downloadToLocal (file: File, errMsg: string): Promise<void> {
if (!file) {
return Promise.reject(Error(errMsg))
}
const time = (new Date()).toISOString().replace('T', ' ')
const a = document.createElement('a')
a.href = URL.createObjectURL(file)
a.setAttribute('download', `${time}.mp3`)
a.click()
return Promise.resolve()
}
录音文件压缩
使用MediaRecorder录制的文件,其数据本身已经做了优化,因此不需要再压缩,我们只需要对WebAudio录制的音频进行压缩处理。
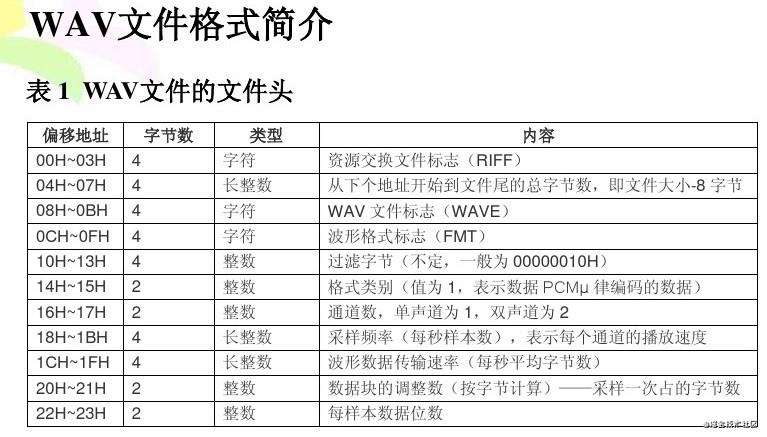
查阅了WAV文件头,具体要做的操作如下:
- 双声道变单声道
- 降低采样位数
- 降低采样率
双声道变单声道
改变声道数量是最简单的方法,只需要如下操作:
- 在创建ScriptProcessorNode的时候指定输入输出为单声道(实际体积减少二分之一)
- 音频数据流入缓冲区时保存第一个声道的数据
- 创建音频文件时声道有关的都设定为1
改变采样位数
改变采样位数只需要在生成音频文件的时候将采样位数由原来的16改为8即可
降低采样率
采样率决定了每秒钟数据大小,降低采样率能够有效的降低文件体积,弊端就是音频没那么清晰。降低采样率可通过对采集的数据进行切割抛弃,按比例跳过一些数据(比例=原采样率/降低之后的采样率,由于我们直接按比例跳跃式抛弃掉ArrayBuffer中的数据,所以这两个采样率必须有倍数关系)
同时生成音频文件的采样率要和一致
例子
WebRTC+WebAudio实现录音压缩的例子,及代码
实例
WebRTC+MediaRecorder+WebAudio实现录音的例子,及代码
WebRTC+WebAudio实现录音的例子,及代码
WebRTC+WebAudio实现录音压缩的例子,及代码
最后
如果有机会且有时间的话还会更新:
-
WebRTC实现多人视频通话
-
WebRTC实现多人实时聊天
-
WebRTC实现大文件传输
-
。。。
如果这篇文章恰好对你有帮助的话,烦请动动发财的小手帮忙点个赞吧?
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!